【深度学习——分类任务的原理】
一. 分类任务与回归任务的区别
1.分类任务与回归
回归任务是找到一个模型能够反映数据的分布,而分类任务是将找到数据的特征,将不同种类给分开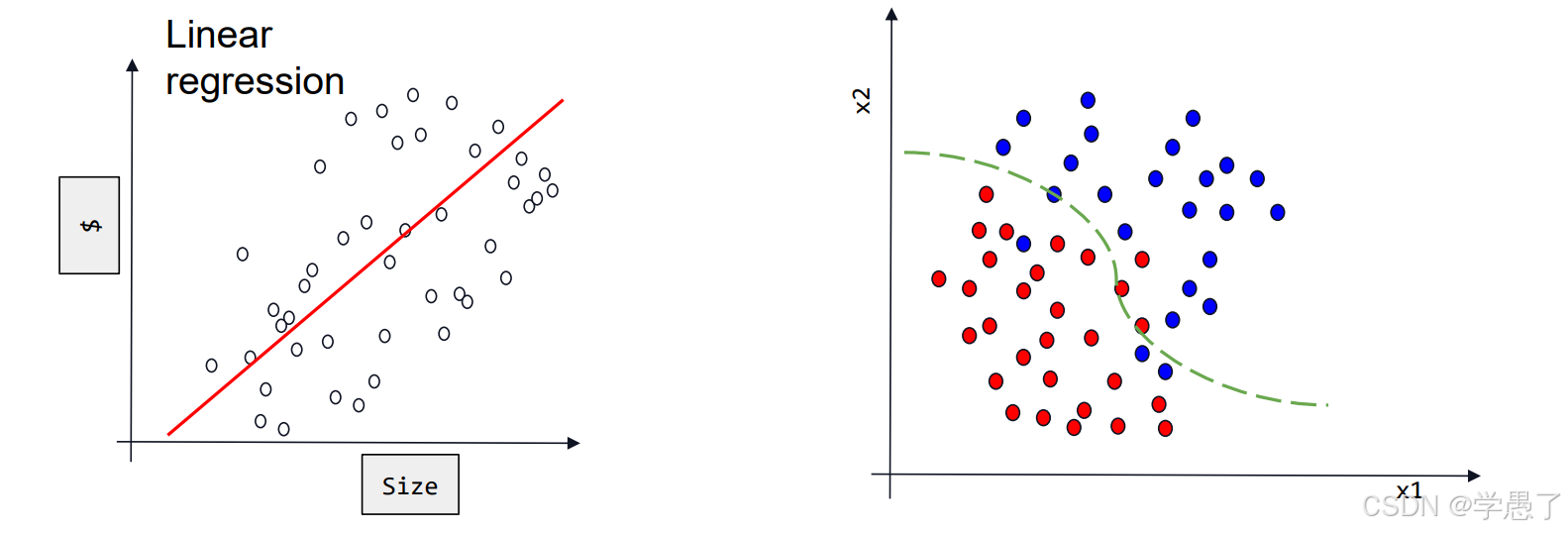
2.分类任务的输出
其输出结果用独热编码表示,例如【0.2,0.5,0.3】其中,每个类别地位是相同的,其数字代表数据对应类别的概率。
二.图片分类原理
1.图片分类大致流程
(1)输入一张图片
(2)通过模型
(3)得到预测结果
(4)预测值与真实值求loss、更新模型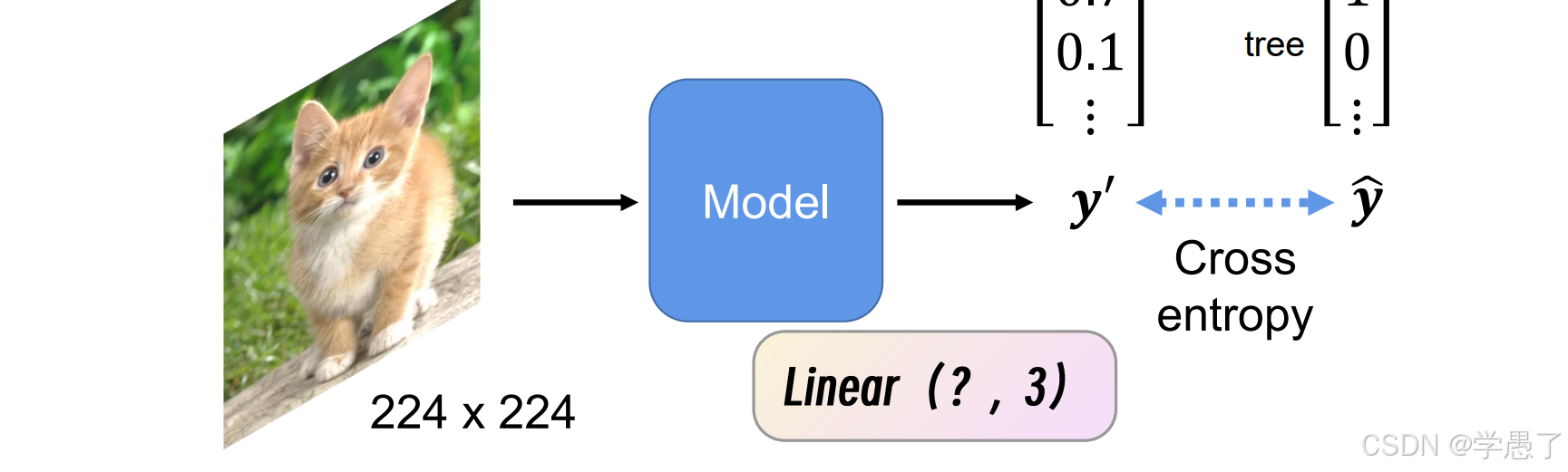
2.输入方式
一张真实的图片是三通道矩阵构成,最直接的方式是将图片的矩阵信息拉直,然后通过神经网络得到结果。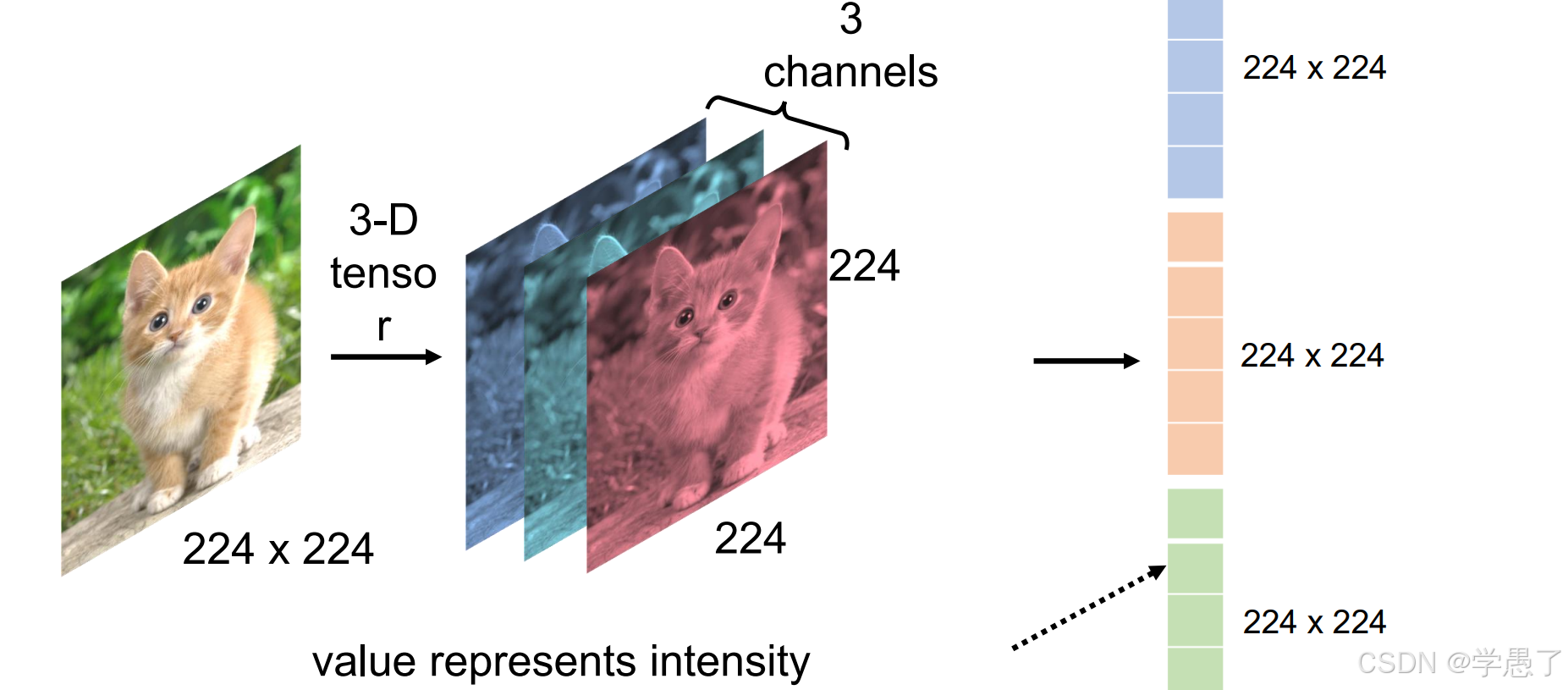
但是此方法伴随而来的问题就是数据量太大,以一张标准图片为例(224224),分类结果有1000,则数据量为22422431000+1000,参数量越多,越容易过拟合。因此提出了卷积神经网络解决。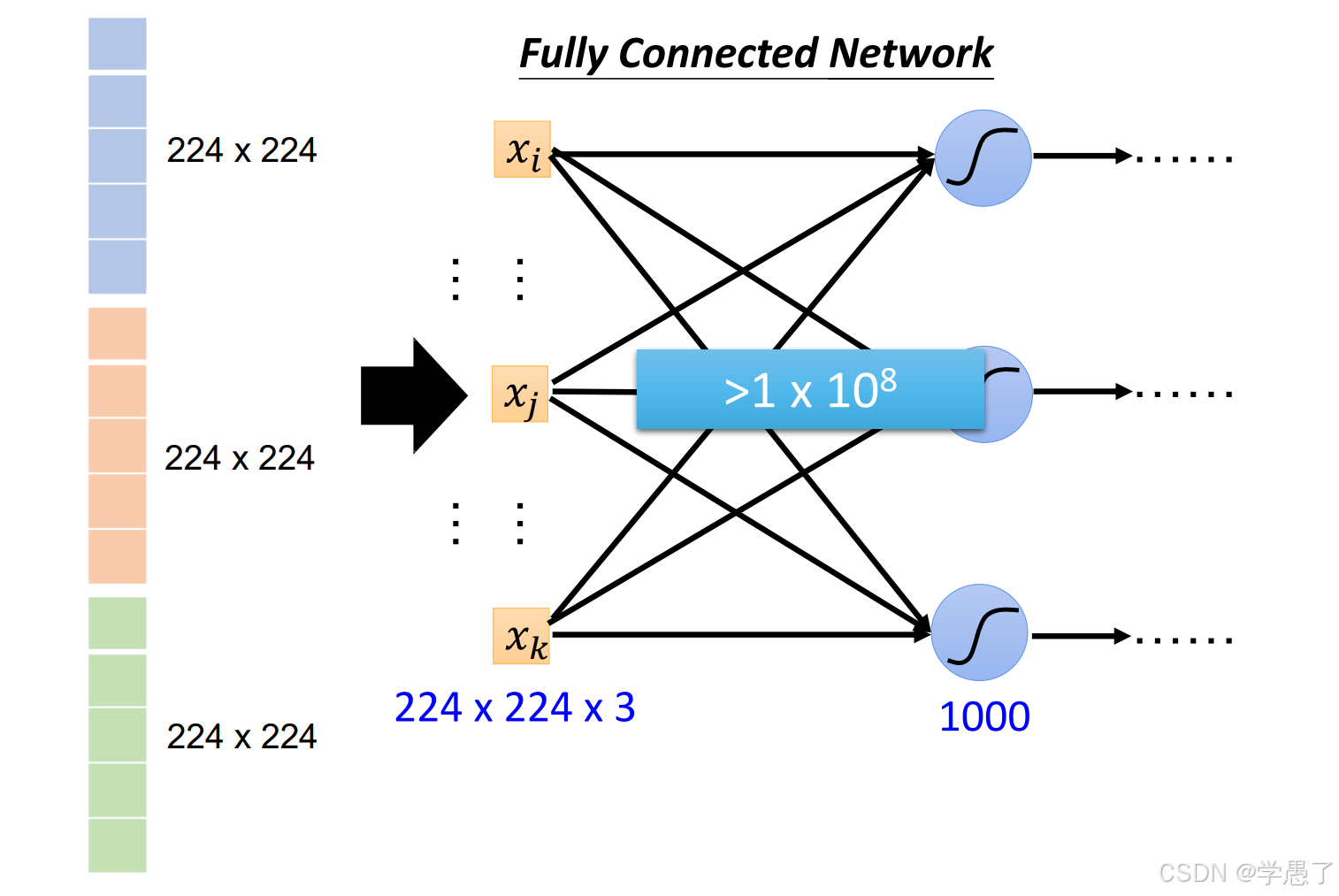
3.卷积神经网络(CNN)
将卷积核与原特征图所有位置进行相乘相加,从而得到新的特征图,新的特征图可以再与新的卷积核进行同样操作再次得到另外一个新的特征图。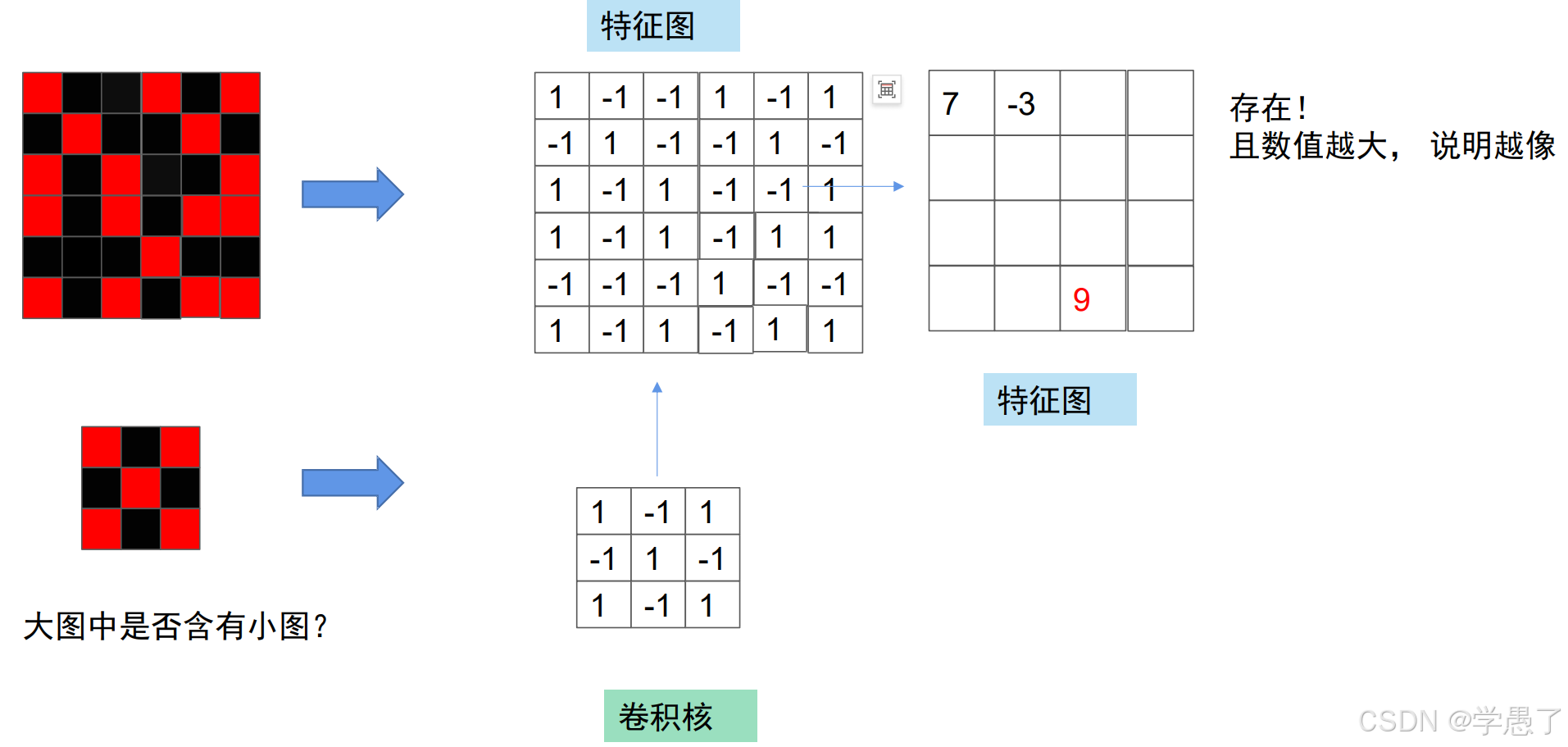
卷积的重要目标是得到一个我们想要的卷积核使我们可以提取到图片的特征。一张图片通常是三通道的,以33的卷积核为例,其参数为33*3=27,也就是卷积核有三层,27个数相加得到一个值。卷积核又称为感受野。
padding的作用是保持卷积后的特征图大小不变。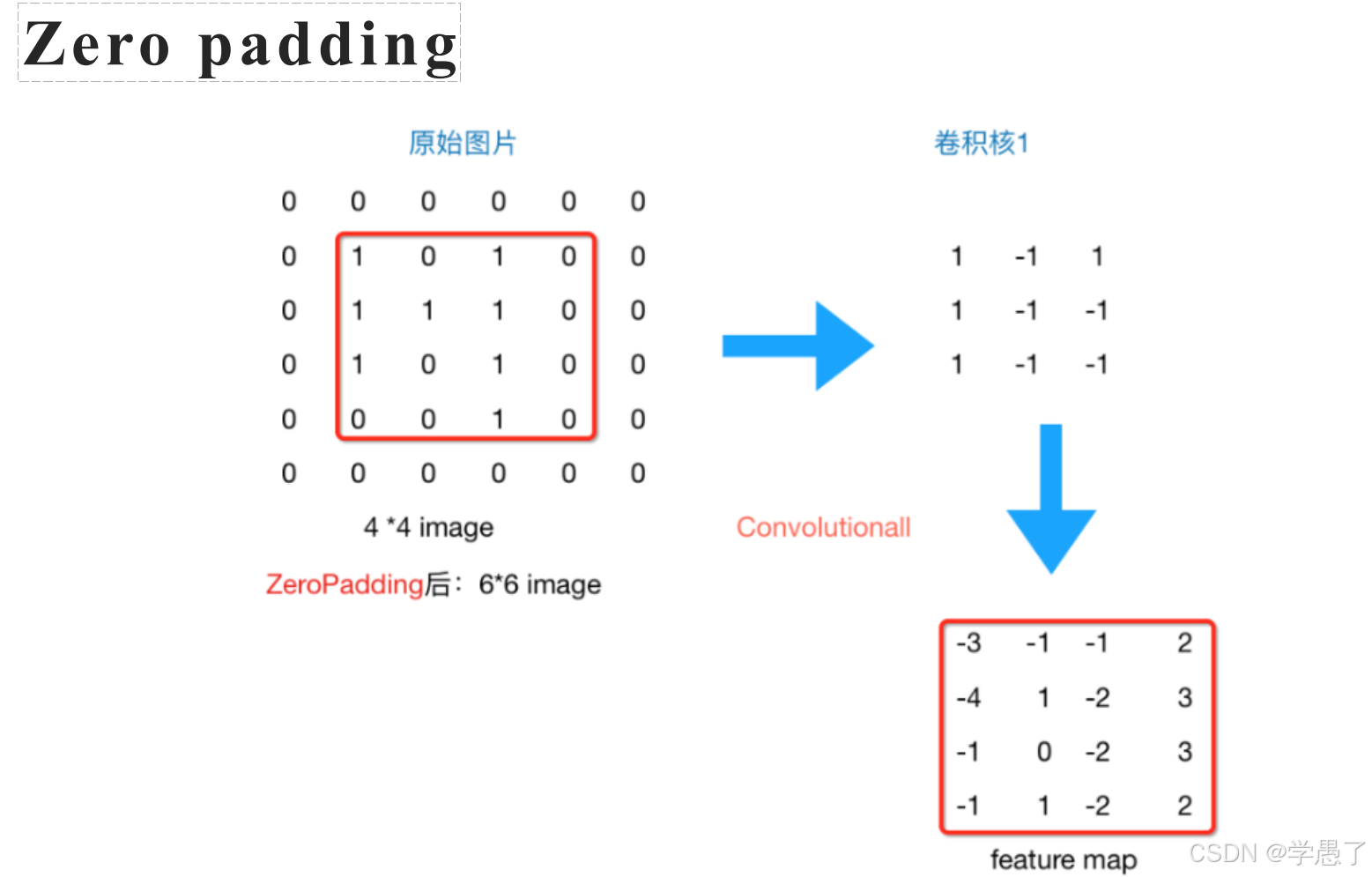
在进行多次卷积时,每一次卷积后得到的特征图层数会发生变化,则对应的卷积核层数也要发生变化。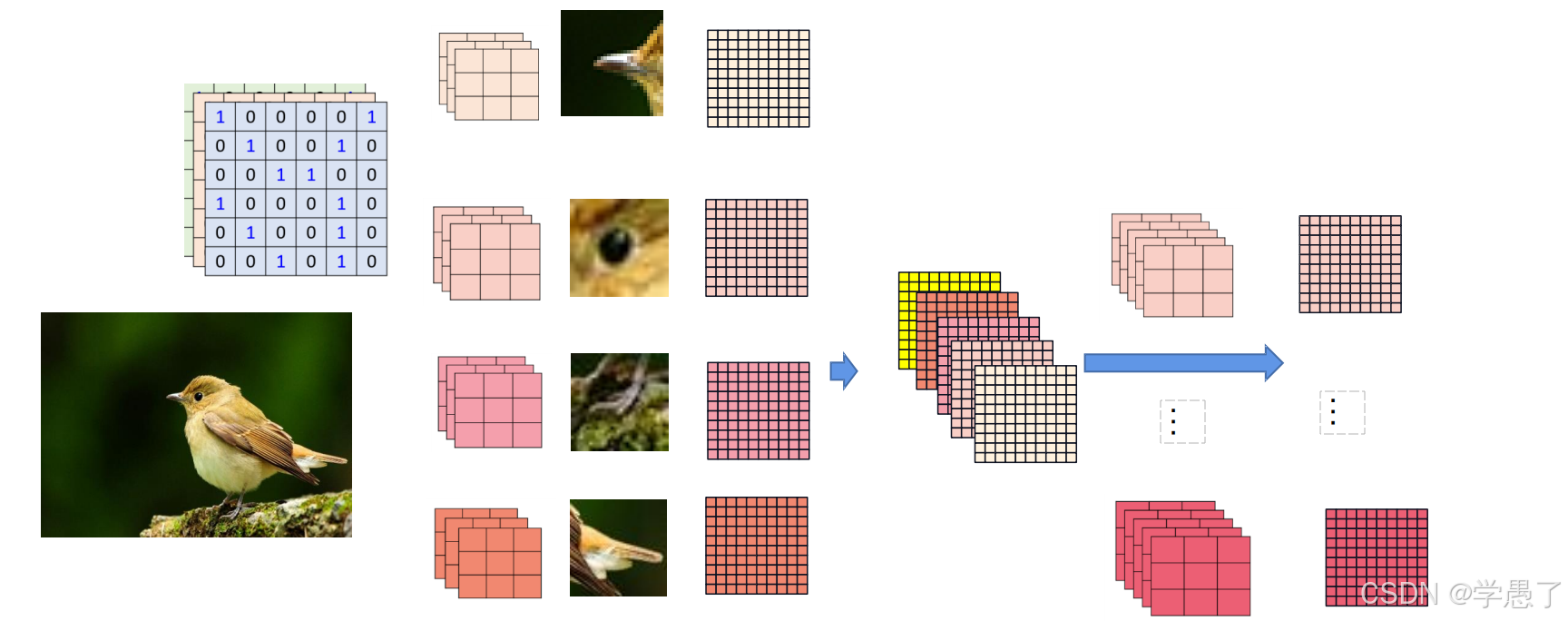
4.卷积的计算方法
(1)扩大步长(不常用,会丢失信息以及引入复杂计算)

例1:特征图64224224. 卷积核6433, padding=1,步长1,卷积核数量128卷出来特征图多大。这套卷积核的参数量多少?
一层的大小为:224 - 3 + 12 + 1 = 224
共128层,特征图大小为128224224 参数量为6433128
例2:请计算, 输入 3224224, 卷积核11, padding = 2 Stride = 4 , 卷积核数量64, 问输出多少。
一层为(224 + 22 -11)/ 4 + 1 = 54(向下取整)+ 1 =55
共64层,特征图大小为645555 参数量为 1111*64
(2)池化
池化有两种,一种是最大池化,一种是平均池化,一般采用最大池化。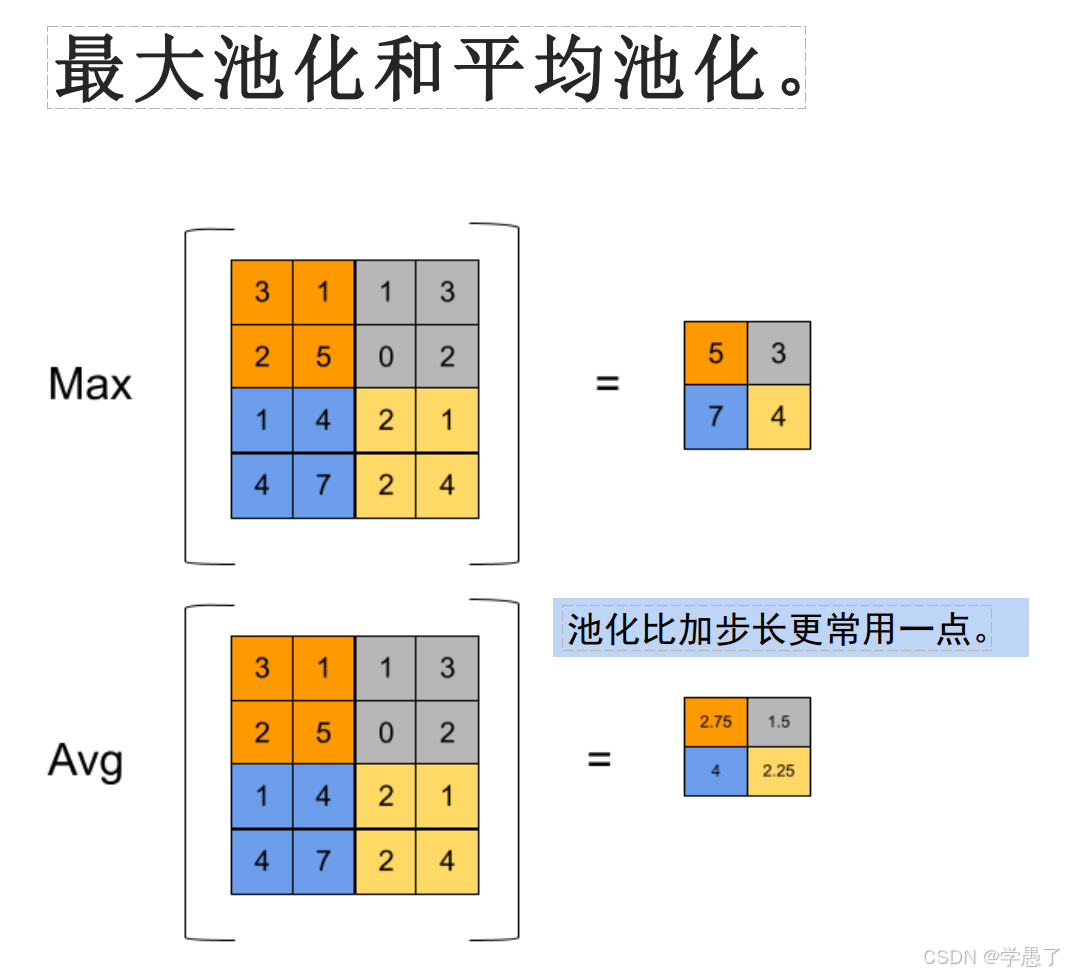
其中Pooling(2)表示22组成一个
AdaptiveAvgPool(7)表示无论初始多大,最终都变为77
注:卷积的目的是为了减少参数量,最终就可以再拉直,然后通过模型得到结果
5.loss计算方法
上述得到的结果并不是概率分布,利用softmax转化成概率分布,即可求loss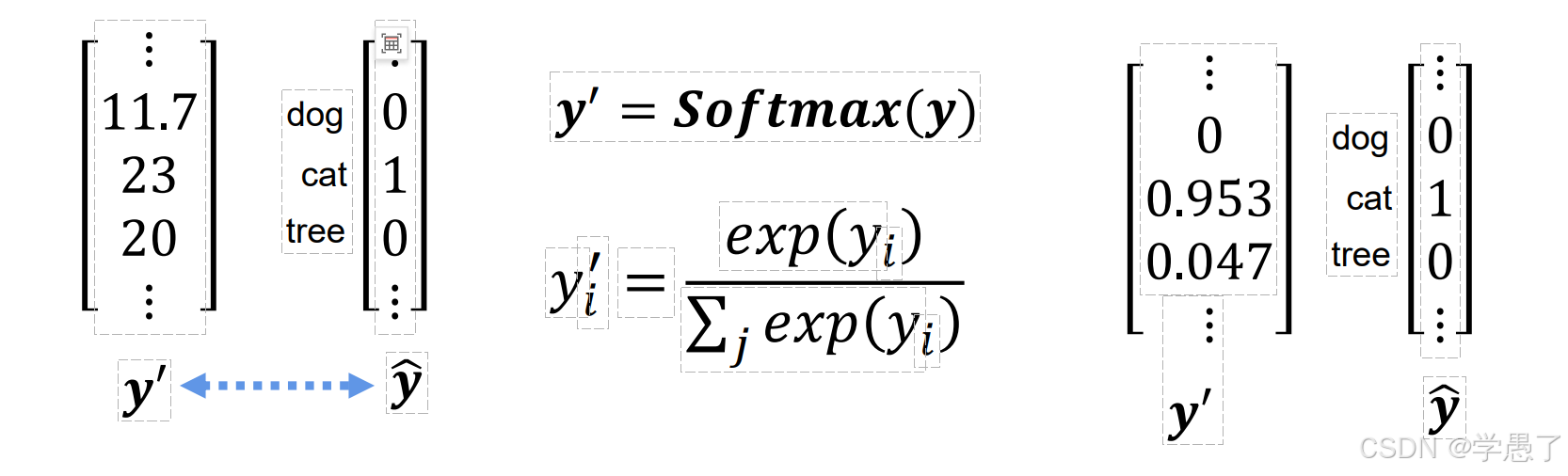
此处求loss的方法为CrossEntropy Loss:交叉熵损失(懂得调用即可)
交叉熵损失介绍
三.分类任务总结
【前向过程】首先输入图片,然后经过若干次卷积得到特征,最后拉直,经过全连接求出预测值,有了预测值与真实值就可以算出loss。
【反向过程】梯度回传,得到每一个卷积核上每一个权重的梯度,更新模型。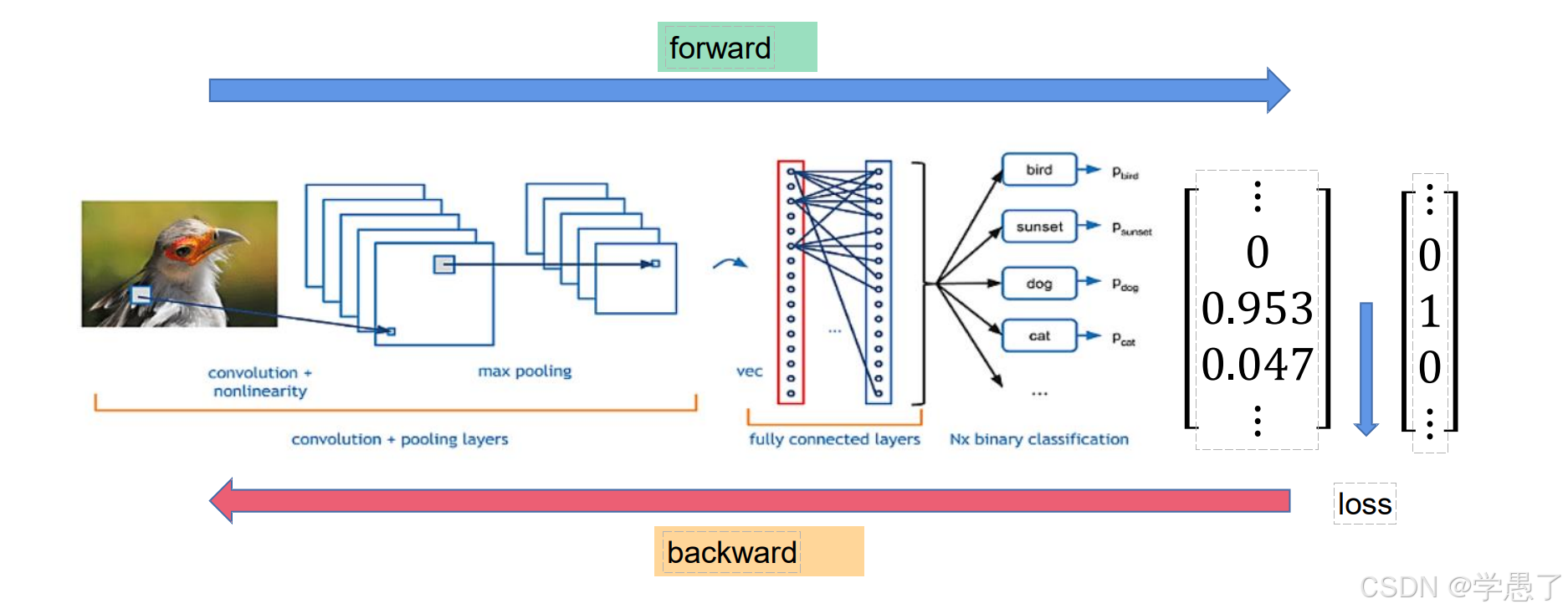
四.神经网络的发展
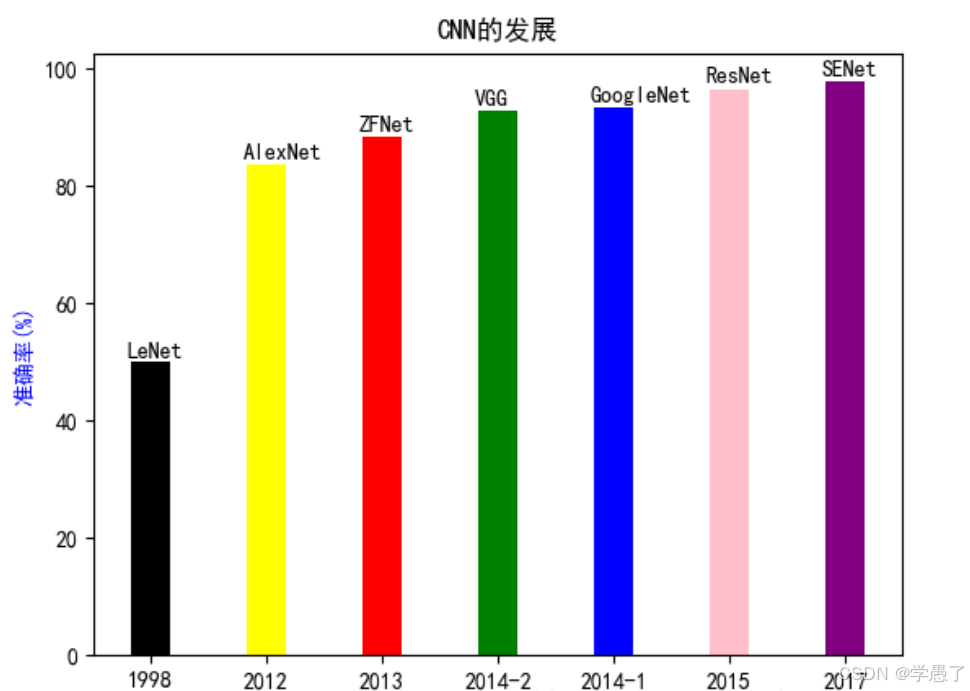
1.AlexNet神经网络
AlexNet在 ImageNet LSVRC-2012的比赛中,取得了top-5错误率为15.3%的成绩。 第二名是30多的错误率。
AlexNet有6亿个参数和650,000个神经元,包含5个卷积层,有些层后面跟了max-pooling层,3个全连接层
创新点:
(1)使用了relu激活函数
relu相比于sigmoid,计算更加方便,也可以缓解梯度消失问题。
(2)drop out
在训练时随机丢弃一些神经元,本轮不用,下次再换,可以缓解过拟合。
(3)池化
(4)归一化
它可以让模型关注数据的分布,而不受数据量纲的影响。归一化可以 保持学习有效性, 缓解梯度消失和梯度爆炸。
(3,64,11,4,2)分别对应输入特征图数量、输出特征图数量、卷积核大小、步长、padding
Pool(3,2)表示3*3卷积一次,步长为2.
经过八次卷积,最终得到结果拉直,全连接输出结果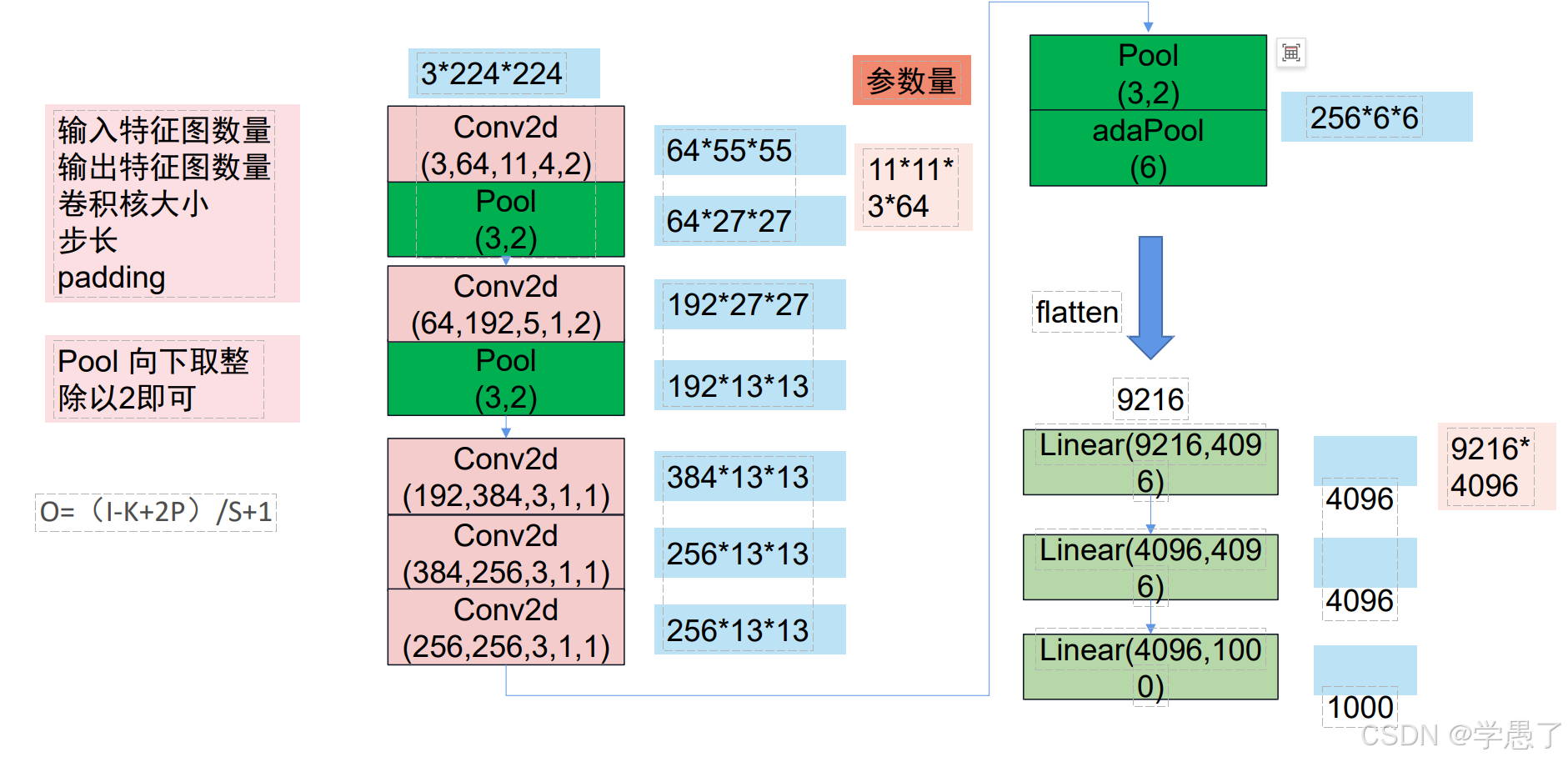
代码实现
from torchvision import models
import torch
import torch.nn as nn
# models = models.alexnet()
# print(models)
class myModel(nn.Module):
def __init__(self,num_cls): #分类数量
super(myModel, self).__init__()
self.conv1 = nn.Conv2d(3,64,11,4,2) # 第一层卷积
self.pool1 = nn.MaxPool2d(3,2) #第一层的pool
self.conv2 = nn.Conv2d(64, 192, 5, 1, 2) # 第二层卷积
self.pool2 = nn.MaxPool2d(3, 2) # 第二层的pool
self.conv3 = nn.Conv2d(192, 384, 3, 1, 1) # 第3层卷积
self.conv4 = nn.Conv2d(384, 256, 3, 1, 1) # 第4层卷积
self.conv5 = nn.Conv2d(256, 256, 3, 1, 1) # 第5层卷积
self.pool3 = nn.MaxPool2d(3,2) #第三次池化
self.pool4 = nn.AdaptiveMaxPool2d(6) #第四次池化 池化不计入卷积层数
self.fc1 = nn.Linear(9216, 4096)#展平,三层全连接
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, num_cls)
def forward(self,x): #x前向过程
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool3(x)
x = self.pool4(x) #此时的结果为batch*256*6*6
x = x.view(x.size()[0],-1) #展平,前面为batch数据量,后面全部展开放在第二维 batch*9216
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
model = myModel(1000)
data = torch.ones(4,3,224,224) #四个样本 大小为3*224*24
pred = model(data)
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
print(get_parameter_number(model))
2.VggNet
2014年,VGG网络被提出,其在AlexNet的基础上,运用了更小的卷积核,并且加深了网络,达到了更好的效果
创新点:更深 , 更大。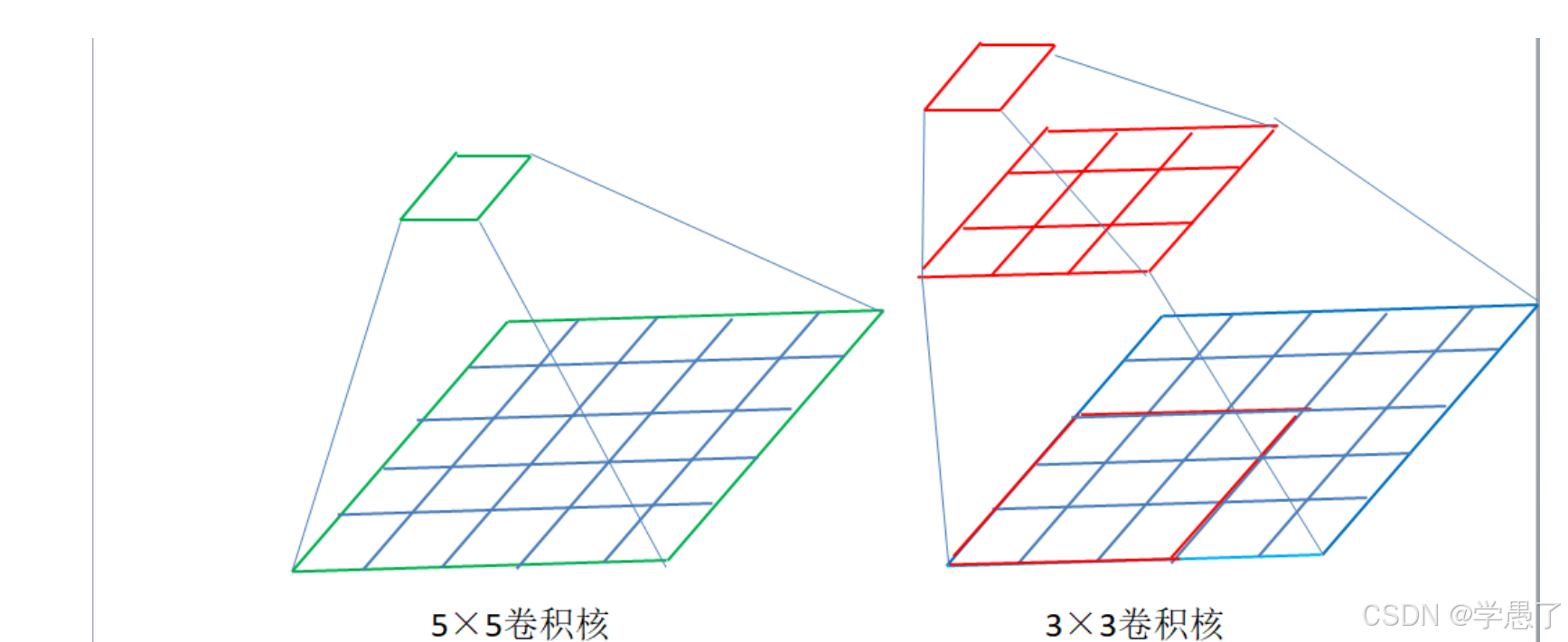
原来的参数量为55=25 现在为33+3*3=18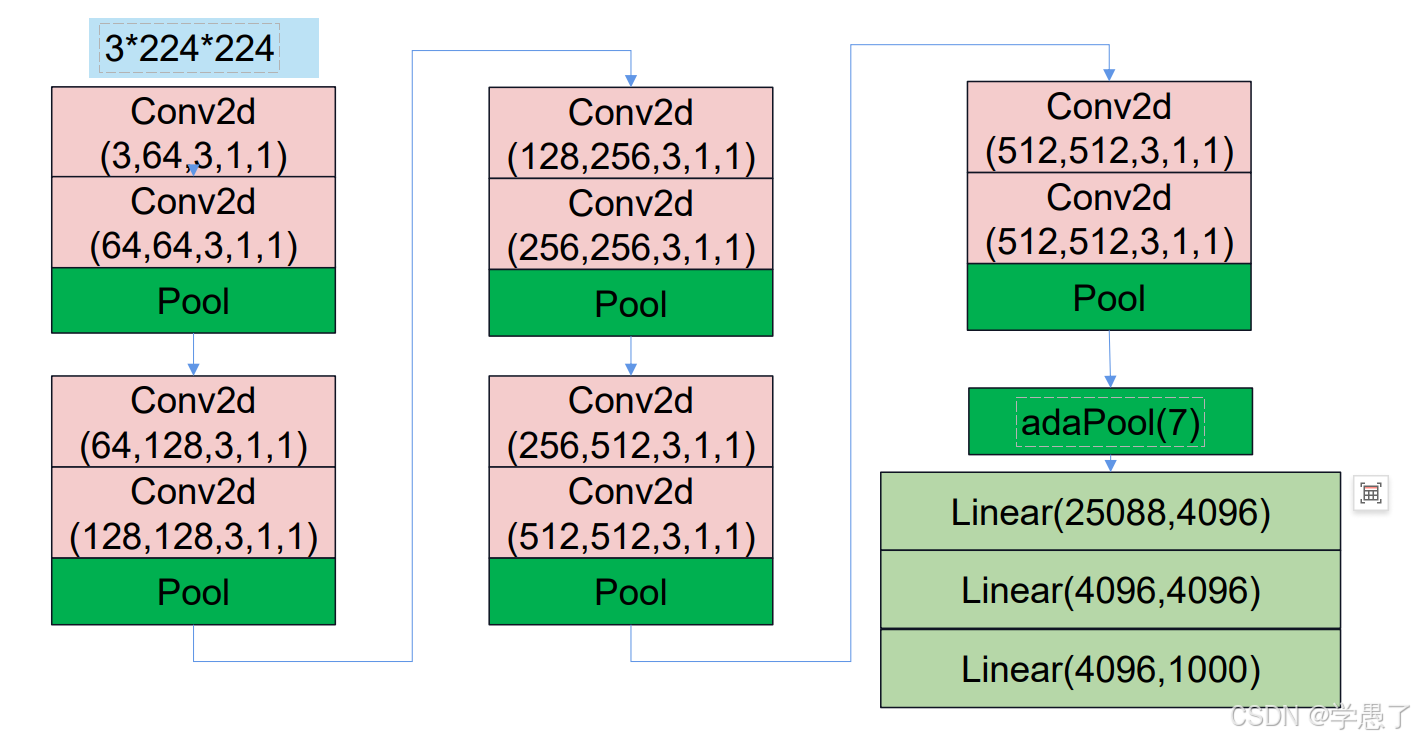
代码实现
import torchvision.models as models
import torch.nn as nn
class vgglayer(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel):
super(vgglayer, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2)
self.conv1 = nn.Conv2d(in_channel, mid_channel, 3, 1, 1)
self.conv2 = nn.Conv2d(mid_channel, out_channel, 3, 1, 1)
def forward(self, x): # 经过每一层都有再经过激活函数
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
return x
class Mymodel(nn.Module):
def __init__(self, num_cls):
super(Mymodel, self).__init__()
self.layer1 = vgglayer(3, 64, 64)
self.layer2 = vgglayer(64, 128, 128)
self.layer3 = vgglayer(128, 256, 256)
self.layer4 = vgglayer(256, 512, 512)
self.layer5 = vgglayer(512, 512, 512)
self.adapool2 = nn.AdaptiveMaxPool2d(7)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(25088, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, num_cls)
def forward(self, x): # 前向过程
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.adapool2(x)
x = self.relu(x)
x = x.view(x.size()[0],-1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
x = self.relu(x)
return x
import torch
model = Mymodel(1000)
data = torch.zeros(1,3,224,224)
out = model(data)
print(out.size)
3.ResNet
创新:
(1)1*1卷积
降维,减少参数量
(2)残差链接
解决梯度消失和梯度爆炸
当偏导都很小时,梯度太小,几乎无法更新模型;当偏导很大时,梯度太大,模型变化太大;经过此公式,可以使得梯度恒大于1,避免梯度消失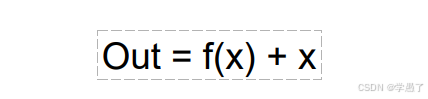
代码实现
import torch
import torch.nn as nn
import torchvision.models as models
resNet = models.resnet18()
print(resNet)
class Residual_block(nn.Module): #@save
def __init__(self, input_channels, out_channels, down_sample=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, out_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(out_channels, out_channels,
kernel_size=3, padding=1, stride= 1)
if input_channels != out_channels:
self.conv3 = nn.Conv2d(input_channels, out_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, X):
out = self.relu(self.bn1(self.conv1(X)))
out= self.bn2(self.conv2(out))
if self.conv3:
X = self.conv3(X)
out += X
return self.relu(out)
class MyResNet18(nn.Module):
def __init__(self):
super(MyResNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.bn1 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(3, stride=2, padding=1)
self.relu = nn.ReLU()
self.layer1 = nn.Sequential(
Residual_block(64, 64),
Residual_block(64, 64)
)
self.layer2 = nn.Sequential(
Residual_block(64, 128, strides=2),
Residual_block(128, 128)
)
self.layer3 = nn.Sequential(
Residual_block(128, 256, strides=2),
Residual_block(256, 256)
)
self.layer4 = nn.Sequential(
Residual_block(256, 512, strides=2),
Residual_block(512, 512)
)
self.flatten = nn.Flatten()
self.adv_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(512, 1000)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.adv_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
myres = MyResNet18()
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
print(get_parameter_number(myres.layer1))
print(get_parameter_number(myres.layer1[0].conv1))
print(get_parameter_number(resNet.layer1[0].conv1))
x = torch.rand((1,3,224,224))
out = resNet(x)
out = myres(x)
五.神经网络透析
1.显卡的发展推动了神经网络发展
2.卷积比全连接,参数量更小,能有效防止过拟合。卷积是参数共享的不全链接
3.深度学习就是玩特征

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)