一次生产事故复盘:服务报 “Failed to obtain JDBC Connection” 的完整排查与解决
摘要 本文复盘了一次生产环境数据库连接耗尽事故。问题表现为"Failed to obtain JDBC Connection"错误,最初误判为连接泄漏,实际排查发现是慢SQL长时间占用连接所致。一条包含相关子查询的SQL执行时间超过40分钟,导致连接池被耗尽。文章详细分析了问题成因、排查过程,并提出优化方案:添加复合索引、避免相关子查询、分批处理和限制任务并发。最终强调,遇到连
一次生产事故复盘:服务报 “Failed to obtain JDBC Connection” 的完整排查与解决
一、问题现象
系统运行一段时间后,开始频繁出现如下异常:
Failed to obtain JDBC Connection;
nested exception is java.sql.SQLTransientConnectionException:
swxx - Connection is not available, request timed out after 30000ms.
表现为:
- 接口全部超时
- 定时任务报错
- 数据库连接获取失败
- 服务响应变慢
- 服务器 CPU 飙升接近 100%
重启服务后短暂恢复,运行一段时间再次复现。
二、第一反应(错误判断)
看到这个异常,第一直觉是:
是不是数据库连接泄漏了?
于是我做了这些操作:
1️⃣ 开启连接泄漏检测
remove-abandoned: true
remove-abandoned-timeout: 180
log-abandoned: true
2️⃣ 开启连接保活
test-while-idle: true
validation-query: SELECT 1
time-between-eviction-runs-millis: 60000
结果:
❌ 问题依旧存在
❌ 没有明显泄漏日志
三、进一步排查
1️⃣ 查看数据库连接数
show global status like 'Threads_connected';
发现:
- 服务启动前:241
- 启动后:271
只增加了 30 个连接。
说明:
不是连接无限增长型泄漏
2️⃣ 查看正在执行的 SQL
show processlist;
发现大量相同 SQL:
- 状态:
Sending data - 执行时间:2000+ 秒
- 同一条 SQL 被并发执行
而且:
最长执行时间超过 40 分钟还未结束。
问题开始清晰。
四、真正原因
核心问题不是连接泄漏。
而是:
慢 SQL 长时间占用数据库连接,导致连接池被耗尽。
问题 SQL 结构(核心片段)
and not (
dpg <= CASE ...
AND (
SELECT SUM(t2.drp)
FROM wxddz_r_202602 t2
WHERE t2.adz = t1.adz
AND t2.ecd = t1.ecd
AND t2.tm > DATE_SUB(t1.tm, INTERVAL 24 HOUR)
AND t2.tm <= t1.tm
) <= CASE ...
)
这是一个:
相关子查询(Correlated Subquery)
含义是:
- 外层扫描一行
- 内层子查询再执行一次
如果外层扫描 10 万行:
👉 内层子查询就执行 10 万次
👉 每次还可能扫描大量数据
这是指数级性能灾难。
五、连锁反应机制
整个问题的完整链路是:
1️⃣ SQL 执行时间极长(40分钟)
2️⃣ 连接一直被占用
3️⃣ 连接池 maxActive 很小(如 6)
4️⃣ 新请求无法获取连接
5️⃣ 30秒后超时
6️⃣ 报 Failed to obtain JDBC Connection
7️⃣ 由于数据库疯狂扫表
8️⃣ CPU 被打满
这不是连接不释放。
而是:
连接被“合法地”长时间占用。
六、为什么 CPU 会爆满?
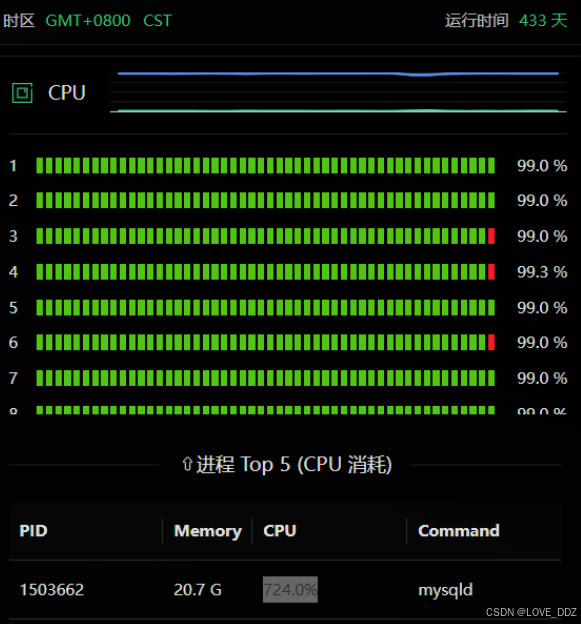
MySQL 状态显示:
Sending data
这通常意味着:
- 正在做大量数据扫描
- 可能 using temporary
- 可能 using filesort
- 没有命中索引
如果是全表扫描 + 子查询循环扫描:
数据库 CPU 会持续 100%。
七、根本优化方案
方案一:加复合索引(必要)
如果没有如下索引:
ALTER TABLE wxddz_r_202602
ADD INDEX idx_adz_ecd_tm (adz, ecd, tm);
子查询必定全表扫。
这是第一步。
方案二:避免相关子查询
相关子查询是性能杀手。
优化思路:
- 先汇总 24 小时数据
- 再 JOIN
- 或改为分批处理
- 或程序层面计算
在 MySQL5.7 没有窗口函数的情况下:
可以改为临时汇总表。
方案三:分批处理
原 SQL:
WHERE t1.id > 9062999 AND t1.id < 9076452
如果数据量大:
建议:
- 分批 1000 条
- 逐批计算
- 控制并发
不要一次性大范围扫描。
方案四:限制定时任务并发
如果是 Quartz 任务:
@DisallowConcurrentExecution
避免同一任务并发执行。
否则慢任务未完成,新任务又启动。
八、数据库参数是否有帮助?
比如:
max_connections=400
是否有用?
答案:
❌ 没本质帮助
如果慢 SQL 不解决:
- 400 个连接 = 400 个慢查询
- 数据库更快崩溃
根因不在连接数。
九、事故总结
这次问题本质是:
规则计算型 SQL 被写成在线实时查询
且使用相关子查询导致指数级性能问题
最终表现为:
- 连接池耗尽
- JDBC 获取失败
- 服务不可用
- CPU 爆满
十、经验总结(非常重要)
1️⃣ 出现 JDBC Connection is not available
不要第一时间怀疑连接泄漏。
先做:
show processlist;
看是否有长时间 SQL。
2️⃣ 相关子查询慎用
结构像:
select ...
where exists (
select ...
)
在大表中极易出问题。
3️⃣ 定时任务必须控制并发
慢任务叠加是灾难。
4️⃣ 数据规则计算应尽量:
- 批处理
- 预汇总
- 离线计算
不要在线复杂聚合。
最终结论
这次问题不是连接池问题。
不是 max_connections 问题。
不是连接泄漏问题。
而是:
一条极慢 SQL 长时间占用连接,导致连接池耗尽。
当你看到:
Failed to obtain JDBC Connection
请优先排查:
是否存在长时间执行的慢 SQL。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)