veRL框架下DAPO强化学习算法的实现解析
随着大语言模型在复杂推理任务中的应用日益广泛,强化学习已成为提升模型生成质量的关键技术。DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)作为一种新型策略优化算法,通过解耦裁剪、动态采样等机制,有效解决了长序列生成中的训练效率和稳定性问题。本文基于VeRL强化学习框架,深入解读DAPO算法的核心原理与代码实现,为开发者提供实践
作者:昇腾实战派
知识地图链接:强化学习知识地图
背景概述
随着大语言模型在复杂推理任务中的应用日益广泛,强化学习已成为提升模型生成质量的关键技术。DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)作为一种新型策略优化算法,通过解耦裁剪、动态采样等机制,有效解决了长序列生成中的训练效率和稳定性问题。本文基于VeRL强化学习框架,深入解读DAPO算法的核心原理与代码实现,为开发者提供实践参考。
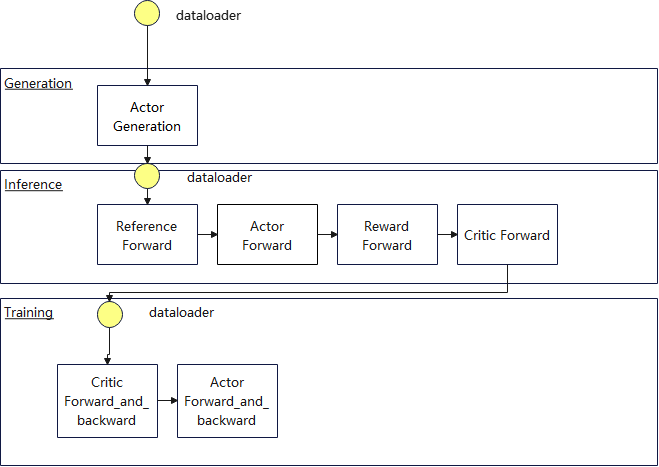
1. 强化学习基本训练流程
2. DAPO算法概述
参考文章:https://www.zhihu.com/question/1895273986537014226/answer/1899582779408245950
论文:https://arxiv.org/abs/2503.14476
详细好文:https://blog.csdn.net/songxia928_928/article/details/146606792
DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization,即解耦裁剪和动态采样策略优化)的优化点有四个(其中前2个是主要亮点,是命名的来源):
解耦剪裁和动态采样策略优化 (DAPO) 算法,其中包含以下几个关键技术。详细分析和见解可在DAPO的技术报告中找到。
- Clip-Higher: 它提升了系统的多样性并避免了熵坍缩。DAPO 在初步实验中观察到熵坍缩现象。DAPO增加策略梯度损失中重要性采样比率的上限剪裁范围以减轻这个问题。
- Dynamic Sampling: 它提高了训练效率和稳定性。DAPO出了一种执行动态采样的策略,并过滤掉准确率等于1和0的提示组,从而保持批次间具有有效梯度的提示数量一致。
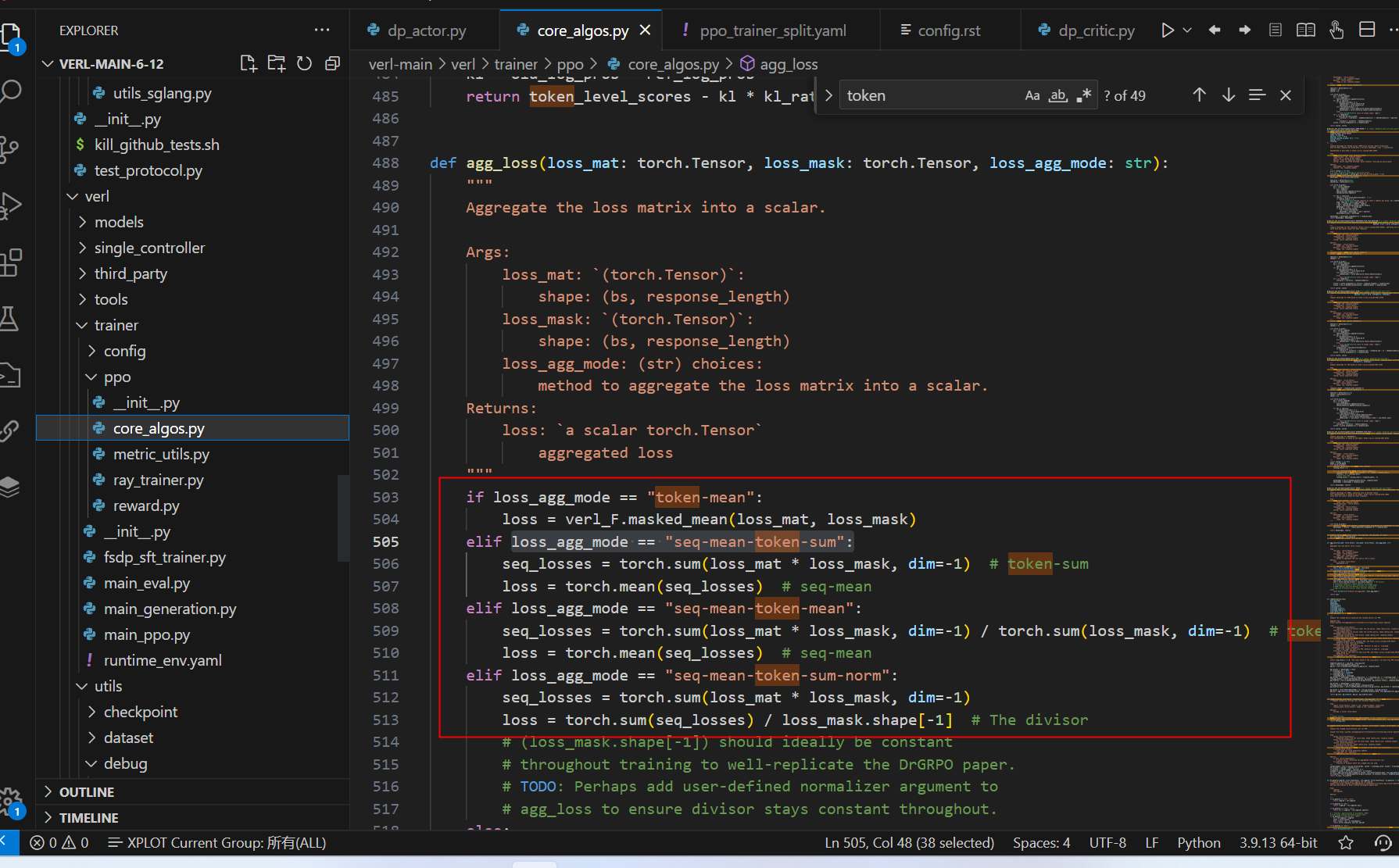
- Token-level Policy Gradient Loss: 这在长链思维强化学习 (long-CoT RL) 场景中至关重要。
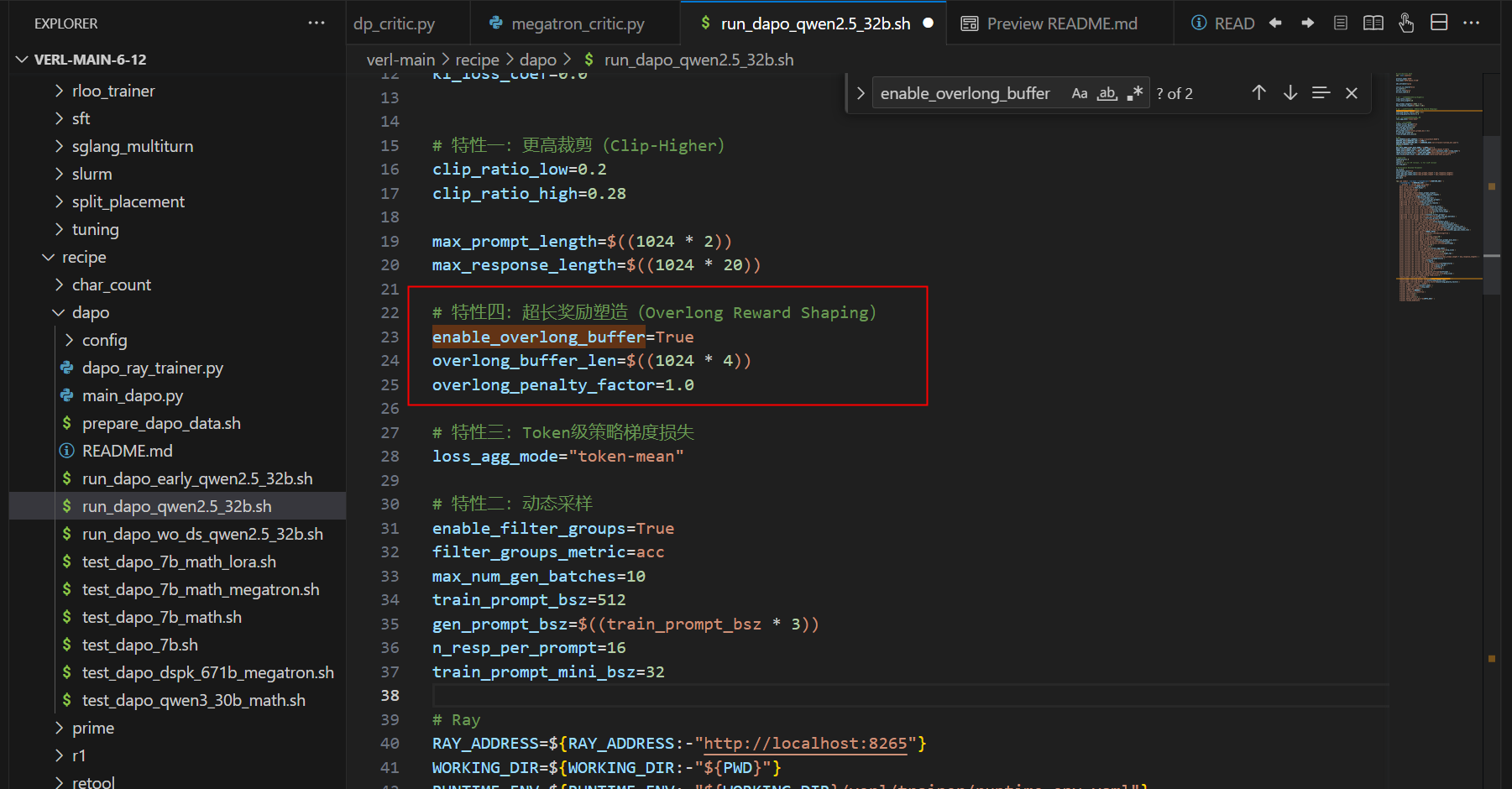
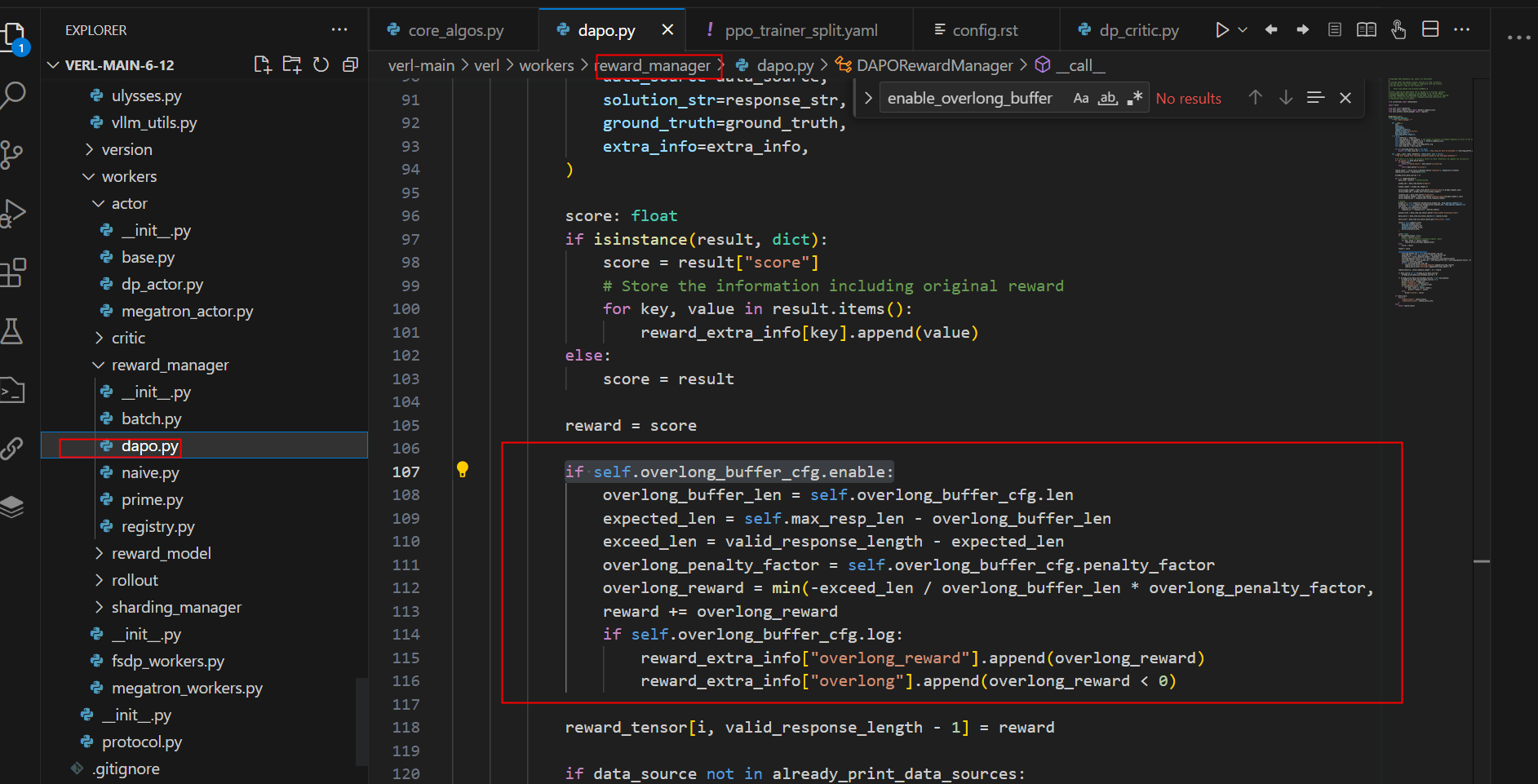
- Overlong Reward Shaping: 它减少了奖励噪声并稳定了训练。
DAPO还把KL散度干掉了。
2.1 更高裁剪(Clip-Higher)
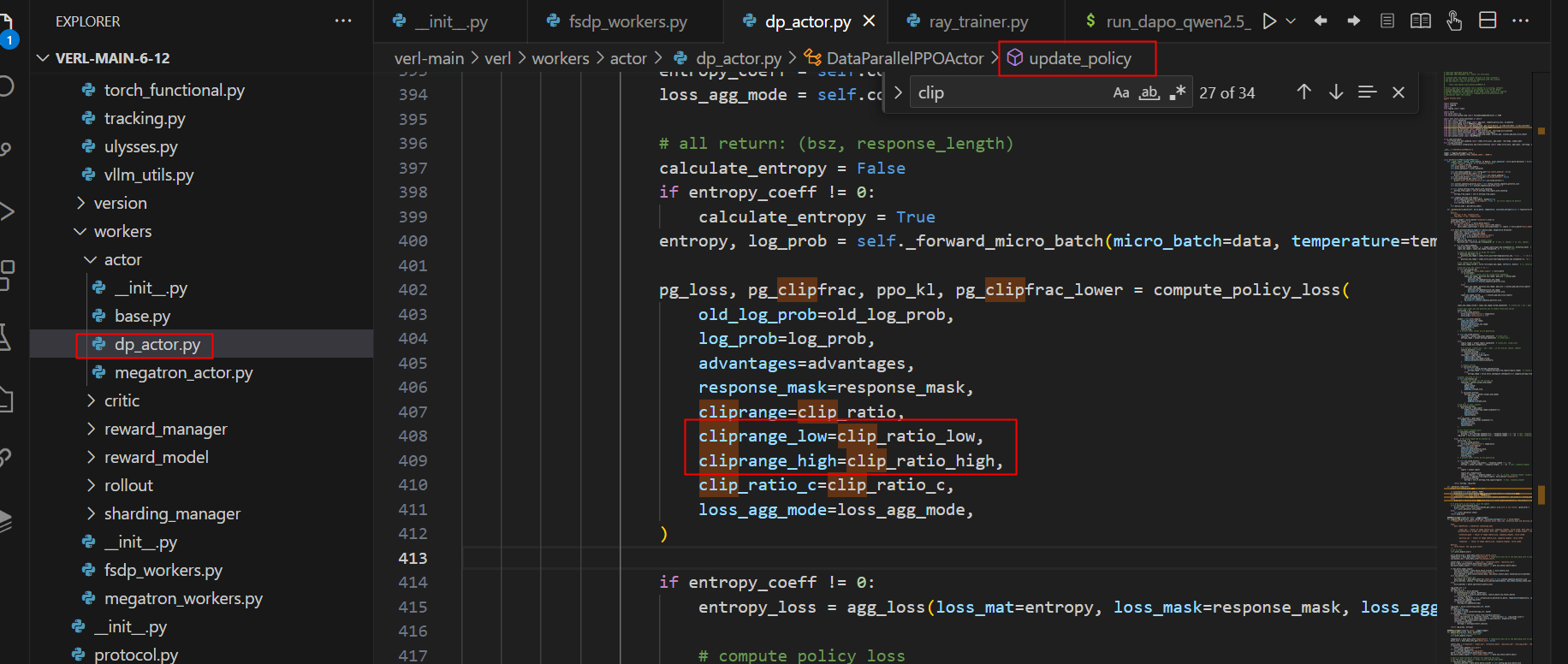
有图可知:clip的右侧区间限制了A>0时策略概率值的增大,clip的左侧区间限制了A<0时策略概率值的减小。同时,存在一个现象:当 ε = 0.2 ε=0.2 ε=0.2 (大多数算法的默认值)时,考虑两个概率为 π θ o l d ( o i ∣ q ) π θ o l d ( o i ∣ q ) π θ o l d ( o i ∣ q ) = 0.01 πθold(oi∣q)π_{\theta_{old}}(o_i∣q)π_{\theta_{old}}(o_i∣q) = 0.01 πθold(oi∣q)πθold(oi∣q)πθold(oi∣q)=0.01 和 0.9 ,其最大可能的更新概率 $πθ(oi∣q)π_{\theta}(o_i∣q)π_{\theta}(o_i∣q) 分别为 0.012 和 1.08 ,这意味着对于概率较高的 t o k e n (如 0.9 )限制较少。相反,对于低概率(如 0.01 )的 t o k e n ,实现概率的显著增加要困难得多。因此,上裁剪阈值确实限制了低概率 t o k e n 的概率增加,从而可能限制系统的多样性。因此,为了适用于 r e a s o n i n g m o d e l ,论文将下裁剪和上裁剪范围解耦为 分别为 0.012 和 1.08,这意味着对于概率较高的token(如0.9)限制较少。相反,对于低概率(如0.01)的token,实现概率的显著增加要困难得多。因此,上裁剪阈值确实限制了低概率token的概率增加,从而可能限制系统的多样性。因此,为了适用于reasoning model,论文将下裁剪和上裁剪范围解耦为 分别为0.012和1.08,这意味着对于概率较高的token(如0.9)限制较少。相反,对于低概率(如0.01)的token,实现概率的显著增加要困难得多。因此,上裁剪阈值确实限制了低概率token的概率增加,从而可能限制系统的多样性。因此,为了适用于reasoningmodel,论文将下裁剪和上裁剪范围解耦为 εlowε_{low}ε_{low} 和 εhighε_{high}ε_{high}$ ,且提升 ε h i g h ε h i g h ε h i g h εhighε_{high}ε_{high} εhighεhighεhigh 的值,为低概率 Token 的增加留出更多空间,以促进样本生成的多样性。

2.2 动态采样(Dynamic Sampling)

2.3 Token级策略梯度损失
在GRPO中,每个样本在最终损失计算中被分配相同的权重,这会导致较长response的token对整体损失的贡献可能不成比例地低。作者也从实验中观察到了这一问题产生的困难。因此,作者在reasoning场景中引入了Token级策略梯度损失,这具备2个优点:
- 在这种设置下,较长序列相比较短序列对整体梯度更新的影响可能更大。
- 从单个token来看,如果特定生成模式能导致奖励增加或减少,无论它出现在哪种长度的响应中,都将被同等地促进或抑制。
为了更好地理解这一策略,这里基于实际数值进行了举例说明,见图2-4:

2.4 超长奖励塑造(Overlong Reward Shaping)

3. DAPO算法在VeRL中的实现对应
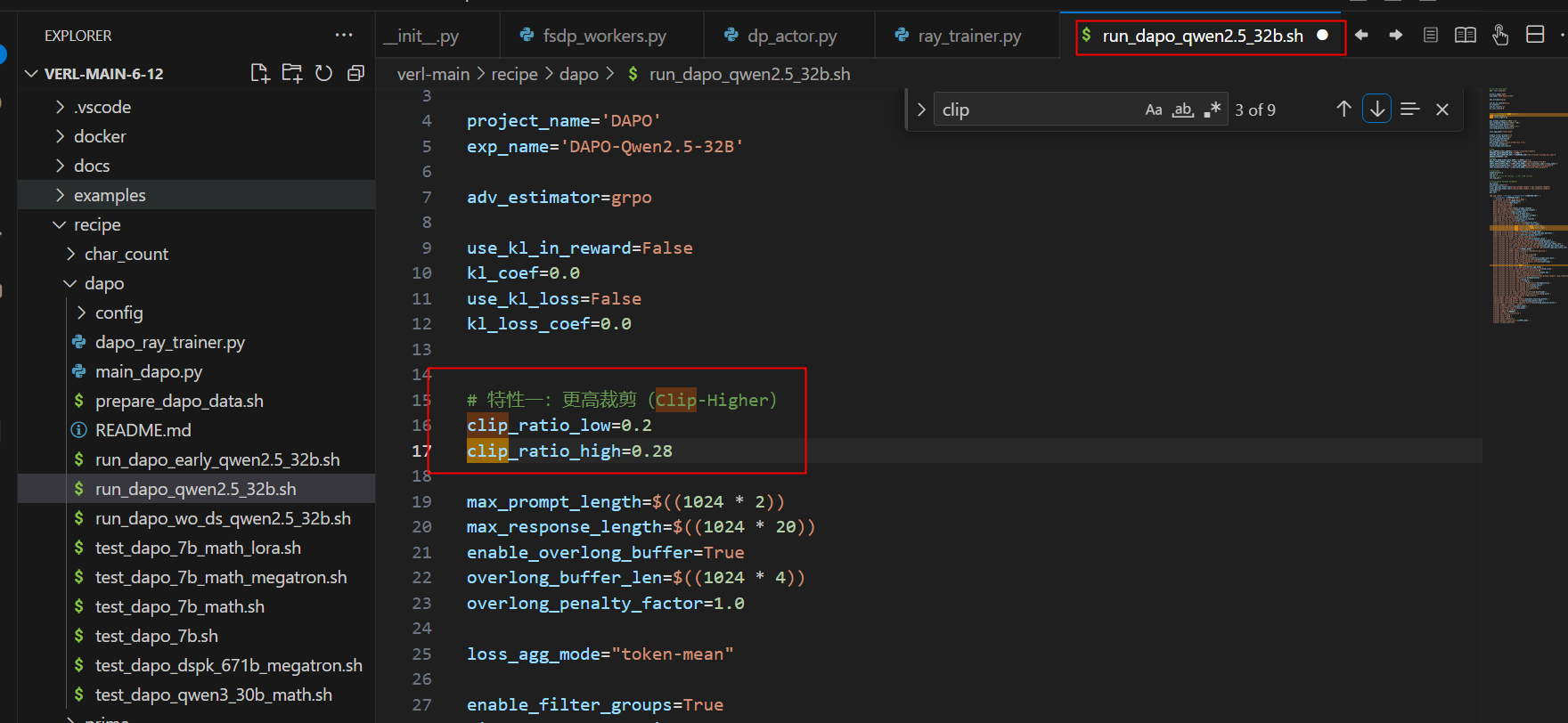
3.1 更高裁剪实现
3.2 动态采样实现
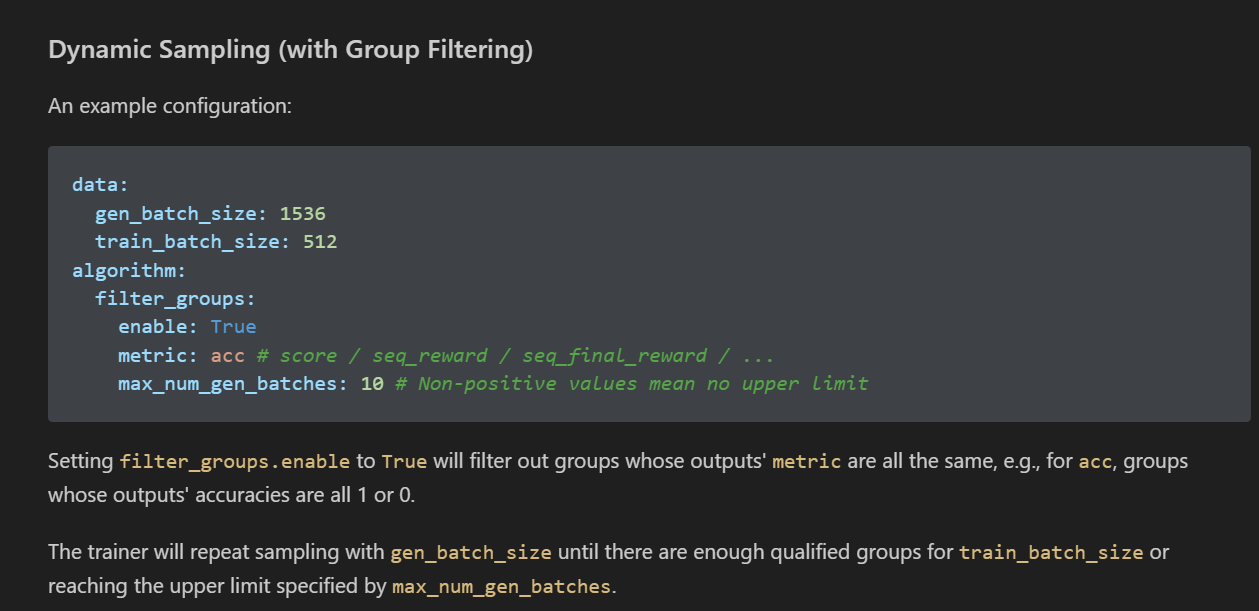
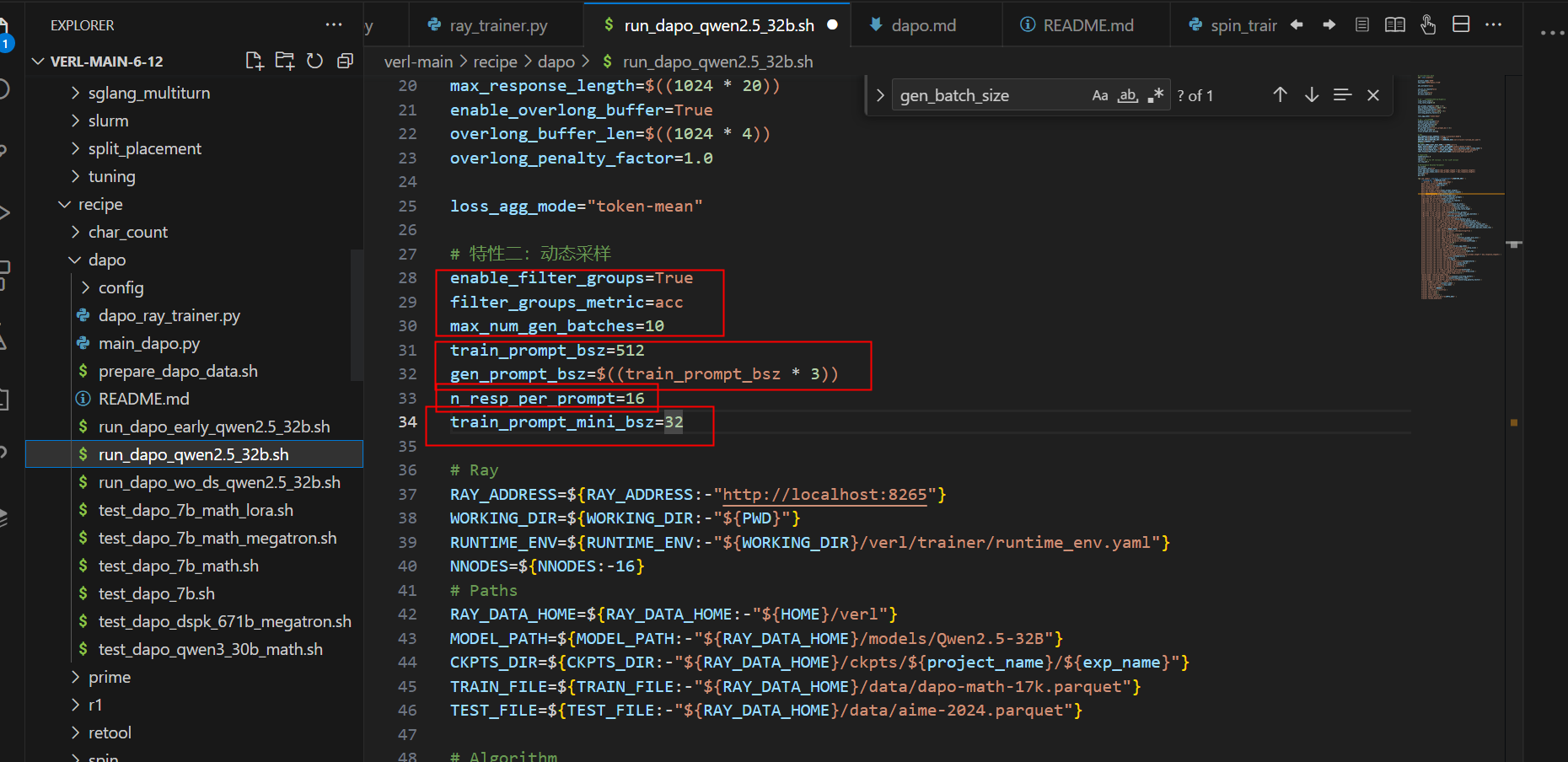
将“filter_groups.enable”设置为“True”将过滤掉输出“metric”都相同的组,即过滤对于“acc”,输出“精度”都为1或0的组。
训练器将使用gen_batch_size重复推理采样,直到有足够的合格组用于train_batch_size 或达到max_num_gen_batches 指定的上限。注意这里的max_num_gen_batches是指经过多少个batches个数,不是batch size
采样逻辑:
在一个epoch内,遍历batch时,一个batch中会抽gen_batch_size 1536条数据去做推理,每条请求会生成n_resp_per_prompt 16条数据(推出每一组数据)。
开启动态采样,会在每个batch中,用filter_groups.enable”设置为“True”将过滤掉输出“metric”都相同的组,即过滤对于输出“acc”都为1或0的组。导致最终1536条会可能低于train_batch_size 512。如果过滤完还大于512,那么直接update到下一个batch。如果低于512,那么会直接continue,把下一个batch gen_batch_size 1536推理出来,直到满足512。
但是可能存在跑了很多个batch还是过滤掉大部分的组,那么通过max_num_gen_batches 10来做限制,一个update最多消耗掉10个batch(10*1536)。
Dapo_ray_trainer.py继承与ray_trainer.py,train_Dataloader的batch_size优先是gen_batch_size。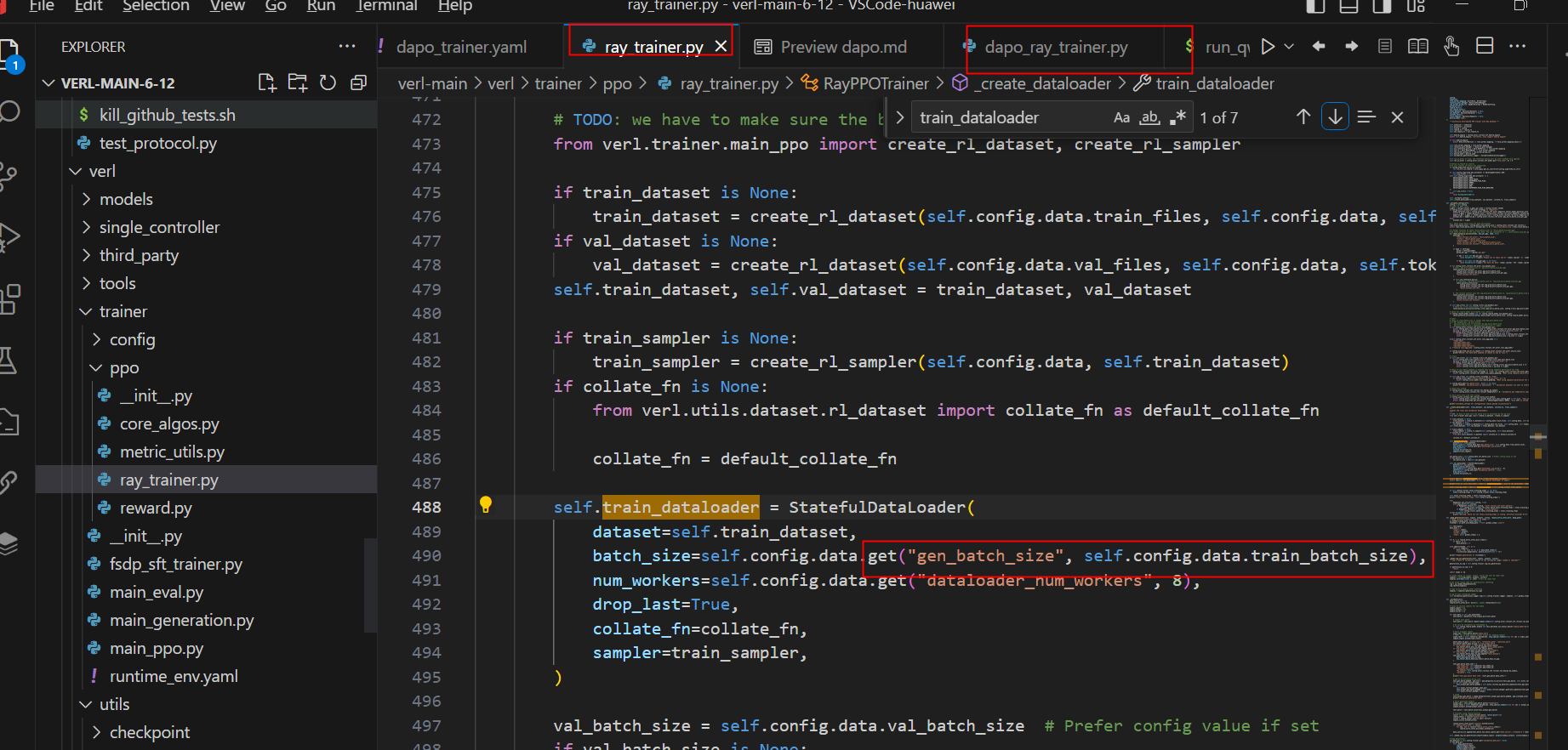
重复采样逻辑: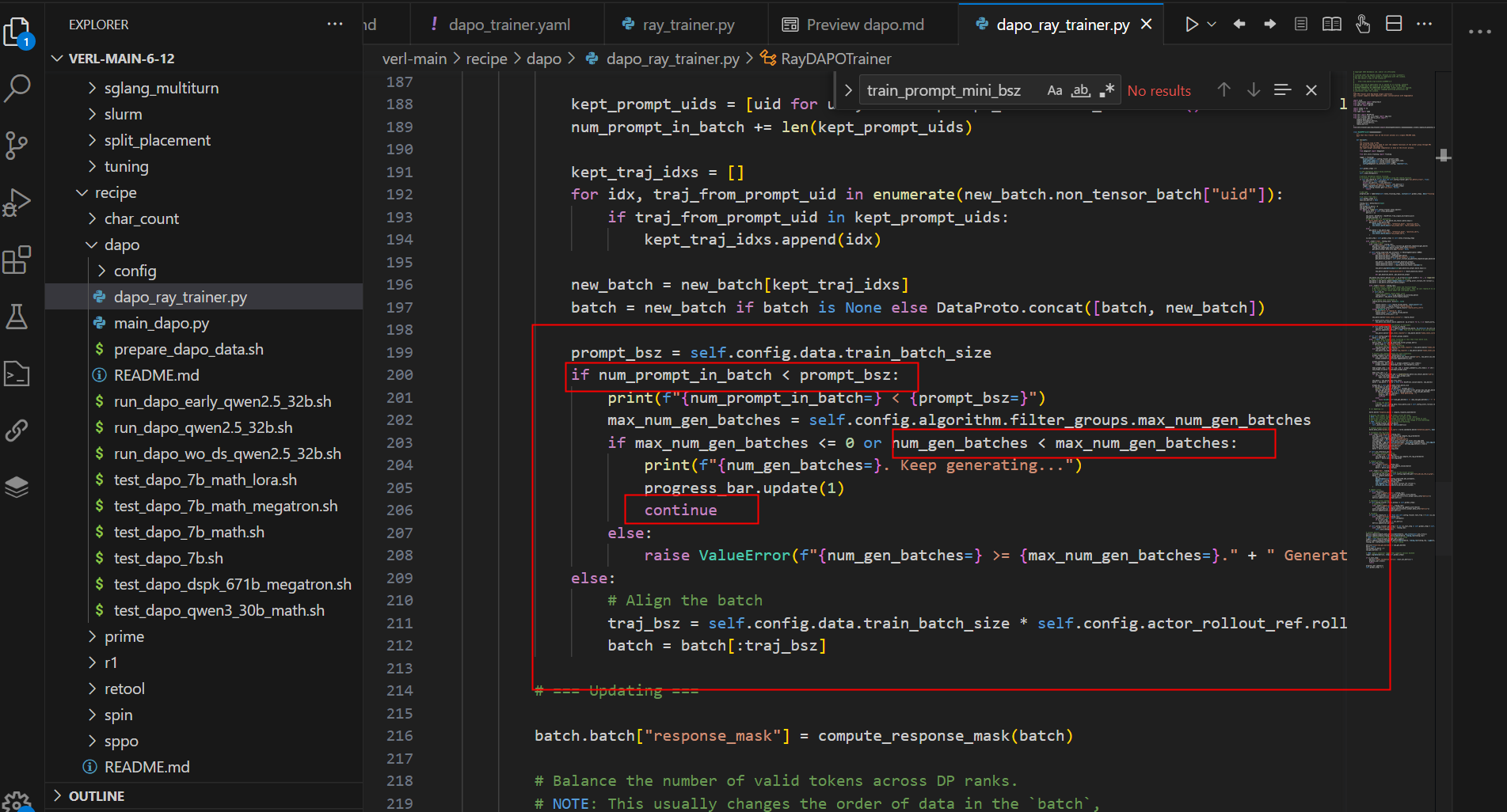
3.3 Token级策略梯度损失实现
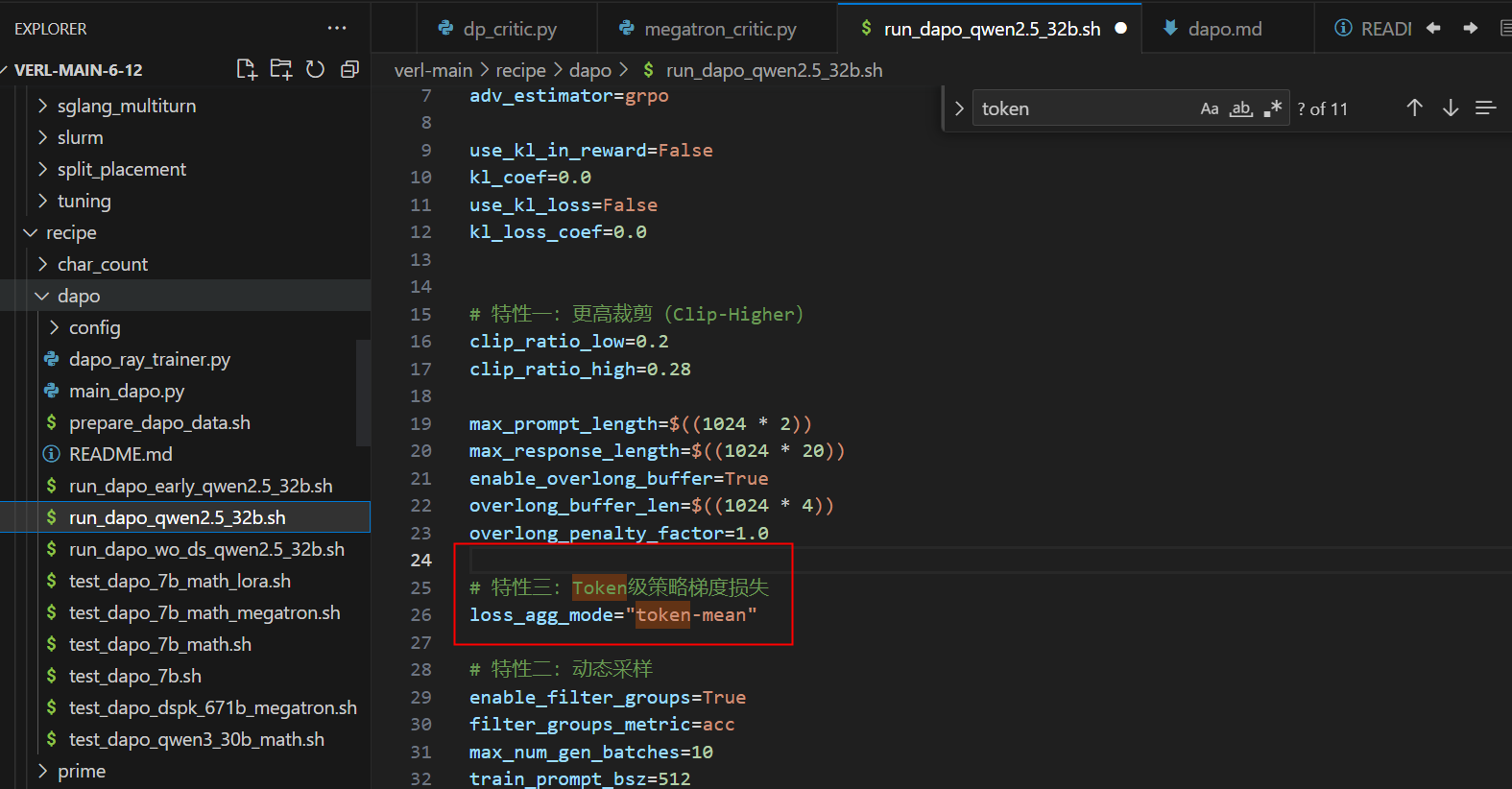
3.4 超长奖励塑造实现
3.5 总结
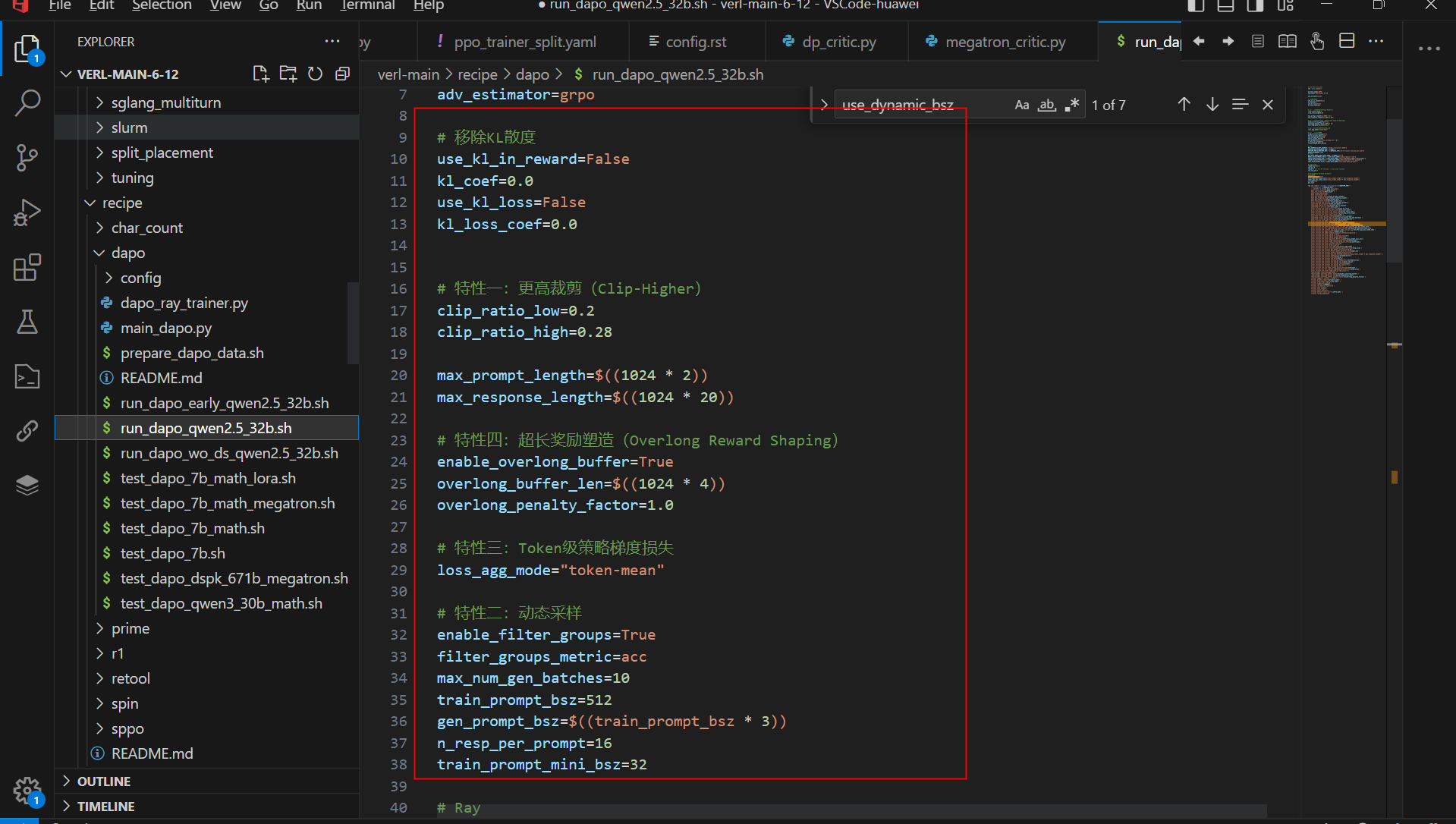
3.6 其他关键参数
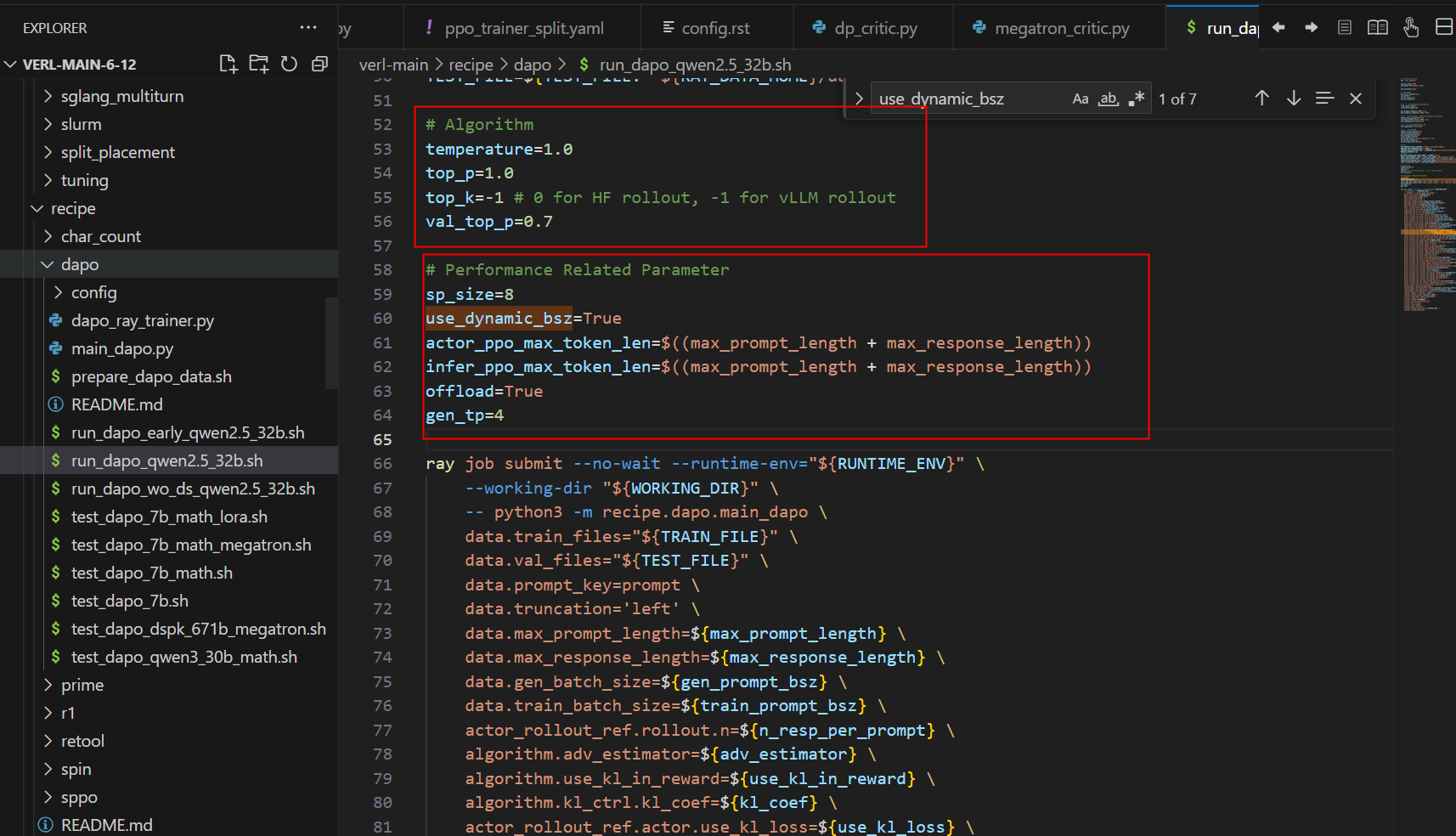
第1部分是sampling,推理的时候增加多样性。
第2部分是性能相关参数,其中关键的动态bs和offload,
4. 示例代码
# DAPO
## Clip-Higher
## - clip_ratio_low and clip_ratio_high specify the εlow and εhigh in the DAPO objective.
clip_ratio_low=0.2
clip_ratio_high=0.28
## Dynamic Sampling (with Group Filtering)
## - 训练器将重复使用 gen_batch_size 进行采样,直到有足够的合格组用于 train_batch_size,或者达到 max_num_gen_batches 指定的上限。
train_batch_size=512
gen_batch_size=train_prompt_bsz * 3
enable_filter_groups=True # 设置为True将过滤掉所有输出指标值都相同的组,例如,对于acc,将过滤掉所有输出准确率都为1或0的组。
filter_groups_metric="acc" # score / seq_reward / seq_final_reward / ...
max_num_gen_batches=10 # Non-positive values mean no upper limit
## Token-level Policy Gradient
## - 将 use_token_level_loss 设置为True意味着将针对批次中所有序列中的所有标记计算策略梯度损失。
use_token_level_loss=True
## Overlong Reward Shaping
## - max_response_length - overlong_buffer_len 是预期长度,超过预期长度的部分会惩罚,惩罚因子由 overlong_penalty_factor 控制
enable_overlong_buffer=True
overlong_buffer_len=1024 * 4
overlong_penalty_factor=1.0
max_prompt_length=1024 * 2
max_response_length=1024 * 20
# Others
## 关闭 KL(Kullback-Leibler Divergence)
kl_coef=0.0
kl_loss_coef=0.0
## Performance Related Parameter
gen_tp=4
sp_size=8
use_dynamic_bsz=True
actor_ppo_max_token_len=max_prompt_length + max_response_length
infer_ppo_max_token_len=max_prompt_length + max_response_length
offload=True
## Train
train_prompt_mini_bsz=32
## Validation
val_top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
n_resp_per_prompt=16

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)