AI-深度学习-循环神经网络RNN
本文介绍了循环神经网络(RNN)的核心概念与应用。RNN是一种专门处理序列数据的神经网络,通过循环连接和隐藏状态机制实现对时序依赖关系的建模。相比传统神经网络,RNN能处理变长输入/输出,并捕捉数据中的顺序信息。文章详细阐述了RNN的核心思想、解决的问题动机,以及其实现方式与关键结构。
目的
为避免一学就会、一用就废,这里做下笔记
说明
本文内容紧承前文-卷积神经网络CNN,欲渐进,请循序
一、是什么?—— 定义与核心思想
循环神经网络 是一种专门设计用于处理序列数据的人工神经网络。它的核心特点是网络中存在 “循环连接”,使信息能够跨时间步持久化
核心思想:拥有“记忆”的神经网络
- 传统神经网络(如CNN、全连接网络):假设所有输入(和输出)是相互独立的。处理“我今天很开心”和“开心今天我”会被视为类似的数据。
- 循环神经网络:承认并利用数据点的顺序依赖关系。它认为“我今天很开心”和“开心今天我”的含义天差地别,因为词序至关重要。
关键机制:隐藏状态
RNN引入了一个核心概念——隐藏状态。您可以把它理解成网络的“短期记忆”或“上下文摘要”。
- 在每个时间步,RNN不仅接收当前的外部输入(如一个词),还会接收来自上一个时间步的隐藏状态。
- 它综合这两者,产生当前时间步的输出,并更新为新的隐藏状态,传递给下一步。
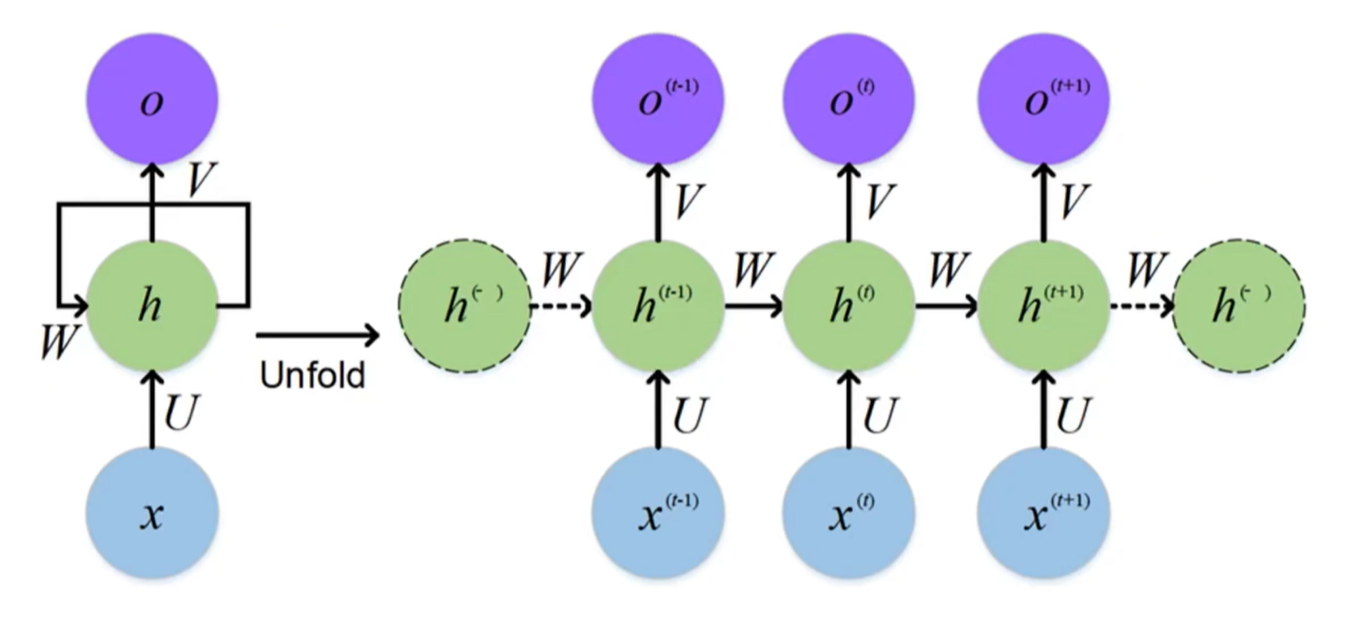
公式表达(简化):
h t = f ( W ∗ h t − 1 + U ∗ x t ) h_t = f(W * h_{t-1} + U * x_t) ht=f(W∗ht−1+U∗xt)
o t = g ( V ∗ h t ) o_t = g(V * h_t) ot=g(V∗ht)
- h t h_t ht:当前时刻的隐藏状态(记忆),本质是一个多维向量
- h t − 1 h_{t-1} ht−1:上一时刻的隐藏状态, h 0 h_0 h0一般设置为全零向量
- x t x_t xt:当前时刻的输入,如china
- o t o_t ot:当前时刻的输出,如中国
- f 、 g f、g f、g:激活函数
- U 、 V 、 W U、V、W U、V、W:核心权重矩阵,属于可训练参数。
- U充当翻译官,把输入转化为神经网络可理解的内部语言
- W充当记忆管理员,管理新旧记忆的融合
- V充当发言人,将内部记忆转化为输出
隐藏状态的额外说明
隐藏状态是一个多维向量,向量的维度数(hidden_size)是一个超参数。
不同任务时,该超参数的典型值:
| 任务类型 | 典型hidden_size | 说明 |
|---|---|---|
| 字符级语言模型 | 128-512 | 字符数量有限(~100),不需要太大 |
| 词级文本分类 | 256-512 | 需要记住句子上下文 |
| 机器翻译 | 512-1024 | 复杂任务,需要强大记忆 |
| 语音识别 | 1024-2048 | 音频特征复杂,序列长 |
因W参数数量随 hidden_size 平方增长,因此设置该值时,应在模型效果和计算量之间权衡选择。
二、为什么?—— 解决的问题与动机
提出RNN是为了解决传统神经网络在序列任务上的根本性缺陷。
1. 处理变长输入/输出
- 传统网络:输入和输出的维度必须固定。无法直接处理一句可长可短的话、一段时长不一的音频。
- RNN:通过循环机制,理论上可以处理任意长度的序列。
2. 建模时间/顺序依赖
许多任务的核心信息蕴含在顺序中:
- 自然语言:“猫追老鼠” ≠ “老鼠追猫”
- 股票价格:今天的价格高度依赖于过去几天的趋势
- 视频理解:每一帧的含义需要结合前后帧来理解
RNN的“记忆”(隐藏状态)就是为了捕获这种依赖关系而设计的。
3. 参数共享
- 在展开图中,所有时间步共享同一组参数(上图中的W, U, V)。
- 这意味着无论序列多长,模型大小不变,并且能将在序列某一位置学到的模式,应用到所有其他位置,大大提升了效率。
三、怎么办?—— 实现、演变与关键结构
基础RNN的实现与局限
虽然基础RNN思想巧妙,但它存在多个缺陷:
- 基础性能问题:无法并行,性能低
- 致命效果问题:长程依赖问题(梯度消失/爆炸):
- 在反向传播时,梯度需要跨越许多时间步进行连乘。
- 这导致网络难以学习到遥远时间步之间的依赖关系(例如,一段话开头的“他”很难影响结尾的动词“是”)。
核心演进:长短时记忆网络与门控循环单元
为了解决长程依赖问题,研究者发明了更复杂的RNN变体,主要通过 “门控机制” 来精细化控制信息的流动。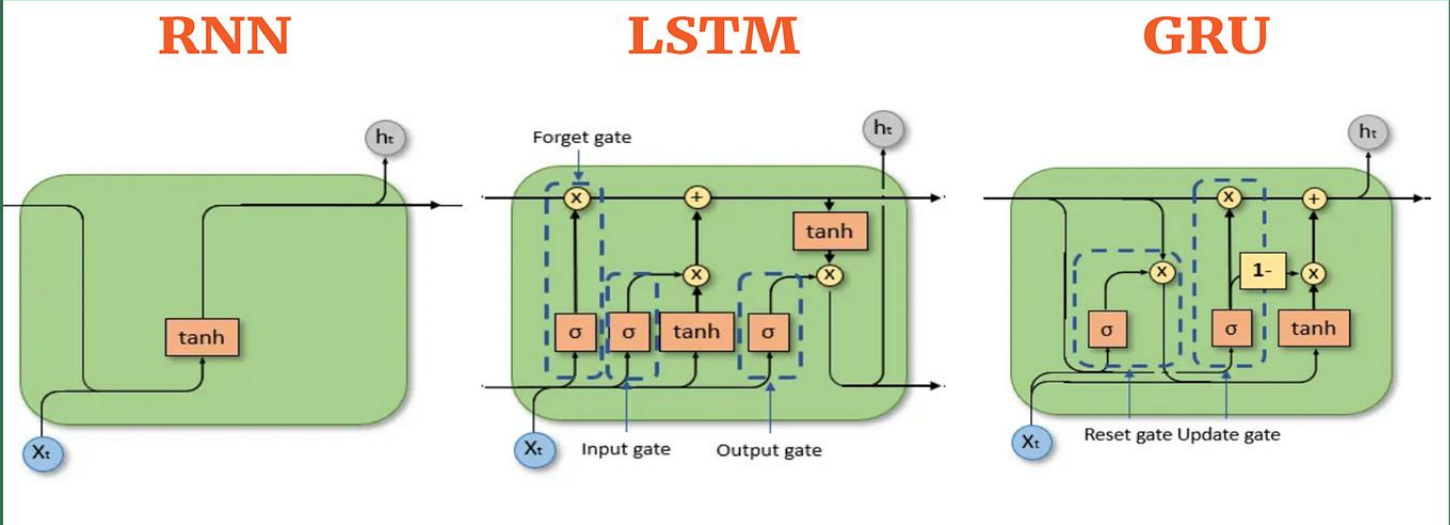
1. LSTM(长短时记忆网络)
LSTM通过引入三个“门”和一个独立的“细胞状态”来实现长期记忆。
- 遗忘门:决定从细胞状态中丢弃什么信息。
- 输入门:决定哪些新信息存入细胞状态。
- 输出门:基于细胞状态,决定输出什么隐藏状态。
- 细胞状态:像一条传送带,贯穿整个时间线,允许信息无损地流动,是长期记忆的关键。
2. GRU(门控循环单元)
GRU是LSTM的简化版,它将遗忘门和输入门合并为一个 “更新门”,并混合了细胞状态和隐藏状态,结构更简洁,计算效率更高,在很多任务上与LSTM表现相当。
下图对比了基础RNN与LSTM/GRU在处理长序列依赖时的核心差异:
双向RNN与深层RNN
- 双向RNN:同时运行前向和后向两个RNN,然后将它们的隐藏状态结合起来。这使得每个时间步的输出都能同时包含过去和未来的上下文信息,在机器翻译、语音识别中非常有效。
- 深层RNN:将多个RNN层堆叠起来,低层捕捉低级特征(如音节),高层捕捉高级特征(如语义),以增强模型的表达能力。
RNN在时间维度上的不同应用模式
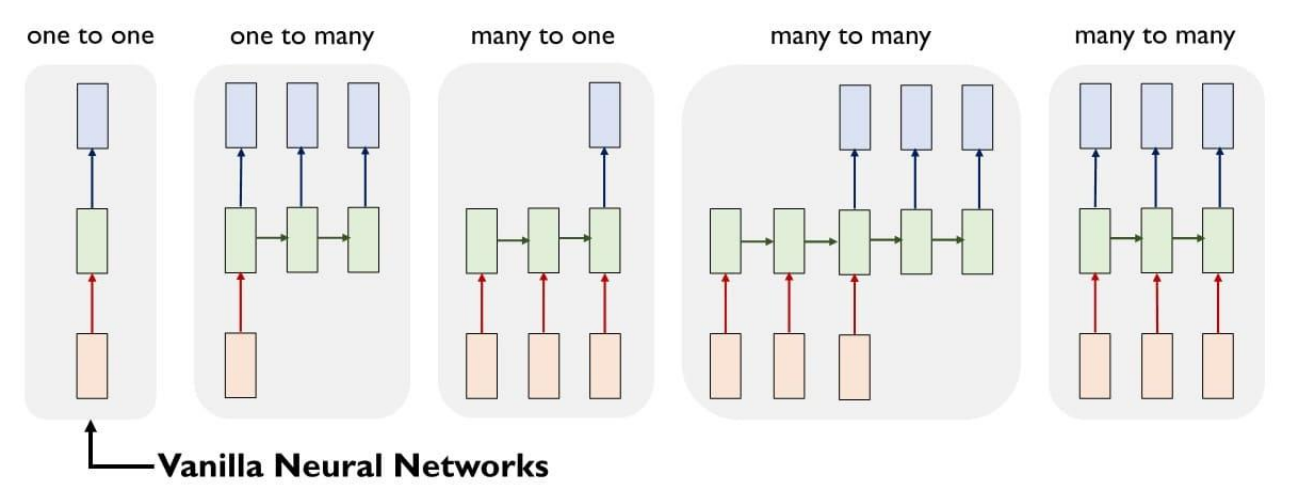
one to one
说明:每个时间步都有输入,每个时间步都产生输出
示例:单词翻译
one to many
说明:只在第一个时间步有输入,然后在多个时间步产生输出序列
示例:看图说话、命题创作等
many to one
说明:在多个时间步接收输入序列,只在最后一个时间步产生一个输出
示例:情感分析、文本分类等
many to many(非同步)
说明:在多个时间步接收输入序列,且在多个时间步产生输出序列,且输出滞后于输入(编码器-解码器)
示例:智能问答、文章摘要等
many to many(同步)
说明:在多个时间步接收输入序列,且在多个时间步产生输出序列,且输出和输入在时间上对齐
示例:实时翻译、实时语音识别等
现代实现与应用
如今,原始的RNN已较少直接使用,LSTM和GRU成为实际标准。它们在以下领域有广泛应用:
- 自然语言处理:机器翻译、文本生成、情感分析
- 语音识别:将音频序列转录为文本
- 时间序列预测:股价预测、气象预测
- 视频分析:行为识别、视频描述生成
注意:虽然Transformer架构在NLP领域很大程度上取代了RNN,但在处理流式数据(如实时语音)、计算资源受限或需要强时序建模的场景中,RNN及其变体因其循环的序列本质,仍然具有重要价值。
总结
- 是什么:一种通过循环连接和隐藏状态来建模序列依赖关系的神经网络,具备“记忆”能力。
- 为什么:为了处理变长序列、捕捉顺序依赖,并实现参数共享。
- 怎么办:基础RNN存在长程依赖问题,通过引入门控机制的LSTM和GRU来解决,并发展出双向和深层结构以增强性能,广泛应用于各类序列任务。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)