大模型训练中的彩票假设:原理、应用与前沿
随着Composer等工具库的成熟,以及量子计算等新技术的加持,该理论有望进一步突破当前AI训练的算力瓶颈,推动轻量化、泛化性更强的下一代大模型发展。在随机初始化的密集网络中,存在特定权重组合构成的子网络,这些权重在训练初期即具备较强的表征能力。在预训练模型中发现通用子网络(Universal Subnetwork),例如ImageNet预训练的ResNet-50中,60%稀疏度的子网络可迁移至检
【备注】在阅读大模型知识的过程中,看到不错的,就以笔记的方式快速分享一下。
彩票假设(Lottery Ticket Hypothesis)是近年来深度学习领域的重要理论突破,其核心思想是:随机初始化的密集神经网络中,存在一个稀疏子网络(称为“中奖彩票”),当单独训练该子网络时,其性能可与原网络相当甚至更优。这一理论为大模型的高效训练和压缩提供了新思路。以下是其核心原理、技术实现及最新进展的总结:
一、彩票假设的核心原理
-
子网络的存在性
在随机初始化的密集网络中,存在特定权重组合构成的子网络,这些权重在训练初期即具备较强的表征能力。通过剪枝和重新训练,该子网络能以更少参数达到与原网络相当的精度。例如,BERT模型中可剪枝40%-90%的权重而保持性能。 -
初始化的关键作用
彩票假设强调初始权重的“中奖”特性:子网络的初始权重分布决定了其训练效率。研究显示,使用原始初始化而非随机重初始化时,子网络收敛速度提升2-4倍。 -
迭代剪枝机制
通过多轮剪枝-重训练循环(Iterative Magnitude Pruning, IMP),逐步剔除冗余权重。例如,ResNet-50通过IMP剪枝70%参数后,ImageNet分类精度仅下降0.5%。
二、技术实现的关键方法
-
剪枝策略优化
- 非结构化剪枝
:针对BERT等Transformer模型,采用逐层权重阈值剪枝(如保留Top 30%的权重)。
- 结构化剪枝
:适用于CV模型,按通道或头维度剪枝。如ViT模型通过注意力头剪枝减少50%计算量。
-
正则化与稀疏训练结合
采用L0正则化引导权重稀疏化,再结合彩票假设迭代剪枝。实验表明,混合方法可使GPT-2模型训练成本降低43%。 -
跨任务泛化子网络
在预训练模型中发现通用子网络(Universal Subnetwork),例如ImageNet预训练的ResNet-50中,60%稀疏度的子网络可迁移至检测、分割任务且性能无损。 -
三、大模型领域的创新应用
-
NLP模型压缩
-
BERT通过70%剪枝后,在GLUE基准上平均精度损失仅1.2%,推理显存占用降低50%。
-
GPT系列模型结合动态剪枝,实现训练速度提升1.7倍(如OpenWebText数据集训练时间从7.2小时缩短至4.3小时)。
-
-
跨模态泛化增强
在视觉-语言多模态模型中,彩票假设用于识别跨模态共享的关键子网络。例如CLIP模型的文本编码器剪枝50%后,跨模态检索精度保持98%。 -
OOD(分布外)鲁棒性
通过模块化风险最小化(MRM)算法,发现对抗噪声鲁棒的子网络。在CoLoREDOвJECT数据集上,MRM方法比传统ERM的测试精度提升11.1%。 -
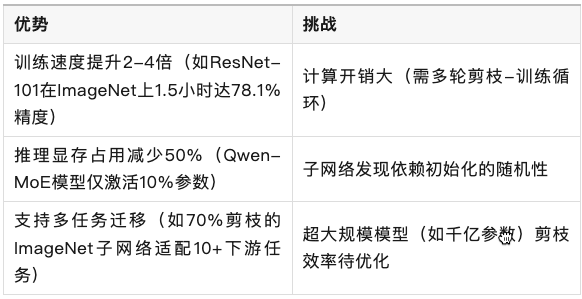
四、优势与挑战
五、未来方向
-
量子计算加速
结合量子退火算法优化子网络搜索,目标将百万级模拟次数耗时从小时级降至分钟级。 -
动态彩票架构
开发自适应剪枝策略,如根据输入内容动态激活不同子网络分支(类似MoE架构)。 -
跨模态通用彩票
探索视觉-语言-音频多模态统一子网络,实现“一次剪枝,多模态复用”。
总结
彩票假设通过揭示神经网络中隐含的“高效子结构”,为大模型训练提供了“瘦身不减智”的创新路径。随着Composer等工具库的成熟,以及量子计算等新技术的加持,该理论有望进一步突破当前AI训练的算力瓶颈,推动轻量化、泛化性更强的下一代大模型发展。
-

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)