深度学习模型部署(四)——RKNN
官方下载地址:https://gitcode.com/gh_mirrors/rk/rknn-toolkit/tree/master?非RKNN模型经过转换得到的RKNN模型可以在模拟器上推理,也可以在开发板上推理;参考:https://blog.csdn.net/qq_40280673/article/details/136211086#/链接: https://pan.baidu.com/s/1
写在之前,这篇文章很长,包含了环境配置、模型转化、推理、量化和部署,作者边学边写,历时两周终于完成啦!!!
一、RKNN部署及工具包安装
参考1:https://blog.csdn.net/qq_40280673/article/details/136211086#/
参考2:瑞芯微官方教程
RKNN部署针对瑞芯微芯片优化,支持NPU硬件加速,需要安装rknn-toolkit,用于将pytorch模型转换为RKNN模型
以下操作均在ubuntu中进行
运行环境要求如下: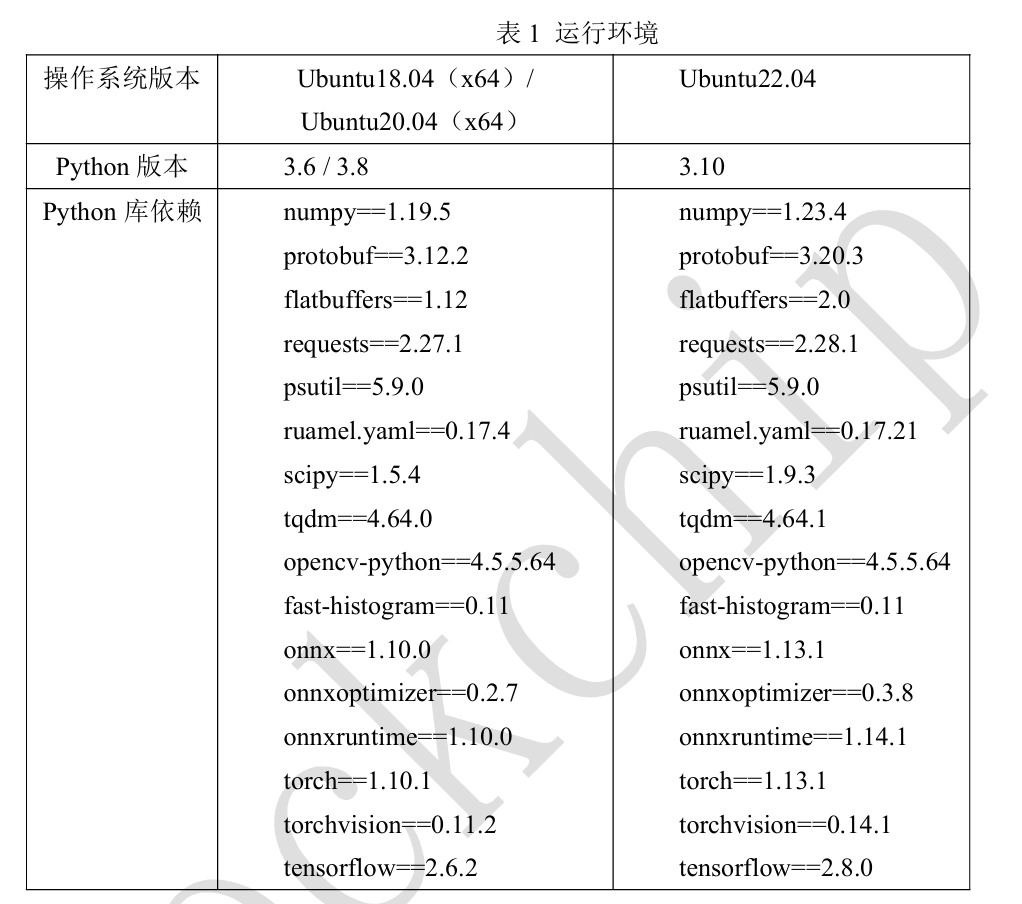
1、安装python及相关依赖
sudo apt-get install python3 python3-dev python3-pip
sudo apt-get install libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 libgl1-mesa-glx libprotobuf-dev gcc
2、创建虚拟环境
# 创建虚拟环境
conda create -n your_env_name
# 激活虚拟环境
conda activate your_env_name
3、下载系统依赖及rknn-tookit安装包
系统依赖的库:requirements_cpxx-1.5.0.txt;
rknn-toolkit2安装包:rknn_toolkit2-1.5.0+fa95b5c-cpxx-linux_x86_64.whl
上述两个文件自取:
通过网盘分享的文件:libpackages
链接: https://pan.baidu.com/s/10xjTZ2Wr8CgGFV80tfXmZA 提取码: wwzn
【注】 cpxx取决于安装的python版本,如我的环境是ubuntu22.04,python版本3.10,因此我需要安装的是requirements_cp310-1.5.0.txt和rknn_toolkit2-1.5.0+fa95b5c-cp310-linux_x86_64.whl
4、安装系统依赖及rknn-toolkit2
激活需要安装的虚拟环境,运行以下指令时,执行目录须为txt文件和whl文件所在目录,也可以指定文件所在路径
pip install -r requirements_cp310-1.5.0.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install rknn_toolkit2-1.5.0+1fa95b5c-cp310-cp310-linux_x86_64.whl -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
【注】 安装过程中可能有包下载不成功,可以手动pip安装,多试几个镜像源,或者爬梯子安装,一定要确保所有包安装成功
二、pytorch模型转换为rknn模型
我的文件结构如下: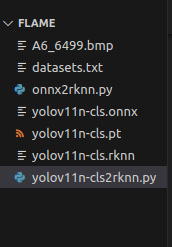
datasets.txt的内容为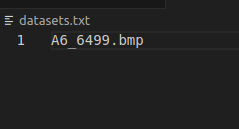
1、torch.nn.module——>rknn
参考1:https://blog.csdn.net/qq_40280673/article/details/136229500#/ 大佬的公众号有源码包,可以下载后执行
我参考着导出了一下yolov11n-cls模型:
【注】 要使用相同版本的pytorch导出模型并转为RKNN模型,否则会因为前后版本不一致导致RKNN转换失败。
# yolov11n-cls.pt转rknn模型
'''
1、导入RKNN包
2、实例化RKNN对象
3、定义数据预处理和量化方法
4、加载pytorch模型,即'.pt'文件
5、构建rknn模型
6、导出rknn模型
7、释放RKNN对象
'''
from rknn.api import RKNN
if __name__=="__main__":
rknn = RKNN()
'''
初始化RKNN对象时,可以设置verbose和verbose_file参数:
verbose:是否在屏幕上打印详细的日志信息
verbose_file:日志文件
示例:将详细日志信息输出到屏幕,并写入到build.log文件中
rknn=RKNN(verbose=True,verbose_file='./build.log')
'''
rknn.config(
mean_values=[[0.0, 0.0, 0.0]],
std_values=[[1.0, 1.0, 1.0]],
target_platform='rk3588'
)
'''
def config(
mean_values: Any | None = None,
输入的均值,用于数据预处理中的normalization,如mean_values=[128, 128, 128]]表示输入的三个通道的值减去128
std_values: Any | None = None,
输入的标准差,用于数据预处理中的normalization,如std_values=[[128, 128, 128]]表示输入的三个通道减去均值后再除以128
quantized_dtype: str = 'asymmetric_quantized-8',
量化类型,目前支持asymmetric_quantized-8、asymmetric_quantized-16
quantized_algorithm: str = 'normal',
计算每一层的量化参数时采用的量化算法,目前支持normal、mmse和kl_divergence
normal:速度快,推荐量化数据量一般为20-100张左右
mmse:暴力迭代方式,速度较慢,但精度比normal要高,推荐量化数据量20-50张左右
kl_divergence:所有时间比normal多,比mmse少,适用于feature分布不均匀的场景,推荐量化数据量20-100张左右
quantized_method: str = 'channel',
目前支持layer、channel
layer:每层的weight只有一套量化参数
channel:每层的weight的每个通道都有一套量化参数,因此channel会比layer精度高
target_platform: Any | None = None,
指定RKNN模型是基于那个目标芯片平台生成的,目前支持‘rk3566’、‘rk3588’等
quant_img_RGB2BGR: bool = False,
表示在加载量化图像时是否需要先做RGB2BGR的操作(一般用在Caffe模型上)。如果有多个输入,则用列表包括起来,如[True, True, False]
该配置只对jpg/jpeg/png/bmp格式的图片有效
该配置仅用于量化阶段(build接口)读取量化图像或量化精度分析(accuracy_analysis接口),并不会保存在最终的RKNN模型中,因此如果模型的输入为bgr,则调用toolkit2的inference或C-API的run函数之前需要保证传入的图像数据为BGR格式
float_dtype: str = 'float16',
用于制定非量化情况下的浮点的数据类型,目前只支持float16
optimization_level: int = 3,
模型优化等级,通过修改该值可以关掉部分或全部模型转换过程中使用到的优化规则
optimization_level=3:打开所有优化选项
optimization_level=1或2:关闭一部分可能会对部分模型精度产生影响的优化选项
optimization_level=0:关闭所有优化选项
custom_string: Any | None = None,
添加自定义字符串信息到RKNN模型,可以在runtime时通过query查询到该信息,方便部署时根据不同的RKNN模型做特殊处理
remove_weight: bool = False,
去除conv等权重以生成一个RKNN的从模型,该从模型可以与带完整权重的RKNN模型共享权重以减少内存消耗
compress_weight: bool = False,
压缩模型权重,可以减小RKNN模型的大小
inputs_yuv_fmt: Any | None = None,
single_core_mode: bool = False,
是否仅生成单核模型,可以减小RKNN模型的大小和内存消耗,目前仅对RK3588生效
dynamic_input: Any | None = None,
用于根据用户制定的多组输入shape,来模拟动态输入的功能,
格式为[[input0_shapeA, input1_shapeA, ...], [input0_shapeB, input1_shapeB, ...], ...]
假设原始模型只有一个输入,shape为[1, 3, 224, 224],但需要该模型支持3种不同的输入shape,如[1, 3, 224, 224], [1, 3, 192, 192]和[1, 3, 160, 160]
可以设置dynamic_input=[1, 3, 224, 224], [1, 3, 192, 192]和[1, 3, 160, 160],转换成RKNN模型后进行推理时,需要传入对应shape的数据
【注】需要原始模型支持动态输入才可以开启此功能
model_pruning: bool = False,
对模型进行无损剪枝,对于权重稀疏的模型,可以减小转换后RKNN模型的大小和计算量
op_target: Any | None = None,
用于指定OP的具体执行目标(如NPU/CPU/GPU等)
格式为{'op0_output_name':'cpu', 'op1_output_name':'npu',...}
'op0_output_name'和'op1_output_name'对应op的输出tensor名,可以通过精度分析(accuracy_analysis)返回结果中获取
'cpu'和'npu'表示该tensor对应的op的执行目标是CPU或NPU
**kwargs: Any
)
无返回值
'''
rknn.load_pytorch(
model = "yolov11n-cls.pt",
input_size_list = [[1, 3, 480, 480]]
)
'''
def load_pytorch(
model: Any,
pytorch模型文件(.pt)路径,必须是torchscript格式的
input_size_list: Any
每个输入节点对应的shape,所有输入shape存放在一个列表中
)
返回值:0:导入成功;-1;导入失败
'''
rknn.build(
do_quantization=True,
dataset='datasets.txt'
)
'''
def build(
do_quantization: bool = True,
是否对模型进行量化
dataset: Any | None = None,
用于量化校正的数据及,目前仅支持文本文件格式,用户可以把用于校正的图片(jpg、bmp或png格式)放到一个.txt文件中,文本文件中每一方存放一条路径信息,如a.jpg
如果有多个输入,每个输入对应的文件用空格隔开,如a.jpg b.jpg
rknn_batch_size: Any | None = None
模型的输入batch参数调整,如果设置为大于1,则可以在一次推理中同时推理多帧输入图像或输入数据
会同时改变输入和输出的batch
)
返回值:0:构建成功;-1:构建失败
'''
rknn.export_rknn(
export_path="yolov11n-cls.rknn"
)
'''
def export_rknn(
export_path: Any,
导出模型文件的路径
cpp_gen_cfg: Any | None = None,
是否生成C++部署示例,生成文件:模型路径同文件夹下,
生成rknn_deploy_demo文件夹、说明文档;
支持验证模型推理是,各CAPI接口耗时;验证推理结果的余弦精度;支持常规API接口;支持图片/NPY输入
**kwargs: Any
)
返回:0:导出成功;-1:导出失败
'''
print("finisned")
rknn.release()
2、torch.nn.module——>onnx——>rknn
可以通过onnx作为中转解决pytorch导出和转换rknn模型的版本不一致问题
参考2:瑞芯微的官方教程
可以看出,onnx转rknn的程序与torch模型转rknn唯一的不同就是在加载模型时,使用load_onnx()
【注】 onnx的opset版本需要注意,如果导出失败可以根据报错提示,去修改导出onnx文件中的opset的版本号,如报错信息为ValueError: Unsupport onnx opset 17, need <= 12!,在导出onnx文件中设置model.export(format=“onnx”, opset=11) 即可
from rknn.api import RKNN
if __name__=='__main__':
rknn = RKNN()
rknn.config(mean_values=[[0.0, 0.0, 0.0]],
std_values=[[1.0, 1.0, 1.0]],
target_platform='rk3588')
rknn.load_onnx('yolov11n-cls.onnx')
'''
def load_onnx(
model: Any,
onnx模型文件路径
inputs: Any | None = None,
模型输入节点(tensor名),支持多个输入节点,所有输入节点名放在一个列表中
input_size_list: Any | None = None,
每个输入节点对应的shape,所有输入shape放在一个列表中。如果inputs有设置,input_size_list也需要设置
input_initial_val: Any | None = None,
设置模型输入的初始值,格式为ndarray的列表。主要用于将某些输入固化为常量,对于不需要固化为常量的输入可以设置为None
outputs: Any | None = None
模型的输出节点(tensor名),支持多个输出节点,所有输出节点名放在一个列表中
)
返回值:0:导入成功;-1:导入失败
'''
rknn.build(do_quantization=True,
dataset='datasets.txt')
rknn.export_rknn('yolov11n-cls.rknn')
rknn.release()
三、模型推理
模型推理有两种方式:
1、在PC上运行非RKNN模型
2、在NPU上运行RKNN模型
1、在PC上运行非RKNN模型
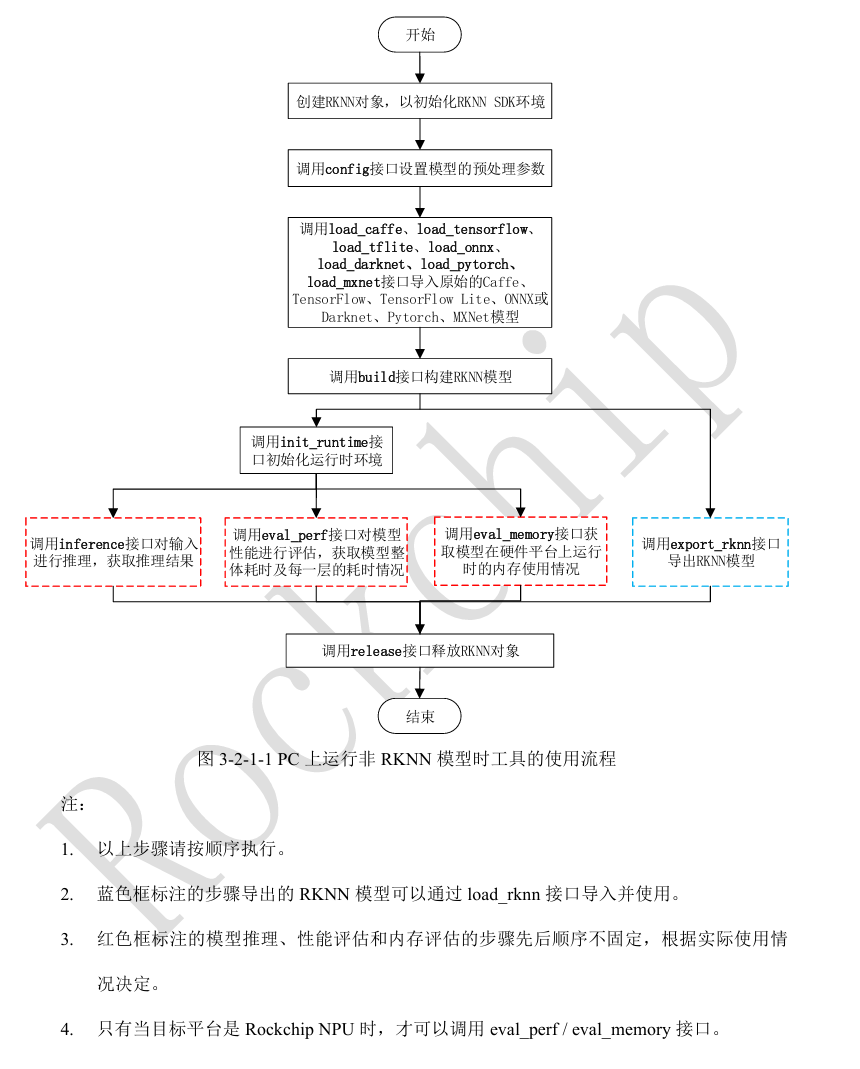
实现步骤为:
'''
1、实例化RKNN对象
2、调用Config接口设置模型的预处理参数
3、调用load_pytorch、load_onnx接口导入pytorch\onnx模型等
4、调用build接口构建RKNN模型
5、调用ini_runtime接口初始化运行环境,注意设置target=None,表示在模拟器上运行
6、导入要推理的数据并预处理数据
7、调用inference接口进行推理,获取推理结果
8、释放RKNN对象
'''
实现代码如下:
from rknn.api import RKNN
import cv2
import numpy as np
if __name__=='__main__':
rknn = RKNN()
rknn.config(
mean_values=[[0.0, 0.0, 0.0]],
std_values=[[1.0, 1.0, 1.0]],
target_platform='rk3588'
)
# rknn.load_pytorch('yolov11n-cls.pt',
# input_size_list=[[1, 3, 480, 480]])
rknn.load_onnx('yolov11n-cls.onnx',
input_size_list=[[1, 3, 480, 480]])
rknn.build(do_quantization=True,
dataset='datasets.txt',
rknn_batch_size=-1)
rknn.init_runtime(
target=None,
# target='rk3588',
target_sub_class=None,
device_id=None,
perf_debug=False,
eval_mem=False,
async_mode=False,
core_mask=RKNN.NPU_CORE_AUTO,
)
img = cv2.imread(filename='A6_6499.bmp')
img = cv2.resize(img, (480, 480))
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
outputs = rknn.inference(
inputs=[img],
data_format="nhwc",
'''
cv2.imread()读取的图像数据的layout为NHWC,data_format的默认值为NHWC,如果模型的输入不是通过cv2.imread()读取,需要设置正确的data_format值
'''
)
print(np.array(outputs[0][0]))
rknn.release()
2、在NPU上运行RKNN模型
2.1 推理前的准备工作
1)确保开发板的USB OTG连接到PC,并正确识别到设备。可以通过adb device命令查询相应设备,也可调用rknn-toolkit2的list_devices接口查询相应设备。
rknn = RKNN()
rknn.list_devices()
'''
def list_devices():无参数,
返回adb_devices列表和ntb_devices列表,如果设备为空,则返回空列表
'''
rknn.release()
输出为:
*************************
all device(s) with adb mode:
VD46C3KM6N
*************************
2)参考https://github.com/rockchip-linux/rknpu2/blob/master/rknn_server_proxy.md说明更新开发板的runtime库和rknn_server库,并确保rknn_server服务已经启动(大部分平台需要手动通过串口启动)
3)调用init_runtime接口初始化运行环境时需要指定target参数(开发平台,如target=‘rk3588’)和device_id参数(由步骤2list_devices中获取,如本例程中device_id=‘VD46C3KM6N’)。
2.2 模型推理实现步骤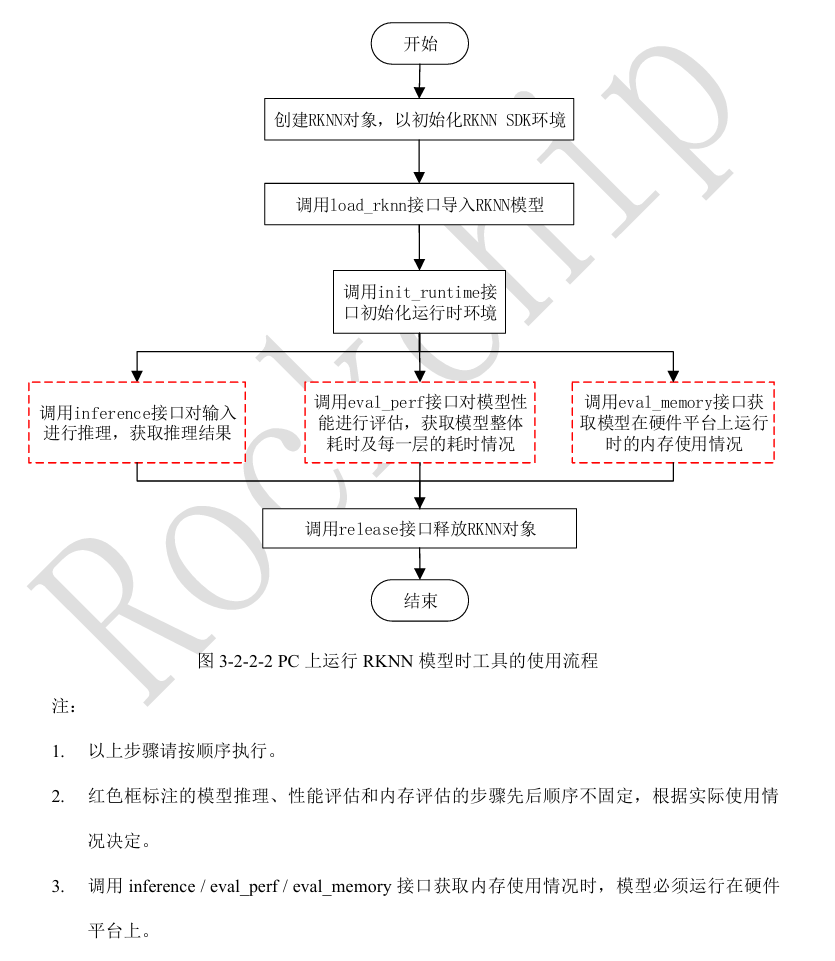
'''
运行RKNN模型,不需要设置模型预处理参数,也不需要构建RKNN模型,推理流程:
1、实例化RKNN对象
2、调用load_rknn导入RKNN模型
3、调用init_runtime初始化,注意设置target='rk3588', device_id的值需要通过rknn.list_devices获取
4、导入要处理的数据并处理成需要的输入格式
5、调用inference进行推理并获取推理结果
6、释放RKNN对象
'''
实现代码:
from rknn.api import RKNN
import cv2
import numpy as np
if __name__=="__main__":
rknn = RKNN()
rknn.load_rknn('yolov11n-cls.rknn')
rknn.init_runtime(target='rk3588',
device_id='VD46C3KM6N')
img = cv2.imread(filename='A6_6499.bmp')
img = cv2.resize(img, (480, 480))
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
outputs = rknn.inference(
inputs=[img],
data_format="nhwc",
'''
cv2.imread()读取的图像数据的layout为NHWC,data_format的默认值为NHWC,如果模型的输入不是通过cv2.imread()读取,需要设置正确的data_format值
'''
)
print(np.array(outputs[0][0]))
rknn.release()
四、模型量化
RKNN模型量化是一种将深度学习模型从浮点精度(如FP32)转换为低比特整数(如INT8)的技术,旨在减少模型体积、提升推理速度并降低功耗。量化对象:权重量化(模型参数从浮点转为整数)、激活量化(推理时中间特征图的数值转换)
4.1 量化原理:
1)线性量化原理
- 使用比例因子scale和零点zero_point将浮点值映射到整数区间, quantized_value = round(float_value / scale) + zero_point
- 反量化是还原近似原始值,float_value ≈ (quantized_value - zero_point) * scale
2)校准过程(PTQ)
- 通过校准数据集统计各层激活值的动态范围,确定最优scale和zero_point
- 关键作用:减少量化误差,避免数值溢出或截断
3)量化类型
- 对称量化:零点为0,适合权重分布对称的场景
- 非对称量化,零点非0,适合偏态分布数据
- 混合精度量化:敏感层保留FP16,其他层用INT8
4.2 量化精度分析
重点函数为accuracy_analysis()
【注】 该接口只能在build和hybrid_quantization_step2之后调用。
【注】 如未制定target,且原始模型应该为已量化的模型,否则会调用失败
【注】 该接口使用的量化方式与config中制定的一致。
4.2.1 量化精度分析步骤
- 实例化RKNN对象
- 设置模型预处理和量化参数
- 调用load_onnx等接口导入模型
- 调用build构建模型
- 调用accuracy_analysis进行量化精度分析
- 释放RKNN对象
4.2.2 代码实现
from rknn.api import RKNN
if __name__=="__main__":
rknn = RKNN()
rknn.config(
mean_values=[[0.0, 0.0, 0.0]],
std_values=[[1.0, 1.0, 1.0]],
target_platform='rk3588'
)
rknn.load_onnx('yolov11n-cls.onnx')
rknn.build(do_quantization=True,
dataset='datasets.txt')
rknn.accuracy_analysis(inputs=['A6_6499.bmp'],
output_dir='snapshot',
target=None, # 如果连接了开发板,target='rk3588', device_id=设备编号
device_id=None)
'''
推理并产生快照,也就是dump出每一层的tensor数据,会dump出包括fp32和quant两种数据类型的快照,用于计算量化误差。
def accuracy_analysis(
inputs: Any,
图像(jpg/png/bmp/npy等)路径list
output_dir: str = './snapshot',
输出目录,所有快照都保存在该目录下,默认值为'./snapshot'
如果没有设置target,在output_dir下会输出:
1、simulator目录:保存整个量化模型在simulator上完整运行时每一层的结果(已经转成float32)
2、golden目录:保存整个浮点模型在simulator上完整跑下来时每一层的结果
3、error_analysis.txt:记录simulator上量化模型逐层运行时每一层的结果与golden浮点模型逐层运行时每一层的结果的余弦距离(entire_error cosine),以及量化模型取上一层的浮点结果作为输入时,输出与浮点模型的余弦距离(single_error cosine)
如果有设置target,则在output_dir里还会多输出:
1、runtime目录:保存整个量化模型在NPU上完整运行时每一层的结果(已转成float32)
2、error_analysis.txt:在上述记录内容的基础上,还会记录量化模型在simulator上逐层运行时每一层的结果的余弦距离
target: Any | None = None,
目标硬件平台,如果设置了target,则会获取NPU运行时每一层的结果,并进行精度分析
device_id: Any | None = None
设备编号,如果pc连接多台设备时,需要指定该参数
)
返回值:0:成功;-1:失败
'''
rknn.release()
4.2.3 输出
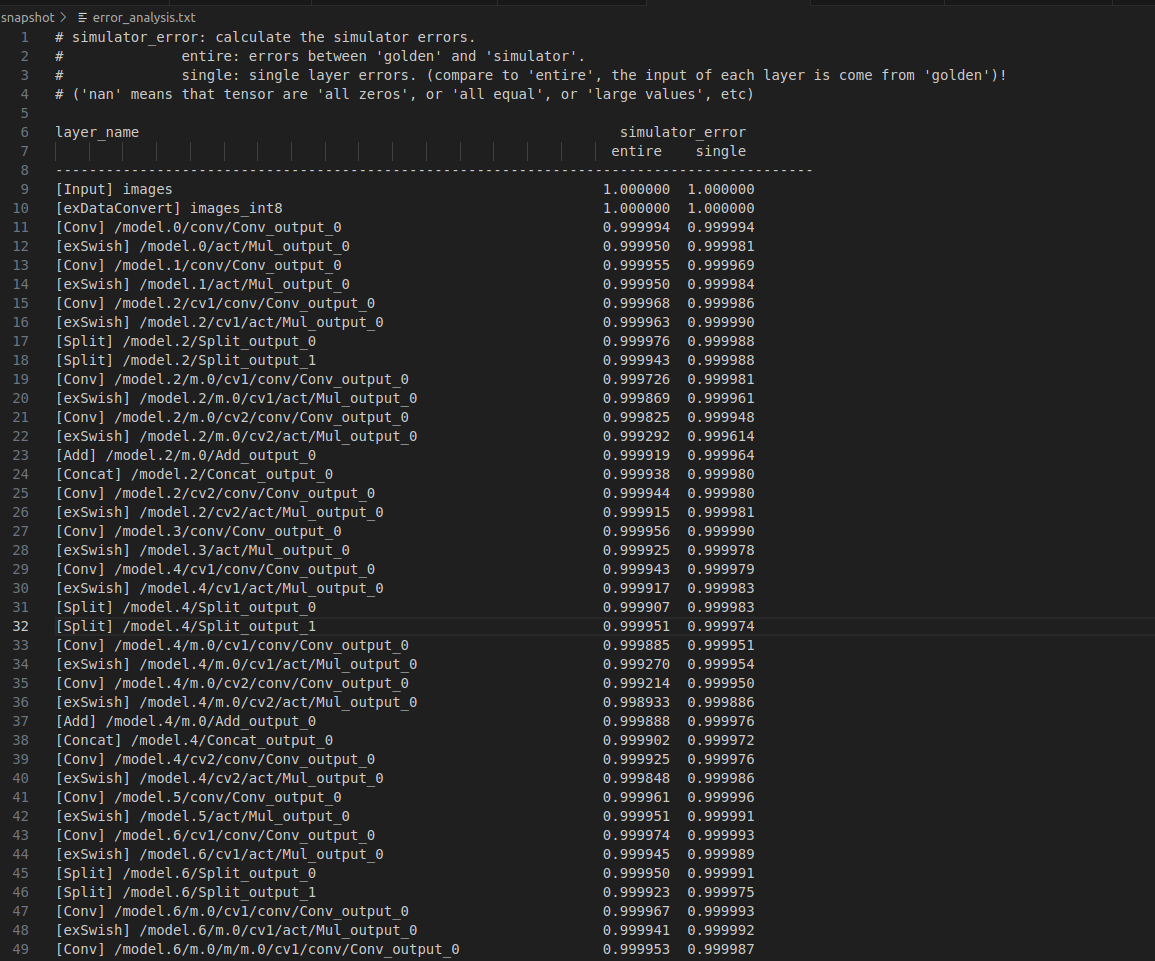
上图右侧有两列数值输出,其中entire表示simulator上量化模型逐层运行时每一层的结果与golden浮点模型逐层运行时每一层的结果的余弦距离,即量化模型整体输出与原始浮点模型(golden)的误差,反映端到端的累计误差;sigle表示量化模型取上一层的浮点结果作为输入时,输出与浮点模型的余弦距离,反映单层量化精度。值越接近于1表示误差越小。
【警惕关键现象1】 误差值范围,越接近1 表示量化误差越小,若出现显著下降(如0.99以下)须警惕精度损失
【警惕关键现象2】 NaN值,表示张量全零或数值极端,可能由无法激活或量化溢出导致。若存在须检查校准数据或量化参数。
4.2.4 优化建议
1)敏感层定位:对比entire和single误差差异较大层,优先采用混合量化
2)校准数据优化:若误差集中在前几层,需检查输入数据预处理是否与训练一致
3)量化策略调整:对误差突增层尝试非对称量化或调整量化粒度
4.3 混合量化
量化功能可能会使模型特殊模型的精度下降,为了在性能和精度之间做更好的平衡,混合优化功能,可以根据用用户的手动指定某些层是否进行量化。
4.3.1 混合量化步骤
- 生成混合量化配置文件,hybrid_quatization_step1()
- 修改第一步生成的量化配置文件(.quantization.cfg)
- 生成新的RKNN模型,hybrid_quantization_step2()
4.3.2 生成混合量化配置文件
重要API为hybrid_quatization_step1(),执行以下代码会生成临时模型文件(.model)、数据文件(.data)和量化配置文件(.quantization.cfg)
步骤为:
- 实例化RKNN对象
- 设置模型预处理参数config
- 加载模型文件, onnx等
- 调用hybrid_quantization_step1()
- 释放RKNN对象
from rknn.api import RKNN
if __name__=="__main__":
rknn = RKNN()
rknn.config(
mean_values=[[0.0, 0.0, 0.0]],
std_values=[[1.0, 1.0, 1.0]],
target_platform='rk3588'
)
rknn.load_onnx('./yolov11n-cls.onnx')
rknn.hybrid_quantization_step1(
dataset='./datasets.txt',
proposal=True,
)
'''
用于生成临时模型文件(.model)、数据文件(.data)和量化配置文件(.quantization.cfg)
def hybrid_quantization_step1(
dataset: Any | None = None,
量化用的数据集
rknn_batch_size: Any | None = None,
模型的输入batch参数的调整
proposal: bool = False,
产生混合量化的配置建议
proposal_dataset_size: int = 1
proposal使用的dataset的张数,默认为1.
因proposal功能比较耗时,所以默认只是用1张,也就是dataset里的第一张
)
'''
rknn.release()
yolov11n-cls.quatization.cfg文件内容如下
custom_quantize_layers:
/model.0/conv/Conv_output_0: float16
/model.0/act/Mul_output_0: float16
/model.1/conv/Conv_output_0: float16
/model.2/m.0/cv1/conv/Conv_output_0: float16
/model.2/m.0/cv1/act/Mul_output_0: float16
/model.2/m.0/Add_output_0: float16
/model.2/Concat_output_0: float16
/model.4/m.0/cv2/conv/Conv_output_0: float16
/model.4/m.0/cv2/act/Mul_output_0: float16
/model.4/m.0/Add_output_0: float16
/model.4/Concat_output_0: float16
/model.4/cv2/conv/Conv_output_0: float16
/model.4/cv2/act/Mul_output_0: float16
/model.5/conv/Conv_output_0: float16
/model.6/m.0/m/m.0/cv1/act/Mul_output_0: float16
/model.6/m.0/m/m.0/cv2/conv/Conv_output_0: float16
/model.6/m.0/m/m.0/cv2/act/Mul_output_0: float16
/model.6/m.0/m/m.0/Add_output_0: float16
/model.6/m.0/cv3/act/Mul_output_0: float16
/model.6/Concat_output_0: float16
/model.8/m.0/m/m.0/cv1/act/Mul_output_0: float16
/model.8/m.0/m/m.0/cv2/conv/Conv_output_0: float16
/model.8/m.0/m/m.0/cv2/act/Mul_output_0: float16
/model.8/m.0/m/m.0/Add_output_0: float16
/model.8/m.0/m/m.1/cv1/conv/Conv_output_0: float16
/model.8/m.0/m/m.1/Add_output_0: float16
/model.8/m.0/m/m.1/cv1/act/Mul_output_0: float16
/model.8/m.0/m/m.1/cv2/conv/Conv_output_0: float16
/model.8/m.0/m/m.1/cv2/act/Mul_output_0: float16
/model.8/m.0/Concat_output_0: float16
/model.8/m.0/cv3/conv/Conv_output_0: float16
/model.8/m.0/cv3/act/Mul_output_0: float16
/model.8/Concat_output_0: float16
/model.8/cv2/conv/Conv_output_0: float16
/model.8/cv2/act/Mul_output_0: float16
/model.9/cv1/conv/Conv_output_0: float16
/model.9/cv1/act/Mul_output_0: float16
/model.9/Split_output_0: float16
/model.9/Concat_output_0: float16
/model.9/Split_output_1: float16
/model.9/m/m.0/attn/qkv/conv/Conv_output_0: float16
/model.9/m/m.0/Add_output_0: float16
/model.9/m/m.0/attn/Reshape_output_0: float16
/model.9/m/m.0/attn/Split_output_0: float16
/model.9/m/m.0/attn/Softmax_output_0: float16
/model.9/m/m.0/attn/Transpose_1_output_0: float16
/model.9/m/m.0/attn/MatMul_1_output_0: float16
/model.9/m/m.0/attn/Reshape_1_output_0: float16
/model.9/m/m.0/attn/Add_output_0: float16
/model.9/m/m.0/attn/proj/conv/Conv_output_0: float16
/model.9/m/m.0/ffn/ffn.0/act/Mul_output_0: float16
/model.9/m/m.0/ffn/ffn.1/conv/Conv_output_0: float16
/model.9/cv2/act/Mul_output_0: float16
/model.10/conv/conv/Conv_output_0: float16
/model.10/conv/act/Mul_output_0: float16
/model.10/pool/GlobalAveragePool_2conv_0: float16
/model.10/pool/GlobalAveragePool_output_0: float16
/model.10/linear/Gemm_output_0_conv: float16
quantize_parameters:
images:
qtype: asymmetric_quantized
qmethod: layer
dtype: float32
min:
- 0.0
max:
- 255.0
scale: []
zero_point: []
ori_min:
- 0.0
ori_max:
- 255.0
...
其中,custom_quatize_layers是一个自定义量化tensor字典,用户可以将tensor名和相应的量化类型添加到该字典中,即可实现将该tensor作为输出的层的运算类型改为指定的运算类型。上面的文件是我的rknn导出的cfg文件,可以看出custom_quatize_layers已经列了一些优化层了。
quantize_parameters:是模型中每个tensor的量化参数,每一个tensor都是一个字典,每个字典的key为tensor的名,字典的value为量化参数,如果没有经过量化,dtype值为float16
4.3.3 修改第一步生成的量化配置文件(.quantization.cfg)
为了测试一下混合量化,我自己修改了一下我的cfg文件,在上一步量化精度分析中,下面两层的entire和single误差差值有一点点大
[exSwish] /model.4/cv1/act/Mul_output_0 0.999917 0.999983
[Split] /model.4/Split_output_0 0.999907 0.999983
因此修改yolov11n-cls.quatization.cfg文件如下
【注】 custom_quantize_layers格式问题,官方文档给的是custom_quantize_layers:{x:float16, x2:float16},但是我这边会报错,改成YAML格式的就好了,不晓得为啥。YAML不需要{},也不需要,作为分割,只要缩进做好就可,详细请参考下述代码
custom_quantize_layers:
/model.4/cv1/act/Mul_output_0:float16
/model.4/Split_output_0:float16
# 将/model.4/cv1/act/Mul_output_0,/model.4/Split_output_0设置为float16,即不进行量化
quantize_parameters:
images:
qtype: asymmetric_quantized
qmethod: layer
dtype: float32
min:
- 0.0
max:
- 255.0
scale: []
zero_point: []
ori_min:
- 0.0
ori_max:
- 255.0
/model.0/conv/Conv_output_0:
qtype: asymmetric_quantized
qmethod: layer
dtype: int8
min:
- -15024.08984375
max:
- 9862.2978515625
scale:
- 97.59367723651961
zero_point:
- 26
ori_min:
- -15024.08984375
ori_max:
- 9862.2978515625
4.3.4 生成新的RKNN模型,hybrid_quantization_step2()
步骤为:
- 实例化RKNN对象
- 调用hybrid_quantization_step2()
- 调用accuracy_analysis()再次评估模型,验证混合量化效果
- 导出RKNN模型
- 释放RKNN模型
# 混合量化前
[exSwish] /model.4/cv1/act/Mul_output_0 0.999917 0.999983
[Split] /model.4/Split_output_0 0.999907 0.999983
# 混合量化后
[exSwish] /model.4/cv1/act/Mul_output_0 0.999791 1.000000
[Split] /model.4/Split_output_0 0.999786 1.000000
五、模型部署
参考【1】:https://blog.csdn.net/m0_48241022/article/details/141687378
参考【2】:https://blog.csdn.net/m0_48241022/article/details/141722775
参考【3】:https://blog.csdn.net/qq_40280673/article/details/136560685#/
参考【4】:https://blog.csdn.net/qq_40280673/article/details/136619664#/
3rdpart包链接:通过网盘分享的文件:3rdparty
链接: https://pan.baidu.com/s/1AWu8Kc2lr3h5OEfz341esg 提取码: wrs6
1、CMake编程
瑞芯微提供的历程都是以CMake自动化构建工具来生成可执行文件、库和其他构建目标的。
没有CMake编程经验,可以参考b站up主的1小时入门教程,教程链接:【1小时学会CMake干货知识和实战|C++ | VSCode】 https://www.bilibili.com/video/BV1eAQrYCEkp/?p=5&share_source=copy_web&vd_source=83d15c2aca602cd6a8c26a0ec023457f
准备如下文件结构如下:
- model文件夹中存放测试图片及rknn模型,我用了yolov8和yolov11
- src文件夹中存放要编译的源码main.cc
- build.sh文件中设置了一些基本的环境变量,以及开始cmake的指令
- CMakeLists.txt文件设置编译源码需要的一些第三方依赖库
1.1 编写CMakeList.txt文件
【注】 因图像预处理和模型推理需要依赖opencv及rknn库,因此需要添加第三方库,如下一行代码设置了librknn_api的路径。将官方提供的3rdparty文件夹(包含rknn_api、opencv等第三方库)放入本项目路径下,与05_API文件夹同级。如下图。
set(RKNN_API_PATH ${CMAKE_SOURCE_DIR}/../3rdparty/librknn_api)
3rdparty文件夹结构:
CMakeLists文件内容如下:
# CMake需要的最低版本号是3.4.1, 本机cmake版本:3.22.1
cmake_minimum_required(VERSION 3.4.1)
# 指定了项目的名称为yolo
project(yolo)
# 不使用任何C编译器标志,使用C++11标准进行编译
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
# rknn api
set(RKNN_API_PATH ${CMAKE_SOURCE_DIR}/../3rdparty/librknn_api) #该变量定义了RKNN API库的路径,定义RKNN_API_PATH变量为../3rdparty/librknn_api
# CMAKE_SOURCE_DIR文件主目录
set(LIB_ARCH aarch64) # 定义LIB_ARCH变量为aarch64
set(RKNN_RT_LIB ${RKNN_API_PATH}/${LIB_ARCH}/librknnrt.so) # 该变量定义了RKNN运行时库的路径。路径为:../3rdparty/librknn_api/arrch64/librknnrt.so
include_directories(${RKNN_API_PATH}/include) # 添加RKNN API的头文件,路径为./3rdparty/librknn_api/include
# opencv
set(OpenCV_DIR ${CMAKE_SOURCE_DIR}/../3rdparty/opencv/share/OpenCV) # 指定了OpenCV库的路径。
find_package(OpenCV REQUIRED) # 自动查找OpenCV库,并将相关信息保存在CMake内置变量中
# 指定了程序运行时查找动态链接库的路径
set(CMAKE_INSTALL_RPATH "lib")
# 创建一个可执行文件
add_executable(${PROJECT_NAME}
src/main.cc
)
# 指定工程需要链接的库文件
target_link_libraries(${PROJECT_NAME}
${RKNN_RT_LIB}
${OpenCV_LIBS}
)
# 指定了程序安装的路径install,用于存放编译完成后的可执行程序、运行所用到的库以及RKNN模型和推理图片
set(CMAKE_INSTALL_PREFIX ${CMAKE_SOURCE_DIR}/install/${PROJECT_NAME}_${CMAKE_SYSTEM_NAME})
# CMAKE_SYSTEM_NAME:
# 拷贝可执行程序和需要用的库以及后面测试要用到的model测试文件
install(TARGETS ${PROJECT_NAME} DESTINATION ./)
install(DIRECTORY model DESTINATION ./)
install(PROGRAMS ${RKNN_RT_LIB} DESTINATION lib)
1.2 build.sh文件
简单的cmake构建工程,通过以下指令可以进行
mkdir build && cd build # 创建并进入构建目录
cmake .. # 生成构建系统文件
# 若CMakeList.txt位于源码的上一层目录,使用cmake .. 若与源码位于同一层目录,使用 cmake .
make # 编译项目
本项目参考两位up主及官方教程,使用build.sh构建工程
build.sh文件内容如下:
#!/bin/bash
set -e
ROOT_PWD=$( cd "$( dirname $0 )" && cd -P "$( dirname "$SOURCE" )" && pwd )
# for aarch64
GCC_COMPILER=/usr/local/arm64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu
# build, 存放工程构建过程中生成的中间文件
BUILD_DIR=${ROOT_PWD}/build/build_linux_aarch64
if [[ ! -d "${BUILD_DIR}" ]]; then
mkdir -p ${BUILD_DIR}
fi
cd ${BUILD_DIR}
cmake ../.. \
-DCMAKE_C_COMPILER=${GCC_COMPILER}-gcc \
-DCMAKE_CXX_COMPILER=${GCC_COMPILER}-g++
make -j4
# install,拷贝可执行程序和需要用的库以及后面测试要用到的model测试文件
make install
cd -
1.2.1 安装gcc交叉编译器
安装包链接:通过网盘分享的文件:gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.gz
链接: https://pan.baidu.com/s/1kXqIr1PYSb7by491WDUiKg 提取码: 5yne
【注】build.sh指定了gcc交叉编译器安装路径为
GCC_COMPILER=/usr/local/arm64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu
在/usr/local路径下创建arm64文件夹,将gcc压缩包拷贝到/usr/local/arm64/路径下并解压
cd /usr/local
mkdir arm64
sudo mv ~/samba_share/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.gz /usr/local/arm64
//~/samba_share是我存放压缩包的路径
unzip gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.gz
1.3 CMake构建工程
在编写好main.cc文件后,执行cmake构建,构建指令为
cd 05_API
./build.sh
如果遇到权限不够问题,是因为文件的权限文件,执行以下指令修改文件权限后再执行构建即可
chmod +x build.sh
2、编写部署源码main.cc
RK3588目前支持两种API接口,分别是通用API接口和零拷贝流程的API接口。两组API的主要区别是:
- 通用API接口每次更新帧数据,需要将外部模块分配的数据拷贝到NPU运行时的输入内存
- 零拷贝流程的接口会直接使用预先分配的内存,减少内存拷贝的花销
- 当用户输入数据只有虚拟地址时,只能使用通用API接口,本项目实际落地时是视频流取帧后进行推理,因此使用通用API
- 当用户输入数据有物理地址或fd时,两组接口都可以使用
- 通用API和零拷贝API不能混合调用
2.1 通用API
实现流程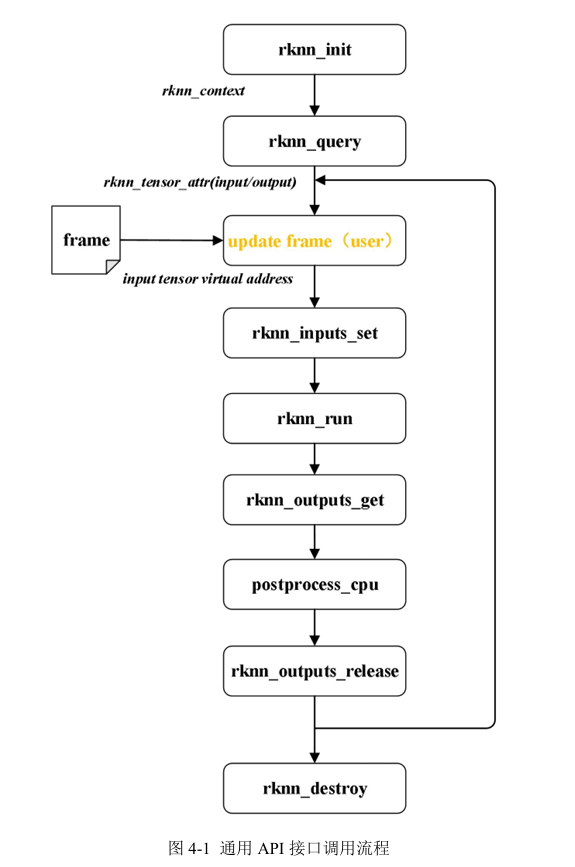
完整代码:
#include <stdio.h>
#include <string.h>
#include "rknn_api.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/opencv.hpp"
#include <sys/time.h>
#include <iostream>
using namespace cv;
static inline int64_t getCurrentTimeUs()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void softmax(float* x, int length) {
float max_val = x[0];
for (int i = 1; i < length; ++i) {
if (x[i] > max_val) max_val = x[i];
}
float sum = 0.0f;
for (int i = 0; i < length; ++i) {
x[i] = expf(x[i] - max_val);
sum += x[i];
}
for (int i = 0; i < length; ++i) {
x[i] /= sum;
}
}
void inference(char *model_path, const Mat src, int &class_id, double &confidence)
{
/*
模型推理:
const Mat src:输入,RGB三通道图像
int class_id:输出,分类
double confidence:输出,置信度值
*/
// 设置模型加载路径
// const char *model_path = "/model/yolo.rknn";
// 图像处理:
// 模型输入:480x480
// 原图尺寸:1920x1200
if(src.empty())
{
std::cout << "Failed to load image, check:" << std::endl;
std::cout << "1. File exists: " << std::endl;
std::cout << "2. File size: " << std::endl;
}
Mat resize_img, gray_img;
resize(src, resize_img, Size(480, 480));
cvtColor(resize_img, gray_img, COLOR_BGR2RGB);
rknn_context context;
int init_ret = rknn_init(&context, model_path, 0, 0,NULL);
if(init_ret < 0)
{
std::cout << "init rknn model error!\n" << std::endl;
}
rknn_input_output_num io_num;
rknn_query(context, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(rknn_input_output_num));
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].size = gray_img.cols * gray_img.rows * gray_img.channels();
inputs[0].pass_through = 0;
inputs[0].buf = gray_img.data;
rknn_inputs_set(context, io_num.n_input, inputs);
// Run
int ret = rknn_run(context, NULL);
if (ret < 0) {
printf("rknn run error %d\n", ret);
}
rknn_output outputs[1];
memset(outputs, 0, sizeof(outputs));
outputs[0].index = 0;
outputs[0].is_prealloc = 0;
outputs[0].want_float = 1; // 强制输出浮点数
if(rknn_outputs_get(context, io_num.n_output, outputs, NULL) != RKNN_SUCC)
{
std::cout << "rknn output get failed!\n" << std::endl;
}
// Post Process
float *pred = (float*)outputs[0].buf;
softmax(pred, 2);
class_id = pred[0] > pred[1] ? 0 : 1;
confidence = pred[class_id];
rknn_outputs_release(context, io_num.n_output, outputs);
rknn_destroy(context);
}
int main(int argc, char *argv[])
{
char *model_path = argv[1];
char *image_path = argv[2];
Mat src = imread(image_path);
int class_id = 0;
double confidence = 0.0;
int64_t start_us = getCurrentTimeUs();
inference(model_path, src, class_id, confidence);
int64_t elapse_us = getCurrentTimeUs() - start_us;
printf("%4d: Elapse Time = %.2fms, FPS = %.2f\n", 0, elapse_us / 1000.f, 1000.f * 1000.f / elapse_us);
printf("Class: %d, Confidence: %.4f\n", class_id, confidence);
return 0;
}
2.2 通用接口解释
在编程之前,需要配置编译环境,否则include包会找不到路径。
在项目中按下contrl+shift+p打开配置窗口,搜索C/C++:编辑配置(JSON),如果你搜索不到,需要安装C++扩展
点进C/C++:编辑配置(JSON),内容如下,在“includePath”下添加rknn_api.h和opencv的路径,这两个文件都在上述提到的3rdparty文件夹中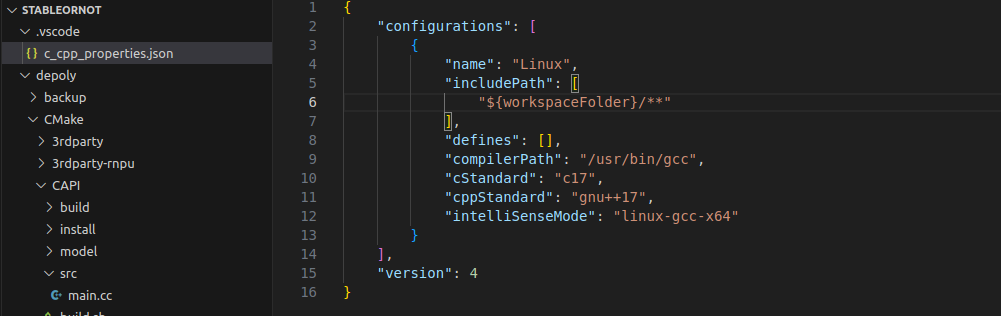
添加完成后,如下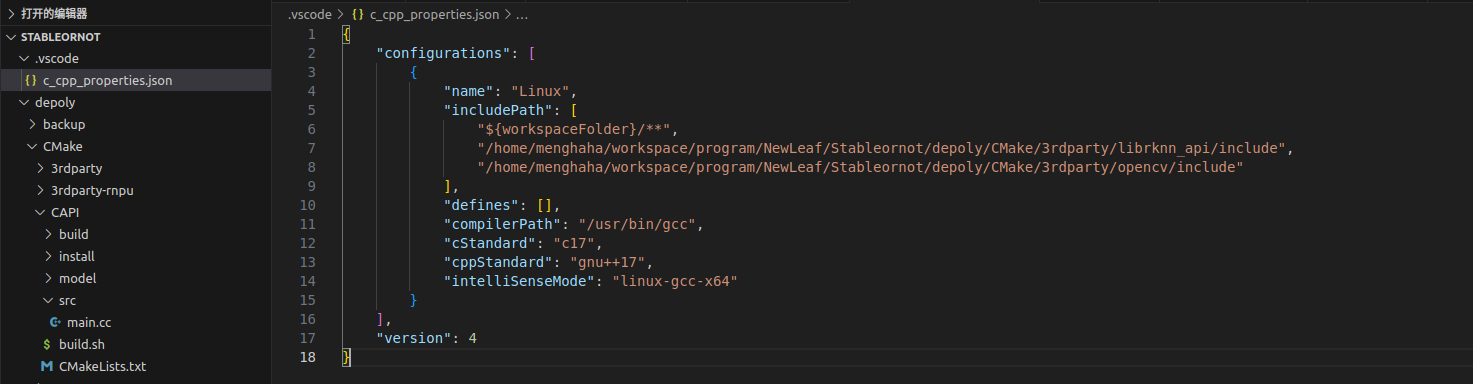
2.2.1 rknn_init
初始化RKNN,实际代码书写:
传入的是model路径,因此第三个参数为0;第四个参数因不需要特定的初始化标志,因此也为0。
rknn_context context;
int init_ret = rknn_init(&context, model_path, 0, 0,NULL);
if(init_ret < 0)
{
std::cout << "init rknn model error!\n" << std::endl;
}
接口解释: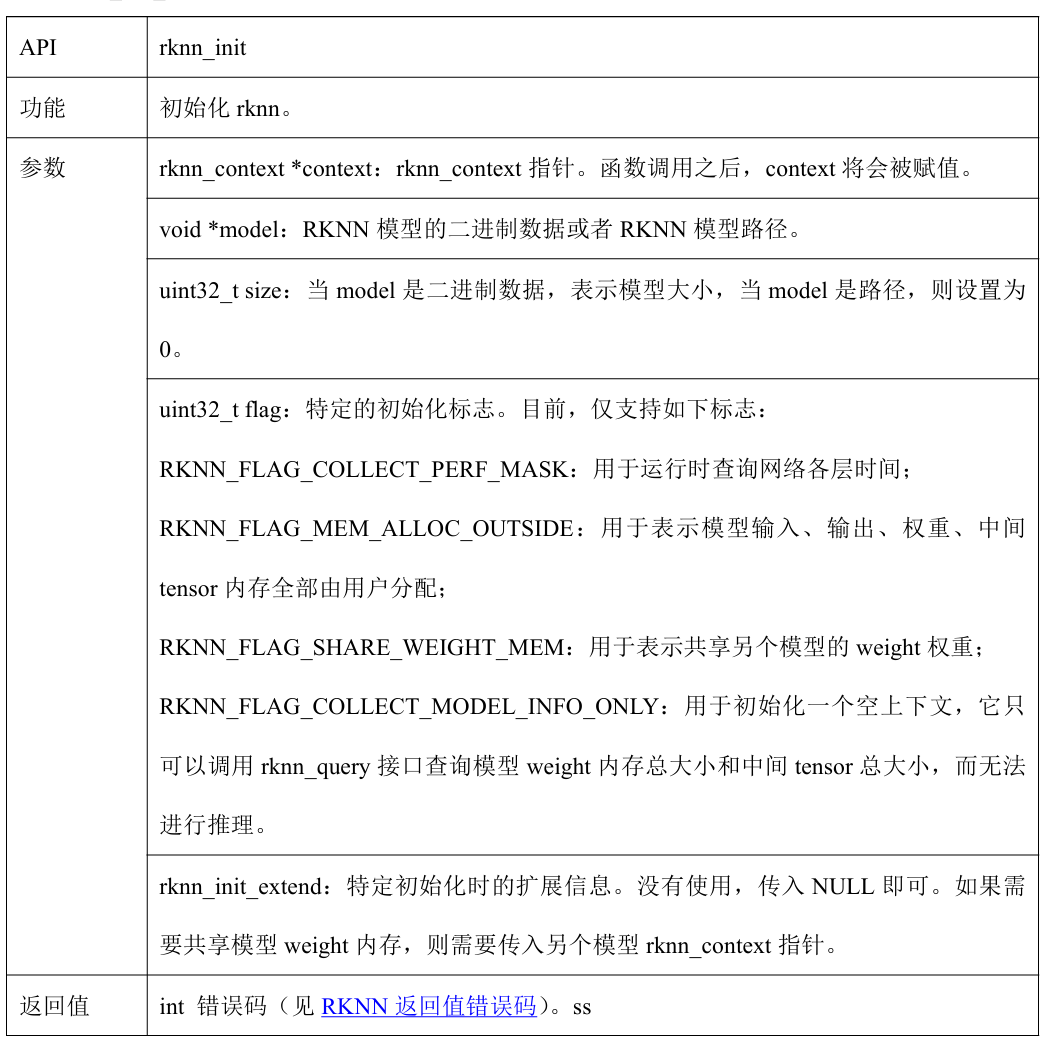

示例代码:
rknn_context ctx_a, ctx_b;
rknn_init(&ctx_a, model_path_a, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_a, RKNN_QUERY_MEM_SIZE, &mem_size_a, sizeof(mem_size_a));
rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_b, RKNN_QUERY_MEM_SIZE, &mem_size_b, sizeof(mem_size_b));
max_internal_size = MAX(mem_size_a.total_internal_size, mem_size_b.total_internal_size);
internal_mem_max = rknn_create_mem(ctx_a, max_internal_size);
internal_mem_a = rknn_create_mem_from_fd(ctx_a, internal_mem_max->fd,internal_mem_max->virt_addr, mem_size_a.total_internal_size, 0);
rknn_set_internal_mem(ctx_a, internal_mem_a);
internal_mem_b = rknn_create_mem_from_fd(ctx_b, internal_mem_max->fd,internal_mem_max->virt_addr, mem_size_b.total_internal_size, 0);
rknn_set_internal_mem(ctx_b, internal_mem_b);

示例代码:
rknn_context ctx_a,ctx_b;
rknn_init(&ctx_a,model_path_a,0,0,NULL);
rknn_init_extend extend;
extend.ctx=ctx_a;
rknn_init(&ctx_b,model_path_b,0,RKNN_FLAG_SHARE_WEIGHT_MEM,&extend);
2.2.2 rknn_query
rknn_query查询模型与SDK的相关信息。因rknn_inputs_set、rknn_outputs_get需要用到输入输出tensor个数。
实际代码编写:
rknn_input_output_num io_num;
rknn_query(context, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(rknn_input_output_num));
接口解释:
rknn_query_cmd选项详见官方开发文档。
2.2.3 rknn_inputs_set
设置模型输入数据,该函数支持多个输入,其中每个输入是rknn_input结构体对象,在传入之前需要设置该对象。
实际代码编写:
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0; // 该输入的索引位置,可设置多个输入
inputs[0].type = RKNN_TENSOR_UINT8; // 输入数据的类型
inputs[0].fmt = RKNN_TENSOR_NHWC;
// 输入数据的格式:torch数据shape顺序为NHWC
inputs[0].size = gray_img.cols * gray_img.rows * gray_img.channels();
// 输入数据的内存大小
inputs[0].pass_through = 0;
// 设置为1时会将buf存放的输入数据直接设置给模型的输入节点,不做任何预处理
inputs[0].buf = gray_img.data;
// 输入数据的指针
rknn_inputs_set(context, io_num.n_input, inputs);
接口解释:
- rknn_input结构体
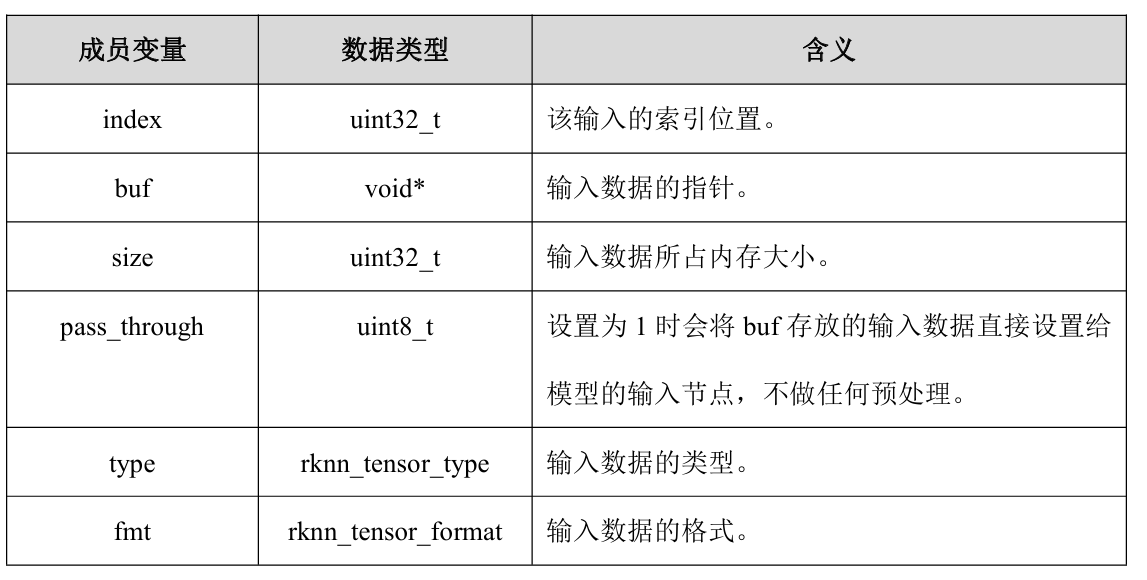
- rknn_inputs_set()API

2.2.4 rknn_run
执行一次模型推理,调用之前需要线通过rknn_input_set函数或零拷贝接口设置输入数据。
实际代码编写:
int ret = rknn_run(context, NULL)
接口解释:
2.2.5 rknn_outputs_get
获取模型推理的输出数据。该函数能够一次获取多个输出数据,其中每个输出是rknn_output结构体对象,在函数调用之前需要依次创建并设置每个rknn_output对象
实际代码编写:
int ret = rknn_run(context, NULL);
if (ret < 0) {
printf("rknn run error %d\n", ret);
}
rknn_output outputs[1];
memset(outputs, 0, sizeof(outputs));
outputs[0].index = 0;
outputs[0].is_prealloc = 0;
// 对于输出数据的buffer存放可以采用两种方式:
// 1、用户自行申请和释放,设置is_prealloc = 1,并将buf指针指向用户申请的buffer
// 2、由rknn进行分配,设置is_prealloc = 0即可,函数执行之后buf将指向输出数据
outputs[0].want_float = 1; // 强制输出浮点数
if(rknn_outputs_get(context, io_num.n_output, outputs, NULL) != RKNN_SUCC)
{
std::cout << "rknn output get failed!\n" << std::endl;
}
接口解释:
- rknn_output结构体
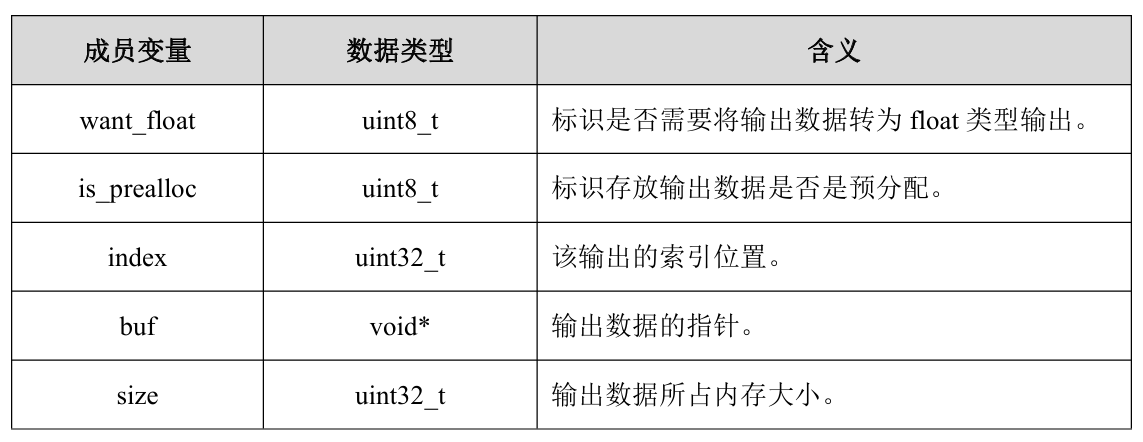
- rknn_outputs_get()API
2.2.6 结果后处理
yolo分类模型的结果后处理需要手动实现softmax函数
实际代码书写:
void softmax(float* x, int length) {
float max_val = x[0];
for (int i = 1; i < length; ++i) {
if (x[i] > max_val) max_val = x[i];
}
float sum = 0.0f;
for (int i = 0; i < length; ++i) {
x[i] = expf(x[i] - max_val);
sum += x[i];
}
for (int i = 0; i < length; ++i) {
x[i] /= sum;
}
}
// 推理函数体里添加以下代码
// Post Process
float *pred = (float*)outputs[0].buf; // 输出数据的buffer
softmax(pred, 2);
class_id = pred[0] > pred[1] ? 0 : 1;
confidence = pred[class_id];
2.2.7 rknn_outputs_release
rknn_outputs_release将释放rknn_outputs_get函数得到的输出的相关资源
实际代码编写:
rknn_outputs_release(context, io_num.n_output, outputs);
接口解释: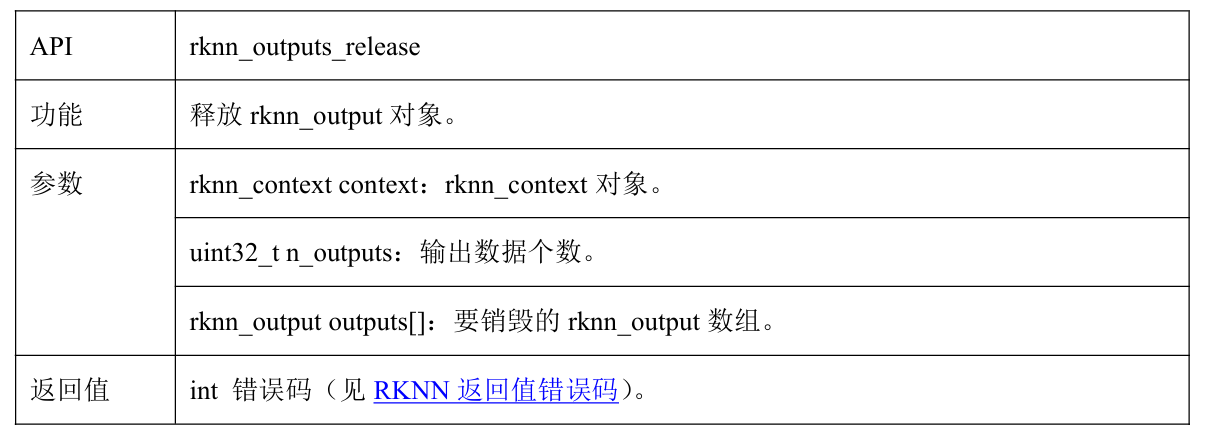
2.2.8 rknn_destory
rknn_destory将释放传入的rknn_context及其相关资源
实际代码编写:
rknn_destory(context);
接口解释: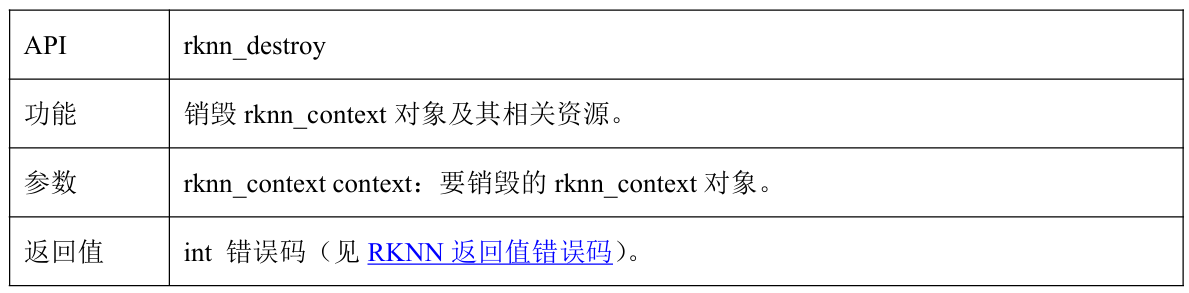
2.3 零拷贝
实现流程: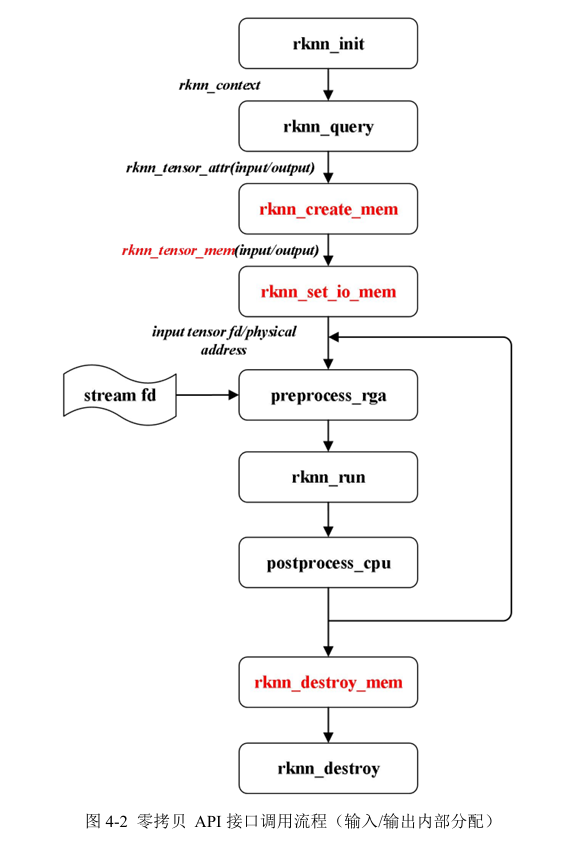
实际代码编写:
我在通用API里写的inference函数的接口与这个有一点差异,这个只是跟着实现流程走一点,实际项目用不到零拷贝,所以就不再完善了
#include <stdio.h>
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "rknn_api.h"
#include "sys/time.h"
#include <iostream>
using namespace cv;
static inline int64_t getCurrentTimeUs()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void softmax(float* x, int length) {
float max_val = x[0];
for (int i = 1; i < length; ++i) {
if (x[i] > max_val) max_val = x[i];
}
float sum = 0.0f;
for (int i = 0; i < length; ++i) {
x[i] = expf(x[i] - max_val);
sum += x[i];
}
for (int i = 0; i < length; ++i) {
x[i] /= sum;
}
}
int inference(char *model_path, Mat src)
{
/*
图像处理:
模型输入:480x480
原图尺寸:1920x1200
*/
if(src.empty())
{
std::cout << "Failed to load image, check:" << std::endl;
std::cout << "1. File exists: " << std::endl;
std::cout << "2. File size: " << std::endl;
return -1;
}
resize(src, src, Size(480, 480));
Mat gray_img;
cvtColor(src, gray_img, COLOR_BGR2RGB);
rknn_context context;
int init_ret = rknn_init(&context, model_path, 0, 0, NULL);
if(init_ret < 0)
{
printf("init rknn model error %d\n", init_ret);
return -1;
}
// 调用rknn_query接口查询输入输出的tensor属性
// input_attr output_attr分别记录输入、输出tensor属性
rknn_tensor_attr input_attr[1], output_attr[1];
memset(input_attr, 0, sizeof(rknn_tensor_attr));
memset(output_attr, 0, sizeof(rknn_tensor_attr));
rknn_query(context, RKNN_QUERY_INPUT_ATTR, input_attr, sizeof(input_attr));
rknn_query(context, RKNN_QUERY_OUTPUT_ATTR, output_attr, sizeof(output_attr));
// 调用rknn_create_mem申请输入和输出内存
rknn_tensor_mem *input_mem[1], *output_mem[1];
input_mem[0] = rknn_create_mem(context, input_attr[0].size_with_stride); // size_with_stride表示补齐了无效像素后,实际存储图像数据所占用的内存空间的大小
output_mem[0] = rknn_create_mem(context, output_attr[0].n_elems * sizeof(float)); // n_elems表示输出数据的元素个数,输出数据所占内存为输出数据的元素个数成每个元素所占空间的大小
// 使用memcpy将要推理的数据加载到刚申请的内存中
unsigned char *input_data = gray_img.data;
memcpy(input_mem[0]->virt_addr, input_data, input_attr[0].size_with_stride);
/*
*/
// 调用rknn_set_io_mem接口让NPU使用上一步申请的内存
input_attr[0].type = RKNN_TENSOR_UINT8;
output_attr[0].type = RKNN_TENSOR_FLOAT32;
rknn_set_io_mem(context, input_mem[0], input_attr);
rknn_set_io_mem(context, output_mem[0], output_attr);
// 调用rknn_run接口执行模型推理
int64_t start_us = getCurrentTimeUs();
int ret = rknn_run(context, NULL);
int64_t elapse_us = getCurrentTimeUs() - start_us;
if(ret < 0)
{
printf("rknn run error %d\n", ret);
return -1;
}
printf("%4d: Elapse Time = %.2fms, FPS = %.2f\n", 0, elapse_us / 1000.f, 1000.f * 1000.f / elapse_us);
// 结果后处理
float *pred = (float*)output_mem[0]->virt_addr;
softmax(pred, 2);
int class_id = pred[0] > pred[1] ? 0 : 1;
float confidence = pred[class_id];
printf("Class: %d, Confidence: %.4f\n", class_id, confidence);
// 销毁内存
rknn_destroy_mem(context, input_mem[0]);
rknn_destroy_mem(context, output_mem[0]);
rknn_destroy(context);
return 0;
}
int main(int argc, char *argv[])
{
char *model_path = argv[1];
char *image_path = argv[2];
Mat src = imread(image_path);
inference(model_path, src);
return 0;
}
2.4零拷贝API解释
前文提到,通用拷贝和零拷贝的差别在处理输入数据上有所不同,零拷贝需要手动做输入内存的分配,因此多了以下三个接口进行内存的操作。
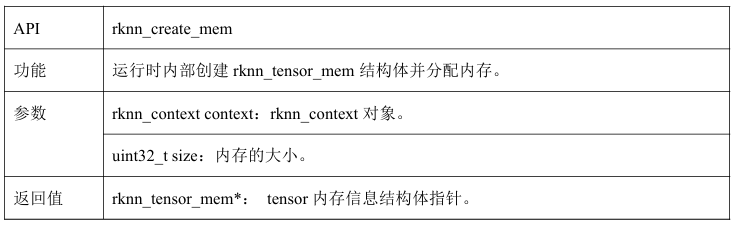
2.4.1 rknn_create_mem
申请NPU内部分配内存,rknn_create_mem函数可以创建一个rknn_tensor_mem结构体,并得到它的指针,该函数通过传入内存大小,运行时初始化rknn_tensor_mem结构体。因需要传入内存大小,所以需要先使用rknn_query查询到输入输出的tensor属性。
实际代码编写:
// 调用rknn_query接口查询输入输出的tensor属性
// input_attr output_attr分别记录输入、输出tensor属性
rknn_tensor_attr input_attr[1], output_attr[1];
memset(input_attr, 0, sizeof(rknn_tensor_attr));
memset(output_attr, 0, sizeof(rknn_tensor_attr));
rknn_query(context, RKNN_QUERY_INPUT_ATTR, input_attr, sizeof(input_attr));
rknn_query(context, RKNN_QUERY_OUTPUT_ATTR, output_attr, sizeof(output_attr));
// 调用rknn_create_mem申请输入和输出内存
rknn_tensor_mem *input_mem[1], *output_mem[1];
input_mem[0] = rknn_create_mem(context, input_attr[0].size_with_stride); // size_with_stride表示补齐了无效像素后,实际存储图像数据所占用的内存空间的大小
output_mem[0] = rknn_create_mem(context, output_attr[0].n_elems * sizeof(float)); // n_elems表示输出数据的元素个数,输出数据所占内存为输出数据的元素个数成每个元素所占空间的大小
// 使用memcpy将要推理的数据加载到刚申请的内存中
unsigned char *input_data = gray_img.data;
memcpy(input_mem[0]->virt_addr, input_data, input_attr[0].size_with_stride);
接口解释:
-
rknn_tensor_attr结构体
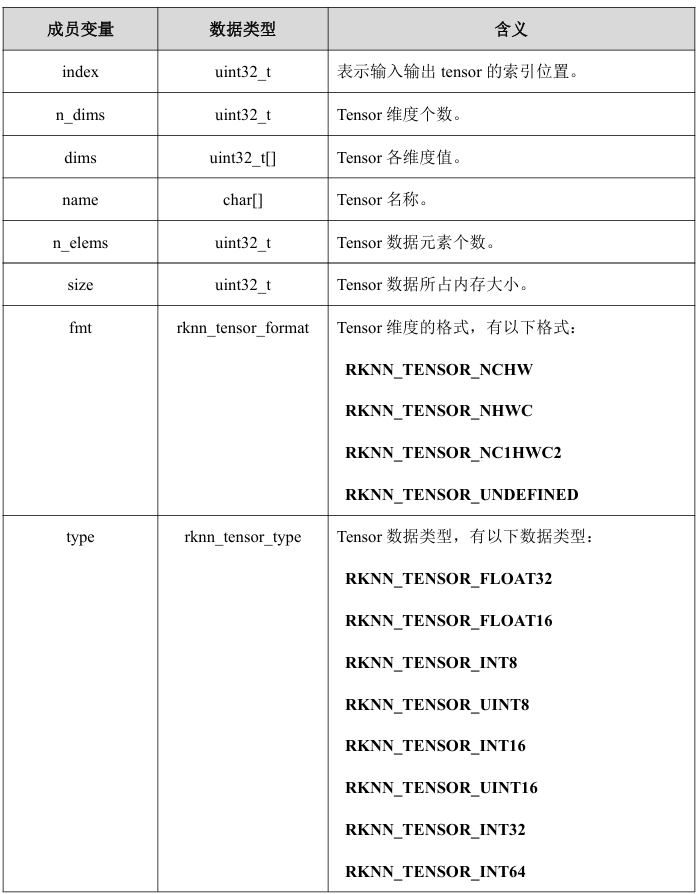
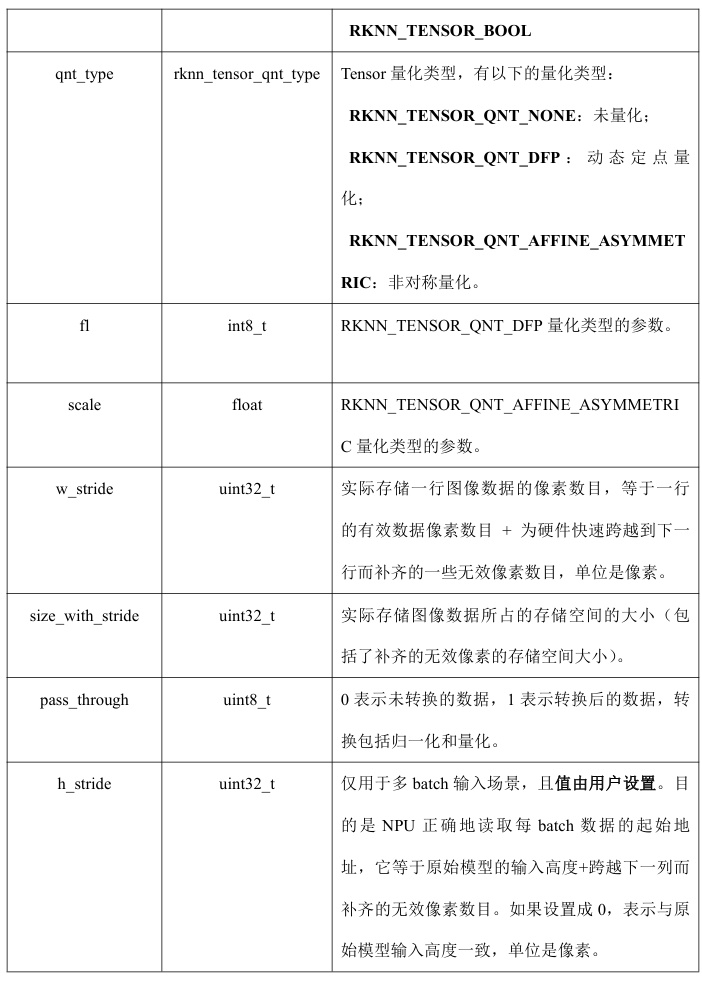
-
rknn_tensor_mem结构体
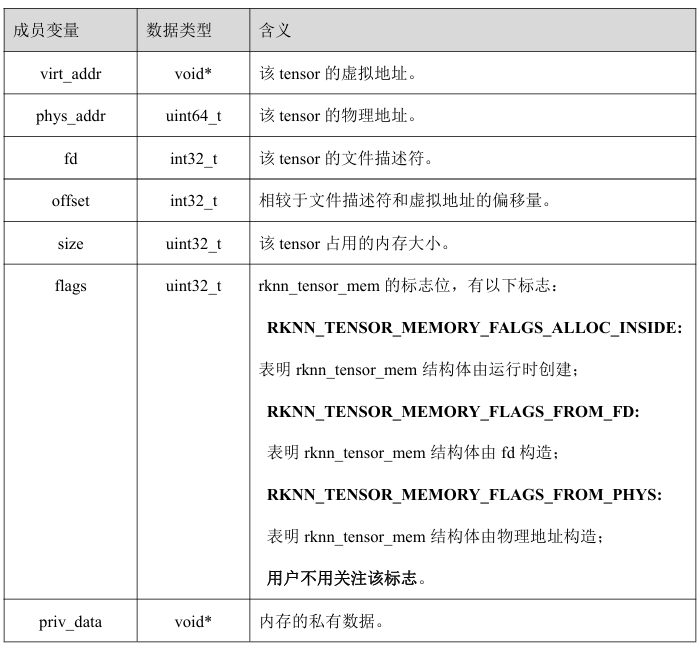
-
rknn_create_mem()API
2.4.2 rknn_set_io_mem
调用rknn_set_io_mem让NPU使用rknn_create_mem申请的内存
实际代码编写:
// 调用rknn_set_io_mem接口让NPU使用上一步申请的内存
input_attr[0].type = RKNN_TENSOR_UINT8;
output_attr[0].type = RKNN_TENSOR_FLOAT32;
rknn_set_io_mem(context, input_mem[0], input_attr);
rknn_set_io_mem(context, output_mem[0], output_attr);
接口解释:
2.4.3 rknn_destory_mem
rknn_destory_mem会销毁rknn_tensor__mem结构体,用户分配的内存需要自行释放
实际代码编写:
rknn_destroy_mem(context, input_mem[0]);
rknn_destroy_mem(context, output_mem[0]);
接口解释: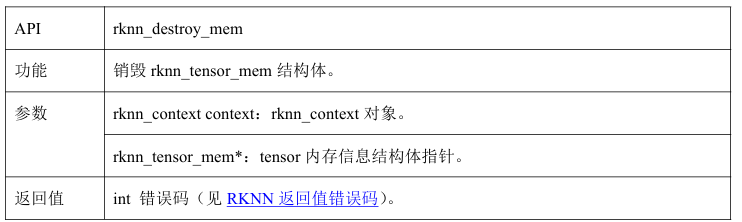
3、开发板上运行
在编写完成main.cc后,执行./build.sh构建工程后能获得build和install两个文件夹。build文件夹中存放的是编译过程文件,install文件夹存放的是可执行程序、模型、测试图片等文件。接下来就是将install文件夹push到开发板上运行了。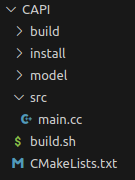
如果你有嵌入式基础那接下来的操作很简单,我使用的是创龙开发板,NPU是瑞芯微rk3588。
3.1 安装windows版adb
安装包链接:通过网盘分享的文件:platform-tools-latest-windows.zip
链接: https://pan.baidu.com/s/1EOM3op8GDep1VI02e50igA 提取码: y2se
- 将压缩包解压到自定义目录下,并将adb文件路径添加到环境变量中
- 验证安装,输入adb version 正确输出版本号即可,如果输出为‘adb’不是内部或外部命令,请检查环境变量是否设置正确
3.2 接通板子
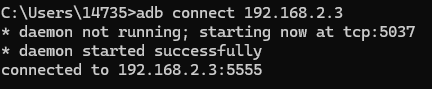
- 使用网线接入windows系统,将网口ip设置为板子同网段
- cmd进入终端,使用adb connect 192.168.2.3连接板子(192.168.2.3是开发板的IP),如果出现下面的提示,表示接通成功
adb常用指令:
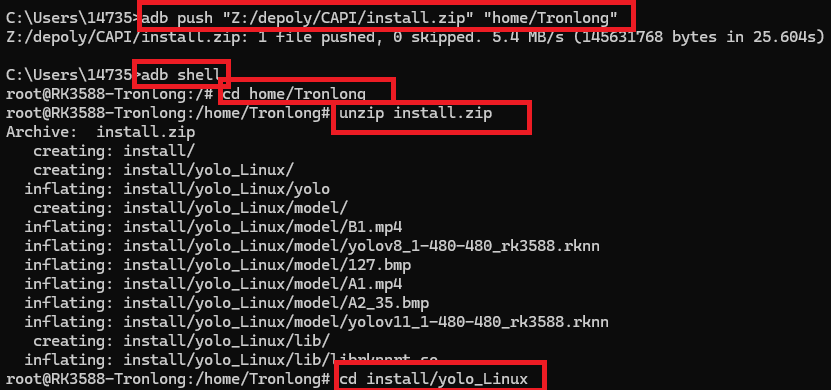
adb push "z:/install.zip" "home/Tronlong" # 将本地z路径下的install.zip文件推到板子的home/Tronlong文件夹下
adb shell # 进入开发板
exit # 退出开发板
unzip install.zip # 解压文件
cd home/Tronlong # 进入home/Tronlong文件夹
ls # 列出文件夹内文件
./yolo model/yolo.rknn model/1.bmp # 执行yolo程序,程序的输入为rknn模型路径和图片路径


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)