深度学习——分类任务经典数据集(更新中)
数据集较大,可以下载torrent文件后,用迅雷下载,torrent文件下载地址:通过网盘分享的文件:ImageNet.torrent。依次对应airplane、automobile、bird、cat、deer、dog、frog、horse、ship和truck。第i个元素表示data中第i张图像的标签。32的图片,前1024个元素表示红通道的值,下一个1024个元素表示绿通道,最后一个1024表
一、CIFAR-10数据集
参考官方解释:https://www.cs.toronto.edu/~kriz/cifar.html
1、图像信息:
3x32x32,共60000个样本,划分为50000个训练样本和10000个测试样本
2、标签0~9:
依次对应airplane、automobile、bird、cat、deer、dog、frog、horse、ship和truck
3、下载方式:一般直接用torch下载使用
# 加载训练数据集
train_datasets = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=transform)
# 训练数据集划分批次
train_dataloder = DataLoader(train_datasets, batch_size=36, shuffle=True, num_workers=0)
# 加载测试数据集
test_datasets = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=transform)
# 测试数据集划分批次
test_dataloader = DataLoader(test_datasets, batch_size=10000, shuffle=True, num_workers=0)
4、数据集结构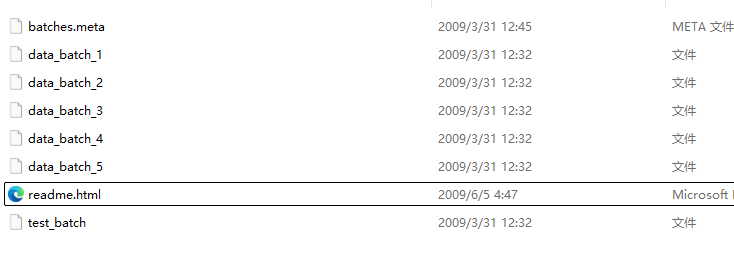
包含5个data_batch和一个test_batch,都是采用python的pickle方式进行打包的。基于python3,可以使用以下代码解包得到一个字典,字典里包含两个信息:
1)data:一个10000x3072的numpy数组,数组的行存储一张3通道的32x32的图片,前1024个元素表示红通道的值,下一个1024个元素表示绿通道,最后一个1024表示蓝通道
2)label:一个含有10000个元素的列表,元素取值为0~9;第i个元素表示data中第i张图像的标签
还包含一个batches.meta文件,这个文件也包含一个含有10个元素的python字典,字典内容是10分类的标签和word的对应,如:
label_names[0] == “airplane”, label_names[1] == “automobile”
import pickle
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict[b'data'],dict[b'labels']
5、标签获取方法:使用迭代器
# 将测试机test_dataloader转换为可迭代的迭代器
test_data_iter = iter(test_dataloader)
# 通过next方法获取一批数据,包括图像及其对应的标签值
test_image, test_label = next(test_data_iter)
二、ILSVRC2012-ImageNet猫狗数据集(大数据集需要手动建立映射,网上资源多,懒得看)
1、图像信息:
3通道彩色图像,图像大小不限,(AlexNet网络的图像被统一随机切割成224x224)
2、标签0~999
3、下载方式:
数据集较大,可以下载torrent文件后,用迅雷下载,torrent文件下载地址:通过网盘分享的文件:ImageNet.torrent
链接: https://pan.baidu.com/s/1FGbaNo0GpEHPxNQK3laZ-A 提取码: vxnz
猫狗数据集较小,练习时可以用这个,下载地址:通过网盘分享的文件:ImageNet猫狗.zip
链接: https://pan.baidu.com/s/1fMQXDYEG9suUq8LfUmCsZQ 提取码: gd8x
4、数据集结构
文件夹划分为train和test,标签与文件夹名称对应
5、数据集加载
# 从本地加载数据集
train_dataset = datasets.ImageFolder(root=image_path + '/train', transform=data_transform["train"])
"""
ImageFolder:加载数据集
文件夹结构:
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
ImageFolder返回值:train_dataset.class_to_idx:"dog" :0; "cat":1
"""
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
# 测试集
test_dataset = datasets.ImageFolder(root=image_path + '/test', transform=data_transform['test'])
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
6、AlexNet的数据预处理
# 数据增强
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]),
"test": transforms.Compose([transforms.Resize((224, 224)), # 重定义尺寸
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
}
6、标签获取方法:
# 获取分类的名称
label_list = train_dataset.class_to_idx
二、MNIST
三、ImageNet数据集

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)