NVIDIA CUTLASS 深度学习教程
NVIDIA CUTLASS (CUDA Templates for Linear Algebra Subroutines and Solvers) 是一个用于线性代数运算的CUDA C++模板库。它专门为深度学习中的矩阵运算优化,提供了高性能的GEMM(通用矩阵乘法)实现。
·
NVIDIA CUTLASS 深度学习教程
文章目录
简介
NVIDIA CUTLASS (CUDA Templates for Linear Algebra Subroutines and Solvers) 是一个用于线性代数运算的CUDA C++模板库。它专门为深度学习中的矩阵运算优化,提供了高性能的GEMM(通用矩阵乘法)实现。
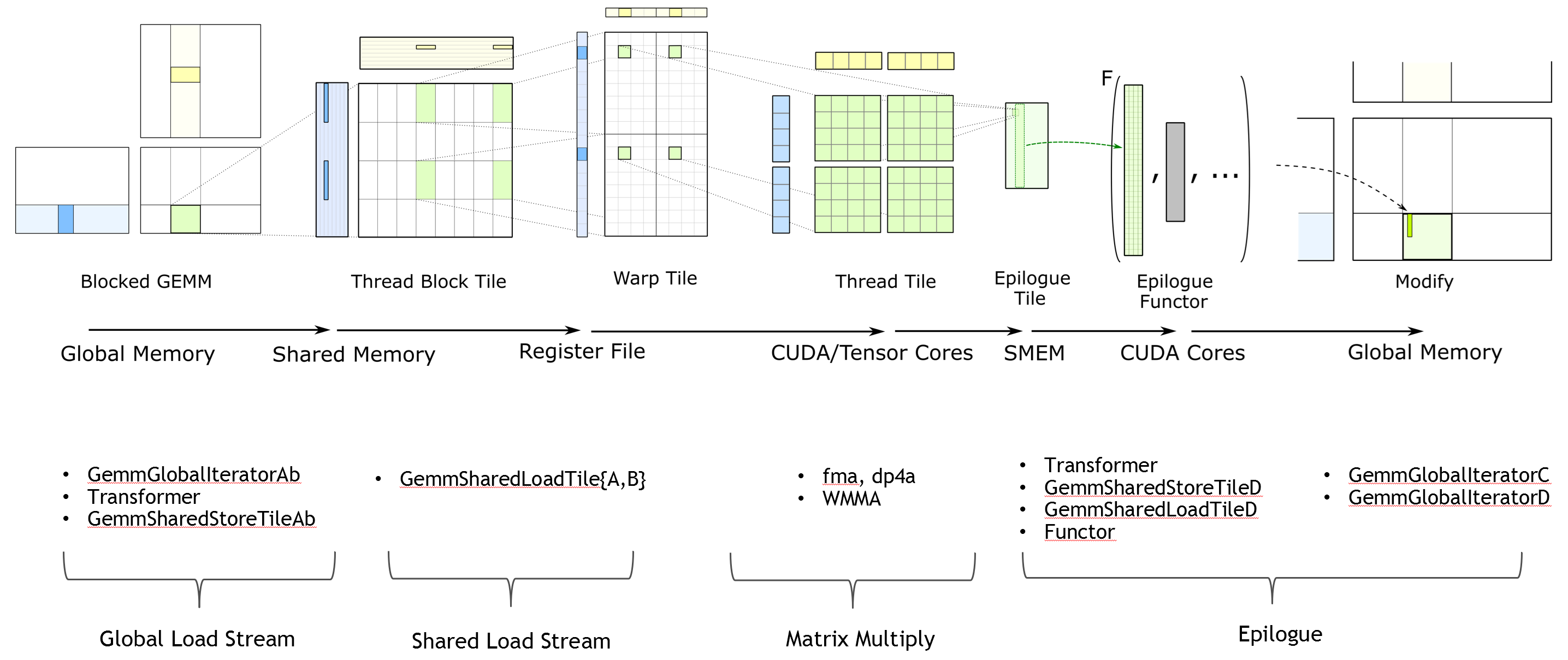
主要特点
- 支持多种数据类型(FP32, FP16, INT8等)
- 高度优化的性能
- 灵活的架构设计
- 与CUDA完全兼容
- 支持多种硬件架构
应用场景
- 深度学习推理
- 计算机视觉
- 自然语言处理
- 科学计算
安装指南
系统要求
- CUDA 11.0或更高版本
- C++14兼容的编译器
- CMake 3.10或更高版本
- NVIDIA GPU (支持Tensor Core的GPU可获得最佳性能)
安装步骤
- 克隆仓库:
git clone https://github.com/NVIDIA/cutlass.git
cd cutlass
- 创建构建目录:
mkdir build && cd build
- 配置CMake:
cmake ..
- 编译:
make -j$(nproc)
验证安装
# 运行测试用例
./test/unit/gemm/device/gemm_f16n_f16n_f32n_tensor_op_f32_sm80_test
基础概念
1. 核心组件
- Tile: 矩阵运算的基本计算单元
- Thread Block: 包含多个线程的计算块
- Warp: 32个线程的集合,是CUDA的基本执行单元
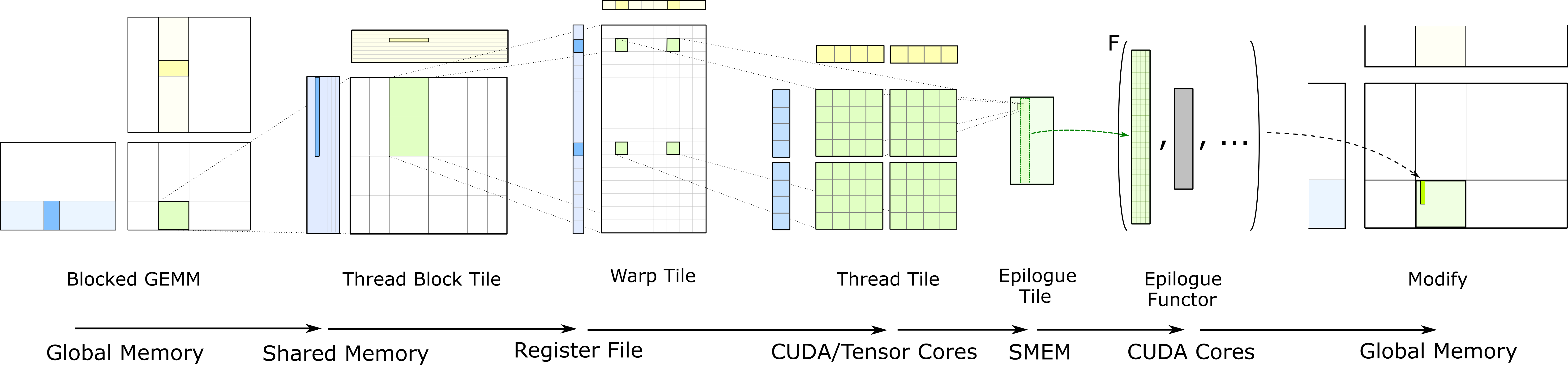
2. 主要操作类型
- GEMM (General Matrix Multiplication)
- Convolution
- Reduction
- Transpose
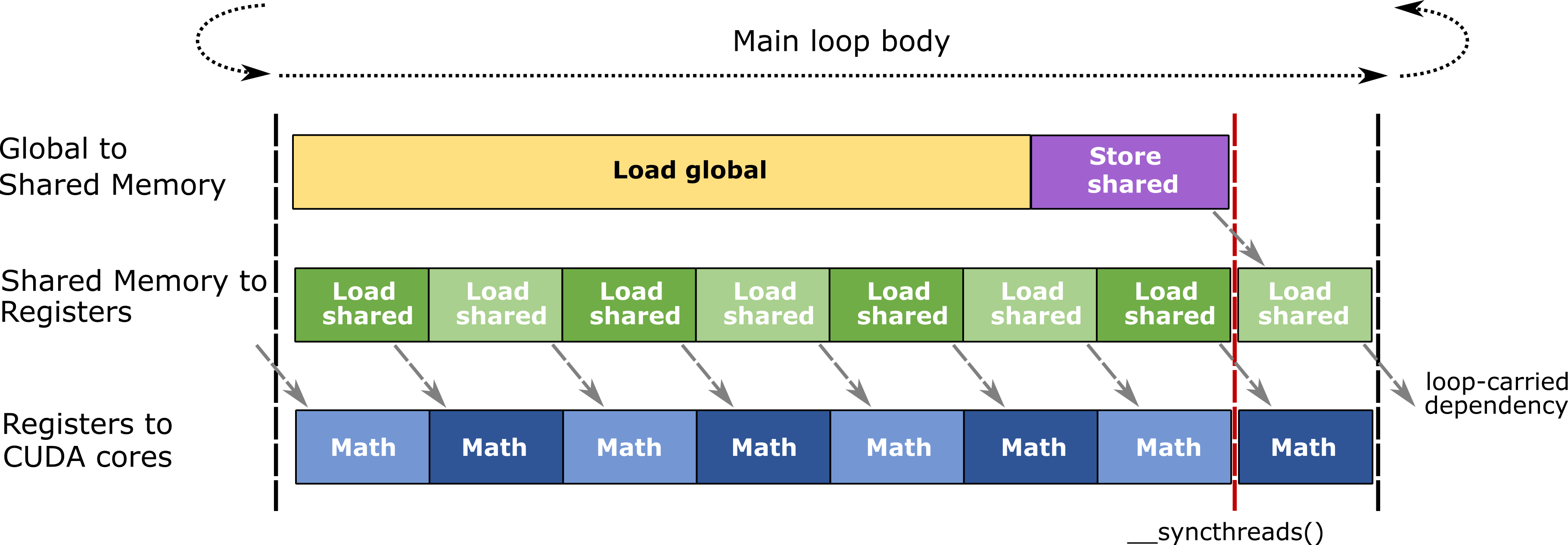
3. 内存层次结构
示例代码
1. 基础GEMM示例
#include "cutlass/gemm/device/gemm.h"
#include "cutlass/core_io.h"
#include "cutlass/util/host_tensor.h"
// 定义数据类型和布局
using Element = float; // 使用单精度浮点数
using LayoutA = cutlass::layout::RowMajor; // A矩阵的行主序布局
using LayoutB = cutlass::layout::ColumnMajor; // B矩阵的列主序布局
using LayoutC = cutlass::layout::RowMajor; // C矩阵的行主序布局
// 定义GEMM操作
using Gemm = cutlass::gemm::device::Gemm<
Element, // 数据类型
LayoutA, // A矩阵布局
Element, // B矩阵数据类型
LayoutB, // B矩阵布局
Element, // C矩阵数据类型
LayoutC, // C矩阵布局
Element, // 计算类型
cutlass::arch::OpClassTensorOp, // 操作类型
cutlass::arch::Sm80 // 目标架构
>;
int main() {
// 矩阵维度
int M = 1024; // A矩阵行数
int N = 1024; // B矩阵列数
int K = 1024; // A矩阵列数/B矩阵行数
// 创建GEMM操作实例
Gemm gemm_op;
// 配置GEMM参数
typename Gemm::Arguments args{
{M, N, K}, // 问题大小
nullptr, // A矩阵指针
{K}, // A矩阵步长
nullptr, // B矩阵指针
{N}, // B矩阵步长
nullptr, // C矩阵指针
{N}, // C矩阵步长
{1.0f, 0.0f} // alpha和beta值
};
// 分配设备内存
cutlass::device_memory::allocation<Element> A(M * K);
cutlass::device_memory::allocation<Element> B(K * N);
cutlass::device_memory::allocation<Element> C(M * N);
// 初始化数据
// ... 初始化代码 ...
// 执行GEMM操作
gemm_op(args);
return 0;
}
2. 卷积操作示例
#include "cutlass/conv/device/conv2d.h"
// 定义卷积参数
using Element = float;
using Layout = cutlass::layout::TensorNHWC;
// 定义卷积操作
using Conv2d = cutlass::conv::device::Conv2d<
Element, // 输入数据类型
Layout, // 输入布局
Element, // 权重数据类型
Layout, // 权重布局
Element, // 输出数据类型
Layout, // 输出布局
Element, // 计算类型
cutlass::arch::OpClassTensorOp,
cutlass::arch::Sm80
>;
int main() {
// 创建卷积操作实例
Conv2d conv_op;
// 配置卷积参数
typename Conv2d::Arguments args{
{32, 28, 28, 64}, // 输入尺寸 (N, H, W, C)
{64, 3, 3, 64}, // 权重尺寸 (K, R, S, C)
{32, 26, 26, 64}, // 输出尺寸
{1, 1}, // 步长
{1, 1}, // 填充
{1, 1}, // 膨胀
nullptr, // 输入指针
nullptr, // 权重指针
nullptr, // 输出指针
{1.0f, 0.0f} // alpha和beta值
};
// 分配设备内存
// ... 内存分配代码 ...
// 执行卷积操作
conv_op(args);
return 0;
}
3. 高级GEMM示例(使用Tensor Core)
#include "cutlass/gemm/device/gemm_tensor_op.h"
// 使用FP16数据类型和Tensor Core
using ElementA = cutlass::half_t; // FP16
using ElementB = cutlass::half_t; // FP16
using ElementC = float; // FP32
using ElementAccumulator = float; // FP32
// 定义Tensor Core GEMM操作
using Gemm = cutlass::gemm::device::GemmTensorOp<
ElementA, // A矩阵数据类型
cutlass::layout::RowMajor, // A矩阵布局
ElementB, // B矩阵数据类型
cutlass::layout::ColumnMajor, // B矩阵布局
ElementC, // C矩阵数据类型
cutlass::layout::RowMajor, // C矩阵布局
ElementAccumulator, // 累加器类型
cutlass::arch::OpClassTensorOp, // 使用Tensor Core
cutlass::arch::Sm80, // 目标架构
cutlass::gemm::GemmShape<128, 128, 32>, // 线程块大小
cutlass::gemm::GemmShape<64, 64, 32> // Warp大小
>;
int main() {
// ... 实现代码 ...
}
性能优化
1. 内存访问优化
- 使用共享内存缓存数据
- 优化内存访问模式
- 使用适当的矩阵布局
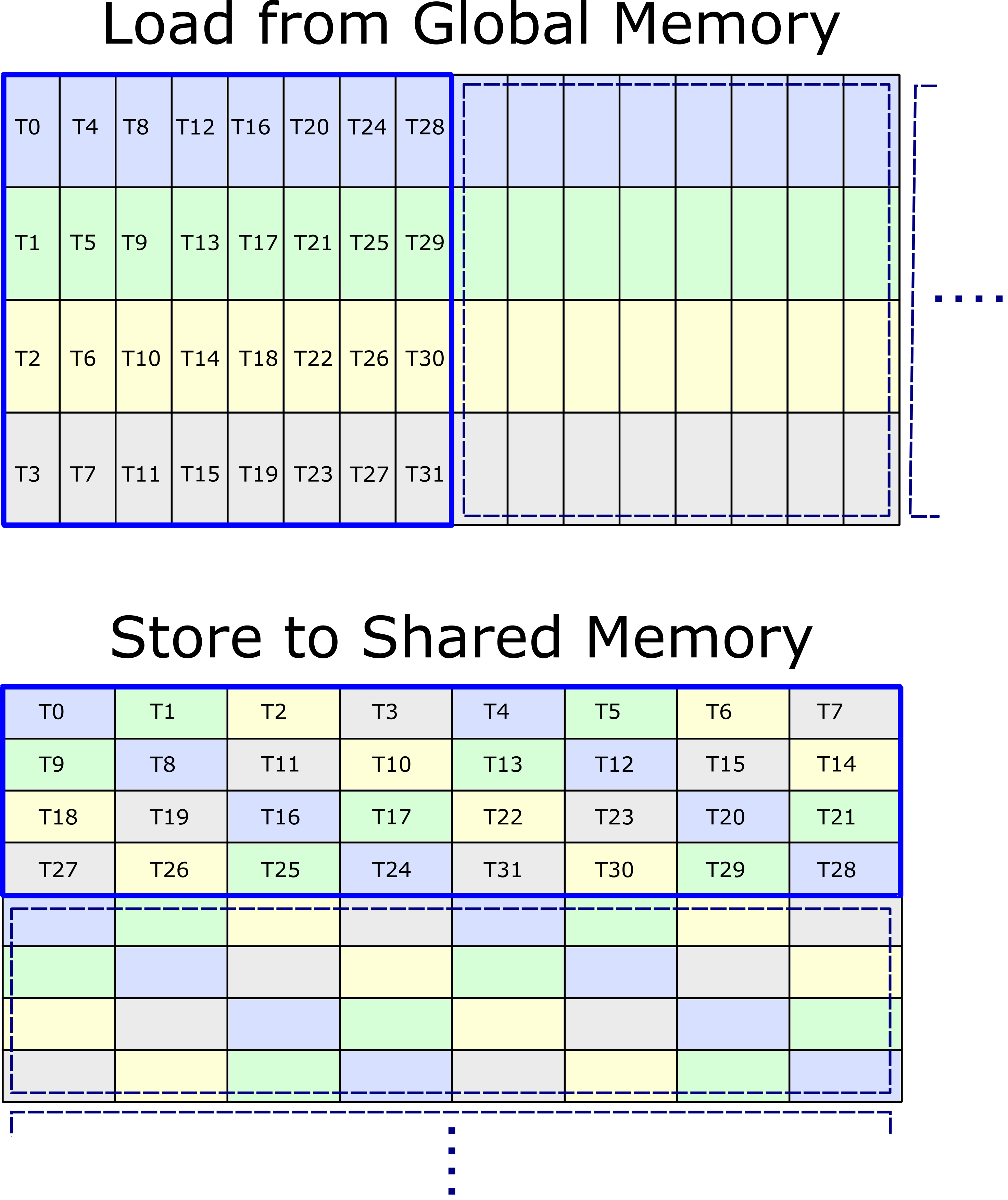
2. 计算优化
- 选择合适的Tile大小
- 使用Tensor Core加速
- 优化线程块配置
3. 性能基准测试

高级应用
1. 混合精度训练
// 使用FP16进行前向传播
using ElementA = cutlass::half_t;
using ElementB = cutlass::half_t;
using ElementC = float;
// 使用FP32进行反向传播
using ElementD = float;
using ElementE = float;
using ElementF = float;
2. 量化推理
// 使用INT8进行量化推理
using ElementA = int8_t;
using ElementB = int8_t;
using ElementC = int32_t;
常见问题
1. 编译错误
- 确保CUDA版本兼容
- 检查CMake配置
- 验证编译器支持C++14
2. 运行时错误
- 检查内存分配
- 验证矩阵维度
- 确认数据类型匹配
3. 性能问题
- 检查GPU利用率
- 验证内存带宽
- 优化线程配置
参考资料

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)