StepSearch:用强化学习点燃大模型的多跳搜索能力
StepSearch的成功证明:在复杂推理任务中,“细致入微的过程监督”比“事后诸葛亮式的全局评价”更有效。它不仅为大模型赋予了类似人类的分步信息检索能力,也为构建更可靠、可解释的AI系统提供了新思路。随着技术发展,我们有望看到能像人类研究员一样“提出问题-搜索验证-整合结论”的智能体,在科研、教育等领域发挥变革性作用。(本文代码与数据集已开源:https://github.com/Zillwan
论文名称:StepSearch: Igniting LLMs Search Ability via Step-Wise Proximal Policy Optimization
论文地址:https://www.arxiv.org/pdf/2505.15107
在人工智能飞速发展的今天,大型语言模型(LLMs)已展现出惊人的语言理解与生成能力。然而,当面对需要多步推理的复杂问题时,这些模型常常因知识缺口和低效的知识整合机制而力不从心。想象一下,当被问及“《季度刊》由哪所教育机构出版?该刊物以伊斯特伍德公园历史区所在的州命名”这样的问题时,模型需要先确定伊斯特伍德公园的位置,再找到以该州命名的期刊及其出版机构——这就是典型的多跳推理任务。
现有研究尝试用强化学习(RL)训练模型进行搜索式文档检索,虽在问答性能上有所提升,但在复杂多跳任务中仍显不足。核心问题在于:它们依赖全局奖励信号,而这种稀疏的反馈难以指导每一步的搜索决策。为此,来自商汤科技、南京大学和深圳大学的研究团队提出了StepSearch框架,通过分步近端策略优化(PPO)方法,为大模型注入了更精细的搜索能力。
一、多跳推理的困境:全局奖励的局限性
多跳问答要求模型像人类一样,逐步获取外部知识并整合信息。例如,解答“谁是入侵了尤瑟夫·阿尔-萨维德所在国家并引发美国军事行动的国家的现任总理?”这一问题,需要依次完成:
- 确定尤瑟夫·阿尔-萨维德的国籍;
- 找出入侵该国的国家;
- 查询该国现任总理。
传统方法存在两大瓶颈:
- 奖励信号稀疏:仅依赖最终答案的正确性(全局奖励),无法指导中间步骤的搜索决策。例如,若模型在第一步搜索时就找错了人物国籍,后续推理将全盘皆错,但全局奖励无法定位这一问题。
- 搜索效率低下:模型可能重复搜索相同信息或检索无关文档,浪费计算资源且降低准确率。
以基于强化学习的现有方法(如Search-R1、ZeroSearch)为例,它们虽能调用搜索引擎,但因缺乏分步监督,在3跳以上的复杂任务中性能显著下降。
二、StepSearch:分步奖励与过程监督的创新框架
StepSearch的核心突破在于将“全程盲搜”转变为“步步引导”,通过精细的中间奖励和token级过程监督,让模型在每一步搜索中都能得到明确反馈。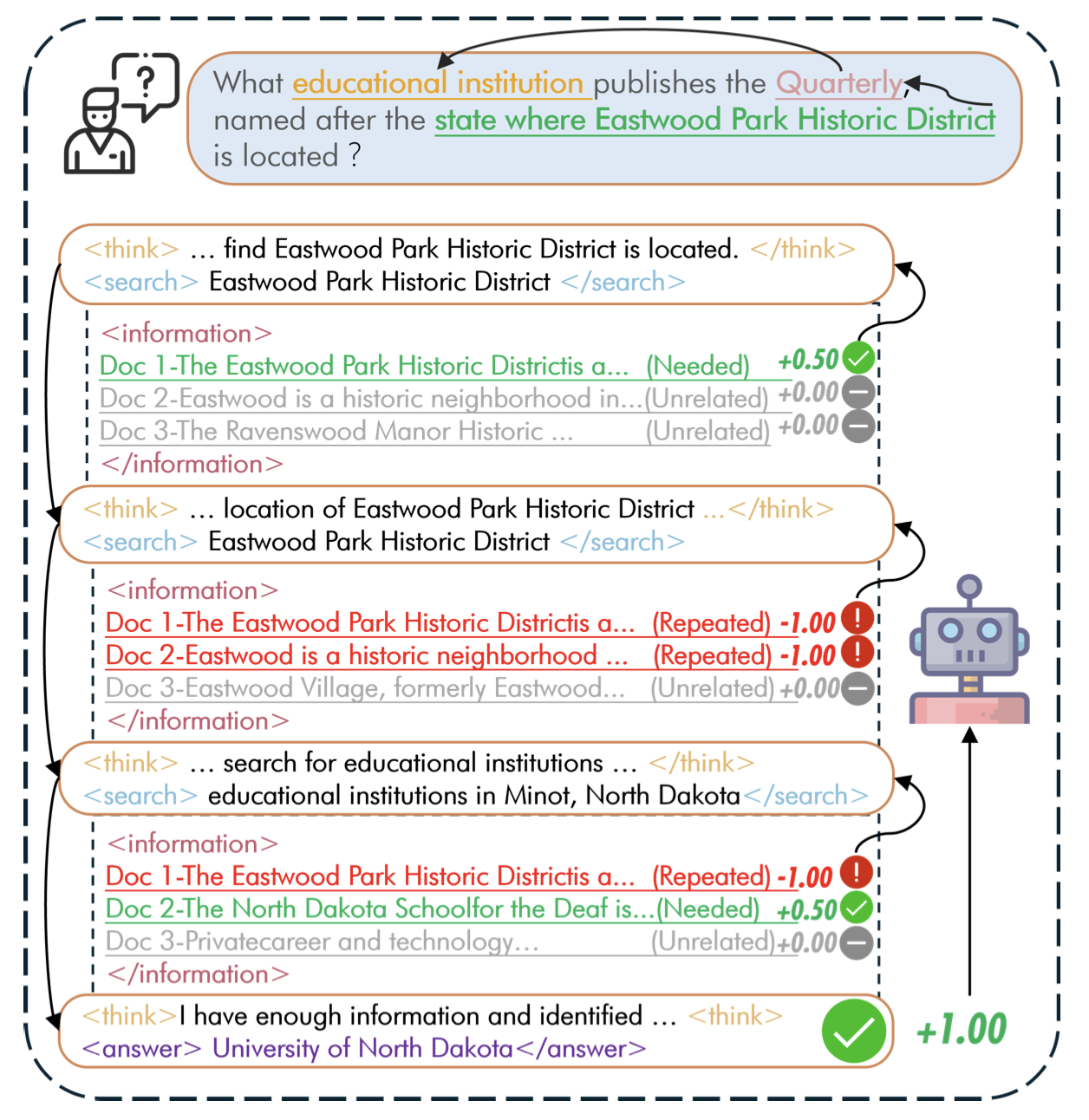
其架构包含三大支柱: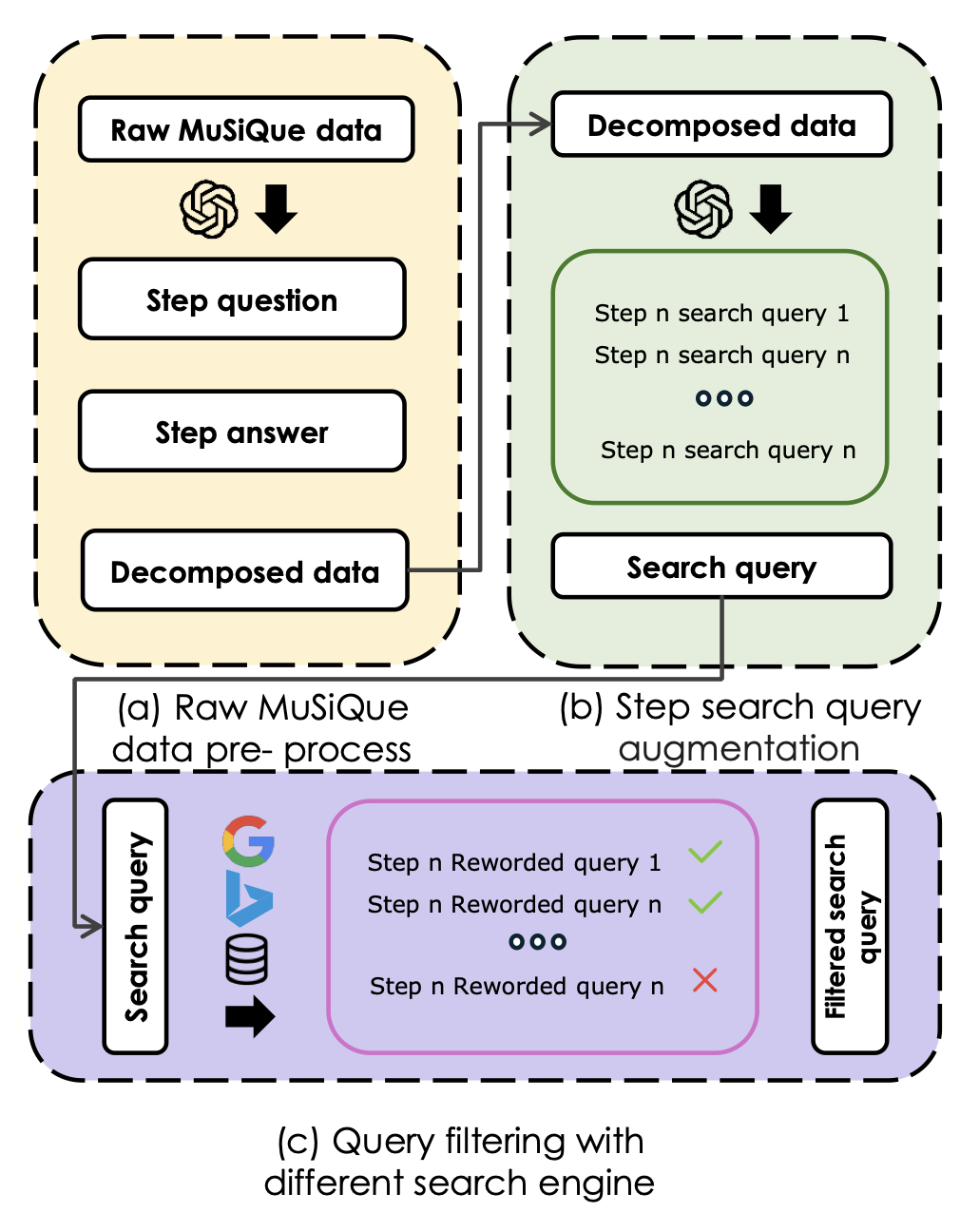
1. 细粒度数据生成管道
为了训练模型掌握分步搜索策略,研究团队基于MuSiQue数据集构建了包含子问题-搜索轨迹对齐的数据。流程如下:
- 子问题分解:使用GPT-4o将原始多跳问题拆解为连贯的子问题序列。
- 搜索关键词生成:为每个子问题生成多个候选搜索关键词。
- 跨引擎验证:保留在至少半数搜索引擎(如Google、Bing)中返回有效结果的关键词,确保实用性。
这一过程最终生成了包含60k子问题-搜索轨迹对的数据集,为分步训练提供了高质量监督信号。
2. 双类型奖励机制
StepSearch设计了全局奖励与分步奖励结合的机制,既关注最终答案正确性,又优化每一步搜索质量:
-
全局奖励(Type 1):
- 答案奖励:通过预测答案与真实答案的词级F1分数评估最终结果。
- 搜索关键词奖励:衡量生成的搜索词与参考关键词的对齐度,确保查询质量。
-
分步奖励(Type 2):
- 信息增益:计算每一步检索文档与真实所需信息的余弦相似度增量,鼓励模型获取新信息。例如,若当前搜索使相关文档匹配度从0.3提升至0.7,则信息增益为0.4。
- 冗余惩罚:统计当前检索文档与历史记录的重复比例,抑制无效重复搜索。若60%的文档已在之前出现,则惩罚值为0.6。
这种设计让模型在每一步都能明确知道“搜索是否有效”“是否需要换关键词”,避免了传统方法中“直到最后才知道对错”的盲目性。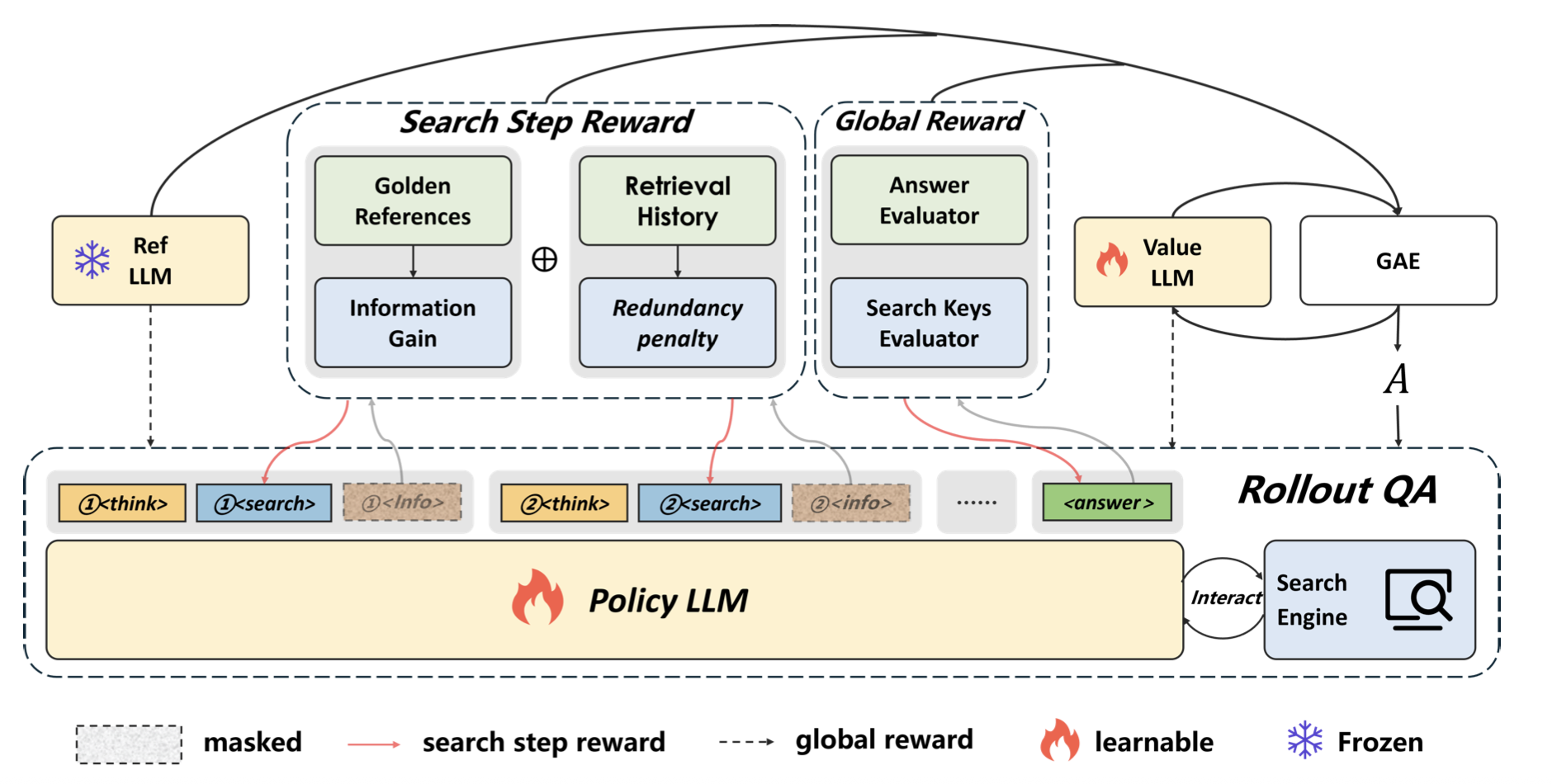
3. StePPO优化算法
基于PPO(近端策略优化),StepSearch提出了StePPO算法,实现token级别的过程监督。其核心是在每一步生成搜索词或推理内容时,根据信息增益和冗余惩罚实时调整策略,公式如下:
JStePPO(θ)=E{1∑I(ot)∑[πθ(ot)πθold(ot)At,clip(...)At]} \mathcal{J}_{StePPO}(\theta) = \mathbb{E} \left\{ \frac{1}{\sum I(o_t)} \sum \left[ \frac{\pi_\theta(o_t)}{\pi_{\theta_{old}}(o_t)} A_t, \text{clip}(...) A_t \right] \right\} JStePPO(θ)=E{∑I(ot)1∑[πθold(ot)πθ(ot)At,clip(...)At]}
其中,AtA_tAt(优势函数)综合了未来奖励与当前价值估计,使模型能动态调整每一步决策。
3. 实验结果:小数据撬动大提升
StepSearch在四大多跳QA基准测试(HotpotQA、MuSiQue、2Wiki、Bamboogle)中表现惊艳,尤其在小模型上优势显著: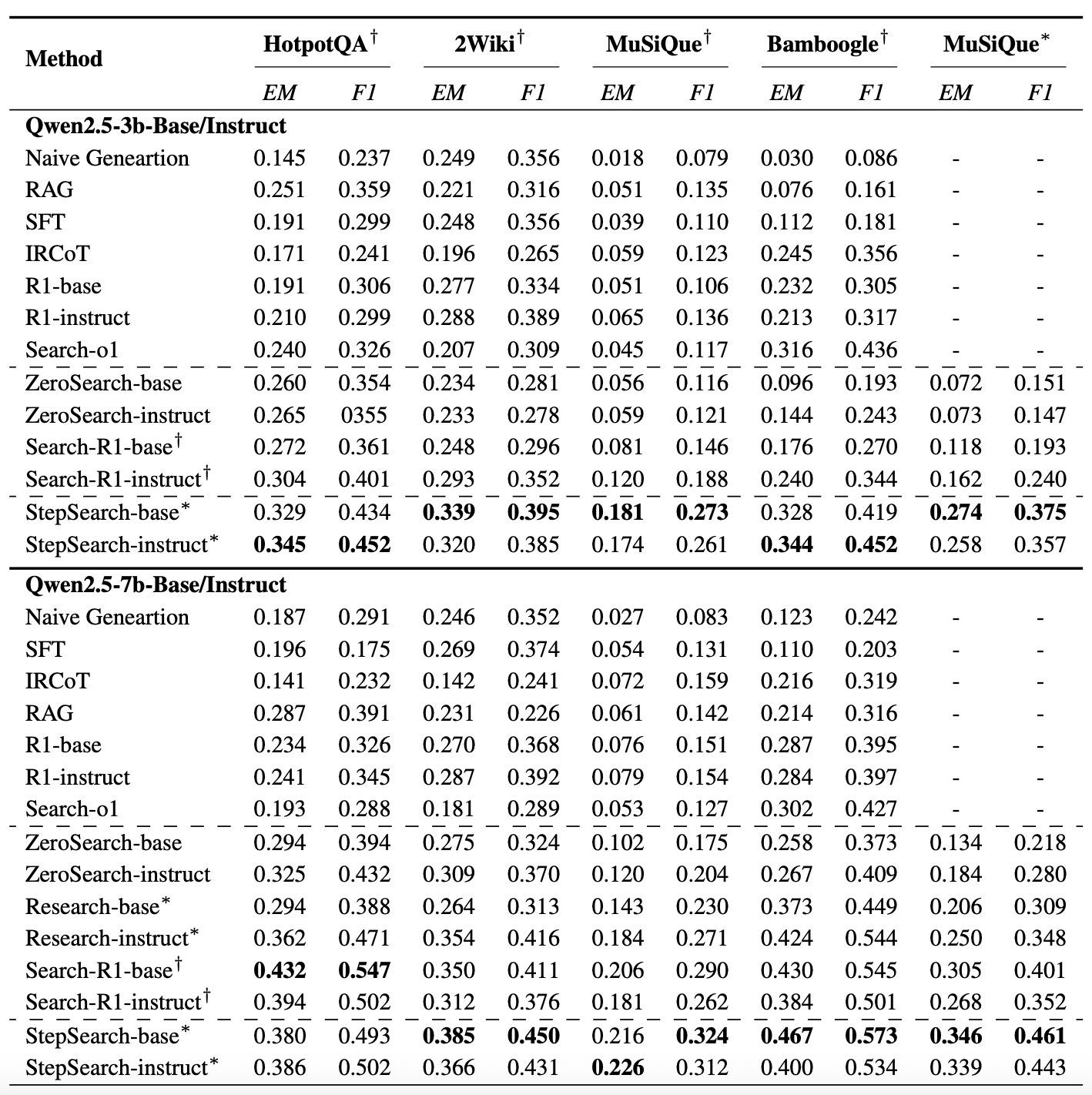
- 性能飞跃:3B参数模型在HotpotQA上的EM分数比现有RL方法高出11.2%,7B模型在Bamboogle上F1分数提升4.2%。
- 数据效率:仅用19k训练数据(约为Search-R1的11%)就实现了超越,证明分步监督的高效性。
- 泛化能力:在未见过的知识库(如自定义MuSiQue子集)上仍保持优势,显示出强大的迁移能力。
对比实验揭示了关键发现:
- 移除信息增益惩罚后,模型在2Wiki数据集上的F1分数下降8.3%,证明其对获取有效信息的必要性。
- 单独使用冗余惩罚无法提升性能,但与信息增益结合时,能使模型搜索效率提升27%,减少重复查询。
三、与现有方法的本质区别
StepSearch的革新之处在于将“黑箱式搜索”转变为“可解释的分步决策”。与主流方法对比:
- 传统RAG:仅在生成前检索一次文档,无法应对多步依赖。
- Search-R1等RL方法:依赖全局奖励,中间步骤缺乏指导,在3跳以上任务中性能骤降。
- CoT提示:虽能分解推理步骤,但无法动态调整搜索策略,易受幻觉影响。
例如,在“KBQI所在城市属于哪个县和州”的问题中:
- 传统RL模型可能反复搜索“KBQI location”而得不到有效信息。
- StepSearch会先搜索“KBQI所在城市”得到阿尔伯克基,再搜索“阿尔伯克基的县和州”,每一步都基于前序结果优化,最终高效定位答案“新墨西哥州伯纳利欧县”。
四、局限性与未来方向
尽管表现优异,StepSearch仍存在局限:
- 模态限制:目前仅支持文本问答,尚未扩展至图像、音频等多模态输入。
- 模型规模:实验限于3B和7B参数模型,更大模型(如14B)可能面临训练不稳定问题。
- 数据规模:训练数据仅19k,需验证在更大数据集上的表现。
未来研究将聚焦于:
- 增强模型的检索后理解与元认知能力,提升信息整合精度。
- 扩展至多模态任务,如基于图像的多跳推理。
- 探索更大模型训练策略,解决奖励崩塌问题。
五、结语
StepSearch的成功证明:在复杂推理任务中,“细致入微的过程监督”比“事后诸葛亮式的全局评价”更有效。它不仅为大模型赋予了类似人类的分步信息检索能力,也为构建更可靠、可解释的AI系统提供了新思路。随着技术发展,我们有望看到能像人类研究员一样“提出问题-搜索验证-整合结论”的智能体,在科研、教育等领域发挥变革性作用。
(本文代码与数据集已开源:https://github.com/Zillwang/StepSearch)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)