深度学习之卷积神经网络、循环神经网络
一.1.图像基础知识
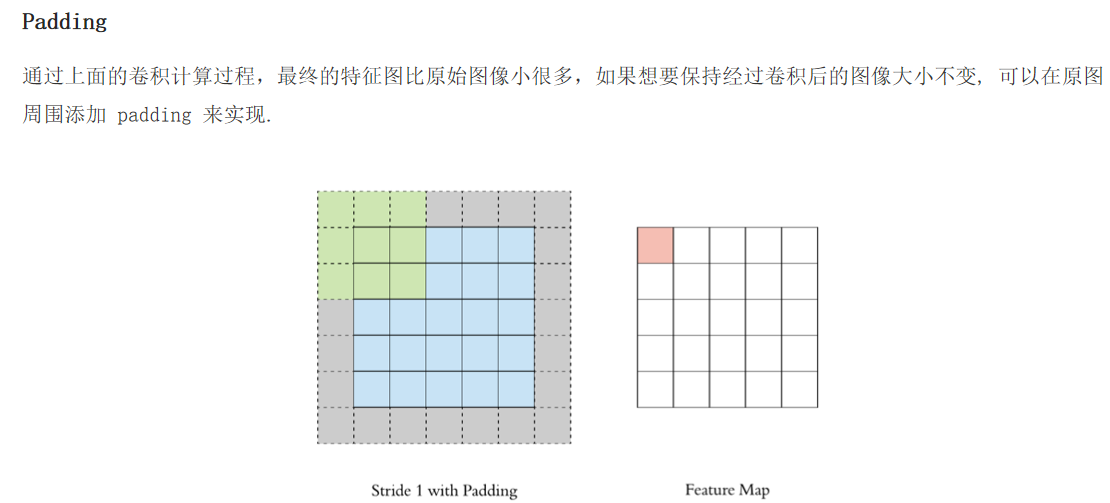
图像基本概念:图像是由像素点组成的,每个像素点的取值范围为: [0, 255] 。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。 在深度学习中,我们使用的图像大多是彩色图,彩色图由RGB3个通道组成,如下图所示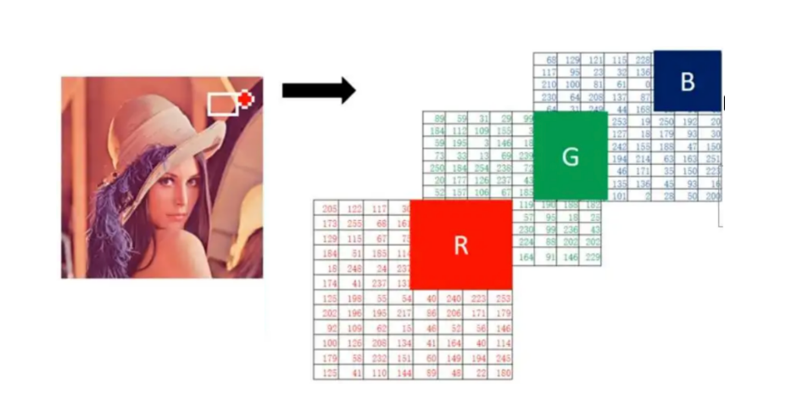
1、图像的构成 由像素点构成,【0-255】,RGB,【HWC】
2、图像的加载方法 Plt.imread() Plt.imshow()
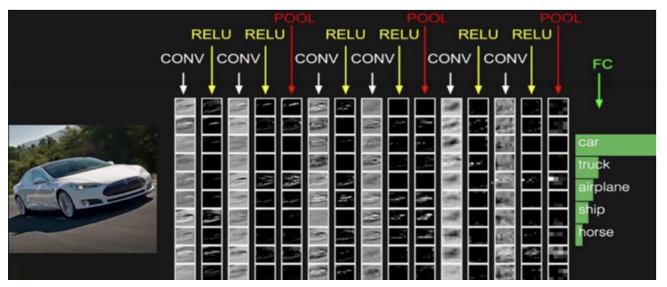
1.2CNN概述:卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征.
CNN网络主要由三部分构成:卷积层、池化层和全连接层
构成: 卷积层负责提取图像中的局部特征; 池化层用来大幅降低参数量级(降维); 全连接层用来输出想要的结果。
1.什么是卷积神经网络? 包含卷积层的神经网络
2.卷积神经网络的构成 卷积层:特征提取 池化层:降维 全连接层:输出结果
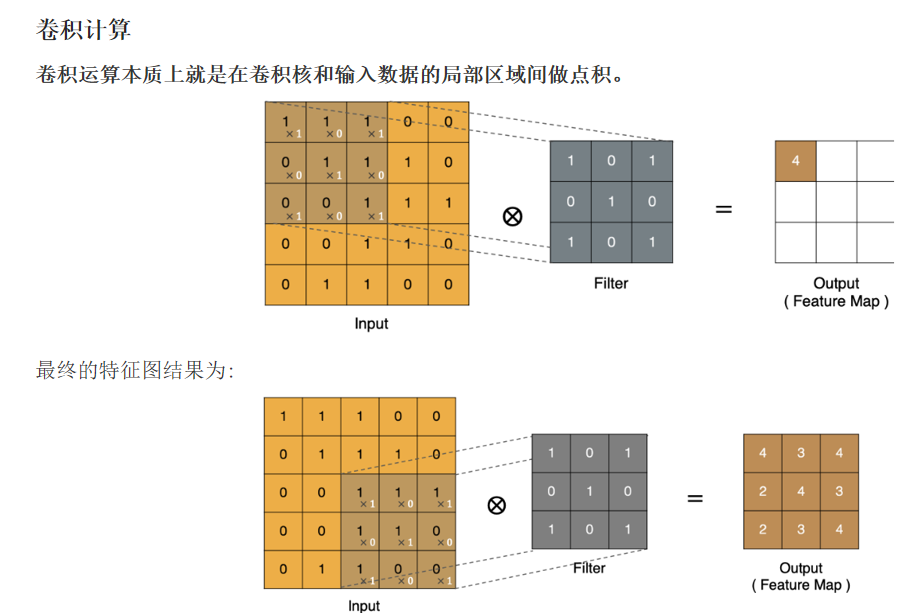
卷积层: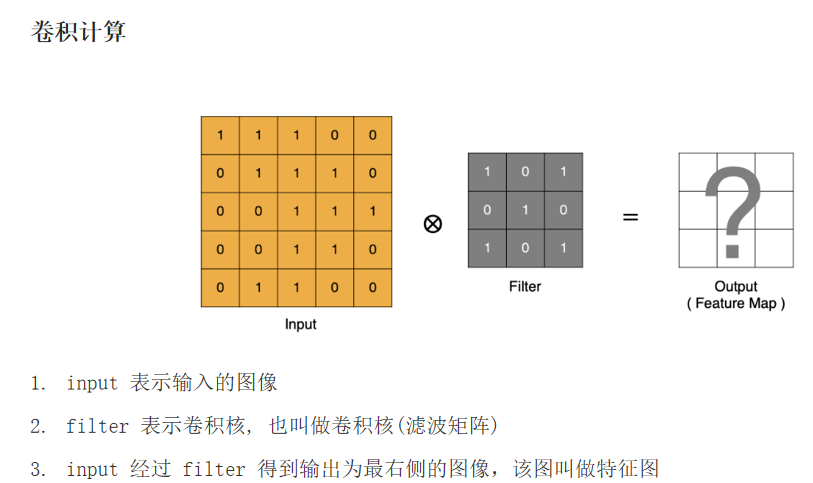
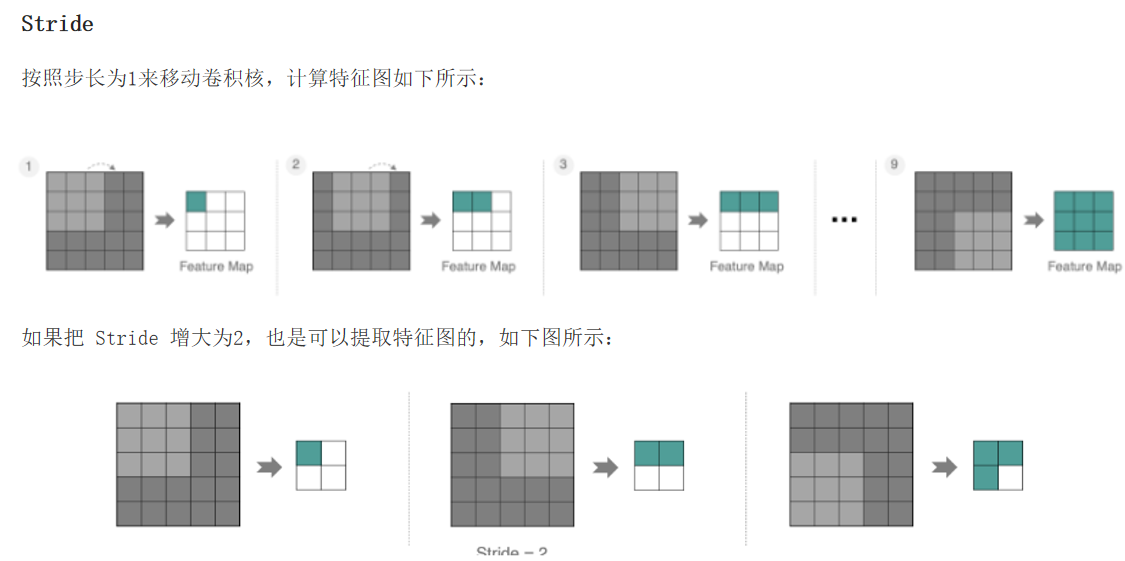
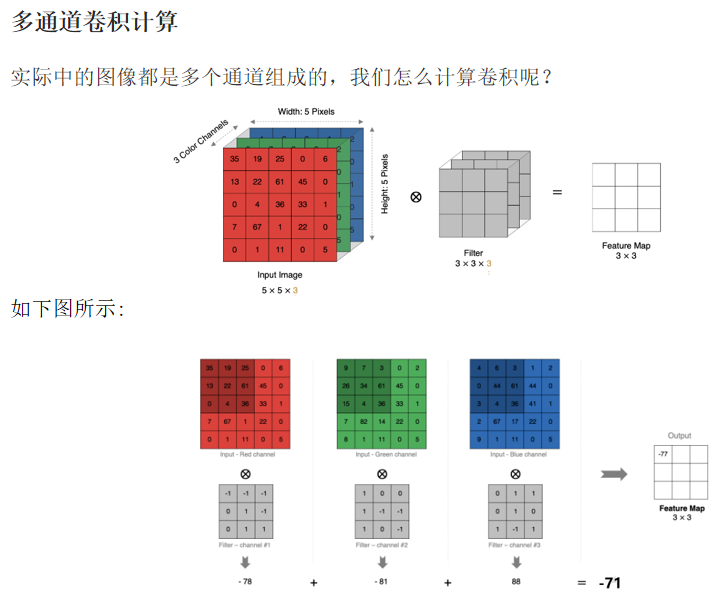
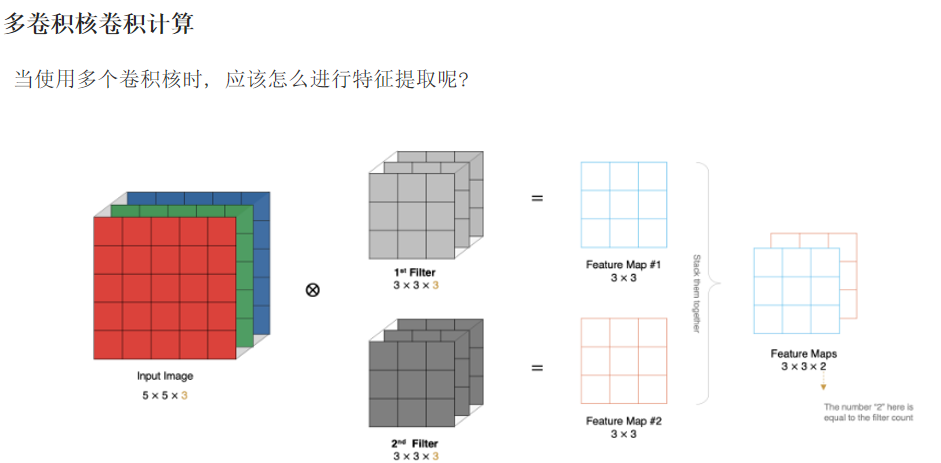
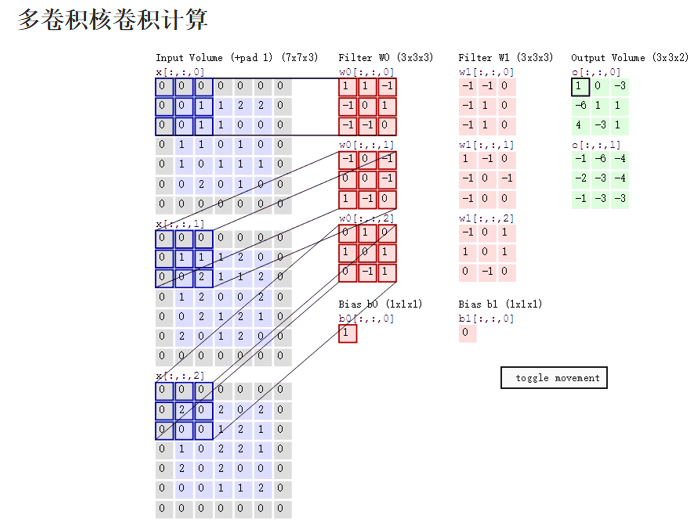


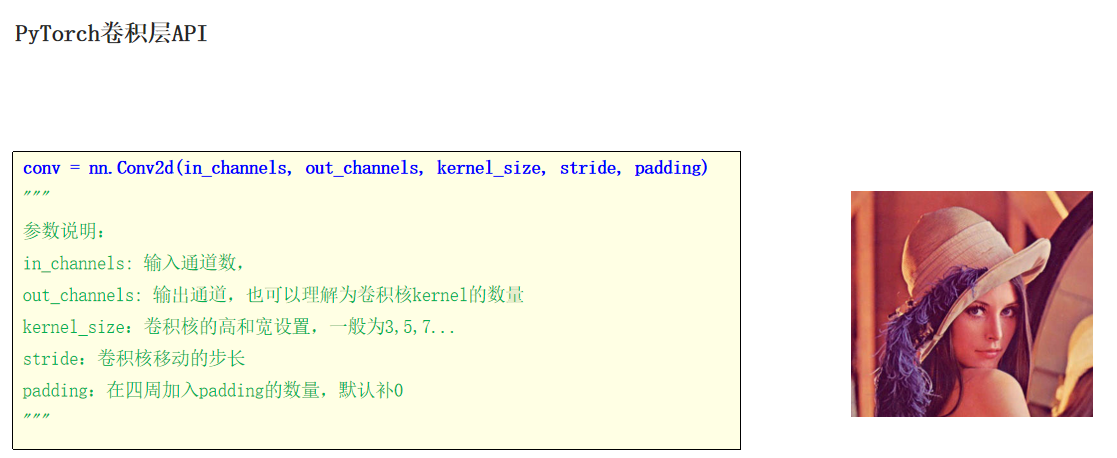
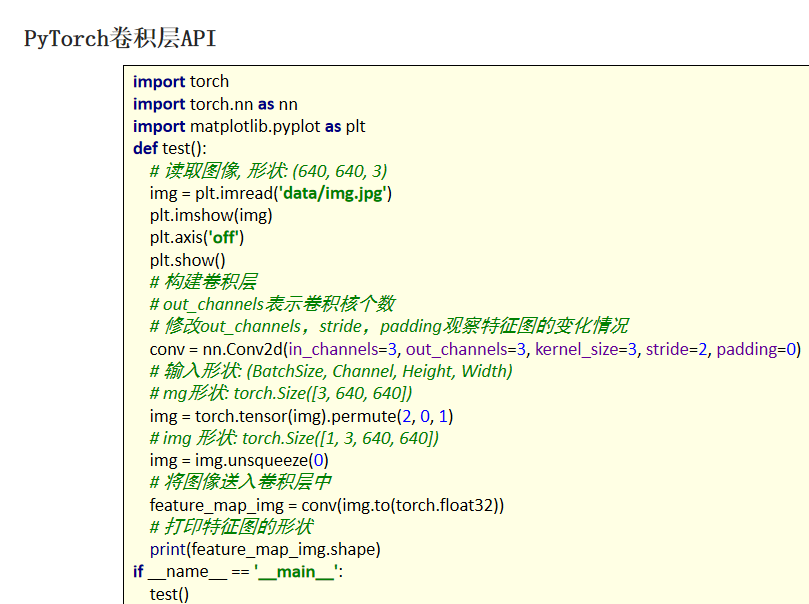
池化层:
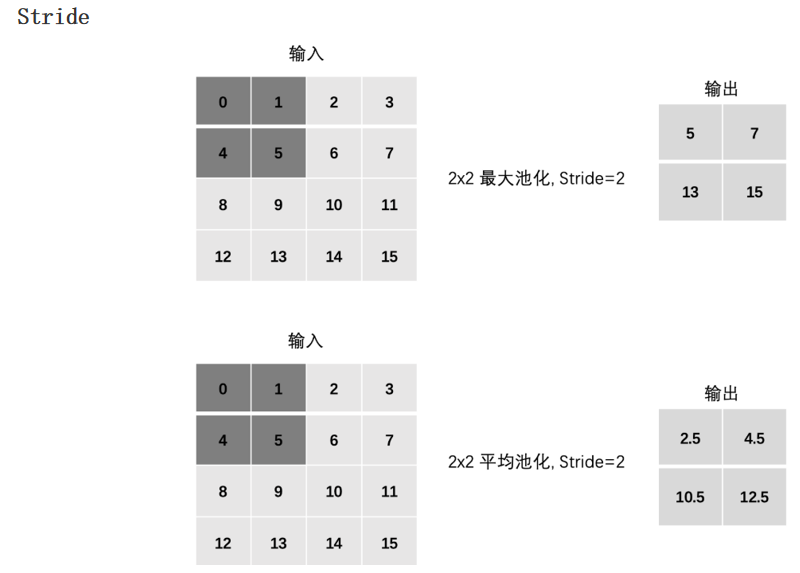
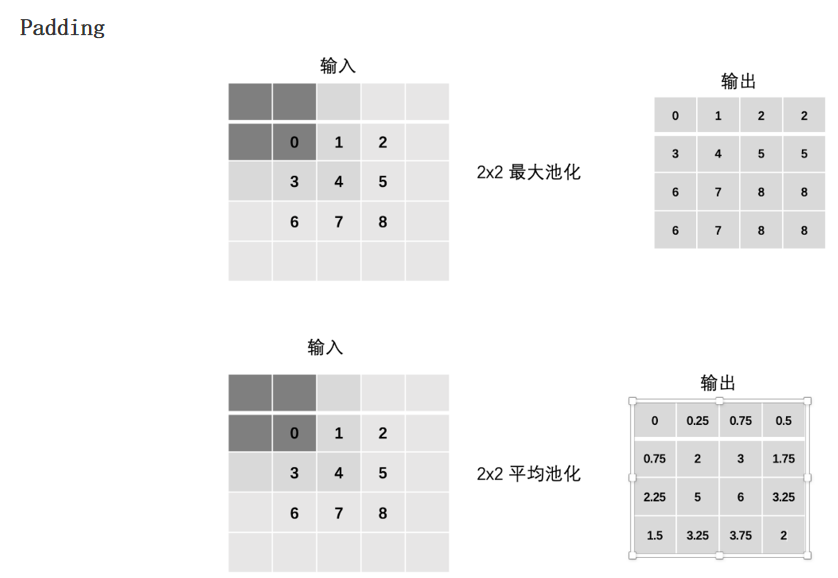
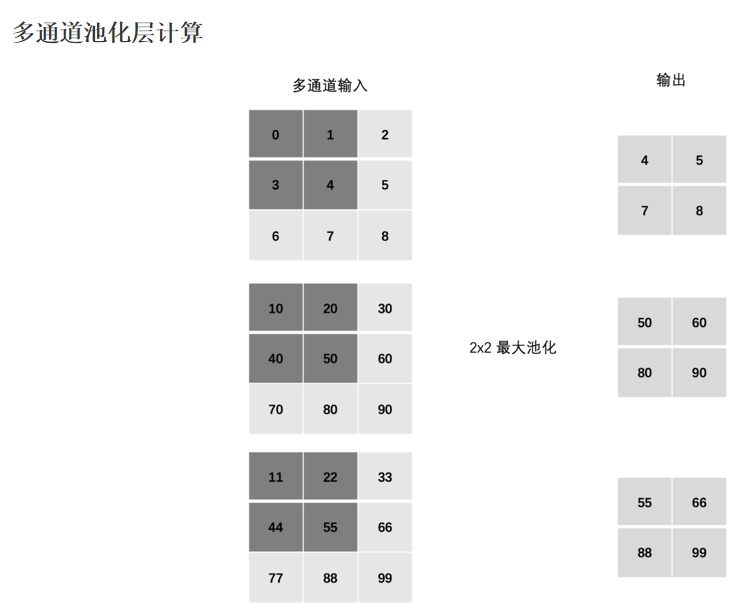

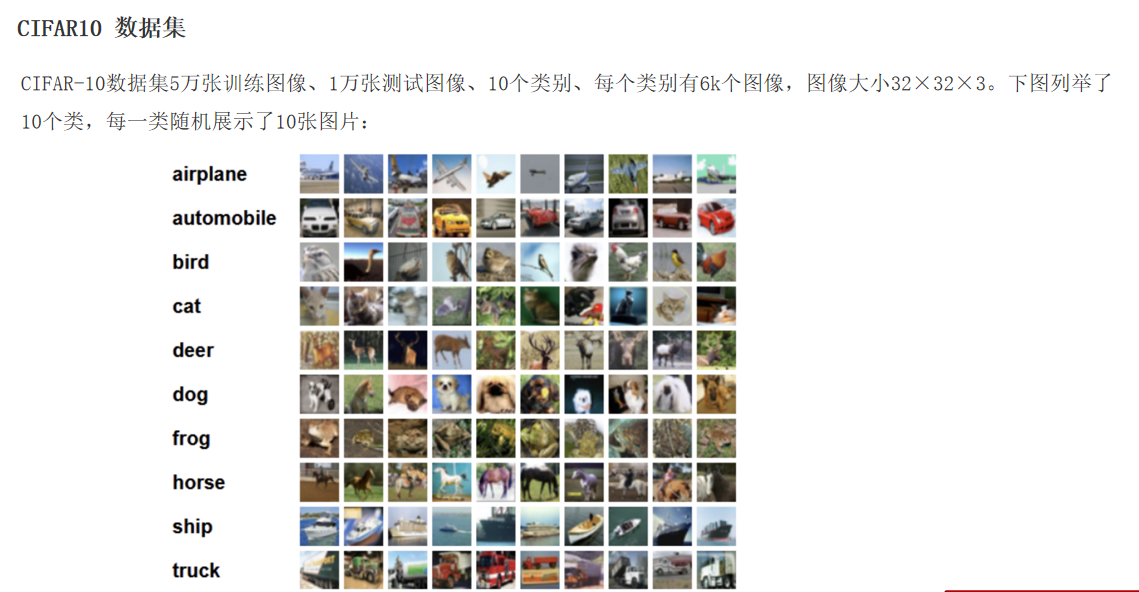
图像分类案例:
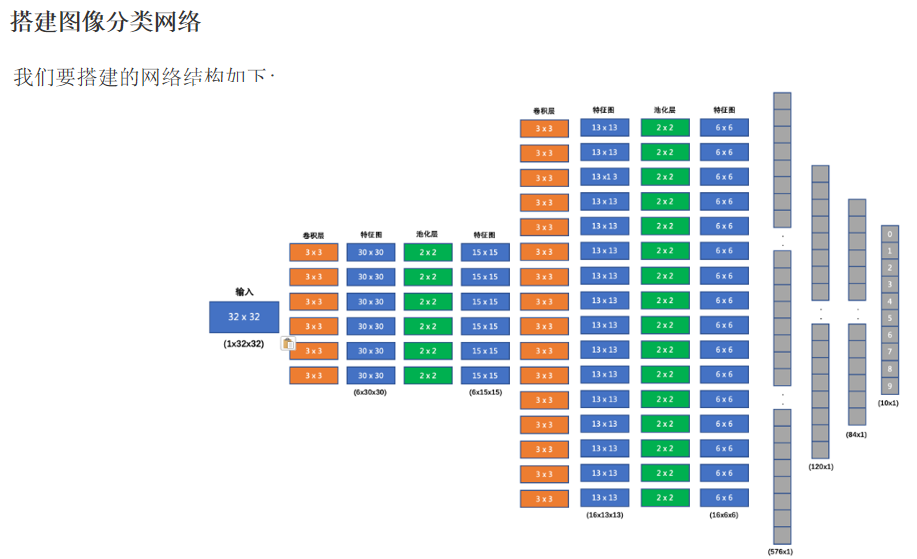 搭建图像分类网络:
搭建图像分类网络:
我们要搭建的网络结构如下: 输入形状: 32x32 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2 第一个全连接层输入 576 维, 输出 120 维 第二个全连接层输入 120 维, 输出 84 维 最后的输出层输入 84 维, 输出 10 维 我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
代码:
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.transforms import Compose
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
BATCH_SIZE = 8
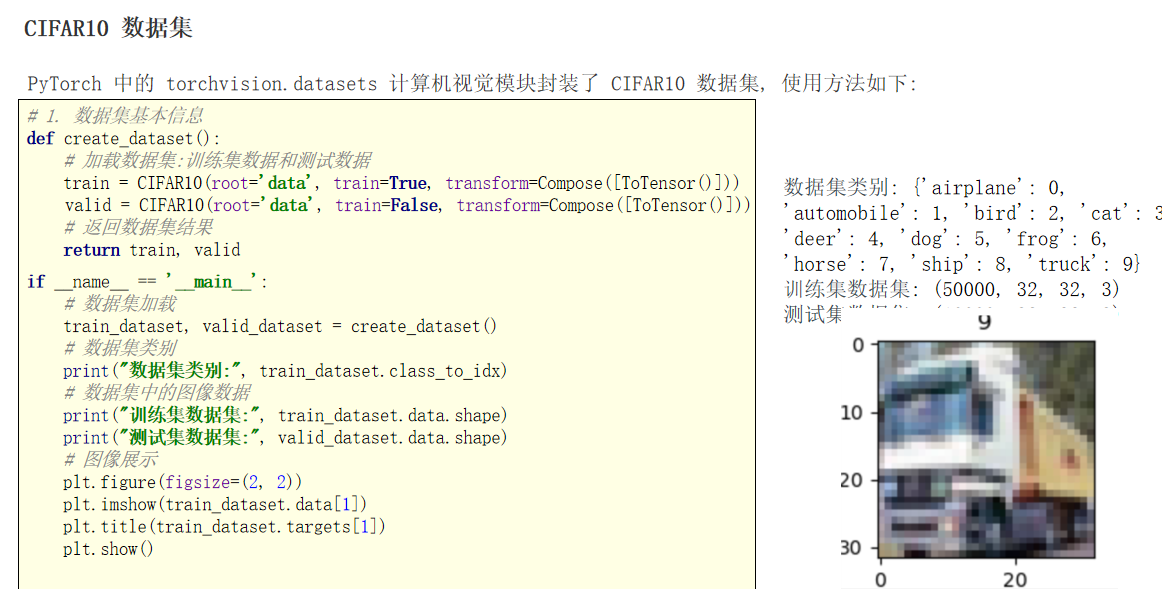
# 1.数据集
def create_dataset():
train_dataset =CIFAR10(root='data',train=True,transform=Compose([ToTensor()]))
valid_dataset =CIFAR10(root='data',train=False,transform=Compose([ToTensor()]))
return train_dataset,valid_dataset
# 2.模型构建
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
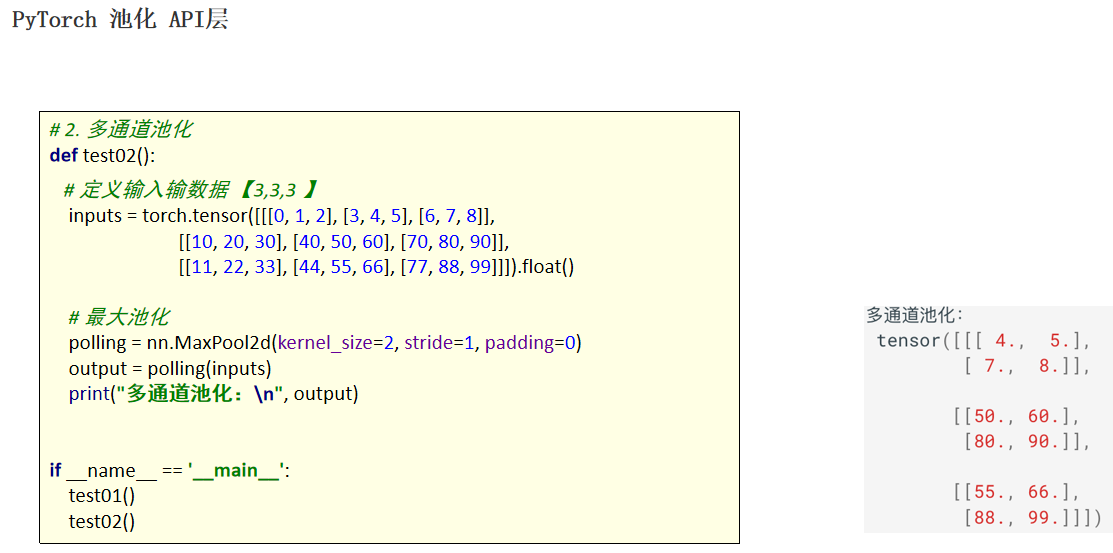
self.layer1 =nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3)
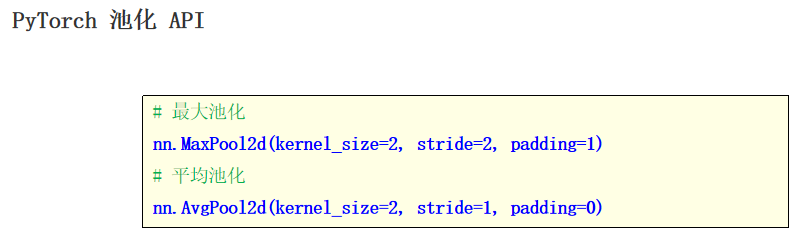
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.layer2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.layer3 = nn.Linear(in_features=576,out_features=120)
self.layer4 = nn.Linear(in_features=120,out_features=84)
self.layer5 = nn.Linear(in_features=84,out_features=10)
def forward(self,x):
x1 =torch.relu(self.layer1(x))
x1 =self.pool1(x1)
x2 = torch.relu(self.layer2(x1))
x2 = self.pool2(x2)
x2 =x2.reshape(x2.size(0),-1)
x3 = torch.relu(self.layer3(x2))
x4 = torch.relu(self.layer4(x3))
out = self.layer5(x4)
return out
# 3.模型训练
def train():
train_dataset, valid_dataset = create_dataset()
model = Model()
loss = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(),lr = 0.001,betas=[0.9,0.99])
for epoch in range(2):
dataloader =DataLoader(dataset=train_dataset,batch_size=4,shuffle=True)
for x,y in dataloader:
y_pred =model(x)
loss_val= loss(y_pred,y)
print(loss_val.item())
opt.zero_grad()
loss_val.backward()
opt.step()
break
torch.save(model.state_dict(),'03-CNN/data/img_cls.pth')
# 4.预测评估
def test():
train_dataset, valid_dataset = create_dataset()
model = Model()
weight =torch.load('03-CNN/data/img_cls.pth')
model.load_state_dict(weight)
# model.eval()
# model.train()
dataloader =DataLoader(valid_dataset,batch_size=8,shuffle=False)
total_correct_num = 0
total_num = 0
for x,y in dataloader:
out =model(x)
y_pred =torch.argmax(out,dim=-1)
correct_num =(y_pred == y).sum()
total_correct_num+=correct_num
total_num+=len(y)
print(total_correct_num/(total_num+0.01))
if __name__ == '__main__':
# train_dataset,valid_dataset = create_dataset()
# print(train_dataset.data.shape)
# print(valid_dataset.data.shape)
# plt.imshow(train_dataset.data[2])
# plt.show()
# model =Model()
# summary(model,input_size=(3,32,32),batch_size=1)
# train()
test()二。循环神经网络:
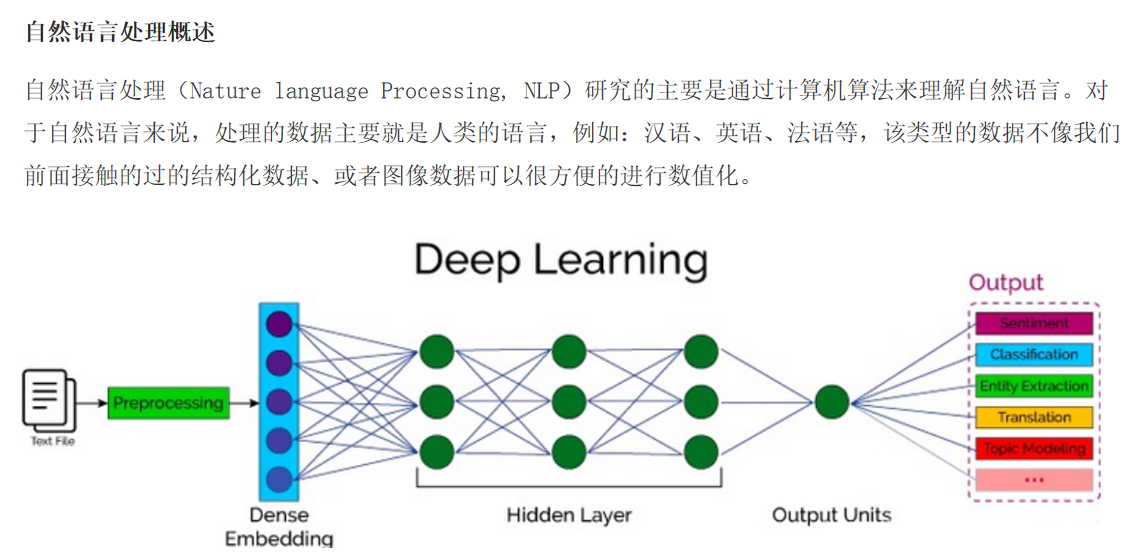
1.自然语言处理概述:
2.词嵌入层:词嵌入层的作用就是将文本转换为向量。 词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
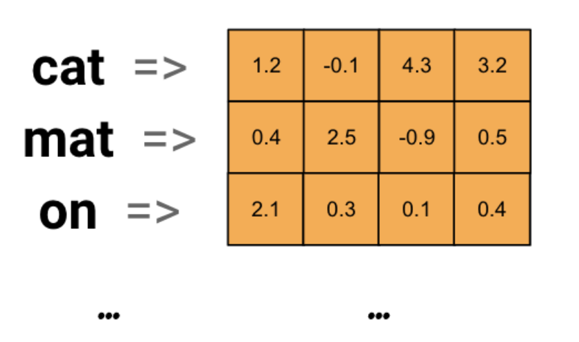

接下来,我们将会学习如何将词转换为词向量,其步骤如下: 先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引 然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。 例如,我们的文本数据为: "北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。",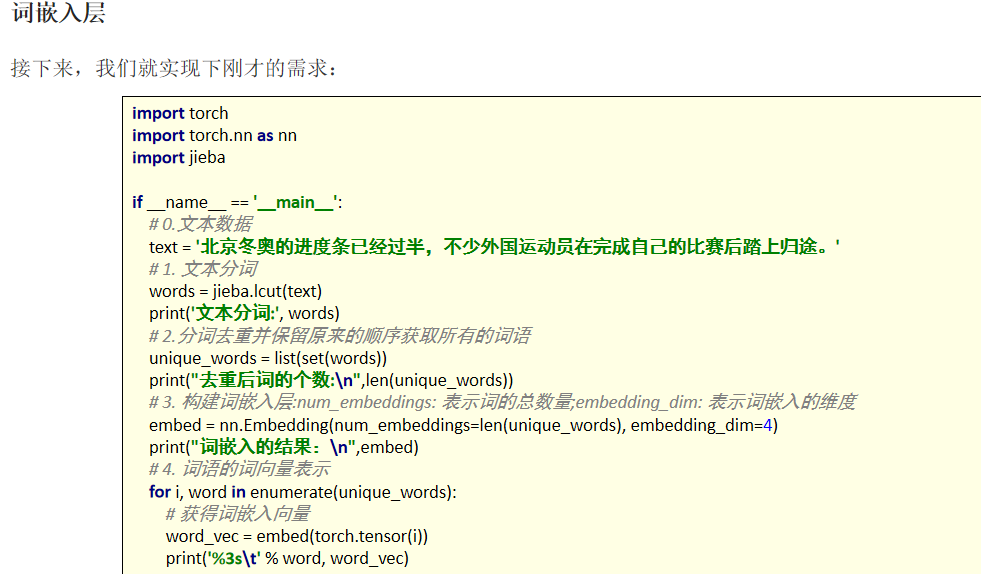

import torch
import torch.nn as nn
import jieba
# 语料
text = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# 分词+去重
words=jieba.lcut(text)
words_u = list(set(words))
print(len(words_u))
print(words_u)
# emb
embs=nn.Embedding(18,3)
print(embs)
# 获取词向量
print(embs(torch.tensor(0)))
循环网络层:
1.RNN网络原理:
文本数据是具有序列特性的 例如: "我爱你", 这串文本就是具有序列关系的,"爱" 需要在 "我" 之后,"你" 需要在 "爱" 之后, 如果颠倒了顺序,那么可能就会表达不同的意思。 为了表示出数据的序列关系,需要使用循环神经网络(Recurrent Nearal Networks, RNN) 来对数据进行建模,RNN 是一个作用于处理带有序列特点的样本数据。
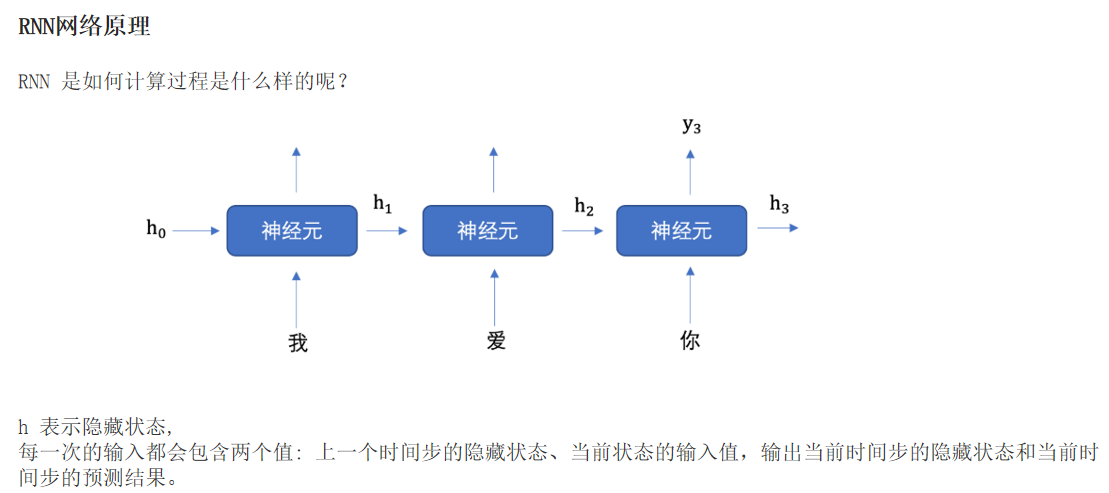
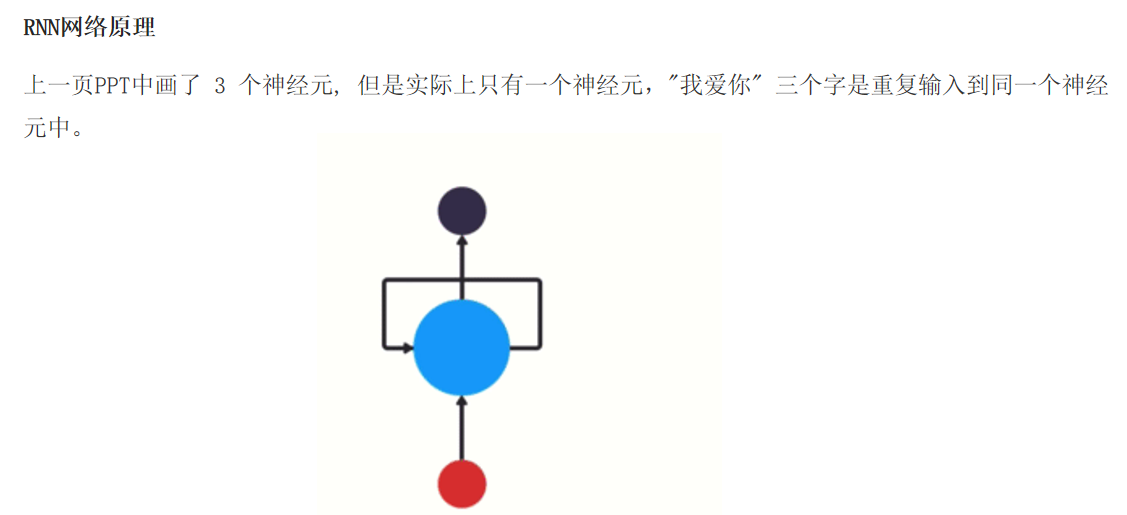
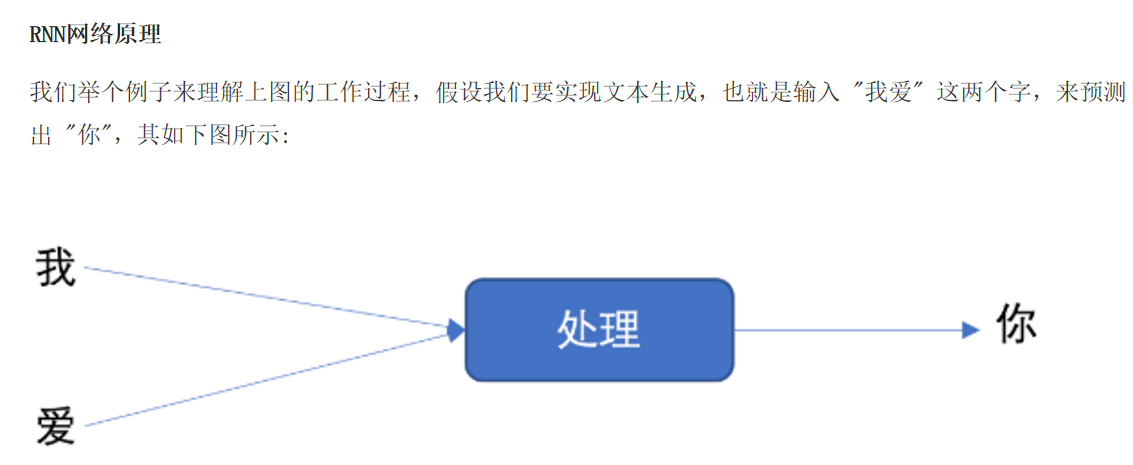
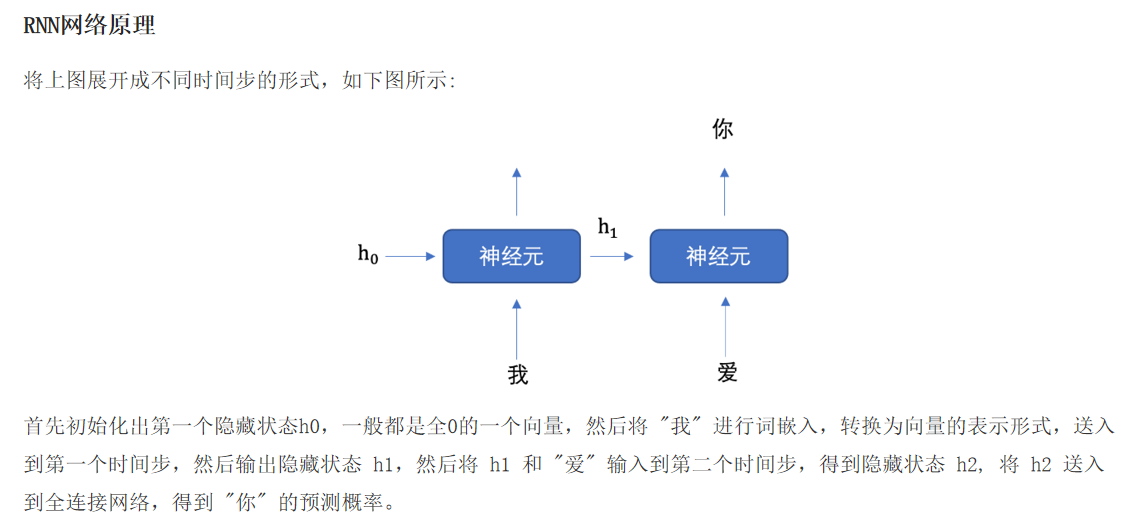
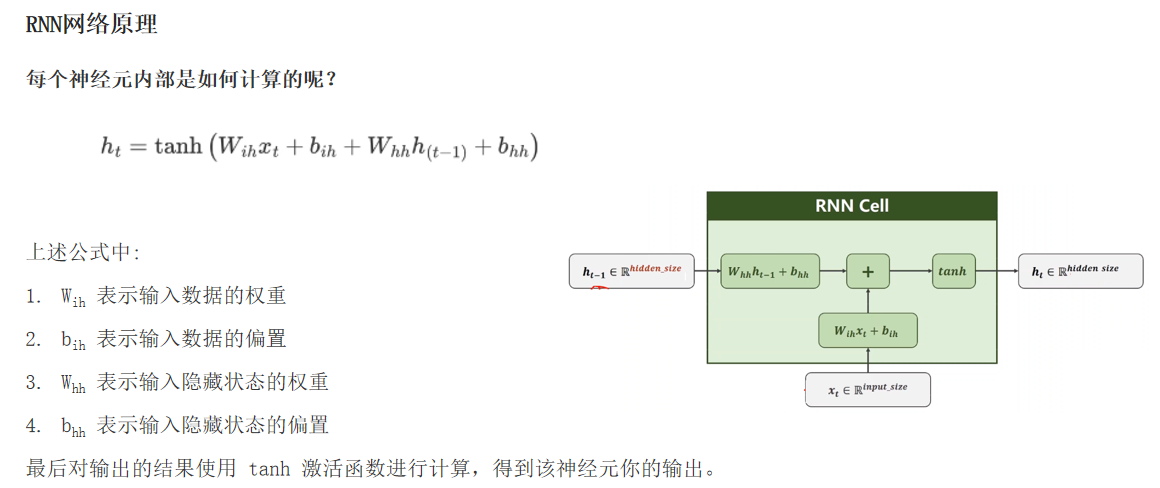



import torch
import torch.nn as nn
rnn =nn.RNN(input_size=128,hidden_size=64)
inputs = torch.randn(10,32,128)
hidden0 = torch.zeros(1,32,64)
y,h=rnn(inputs,hidden0)
print(y)
print(h)文本生成案例:


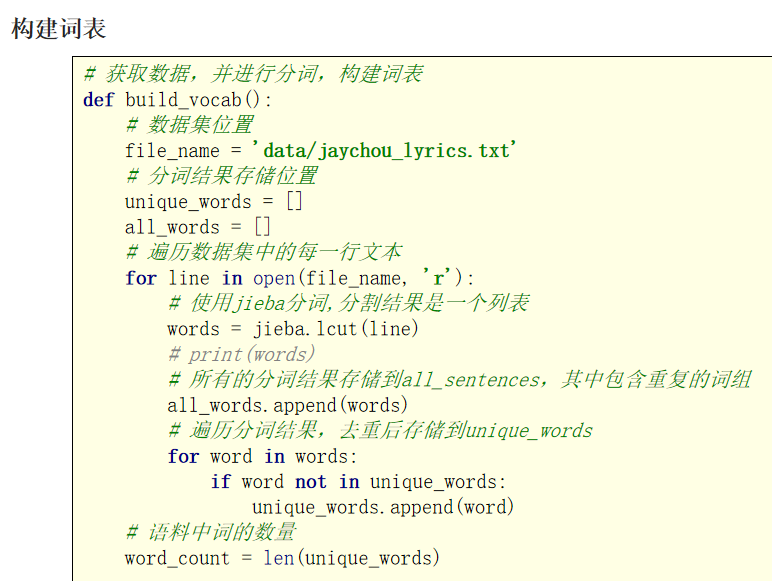
接下来, 我们对周杰伦歌词的数据进行处理构建词表,具体实现如下所示: 整体流程是: 获取文本数据 分词,并进行去重 构建词表。
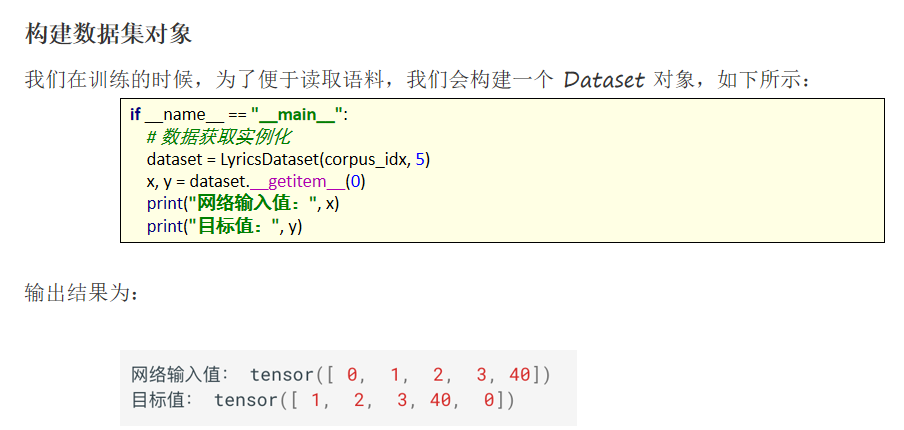
我们用于实现《歌词生成》的网络模型,主要包含了三个层: 词嵌入层: 用于将语料转换为词向量 循环网络层: 提取句子语义 全连接层: 输出对词典中每个词的预测概率。
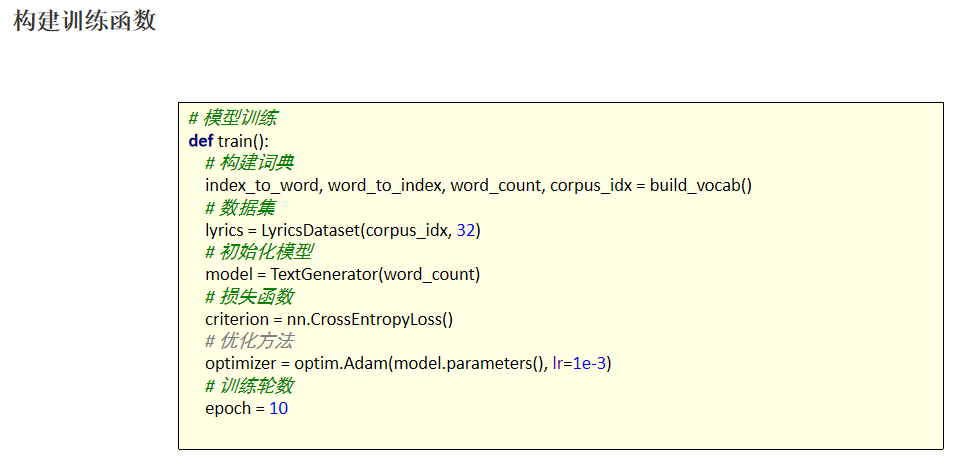
前面的准备工作完成之后, 我们就可以编写训练函数。训练函数主要负责编写数据迭代、送入网络、计算损失、反向传播、更新参数,其流程基本较为固定。 由于我们要实现文本生成,文本生成本质上,输入一串文本,预测下一个文本,也属于分类问题,所以,我们使用多分类交叉熵损失函数。优化方法我们学习过 SGB、AdaGrad、Adam 等,在这里我们选择学习率、梯度自适应的 Adam 算法作为我们的优化方法。 训练完成之后,我们使用 torch.save 方法将模型持久化存储。

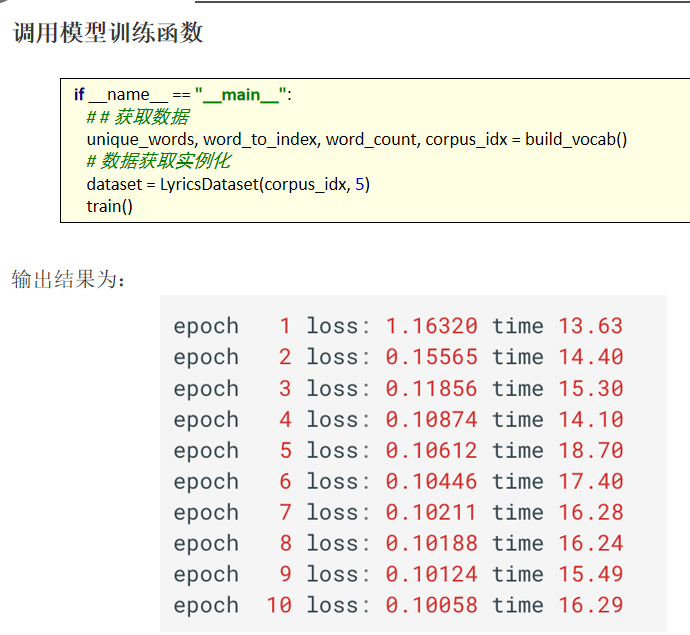
构建预测函数:
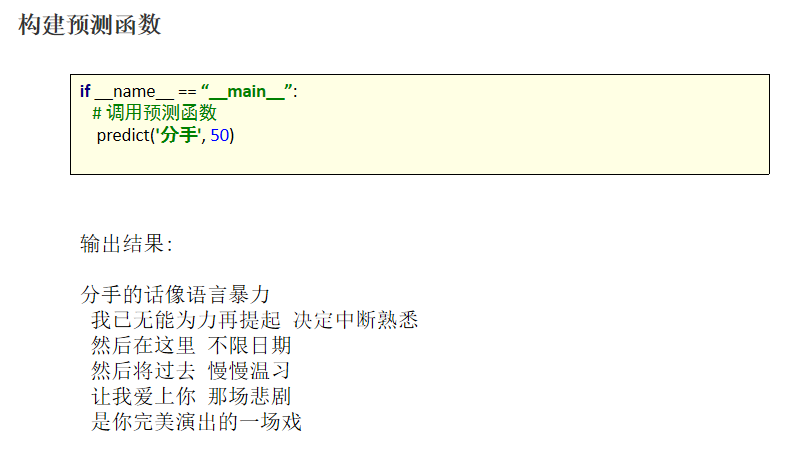
从磁盘加载训练好的模型,进行预测。预测函数,输入第一个指定的词,我们将该词输入网路,预测出下一个词,再将预测的出的词再次送入网络,预测出下一个词,以此类推,知道预测出我们指定长度的内容。 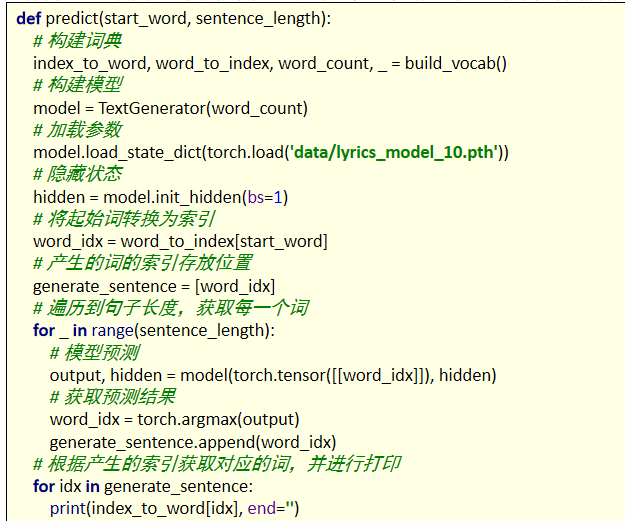
总结:
构建了一个《歌词生成》的项目,该项目的实现流程如下: 构建词汇表 构建数据对象 编写网络模型 编写训练函数 编写预测函数 。
import torch
import re
import jieba
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import time
# 1.加载数据
# 1.1 分词+去重
# 1.2 词表
def build_vocab():
file_name = '/04-RNN/data/jaychou_lyrics.txt'
all_words = []
u_words= []
for line in open(file_name,'r'):
words = jieba.lcut(line)
all_words.append(words)
for word in words:
if word not in u_words:
u_words.append(word)
# print(len(all_words))
# print(len(u_words))
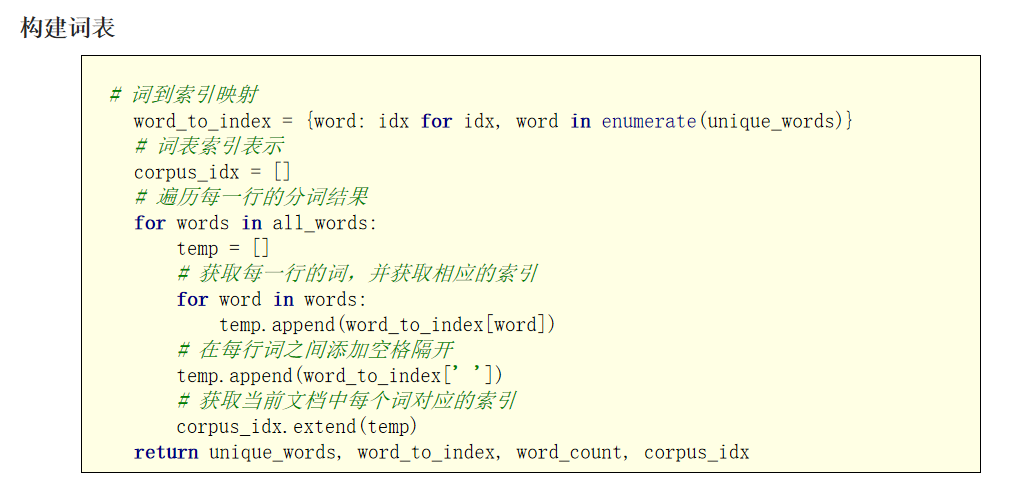
word_to_idx={word:idx for idx,word in enumerate(u_words)}
corpus_idx = []
for words in all_words:
temp =[]
for word in words:
temp.append(word_to_idx[word])
temp.append(word_to_idx[' '])
corpus_idx.extend(temp)
return u_words,word_to_idx,len(u_words),corpus_idx
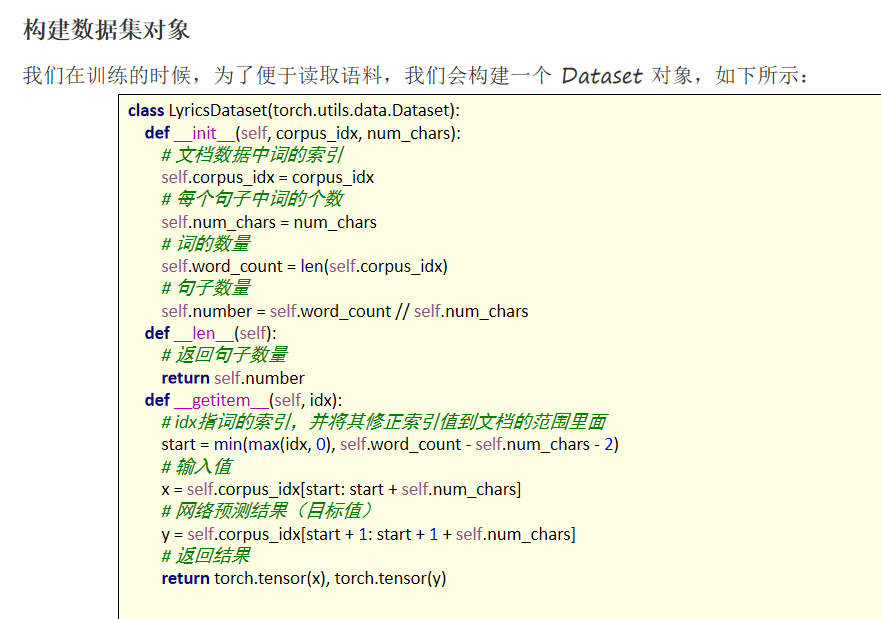
# 1.3 构建可迭代对象(相当于TensorDatadset)(重点)
class SongDataSet(torch.utils.data.Dataset):
def __init__(self,corpus_idx,num_char):
super(SongDataSet, self).__init__()
self.corpus_idx = corpus_idx
self.num_char = num_char
self.wordcount = len(self.corpus_idx)
self.number = self.wordcount//self.num_char
def __len__(self):
return self.number
def __getitem__(self, idx):
start =min(max(0,idx),self.wordcount-self.num_char-10)
x = self.corpus_idx[start:start+self.num_char]
y = self.corpus_idx[start+1:start+1+self.num_char]
return torch.tensor(x),torch.tensor(y)
# 2.构建模型
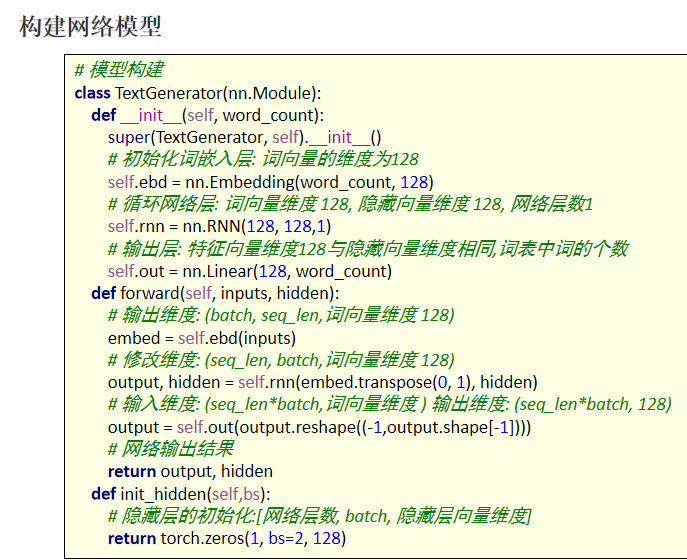
class TextGenerator(nn.Module):
def __init__(self, word_count):
super(TextGenerator, self).__init__()
# 初始化词嵌入层: 词向量的维度为128
self.ebd = nn.Embedding(word_count, 128)
# 循环网络层: 词向量维度 128, 隐藏向量维度 128, 网络层数1
self.rnn = nn.RNN(128,256,1)
# 输出层: 特征向量维度128与隐藏状态维度相同,词表中词的个数
self.out = nn.Linear(256, word_count)
def forward(self, inputs, hidden):
# 输出维度: (batch, seq_len, 128)
embed = self.ebd(inputs)
# 修改维度: (seq_len, batch, 128)
output, hidden = self.rnn(embed.transpose(0, 1), hidden)
# 输入维度: (seq_len*batch, 128) 输出维度: (seq_len*batch, 5682)
output = self.out(output.reshape((-1,output.shape[-1])))
# 网络输出结果
return output, hidden
def init_hidden(self,bs):
# 隐藏层的初始化:[seq_len, batch, 隐藏层向量维度]
return torch.zeros(1, bs,256)
# 3.模型训练
# 模型训练
def train():
# 构建词典
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
# 数据集
lyrics = SongDataSet(corpus_idx, 32)
# 初始化模型
model = TextGenerator(word_count)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化方法
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练轮数
epoch = 2
# 开始训练
for epoch_idx in range(epoch):
# 数据加载器
lyrics_dataloader = DataLoader(lyrics, shuffle=True, batch_size=1)
# 训练时间
start = time.time()
# 迭代次数
iter_num = 0
# 训练损失
total_loss = 0.0
# 遍历数据集
for x, y in lyrics_dataloader:
# 隐藏状态的初始化
hidden = model.init_hidden(bs=1)
# 模型计算
output, hidden = model(x, hidden)
# 计算损失
# y:[batch,seq_len]->[seq_len,batch]->[seq_len*batch]
y = torch.transpose(y, 0, 1).contiguous().view(-1)
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 迭代次数加1
iter_num += 1
total_loss += loss.item()
# 打印训练信息
print('epoch %3s loss: %.5f time %.2f' % \
(epoch_idx + 1,
total_loss / iter_num,
time.time() - start))
# 模型存储
torch.save(model.state_dict(), 'data/lyrics_model_%d.pth' % epoch)
# 4.模型预测,模型评估
def predict(start_word, sentence_length):
# 构建词典
index_to_word, word_to_index, word_count, _ = build_vocab()
# 构建模型
model = TextGenerator(word_count)
# 加载参数
model.load_state_dict(torch.load('data/lyrics_model_2.pth'))
# 隐藏状态
hidden = model.init_hidden(bs=1)
# 将起始词转换为索引
word_idx = word_to_index[start_word]
# 产生的词的索引存放位置
generate_sentence = [word_idx]
# 遍历到句子长度,获取每一个词
for _ in range(sentence_length):
# 模型预测
output, hidden = model(torch.tensor([[word_idx]]), hidden)
# 获取预测结果
word_idx = torch.argmax(output)
generate_sentence.append(word_idx)
# 根据产生的索引获取对应的词,并进行打印
for idx in generate_sentence:
print(index_to_word[idx], end='')
if __name__ == '__main__':
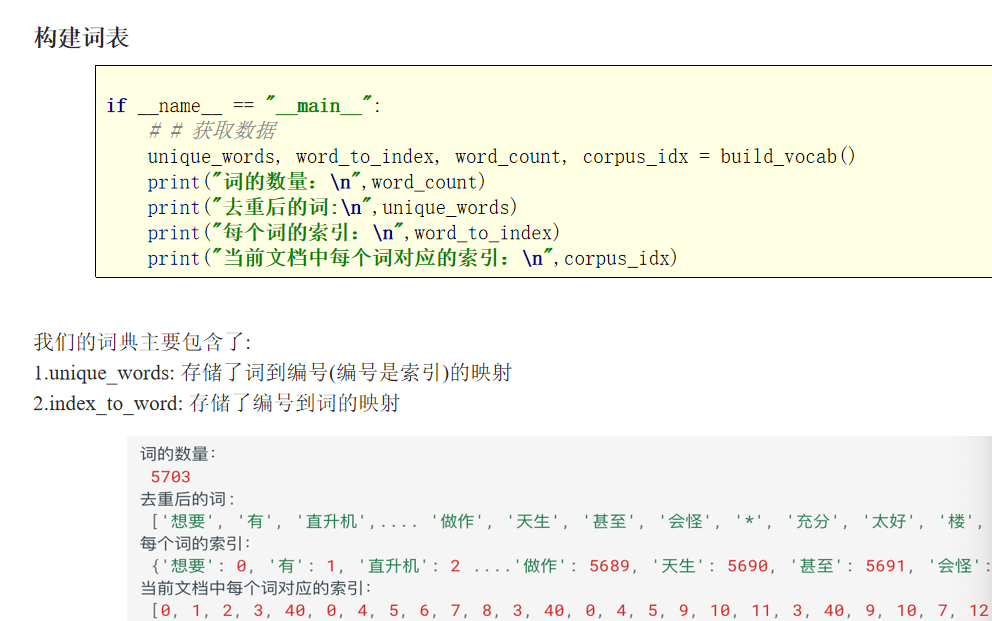
u_words, word_to_idx, count, corpus_idx= build_vocab()
# print(u_words)
# print(count)
# print(word_to_idx)
# print(corpus_idx)
# dataset =SongDataSet(corpus_idx,10)
# x,y = dataset.__getitem__(0)
# print(x)
# print(y)
# train()
predict('分手',50)总结:可能写的不太好,一直在学习,学了复旦大学赵卫东硕导的讲解,听了浙大吴飞教授的人工智能与模型,以及B站和请教了部分企业老师讲述,个人总结,希望能帮到学习人工智能基础知识的人,人工智能学习任重道远各位一起加油!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)