神经网络与深度学习课程总结(二)——卷积神经网络
这16个卷积核分别是下图中的3,4,6通道的卷积核,输出图像的大小为10*10*16.训练的参数有6*[5*5*3+1]+9*[5*5*4+1]+1*[5*5*6+1]=1516;第二层S2:池化层2*2步长2,下采样,输入28*28*6输出为14*14*6;14*14*6*(2*2+1)=5880个连接。第四层S4:同S2操作,池化层2*2步长2,输入为10*10*16,输出为(10-2+2)/
目录
一、PyTorch的基本使用
PyTorch官方教程中文版 (pytorch123.com)
1.使用tensor张量表示数据:tensor是一个物理量,对高维 (维数 ≥ 2) 的物理量进行“量纲分析” 的一种工具。简单的可以理解为:一维数组称为矢量,二维数组为二阶张量,三维数组为三阶张量
2.利用Dataset,Dataloader读取数据;
3. 使用变量 (Variable) 存储神经网络权值等参数
4.使用计算图 (computational graph) 来表示计算任务
深度之眼Pytorch打卡(五):Pytorch计算图(动态图与静态图)与自动求导tensor.backgrad()-CSDN博客
5.在代码运行过程中同时执行计算图
二、卷积神经网络
1.基本概念
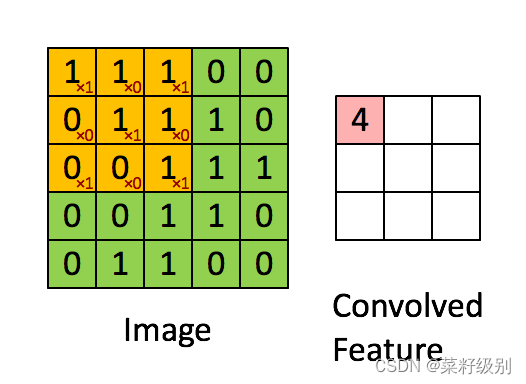
传统的全连接网络收敛较慢,计算量大(每一层的神经元之间都是全连接的,连接数数目=参数个数),通过卷积的局部链接,权值共享可以实现参数的减少,大大提高了特征提取的效率。卷积操作本质是一个固定大小的模板对选中区域的数据进行加权求和后的结果,是一种信号的滤波。此外,卷积网络感视野同人眼睛对于局部信息捕捉的特点相符合。在卷积神经网络中,卷积层的神经元只与前一层的部分神经元节点相连,即它的神经元间的连接是非全连接的,且同一层中某些神经元之间的连接的权重和偏移是相同的,这样大量地减少了需要训练参数的数量。卷积操作如图所示:卷积神经网络一开始兴起于图像处理领域,左图的各个小块可以看作是像素点,其上的右下角的红色数值为卷积视野上的卷积核权重,右侧图第一个子块为左图中橙色区域各子块的加权求和即:1+0+1+0+1+0+0+0+1=4,将卷积核依次从左向右从上大小平移得到结果为特征图原图5x5卷积操作后→3x3,存在边缘效应。
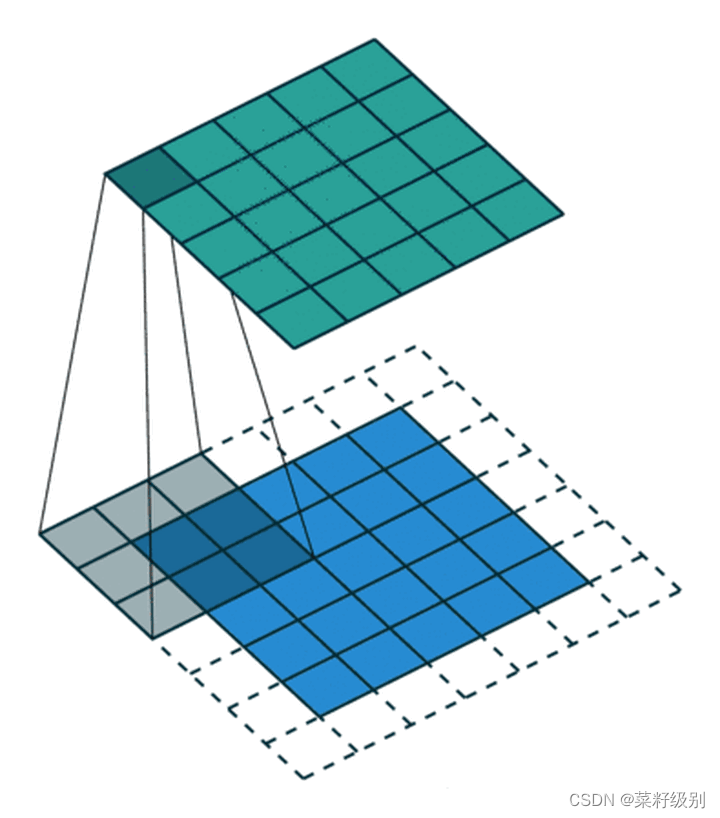
因此如果要实现尺度的不变需要对原图进行边缘填充,即padding,填充后的输出可以实现原输入的尺寸,如下图:
2.CNN的结构
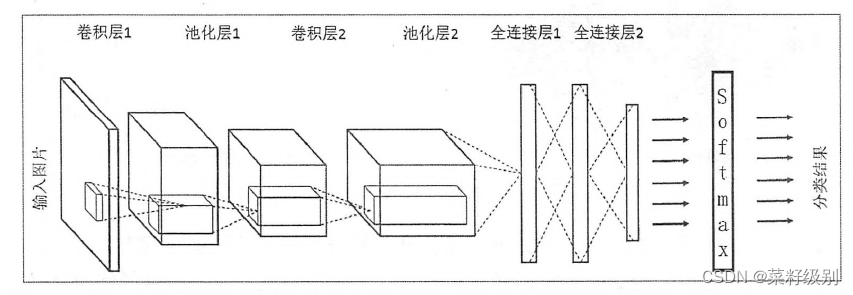
1)输入层:用于数据的输入;(CNN的输入层的输入格式保留了图片本身的结构。)
2)卷积层:使用卷积核进行特征提取和特征映射;
隐藏层中的神经元的感受视野比较小,隐藏层中的神经元具有一个固定大小的感受视野去感受上一层的部分特征,只能看到上一次的部分特征上一层的其他特征可以通过平移感受视野来得到同一层的其他神经元。
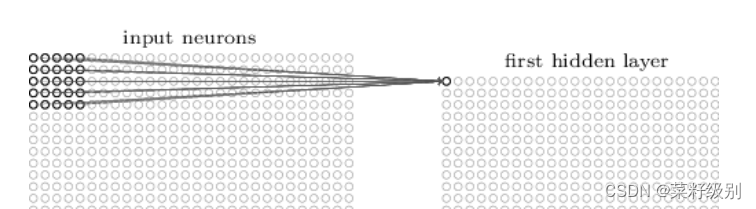
一个感受视野带有一个卷积核,我们将感受视野中的权重w矩阵称为卷积核(权值共享),将感受视野对输入的扫描间隔称为步长(stride);当步长比较大时(stride>1),为了扫描到边缘的一些特征,感受视野可能会“出界”,这时需要对边界扩充(pad),边界扩充可以设为0或其他值。卷积核、步长和边界扩充值的大小由用户来定义。感受视野扫描时可以计算出下一层神经元的值为:
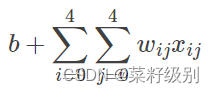
一个带有卷积核的感受视野扫描生成的下一层神经元矩阵称为 一个feature map (特征映射图)一个feature map对应一个卷积核,若我们使用3个不同的卷积核,可以输出3个feature map。即一个卷积核可提取一个关键特征,为了不遗漏关键特征可以采用多个卷积核。假如感受视野为5×5步长为1,则在卷积层需要训练的参数为5×5×1×3=75个。对于有深度的二维输入数据,感受视野增加一个深度的参数。
 3)激励层:由于卷积也是一种线性运算,因此需要增加非线性映射;
3)激励层:由于卷积也是一种线性运算,因此需要增加非线性映射;
激励层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算还是一种线性计算。使用的激励函数一般为ReLu函数:
f(x)=max(x,0)

Relu函数图像
4)池化层:进行下采样(down sampling)对特征图稀疏处理,减少数据运算量(参数约减);实现变换不变性(一定的抗干扰能力)
池化层和卷积层的操作基本相同,也采用局部连接。若感受视野比较小,布长stride比较小,得到的feature map(特征图)还是比较大,可以通过池化层来对每一个 feature map 进行降维操作,输出的深度还是不变的,依然为 feature map 的个数。
池化层也有一个“filter”来对feature map矩阵进行扫描,对“filter”中的矩阵值进行计算,一般有两种计算方式:
- 最大池化Max pooling:取“filter”矩阵中的最大值
- 平均池化Average pooling:取“池化视野”矩阵中的平均值
扫描的过程中同样地会涉及的扫描布长stride,扫描方式同卷积层一样,先从左到右扫描,结束则向下移动布长大小,再从左到右。
5)全连接层:(一维拼接)通常在CNN的尾部进行重新拟合,减少特征信息的损失;
6)输出层:用于输出结果,输出为训练好的网络。
输出层一般为logistic层和softmax层构成对输出分类
- logistics二分类模型:目标变量Y为0,1;添加激活函数sigmoid函数
- softmax多分类模型:可以将多个神经元的输出映射到(0,1)区间内, 输出结果可以看成数据被分为每个类的概率。假设有数组V, Vi表示V中的第i个元素,则此元素的softmax值为:

其中j为分类的类别数。
小结:卷积神经网络可分为局部特征识别,全局分类判决两个部分。其中局部特征识别阶段由输入层和交替出现的卷积层和池化层构成;全局分类判决包括两层以上的全连接层和输出层构成。
Conv1D、Conv2D 和 Conv3D 是三种不同的卷积层,它们都是用于处理一维、二维和三维数据的卷积运算。Conv1D 层是对一维数据进行卷积,常用于处理序列数据,如文本、音频和时间序列。它的输入是一个二维张量,第一维表示时间步数,第二维表示每个时间步的特征维度。Conv2D 层是对二维数据进行卷积,常用于处理图像数据。它的输入是一个三维张量,第一维和第二维表示图像的高度和宽度,第三维表示图像的通道数。Conv3D 层是对三维数据进行卷积,常用于处理视频数据或三维图像数据。它的输入是一个四维张量,第一维、第二维和第三维表示三维图像的长、宽和高,第四维表示图像的通道数。
补充:卷积核与神经元个数之间的关系
卷积网络计算_卷积神经网络神经元个数怎么计算-CSDN博客 https://blog.csdn.net/m0_37313123/article/details/90143032
https://blog.csdn.net/m0_37313123/article/details/90143032
3.典型的卷积神经网络:
LeNet-5模型、AlexNet 模型、VGGNet 模型、GoogleNet 模型:

4.卷积神经网络的计算
1)向前传播过程
(1)从样本中读取(x,y),将x输入网络。
(2)计算相应的实际输出。
在此阶段,信息从输入层经过逐层变换,传送到输出层,输出层与每层的权值矩阵点乘,得到输出结果。

2)误差反向传播阶段
(1)计算实际输出与理想输出的差值(误差反向传播)。以y为实际输出,J(W,b)为误差函数。
网络输出层上游误差:

三、卷积模型的实现
1.手写数字识别模型LeNet-5:

LeNet-5: Gradient-Based Learning Applied to Document Recognitionm_lenet-5 grandient-based learing apply to document -CSDN博客https://blog.csdn.net/Indus_permanent/article/details/80161742?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-80161742-blog-105730556.235%5Ev43%5Epc_blog_bottom_relevance_base8&spm=1001.2101.3001.4242.2&utm_relevant_index=4原论文:Gradient-Based Learning Applied to Document Recognition
第一层C1:卷积层——原始输入图片为32*32,采用6个5*5卷积核输入进行卷积; 每个神经元对应5*5+1(1为全卷积操作中参数)个参数,输出共6个feature map,28*28个神经元,共有(5*5+1)*6*(28*28)=122,304连接;[5*5+1]*6=156个参数
第二层S2:池化层2*2步长2,下采样,输入28*28*6输出为14*14*6;文中将每个池化模块有两个参数,池化层最终训练参数为2*6=12个;14*14*6*(2*2+1)=5880个连接

第三层C3:卷积层——文中采用16个5*5的卷积核对输入的14*14*6进行特征提取;这16个卷积核分别是下图中的3,4,6通道的卷积核,输出图像的大小为10*10*16.训练的参数有6*[5*5*3+1]+9*[5*5*4+1]+1*[5*5*6+1]=1516;模型的连接有10*10*1516个。

第四层S4:同S2操作,池化层2*2步长2,输入为10*10*16,输出为(10-2+2)/2=5*5*16,参数为16*2=32个,连接为5*5*16*(2*2+1)=2000。
第五层C5:120个1*1*16的卷积核,相当于全连接,输入为5*5*16,输出为1*1*120,每一个连接对应一个参数共有(5*5*16+1)*120=48120.
第六层F6:84个神经元,与C5全连接,总连接(参数):(120+1)*84=10164
输出层:10(0-9个数字识别),由欧式径向基函数单元构成,每类一个单元,输出RBF单元计算输入向量和参数向量之间的欧式距离——这种方法一般不用现在,取而代之的是sigmoid或者softmax代码如下:
#LeNet-5
import torch
from torch import nn
from d2l import torch as d2l
#构建模型
net = nn.Sequential(#Sequential用于构建模型的前向传播框架
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))#去掉了最后一层的高斯激活,采用sigmoid
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)#这里不同于原模型输入设置为28*28
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)模型显示


batch_size = 256
#选用Fashion‐MNIST数据集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]#加载到GPU上
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
#模型初始化
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())模型训练结果:

说明:
1.LeNet-5与现在网络的区别:-卷积时不进行填充( padding); -池化层选用平均池化而非最大池化;选用Sigmoid或tanh而非ReLU作为非线性环节激活函数-层数较浅,参数数量小(约为6万)
2.普遍规律-随网络深入,宽、高衰减,通道数增加

卷积模型的可视化平台:An Interactive Node-Link Visualization of Convolutional Neural Networks (adamharley.com)3D Visualization of a Convolutional Neural Network (adamharley.com)
2. AlexNet
原论文:ImageNet Classification with Deep Convolutional Neural Networks重读经典:《ImageNet Classification with Deep Convolutional Neural Networks》-CSDN博客
网络结构:


和LeNet-5结构对比:


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)