基于YOLO与RKNN模型训练与部署
物资抢占过程说明:比赛车辆识别物资必须在两个斑马线之间的区域(至少两个轮子均在两个斑马线之间的区域),例如识别2号物资,车辆需要在如图3.3.2-1所示的区域内识别物资并开始语音播报。每个物资编号对应的抢占物资区域如图3.3.2-2所示。语音播报开始后,即可离开指定区域;成功抢占并确认物资后(成功抢占物资标准:在指定区域识别物资且语音播报正确),小车需回到己方基地车位上停稳(至少两个轮子在基地停车


01模型训练
一、物资抢占与数据集
物资抢占过程说明:比赛车辆识别物资必须在两个斑马线之间的区域(至少两个轮子均在两个斑马线之间的区域),例如识别2号物资,车辆需要在如图3.3.2-1所示的区域内识别物资并开始语音播报。每个物资编号对应的抢占物资区域如图3.3.2-2所示。语音播报开始后,即可离开指定区域;成功抢占并确认物资后(成功抢占物资标准:在指定区域识别物资且语音播报正确),小车需回到己方基地车位上停稳(至少两个轮子在基地停车框内,并且做出停车动作,停车时间不限),记为一次抢占物资完成;抢占物资完成会增加相应的分数和子弹数量。同一圈只能抢占一个物资,抢占多个只记录第一个未被抢占完成的物资;同一位置物资只能被抢占一次,被抢占成功后,相同位置物资不能被再次抢占。准确识别到物体,并语音播报正确,播报内容包括识别物资的位置和类别,例如:2号位置识别到显示器。
物资图片种类:本届竞赛物资识别参考竞速组-视觉组图片类别,分为“电子外设”和“常用工具”及“手写数字”三大类,每一大类又包括有若干小类,图片共15个小类(还可能出现未公布的小类)。物资图片竖立粘贴在对应位置的掩体围挡上面。
- 电子外设:鼠标、键盘、显示器、头戴式耳机、音响、打印机、手机
- 交通常用工具:扳手、螺丝刀、手电钻、钳子、万用表、示波器、电烙铁、卷尺
- 手写体的数字:裁判或参赛选手或志愿者现场写的数字(范围0-99)。
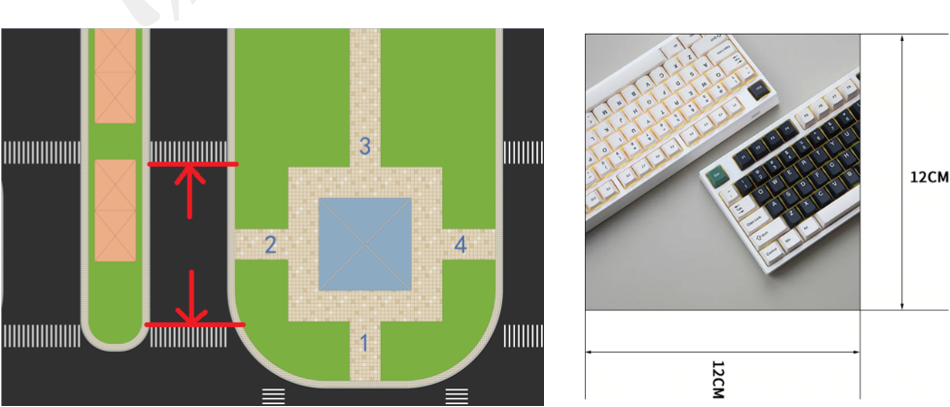
图片目标为彩色打印或者喷涂有用于识别的图片,图片不再有黄色边框,均为无框图片,图片边长为12cm,如下图所示。
第二十届智能车竞赛智能视觉组数据集请通过下方云盘链接下载使用,祝大家训练愉快!
- 链接:https://pan.baidu.com/s/1H9fIQBH8EPBujRixQcdOrQ?pwd=65pw
- 提取码:65pw
1.1 数据集结构
当前数据集结构为每个类别的图片一个文件夹。需要将其转换为 YOLO 格式。
* 数据集目录结构示例
dataset/
├── train/
│ ├── images/ # 训练集图片
│ └── labels/ # 训练集标注文件(.txt)
├── valid/
│ ├── images/ # 验证集图片
│ └── labels/ # 验证集标注文件(.txt)
├── test/ # 可选
│ ├── images/ # 测试集图片
│ └── labels/ # 测试集标注文件(.txt)
└── data.yaml # 数据集配置文件
* YAML数据集配置文件示例:
train: ./dataset/train # 训练集路径
val: ./dataset/val # 验证集路径
test : ./dataset/test # 测试集路径
nc: 15 # 类别数量(不含手写数字)
names: [‘wrench’, ‘soldering_iron’, …, ‘speaker’] # 类别名称列表
1.2 数据标注
1.2.1 标注工具
推荐使用以下工具进行标注:
- LabelImg:本地标注工具,适合中小型数据集。
- Roboflow:在线标注工具,支持直接导出 YOLO 格式。
1.2.2 标注格式
YOLO 使用 TXT 文件存储标注信息,每个目标一行,格式为:
<class_id> <center_x> <center_y>
- class_id:类别索引(从 0 开始)
- center_x, center_y:归一化后的边界框中心点
- width, height:归一化后的边界框宽度和高度
1.2.3 数字识别标注策略
对于手写数字识别,有三种可行方案:
- 1. 方案一:将数字识别分解为 0-9 的单数字识别,然后通过后处理组合成多位数。
- 2. 方案二:直接训练识别 0-99 的模型(需要更多样本)。
- 3. 方案三:通过YOLO识别数字区域后通过OCR模型识别区域内的数字。
由于场景相对简单,推荐优先尝试方案一,实现步骤:
- 标注所有单个数字(0-9)。
- 训练 YOLO 模型识别这些数字。
- 后处理阶段根据识别框的位置和大小关系判断是否应组合成多位数。
二、模型训练与优化
2.1 环境准备
以 YOLOv5 为例(YOLO系列整体类似),克隆源码并安装依赖:
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
2.2 模型训练
2.2.1 下载预训练模型权重
根据需求选择合适的预训练模型,如n、s、m、l、xl版本等。
2.2.2 配置训练参数
修改train.py中的参数,或通过命令行传递参数:
关键参数说明:
- –weights:预训练模型路径
- –data:数据集配置文件路径
- –epochs:训练轮数
- –batch-size:批次大小
- –img:输入图像尺寸
- –cfg:模型配置文件(如需自定义模型结构)
2.3 模型优化策略
2.3.1 提高准确率的方法
(1) 数据增强:
- 随机缩放、旋转、翻转
- 颜色抖动
- 马赛克增强(Mosaic augmentation)
(2) 调整超参数:
- 调整训练轮数(–epochs)
- 减小学习率(–lr0)
- 调整动量(–momentum)
- 调整权重衰减(–weight_decay)
(3) 模型选择:
- 尝试更大的模型(如 yolov5m/yolov5l)。
- 使用更深的特征提取网络。
(4) 类别平衡:
- 对小样本类别进行过采样或补充数据
- 使用类别权重调整损失函数,如Focal Loss或Asymmetric Loss
2.3.2 提高推理速度的方法
(1) 模型压缩
- 使用更小的模型(如 yolov5n/yolov5s)
- 降低输入图像尺寸(–img)
- 进行模型量化(如 FP16量化、INT8 量化)
- 将高参数版本的模型蒸馏到小参数量版本的模型上
(2) 推理优化
- 使用Ultralytics的模型剪枝功能减少冗余权重
- RKNN转换时进行INT8量化以提升FPS
- 利用 RK3588S 的 VPU和NPU 加速
2.3.3 数据扩充与增强
(1) 网络数据收集
- 使用爬虫工具收集相关类别的图片
- 利用公开数据集(如 COCO、ImageNet)中的相关类别
- 使用合成数据生成工具
(2) 数据增强方法
- 几何变换:旋转、缩放、平移、翻转
- 颜色变换:亮度、对比度、饱和度、色调调整
- 噪声添加:高斯噪声、椒盐噪声
- 高级增强:MixUp、CutMix、Mosaic
YOLOv5 内置了多种数据增强方法,可通过修改data/hyps/hyp.scratch-low.yaml等配置文件调整参数。
2.4 ultralytics包
若只需使用原始的YOLO模型而无需对模型进行优化和调整,则可直接利用ultralytics包进行模型的训练和导出。可参考:https://docs.ultralytics.com/usage/python/。
三、模型转换与部署
3.1 模型转ONNX格式
在训练完成后,将 YOLO 的PT格式的模型导出为 ONNX 格式。可通过源码中的export.py导出,也可通过ultralytics包工具直接导出。
3.2 模型转RKNN格式
3.2.1 RKNN Toolkit2
RKNN Toolkit2(https://github.com/airockchip/rknn-toolkit2)开发套件提供了模型转换、模型量化、模型推理、性能和内存评估、量化精度分析、模型加密等功能,可用于我们将 ONNX 模型转换为 RK3588S 可用的 RKNPU 模型,所以首先需要安装RKNN Toolkit2,注意PC端和板卡端分别安装RKNN Toolkit2和RKNN Toolkit Lite2。
3.2.1 转换并推理
RKNN Model Zoo(https://github.com/airockchip/rknn_model_zoo)基于 RKNPU SDK 工具链开发, 提供了目前主流算法的部署例程. 例程包含导出RKNN模型, 使用 Python API, CAPI 推理 RKNN 模型的流程。
在该库的examples目录下提供了常见的如YOLO各个系列的模型转换脚本以及推理的示例脚本(包含预处理、推理、后处理流程,若未修改YOLO源码可直接修改使用),可参考该代码实现将ONNX格式的模型转换为RKNN格式的模型,并将RKNN模型上传到板卡端在NPU环境下进行推理测试。
四、常见问题及解决方法
4.1 转换 RKNPU 模型后识别框很多很乱
在YOLO和RKNN Toolkit2的不同版本在可能表现不完全一致,可能会出现识别框很多很乱的情况,可以尝试以下修改:
(1) 修改models/yolo.py的前向传播forward函数。
(2) 修改rknn-toolkit2/examples下对应test.py的源码,查看该代码是否直接对图片处理,由于训练时对图片进行了sigmoid函数处理,所以可添加推理时的sigmoid处理。
(3) 尝试设置合理的NMS阈值。
4.2 转换 RKNPU 模型后精度下降
在将模型转换为RKNN格式的模型后出现推理精度下降,可能是由于量化过程中的信息损失、预处理参数不匹配、模型架构不支持某些操作等导致。可尝试以下方法:
(1) 使用混合精度量化或高精度量化(如 FP16 量化);尝试增加校准数据集,提高量化精度。
(2) 确保预处理参数与训练时一致(如均值和标准差)。
(3) 检查模型是否包含不支持的操作和尝试简化模型,如避免使用Swish激活函数、移除不必要的后处理层。
4.3 推理速度慢
在板卡上部署后推理速度过慢可能是由于模型过大、图片输入尺寸过大、未充分利用NPU等原因,可尝试以下方法:
(1) 使用更小的模型(如 yolov5n/s)。
(2) 降低图像的输入尺寸。
(3) 检查模型是否利用NPU推理而不是CPU。
4.4 数字识别准确率低
对于数字识别准确率低的问题可尝试以下方法:
(1) 增加数字样本多样性,特别是易混淆的数字(如 6 和 9,1 和 7)。
(2) 优化后处理逻辑,调整数字组合的阈值参数。
(3) 对数字区域进行额外的预处理(如二值化、去噪)。
4.5 小物体检测准确率低
若出现对小物体识别准确率低的情况可尝试以下思路来解决这个问题:
(1) 修改预处理阶段的resize缩放策略,尝试保留图像原始宽高比缩放。
(2) 启用多尺度multi_scale。
(3) 尝试在模型结构上如P3这种浅层特征上设置更多检测头来加强小目标的处理。
(4) 尝试将IOU损失换成CIOU损失。
(5) 针对自己的数据集提前使用K-means算法找到合适的anchor并在模型训练前写入配置文件。
4.5 小物体检测准确率低
若出现对小物体识别准确率低的情况可尝试以下思路来解决这个问题:
(1) 修改预处理阶段的resize缩放策略,尝试保留图像原始宽高比缩放。
(2) 启用多尺度multi_scale。
(3) 尝试在模型结构上如P3这种浅层特征上设置更多检测头来加强小目标的处理。
(4) 尝试将IOU损失换成CIOU损失。
(5) 针对自己的数据集提前使用K-means算法找到合适的anchor并在模型训练前写入配置文件。
(6) 针对自己的数据集尝试调整NMS算法的IOU阈值和置信度阈值。
那么,如何快速系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

9周快速成为大模型工程师
第1周:基础入门
-
了解大模型基本概念与发展历程
-
学习Python编程基础与PyTorch/TensorFlow框架
-
掌握Transformer架构核心原理
-

第2周:数据处理与训练
-
学习数据清洗、标注与增强技术
-
掌握分布式训练与混合精度训练方法
-
实践小规模模型微调(如BERT/GPT-2)
第3周:模型架构深入
-
分析LLaMA、GPT等主流大模型结构
-
学习注意力机制优化技巧(如Flash Attention)
-
理解模型并行与流水线并行技术
第4周:预训练与微调
-
掌握全参数预训练与LoRA/QLoRA等高效微调方法
-
学习Prompt Engineering与指令微调
-
实践领域适配(如医疗/金融场景)
第5周:推理优化
-
学习模型量化(INT8/FP16)与剪枝技术
-
掌握vLLM/TensorRT等推理加速工具
-
部署模型到生产环境(FastAPI/Docker)
第6周:应用开发 - 构建RAG(检索增强生成)系统
-
开发Agent类应用(如AutoGPT)
-
实践多模态模型(如CLIP/Whisper)


第7周:安全与评估
-
学习大模型安全与对齐技术
-
掌握评估指标(BLEU/ROUGE/人工评测)
-
分析幻觉、偏见等常见问题
第8周:行业实战 - 参与Kaggle/天池大模型竞赛
- 复现最新论文(如Mixtral/Gemma)
- 企业级项目实战(客服/代码生成等)
第9周:前沿拓展
- 学习MoE、Long Context等前沿技术
- 探索AI Infra与MLOps体系
- 制定个人技术发展路线图

👉福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 50
50 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)