西湖大学最新!ARFM:结合VLA模仿学习与强化学习的优势
以原始 VLA 流模型的动作分布pAt∣otp(A_t|o_t)pAt∣ot为基础(其中Atatat1atHAtatat1...atH,对应未来连续动作序列;otI1tIntℓtqtotI1t...Intℓtqt为多模态观测,包含n幅 RGB 图像IitI_i^tIit、语言指令 token 序列ℓt\ell^tℓt、机器人关节角度。
如今,基于流匹配的视觉-语言-动作(VLA)模型已经能帮机器人完成不少操控任务了,像 π 0 \pi_0 π0这类模型,凭借轨迹级建模能力在常规场景里表现还不错,就连 RT-1、PaLM-E 这些大规模预训练模型,也证明了从多模态数据里学通用策略是可行的。
可一碰到复杂的下游任务,比如要在动态干扰下精准抓东西,这些模型就有点 “力不从心” 了——动作精度掉得厉害。说到底,问题出在它们 “学东西的方式” 上:现在的 VLA 流模型全靠模仿学习做后训练,就像只会照搬别人动作,没法分清哪些训练数据质量更好、哪些策略更适合当前任务。而强化学习(RL)本来就擅长挖掘这些数据质量特性,可之前的离线 RL 方法,比如 ReinboT,在 VLA 流模型上效果并不好,因为这类模型是靠向量场建模整个动作轨迹的,ReinboT 只能间接指导动作生成,效率太低。
那怎么让 VLA 流模型既保留流匹配的轨迹建模优势,又能用好强化学习的能力呢?西湖大学团队提出的 “自适应强化流匹配(ARFM)” 方法就是来解决这个问题的。它通过在模型损失函数里加一个能自动调整的 “缩放因子”,一边让强化学习的优势信号充分发挥作用,重点关注高质量数据,一边控制梯度方差避免训练崩溃,让模型微调又稳又高效。后续的大量实验也证明,ARFM 在泛化、抗干扰、少样本学习这些方面都有明显提升,为机器人应对复杂任务提供了新思路。
论文题目:Balancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models
论文链接:https://arxiv.org/pdf/2509.04063
作者单位:西湖大学;加利福尼亚大学洛杉矶分校;西安交通大学
研究背景与问题
VLA 模型现状:基于流匹配的 VLA 模型(如 π 0 \pi_0 π0)在通用机器人操控任务表现出色,且大规模预训练系统(如 RT-1、RT-2、PaLM-E 等)已验证从多模态数据学习通用策略的可行性,但这类模型依赖模仿学习后训练范式,难以深入理解数据质量分布特性,在复杂下游任务中动作精度欠佳。
现有解决方案局限:部分研究尝试用离线 RL(如 ReinboT、RWR)微调 VLA 模型,其中 ReinboT 引入 RL 未来回报指导微调,但在 VLA 流模型中性能有限 —— 因 VLA 流模型通过向量场建模整个动作轨迹分布,推理阶段最大化未来回报仅能间接、低效地指导动作预测,如何有效对 VLA 流模型进行离线 RL 微调仍待探索。
主要贡献
方法创新:提出自适应强化流匹配(ARFM)这一新型离线强化学习(RL)后训练方法,专门用于视觉 - 语言 - 动作(VLA)流模型,可通过自适应调整数据质量分布,解决现有 VLA 流模型依赖模仿学习后训练、难以挖掘数据质量特性的问题,填补了 VLA 流模型高效离线 RL 微调的技术空白。
理论构建:从理论上确立自适应调整缩放因子的优化目标,通过引入该缩放因子构建具有严谨依据的偏差 - 方差权衡目标函数,同时推导得出实时更新缩放因子的二分迭代算法,实现对 RL 信号强度与流损失梯度方差的精准控制,为 VLA 流模型高效微调提供坚实理论支撑。
实验验证:在 LIBERO 仿真基准(含 Object、Long、Spatial、Goal 四大任务套件)与 UR5 真实机械臂平台开展大量实验,验证 ARFM 在泛化能力、动态扰动鲁棒性、少样本学习及持续学习方面均展现出当前最优性能,且超参数敏感性低、工程落地成本低,充分证明其在实际机器人操控场景中的应用价值。
核心算法设计
文章所提出的ARFM作为面向 VLA 流模型的自适应离线 RL 后训练方法,核心围绕 “构建能量加权损失以融合 RL 信号” 与 “设计自适应机制以平衡训练稳定性” 展开,通过理论推导与算法实现,解决传统模仿学习及现有离线 RL 微调在 VLA 流模型中的局限,具体设计可拆解为三部分:能量加权 VLA 流模型构建、缩放因子 α \alpha α的自适应优化、完整微调算法流程,各环节紧密衔接且具备理论支撑。
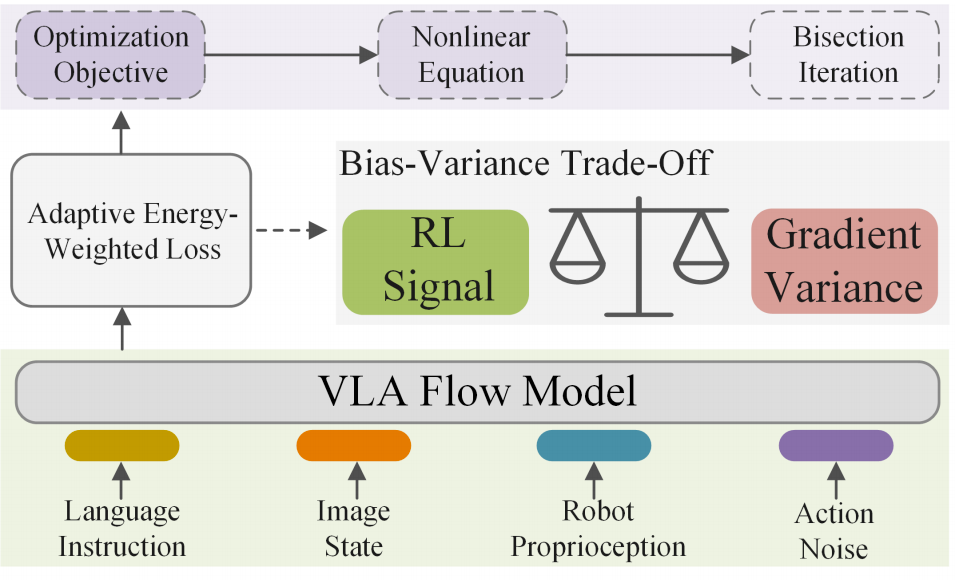
能量加权 VLA 流模型:融合 RL 信号的核心载体
该模块旨在将 RL 优势信号嵌入 VLA 流模型的训练目标,通过能量引导分布重塑动作轨迹的学习偏好,让模型更关注高质量(高 RL 优势)的数据样本,同时沿用流匹配模型对轨迹建模的优势,具体包含分布定义、损失函数设计与实际计算优化三方面。
能量引导的动作分布定义
以原始 VLA 流模型的动作分布 p ( A t ∣ o t ) p(A_t|o_t) p(At∣ot)为基础(其中 A t = [ a t , a t + 1 , . . . , a t + H ] A_t = [a_t, a_{t+1}, ..., a_{t+H}] At=[at,at+1,...,at+H] ,对应未来连续动作序列; o t = [ I 1 t , . . . , I n t , ℓ t , q t ] o_t = [I_1^t, ..., I_n^t, \ell^t, q^t] ot=[I1t,...,Int,ℓt,qt]为多模态观测,包含n幅 RGB 图像 I i t I_i^t Iit、语言指令 token 序列 ℓ t \ell^t ℓt、机器人关节角度 q t q^t qt),引入 RL 未来回报优势 R ∗ ( o t , A t ) R^*(o_t, A_t) R∗(ot,At)(通过 “留一法” 标准化得到,无偏且低方差),构建能量引导的目标分布: π ( A t ∣ o t ) ∝ p ( A t ∣ o t ) exp ( α R ∗ ( o t , A t ) ) \pi(A_t|o_t) \propto p(A_t|o_t) \exp(\alpha R^*(o_t, A_t)) π(At∣ot)∝p(At∣ot)exp(αR∗(ot,At)) 。其中 α \alpha α为缩放因子,是控制 RL 信号强度的核心参数 。具体来讲, exp ( α R ∗ ) \exp(\alpha R^*) exp(αR∗)项通过能量函数形式,对高 R ∗ R^* R∗(即 RL 优势更强)的动作样本赋予更高权重,使模型在训练中更倾向于学习这类高质量动作的轨迹分布。
条件能量加权流匹配(CEFM)损失设计
为学习上述能量引导分布 π ( A t ∣ o t ) \pi(A_t|o_t) π(At∣ot)的向量场(VLA 流模型的核心是通过向量场建模轨迹生成过程),基于能量加权流匹配(EWFM)理论,推导得到条件能量加权流匹配(CEFM)损失,具体形式为: L τ ( θ ) = E [ E ∗ ( A t , o t ) ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 ] \mathcal{L}^\tau(\theta) = \mathbb{E}\left[ \mathcal{E}^*(A_t, o_t) \left\| v_\theta(A_t^\tau, o_t) - u(A_t^\tau|A_t) \right\|^2 \right] Lτ(θ)=E[E∗(At,ot)∥vθ(Atτ,ot)−u(Atτ∣At)∥2]
损失构成解析:
- E ∗ ( A t , o t ) \mathcal{E}^*(A_t, o_t) E∗(At,ot):能量权重项,用于将 RL 优势信号融入损失,计算式为 E ∗ ( A t , o t ) = exp ( α R ∗ ( A t , o t ) ) E A t ∗ ∼ p ( ⋅ ∣ o t ) exp ( α R ∗ ( A t ∗ , o t ) ) \mathcal{E}^*(A_t, o_t) = \frac{\exp(\alpha R^*(A_t, o_t))}{\mathbb{E}_{A_t^* \sim p(\cdot|o_t)} \exp(\alpha R^*(A_t^*, o_t))} E∗(At,ot)=EAt∗∼p(⋅∣ot)exp(αR∗(At∗,ot))exp(αR∗(At,ot)),通过对 exp ( α R ∗ ) \exp(\alpha R^*) exp(αR∗)做归一化,避免因样本间 R ∗ R^* R∗差异过大导致权重失衡,且分母为批次内所有样本的能量均值,保证权重在合理范围。
- v θ ( A t τ , o t ) v_\theta(A_t^\tau, o_t) vθ(Atτ,ot):模型预测的向量场, θ \theta θ为 VLA 流模型(如 π 0 \pi_0 π0)的可学习参数,输入为 “带噪声动作” A t τ A_t^\tau Atτ与观测 o t o_t ot。
- u ( A t τ ∣ A t ) u(A_t^\tau|A_t) u(Atτ∣At):真实去噪向量场,是流匹配模型的核心监督信号,由动作样本 A t A_t At与噪声计算得到,具体形式为 u ( A t τ ∣ A t ) = ϵ − A t u(A_t^\tau|A_t) = \epsilon - A_t u(Atτ∣At)=ϵ−At( ϵ \epsilon ϵ为高斯噪声)。
- A t τ A_t^\tau Atτ:带噪声动作,生成方式为 A t τ = τ A t + ( 1 − τ ) ϵ A_t^\tau = \tau A_t + (1-\tau) \epsilon Atτ=τAt+(1−τ)ϵ( τ ∼ Uniform ( 0 , 1 ) \tau \sim \text{Uniform}(0,1) τ∼Uniform(0,1)为随机时间步, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0,I) ϵ∼N(0,I)为标准高斯噪声),模拟流匹配模型 “从噪声中逐步恢复真实动作轨迹” 的学习过程,确保模型能学习到轨迹的全局分布特性。
实际训练中的损失近似计算
理论上的 CEFM 损失需计算全局期望 E \mathbb{E} E,但实际训练中难以直接求解,因此采用批次采样近似策略,将损失转化为可高效计算的批次加权损失,具体形式为: L 1 τ ( θ ) = ∑ i = 1 B w i ( α ) ∥ v θ ( { A t i } τ , o t ) − u ( { A t i } τ ∣ A t i ) ∥ 2 \mathcal{L}_1^\tau(\theta) = \sum_{i=1}^B w_i(\alpha) \left\| v_\theta(\{A_t^i\}^\tau, o_t) - u(\{A_t^i\}^\tau|A_t^i) \right\|^2 L1τ(θ)=∑i=1Bwi(α) vθ({Ati}τ,ot)−u({Ati}τ∣Ati) 2
关键调整:
- 批次采样:每步训练采样B个数据对 ( o t , A t ) (o_t, A_t) (ot,At)(B为批次大小),用批次内样本替代全局样本计算损失。
- 权重简化: w i ( α ) = exp ( α R ∗ ( A t i , o t ) ) ∑ j = 1 B exp ( α R ∗ ( A t j , o t ) ) w_i(\alpha) = \frac{\exp(\alpha R^*(A_t^i, o_t))}{\sum_{j=1}^B \exp(\alpha R^*(A_t^j, o_t))} wi(α)=∑j=1Bexp(αR∗(Atj,ot))exp(αR∗(Ati,ot)),即批次内归一化的能量权重,替代理论中的全局期望,降低计算复杂度。
- 标准化处理:对 R ∗ R^* R∗按 VLA 多任务场景的 “任务类型” 进行标准化,确保不同任务(如抓取、放置)的 R ∗ R^* R∗具有可比性,避免因任务间回报尺度差异导致权重偏向某类任务。
缩放因子 α \alpha α的自适应优化:平衡信号与稳定性的关键
缩放因子 α \alpha α直接决定 RL 信号的影响力与训练稳定性 。 α \alpha α过小则 RL 优势信号无法有效体现,微调效果接近传统流匹配; α \alpha α过大则高能量样本权重过高,导致损失梯度方差激增,引发梯度爆炸或训练崩溃。为此,ARFM 通过理论构建优化目标与高效求解算法,实现 α \alpha α的实时自适应调整。
α \alpha α的优化目标函数构建
核心思路是 “最小化梯度方差以保证训练稳定” 与 “最大化 RL 优势信号以提升模型性能” 的权衡,基于此构建目标函数 J ( α ) J(\alpha) J(α): J ( α ) = Var ( g ^ ( α ) ) − λ S ( α ) J(\alpha) = \text{Var}(\hat{g}(\alpha)) - \lambda S(\alpha) J(α)=Var(g^(α))−λS(α)。
目标函数各部分解析:
- Var ( g ^ ( α ) ) \text{Var}(\hat{g}(\alpha)) Var(g^(α)):损失梯度的方差, g ^ ( α ) = ∇ θ L 1 τ ( θ ) = ∑ i = 1 B w ^ i ( α ) ∇ θ ∥ v θ ( { A t i } τ , o t ) − u ( { A t i } τ ∣ A t i ) ∥ 2 \hat{g}(\alpha) = \nabla_\theta \mathcal{L}_1^\tau(\theta) = \sum_{i=1}^B \hat{w}_i(\alpha) \nabla_\theta \left\| v_\theta(\{A_t^i\}^\tau, o_t) - u(\{A_t^i\}^\tau|A_t^i) \right\|^2 g^(α)=∇θL1τ(θ)=∑i=1Bw^i(α)∇θ vθ({Ati}τ,ot)−u({Ati}τ∣Ati) 2,代表训练过程的稳定性。方差越小,梯度更新越平稳,避免训练崩溃。
- S ( α ) S(\alpha) S(α):RL 优势得分函数,计算式为 S ( α ) = ∑ i = 1 B w ^ i ( α ) R ∗ ( A t i , o t ) ∑ i = 1 B w ^ i ( α ) S(\alpha) = \frac{\sum_{i=1}^B \hat{w}_i(\alpha) R^*(A_t^i, o_t)}{\sum_{i=1}^B \hat{w}_i(\alpha)} S(α)=∑i=1Bw^i(α)∑i=1Bw^i(α)R∗(Ati,ot)(其中 w ^ i ( α ) = exp ( α R ∗ ( A t i , o t ) ) \hat{w}_i(\alpha) = \exp(\alpha R^*(A_t^i, o_t)) w^i(α)=exp(αR∗(Ati,ot))),代表 RL 信号的有效利用程度 。 S ( α ) S(\alpha) S(α)越大,模型对高 RL 优势样本的关注程度越高,越能利用 RL 信号提升性能。
- λ \lambda λ:超参数,用于调整 “梯度方差控制” 与 “RL 信号保留” 的相对比重,默认取值为 5.0 e − 4 5.0e-4 5.0e−4(参考文章附录表7),实验验证 λ \lambda λ对 ARFM 性能影响较小,因方法自身具备自适应平衡能力。
基于高斯假设的目标函数简化与求解
为使 J ( α ) J(\alpha) J(α)可求解,引入三个温和且合理的假设(基于 VLA 流模型后训练的特性):
- 假设 1:标准化后的 RL 优势信号 R ∗ ( A t , o t ) R^*(A_t, o_t) R∗(At,ot)服从高斯分布 N ( 0 , σ R 2 ) \mathcal{N}(0, \sigma_R^2) N(0,σR2)( σ R 2 \sigma_R^2 σR2为 R ∗ R^* R∗的方差)——因 R ∗ R^* R∗经过标准化处理,分布接近正态。
- 假设 2:条件流匹配(CFM)损失 L C F M i = ∥ v θ ( A t i , o t i ) − u ( { A t i } τ ∣ A t i ) ∥ 2 \mathcal{L}_{CFM}^i = \left\| v_\theta(A_t^i, o_t^i) - u(\{A_t^i\}^\tau|A_t^i) \right\|^2 LCFMi= vθ(Ati,oti)−u({Ati}τ∣Ati) 2服从高斯分布 N ( μ L , σ L 2 ) \mathcal{N}(\mu_L, \sigma_L^2) N(μL,σL2)( μ L \mu_L μL为损失均值, σ L 2 \sigma_L^2 σL2为损失方差)——后训练阶段 CFM 损失快速收敛到低方差状态,分布近似正态。
- 假设 3:当批次大小B足够大时,可用批次样本的期望、方差近似全局的 μ L \mu_L μL、 σ R 2 \sigma_R^2 σR2、 σ L 2 \sigma_L^2 σL2——工程上 B = 16 B=16 B=16(参考附录表 7)即可满足近似精度。
基于上述假设,通过理论推导得到两个关键推论,实现 J ( α ) J(\alpha) J(α)的简化与 α ∗ \alpha^* α∗(最优 α \alpha α)的求解:
- 推论 1( J ( α ) J(\alpha) J(α)简化):将 Var ( g ^ ( α ) ) \text{Var}(\hat{g}(\alpha)) Var(g^(α))与 S ( α ) S(\alpha) S(α)用高斯分布的参数表示, J ( α ) J(\alpha) J(α)简化为: J ( α ) = σ L 2 [ e 2 α 2 σ R 2 − e α 2 σ R 2 ] − λ α σ R 2 J(\alpha) = \sigma_L^2 \left[ e^{2\alpha^2 \sigma_R^2} - e^{\alpha^2 \sigma_R^2} \right] - \lambda \alpha \sigma_R^2 J(α)=σL2[e2α2σR2−eα2σR2]−λασR2 该式消除了原目标函数中的期望与求和项,仅含 α \alpha α与可通过批次样本计算的 σ R 2 \sigma_R^2 σR2、 σ L 2 \sigma_L^2 σL2,为数值求解奠定基础。
- 推论 2( α ∗ \alpha^* α∗求解方程):对 J ( α ) J(\alpha) J(α)求导并令导数为 0(最小化 J ( α ) J(\alpha) J(α)),推导得到关于 α ∗ \alpha^* α∗的非线性方程,通过变量替换 x = α 2 σ R 2 x = \alpha^2 \sigma_R^2 x=α2σR2,转化为: 4 x ∗ e 2 x ∗ − 2 x ∗ e x ∗ − λ σ R σ L 2 = 0 , α ∗ = x ∗ σ R 4\sqrt{x^*} e^{2x^*} - 2\sqrt{x^*} e^{x^*} - \frac{\lambda \sigma_R}{\sigma_L^2} = 0, \quad \alpha^* = \frac{\sqrt{x^*}}{\sigma_R} 4x∗e2x∗−2x∗ex∗−σL2λσR=0,α∗=σRx∗ 其中 x ∗ x^* x∗为替换后的变量, α ∗ \alpha^* α∗可由 x ∗ x^* x∗与 σ R \sigma_R σR计算得到。
二分迭代算法:高效求解 α ∗ \alpha^* α∗
针对推论 2 中的非线性方程,设计二分迭代算法(算法 1)实时求解 α ∗ \alpha^* α∗,确保每批次训练都能获得适配当前数据分布的最优 α \alpha α,算法核心步骤如下:

- 参数初始化:输入批次内的 RL 优势 R i ∗ R_i^* Ri∗、流匹配损失 L F M i \mathcal{L}_{FM}^i LFMi、批次大小B、超参数 λ \lambda λ、 α \alpha α的取值范围 [ α min , α max ] [\alpha_{\text{min}}, \alpha_{\text{max}}] [αmin,αmax](默认 [ 0.01 , 5 ] [0.01,5] [0.01,5])、迭代次数M(默认 20)与容差 ϵ \epsilon ϵ(默认 1.0 e − 5 1.0e-5 1.0e−5),计算 σ R 2 \sigma_R^2 σR2( R i ∗ R_i^* Ri∗的方差)、 μ L \mu_L μL( L F M i \mathcal{L}_{FM}^i LFMi的均值)、 σ L 2 \sigma_L^2 σL2( L F M i \mathcal{L}_{FM}^i LFMi的方差)。
- 函数定义:定义非线性方程对应的函数 F ( x ) = 4 x e 2 x − 2 x e x − λ σ R σ L 2 F(x) = 4\sqrt{x}e^{2x} - 2\sqrt{x}e^x - \lambda \sigma_R \sigma_L^2 F(x)=4xe2x−2xex−λσRσL2,求解 F ( x ) = 0 F(x)=0 F(x)=0的根 x ∗ x^* x∗。
- 二分迭代:
- 初始化搜索区间 [ x low , x high ] [x_{\text{low}}, x_{\text{high}}] [xlow,xhigh](由 α min \alpha_{\text{min}} αmin、 α max \alpha_{\text{max}} αmax与 σ A \sigma_A σA计算得到)。
- 迭代M次:每次取区间中点 x mid x_{\text{mid}} xmid,若 ∣ F ( x mid ) ∣ < ϵ |F(x_{\text{mid}})| < \epsilon ∣F(xmid)∣<ϵ(满足精度要求)则终止;若 F ( x mid ) > 0 F(x_{\text{mid}}) > 0 F(xmid)>0则缩小上界 x high = x mid x_{\text{high}}=x_{\text{mid}} xhigh=xmid,否则缩小下界 x low = x mid x_{\text{low}}=x_{\text{mid}} xlow=xmid。
- α ∗ \alpha^{*} α∗计算与裁剪:由最终区间中点计算 x ∗ x^* x∗,代入 α ∗ = x ∗ σ R \alpha^* = \frac{\sqrt{x^*}}{\sigma_R} α∗=σRx∗,并将 α ∗ \alpha^* α∗裁剪到 [ α min , α max ] [\alpha_{\text{min}}, \alpha_{\text{max}}] [αmin,αmax],避免取值极端。
ARFM 完整微调算法:串联各模块的工程实现
为将上述理论模块落地,设计 ARFM 后训练算法(算法 2),实现 VLA 流模型的端到端离线 RL 微调,具体流程如下:

- 数据输入:输入后训练数据集 { A t , o t } \{A_t, o_t\} {At,ot}(含动作块与多模态观测)、批次大小B、预训练的 VLA 流模型 v θ v_\theta vθ(如 π 0 \pi_0 π0)。
- 批次循环:对每一批次数据 { A t i , o t i } \{A_t^i, o_t^i\} {Ati,oti}( i = 1 i=1 i=1到B)执行以下操作:
- 噪声与时间步采样:为每个样本采样高斯噪声 ϵ i ∼ N ( 0 , I ) \epsilon_i \sim \mathcal{N}(0,I) ϵi∼N(0,I)与随机时间步 τ ∼ Uniform ( 0 , 1 ) \tau \sim \text{Uniform}(0,1) τ∼Uniform(0,1)。
- 带噪声动作生成:计算 { A t i } τ = τ A t i + ( 1 − τ ) ϵ i \{A_t^i\}^\tau = \tau A_t^i + (1-\tau) \epsilon_i {Ati}τ=τAti+(1−τ)ϵi。
- RL 优势与能量计算:计算每个样本的 RL 优势 R i = R ∗ ( A t i , o t i ) R_i = R^*(A_t^i, o_t^i) Ri=R∗(Ati,oti),并预处理得到 g i = exp ( R i ) g_i = \exp(R_i) gi=exp(Ri)。
- 流匹配损失计算:计算基础流匹配损失 L F M i = ∥ v θ ( { A t i } τ , o t ) − ( ϵ − A t i ) ∥ 2 \mathcal{L}_{FM}^i = \left\| v_\theta(\{A_t^i\}^\tau, o_t) - (\epsilon - A_t^i) \right\|^2 LFMi= vθ({Ati}τ,ot)−(ϵ−Ati) 2。
- 最优 α ∗ \alpha^{*} α∗求解:调用算法 1,输入当前批次的 R i R_i Ri、 L F M i \mathcal{L}_{FM}^i LFMi等参数,得到最优缩放因子 α ∗ \alpha^* α∗。
- 加权损失计算:计算每个样本的权重 w i ( α ∗ ) = exp ( α ∗ g i ) ∑ j exp ( α ∗ g j ) w_i(\alpha^*) = \frac{\exp(\alpha^* g_i)}{\sum_j \exp(\alpha^* g_j)} wi(α∗)=∑jexp(α∗gj)exp(α∗gi),并求和得到批次加权损失 L 1 τ ( θ ) = ∑ i w i ( α ∗ ) L F M i \mathcal{L}_1^\tau(\theta) = \sum_i w_i(\alpha^*) \mathcal{L}_{FM}^i L1τ(θ)=∑iwi(α∗)LFMi。
- 模型更新:对 L 1 τ ( θ ) \mathcal{L}_1^\tau(\theta) L1τ(θ)求梯度,采用 AdamW 优化器(学习率等参数见附录表 7)执行梯度下降,更新 VLA 流模型的参数 θ \theta θ。
- 迭代终止:重复批次循环,直至完成预设的后训练步数(LIBERO 仿真中为 40000 步,UR5 真实实验中为 60000 步)。
该算法通过 “批次内自适应调整 α \alpha α”,确保模型在不同数据分布下均能平衡 RL 信号与训练稳定性,且与现有 VLA 流模型(如 π 0 \pi_0 π0)兼容,无需修改模型骨干结构,工程落地成本低。
实验基础设置
实验环境与任务设计
- 仿真环境:采用 LIBERO 基准测试平台,该平台为综合型终身学习机器人基准,通过语言引导指令定义任务,涵盖 4 个核心套件(各含 10 个独立任务),分别针对不同操控能力评估:
- Object 套件:聚焦物体属性相关操控(如抓取特定形状 / 颜色物体);
- Long 套件:侧重长序列动作操控(如多步物体传递);
- Spatial 套件:考察空间位置相关任务(如按指定坐标放置物体);
- Goal 套件:以目标导向任务为主(如将物体堆叠至指定高度)。
- 真实世界环境:使用 UR5 机械臂搭建实验平台,设计 3 类抓取 - 放置任务(操控立方体、玉米、辣椒等物体),并对目标物体引入外部物理扰动(如轻微碰撞、位置偏移),模拟真实场景中的不确定性。
- 数据与奖励配置:真实世界实验收集约 720 条成功轨迹(含 34600 余帧数据),涵盖第一 / 第三人称 RGB 图像(480×640×3 维度)、机器人关节角度(7 维度)及期望关节角度(7 维度);奖励函数采用 13 项密集奖励组件(含子目标达成、任务进度、行为平滑度、任务完成等,具体权重见附录表 8),参考 ReinboT(Zhang 等人,2025)的奖励设计原则,兼顾任务目标与动作稳定性。

基准方法选择与设置
为全面验证 ARFM 性能,将基准方法分为非流匹配型与流匹配型两类,且为保证公平性,基于 π 0 \pi_0 π0模型复现流匹配型基准的适配版本:
- 非流匹配型基准:
- 自回归模型:Octo、OpenVLA,均为通用 VLA 模型;
- 扩散类模型:Diffusion Policy、MDT、Dita,通过扩散过程建模动作生成;
- 离散技能模型:QueST,用 VQ-VAE 将连续动作离散为技能码本后自回归预测。
- 流匹配型基准:
- 基础流模型: π 0 \pi_0 π0,基于轨迹级流匹配的 VLA 模型,为 ARFM 的基础对比模型;
- 离线 RL 微调方法:ReinboT(引入 RL 未来回报指导微调)、RWR(通过奖励加权回归优化模型),二者均基于 π 0 \pi_0 π0复现流模型版本。
关键实验参数
- 训练配置:LIBERO 仿真中执行 40000 步全参数微调,UR5 真实实验中执行 60000 步微调,均使用 2 块 NVIDIA A100-SXM4-80GB GPU,CPU 为 Intel ® Xeon ® Platinum 8358(2.60GHz);
- 超参数:批次大小为 16,动作时域长度 H = 50 H=50 H=50,优化器采用 AdamW(学习率 1.0 e − 4 1.0e-4 1.0e−4,权重衰减 1.0 e − 10 1.0e-10 1.0e−10),学习率调度器为带预热的余弦衰减(预热步数 1000,衰减步数 30000),ARFM 专属超参数 λ = 5.0 e − 4 \lambda=5.0e-4 λ=5.0e−4、 α \alpha α取值范围 [ 0.01 , 5 ] [0.01,5] [0.01,5]、二分迭代次数 M = 20 M=20 M=20(具体见附录表 7);
- 评估指标:以成功率(SR) 为核心性能指标,抗扰动实验中添加 0.1-0.3 级高斯动作噪声,持续学习中采用负向后迁移(NBT) 衡量遗忘程度( N B T = 1 T − 1 ∑ i T − 1 m a x ( 0 , ( S R ) i − ( S R ) i T ) NBT=\frac{1}{T-1}\sum_{i}^{T-1}max(0,(SR)_i-(SR)_i^T) NBT=T−11∑iT−1max(0,(SR)i−(SR)iT), ( S R ) i (SR)_i (SR)i为单任务学习后成功率, ( S R ) i T (SR)_i^T (SR)iT为全任务学习后成功率,NBT 越小表示遗忘越少)。
核心实验结果与分析
多任务学习:验证泛化能力
实验目的:对比 ARFM 与基准方法在 LIBERO 四套件多任务场景下的整体性能,结果如下表所示:
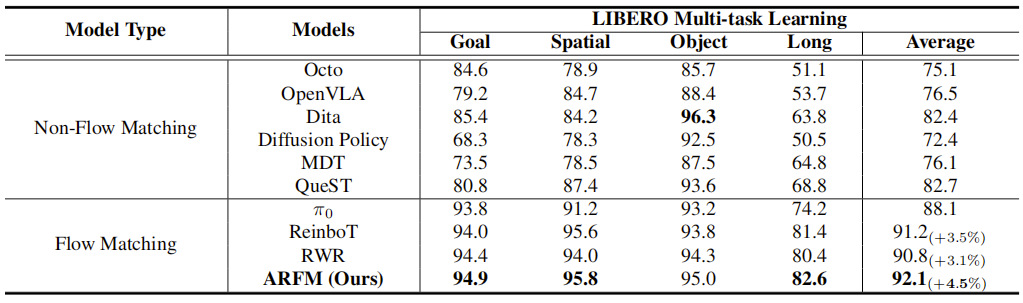
- 核心结论 1:流匹配型模型( π 0 \pi_0 π0、ReinboT、RWR、ARFM)整体成功率显著高于非流匹配型,其中流匹配型平均成功率最低为 π 0 \pi_0 π0的 88.1%,非流匹配型最高为 QueST 的 82.7%,证明流匹配模型的轨迹建模能力更适配 VLA 多任务操控;
- 核心结论 2:ARFM 在流匹配型中表现最优,多任务平均成功率达 92.1%,较基础模型 π 0 \pi_0 π0提升 4.5%,高于 ReinboT(91.2%,+3.5%)与 RWR(90.8%,+3.1%),验证 ARFM 的自适应能量加权机制能更高效利用 RL 信号,提升模型泛化性。
动作扰动实验:验证鲁棒性
实验目的:评估模型在动作噪声干扰下的稳定性,对模型推理阶段的动作添加 0.1-0.3 级高斯噪声,结果如下表所示:
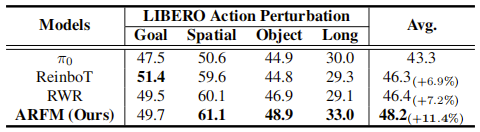
- 核心数据:ARFM 平均成功率为 48.2%,显著高于 π 0 \pi_0 π0(43.3%,+11.4%)、ReinboT(46.3%,+1.9%)与 RWR(46.4%,+1.8%);
- 关键分析:ARFM 通过动态调整 α \alpha α平衡 RL 信号与梯度方差,避免高噪声样本导致的梯度异常,使模型学习到更稳健的动作轨迹分布,因此在噪声干扰下仍能保持较高成功率。
少样本学习实验:验证数据利用效率
实验目的:在 LIBERO-Long 套件中设置 10-shot、20-shot、30-shot(每任务仅 10/20/30 条轨迹数据)场景,评估模型在数据稀缺时的学习能力,结果如下表所示:
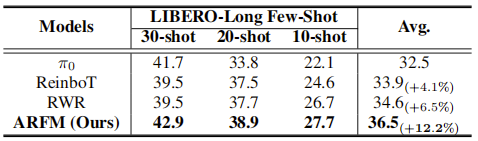
- 核心数据:ARFM 在三种少样本设置下平均成功率为 36.5%,较 π 0 \pi_0 π0(32.5%,+12.2%)、ReinboT(33.9%,+2.6%)、RWR(34.6%,+1.9%)均有提升;
- 关键分析:ARFM 的自适应 α \alpha α能优先聚焦高 RL 优势的稀缺样本,避免数据不足时的噪声干扰,提升数据利用效率,因此在少样本场景下表现更优。
持续学习实验:验证抗遗忘能力
实验目的:评估模型在 “Long→Long+Goal→Long+Goal+Object” 的序列任务学习中,对旧任务的遗忘程度与新任务的学习能力,结果下表 所示:

- 核心数据:ARFM 最终平均成功率 61.0%,较 π 0 \pi_0 π0(55.2%)提升 10.5%;NBT 为 4.7,较 π 0 \pi_0 π0(7.5)降低 38.0%,且显著低于 ReinboT(6.6)与 RWR(7.3);
- 关键分析:ARFM 通过控制梯度方差避免参数更新过度偏向新任务,同时保留旧任务的高 RL 优势信号,有效缓解 “灾难性遗忘”,更适配终身学习场景。
消融实验:验证关键组件有效性
实验目的:分析 ARFM 中核心超参数 λ \lambda λ(RL 信号与梯度方差权衡系数)与M(二分迭代次数)对性能的影响,结果如图所示:
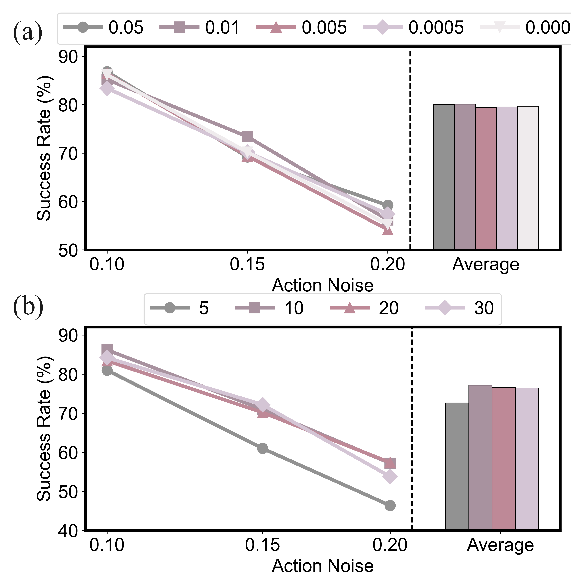
- 超参数 λ \lambda λ:不同 λ \lambda λ下模型成功率波动小于 2%,证明 ARFM 的自适应机制降低了对 λ \lambda λ的敏感性,无需精细调参;
- 迭代次数M:当 M ≥ 10 M≥10 M≥10时,模型成功率趋于稳定(波动小于 1%),说明仅需 10 次迭代即可获得近似最优 α \alpha α,算法轻量化且高效。
真实世界实验:验证场景适配性
实验目的:在 UR5 机械臂抓取 - 放置任务(含外部扰动)中评估模型实际性能,结果如图所示:
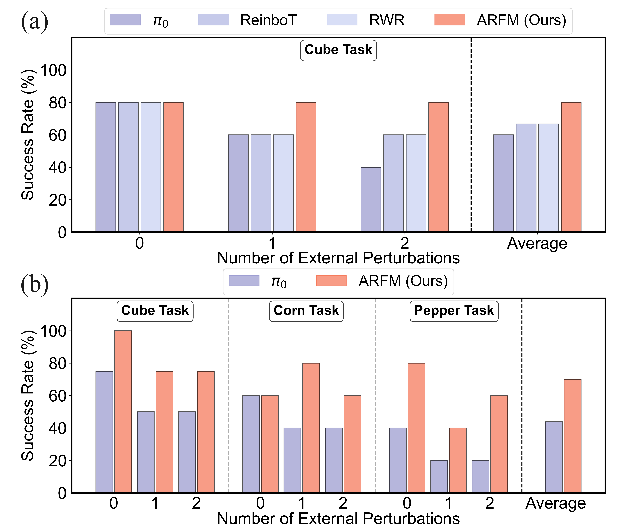
- 核心结论:ARFM 在三类物体操控任务中的平均成功率显著高于 π 0 \pi_0 π0,且抗扰动能力最优——当目标物体受轻微碰撞时,ARFM 成功率较 π 0 \pi_0 π0提升 15%-20%,证明其能将仿真中的性能迁移到真实复杂场景,适配实际机器人操控需求。
总结
ARFM 的核心是在 VLA 流模型损失函数中引入自适应缩放因子,构建偏差 - 方差权衡目标函数,动态平衡 “保留 RL 优势信号” 与 “控制流损失梯度方差”,既放大高RL优势样本权重以捕捉数据质量特性,又避免梯度爆炸保障训练稳定;同时通过合理假设推导缩放因子的优化目标与求解方程,设计二分迭代算法实时更新最优缩放因子,并配套完整微调算法,形成理论到落地的完整链路。
在 LIBERO 仿真基准与 UR5 真实机械臂平台实验中,ARFM 表现优异:多任务学习泛化能力、动作扰动场景鲁棒性、少样本学习数据利用效率、持续学习抗遗忘能力均优于 π 0 \pi_0 π0、ReinboT 等基准;且超参数敏感性低、求解高效,在真实带扰动抓取 - 放置任务中适配性好,验证了其实用价值。
未来可探索 ARFM 在 VLA 流模型在线 RL 后训练中的应用,通过环境交互进一步提升模型对新场景的适配能力。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)