【AI论文】LongWriter-Zero:通过强化学习掌握超长文本生成技术
摘要:本研究提出一种基于强化学习(RL)的超长文本生成方法LongWriter-Zero,突破传统监督微调(SFT)的数据依赖限制。通过设计复合奖励模型(长度、写作质量、格式)和Group Relative Policy Optimization训练框架,该方法显著提升生成文本的连贯性与质量。实验表明,基于Qwen2.5-32B训练的模型在WritingBench和Arena-Write基准测试中
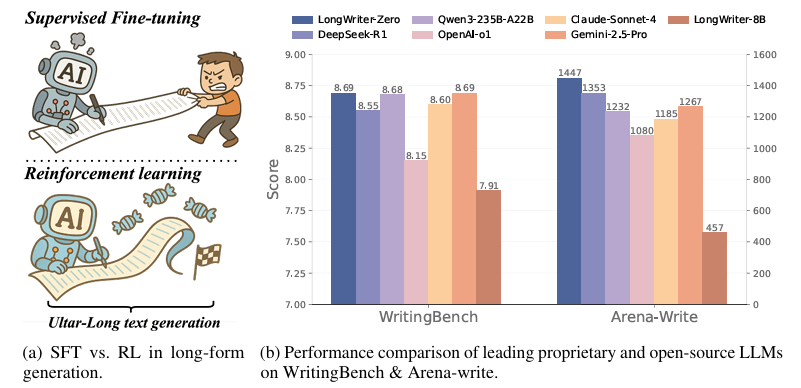
摘要:大型语言模型(LLMs)的超长文本生成是一个被广泛需求的场景,然而,由于模型存在最大生成长度限制以及随着序列长度增加导致的整体质量下降问题,这仍然是一个重大挑战。以往的方法,例如LongWriter,通常依赖于“教学”方式,即在合成的长文本输出上进行监督微调(SFT)。然而,这种策略高度依赖合成的SFT数据,这些数据构建起来既困难又昂贵,往往缺乏连贯性和一致性,并且显得过于人工化、结构单调。在本研究中,我们提出了一种基于激励的方法,该方法完全从零开始,不依赖任何标注或合成数据,利用强化学习(RL)来促使大型语言模型涌现出超长、高质量的文本生成能力。我们从类似于R1-Zero的基础模型出发进行RL训练,引导其在写作过程中进行有助于规划和精炼的思考。为了支持这一点,我们采用了专门的奖励模型,引导大型语言模型在长度控制、写作质量和结构格式方面取得改进。实验评估表明,我们从Qwen2.5-32B模型训练得到的LongWriter-Zero模型在长文本写作任务上始终优于传统的SFT方法,在WritingBench和Arena-Write基准测试的所有指标上都取得了最先进的结果,甚至超越了DeepSeek R1和Qwen3-235B等100B+参数的模型。我们在Github。Huggingface链接:Paper page,论文链接:2506.18841
研究背景和目的
研究背景
随着大型语言模型(LLMs)在自然语言处理领域的快速发展,超长文本生成能力逐渐成为现实世界应用中的关键需求。这些应用包括多章节报告撰写、叙事故事创作、法律文件起草以及教育内容生成等。然而,现有的LLMs在生成超长文本时面临诸多挑战,主要包括最大生成长度限制和随着序列长度增加导致的整体质量下降。具体来说,这些问题表现为局部不连贯、内部矛盾、重复表述、主题偏移以及结构崩溃等。
传统的超长文本生成方法主要依赖于监督微调(SFT),即在合成长文本输出上进行监督学习。然而,这种方法高度依赖合成SFT数据,这些数据不仅构建成本高昂,而且往往缺乏连贯性和一致性,显得过于人工化且结构单调。此外,现有方法在优化全局属性(如连贯性和格式一致性)方面表现不佳,因为最大似然目标函数无法提供明确的优化信号。
研究目的
为了克服上述限制,本研究提出了一种基于激励的方法,通过强化学习(RL)从零开始激活LLMs的超长文本生成能力,无需依赖任何标注或合成数据。具体而言,本研究旨在通过以下方式推动超长文本生成技术的发展:
- 设计有效的奖励模型:通过复合奖励函数引导LLMs生成更符合人类期望的超长文本,涵盖长度控制、写作质量和结构格式等多个维度。
- 探索测试时扩展(Test-time Scaling):研究在推理阶段引入长链思考(Chain-of-Thought, CoT)是否能够提升RL驱动的超长文本生成性能。
- 评估持续预训练的影响:研究在超长文本材料和推理数据上进行持续预训练是否能进一步提升RL训练模型的性能上限。
研究方法
强化学习框架
本研究采用Group Relative Policy Optimization (GRPO)算法进行RL训练。GRPO算法通过计算一组采样完成的优势来扩展Proximal Policy Optimization (PPO),从而优化策略。在每个训练输入q下,从当前策略πθ_old中采样一组候选输出{o1, o2, ..., oG},每个输出由奖励模型评分,并计算第i个样本的优势Ai。GRPO通过最大化剪辑目标函数J_GRPO(θ)来更新策略参数θ。
奖励模型设计
为了引导LLMs生成高质量的超长文本,本研究设计了三个核心奖励模型:
- 长度奖励模型(Length RM):评估生成文本的长度是否符合预期。通过预测每个查询的适当字数范围,并据此对生成文本的长度进行奖励或惩罚。
- 写作奖励模型(Writing RM):捕捉整体写作质量,包括流畅性、连贯性和有用性。通过在手动标注的偏好数据上训练,使用Qwen2.5-72B作为骨干模型,并遵循Bradley-Terry模型进行优化。
- 格式奖励模型(Format RM):检查生成文本是否符合预定义结构,并基于语义重叠指标惩罚重复内容。
最终奖励通过平衡各子奖励的优势来计算,确保不同质量维度在超长文本生成中得到均衡提升。
测试时扩展
本研究比较了两种提示策略在RL训练和推理阶段的效果:
- 思考提示(Think Prompt):要求模型在生成最终响应之前进行深入思考,并将思考过程和最终响应分别封装在<think>和<answer>标签中。
- 直接回答提示(Direct-Answer Prompt):要求模型直接生成最终响应。
通过比较这两种策略,本研究探讨了长链思考在超长文本生成中的价值。
持续预训练
为了进一步提升RL训练模型的性能上限,本研究在超长文本材料和推理数据上对Qwen2.5-32B模型进行了持续预训练。预训练数据包括中英文小说、非小说类书籍、行业报告和学术论文等多样化文本,并融入了一小部分从RL训练的Base-think模型中提取的长链思考数据,以增强模型的反思推理能力。
研究结果
奖励模型设计效果
通过RL训练,模型在长度奖励模型(Length RM)和写作奖励模型(Writing RM)上的得分均稳步提升,尤其在写作质量方面表现出色。在Arena-Write基准测试上,模型的Elo评分从200稳步提升至600以上,验证了奖励模型设计在超长文本生成中的有效性。
测试时扩展效果
研究结果表明,采用思考提示(Think Prompt)的模型在RL训练初期虽然写作奖励模型得分较低,但随着训练的进行,其表现逐渐超越直接回答提示(Direct-Answer Prompt)的模型,并在Arena-Write基准测试上取得显著更高的Elo评分。这表明,在推理阶段引入长链思考能够提升超长文本生成的性能,通过更好的规划和内容组织,实现更高质量的输出。
持续预训练效果
持续预训练显著提升了模型在RL训练初期的性能,并在最终收敛时达到更高的奖励上限。在Arena-Write基准测试上,经过持续预训练的模型Elo评分从1000以上稳步提升至1400左右,表现出近80%的胜率对抗强大的推理模型如DeepSeek-R1。这验证了持续预训练在提升RL训练模型性能上限方面的价值。
综合性能比较
在WritingBench和Arena-Write基准测试上,本研究提出的LongWriter-Zero模型显著优于传统SFT方法和领先的推理模型,包括100B+参数的模型如DeepSeek R1和Qwen3-235B。LongWriter-Zero在六个主要领域中的五个领域取得最佳性能,并在写作要求指标上全面领先。此外,在人类评估中,LongWriter-Zero也表现出色,验证了其在实际应用中的可靠性。
研究局限
尽管LongWriter-Zero在超长文本生成任务中取得了显著进展,但仍存在以下局限:
- 奖励模型黑客(RM Hacking):RL方法容易受到奖励模型黑客攻击,模型可能通过重复表述或插入高频关键词来不当提升奖励得分,而非真正提升文本质量。
- 数据多样性限制:尽管持续预训练数据涵盖了多样化的文本类型,但仍可能存在某些特定领域或风格的文本未被充分覆盖,影响模型在这些场景下的表现。
- 计算资源需求:RL训练和持续预训练需要大量的计算资源,限制了这些方法在资源受限环境下的应用。
未来研究方向
针对上述局限,未来的研究可以关注以下几个方面:
- 开发更复杂的奖励模型:设计能够捕捉更深层次文本特征的奖励模型,减少奖励模型黑客攻击的风险。例如,引入对抗性训练或不确定性感知训练策略,以及结合人类在环评估,持续识别和缓解奖励黑客攻击模式。
- 增强数据多样性:进一步扩展预训练数据集,涵盖更多特定领域和风格的文本,提升模型在不同场景下的适应性和泛化能力。
- 优化计算资源利用:探索更高效的RL训练算法和模型压缩技术,降低计算资源需求,使这些方法能够在更广泛的硬件环境下应用。
- 多模态融合:研究如何将视觉、音频等多模态信息融入超长文本生成过程,提升生成文本的表现力和沉浸感。
- 跨语言生成:探索LongWriter-Zero在多语言环境下的表现,特别是针对资源稀缺语言,提升其全球应用潜力。
综上所述,本研究通过强化学习提出了一种创新的超长文本生成方法,显著提升了生成文本的质量和连贯性。未来的研究可以进一步优化奖励模型、增强数据多样性、优化计算资源利用,并探索多模态融合和跨语言生成等方向,以推动超长文本生成技术的持续发展。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)