LangChain 框架深入解析
LangChain是一个强大的框架,用于构建基于大型语言模型(LLM)的应用程序。它提供模块化设计、链式调用、上下文记忆等功能,支持与多种数据源和工具的集成。核心组件包括模型封装、提示模板、任务链、智能代理等,适用于智能对话、知识问答、自动化任务等多种场景。LangChain简化了LLM应用的开发流程,提高了开发效率和系统灵活性。
目录
前言
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
Langchain使用理由:
1.数据连接:Langchain 允许你将大型语言模型连接到你自己的数据源,比如数据库、PDF文件或其他文档。这意味着你可以使模型从你的私有数据中提取信息。
2.行动执行:不仅可以提取信息,Langchain 还可以帮助你根据这些信息执行特定操作,如发送邮件。
一、LangChain 框架概述
1. 设计理念与核心思想
LangChain 的设计理念是通过链式结构将大型语言模型(LLM)与外部数据源、工具和计算逻辑相结合,以构建复杂且功能强大的自然语言处理应用。其核心思想包括:
- 模块化设计:将复杂的任务拆分为多个可重用、可组合的模块,使得开发者可以灵活地搭建和扩展应用功能。
- 链式调用:通过定义一系列相互关联的“链”,使数据和处理逻辑能够按照特定的顺序和规则流转,形成清晰的执行路径。
- 上下文记忆:引入记忆机制,允许模型在对话或任务过程中保留和利用先前的信息,提高交互的连贯性和智能性。
- 灵活集成:提供开放的接口和适配层,方便与各种外部工具、API 和数据源进行集成,扩展应用的能力范围。
2. 主要功能与特性
- Chains(链):核心组件,用于串联不同的处理步骤,可以是简单的顺序执行,也可以包含复杂的条件和循环逻辑。
- Memory(记忆):支持短期和长期记忆,允许在任务或会话中存储和检索信息,增强模型的上下文理解能力。
- Prompt Templates(提示模板):提供灵活的模板系统,支持参数化和动态生成,方便构建适合不同场景的模型输入。
- Agents(代理):智能决策模块,能够根据当前状态和目标,动态选择和调用适当的工具或动作来完成任务。
- Tools(工具):可执行的功能单元,封装了具体的操作,如查询数据库、调用 API、执行计算等,供代理和链调用。
- LLMs(大型语言模型)集成:与各种主流的大型语言模型无缝对接,支持 OpenAI、Hugging Face 等平台,方便模型的替换和比较。
- 数据连接器:预置了对常见数据源的支持,如文件系统、数据库、网络请求等,方便数据的获取和存储。
3. 应用场景分析
- 智能对话机器人:利用记忆和链式调用,实现上下文连贯、逻辑清晰的多轮对话,提高用户交互体验。
- 知识问答系统:结合大型语言模型和外部知识库,提供准确、高效的问答服务,适用于客服、教育等领域。
- 自动化任务执行:通过代理和工具的协作,完成如数据处理、报告生成、信息检索等复杂的自动化任务。
- 内容生成与创作:利用提示模板和模型能力,生成文章、摘要、代码等多种形式的内容,辅助创作和生产力提升。
- 数据分析与决策支持:集成数据源和分析工具,提供智能的数据解读和决策建议,应用于商业分析、科学研究等。
- 多语言翻译与处理:支持多语言模型,处理翻译、跨语言信息检索等任务,促进全球化交流和合作。
- 情感分析与意见挖掘:分析文本或语音中的情感倾向和观点,为市场调研、舆情监控提供支持。
- 个性化推荐系统:根据用户历史和偏好,提供定制化的内容或产品推荐,增强用户黏性和满意度。
二、核心组件
1)Compents组件:为LLMs提供接口封装、模板提示和信息检索索引。
2)Chains链:将不同的组件组合起来解决特定的任务,比如在大量文本中查找信息。
3)Agents代理:它们使得LLMs能够与外部环境进行交互,例如通过API请求执行操作。
Langchain核心
1.模型models:包装器允许你连接到大型语言模型,如 GPT-4 或 Hugging Face 也包括GLM提供的模型。
2.Prompt Templates:这些模板让你避免硬编码文本输入。你可以动态地将用户输入插入到模板中,并发送给语言模型。
3.Chains:链允许你将多个组件组合在一起,解决特定的任务,并构建完整的语言模型应用程序。
4.Agents:代理允许语言模型与外部API交互。
5.Embedding 嵌入与向量存储 VectorStore 是数据表示和检索的手段,为模型提供必要的语言理解基础。
6.Indexes:索引帮助你从语言模型中提取相关信息。
三、工作原理
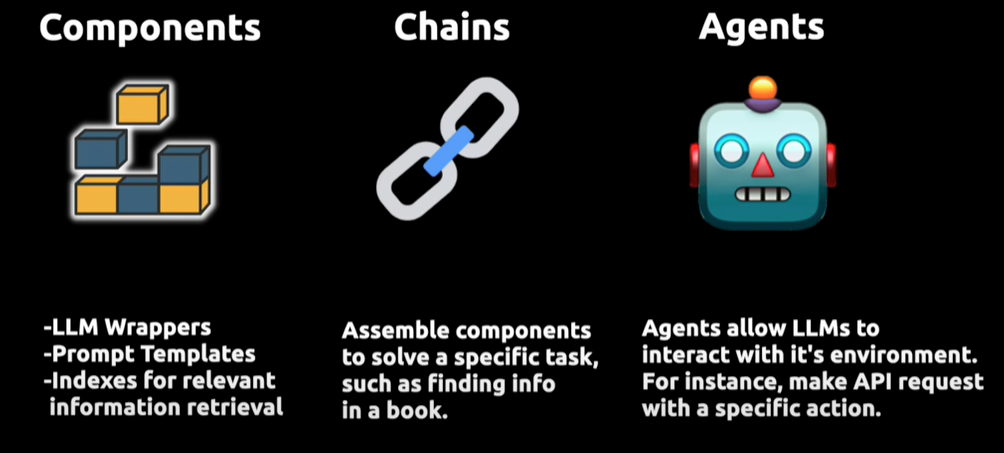
上图展示了Langchain的工作原理,这是一个用于提升大型语言模型(LLMs)功能的框架。
它通过三个核心组件实现增强:
- 首先是 Compents“组件”,为LLMs提供接口封装、模板提示和信息检索索引;
- 其次是 Chains“链”,它将不同的组件组合起来解决特定的任务,比如在大量文本中查找信息;
- 最后是 Agents“代理”,它们使得LLMs能够与外部环境进行交互,例如通过API请求执行操作。
Langchain 的这种结构设计使LLMs不仅能够处理文本,还能够在更广泛的应用环境中进行操作和响应,大大扩展了它们的应用范围和有效性。
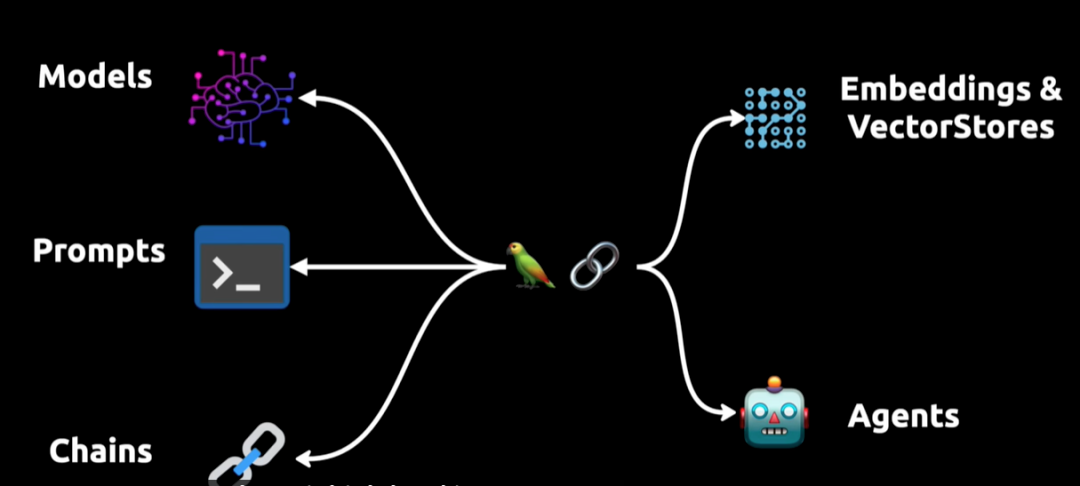
上图展示了一个复杂的语言处理系统,其中包含模型、提示、链、代理和嵌入与向量存储。
- 模型 Models 负责理解和生成语言,提示用于引导模型输出;
- 链条 Chains 代表将多个步骤串联起来完成复杂任务的过程;
- 代理 Agents 则用于让模型与外部环境互动,比如执行API调用。
- Embedding 嵌入与向量存储 VectorStore 是数据表示和检索的手段,为模型提供必要的语言理解基础。
图中的鹦鹉是一个比喻或者象征,表示这个系统的自然语言处理能力,或者可能暗示系统的输出可以像鹦鹉一样“复述”或者是“回应”用户的输入。如此,这整个系统构成了一个高度集成的框架,能够处理高级语言任务并在多种环境下进行动态交互。
四、Langchain安装
pip install langchain
pip install langchain-openai五、LangSmith
1. 简介
LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它可以让您调试、测试、评估和监控基于任何LLM框架构建的链和智能代理,并与LangChain无缝集成,LangChain是使用LLM构建的首选开源框架。
LangSmith是一个用于构建生产级 LLM 应用程序的平台,它提供了调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理的功能,并能与 LangChain 无缝集成。其主要作用包括:
1.调试与测试:通过记录langchain构建的大模型应用的中间过程,开发者可以更好地调整提示词等中间过程,优化模型响应。
2.评估应用效果:langsmith可以量化评估基于大模型的系统的效果,帮助开发者发现潜在问题并进行优化。
3.监控应用性能:实时监控应用程序的运行情况,及时发现异常和错误,确保其稳定性和可靠性。
4.数据管理与分析:对大语言模型此次的运行的输入与输出进行存储和分析,以便开发者更好地理解模型行为和优化应用。
5.团队协作:支持团队成员之间的协作,方便共享和讨论提示模板等。
6.可扩展性与维护性:设计时考虑了应用程序的可扩展性和长期维护,允许开发者构建可成长的系统。
LangSmith是LangChain的一个子产品,是一个大模型应用开发平台。它提供了从原型到生产的全流程工具和服务,帮助开发者构建、测试、评估和监控基于LangChain或其他 LLM 框架的应用程序。
2. 获取方式
登录并且获取LangSmish的API key:https://smith.langchain.com/settings
六、Langchain支持的模型
# 部分举例
#OpenAI
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4")
#Anthropic
pip install -qU langchain-anthropic
import getpass
import os
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
#Google
pip install -qU langchain-google-vertexai
import getpass
import os
os.environ["GOOGLE_API_KEY"] = getpass.getpass()
from langchain_google_vertexai import ChatVertexAI
model = ChatVertexAI(model="gemini-pro")七、案例
1. Langchian实现LLM应用程序
构建一个简单的大型语言模型(LLM)应用程序的快速入门
调用语言模型
使用OutputParsers: 输出解析器
使用PromptTemplate: 提示模板
使用LangSmish追踪你的应用程序
使用LangServe部署你的应用程序pip install "langserve[all]"
import os
from fastapi import FastAPI
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langserve import add_routes
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = 'lsv2_pt_5a857c6236c'
# 调用大语言模型
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
# 2、准备prompt
msg = [
SystemMessage(content='请将以下的内容翻译成意大利语'),
HumanMessage(content='你好,请问你要去哪里?')
]
# result = model.invoke(msg)
# print(result)
# 简单的解析响应数据
# 3、创建返回的数据解析器
parser = StrOutputParser()
# print(parser.invoke(result))
# 定义提示模板
prompt_template = ChatPromptTemplate.from_messages([
('system', '请将下面的内容翻译成{language}'),
('user', "{text}")
])
# 4、得到链
chain = prompt_template | model | parser
# 5、 直接使用chain来调用
# print(chain.invoke(msg))
print(chain.invoke({'language': 'English', 'text': '我下午还有一节课,不能去打球了。'}))
# 把我们的程序部署成服务
# 创建fastAPI的应用
app = FastAPI(title='我的Langchain服务', version='V1.0', description='使用Langchain翻译任何语句的服务器')
add_routes(
app,
chain,
path="/chainDemo",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)2. Langchian构建聊天机器人
这个聊天机器人能够进行对话并记住之前的互动。
需要安装:pip install langchain_community1.Chat History:它允许聊天机器人“记住”过去的互动,并在回应后续问题时考虑它们。
2.流试输出
import os
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langserve import add_routes
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = 'lsv2_pt_5a857c6236c'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
# 定义提示模板
prompt_template = ChatPromptTemplate.from_messages([
('system', '你是一个乐于助人的助手。用{language}尽你所能回答所有问题。'),
MessagesPlaceholder(variable_name='my_msg')
])
# 得到链
chain = prompt_template | model
# 保存聊天的历史记录
store = {} # 所有用户的聊天记录都保存到store。key: sessionId,value: 历史聊天记录对象
# 此函数预期将接收一个session_id并返回一个消息历史记录对象。
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
do_message = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key='my_msg' # 每次聊天时候发送msg的key
)
config = {'configurable': {'session_id': 'zs1234'}} # 给当前会话定义一个sessionId
# 第一轮
resp1 = do_message.invoke(
{
'my_msg': [HumanMessage(content='你好啊! 我是LaoXiao')],
'language': '中文'
},
config=config
)
print(resp1.content)
# 第二轮
resp2 = do_message.invoke(
{
'my_msg': [HumanMessage(content='请问:我的名字是什么?')],
'language': '中文'
},
config=config
)
print(resp2.content)
# 第3轮: 返回的数据是流式的
config = {'configurable': {'session_id': 'lis2323'}} # 给当前会话定义一个sessionId
for resp in do_message.stream({'my_msg': [HumanMessage(content='请给我讲一个笑话?')], 'language': 'English'},
config=config):
# 每一次resp都是一个token
print(resp.content, end='-')总结
随着人工智能领域的迅猛发展,大型语言模型在自然语言处理中的应用变得越来越广泛。然而,如何有效地将这些强大的模型应用于实际场景,并与各种数据源和工具进行无缝集成,成为了开发者面临的重大挑战。传统的开发方式往往需要处理大量的底层逻辑和重复性工作,降低了开发效率。
LangChain 的出现正是为了解决这些问题。通过模块化和链式的设计理念,LangChain 提供了一个高度可扩展和灵活的框架,使得开发者可以专注于应用的核心功能,而无需过多关注底层实现。这不仅提高了开发效率,还为快速迭代和创新提供了有力支持。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 49
49 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)