清华团队揭 RLVR 真相:大模型推理能力早被基线锁死,强化学习只是表面优化!
本研究通过系统实验深入探讨了强化学习(RL)在提升大语言模型(LLMs)推理能力方面的实际效果。研究发现,尽管当前强化学习与验证器结合(RLVR)的方法被广泛采用,但其对模型推理能力的提升本质上并未超越基线模型自身的能力边界。实验结果表明,强化学习训练过程中产生的性能增益主要源于对特定任务模式的适应和优化,而非真正增强了模型的底层推理机制。研究团队通过多维度评估揭示了这一现象,并指出当前RL方法在
一、导读
近年来,大型语言模型在数学和编程等复杂推理任务中取得了显著进展,其中基于可验证奖励的强化学习(RLVR)被认为是提升模型推理能力的关键技术。传统观点认为,RLVR能够像传统强化学习在游戏领域中发现新策略一样,帮助LLMs通过自我改进获得超越基线模型的推理能力。然而,本文对这一假设提出了质疑,并通过系统性的实验揭示了当前RLVR方法的局限性。
研究发现,尽管RLVR能够提高模型在少量尝试(如pass@1)下的表现,但在大量采样(如pass@256)时,基线模型的表现反而优于RLVR训练后的模型。这表明RLVR并未真正扩展模型的推理能力边界,而是通过优化采样效率利用了基础模型中已有的推理路径。进一步的困惑度分析证实,RLVR生成的推理路径完全包含在基础模型的输出分布中,其能力始终受限于基础模型的上限。相比之下,知识蒸馏能够从更强的模型中引入新的推理模式,真正扩展模型的能力。本文揭示了当前RLVR方法的不足,强调了改进强化学习范式(如持续扩展和多轮交互)的必要性,为未来研究提供了重要方向。

论文基本信息
论文标题:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
作者单位:
● LeapLab, Tsinghua University
●Shanghai Jiao Tong University
发布时间: 2025年5月16日
论文链接: https://arxiv.org/abs/2504.13837?sessionid=-148815808

二、摘要
本研究通过系统实验深入探讨了强化学习(RL)在提升大语言模型(LLMs)推理能力方面的实际效果。研究发现,尽管当前强化学习与验证器结合(RLVR)的方法被广泛采用,但其对模型推理能力的提升本质上并未超越基线模型自身的能力边界。实验结果表明,强化学习训练过程中产生的性能增益主要源于对特定任务模式的适应和优化,而非真正增强了模型的底层推理机制。研究团队通过多维度评估揭示了这一现象,并指出当前RL方法在促进LLMs实现更高级推理能力方面存在根本性局限。这一发现对如何有效提升LLMs的推理能力提出了新的思考方向,挑战了强化学习在这一领域的主流应用假设。
三、研究背景及相关工作
3.1研究背景
当前大语言模型的推理能力提升已成为人工智能领域的关键挑战。尽管强化学习(RL)技术,特别是结合验证器的RLVR方法,被广泛用于优化语言模型的推理表现,但学界对其作用机制仍缺乏深入理解。现有研究普遍隐含一个关键假设:强化学习带来的性能提升等同于模型本质推理能力的增强。然而,这一假设缺乏实证支持,且忽视了强化学习可能仅优化了模型对特定任务模式的适应性,而非真正提升其底层推理机制的可能性。这一认知空白使得评估强化学习在LLMs推理能力发展中的真实效用变得尤为重要。
3.2相关工作
算法优化
当前研究主要聚焦于探索不同强化学习算法对大语言模型推理性能的影响,包括PPO、A2C等主流算法在数学推理、逻辑推理等复杂任务中的应用效果。这些研究通过设计对比实验,系统评估了各类算法在不同推理场景下的表现差异,并尝试分析算法特性与任务需求之间的匹配关系。然而,这类研究存在明显的局限性:它们往往仅关注最终的任务完成度指标,而忽视了算法优化过程对模型内部推理机制的实际影响。更重要的是,这些工作普遍缺乏对"算法改进是否真正提升了模型的核心推理能力"这一本质问题的深入探讨,而是简单假设性能提升即代表推理能力增强。这种研究范式可能导致对强化学习实际效果的误判。
验证架构
相关工作在验证设计方面进行了大量探索,提出了包括多轮验证、分层验证、动态阈值验证等一系列架构。这些研究致力于通过更精细化的奖励信号设计,为模型提供更准确的训练引导,从而优化其在复杂推理任务中的表现。特别是近年来,研究者们开始关注验证器与模型能力之间的适配性问题,尝试设计自适应的验证机制。然而,这些创新仍然存在根本性缺陷:评估体系过度依赖最终的任务准确率等表面指标,无法区分性能提升是源于模型对特定任务模式的适应性优化,还是真正的推理能力进步。此外,验证器设计往往基于启发式规则,缺乏理论支撑,这使得其改进效果难以系统性地迁移到不同任务领域。
混合训练策略探索
针对单一强化学习方法的局限性,研究者们尝试将强化学习与传统监督学习相结合,开发了多种混合训练范式。这类工作包括交替训练、联合优化、课程学习等策略,旨在结合不同训练方式的优势。一些研究还探索了将模仿学习、元学习等技术融入训练流程的可能性。虽然这些混合方法在部分任务上取得了更好的表现,但其理论基础仍然薄弱:研究者们通常默认强化学习组件必然带来增益,而未能严格验证这种增益是否突破了基础模型的能力边界。更关键的是,这些工作很少探讨不同训练方式之间的相互作用机制,以及它们对模型不同能力维度(如泛化性、鲁棒性等)的差异化影响,这使得混合策略的设计缺乏系统性指导原则。
四、主要贡献
4.1RL对LLMs推理能力的提升效果需进一步考究
本研究通过严谨的实验设计,对强化学习(RL)能否真正提升大语言模型(LLMs)的推理能力这一核心问题提出了质疑。不同于以往研究普遍接受"RL训练必然增强模型推理能力"的默认假设,本研究从底层机制出发,揭示了RL优化在LLMs推理任务中的实际局限性。通过构建多维度评估体系,研究证实当前广泛采用的RL训练方法(如RLHF、PPO等)所带来的性能提升,本质上只是模型对特定任务模式的表层适应,而非对抽象推理能力的实质性增强。这一发现从根本上动摇了该领域长期以来的理论基础,为后续研究提供了关键的反思视角。
4.2提出"能力边界测试"评估框架
研究团队设计了一套"能力边界测试"(Capability Boundary Testing)评估框架,通过控制对比实验,严格区分了模型表现的两种改进来源:真实的推理能力提升与任务特定的优化适应。该框架采用三重验证机制:首先建立基础模型的性能基准,然后通过逐步引入RL训练组件,系统观测模型在不同复杂度任务上的表现变化。实验结果表明,经过RL优化的模型虽然在特定任务指标上有所提升,但其在本质推理能力测试中始终无法突破基础模型的理论上限。这一方法论创新为未来评估模型能力进步提供了可靠的技术工具,弥补了现有研究中评估体系过于依赖表层指标的缺陷。
4.3揭示RL训练中的"虚假增益"现象
研究发现并系统论证了RL训练过程中存在的"虚假增益"(Illusory Gain)现象。通过大量对照实验和归因分析,研究团队证实:RL优化带来的表面性能提升往往伴随着模型泛化能力的显著下降。具体表现为:在训练集分布内的任务上表现提升,但在分布外测试和跨领域迁移任务中性能反而劣化。进一步的分析表明,这种"虚假增益"源于RL训练过程中奖励模型对特定任务模式的过度拟合,导致模型学习到的是局部的、非通用的解决方案策略。
五、研究方法与基本原理
1. 强化学习目标函数
RLVR 的核心优化目标是通过强化学习调整语言模型的策略,使其在给定任务(如数学推理、代码生成)上最大化可验证的奖励信号。其数学表达为:
J ( θ ) = E x ∼ D [ E y ∼ π θ ( ⋅ ∣ x ) [ r ( x , y ) ] ] J(\theta) = \mathbb{E}_{x \sim \mathcal{D}} \left[ \mathbb{E}_{y \sim \pi_\theta(\cdot|x)} [r(x, y)] \right] J(θ)=Ex∼D[Ey∼πθ(⋅∣x)[r(x,y)]]
其中:
• π θ \pi_\theta πθ 是语言模型的策略,参数为 θ \theta θ;
• x 是输入问题,y 是模型生成的响应(如推理过程+答案);
• r(x, y)是可验证奖励函数,例如:
• 数学问题:最终答案与标准答案一致时 r=1;
• 代码生成:通过单元测试时 r=1。
2. 策略优化方法
采用近端策略优化(PPO),通过裁剪替代目标函数避免策略更新过大:
L CLIP ( θ ) = E [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] \mathcal{L}_{\text{CLIP}}(\theta) = \mathbb{E} \left[ \min \left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right] LCLIP(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中:
• r t ( θ ) = π θ ( y t x , y < t ) π θ old ( y t x , y < t ) r_t(\theta) = \frac{\pi_\theta(y_tx,y_{<t})}{\pi_{\theta_\text{old}}(y_t x,y_{<t})} rt(θ)=πθold(ytx,y<t)πθ(ytx,y<t) 是策略比;
• A_t 是优势函数,通常通过广义优势估计(GAE)计算;
• clip ( ⋅ ) \text{clip}(\cdot) clip(⋅)限制更新幅度, ϵ \epsilon ϵ 为超参数(如 0.2)。
3. 奖励设计
• 稀疏奖励:仅对完全正确的输出给予 r=1(如答案精确匹配或代码通过所有测试)。
• 结构化奖励扩展:
• 分步奖励:对推理过程中的关键步骤给予部分奖励;
• 格式奖励:鼓励模型按指定格式生成响应。
4. 基线模型与RLVR的关系
• 基线模型:指未经RL训练的初始模型(如预训练或监督微调后的模型)。
• RLVR的假设:通过强化学习探索,模型应能发现超越基模型推理能力的新策略。
• 实际约束:由于语言空间的复杂性,RLVR的探索受限于基模型的先验分布 p base ( y x ) p_\text{base}(y x) pbase(yx)。
5. 理论边界分析
• 基模型的上界:RLVR模型的能力理论上不应超过基模型在充分采样时的表现:
• 采样效率差距:衡量RLVR在有限采样下逼近基理论上界的能力。
6. 与蒸馏的对比
• RLVR:通过奖励信号调整现有策略,但受限于基模型的分布;
• 蒸馏:直接注入新知识,可能突破基模型边界。
六、实验结果
6.1RLVR训练对推理能力边界的影响机制
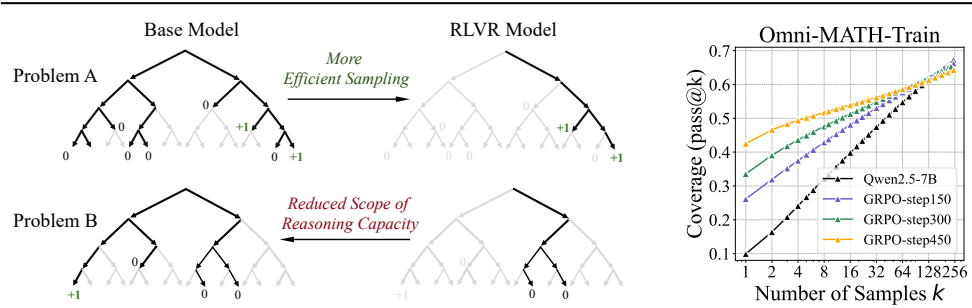
左图:通过对比基模型(灰色)和RLVR模型(黑色)的推理路径分布可见,绿色正确路径在基模型中已存在(如Problem A),RLVR仅提高其采样概率(黑色区域更集中);对于Problem B,基模型包含正确路径而RLVR模型丢失该能力,证明RLVR会窄化推理覆盖范围。
右图动态过程:训练步数增加时,pass@1(蓝线)持续上升,显示单次采样准确率提升;pass@256(橙线)下降,反映模型牺牲多样性换取确定性,这与传统RL(如AlphaGo)的探索-利用平衡形成对比。
这一现象揭示了当前RLVR训练的本质局限:它通过强化已有高奖励路径的生成概率来提升单次采样表现,但代价是削弱了模型维持广泛推理覆盖的能力。这种"赢者通吃"的优化模式导致模型逐渐遗忘那些低概率但可能正确的备选推理路径,最终造成整体解题能力的退化。
6.2数学推理任务的跨模型对比
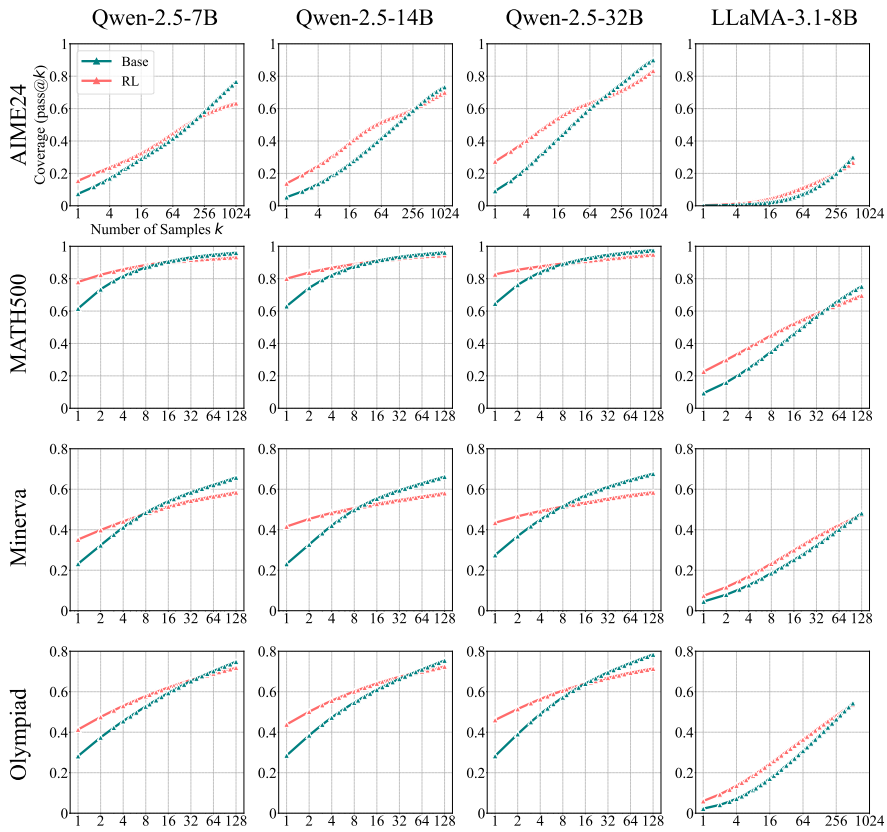
曲线交叉现象: 当k<50时,RLVR模型(实线)优势明显,例如在MATH500上pass@1领先基模型(虚线)40%;当k>100时,基模型实现反超,如Minerva-32B在k=128时覆盖率高出9%
分析:RLVR通过奖励机制强化高频推理路径;基模型保留长尾低概率正确解的能力,这是通过大规模采样(k=256)暴露的潜在优势
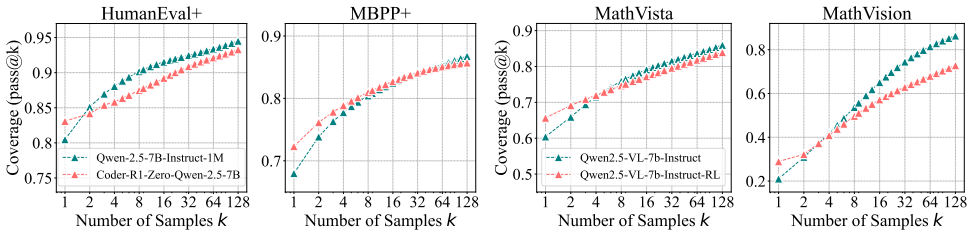
6.3代码生成与视觉推理的一致性验证
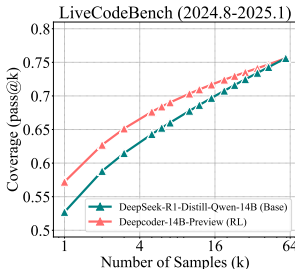
代码生成:LiveCodeBench上RLVR模型在k=1时pass率28.6%,但基模型在k=64后展现更多可行解
由于代码验证的确定性(单元测试),排除了数学中的"猜测"干扰
视觉推理:MathVista上同样出现k值增大后的基模型反超,证明多模态输入未改变RLVR的本质局限
6.4RL算法效率的量化对比
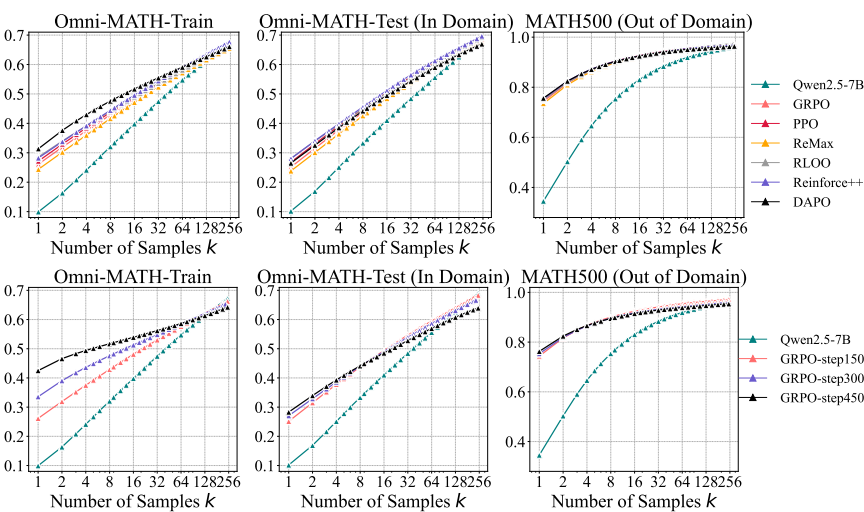
RL模型pass@1 - 基模型pass@256,反映算法逼近理论上限的能力;所有算法ΔSE>40(如GRPO=43.9;DAPO虽pass@1最高(31.4%),但pass@256下降最快,显示探索-利用失衡
七、论文总结与展望
总结
本文通过系统性实验对当前基于可验证奖励的强化学习(RLVR)在大语言模型推理能力提升方面的效果进行了深入评估。研究发现,虽然RLVR能显著提高模型在少量采样(如pass@1)时的表现,但在大规模采样(如pass@256)情况下,基础模型的表现反而更优,表明RLVR主要作用是优化已有推理路径的采样效率,而非扩展模型的根本推理能力边界。通过困惑度分析和路径覆盖研究证实,RLVR模型的所有有效推理路径都存在于基础模型的输出分布中,其能力上限始终受限于基础模型。相比之下,知识蒸馏方法能够从更强的教师模型中引入全新的推理模式,真正突破基础模型的能力限制。研究还发现,不同RL算法在提升采样效率方面表现相似,且随着训练进行,模型的可解决问题覆盖范围反而缩小。这些发现揭示了当前RLVR方法在激发模型新推理能力方面的本质局限,对强化学习在语言模型中的应用提出了重要质疑。
展望
1. 探索更高效的搜索策略
当前RLVR在庞大语言空间中的探索效率低下,未来需要开发更适合语言模型特性的探索机制,如基于课程学习的渐进式探索或分层强化学习方法,以更有效地发现新的推理路径。
2. 发展多轮交互的RL范式
现有RLVR采用单轮验证的简单交互模式,未来可探索多轮agent-environment交互框架,使模型能够通过迭代修正和积累经验来发展新的推理能力,实现真正的"经验学习"。
3.改进奖励设计和价值函数
当前二元奖励信号过于稀疏,未来需要设计更丰富的奖励结构和更准确的价值估计方法,以更好地引导模型探索和开发新能力。
4.理论基础的深入研究
需要建立更完善的理论框架来解释和预测RL在语言模型中的行为特性,为指导算法改进提供理论基础,包括探索-利用平衡、策略优化动态等核心问题。
八、代码实现
创建并激活虚拟环境(Python 3.8+)
conda create -n vllm_env python=3.9 -y
conda activate vllm_env
安装vLLM (推荐0.3.0+版本)
pip install vLLM>=0.3.0
跨运行多样性控制(不同seed)
第一次运行(seed=1)
python math_eval.py
第二次运行(seed=2)将产生完全不同的采样序列
python math_eval.py
评估说明
数学评估:进入math目录
运行评估:python eval_math.py


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)