【强化学习】第八章:基于策略的强化学习、REINFORCE
本章节讲基于策略的强化学习,是强化学习领域中的一个独立分支,也是强化学习领域的重要研究方向,目前是OpenAI和加州大学伯克利分校(UC Berkeley)在研究。
【强化学习】第八章:基于策略的强化学习、REINFORCE
一、本章节在整个强化学习体系中的位置
1、强化学习的三种范式
强化学习分三种范式:基于价值的强化学习(Value-based)、基于策略的强化学习(Policy-based)、基于AC框架(Actor-Critic方法)的强化学习。其中基于AC框架的强化学习是前两种的大一统范式。这三种范式可以说是强化学习领域的三个独立技术分支。 基于价值的强化学习(包括状态价值和动作价值)就是我们常说的传统强化学习,本章之前所有章节的所有算法都属于这一分支。本章节讲基于策略的强化学习,是强化学习领域中的一个独立分支,也是强化学习领域的重要研究方向,目前是OpenAI和加州大学伯克利分校(UC Berkeley)在研究。OpenAI侧重于实用化、稳定化的算法设计,而伯克利则更注重理论创新与泛化能力的提升。
基于价值的强化学习(包括状态价值和动作价值)就是我们常说的传统强化学习,本章之前所有章节的所有算法都属于这一分支。本章节讲基于策略的强化学习,是强化学习领域中的一个独立分支,也是强化学习领域的重要研究方向,目前是OpenAI和加州大学伯克利分校(UC Berkeley)在研究。OpenAI侧重于实用化、稳定化的算法设计,而伯克利则更注重理论创新与泛化能力的提升。
2、强化学习三种范式之间的异同点
(1)基于价值的强化学习核心是学习价值函数(也叫价值值),通过价值值来指导行动。
比如说你现在面前有两条路,A路和B路,你是走A还是走B?那就先计算一下走A的价值值,A的价值值就是走A路的未来好处分值,假如我算出是80分。同理假如我算出走B路的未来好处是90分。那我就根据这个价值值选B路走。
所以这一分支的核心在于计算价值值,就是计算你在当下状态下,所有行动的未来好处分,按未来好处最大的方向走。也所以我们之前说的计算价值值,其实就是策略评估的意思。也所以这一分支的决策逻辑就是:在当前状态下,选那些能让你进入 “更高分状态” 的行动。
所以value-based强化学习的具体做法是:先计算一个策略的action value,这就是策略评估policy evaluation-->在策略评估的基础上,我去选择更好的策略-->然后用这个更好的策略再去采样->计算action value评估策略->提升策略-->用新策略继续采样...,如此不断迭代循环,直到找到一个最优的策略。这个过程是以value为核心,value发挥了非常重要的作用。
(2)基于策略的强化学习核心是直接学“行动规则”。
比如通过大量练习,我们总结出:“看到A怪物就后退,看到B道具就捡,在C路口就往右拐”,这套规则就叫 “策略”。哪怕有时候按这套规则做,短期看可能吃亏(比如绕了点路),但它还是会坚持按规则来,因为这套规则是长期试错后“大概率能赢”的总结。所以这一分支的核心是直接学习 “策略函数”,通过策略函数直接输出动作。
所以policy-based强化学习是直接建立一个关于策略的目标函数,通过优化这个目标函数就可以直接得到最优策略。
(3)Actor-Critic方法是把policy gradient和value function approximation两种方法结合起来。我们下一个篇章讲AC方法。
3、基于策略的强化学习的优缺点
虽然Value Based强化学习,思路直观,通过价值函数直接判断动作的优劣,但它不是所有场景都通吃的方法,所以我们还是得学基于策略的强化学习。
(1)Value Based无法计算最优的随机策略,但Policy Based可以。 上图的两个例子,最优的策略就是一个随机策略,所有确定性策略都不是最优的。像这种场景value based方法就无法求解,因为value based方法只能求最优的确定性策略。即使还有ε-greedy中的探索,但毕竟ε是一个人为规定的小概率,这和真正的随机策略是有本质不同的。
上图的两个例子,最优的策略就是一个随机策略,所有确定性策略都不是最优的。像这种场景value based方法就无法求解,因为value based方法只能求最优的确定性策略。即使还有ε-greedy中的探索,但毕竟ε是一个人为规定的小概率,这和真正的随机策略是有本质不同的。
(2)Value Based难以处理连续动作空间,但Policy Based可以。
Value Based强化学习在离散动作空间中表现稳定,因为选取最大价值动作只需要排个序,取最大值即可,非常简单。但是在连续动作空间的场景中,Value Based强化学习“找最大价值动作”需要复杂的优化,比如数值搜索,非常消耗算力。
而Policy Based强化学习天然就适合连续动作空间,因为Policy Based强化学习是直接优化策略本身,而不是借助价值函数来找,所以它可以直接输出随机策略的概率分布,从概率分布中采样动作即可,这样的操作就天然的兼顾了“探索与利用”,而且还避免了价值函数估计的中间步骤,使得它在某些复杂环境中具有独特的优势。
二、Policy Based强化学习基本思想
1、本章的突破点
学完本章节,强化学习方法就从下面两个方面改进了:
一是,from value-based methods to policy-based methods。从基于价值的强化学习方法升级到基于策略的方法。
二是,from value function approximation to policy function approximation。从价值函数逼近的方法到策略函数逼近的方法。
2、Policy Based强化学习的思路 (1)这个可以类比深度强化学习。在深度强化学习中,我们是创建一个价值逼近函数(value function approximation)-->然后构建关于价值逼近函数的目标函数-->计算目标函数的梯度-->优化目标函数,如此循环,直到得到最优的价值逼近函数。有了价值逼近函数,就可以进行策略评估、策略提升了。
(1)这个可以类比深度强化学习。在深度强化学习中,我们是创建一个价值逼近函数(value function approximation)-->然后构建关于价值逼近函数的目标函数-->计算目标函数的梯度-->优化目标函数,如此循环,直到得到最优的价值逼近函数。有了价值逼近函数,就可以进行策略评估、策略提升了。
(2)Policy Based强化学习也是同理,但它是直接学习一个最优的“策略逼近函数”,通过最优的策略逼近函数直接输出最优策略。具体也是先创建一个策略逼近函数(policy function approximation)-->构建关于策略函数的目标函数-->计算目标函数的梯度(也叫策略梯度policy gradient)-->然后策略梯度去优化目标函数,得到最优的策略函数(最优的策略逼近函数)。有了最优的策略函数,就可以直接输出最优策略了。
(3)虽然Policy Based强化学习的基本思想极为简单、直观,但是在构建策略逼近函数、构建目标函数、计算梯度、优化目标函数这几个环节都非常非常的复杂,还有一些技巧,所以下面针对这几个环节用大标题展开详细讲解。
三、构建策略逼近函数
前面第三章 https://blog.csdn.net/friday1203/article/details/155533020?spm=1001.2014.3001.5501 解释“策略”这个概念时说过:
1、智能体在某个状态下做出某个动作,是由智能体的策略函数(Policy)来决定的。也就是策略是指导action的。所有action都是在某个policy下做出的。不同的策略会得到不同的Trajectory(path/trace)。
2、在强化学习中,智能体的目标是学习一个“策略”(Policy),即从“状态”到“动作”的映射,使长期累积奖励最大化。
3、策略分确定性策略和随机策略。之前的强化学习学的最优策略都是确定性策略。本篇学的最优策略是最优随机策略。
4、策略逼近函数的形式:从表格型的随机策略到策略逼近函数、从离散动作空间到连续动作空间 从表格型的随机策略到策略逼近函数的过程和前面的value function approximation的思想一模一样。表格形式的随机策略用数学表示是π(a|s),现在我们想用一个函数来逼近表格,具体说就是想用一个神经网络来逼近表格,那么随机策略的数学表示就变成了π(a|s,θ) ,其中θ是神经网络的参数。
从表格型的随机策略到策略逼近函数的过程和前面的value function approximation的思想一模一样。表格形式的随机策略用数学表示是π(a|s),现在我们想用一个函数来逼近表格,具体说就是想用一个神经网络来逼近表格,那么随机策略的数学表示就变成了π(a|s,θ) ,其中θ是神经网络的参数。
(1)如果你的实际场景中是有限的动作空间,比如上图的表格策略就是格子游戏的策略函数,这个游戏的动作空间就是有限的,只有不动、上、下、左、右这5个动作,那么神经网络(也就是策略逼近函数)的输出有5个神经元 + softmax层,输出5个类概率值即可作为逼近函数。这5个类概率值就是输入的状态s对应的随机策略的随机概率值。网络输出层的架构设计就是上面的中间图形。
(2)如果你的实际场景中是连续动作空间,比如自动驾驶中,需要决策车辆的速度、加速度、油门刹车的角度等,在游戏AI中,需要决策角色的移动和攻击的方向、距离、预判敌人的位置等。这种场景下动作空间就是一个连续性的,我们只需要输出随机策略的概率分布,从概率分布中采样动作即可。此时神经网络的输出层就得像右图的设计架构。
5、小结:
策略逼近函数的数学形式是π(a|s,θ)(或者πθ(a|s)、πθ(a,s)),从架构上看就是一个浅层的神经网络,输入是s向量,输出是s下的所有动作的类概率值或者是某种分布的参数。
6、说明:
(1)由于策略逼近函数直接拟合的是策略,所以以后我们给策略逼近函数直接叫策略函数 in short。
(2)以后我们再说函数逼近,这个函数都指神经网络。因为随着深度学习的突飞猛进,神经网络在线性、非线性拟合方面都表现出了碾压式的优势,所以现在大家基本都是用神经网络来拟合的。
有了策略的逼近函数,下面就是构建关于逼近函数的目标函数。
四、构建目标函数
目标函数是牵引逼近网络的参数θ向"好"的方向更新的函数。我们之前常用的目标函数比如均方误差、交叉熵损失、KL散度等,在这里都无法行得通,因为真实的策略我们是不知道的,没法用它来构建目标函数!
但是强化学习中的价值值(状态价值值、动作价值值)以及奖励都是和策略密切相关的,或者说价值值和奖励本身就是关于策略的函数!这就给我们提供了一个思路,是不是可以用价值值或者奖励来构建目标函数? 系统中的状态是多个的,所以每个状态都有价值值,到达每个状态也有奖励值,那我们以哪个状态的的价值值、或者到达哪个状态的奖励值,为标准去构建目标函数呢?很自然的想法就是:
如果用价值值,那就用所有状态的平均值(v̄π)。
如果用系统奖励值,那就用所有状态的单步平均奖励(r̄π)。
下面我们详细分析一下平均状态价值值和单步平均奖励:
1、平均价值(v̄π) (1)上图三个红框中的式子都是v̄π的表示形式。
(1)上图三个红框中的式子都是v̄π的表示形式。
(2)上图中d(s)表示所有状态被访问的概率。我们求v̄π时就以d(s)为权重进行加权平均的。
因为在有的场景中d(s)与策略π无关,在有的场景中d(s)和策略π有关。
如果d(s)和策略π无关:
如果d(s)和策略π有关:
那么一旦策略π确定下来,d(s)也就随之确定了,而且d(s)是stationary distribution:
关于d(s)的详细性质在 https://blog.csdn.net/friday1203/article/details/157395866?spm=1001.2014.3001.5501 这篇博文中有详细描述和案例展示。


2、单步平均奖励(r̄π)
上图的r̄π就是单步MDPs的平均即时奖励。r̄π的计算公式不难理解,这里我就不详细展开了。但是要重点说明的是,它表明了策略π和r̄π也是一一对应的。或者说“策略”到“单步平均即时奖励”之间的映射是单向的、确定的、一一对应的。
3、v̄π 和 r̄π 的关系
上面1、2都是从v̄π、r̄π的定义出发,解释了二者的含义,并且从直觉上描述了,二者都是策略逼近函数的函数,所以都可以作为目标函数,然后梯度上升法最大化v̄π、r̄π,就可以得到最优的随机策略。本小标题从数学上再深入推导一下v̄π和r̄π之间的关系: 至此,我们可以得到下面这些结论:
至此,我们可以得到下面这些结论: (1)策略的数学表示是π(a|s,θ)。策略是θ的函数。v̄π、r̄π又是策略的函数,所以v̄π、r̄π也是θ的函数。所以不同的θ就会得到不同的v̄π、r̄π。那就会存在一个最优的θ,可以最大化v̄π、r̄π。
(1)策略的数学表示是π(a|s,θ)。策略是θ的函数。v̄π、r̄π又是策略的函数,所以v̄π、r̄π也是θ的函数。所以不同的θ就会得到不同的v̄π、r̄π。那就会存在一个最优的θ,可以最大化v̄π、r̄π。
(2)r̄π是系统的即时奖励,是short-sighted的。而v̄π是所有回报的折扣奖励,是long-sighted的。二者是有等价关系的,具体就是上图红框中的关系。所以只要我们对v̄π和r̄π其中任意一个做优化时,另外一个也达到了极值。
五、求策略梯度
既然v̄π、r̄π都是策略的函数,那我们优化v̄π、r̄π就可以得到最优的策略函数了。但是优化v̄π、r̄π的第一步就是求出策略梯度,有了梯度值才能梯度上升法更新策略函数的参数θ。
1、推导策略梯度公式 上图红框中的公式就是最基本、最本原的策略梯度公式。此后各种算法都是基于这个公式的继续推导。
上图红框中的公式就是最基本、最本原的策略梯度公式。此后各种算法都是基于这个公式的继续推导。
基于策略的强化学习处理的都是无模型的复杂场景,所以真实的d(s)、qπ(s,a),我们是很难得到的。也就是上面的公式是很难被计算出来的。
在深度学习中,求梯度也是通过样本数据求的。所以求梯度这件事情一定一定要先考虑你手上都是些什么样本数据。正可谓巧妇难为无米之炊,你的数据决定了模型是否可被顺利训练。
在强化学习中,我们一般都是根据策略π实际打出一些trajectory片段,或者通过拿到一些别人打的trajectory,而且也不知道别人是在什么策略下打的轨迹。当我们自己打trajectory时,我们也不会打到无穷步,直到逼近一个真正的d(s),如果是别人的数据就更不知道d(s)了。就是说数据非常有限,仅仅是一些不知道策略的trajectory片段,我们希望通过这仅有的数据优化模型。
2、既然上图的策略梯度公式很难计算出真实的梯度值的,那我们要对上面的公式继续推导: 期望形式的策略梯度(上图绿框)就可以用采样来近似期望(上图蓝框)。或者说蓝框中的策略梯度是可以通过样本数据计算而得的。
期望形式的策略梯度(上图绿框)就可以用采样来近似期望(上图蓝框)。或者说蓝框中的策略梯度是可以通过样本数据计算而得的。
上图中把"策略的梯度"变形成"策略的对数的梯度"是为了去掉内层的累加符号Σ。如此一来:
(1)第一个累加符号Σ就可以写成S~d(s)分布,既然服从一个分布,那就可以写成期望的形式。
(2)第二个累加符号Σ就可以写成A~π(θ)分布,既然服从一个分布,也就可以写成期望的形式。
(3)为什么要把两个Σ改写成两个分布呢?
因为我们要用样本来计算梯度的,我们的样本就是在策略π下的trajectroy:s0,a0,r1,s1,a1,r2,s2,a2,r3,,,,,,这个trajectroy是在策略π下生成的,所以这里的所有s都服从d(s)分布、这里的所有a也是策略π下的action。而且我们还可以根据这些trajectory求q(s,a),如此我们就可以用样本来极大似然估计期望、计算梯度了。
也所以这个算法是在轨的算法。根据策略π0下的所有trajectroy更新一轮梯度后,要用新策略函数的策略π1去实实在在再打出一些trajectory,再用这些新trajectory继续更新梯度,,,如此循环直到策略函数收敛。所以是在轨的算法。
3、这就是stochastic gradient descent或者是ascent的基本思路,下面总结一下: (1)策略函数的输出层一定一定要加softmax层!!!其他非线性变换层都不可以!!!
(1)策略函数的输出层一定一定要加softmax层!!!其他非线性变换层都不可以!!!
(2)上图蓝框中的梯度计算公式仅仅针对策略函数的输出是有限动作的场景。如果策略函数输出的是概率分布,然后按照概率采样动作,那策略梯度的计算方法就会稍稍不一样,后面我会另开一个篇章专门讲随机高斯策略,解决连续动作空间的场景。
六、策略优化1:REINFORCE算法
从前面的策略梯度公式我们可以看出,策略梯度是由两部分组成的:一部分是求策略函数的导数,另一部是求q(s,a)。
而策略函数是分可微分的函数和不可微分的函数。比如神经网络就是可微分的。
而求q(s,a)的方法也有很多,我们之前学过MC学习和TD学习,都是可以求q(s,a)的。
所以策略优化就分:可导的策略函数+MC、不可导的策略函数+MC、可导的策略函数+TD、不可导的策略函数+TD,四种情况。
本部分讲可导的策略函数+MC学习q函数,也就是REINFORCE算法。下一个大标题讲不可导的策略函数的梯度计算。至于策略函数+TD算法,我们会再下一个篇章AC框架中讲解。
1、什么是REINFORCE算法?
REINFORCE算法的策略梯度计算过程就是上面大标题五的计算结果。REINFORCE算法的策略函数使用的是神经网络,所以策略函数是可微的,当下pytorch可以轻松实现。REINFORCE在求q(s,a)用的是MC学习: REINFORCE是用蒙特卡洛方法估计q(s,a)的,所以REINFORCE也叫蒙特卡洛策略梯度。我们把策略梯度带到梯度上升算法中去优化梯度函数,就是REFORCE算法。
REINFORCE是用蒙特卡洛方法估计q(s,a)的,所以REINFORCE也叫蒙特卡洛策略梯度。我们把策略梯度带到梯度上升算法中去优化梯度函数,就是REFORCE算法。
2、蒙特卡洛方法是如何估计q(s,a)的?
用蒙特卡洛方法估计q(s,a)叫蒙特卡洛学习(MC学习)。关于MC学习在博客 https://blog.csdn.net/friday1203/article/details/156023792?spm=1001.2014.3001.5501 中有所有细节的详细讲解,博客中举的例子是MC方法学习状态价值,MC方法学习动作价值也是同理,就是把所有的(s,a)对儿看成学习目标,学习所有(s,a)对儿的价值即可。
3、MC学习的采样要求 小结:REINFORCE算法就是直接基于蒙特卡洛采样来估计策略梯度,并通过梯度上升的方法来更新策略参数。
小结:REINFORCE算法就是直接基于蒙特卡洛采样来估计策略梯度,并通过梯度上升的方法来更新策略参数。
4、REINFORCE的伪代码 上述代码是按照策略π,采样多条episode,用加入了因果时序关系的MC方法来估计动作价值的算法。
上述代码是按照策略π,采样多条episode,用加入了因果时序关系的MC方法来估计动作价值的算法。
所谓MC学习,就是在计算q(s',a')时用的数据样本都是一条条完整的episodes。也就是直到游戏结束的一条条轨迹。这样才能求(s,a)对儿的价值。
而所谓的因果时序就是,比如我计算q(s',a')时,不用first-visit、也不用every-visit,而是只用从结束状态到离结束状态最近的s' 这段轨迹计算q(s',a')。意思就是之前的所有的s'都是已经过去的既定事实,不应该参与价值计算,就是我只考虑(s,a)之后的序列的价值,之前的序列不参与计算。这样一定程度上可以减轻策略梯度方差过大的现象,使得训练过程波动不至于过大。
算法具体详情可参考:
Williams(1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning: introduces REINFORCE algorithm
七、策略优化2:策略函数不可导时的梯度计算
本部分再补充一下策略函数无法求导的情况。下面介绍2种优化方法:
1、交叉熵法(CEM) 当然上面的第1步,你不一定非得采用正态分布,你也可以用均匀分布,或者其他都可以。
当然上面的第1步,你不一定非得采用正态分布,你也可以用均匀分布,或者其他都可以。
2、有限差分近似梯度(有限差分法)
八、从数学角度,再次理解策略梯度
本篇比较难学,其实就是非常多的数学公式在绕来绕去,你看别的文章,各种数学表示形式、各种脚标,各种不说前因后果,上来就是一堆数学推导。本部分是看懂数学推导后的,对数学推导的通俗说明。当你知道它到底是想干什么时,理解数学公式也就会轻松了。
基于策略的强化学习,其原理和框架都极其简单和通俗,不难理解。但其优化过程非常难,难就是因为它本质上就是一个数学问题,是数学上的优化问题,所以涉及很多数学公式,大家一看就知难而退了。本小标题从一个提纲挈领的角度去说明这些数学公式都是在干什么?为什么要这么干?好处是什么?为下一篇AC框架打一个基础。
1、从反向传播求梯度的角度给大家梳理一下,为什么强化学习的训练过程和深度学习的训练过程不一样?
(1)从上面的公式中也可以看出来,REINFORCE其实就是在更新神经网络,只不过它不是显示的、像深度学习中的那样,有显示的损失函数,通过损失函数最小化来更新网络参数。因为我之前的深度学习都是有监督的深度学习,也就是所有的训练样本都是有标签的,或者说是有标答的。我们通过标答构建的损失函数(目标函数)是可见的、显示的、易于理解的。
从数学角度看就是,目标函数是可以写出完整的表达式的-->完整的表达式就意味着:从神经网络的输出到目标函数的loss,是一个连续的函数过程-->是一个连续的函数过程就意味着可以用链式法则丝滑求导。
链式法则求导的过程是:偏(loss)/偏(神经网络的输出结果) x 偏(神经网络的输出结果)/偏(神经网络的最后一个隐藏层的结果) x 偏(神经网络的最后一个隐藏层的结果)/偏(神经网络倒数第二个隐藏层的结果) x 偏(神经网络倒数第二个隐藏层的结果)/偏(神经网络倒数第三个隐藏层的结果) x ... x 偏(神经网络正数第1个隐藏层的结果)/偏(神经网络的输入层)
可见,链式法则的求导过程是从后往前,一个个环节单独求出,然后再连乘,才能求出从输入到loss的梯度。有了“从输入到loss的梯度”,那最小化loss,就梯度下降法,通过梯度更新网络参数即可。
(2)而无模型的强化学习,我们的训练样本是没有标答的!我们的目标函数v̄π、r̄π是需要从训练样本中大量抽样、通过大数定律去逼近的。所以目标函数v̄π、r̄π是隐式的、不可见、估计的、猜测的、难以理解的。
所以从数学角度看就是,从神经网络的输出到目标函数v̄π、r̄π,这个过程不是一个连续的函数过程,而是一个大数定理的过程,就是是一个需要通过大量试验逼近的过程。那如果我们从v̄π、r̄π往后链式法则求梯度时,第一步就卡壳了:偏(J(θ))/偏(神经网络的输出结果)这一步就卡住了!所以为了求这一步,我们一般是先单独把这一步先用其他方法算出,所以针对这个环节的梯度求法,就衍生出不同的算法。其中REINFORCE算法就是最早、最简单的一种方法。只要这步的导数有了,后面从神经网络的输出到输入的各个环节都是可导的,如此以来从J(θ)到神经网络的输入整个链条的导数就都有了,从后往前导数连乘就是梯度了。我们想最大化J(θ),用梯度上升法更新网络参数即可。
2、REINFORCE是如何求偏(J(θ))/偏(神经网络的输出结果) 这一步的?
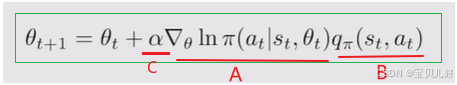
策略梯度是由C、A、B三部分组成的。其中:
C是梯度上升法中步长系数,是一个人为指定的超参数,和深度学习中梯度上升法中步长的含义一模一样。所以这部分可以看成一个常量,对策略梯度的影响没啥可讨论的。
A部分是神经网络的输出结果的自然对数,这部分的各个环节都是连续可导可微的。一旦神经网络的参数初始化完毕,就可以顺利正向传播,以及从ln开始反向传播求导。所以这部分只与深度网络有关,和其他无关!
B部分就非常奇特了,也是理解策略梯度的最关键的部分。B中q(s,a)是(s,a)对儿的动作价值。这个动作价值却是需要从样本中求得的,而且对样本还是有要求的,要求是A部分中神经网络输出的策略下的样本数据。所以从这个角度说,REINFORCE算法是一个在轨算法。
也所以,我们是先根据神经网络的输出策略π0,在π0下去收集trajectory样本序列。然后计算这些trajectory样本序列中的q(s,a),最后ABC三部分连乘作为梯度来更新神经网络的参数。这便是REINFORCE训练模型的第一轮迭代过程,如此迭代多轮,直到策略最优,也就是v̄π或者r̄π达到最大。
在上面的每轮迭代过程中:当某个q(s',a')较大时,意思就是在s'下做a'动作的未来好处较大,那我们就希望神经网络在输入s'时,输出的π(s',a')(也可以写成p(s',a'))的概率就越大,这样就意味着我们提升了策略。那如何能让网络在输入s'时,输出更大的π(s',a')呢?自然是沿着函数梯度的方向走了。从π(s',a')到s'都是丝滑可导的,所以梯度的大小和方向都是可以用链式法则轻松求出的。所以此时我们把BC两部分看出一部分,其中C又是一个人为设置的常数,那B就是可以看成是步长了。当q(s',a')较大时,就意味着网络朝输出更大的π(s',a')的方向迈出了更大的步伐。那下一轮迭代需要收集样本数据时,也会更多的收集(s',a'),神经网络下次再被喂入s'时,也会输出更大的p(s',a')。如此我们就完美的优化了策略,而且完美的进行了利用。
同理,如果某个q(s',a')较小时,那就意味神经网络朝着输出更小的π(s',a')的方向进行迭代,下次神经网络再被喂入s'就会输出更小的p(s',a')。这正是我们想要神经网络迭代的方向!
但是从另外一个层面讲:如果q(s',a')极小时,网络的梯度就不再遵守上面的逻辑,因为此时A部分会被无限放大。因为A是lnx,如果x趋向0,那lnx就趋向无限大。所以此时梯度的大小就不再是由B部分起主导作用了,而是由A部分决定了,此时网络梯度反而会朝输出更大的p(s',a')方向迭代,于是下一轮迭代需要收集的样本数据时,收集(s',a')的概率反而增大了,也就是自动开始探索了!
小结:
REINFORCE是从样本数据中估计的偏(J(θ))/偏(神经网络的输出结果)部分的导数的,而且是把估计的结果看成步长来调节梯度的大小和方向的。如果(s,a)的价值越大,就逼迫网络往输出更大的π(s',a')输出方向迭代。如果(s,a)的价值越小,就逼迫网络往输出更小的π(s',a')输出方向迭代。如果(s,a)的价值趋向无穷小,反而逼迫网络往输出较大的π(s',a')方向迭代,自适应的进行利用和探索。
也所以,动作a是由策略决定的,策略是由神经网络决定的。所以REINFORCE是,根据神经网络的策略,不断试探环境Environment,从环境中窥视状态s的分布d(s)、s的价值q(s,a),不断逼近d(s)的真实值、以及q(s,a)的最大值,从而直接优化策略函数。
REINFORCE原理简单,直接优化策略函数,理论上可收敛到全局最优。但缺点是:
高方差:单条轨迹的累积奖励波动大,导致梯度估计不稳定。
样本效率低:需要大量轨迹才能得到可靠的梯度。
所以我们下一个篇章讲的AC框架,就是对策略梯度方法的缺点进行的改进。希望大家深刻理解本篇,为学习AC框架下的各种算法,打一个坚实的基础。下篇不见不散。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)