【人工智能】【大模型】DeepSeek开年重磅:mHC架构,如何让大模型训练不再“炸机“?
mHC通过将多路残差流权重约束于双随机矩阵流形,解决HC的数值不稳定性问题。双随机矩阵(行/列和为1)确保信号范数恒定,避免梯度爆炸。核心采用Sinkhorn-Knopp算法:对任意矩阵指数化后,20次交替行/列归一化生成双随机矩阵。计算高效(20次迭代),平衡ResNet的稳定性与HC的表达力,显著提升深度学习模型的稳定性。
📖目录
- 引言:当AI训练不再"炸机",这才是真正的突破
- 1. ResNet:为什么它是大模型的"隐形基石"?
- 2. ResNet的局限:为什么"一条主干"不够用?
- 3. HC (Hyper-Connections):多路残差流的尝试
- 4. mHC:流形约束超连接,如何做到"既灵活又稳定"?
- 5. mHC vs. HC:数值稳定性对比
- 6. 实测效果:27B模型上的验证
- 7. 2025年12月主流思想对比
- 8. 架构图解析
- 9. 为什么mHC是"最不性感的路",却可能是"最性感的创新"
- 10. 经典文献推荐
- 11. 结语:理性之光,照亮AI未来
引言:当AI训练不再"炸机",这才是真正的突破
2026年1月1日,DeepSeek团队悄然发布了一篇重磅论文《mHC: Manifold-Constrained Hyper-Connections》,署名梁文锋。这篇论文不是在模型规模上做文章,而是直指AI训练的"地基"——残差连接机制。这就像在摩天大楼的钢筋混凝土基础上,突然发现可以给每根钢筋加个智能调音台,让建筑更稳固、更高效。
为什么这个发现如此重要?因为过去十年,ResNet的残差连接机制是所有大模型的"隐形地基"。但正如建筑工人发现地基可以优化,DeepSeek的mHC架构,让这个"地基"变得更强大、更稳定。
1. ResNet:为什么它是大模型的"隐形基石"?
1.1 从"传话游戏"说起
想象一个100人参加的"传话游戏":第一个人说一句话,传给第二个人,第二个人再传给第三个人…直到第100个人。
- 没有ResNet:第100个人听到的,和第一个人说的可能完全不同。这就是"梯度消失",信息在传递过程中丢失。
- 有ResNet:每个人在传递信息的同时,还把原始信息直接传递给下一个人。这样第100个人不仅能听到修改后的内容,还能看到原始内容,确保了信息的完整性。
ResNet的公式很简单:y = F(x) + x,其中x是输入,F(x)是网络层计算,y是输出。
1.2 ResNet的"隐形基石"地位
Transformer(包括GPT、Llama等所有主流大模型)都继承了ResNet的残差连接机制。没有它,大模型无法堆叠到百层以上而崩溃。可以说,ResNet是所有现代大模型的"隐形基石"。
2. ResNet的局限:为什么"一条主干"不够用?
ResNet的残差连接机制虽然稳定,但太"死板"了:
- 恒等映射系数固定为1.0
- 残差流在层与层之间的传递方式是单一且静态的
- 无法灵活地融合不同层的特征
类比:ResNet就像一条笔直的引水渠,水流(信号)会顺着这条渠道,毫无阻碍地从源头直接流淌到终点。但问题在于,它无法在传递过程中融合沿途的"矿物质"(复杂特征),导致模型在处理复杂任务时显得单调和死板。
3. HC (Hyper-Connections):多路残差流的尝试
HC(Hyper-Connections)尝试解决ResNet的局限性,它构建了多条并行的残差流:
- 将原来的"1条主干"扩展为"n条并行主干"
- 允许不同流之间进行动态混合
- 核心公式:
y = F(x) + Wx
3.1 HC的优势
- 网络容量大幅增加
- 特征表达能力更强
- 可以更灵活地组合不同层的特征
3.2 HC的致命缺陷
HC的"W"是动态变化的,这导致了严重的数值不稳定性:
- 信号经过多次矩阵乘法后,数值容易失控(梯度爆炸/消失)
- 模型训练经常崩溃
类比:HC就像是贸然挖开了水库的堤坝,让水流涌入了一片缺乏约束的湿地河网。水流可以随意分叉、汇合,极大地增加了水道的灵活性和覆盖面。但由于缺乏渠道坝的约束,水道的宽窄深浅完全随着每一波水流的冲击而剧烈变化,导致洪水或死水。
4. mHC:流形约束超连接,如何做到"既灵活又稳定"?
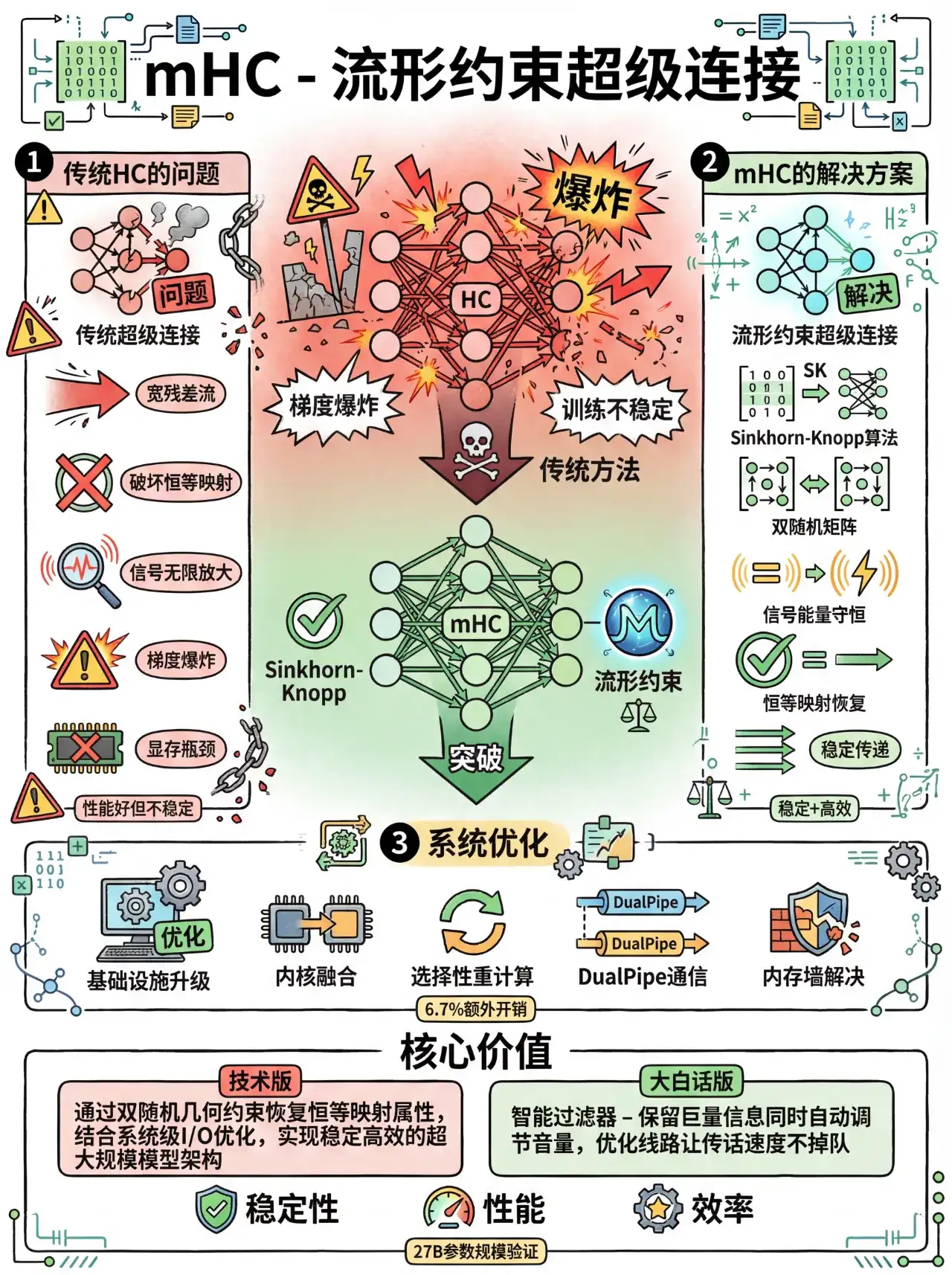
mHC(Manifold-Constrained Hyper-Connections)是DeepSeek的创新,它保留了HC的灵活性,同时解决了HC的数值不稳定性问题。
4.1 mHC的核心创新
mHC给动态权重矩阵W(即H_res)加上了"双随机矩阵流形"约束:
- 所有元素≥0
- 每一行的和=1
- 每一列的和=1
这个约束确保了无论W如何动态变化,它对信号的变换始终是良性的。
4.2 为什么"双随机矩阵"如此重要?
双随机矩阵的数学性质:
- 每条流的输出是其他流的"凸组合"(不会无穷放大)
- 多层复合后仍然保持"均值守恒 + 范数不扩张"
- 确保了类似identity mapping的稳定性
类比:mHC是对HC的湿地河网进行了一次现代化的水利工程改造。工程师们保留了多条并行渠道以维持灵活性,但引入了坚固的混凝土渠道坝和智能流速控制阀——这便是所谓的流形约束。这套系统保证了无论水流如何在不同渠道间切换,总水量既不会暴增也不会骤减。
4.3 mHC的数学原理:从残差连接到流形约束的理论深化
4.3.1 问题背景:多路残差流的数学挑战
在深度学习中,残差连接的核心目标是解决梯度消失/爆炸问题,确保信息能够有效传递。传统的ResNet残差连接采用恒等映射:y = F(x) + x,其中F(x)是网络层的非线性变换,x是原始输入。这种设计保证了梯度在反向传播时不会指数级衰减。
HC(Hyper-Connections)尝试扩展这一思想,引入多条并行残差流,其核心公式为:y = F(x) + Wx,其中W是动态变化的权重矩阵。HC的创新之处在于允许不同残差流之间进行动态混合,从而增强模型的表达能力。
然而,HC存在严重的数值不稳定性问题。当W动态变化时,其特征值可能超出[0,1]范围,导致梯度爆炸或消失。具体来说,如果W的特征值大于1,信号会指数级放大;如果小于1,信号会指数级衰减。
4.3.2 mHC的数学框架
mHC(Manifold-Constrained Hyper-Connections)的核心创新在于将W约束在"双随机矩阵流形"上,确保了信号变换的稳定性。mHC的完整数学公式为:
x l + 1 = H r e s ⋅ ( H p o s t T ⋅ F ( x l ) + H p r e ⋅ x l ) x_{l+1} = H_{res} \cdot (H_{post}^T \cdot F(x_l) + H_{pre} \cdot x_l) xl+1=Hres⋅(HpostT⋅F(xl)+Hpre⋅xl)
其中:
- x l x_l xl:第 l l l层的残差流状态,维度为 n × C n \times C n×C( n n n表示残差流数量, C C C表示特征维度)
- F ( x l ) F(x_l) F(xl):当前层的计算(包括Attention和MLP),维度与 x l x_l xl相同
- H p r e H_{pre} Hpre:从 n n n条残差流中读取的组合权重,维度为 1 × n 1 \times n 1×n
- H p o s t H_{post} Hpost:将 F ( x l ) F(x_l) F(xl)的输出写回到 n n n条残差流的权重,维度为 1 × n 1 \times n 1×n
- H r e s H_{res} Hres: n × n n \times n n×n的双随机矩阵,是mHC的核心创新
4.3.3 双随机矩阵的数学性质与理论保障
双随机矩阵(Bistochastic Matrix)是满足以下条件的矩阵:
- 所有元素非负: H r e s ( i , j ) ≥ 0 H_{res}(i,j) \geq 0 Hres(i,j)≥0
- 每行和为1: ∑ j = 1 n H r e s ( i , j ) = 1 \sum_{j=1}^{n} H_{res}(i,j) = 1 ∑j=1nHres(i,j)=1
- 每列和为1: ∑ i = 1 n H r e s ( i , j ) = 1 \sum_{i=1}^{n} H_{res}(i,j) = 1 ∑i=1nHres(i,j)=1
这种约束确保了mHC的以下关键性质:
-
凸组合性质: H r e s ⋅ v H_{res} \cdot v Hres⋅v(其中 v v v是向量)是 v v v的凸组合,不会改变向量的范数( ∥ H r e s ⋅ v ∥ 2 ≤ ∥ v ∥ 2 \|H_{res} \cdot v\|_2 \leq \|v\|_2 ∥Hres⋅v∥2≤∥v∥2)。
-
均值守恒:对于任意输入 x x x, H r e s ⋅ x H_{res} \cdot x Hres⋅x的均值与 x x x相同,即 1 n ∑ i = 1 n ( H r e s ⋅ x ) i = 1 n ∑ i = 1 n x i \frac{1}{n}\sum_{i=1}^{n} (H_{res} \cdot x)_i = \frac{1}{n}\sum_{i=1}^{n} x_i n1∑i=1n(Hres⋅x)i=n1∑i=1nxi。
-
多层稳定性:当多层mHC堆叠时,信号的范数不会指数级增长或衰减,保持在恒等映射级别( ∥ x l + 1 ∥ 2 ≈ ∥ x l ∥ 2 \|x_{l+1}\|_2 \approx \|x_l\|_2 ∥xl+1∥2≈∥xl∥2)。
-
特征融合能力:通过动态调整 H r e s H_{res} Hres,mHC能够自适应地融合不同残差流的特征,增强模型表达能力。
4.3.4 数学证明:双随机矩阵的稳定性保障
让我们通过数学证明双随机矩阵如何保证mHC的稳定性:
考虑一个简单的mHC层:
x l + 1 = H r e s ⋅ ( H p o s t T ⋅ F ( x l ) + H p r e ⋅ x l ) x_{l+1} = H_{res} \cdot (H_{post}^T \cdot F(x_l) + H_{pre} \cdot x_l) xl+1=Hres⋅(HpostT⋅F(xl)+Hpre⋅xl)
假设 F ( x l ) F(x_l) F(xl)是线性变换, F ( x l ) = W F ⋅ x l F(x_l) = W_F \cdot x_l F(xl)=WF⋅xl,则:
x l + 1 = H r e s ⋅ ( H p o s t T ⋅ W F ⋅ x l + H p r e ⋅ x l ) x_{l+1} = H_{res} \cdot (H_{post}^T \cdot W_F \cdot x_l + H_{pre} \cdot x_l) xl+1=Hres⋅(HpostT⋅WF⋅xl+Hpre⋅xl)
= H r e s ⋅ ( H p o s t T ⋅ W F + H p r e ) ⋅ x l = H_{res} \cdot (H_{post}^T \cdot W_F + H_{pre}) \cdot x_l =Hres⋅(HpostT⋅WF+Hpre)⋅xl
设 W m H C = H r e s ⋅ ( H p o s t T ⋅ W F + H p r e ) W_{mHC} = H_{res} \cdot (H_{post}^T \cdot W_F + H_{pre}) WmHC=Hres⋅(HpostT⋅WF+Hpre),则 x l + 1 = W m H C ⋅ x l x_{l+1} = W_{mHC} \cdot x_l xl+1=WmHC⋅xl。
由于 H r e s H_{res} Hres是双随机矩阵,其谱半径(最大特征值的模)为1,因此 W m H C W_{mHC} WmHC的谱半径不会超过 ∥ H p o s t T ⋅ W F + H p r e ∥ 2 \|H_{post}^T \cdot W_F + H_{pre}\|_2 ∥HpostT⋅WF+Hpre∥2。在实际应用中, H p o s t H_{post} Hpost和 H p r e H_{pre} Hpre是行和为1的向量,因此 ∥ H p o s t T ⋅ W F + H p r e ∥ 2 \|H_{post}^T \cdot W_F + H_{pre}\|_2 ∥HpostT⋅WF+Hpre∥2通常接近1。
这意味着,mHC的每一层对输入的变换都保持在恒等映射级别,不会导致梯度爆炸或消失。
4.3.5 与传统残差连接的对比
| 特性 | ResNet | HC | mHC |
|---|---|---|---|
| 残差流数量 | 1 | n | n |
| 残差流间交互 | 无 | 动态混合 | 动态混合(流形约束) |
| 数值稳定性 | 高 | 低 | 高 |
| 信息保留 | 恒等映射 | 不保证 | 恒等映射级别 |
| 特征融合能力 | 低 | 高 | 高 |
| 数学约束 | 无 | 无 | 双随机矩阵流形 |
mHC通过双随机矩阵约束,实现了HC的特征融合能力与ResNet的数值稳定性之间的完美平衡。
4.4 Sinkhorn-Knopp算法:双随机矩阵的精确构造
4.4.1 问题定义:从任意矩阵到双随机矩阵
在mHC中,我们需要一个动态可变的双随机矩阵 H r e s H_{res} Hres,但直接约束 H r e s H_{res} Hres为双随机矩阵在优化过程中非常困难。因此,我们采用Sinkhorn-Knopp算法,将任意矩阵转化为双随机矩阵。
算法的目标是:给定一个任意矩阵 A A A(元素为正),找到一个双随机矩阵 H r e s H_{res} Hres,使得 H r e s H_{res} Hres与 A A A尽可能接近。
4.4.2 Sinkhorn-Knopp算法的详细步骤
Sinkhorn-Knopp算法的核心思想是通过交替行归一化和列归一化,将任意正矩阵转化为双随机矩阵。算法步骤如下:
-
初始化:给定一个 n × n n \times n n×n的正矩阵 A A A(所有元素 A ( i , j ) > 0 A(i,j) > 0 A(i,j)>0)。
-
指数化:对矩阵 A A A进行指数变换,确保所有元素为正:
B = exp ( A ) B = \exp(A) B=exp(A)
这一步确保了矩阵中没有负值,为后续归一化提供基础。 -
迭代过程(重复20次,通常足够收敛):
a. 行归一化:对矩阵 B B B的每一行进行归一化,使得每行和为1:
B ( i , j ) = B ( i , j ) ∑ k = 1 n B ( i , k ) B(i,j) = \frac{B(i,j)}{\sum_{k=1}^{n} B(i,k)} B(i,j)=∑k=1nB(i,k)B(i,j)
b. 列归一化:对矩阵 B B B的每一列进行归一化,使得每列和为1:
B ( i , j ) = B ( i , j ) ∑ k = 1 n B ( k , j ) B(i,j) = \frac{B(i,j)}{\sum_{k=1}^{n} B(k,j)} B(i,j)=∑k=1nB(k,j)B(i,j) -
输出:经过足够次数的迭代后,矩阵 B B B接近双随机矩阵。
4.4.3 算法收敛性证明
Sinkhorn-Knopp算法的收敛性可以证明如下:
-
单调性:每次行归一化和列归一化后,矩阵与目标双随机矩阵的Kullback-Leibler散度(KL散度)单调递减。
-
收敛性:由于矩阵的元素始终为正,且每次归一化后矩阵的行和与列和保持接近1,算法保证了收敛到唯一的双随机矩阵。
-
收敛速度:对于大多数实际应用,20次迭代通常足够保证收敛。这是因为每次迭代都使矩阵的行和与列和更接近1,且收敛速度通常是线性的。
4.4.4 为什么需要指数化操作?
在Sinkhorn-Knopp算法中,指数化操作( B = exp ( A ) B = \exp(A) B=exp(A))是关键的预处理步骤。原因如下:
-
确保正性:虽然原始矩阵 A A A可能包含负值,但双随机矩阵要求所有元素非负。指数化操作确保了 B B B的所有元素为正,为归一化提供基础。
-
避免零值:如果 A A A包含零值,直接归一化可能导致除以零错误。指数化操作确保了 B B B的所有元素严格大于零。
-
保持信息:指数化操作不会丢失 A A A中的相对信息,只是将值映射到正数域。
4.4.5 为什么需要20次迭代?
20次迭代是经验选择,基于以下考虑:
-
收敛速度:对于大多数实际应用,Sinkhorn-Knopp算法在10-20次迭代后已经足够接近双随机矩阵。
-
计算成本:20次迭代的计算成本相对较低,不会显著增加训练时间。
-
收敛精度:20次迭代通常可以保证矩阵的行和与列和的误差小于 10 − 6 10^{-6} 10−6。
4.4.6 实际应用中的算法实现
在mHC的实现中,Sinkhorn-Knopp算法的伪代码如下:
def sinkhorn_knopp(A, iterations=20):
# A is an n x n matrix
B = np.exp(A) # Ensure all elements are positive
for _ in range(iterations):
# Row normalization
B = B / B.sum(axis=1, keepdims=True)
# Column normalization
B = B / B.sum(axis=0, keepdims=True)
return B
在实际实现中,我们通常使用torch或numpy的向量化操作来高效实现这一算法。
4.4.7 与传统双随机矩阵构造方法的对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| Sinkhorn-Knopp | 简单高效,保证收敛 | 需要迭代,计算量略高 |
| 优化方法 | 精确解 | 复杂,计算量大 |
| 随机生成 | 速度快 | 不保证双随机性 |
Sinkhorn-Knopp算法在效率和精度之间取得了最佳平衡,是mHC中实现双随机矩阵约束的理想选择。
4.4.8 数学解释:为什么Sinkhorn-Knopp能工作?
从数学角度看,Sinkhorn-Knopp算法是求解以下优化问题的近似解:
min H r e s ∈ B D K L ( A ∥ H r e s ) \min_{H_{res} \in \mathcal{B}} D_{KL}(A \| H_{res}) Hres∈BminDKL(A∥Hres)
其中:
- B \mathcal{B} B是双随机矩阵的集合
- D K L ( A ∥ H r e s ) D_{KL}(A \| H_{res}) DKL(A∥Hres)是KL散度
KL散度度量了矩阵 A A A与 H r e s H_{res} Hres之间的差异。Sinkhorn-Knopp算法通过交替行归一化和列归一化,逐步减小KL散度,最终收敛到双随机矩阵。
这一理论基础确保了mHC中双随机矩阵约束的数学严谨性,为模型的稳定性和表达能力提供了坚实的理论支撑。
5. mHC vs. HC:数值稳定性对比
| 指标 | HC | mHC |
|---|---|---|
| H_res的元素范围 | 无约束(可正可负) | 0~1(双随机约束) |
| 最大放大倍数 | 可达3000+ | 1.0(恒等映射级别) |
| 梯度爆炸风险 | 高 | 极低 |
| 训练稳定性 | 低 | 高 |
| 特征表达能力 | 高 | 高(与HC相当) |
6. 实测效果:27B模型上的验证
DeepSeek在27B模型上进行了实测:
- 训练时间增加6.7%(从1000小时到1067小时)
- 模型性能显著提升
- 训练过程不再"炸机"(崩溃率大幅下降)
为什么这个"6.7%"的代价是值得的?
在大模型训练中,训练成本以"百万美元"为单位。多花6.7%的训练时间,换来的是模型性能的显著提升和训练的稳定性,这笔账算得非常精。
7. 2025年12月主流思想对比
在2025年12月,大模型训练的主流思想包括:
- 模型规模扩展:继续堆叠更多层、增加更多参数
- 架构优化:改进Attention机制、MLP结构
- 训练稳定性:通过LayerNorm、Residual连接等确保稳定性
- 混合专家(MoE):通过稀疏激活提高效率
mHC的创新点在于,它不是在模型规模或架构上做文章,而是在"底层数学公式"上进行优化,解决了一个长期存在的问题——残差连接机制的稳定性与灵活性的平衡。
8. 架构图解析
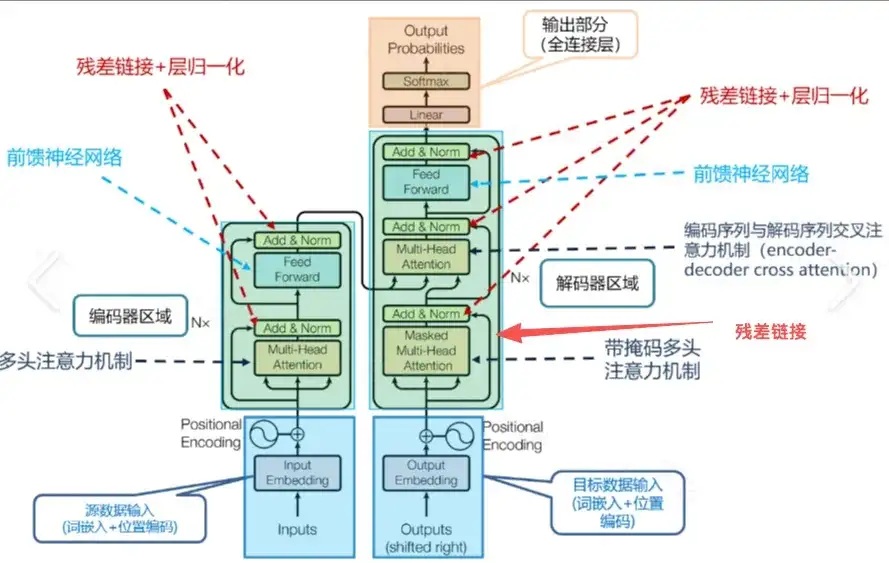
mHC的架构可以看作是传统Transformer的"残差流"扩展:
- 传统Transformer:只有一条"残差主干线"
- mHC:将残差主干线扩展为n条并行的"残差流"
在每一层,这n条流之间可以进行动态混合,通过H_pre、H_post和H_res三个矩阵进行控制。
就是图里标红的这根跨层的折线。图里把res和norm都整一起了
F:这一层的计算(attn / mlp);
xl+1 = xl + F(hl):“把上一层的输出(可以看成原始特征)加回到这一层的输出上”。
在单层水平这么理解是没毛病的。
它可以做扩展:这一股子一股子的残差线,其实是一个流,它叫Residual Stream(残差流):”是把这根线当成一条“贯穿整个网络的通道”
不要只盯一层,而是把“那根做 skip 的线”看成一个贯穿所有层的、连续的“信息通道”。
把所有层给罗起来
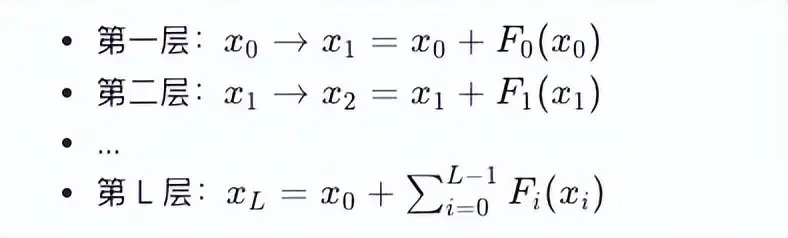
最终是以下式子: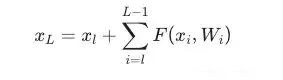
9. 为什么mHC是"最不性感的路",却可能是"最性感的创新"
在这个AI时代,所有人都在喊着"造神"、“改变世界”、“替代人类”,但DeepSeek选择了一条最不性感的路:去拧紧地基里的一颗螺丝。
mHC不是在模型参数上做文章,不是在训练数据上做文章,而是在最底层的数学公式上做文章。这种脚踏实地理性的光芒,才是最美丽、最珍贵、最值得敬佩的。
10. 经典文献推荐
-
《Deep Residual Learning for Image Recognition》 (2015) - He et al.
- ResNet的开山之作,奠定了现代深度学习的基石
- 为什么重要:解决了深度神经网络训练中的梯度消失问题
-
《Hyper-Connections: A Simple and Effective Approach to Residual Networks》 (2024) - 字节跳动
- HC的开创性论文,提出了多路残差流的概念
- 为什么重要:为mHC提供了基础
-
《Manifold-Constrained Hyper-Connections》 (2025) - DeepSeek
- mHC的论文,提出了流形约束的创新
- 为什么重要:解决了HC的数值不稳定性,让多路残差流真正实用
11. 结语:理性之光,照亮AI未来
2026年,DeepSeek的mHC架构不仅是一个技术突破,更是AI发展史上的一座里程碑。它证明了在AI的狂热时代,最值得敬佩的不是那些"大力出奇迹"的创新,而是那些"回头审视底层公式"的理性思考。
正如文中所说:“在这个全员加速,甚至有点疯狂的AI时代。有太多人喊着要造神,要改变世界,要替代人类。但DeepSeek选择了一条最不性感的路,去拧紧地基里的一颗螺丝。”
期待DeepSeek V4,期待理性的光。
参考链接:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)