【CleanRL】强化学习SAC代码实现与原理详解
SAC(Soft Actor-Critic)算法是一种基于熵最大化的Off-Policy Actor-Critic方法,擅长处理连续动作空间问题。其核心思想是通过最大化策略的随机性来鼓励探索,避免局部最优。算法使用两个Critic网络(SoftQNetwork)实现Clipped Double-Q Learning,并通过Actor网络输出动作的概率分布。
文章目录
SAC 是一种 Off-Policy 的 Actor-Critic算法,特别擅长处理 连续动作空间 的问题。它的核心思想是 最大化熵 (entropy),即在完成任务的同时,尽可能地让策略保持随机性,从而鼓励更多的探索,避免过早地收敛到局部最优解,使得算法更加稳定鲁棒。
接下来基于对CleanRL中对SAC算法实现的讨论,来学习这一经典算法的原理,以及分析一下后续修改的方向。
1. SAC算法思想架构
这里贴上一个自己画的实现架构图,可以跟着来理解代码中的每个部分在算法中的作用: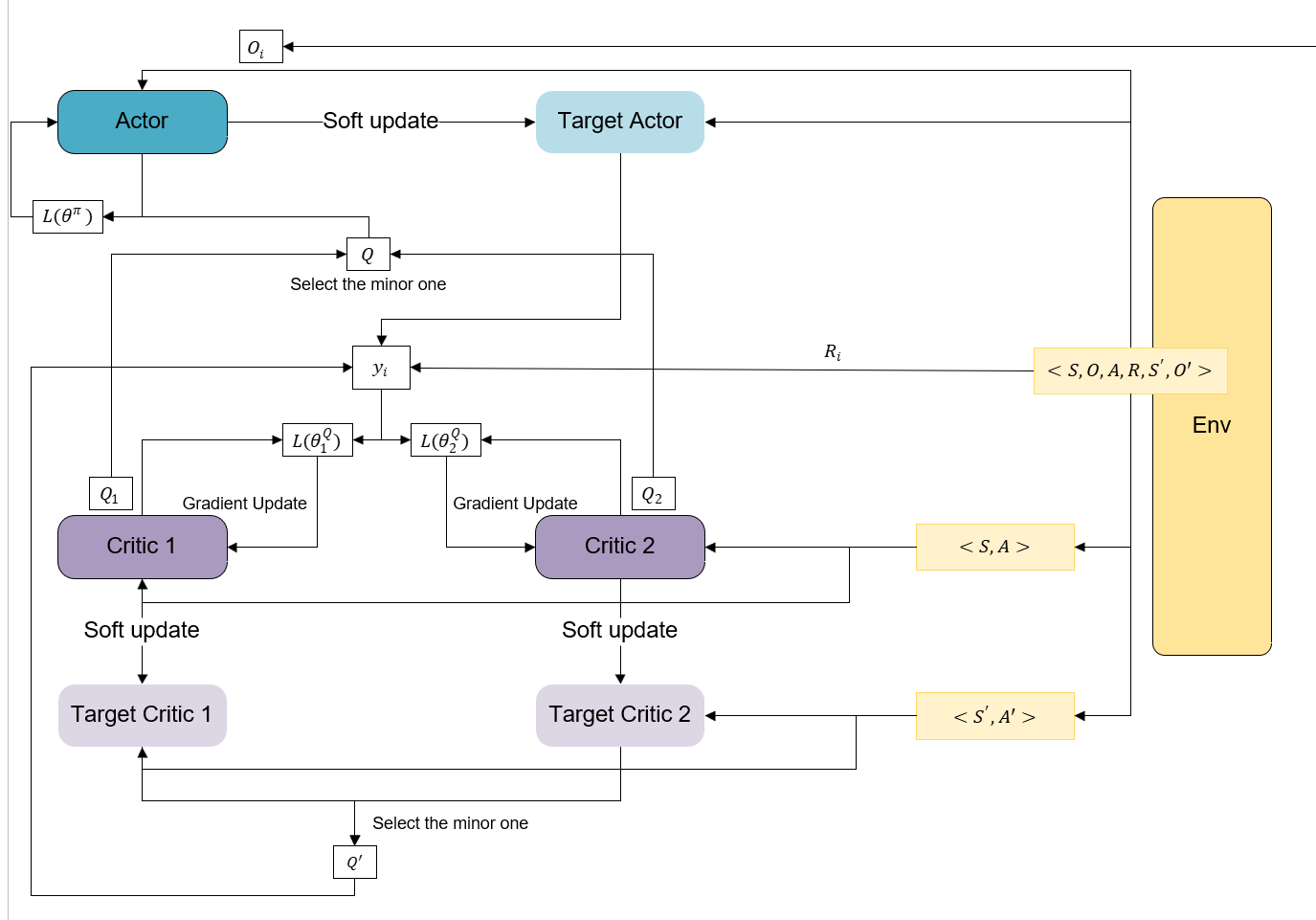
2. 代码结构总览
这个脚本遵循了 CleanRL 的一贯风格,可以分为四个主要部分:
- 参数定义 (
Args类): 定义所有实验相关的超参数。 - 环境和辅助设置 (
make_env函数): 创建和配置模拟环境,这里主要用到的是gym。 - 神经网络定义 (
SoftQNetwork和Actor类): 定义 SAC 算法所需的神经网络结构。 - 主程序 (
if __name__ == "__main__":): 包含了整个训练流程的编排。
3. 参数定义 (@dataclass class Args)
这部分代码使用 dataclass 和 tyro 来管理所有可以通过命令行调整的参数。
exp_name: 实验名称,默认为文件名。seed: 随机种子,用于保证实验的可复现性。track: 是否使用wandb(Weights & Biases) 工具来跟踪和可视化实验。capture_video: 是否录制智能体表现的视频。env_id: 环境名称,默认为"Hopper-v4",这是一个需要控制机器人跳跃的连续动作环境,是gym中的一个项目。total_timesteps: 总的训练步数。buffer_size: 经验回放池 (Replay Buffer) 的大小。SAC 是 Off-Policy 算法,会把过去的经验(s, a, r, s')存储起来,训练时从中随机采样。gamma: 折扣因子,决定了未来奖励的重要性。tau: 目标网络软更新 (Soft Target Update) 的系数。SAC 使用目标网络来稳定训练,tau控制了目标网络追赶主网络的速率。 θ − ← τ θ + ( 1 − τ ) θ − \theta^-\leftarrow\tau\theta+(1-\tau)\theta^- θ−←τθ+(1−τ)θ−batch_size: 每次从经验池中采样的批量大小。learning_starts: 在多少步之后才开始正式的训练。早期主要进行随机探索,填充经验池。policy_lr,q_lr: Actor 和 Critic 网络的学习率。policy_frequency: 策略网络(Actor)的更新频率。SAC 借鉴了 TD3 的思想,让 Actor 的更新频率低于 Critic,这被称为延迟策略更新 (Delayed Policy Updates),可以使训练更稳定。alpha: 熵正则化系数。这是 SAC 的精髓,alpha控制了奖励和熵之间的平衡。alpha越大,策略越倾向于探索(更随机)。autotune: 是否自动调整alpha。这是一个高级技巧,算法可以学习出一个最优的alpha值,而不需要我们手动设置。
4. 神经网络定义 (算法的核心)
SoftQNetwork(nn.Module) - 评论家 (Critic)
Critic网络的任务是评估在某个状态s下,采取某个动作a的好坏程度,即输出 Q 值 Q(s,a),这也是在代码中后续两个实例明明qf的原因。
class SoftQNetwork(nn.Module):
def __init__(self, env):
super().__init__()
self.fc1 = nn.Linear(
np.array(env.single_observation_space.shape).prod() + np.prod(env.single_action_space.shape),256,)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, x, a):
x = torch.cat([x, a], 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
- 输入为 状态 (observation) 和 动作 (action) 的拼接向量。因为代码直接使用了
gym的仿真环境,因此状态和动作都是提前已经定义好了的,即env.single_observation_space和env.single_action_space。 - 接着的网络本体就是简单的几层全连接网络 (Linear layers)。
- 输出为一个标量 (scalar),代表预测的 Q 值。
在主程序中,有 qf1 和 qf2 两个 SoftQNetwork 的实例。这是 SAC 借鉴 TD3 的另一个关键技术,叫做 Clipped Double-Q Learning。通过使用两个独立的 Q 网络,并在计算目标 Q 值时取它们中较小的一个,可以有效地缓解 Q 值被高估的问题,使训练更稳定。
Actor(nn.Module) - 演员 (Actor)
- 作用: 它的任务是决策。给定一个状态
s,它要决定应该采取什么样的动作a。
class Actor(nn.Module):
def __init__(self, env):
super().__init__()
self.fc1 = nn.Linear(np.array(env.single_observation_space.shape).prod(), 256)
self.fc2 = nn.Linear(256, 256)
self.fc_mean = nn.Linear(256, np.prod(env.single_action_space.shape))
self.fc_logstd = nn.Linear(256, np.prod(env.single_action_space.shape))
# action rescaling
self.register_buffer(
"action_scale",
torch.tensor((env.single_action_space.high - env.single_action_space.low) / 2.0,dtype=torch.float32,),)
self.register_buffer(
"action_bias", torch.tensor((env.single_action_space.high + env.single_action_space.low) / 2.0,dtype=torch.float32,),)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
mean = self.fc_mean(x)
log_std = self.fc_logstd(x)
log_std = torch.tanh(log_std)
log_std = LOG_STD_MIN + 0.5 * (LOG_STD_MAX - LOG_STD_MIN) * (log_std + 1) # From SpinUp / Denis Yarats
return mean, log_std
def get_action(self, x):
mean, log_std = self(x)
std = log_std.exp()
normal = torch.distributions.Normal(mean, std)
x_t = normal.rsample() # for reparameterization trick (mean + std * N(0,1))
y_t = torch.tanh(x_t)
action = y_t * self.action_scale + self.action_bias
log_prob = normal.log_prob(x_t)
# Enforcing Action Bound
log_prob -= torch.log(self.action_scale * (1 - y_t.pow(2)) + 1e-6)
log_prob = log_prob.sum(1, keepdim=True)
mean = torch.tanh(mean) * self.action_scale + self.action_bias
return action, log_prob, mean
- 网络结构:
- 输入为环境状态 (observation)。
- 网络组成也是几层全连接网络。但它的输出层比较特殊,分成了两部分:
fc_mean(均值) 和fc_logstd(对数标准差),用来得到后面的概率分布。 - 输出为一个概率分布,而不是一个确定的动作。具体来说,它输出一个正态分布的均值和标准差。
get_action(self, x)方法 (非常核心!):-
输出分布:
mean, log_std = self(x),网络根据输入的状态x输出分布参数。 -
重参数化技巧 (Reparameterization Trick):
x_t = normal.rsample()。这是让 Actor-Critic 方法能够有效训练的关键。它不直接从分布中采样动作,而是先从一个标准正态分布 N(0,1) 中采样一个噪声 ϵ,然后通过action = mean + std * noise来计算动作。这样做的好处是,动作的生成过程变得可微了,梯度可以顺利地从 Critic 反向传播到 Actor。 -
动作缩放和偏移:
y_t = torch.tanh(x_t)和action = y_t * self.action_scale + self.action_bias。神经网络输出的动作通常在一个固定的范围(tanh函数将其限制在 -1 到 1 之间),而环境的动作空间可能是另一个范围(比如 -2 到 2)。这两行代码就是将动作映射到环境允许的正确范围内。 -
计算对数概率
log_prob:log_prob = normal.log_prob(x_t)。这部分是计算在该分布下,生成我们采样的动作x_t的对数概率。这个log_prob就是熵的体现,它将直接用于后续 Actor 和 Critic 的损失函数计算中,是 SAC “Soft” 的来源。
y i = R i + γ ( Q n e x t ′ − α log π ′ ( ⋅ ∣ o i ′ ; θ π − ) ) y_i=R_i+\gamma(Q'_{next}-\alpha\log\pi'(\cdot|o'_i;\theta^{\pi-})) yi=Ri+γ(Qnext′−αlogπ′(⋅∣oi′;θπ−))
-
5. 结合公式实现来看看
我们的目标函数:
J ( π ) = ∑ t = 0 T E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] J(\pi)=\sum_{t=0}^T\mathbb{E}_{(s_t,a_t)\sim\rho_{\pi}}[r(s_t,a_t)+\alpha\mathcal{H}(\pi(\cdot|s_t))] J(π)=t=0∑TE(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))]
Critic(Q网络)的更新
Critic 的任务是评估一个 (状态, 动作) 对的价值,别忘了,SAC算法里面也是有类似值函数的Q网络的,这里就是评估包含了熵的“软”Q-value。
在理论中熵正则化Bellman更新目标的估计值为: r t + γ Q θ i ′ ( s ′ , a ′ ) + α H [ π ( a ′ ∣ s ′ ) ] r_t + \gamma \, Q_{\theta_{i}^{'}}(s', a') + \alpha \, \mathcal{H} \big[ \pi(a' \vert s') \big] rt+γQθi′(s′,a′)+αH[π(a′∣s′)]
而在我们的实际实现中,对于两个Critic网络,软Q-value的损失函数,使用的是MSE损失,为:
J ( θ i Q ) = E ( s , a , r , s ′ ) ∼ D [ ( Q θ i ( s , a ) − y ) 2 ] J(\theta^{Q}_{i}) = \mathbb{E}_{(s,a,r,s') \sim \mathcal{D}} \big[ (Q_{\theta_i}(s, a) - y)^2 \big] J(θiQ)=E(s,a,r,s′)∼D[(Qθi(s,a)−y)2]
核心的软Bellman更新目标函数是:
y = r ( s , a ) + γ ( min θ 1 , 2 Q θ i ′ ( s ′ , a ′ ) − α log π ( ⋅ ∣ s ′ ) ) y = r(s, a) + \gamma ({\color{orange} \min_{\theta_{1,2}}Q_{\theta_i^{'}}(s',a')} - \alpha \, \text{log} \pi( \cdot \vert s')) y=r(s,a)+γ(θ1,2minQθi′(s′,a′)−αlogπ(⋅∣s′))
其中 a ′ ∼ π ( ⋅ ∣ s ′ ) a'\sim\pi(\cdot|s') a′∼π(⋅∣s′),用 log π ( ⋅ ∣ s ′ ) \log\pi(\cdot|s') logπ(⋅∣s′)来近似策略的熵,带’的都是下一状态的项,并且用到的 Q θ ′ Q_{\theta'} Qθ′也指的是target-Q网络。D是存放agent采样的经验回放池。橙色部分取最小值对盈利上面说的Clipped Double-Q Learning取较小的那个,减少估计偏差。
这一块的代码,在下面:
# if global_step > args.learning_starts:
# data = rb.sample(args.batch_size)
with torch.no_grad():
# --- 对应公式中的 a' ~ π(·|s') 和 log π(a'|s') ---
next_state_actions, next_state_log_pi = actor.get_action(data.next_observations)
# --- 对应公式中的 Q_target(s', a') ---
qf1_next_target = qf1_target(data.next_observations, next_state_actions)
qf2_next_target = qf2_target(data.next_observations, next_state_actions)
# --- 对应公式中的 min Q_target ---
min_qf_next_target = torch.min(qf1_next_target, qf2_next_target)
# --- 对应公式中的 (min Q_target - α * log π) ---
next_q_value_rhs = min_qf_next_target - alpha * next_state_log_pi
# --- 对应公式中的 y = r + γ * (...) ---
# (1 - data.dones.flatten()) ensures that if a state is terminal, the future value is 0.
next_q_value = data.rewards.flatten() + (1 - data.dones.flatten()) * args.gamma * next_q_value_rhs.view(-1)
# --- 对应公式中的 Q_θ(s, a) ---
qf1_a_values = qf1(data.observations, data.actions).view(-1)
qf2_a_values = qf2(data.observations, data.actions).view(-1)
# --- 对应公式中的 L_Q(θ) = MSE(Q_θ(s,a), y) ---
qf1_loss = F.mse_loss(qf1_a_values, next_q_value)
qf2_loss = F.mse_loss(qf2_a_values, next_q_value)
qf_loss = qf1_loss + qf2_loss
# --- 更新 Critic 网络 ---
q_optimizer.zero_grad()
qf_loss.backward()
q_optimizer.step()
Actor (策略网络) 的更新
对于动作网络,目标是调整自己的动作策略,使其能够输出拥有更高去软Q值的动作,也就是同时考虑期望Q值和熵。损失函数如下:
L π ( ϕ ) = E s ∼ D , a ∼ π ϕ [ α log π ϕ ( a ∣ s ) − min j = 1 , 2 Q θ j ( s , a ) ] L_{\pi}(\phi)=\mathbb{E}_{s\sim\mathcal{D},a\sim\pi_{\phi}}[\alpha\log\pi_{\phi}(a|s)-\min_{j=1,2}Q_{\theta_j}(s,a)] Lπ(ϕ)=Es∼D,a∼πϕ[αlogπϕ(a∣s)−j=1,2minQθj(s,a)]
注意这里的 Q θ Q_{\theta} Qθ是指的主Q网络(Critic),而不是target网络,在代码实现时,在if global_step % args.policy_frequency == 0:内:
# --- 对应公式中的 a ~ π_φ(·|s) 和 log π_φ(a|s) ---
# `actor.get_action` 内部使用了重参数化技巧来采样,这个函数的实现后面再讲
pi, log_pi = actor.get_action(data.observations)
# --- 对应公式中的 Q_θ(s, a) ---
qf1_pi = qf1(data.observations, pi)
qf2_pi = qf2(data.observations, pi)
# --- 对应公式中的 min Q_θ(s, a) ---
min_qf_pi = torch.min(qf1_pi, qf2_pi).view(-1)
# --- 对应公式 L_π(φ) = E[α*logπ - minQ] ---
# 我们要最小化这个损失,等价于最大化 E[minQ - α*logπ]
actor_loss = ((alpha * log_pi) - min_qf_pi).mean()
# --- 更新 Actor 网络 ---
actor_optimizer.zero_grad()
actor_loss.backward()
actor_optimizer.step()
α \alpha α熵系数的自动调整
对于“熵” α \alpha α在目标函数中的变化,采用了一种随着训练变化的策略,目的是在刚开始基于较大的熵,在训练后期给较少的熵来维持稳定:
α t ∗ = argmin α t E a t ∼ π t ∗ [ − α t log π t ∗ ( a t ∣ s t ; α t ) − α t H ] , \alpha^{*}_t = \text{argmin}_{\alpha_t} \mathbb{E}_{a_t \sim \pi^{*}_t} \big[ -\alpha_t \, \text{log}\pi^{*}_t(a_t \vert s_t; \alpha_t) - \alpha_t \mathcal{H} \big], αt∗=argminαtEat∼πt∗[−αtlogπt∗(at∣st;αt)−αtH],
对 α \alpha α求导并更新,就可以让 α 自动调整。target_entropy H \mathcal{H} H通常被设置为 -dim(A),其中 A 是动作空间维度。在代码中,是在if args.autotune:
# 我们优化的是 log(α) 而不是 α,以保证 α > 0
# 注意 actor_loss.backward() 之前已经计算了 log_pi
# --- 对应公式 L(α) ---
# .detach() 是因为我们在这里只想优化 α,不想让梯度流回 Actor
alpha_loss = (-log_alpha.exp() * (log_pi + target_entropy).detach()).mean()
# --- 更新 α ---
alpha_optimizer.zero_grad()
alpha_loss.backward()
alpha_optimizer.step()
# 更新 α 的实际值
alpha = log_alpha.exp().item()
Actor重参数化生成动作
Actor不直接从分布中采样动作,而是先从一个高斯分布为 μ ϕ s \mu_{\phi_s} μϕs和 σ ϕ s \sigma_{\phi_s} σϕs,动作a由以下方式生成:
a = tanh ( μ ϕ ( s ) + σ ϕ ( s ) ⊙ ϵ ) a=\tanh(\mu_{\phi}(s)+\sigma_{\phi}(s)\odot\epsilon ) a=tanh(μϕ(s)+σϕ(s)⊙ϵ)
- ⊙ \odot ⊙表示逐元素相乘, ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I)
tanh函数将动作值压缩到[-1, 1]范围内。- 由于
tanh是一个非线性变换,计算log π时需要一个修正项。
在Actor类的get_action方法中:
# class Actor(nn.Module):
# def get_action(self, x):
mean, log_std = self(x)
std = log_std.exp()
# --- 对应公式中的 ε ~ N(0, I) ---
normal = torch.distributions.Normal(mean, std)
# --- 对应公式中的 μ + σ * ε ---
# .rsample() 内部就实现了重参数化
x_t = normal.rsample()
# --- 对应公式中的 tanh(...) ---
y_t = torch.tanh(x_t)
# --- 将动作映射到环境的实际范围 ---
action = y_t * self.action_scale + self.action_bias
# --- 计算 log π(a|s) 并加入 tanh 的修正项 ---
log_prob = normal.log_prob(x_t)
log_prob -= torch.log(self.action_scale * (1 - y_t.pow(2)) + 1e-6)
log_prob = log_prob.sum(1, keepdim=True)
return action, log_prob
这个 log_prob 的计算看起来复杂,但它正是应用了概率论中的变量替换法则,来精确计算经过 tanh 变换后的动作的对数概率。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)