11种常用的深度学习图像分割模型(介绍 + 代码)
图像分割是计算机视觉领域的一项关键任务,其中图像中的每个像素被分配给特定的类别或对象。近年来,随着深度学习的发展,图像分割技术取得了长足的进步。本文将介绍11种常用的深度学习模型,帮助你理解和掌握这些强大的工具。【戳下面蓝字,即可跳转到学习页面】U-Net 是一个经典的图像分割模型,最初设计用于生物医学图像分割。其架构采用编码器-解码器结构,通过跳跃连接将低级特征传递到更高级别,从而保留更详细的信
图像分割是计算机视觉领域的一项关键任务,其中图像中的每个像素被分配给特定的类别或对象。
近年来,随着深度学习的发展,图像分割技术取得了长足的进步。
本文将介绍11种常用的深度学习模型,帮助你理解和掌握这些强大的工具。
【戳下面蓝字,即可跳转到学习页面】
【2025】这才是科研人该学的pytorch教程!通俗易懂,完全可以自学,7天带你构建神经网络,解决pytorch框架问题!深度学习|机器学习|人工智能
深度学习八大算法真不难!一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM八大神经网络!机器学习|卷积神经网络|pytorch
 1. U-Net
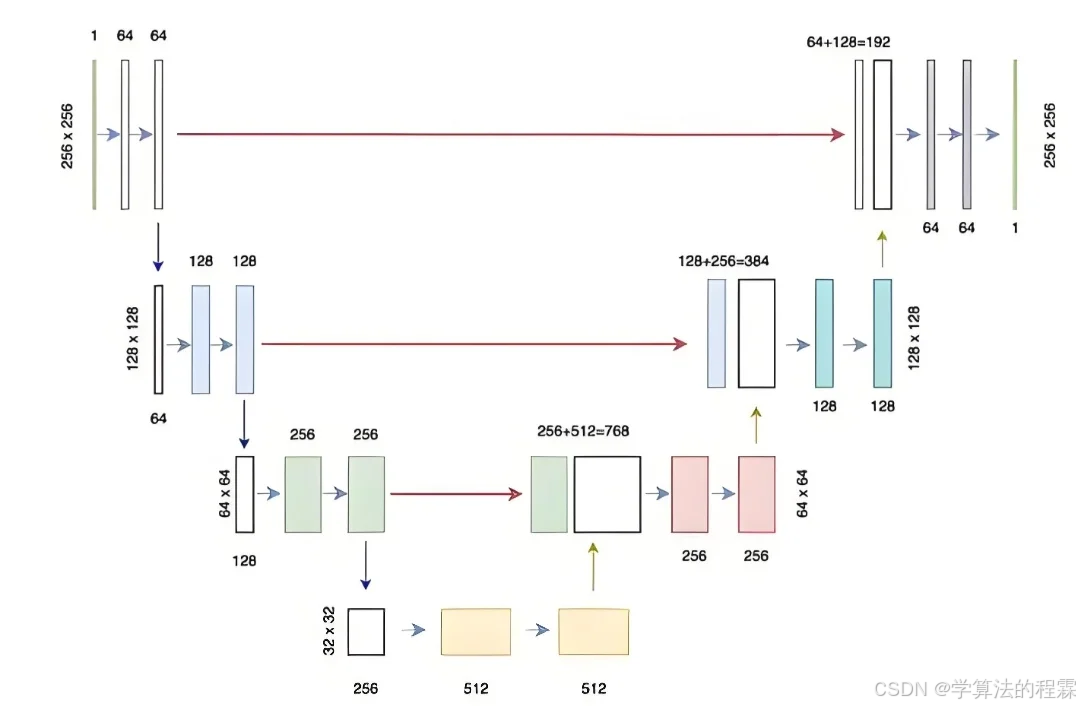
1. U-Net
U-Net 是一个经典的图像分割模型,最初设计用于生物医学图像分割。其架构采用编码器-解码器结构,通过跳跃连接将低级特征传递到更高级别,从而保留更详细的信息。
代码示例:
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(UNet, self).__init__()
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Decoder part
self.decoder = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(64, out_channels, kernel_size=2, stride=2)
)
def forward(self, x):
# Encoder
x1 = self.encoder(x)
# Decoder
x2 = self.decoder(x1)
return x2
# Create model instance
model = UNet(in_channels=3, out_channels=1)
print(model)输出:
UNet(
(encoder): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(decoder): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): ConvTranspose2d(64, 1, kernel_size=(2, 2), stride=(2, 2), padding=(0, 0))
)
) 2. DeepLab v3+
DeepLab v3+ 是一个基于卷积神经网络的分割模型,利用空洞卷积来捕捉多尺度信息,并通过 ASPP(空洞空间金字塔池化)模块增强其表达能力。
代码示例:
import torchvision.models.segmentation as segmentation_models
# Load pretrained DeepLab v3+ model
model = segmentation_models.deeplabv3_resnet101(pretrained=True)
# Modify output channels
model.classifier[4] = nn.Conv2d(256, 1, kernel_size=1)
print(model) 输出:
DeepLabV3(
(backbone): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Bottleneck(...)
(layer2): Bottleneck(...)
(layer3): Bottleneck(...)
(layer4): Bottleneck(...)
)
(classifier): DeepLabHead(
(aspp): ASPP(
(convs): ModuleList(
(0): ASPPConv(...)
(1): ASPPConv(...)
(2): ASPPConv(...)
(3): ASPPPooling(...)
)
(project): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
)
)
(classifier): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
(aux_classifier): None
) 3. Mask R-CNN
Mask R-CNN 是基于 Faster R-CNN 的实例分割模型,不仅可以检测图像中的物体,还可以为每个物体生成像素级的 mask。
代码示例:
import torchvision.models.detection.mask_rcnn as mask_rcnn
# Load the pretrained Mask R-CNN model
model = mask_rcnn.maskrcnn_resnet50_fpn(pretrained=True)
# Modify the number of output classes
model.roi_heads.box_predictor.cls_score.out_features = 2
model.roi_heads.box_predictor.bbox_pred.out_features = 8
model.roi_heads.mask_predictor.mask_fcn_logits.out_channels = 1
print(model) 
4. PSPNet
PSPNet(金字塔场景解析网络)是一个基于金字塔池化的图像分割模型,通过不同尺度的池化操作来捕捉全局上下文信息。
代码示例:
import torchvision.models.segmentation as segmentation_models
# Load the pretrained PSPNet model
model = segmentation_models.fcn_resnet101(pretrained=True)
# Modify the number of output channels
model.classifier[4] = nn.Conv2d(512, 1, kernel_size=1)
print(model) 5. SegNet
SegNet 是一种基于编码器 - 解码器架构的图像分割模型。它使用最大池化索引进行上采样,这有助于保留更详细的信息。
代码示例:
import torch
import torch.nn as nn
class SegNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(SegNet, self).__init__()
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
)
# Decoder part
self.decoder = nn.Sequential(
nn.MaxUnpool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1)
)
def forward(self, x):
# Encoder
x, indices = self.encoder(x)
# Decoder
x = self.decoder((x, indices))
return x
# Create model instance
model = SegNet(in_channels=3, out_channels=1)
print(model) 6. LinkNet
LinkNet 是一个轻量级的图像分割模型,通过跳过连接来连接编码器和解码器,减少参数数量并提高计算效率。
代码示例:
import torch
import torch.nn as nn
class LinkNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(LinkNet, self).__init__()
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Decoder part
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1)
)
def forward(self, x):
# Encoder
x1 = self.encoder(x)
# Decoder
x2 = self.decoder(x1)
return x2
# Create model instance
model = LinkNet(in_channels=3, out_channels=1)
print(model) 7. HRNet
HRNet(High-Resolution Network)是一种高分辨率网络,通过多尺度融合和并行处理来保持高分辨率的特征图,从而提高分割精度。
代码示例:
import torch
import torch.nn as nn
class HRNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(HRNet, self).__init__()
# High-resolution branch
self.high_res_branch = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
# Low-resolution branch
self.low_res_branch = nn.Sequential(
nn.Conv2d(in_channels, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Fusion module
self.fusion = nn.Sequential(
nn.Conv2d(96, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, out_channels, kernel_size=1)
)
def forward(self, x):
# High-resolution branch
high_res = self.high_res_branch(x)
# Low-resolution branch
low_res = self.low_res_branch(x)
# Upsample low-resolution feature map
low_res_upsampled = nn.functional.interpolate(low_res, scale_factor=2, mode='bilinear', align_corners=True)
# Fuse high-resolution and low-resolution feature maps
fused = torch.cat([high_res, low_res_upsampled], dim=1)
# Output
output = self.fusion(fused)
return output
# Create model instance
model = HRNet(in_channels=3, out_channels=1)
print(model) 8. RefineNet
RefineNet 是一个多路径细化网络,它通过多路径细化模块逐步细化特征图,从而提高分割精度。
代码示例:
import torch
import torch.nn as nn
class RefineNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(RefineNet, self).__init__()
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Multi-path refinement module
self.refine_module = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
# Decoder part
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1)
)
def forward(self, x):
# Encoder
x1 = self.encoder(x)
# Multi-path refinement
x2 = self.refine_module(x1)
# Decoder
x3 = self.decoder(x2)
return x3
# Create model instance
model = RefineNet(in_channels=3, out_channels=1)
print(model) 9. BiSeNet
BiSeNet(双边分割网络)是一种高效的实时图像分割模型,它通过空间和上下文路径分别捕获空间细节和全局上下文信息。
代码示例:
import torch
import torch.nn as nn
class BiSeNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(BiSeNet, self).__init__()
# Spatial Path
self.spatial_path = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
# Context Path
self.context_path = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Fusion Module
self.fusion = nn.Sequential(
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, out_channels, kernel_size=1)
)
def forward(self, x):
# Spatial Path
spatial = self.spatial_path(x)
# Context Path
context = self.context_path(x)
# Upsample context feature map
context_upsampled = nn.functional.interpolate(context, scale_factor=2, mode='bilinear', align_corners=True)
# Fuse spatial and context feature maps
fused = torch.cat([spatial, context_upsampled], dim=1)
# Output
output = self.fusion(fused)
return output
# Create model instance
model = BiSeNet(in_channels=3, out_channels=1)
print(model) 10. OCRNet
OCRNet(用于语义分割的对象上下文表示)是一种利用对象上下文表示来改进语义分割的模型。它通过注意力机制增强特征图的表现力。
代码示例:
import torch
import torch.nn as nn
class OCRNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(OCRNet, self).__init__()
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# Object-context module
self.object_context = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
# Decoder part
self.decoder = nn.Sequential(
nn.Conv

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)