yolov8 训练图像识别模型划分数据集脚本(训练集,测试集,验证集)
【代码】yolov8 训练图像识别模型划分数据集脚本(训练集,测试集,验证集)
·
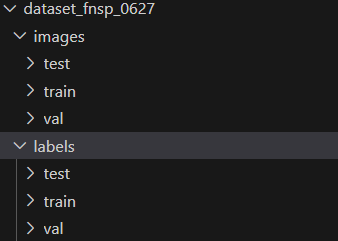
法1,划分为images/train-test-val,labels/train-test-val
目录结构
import os
import shutil
import random
random.seed(0)
def split_data(img_dir, label_dir, output_dir, ratios=(0.7, 0.1, 0.2)):
"""
划分数据集并保持图像-标签对应关系
参数:
img_dir: 原始图像目录
label_dir: 原始标签目录
output_dir: 输出根目录
ratios: 训练/验证/测试集划分比例 (train, val, test)
"""
# 创建输出目录结构
img_output = {
'train': os.path.join(output_dir, 'images', 'train'),
'val': os.path.join(output_dir, 'images', 'val'),
'test': os.path.join(output_dir, 'images', 'test')
}
label_output = {
'train': os.path.join(output_dir, 'labels', 'train'),
'val': os.path.join(output_dir, 'labels', 'val'),
'test': os.path.join(output_dir, 'labels', 'test')
}
# 确保输出目录存在
for d in [*img_output.values(), *label_output.values()]:
os.makedirs(d, exist_ok=True)
# 获取图像和标签的配对关系
img_files = sorted(os.listdir(img_dir))
label_files = sorted(os.listdir(label_dir))
# 验证基础文件名是否匹配(不含扩展名)
paired_data = []
for img in img_files:
base_name = os.path.splitext(img)[0]
matching_labels = [l for l in label_files if os.path.splitext(l)[0] == base_name]
if not matching_labels:
print(f"警告: 图像 {img} 没有对应的标签文件")
continue
# 使用找到的第一个匹配标签
paired_data.append((img, matching_labels[0]))
# 随机打乱数据对
random.shuffle(paired_data)
total = len(paired_data)
print(f"找到 {total} 对有效图像-标签数据")
# 计算划分点
train_end = int(ratios[0] * total)
val_end = train_end + int(ratios[1] * total)
# 划分数据集
sets = {
'train': paired_data[:train_end],
'val': paired_data[train_end:val_end],
'test': paired_data[val_end:]
}
# 复制文件到对应目录
for set_name, pairs in sets.items():
print(f"正在处理 {set_name} 集 ({len(pairs)} 个样本)")
for img_file, label_file in pairs:
# 复制图像
shutil.copy2(
os.path.join(img_dir, img_file),
os.path.join(img_output[set_name], img_file)
)
# 复制标签
shutil.copy2(
os.path.join(label_dir, label_file),
os.path.join(label_output[set_name], label_file)
)
if __name__ == '__main__':
# 配置路径参数
IMAGE_DIR = "xx"
LABEL_DIR = "xx"
OUTPUT_DIR = "xx"
# 执行划分 (70% 训练集, 10% 验证集, 20% 测试集)
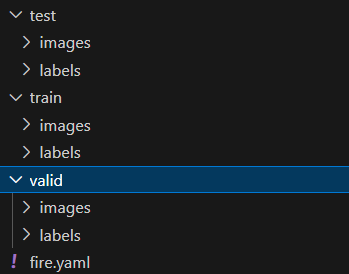
split_data(IMAGE_DIR, LABEL_DIR, OUTPUT_DIR)法2. val/images、labels等等
import os
import random
import shutil
def copy_files(src_dir, dst_dir, filenames, extension):
os.makedirs(dst_dir, exist_ok=True)
missing_files = 0
for filename in filenames:
src_path = os.path.join(src_dir, filename + extension)
dst_path = os.path.join(dst_dir, filename + extension)
# Check if the file exists before copying
if os.path.exists(src_path):
shutil.copy(src_path, dst_path)
else:
print(f"Warning: File not found for {filename}")
missing_files += 1
return missing_files
def split_and_copy_dataset(image_dir, label_dir, output_dir, train_ratio=0.7, valid_ratio=0.1, test_ratio=0.2):
# 获取所有图像文件的文件名(不包括文件扩展名)
image_filenames = [os.path.splitext(f)[0] for f in os.listdir(image_dir)]
# 随机打乱文件名列表
random.shuffle(image_filenames)
# 计算训练集、验证集和测试集的数量
total_count = len(image_filenames)
train_count = int(total_count * train_ratio)
valid_count = int(total_count * valid_ratio)
test_count = total_count - train_count - valid_count
# 定义输出文件夹路径
train_image_dir = os.path.join(output_dir, 'train', 'images')
train_label_dir = os.path.join(output_dir, 'train', 'labels')
valid_image_dir = os.path.join(output_dir, 'valid', 'images')
valid_label_dir = os.path.join(output_dir, 'valid', 'labels')
test_image_dir = os.path.join(output_dir, 'test', 'images')
test_label_dir = os.path.join(output_dir, 'test', 'labels')
# 复制图像和标签文件到对应的文件夹
train_missing_files = copy_files(image_dir, train_image_dir, image_filenames[:train_count], '.jpg')
train_missing_files += copy_files(label_dir, train_label_dir, image_filenames[:train_count], '.txt')
valid_missing_files = copy_files(image_dir, valid_image_dir, image_filenames[train_count:train_count + valid_count], '.jpg')
valid_missing_files += copy_files(label_dir, valid_label_dir, image_filenames[train_count:train_count + valid_count], '.txt')
test_missing_files = copy_files(image_dir, test_image_dir, image_filenames[train_count + valid_count:], '.jpg')
test_missing_files += copy_files(label_dir, test_label_dir, image_filenames[train_count + valid_count:], '.txt')
# Print the count of each dataset
print(f"Train dataset count: {train_count}, Missing files: {train_missing_files}")
print(f"Validation dataset count: {valid_count}, Missing files: {valid_missing_files}")
print(f"Test dataset count: {test_count}, Missing files: {test_missing_files}")
# 使用例子
image_dir = 'xx'
label_dir = 'xx'
output_dir = 'xx'
split_and_copy_dataset(image_dir, label_dir, output_dir)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)