图神经网络—如何创建自己的图数据集结构
在第二部分我们学习如何将一个指定场景的数据转化成为,图神经网络可以去使用的数据类型。这里使用的是sklearn中的电商系统用户行为分析的数据来进行学习和使用。我们的任务是结合给定的这一副图,来构建出符合结构的数据集。获取出标签数据重新的进行输出。
·
图神经网络代码学习—如何创建自己的图数据集结构
如果我们要在目标跟踪任务中,或者是在其他的一些cv领域使用到图神经网络的话,就需要思考一个必要的问题了,如何将我们得到的数据,转化为图神经网络可以计算的数据呢?
按照张量的形式直观理解
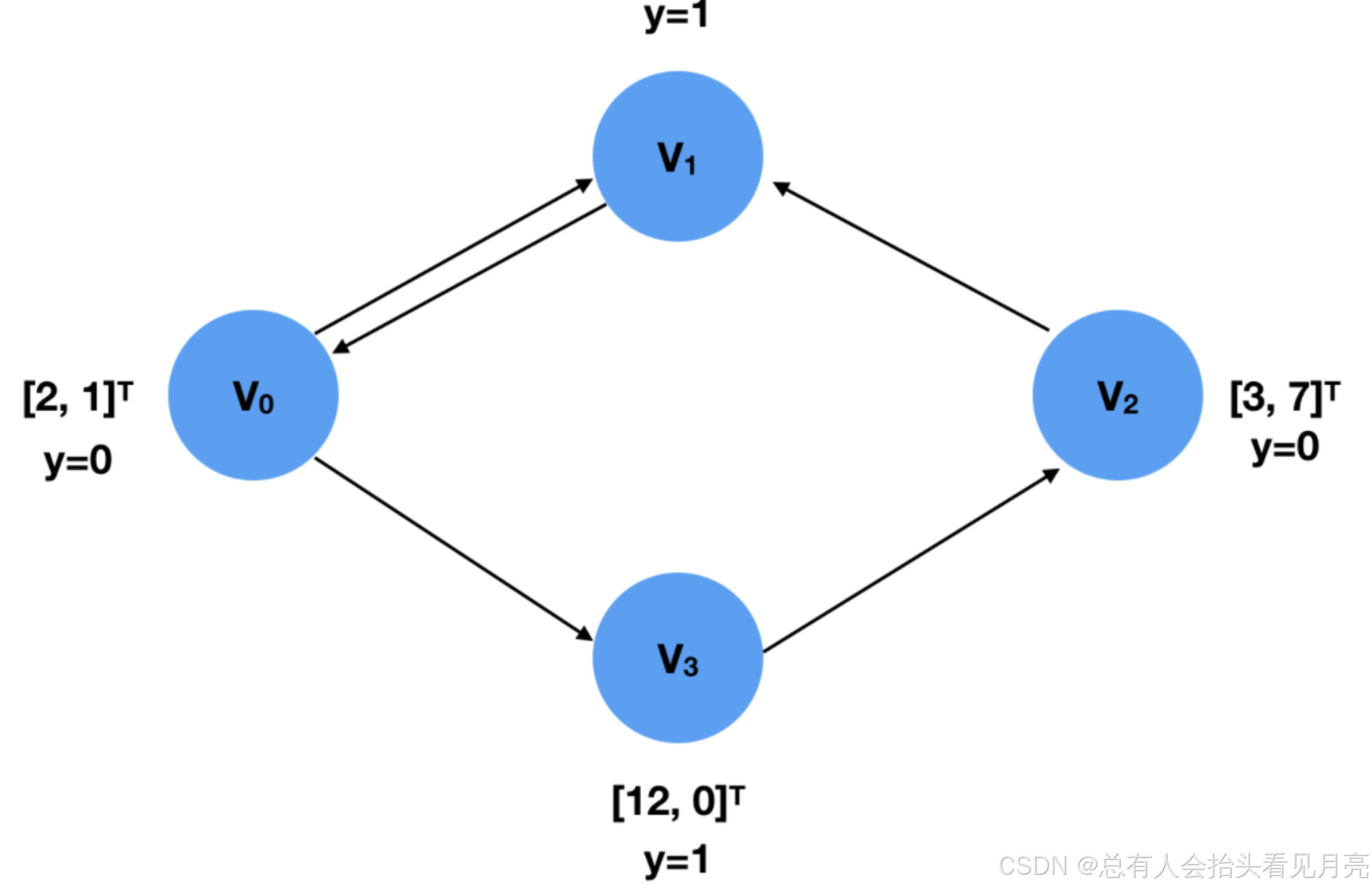
我们的任务是结合给定的这一副图,来构建出符合结构的数据集。
import torch
from torch_geometric.data import Data
# 构造节点和类别
x = torch.tensor([[2,1],[5,6],[3,7],[12,0]],dtype=torch.float)
y = torch.tensor([0,1,0,1],dtype=torch.float)
# 边的顺序无所谓
edge_index = torch.tensor([[0, 1, 2, 0, 3],#起始点
[1, 0, 1, 3, 2]], dtype=torch.long)#终止点
# 输入这些特征构造自己的数据集
data = Data(x=x, y=y, edge_index=edge_index)
print(data)
Data(edge_index=[2, 5], x=[4, 2], y=[4])
实际数据集参考案例
在第二部分我们学习如何将一个指定场景的数据转化成为,图神经网络可以去使用的数据类型。
这里使用的是sklearn中的电商系统用户行为分析的数据来进行学习和使用。
读取这一个数据集
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv('yoochoose-clicks.dat', header=None,low_memory=False)
df.columns = ['session_id', 'timestamp', 'item_id', 'category']
buy_df = pd.read_csv('yoochoose-buys.dat', header=None)
buy_df.columns = ['session_id', 'timestamp', 'item_id', 'price', 'quantity']
item_encoder = LabelEncoder()
df['item_id'] = item_encoder.fit_transform(df.item_id)
df.head()
print(df)
print(df.head())
选择该数据集的一小部分来进行制作。
import numpy as np
#数据有点多,咱们只选择其中一小部分来建模
sampled_session_id = np.random.choice(df.session_id.unique(), 100000, replace=False)
df = df.loc[df.session_id.isin(sampled_session_id)]
print(df.nunique())
session_id 100000
timestamp 357297
item_id 20591
category 123
dtype: int64
获取出标签数据重新的进行输出。
session_id timestamp item_id category label
10 3 2014-04-02T13:17:46.940Z 28989 0 False
11 3 2014-04-02T13:26:02.515Z 35310 0 False
12 3 2014-04-02T13:30:12.318Z 43178 0 False
316 89 2014-04-07T14:12:35.665Z 6240 0 False
317 89 2014-04-07T14:12:51.832Z 2230 0 False
df['label'] = df.session_id.isin(buy_df.session_id)
print(df.head())
数据集的制作流程
咱们把每一个session_id都当作一个图,每一个图具有多个点和一个标签
其中每个图中的点就是其item_id,特征咱们暂且用其id来表示,之后会做embedding
数据集制作流程
- 首先遍历数据中每一组session_id,目的是将其制作成(from torch_geometric.data import Data)格式
- 对每一组session_id中的所有item_id进行编码(例如15453,3651,15452)就按照数值大小编码成(2,0,1)
- 这样编码的目的是制作edge_index,因为在edge_index中我们需要从0,1,2,3…开始
- 点的特征就由其ID组成,edge_index是这样,因为咱们浏览的过程中是有顺序的比如(0,0,2,1)
- 所以边就是0->0,0->2,2->1这样的,对应的索引就为target_nodes: [0 2 1],source_nodes: [0 0 2]
- 最后转换格式data = Data(x=x, edge_index=edge_index, y=y)
- 最后将数据集保存下来(以后就不用重复处理了)
from tqdm import tqdm
df_test = df[:100]
grouped = df_test.groupby('session_id')
for session_id, group in tqdm(grouped):
print('session_id:',session_id)
sess_item_id = LabelEncoder().fit_transform(group.item_id)
print('sess_item_id:',sess_item_id)
group = group.reset_index(drop=True)
group['sess_item_id'] = sess_item_id
print('group:',group)
node_features = group.loc[group.session_id==session_id,['sess_item_id','item_id']].sort_values('sess_item_id').item_id.drop_duplicates().values
node_features = torch.LongTensor(node_features).unsqueeze(1)
print('node_features:',node_features)
target_nodes = group.sess_item_id.values[1:]
source_nodes = group.sess_item_id.values[:-1]
print('target_nodes:',target_nodes)
print('source_nodes:',source_nodes)
edge_index = torch.tensor([source_nodes, target_nodes], dtype=torch.long)
x = node_features
y = torch.FloatTensor([group.label.values[0]])
data = Data(x=x, edge_index=edge_index, y=y)
print('data:',data)
这里是其中的一个制作的过程的结果
node_features: tensor([[ 113],
[ 2910],
[26361],
[29282]])
target_nodes: [2 3 2 1 0 1]
source_nodes: [0 2 3 2 1 0]
data: Data(edge_index=[2, 6], x=[4, 1], y=[1])
session_id: 2748
sess_item_id: [5 2 4 5 4 2 3 5 5 2 2 4 4 4 4 4 4 2 4 5 0 1 1]
group: session_id timestamp item_id category label sess_item_id
0 2748 2014-04-02T13:20:55.298Z 41304 0 False 5
1 2748 2014-04-02T13:22:41.735Z 26294 0 False 2
2 2748 2014-04-02T13:24:20.168Z 39926 0 False 4
3 2748 2014-04-02T13:25:15.644Z 41304 0 False 5
4 2748 2014-04-02T13:25:36.519Z 39926 0 False 4
5 2748 2014-04-02T13:26:18.715Z 26294 0 False 2
6 2748 2014-04-02T13:26:31.468Z 35309 0 False 3
7 2748 2014-04-02T13:26:36.730Z 41304 0 False 5
8 2748 2014-04-02T13:26:48.726Z 41304 0 False 5
9 2748 2014-04-02T13:27:08.813Z 26294 0 False 2
10 2748 2014-04-02T13:27:11.772Z 26294 0 False 2
11 2748 2014-04-02T13:28:18.283Z 39926 0 False 4
12 2748 2014-04-02T13:30:31.885Z 39926 0 False 4
13 2748 2014-04-02T13:31:08.218Z 39926 0 False 4
14 2748 2014-04-02T13:31:21.605Z 39926 0 False 4
15 2748 2014-04-02T13:31:43.433Z 39926 0 False 4
16 2748 2014-04-02T13:32:05.564Z 39926 0 False 4
17 2748 2014-04-02T13:32:23.018Z 26294 0 False 2
18 2748 2014-04-02T13:33:39.146Z 39926 0 False 4
19 2748 2014-04-02T13:33:42.228Z 41304 0 False 5
20 2748 2014-04-02T13:33:44.812Z 14665 0 False 0
21 2748 2014-04-02T13:33:46.957Z 22666 0 False 1
22 2748 2014-04-02T13:34:38.227Z 22666 0 False 1
node_features: tensor([[14665],
[22666],
[26294],
[35309],
[39926],
[41304]])
target_nodes: [2 4 5 4 2 3 5 5 2 2 4 4 4 4 4 4 2 4 5 0 1 1]
source_nodes: [5 2 4 5 4 2 3 5 5 2 2 4 4 4 4 4 4 2 4 5 0 1]
data: Data(edge_index=[2, 22], x=[6, 1], y=[1])
100%|██████████| 21/21 [00:00<00:00, 175.91it/s]
最后简单的进行一下总结:对于图神经网络的部分这里并不会过多的进行学习,主要的目的为了看代码和做实验,使用图神经网络来完成图匹配的过程。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)