强化学习的学习之路(十九)_2021-01-19: Multi-step DQN
作为一个新手,写这个教程也是想和大家分享一下自己学习强化学习的心路历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己能保证起码平均一天一更的速度,先是介绍强化学习的一些基础知识,后面介绍强化学习的相关论文。本来是想每一篇多更新一点内容的,后面想着大家看CSDN的话可能还是喜欢短一点的文章,就把很多拆分开来了,目录我单独放在一篇单独的博客里面了。完整的我整理好了会放在github上,大家一
作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己学习强化学习的学习历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己在2021年能保证平均每日一更的更新速度,主要是介绍强化学习的基础知识,后面也会更新强化学习的论文阅读专栏。本来是想每一篇多更新一点内容的,后面发现大家上CSDN主要是来提问的,就把很多拆分开来了(而且这样每天任务量也小一点哈哈哈哈偷懒大法)。但是我还是希望知识点能成系统,所以我在目录里面都好按章节系统地写的,而且在github上写成了书籍的形式,如果大家觉得有帮助,希望从头看的话欢迎关注我的github啊,谢谢大家!另外我还会分享深度学习-基础知识专栏以及深度学习-论文阅读专栏,很早以前就和小伙伴们花了很多精力写的,如果有对深度学习感兴趣的小伙伴也欢迎大家关注啊。大家一起互相学习啊!可能会有很多错漏,希望大家批评指正!不要高估一年的努力,也不要低估十年的积累,与君共勉!
接下来的几个博客将会分享以下有关DQN算法及其改进,包括DQN(Nature)、Double DQN、 Multi-step DQN、Pirority Replay Buffer、 Dueling DQN、DQN from Demonstrations、Distributional DQN、Noisy DQN、Q-learning with continuous actions、Rainbow、Practical tips for DQN等。
Multi-step的思想在前面已经多次提到了,这里就不再赘述了,也就是用n-steps return 来替代reward:
y j , t = ∑ t ′ = t t + N − 1 γ t − t ′ r j , t ′ + γ N max a j , t + N Q ϕ ′ ( s j , t + N , a j , t + N ) y_{j, t}=\sum_{t^{\prime}=t}^{t+N-1} \gamma^{t-t^{\prime}} r_{j, t^{\prime}}+\gamma^{N} \max _{\mathbf{a}_{j, t+N}} Q_{\phi^{\prime}}\left(\mathbf{s}_{j, t+N}, \mathbf{a}_{j, t+N}\right) yj,t=t′=t∑t+N−1γt−t′rj,t′+γNaj,t+NmaxQϕ′(sj,t+N,aj,t+N)
它的好处是减少了Q值估计不准的时候的biased,通常也能加速训练。但是问题也是来自于n-steps,既然出现了n-steps,那么自然就涉及到状态转移了,在不同policy下,当前的n-steps trajectory出现的概率就不同,这也就导致了在off-policy的buffer data存在出现distribution mismatch的问题,所以导致它只在on-policy的情况下有用: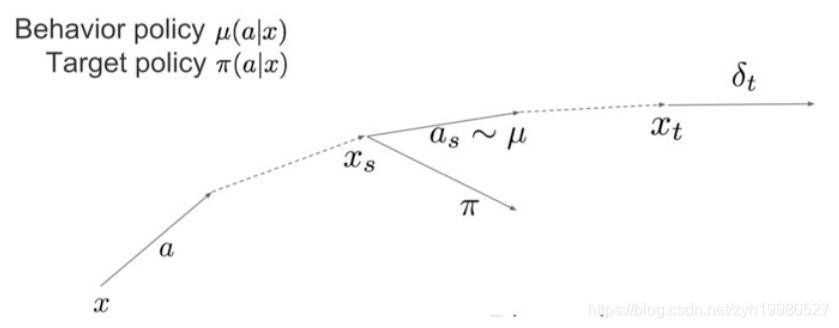
那么怎么解决这个问题呢?大致有以下三种思路:
- ignore the problem often works very well 忽略他们,算法一般也能有用,在现在大部分使用n-steps的算法,包括GORILA、Ape-X,R2D2等都是这样操作的。
- cut the trace - dynamically choose N \mathrm{N} N to get only on-policy data 利用某些手段去cut掉这些trace,一般都是通过两个policy生成这个trace的probability比值是否超过某个阈值来判定,比较著名的就是Retrace以及基于它的ACER,IMPALA等
- works well when data mostly on-policy, and action space is small
- importance sampling 重要性采样
上一篇:强化学习的学习之路(十八)_2021-01-18:Double Q-learning(Deep Reinforcement Learning with Double Q-learning)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)