PaddleOCR----制作数据集,模型训练,验证,QT部署
本文介绍了基于Windows系统部署PaddleOCR模型的完整流程。首先通过conda创建Python 3.10环境并安装PaddlePaddle框架和PaddleOCR库。然后使用PPOCRLabel工具进行数据集标注,生成训练集、验证集和测试集。接着配置训练参数,分别训练文本检测和识别模型,并进行模型验证评估。最后导出训练好的模型用于推理任务,包括单模型验证和检测识别联合验证。文章提供了详细
typora-copy-images-to: upload
文章目录
- 1.安装
- 2.制作数据集
- 3.训练模型
- 4.验证模型
- 5 部署c++
- 6.模型转onnx,部署更简单(新版本目前有bug,不用看了)
- 7 paddle3.1转换onnx模型,QT部署
- 遇到问题
-
- 1.AssertionError: The length of ratio_list should be the same as the file_list.
- 2.验证时候爆显存
- 3.OpenCV was not compiled with the freetype module (opencv_freetype) !
- 4.opencv部分库下载失败
- 5.opencv编译No SOURCES given to target: ade
- 6.检测到“_ITERATOR_DEBUG_LEVEL”的不匹配项: 值“2”不匹配值“0”(algorithm.obj 中)
- 7.onnx模型转换失败
- 8.onnxRuntime加载onnx模型生成环境报异常
部署环境, windows10,camke 4.2 freetype 2.14.0 ,harbuzz11.0 文档未写完,推荐onnx部署简单不用编译
qt部署和onnx模型转化直接看第7章
1.安装
1.1 paddle框架安装
conda 创建一个python =3.10的基础环境
根据自己的环境安装paddle框架链接
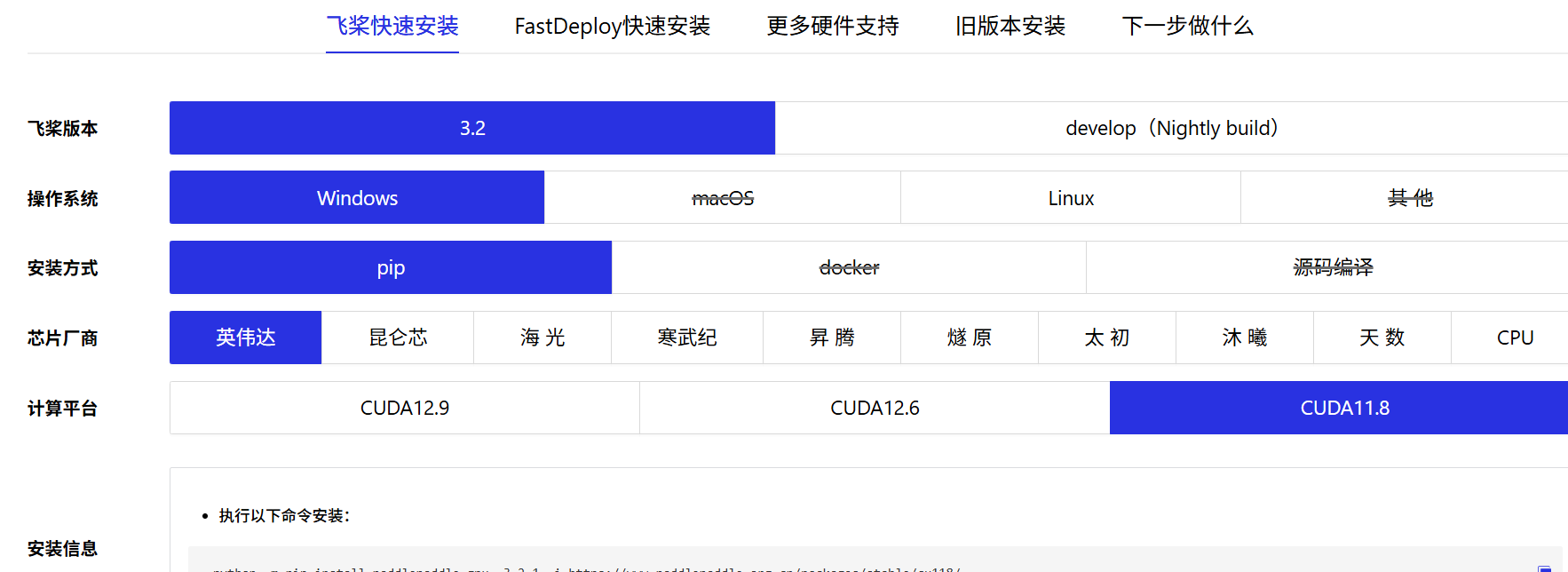
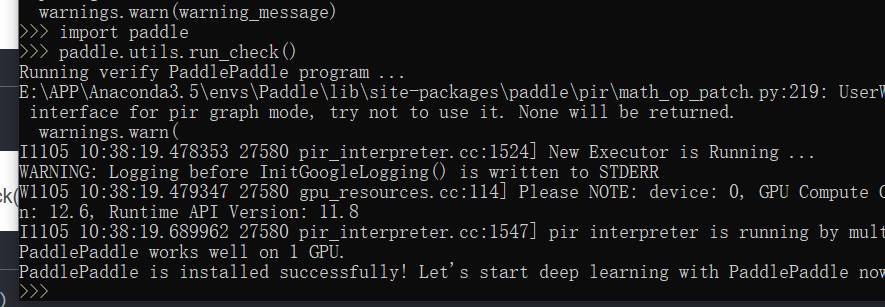
安装完成后进入环境,输入
python
import paddle
paddle.utils.run_check()
如果看到以下输出则没有问题,输入exit()退出
1.2 paddleOCR安装
pip install paddleocr出现以下说明安装成功,不用指定版本,指定了还出错
2.制作数据集
2.1工具下载
下载数据集制作工具下载地址
解压后,进入环境,cd到解压目录
pip3 install "paddlex[ocr]" -i https://pypi.tuna.tsinghua.edu.cn/simple/安装必要库
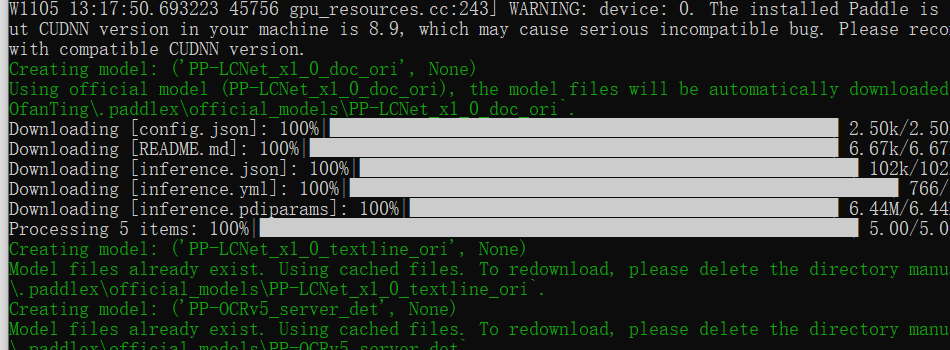
启动插件python ./PPOCRLabel.py,此时会一直下载模型,然后就会打开软件
2.2 数据集制作
打开图片文件夹,矩形框标注,可以更改识别结果,标注完成点击确定
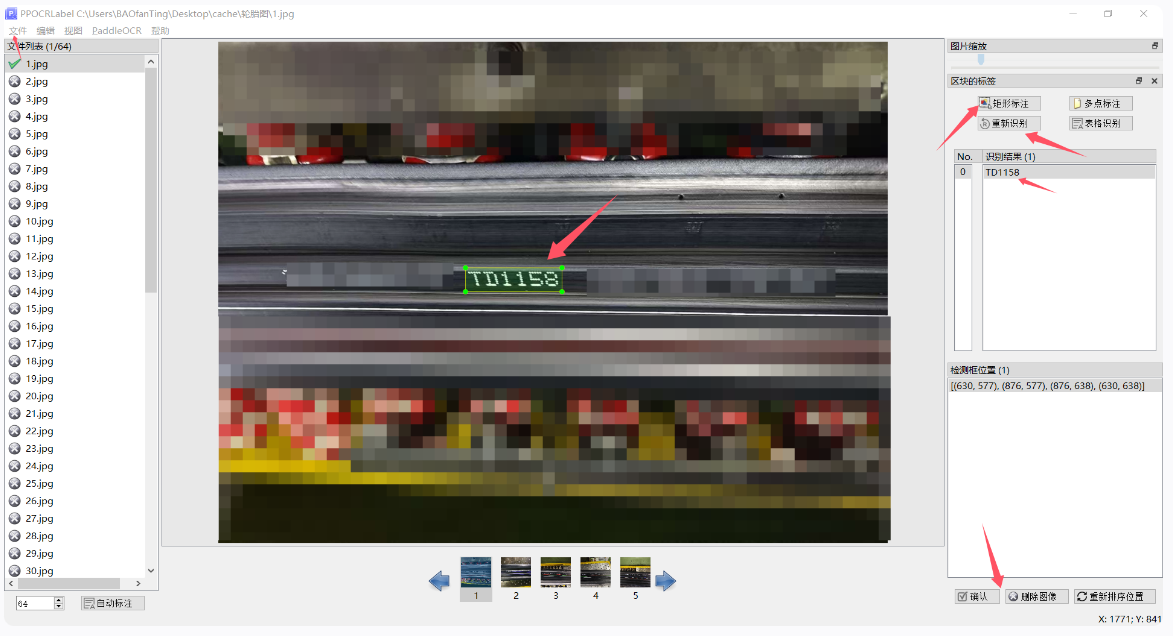
制作完成后,点击文件→导出标记结果,点击文件→导出识别结果,得到四个文件
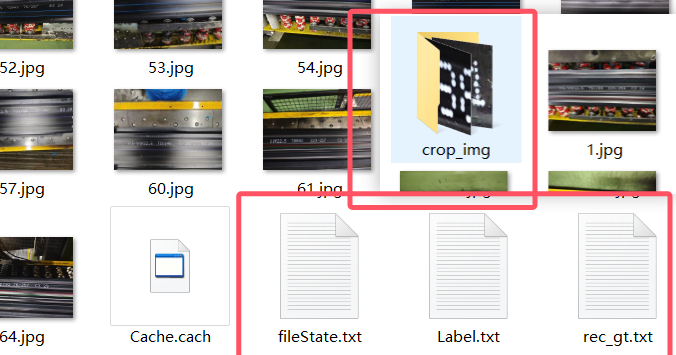
2.3 划分训练集和测试集
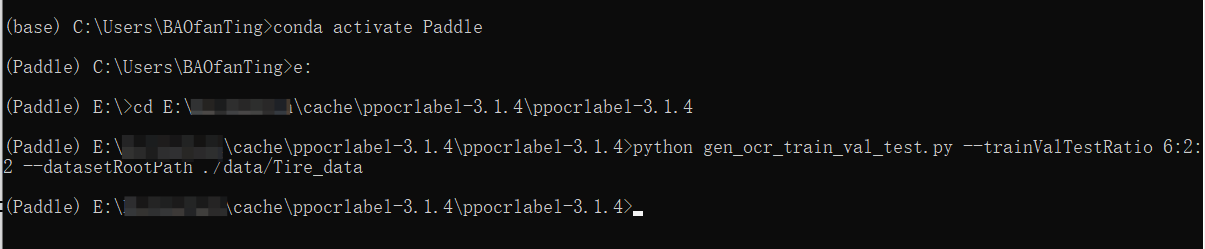
打开conda终端进入环境,cd进入PPOCRLabel文件夹,把图片文件夹复制到data文件夹下,执行划分命令
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ./data/Tire_data
–trainValTestRatio 6:2:2 #训练集、验证集和测试集的比例
–datasetRootPath #数据集路径
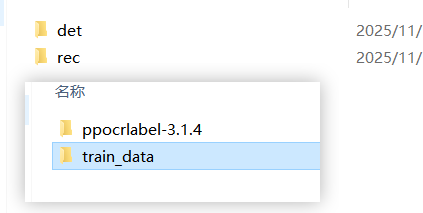
运行完成后再代码的上一级文件夹就会有train_data,里边就是划分好的数据集
3.训练模型
3.1 代码下载
克隆也行,下载也行,下载地址
解压后cd进入,安装必要库pip install -r requirements.txt

3.2 预训练模型下载
https://www.paddleocr.ai/main/version3.x/module_usage/text_detection.html#411下载文本检测和识别的预训练模型
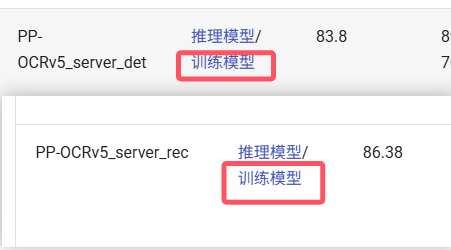
3.3 文本检测训练
windows 端训练 终端输入指令
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \ # 配置文件路径
-o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams \ #模型路径
Train.dataset.data_dir=../train_data/det \ # 数据集路径
Train.dataset.label_file_list='[../train_data/det/train.txt]' \ # train.txt路径
Eval.dataset.data_dir=../train_data/det \ # 数据集路径
Eval.dataset.label_file_list='[../train_data/det/val.txt]' # val.txt路径
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams Train.dataset.data_dir=../train_data/det Train.dataset.label_file_list=[../train_data/det/train.txt] Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
3.4 文本识别模型训练
同理
4.验证模型
4.1 验证文本检测模型
进入终端,环境,cd到目录
python3 tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \
-o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 保存的模型地址
Eval.dataset.data_dir=./ocr_det_dataset_examples \ # 数据集路径
Eval.dataset.label_file_list='[./ocr_det_dataset_examples/val.txt]' #valtext 路径
python tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
4.3 模型导出
在训练的output找到你最优的模型
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o \ # 配置文件
Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 模型参数路径
Global.save_inference_dir="./PP-OCRv5_server_det_infer/" #导出地址
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Global.save_inference_dir="./PP-OCRv5_server_det_infer/"
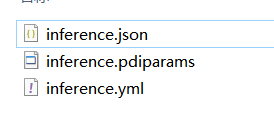
会得到这三个文件,然后就可以推理
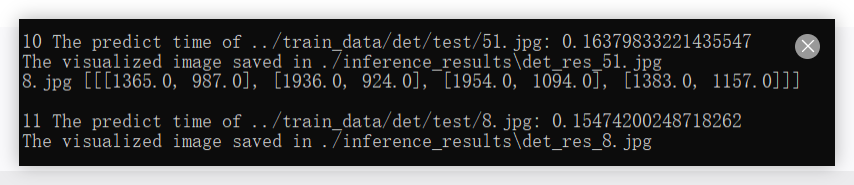
4.2 推理可视化
python tools\infer\predict_det.py \
--image_dir "../train_data/det/test/" \ # 预测图像路径
--det_model_dir "./output/PP-OCRv5_server_det/" \ # 模型路径
--use_gpu true
python tools\infer\predict_det.py --image_dir "../train_data/det/test/" --det_model_dir "./PP-OCRv5_server_det_infer/" --use_gpu true
在这个路径下就能看到识别后的可视化结果
4.3 文本识别模型
同理
4.4 检测和识别一同验证可视化
python tools/infer/predict_system.py
--det_model_dir=./ch_PP-OCRv2_det_infer/ \ # 检测模型目录
--rec_model_dir=./ch_PP-OCRv2_rec_infer/ \ # 识别模型目录
--image_dir=./datasets/img_dir/ \ # 测试图片目录
--draw_img_save_dir=./ch_PP-OCRv2_results/ \ # 可视化结果保存目录
--is_visualize=True
5 部署c++
5.1 编译Opencv
下载cmake安装下载链接
下载opencv原码和对应的第三方库下载 opencv-4.7.0 下载 opencv_contrib-4.7.0(版本可以自己选择我这边是官方教程的版本)
下载pkg-config解压 pkg-config 后添加其 bin 目录到系统 PATH 环境变量。
5.2.1 freetype2.14.0 编译
下载freetype2下载解压后打开cmake,我选择2.14版本,选择路径和编译导出路径,点击config,选择你的vs版本,x64,最后点击Generate,完成后,点击 Open Project 按钮,打开 VS ,编译。 VS里ALL_BUILD, INSTALL. 会在构建文件夹的 install 目录下生成所需的 include 和 lib 文件。
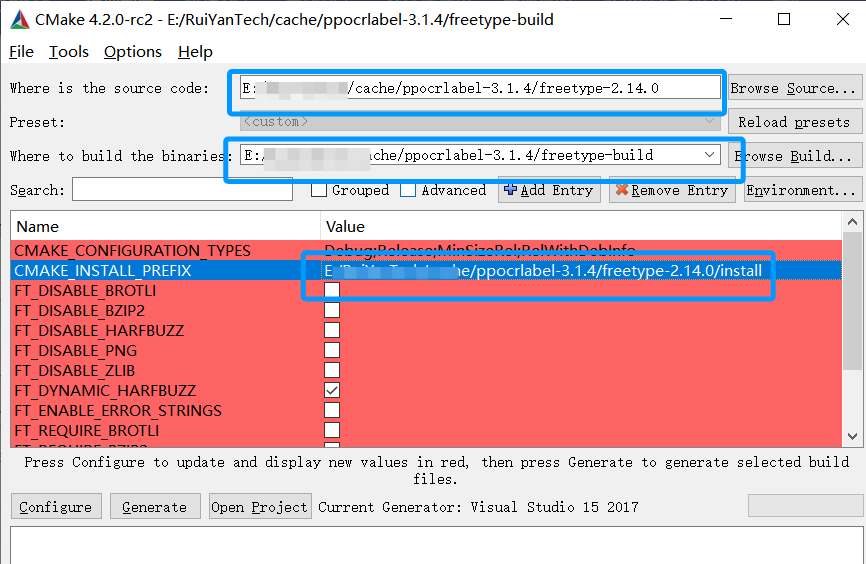
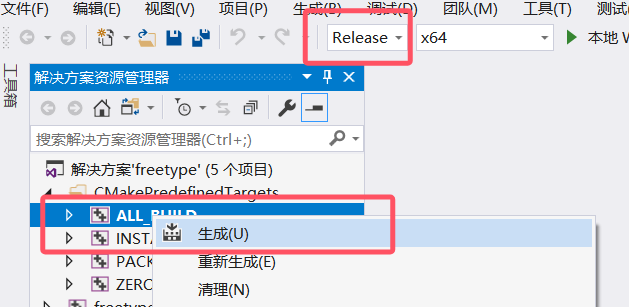
debug和release都运行一下install生成,然后将 freetype 的install路径添加至系统环境变量,重启电脑.
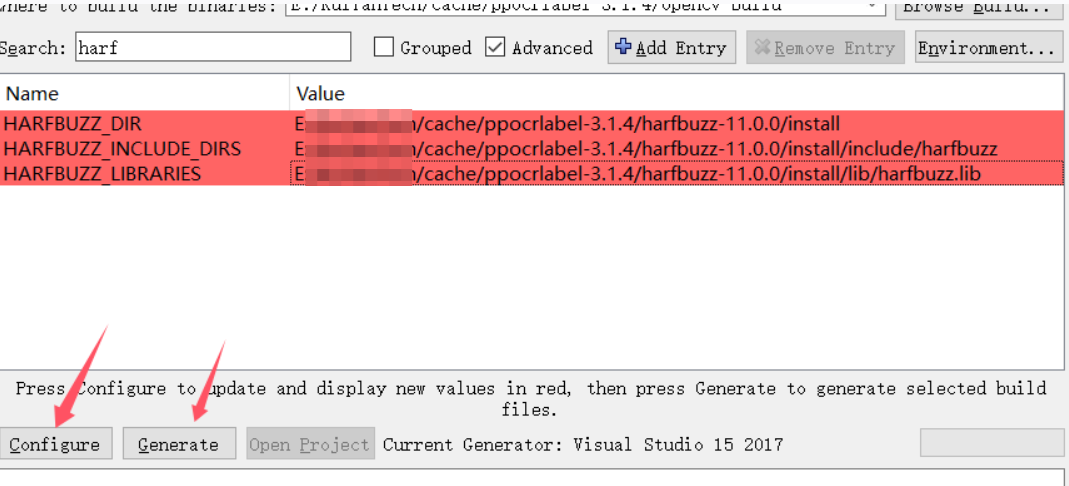
5.3.1 harfbuzz11.0编译
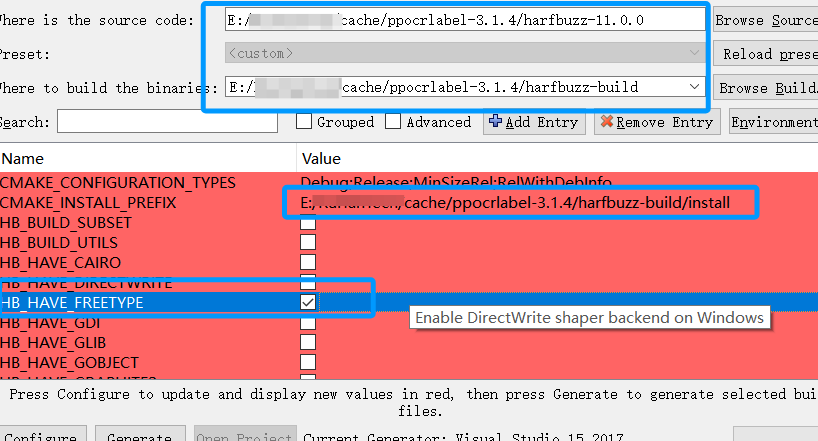
设置好上面两项后,再次点击 Configure 按钮,选择 Advanced Options ,填写 freetype 安装路径, 再次点击Configure 按钮,最后点击Generate,完成后,点击 Open Project 按钮,打开 VS ,install 生成。
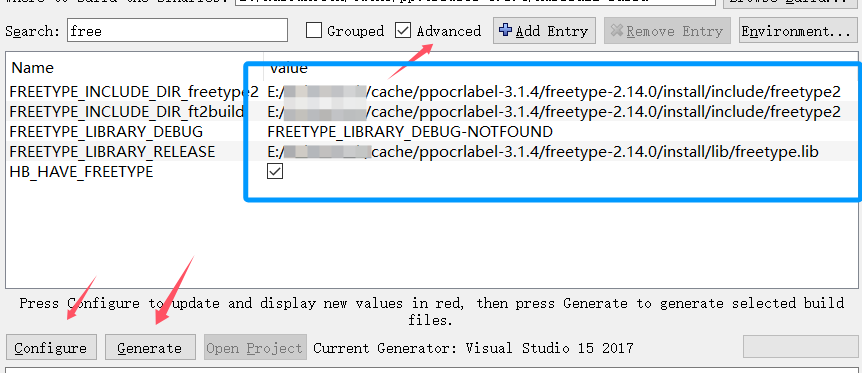
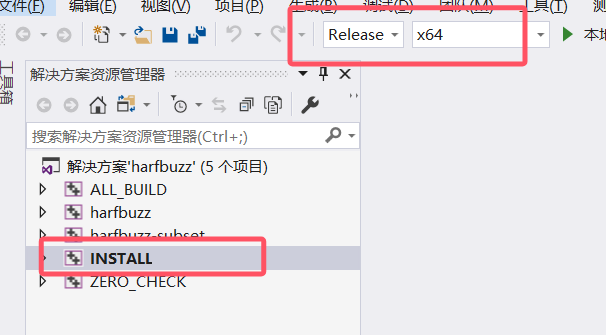
然后将 harbuzz 的install路径添加至系统环境变量,重启电脑.
5.1.3 opencv编译
修改 opencv_contrib-4.7.0 下的 modules/freetype/CMakeLists.txt
set(the_description "FreeType module. It enables to draw strings with outlines and mono-bitmaps/gray-bitmaps.")
find_package(Freetype REQUIRED)
# find_package(HarfBuzz) is not included in cmake
set(HARFBUZZ_DIR "$ENV{HARFBUZZ_DIR}" CACHE PATH "HarfBuzz directory")
find_path(HARFBUZZ_INCLUDE_DIRS
NAMES hb-ft.h PATH_SUFFIXES harfbuzz
HINTS ${HARFBUZZ_DIR}/include)
find_library(HARFBUZZ_LIBRARIES
NAMES harfbuzz
HINTS ${HARFBUZZ_DIR}/lib)
find_package_handle_standard_args(HARFBUZZ
DEFAULT_MSG HARFBUZZ_LIBRARIES HARFBUZZ_INCLUDE_DIRS)
if(NOT FREETYPE_FOUND)
message(STATUS "freetype2: NO")
else()
message(STATUS "freetype2: YES")
endif()
if(NOT HARFBUZZ_FOUND)
message(STATUS "harfbuzz: NO")
else()
message(STATUS "harfbuzz: YES")
endif()
if(FREETYPE_FOUND AND HARFBUZZ_FOUND)
ocv_define_module(freetype opencv_core opencv_imgproc PRIVATE_REQUIRED ${FREETYPE_LIBRARIES} ${HARFBUZZ_LIBRARIES} WRAP python)
ocv_include_directories(${FREETYPE_INCLUDE_DIRS} ${HARFBUZZ_INCLUDE_DIRS})
else()
ocv_module_disable(freetype)
endif()
- 设置
OPENCV_EXTRA_MODULES_PATH项,填入 opencv-contrib-4.7.0 的目录下的 modules 目录。 - 勾选
WITH_FREETYPE项,必须先编译 freetype 和 harfbuzz。再次点击config
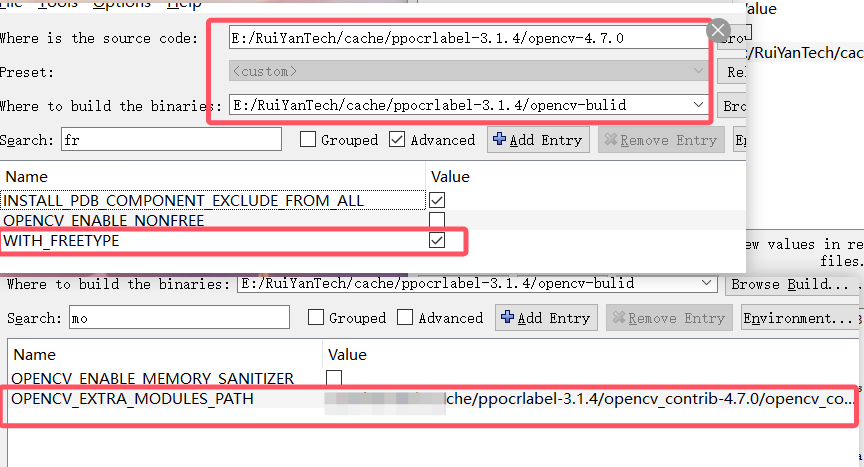
确定freetype的路径正确
填入harfbuzz路径
打开qt,world,opengl,nonfree
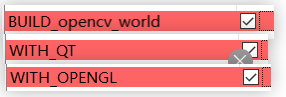
取消勾选test,wechat_qrcode,java,js,python,cvv的所有勾选
完成后,再次在 Cmake 界面,点击 configure, 确定没报错后,点击 Generate,最后点击 Open Project,打开 Visual studio,将 Debug 切换为 Release, 找到 INSTALL 右键 Build。没有报错即为编译成功
opencv部分库下载不下,看问题4,5
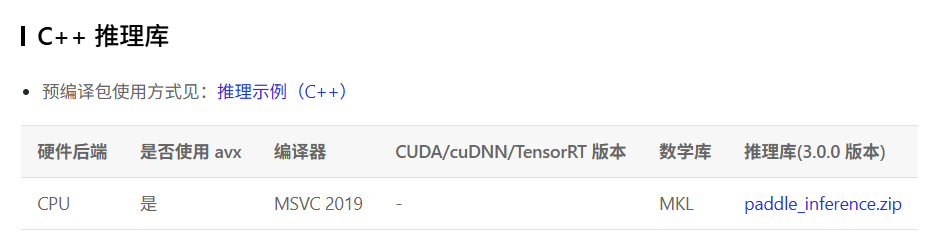
5.2 编译Paddle Inference
参考官方教材,直接安装编译包就行,省去编译过程官方教程
5.3 编译程序
source code填入PaddleOcr的deploy的cpp_infer路径
build填入任意地址即可,存放编译的文件,完成后点击configure
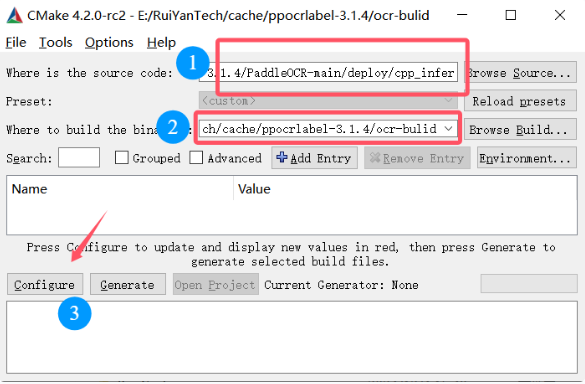
VS的版本根据你安装的来,平台选择x64

第一次点击 Configure 报错是正常的,在后续弹出的编译选项中,添加 OpenCV 的安装路径和 Paddle Inference 预测库路径。
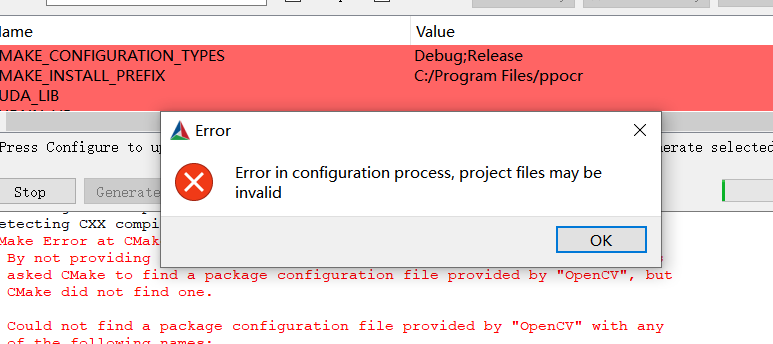
- OPENCV_DIR:填写 OpenCV 安装路径。
- OpenCV_DIR:同 OPENCV_DIR。
- PADDLE_LIB:Paddle Inference 预测库路径。

两个库编译完,opencv编译完,后边应该没啥问题,直接参考官方后续的步骤官方步骤
6.模型转onnx,部署更简单(新版本目前有bug,不用看了)
进入conda环境,执行如下命令,通过 PaddleX CLI 安装 PaddleX 的 Paddle2ONNX 插件:
# Windows 用户需使用以下命令安装 paddlepaddle dev版本
pip install --pre paddlepaddle -i https://www.paddlepaddle.org.cn/packages/nightly/cpu/
paddlex --install paddle2onnx
ERROR: Could not find a version that satisfies the requirement onnx<=1.17.0,>=1.16 (from paddle2onnx) (from versions: none)
ERROR: No matching distribution found for onnx<=1.17.0,>=1.16
Installation failed
遇到报错onnx版本不对,直接卸载安装
pip uninstall paddle2onnx onnx onnxruntime -y
pip install paddle2onnx onnx==1.17.0 onnxruntime==1.17.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
执行如下命令完成模型转换:需要使用导出后的推理模型,训练的不可以
paddlex \
--paddle2onnx \ # 使用paddle2onnx功能
--paddle_model_dir /your/paddle_model/dir \ # 指定 Paddle 模型所在的目录
--onnx_model_dir /your/onnx_model/output/dir \ # 指定转换后 ONNX 模型的输出目录
--opset_version 7 # 指定要使用的 ONNX opset 版本
paddlex --paddle2onnx --paddle_model_dir ./PP-OCRv5_server_det_infer --onnx_model_dir ./output/PP-OCRv5_server_det --opset_version 11
7 paddle3.1转换onnx模型,QT部署

7.1 文本检测模型转onnx
卸载pip uninstall paddlepaddle-gpu
安装python -m pip install paddlepaddle-gpu==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
pip install paddleocr==3.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果安装ocr过程中报错,某些库冲突找不到,就单独pip先把那些库安装了
pip install paddle2onnx onnx==1.17.0 onnxruntime==1.18.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
下载3.1版本的PaddleOCR代码,替换原来的PaddleOCR-main下载PaddleOCR3.1
完成后依旧是用之前的代码训练一个小的模型先试试能不能转换
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_mobile_det.yml -o Global.pretrained_model=./model/PP-OCRv5_mobile_det_pretrained.pdparams Train.dataset.data_dir=../train_data/det Train.dataset.label_file_list=[../train_data/det/train.txt] Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
导出可视化验证模型,没有问题
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_mobile_det.yml -o Global.pretrained_model=output/PP-OCRv5_mobile_det/latest.pdparams Global.save_inference_dir="./PP-OCRv5_mobile_det_infer/
python tools\infer\predict_det.py --image_dir "../train_data/det/test/" --det_model_dir "./PP-OCRv5_mobile_det_infer/" --use_gpu true
导出onnx模型
paddlex --paddle2onnx --paddle_model_dir ./PP-OCRv5_mobile_det_infer --onnx_model_dir ./output/PP-OCRv5_mobile_det --opset_version 13
报错numpy不兼容,安装旧版本numpypip install "numpy<2" -i https://pypi.tuna.tsinghua.edu.cn/simple
成功导出模型,并且模型大小也是正确的,使用以下代码验证onnx模型的有效性,结果正确
import os
import cv2
import numpy as np
import onnxruntime
import pyclipper
# ================= 配置 =================
MODEL_PATH = "./trainModel/inference.onnx"
IMG_PATH = "./tools/1.jpg"
SAVE_PATH = "./result.jpg"
INPUT_SIZE = (640, 640)
BINARY_THRESH_MIN = 0.2 # 最小阈值
BINARY_THRESH_MAX = 0.6 # 最大阈值
MIN_AREA = 100 # 最小文字区域面积
UNCLIP_RATIO = 1.5 # 膨胀比例
# =======================================
# ---------- unclip 膨胀 ----------
def unclip(box, unclip_ratio=1.5):
area = cv2.contourArea(box)
if area <= 0:
return box
perimeter = cv2.arcLength(box, True)
distance = area * unclip_ratio / max(perimeter, 1e-6)
offset = pyclipper.PyclipperOffset()
pts = box.astype(np.int32).tolist()
offset.AddPath(pts, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
if len(expanded) == 0:
return box
expanded = np.array(expanded[0]).reshape(-1, 2)
return expanded
# ---------- ONNX 推理 ----------
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
session = onnxruntime.InferenceSession(MODEL_PATH, providers=providers)
input_name = session.get_inputs()[0].name
# ---------- 读取图片 ----------
img = cv2.imread(IMG_PATH)
if img is None:
raise FileNotFoundError(f"图片不存在: {IMG_PATH}")
orig_img = img.copy()
orig_h, orig_w = img.shape[:2]
# ---------- 预处理 ----------
img_resized = cv2.resize(img, INPUT_SIZE)
img_norm = img_resized.astype(np.float32) / 255.0
img_norm = img_norm.transpose(2,0,1) # HWC -> CHW
img_input = np.expand_dims(img_norm, axis=0).astype(np.float32)
# ---------- 推理 ----------
pred_map = session.run(None, {input_name: img_input})[0]
pred_map = 1 / (1 + np.exp(-pred_map)) # sigmoid
pred_map_resized = cv2.resize(pred_map[0,0], (orig_w, orig_h))
# ---------- 自适应二值化 ----------
mean_val = pred_map_resized.mean()
binary_thresh = np.clip(mean_val*1.5, BINARY_THRESH_MIN, BINARY_THRESH_MAX)
binary_map = (pred_map_resized > binary_thresh).astype(np.uint8)
# ---------- 找轮廓 + unclip ----------
contours, _ = cv2.findContours(binary_map, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
boxes = []
for cnt in contours:
if cv2.contourArea(cnt) < MIN_AREA:
continue
epsilon = 0.01 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
expanded = unclip(approx[:,0,:], UNCLIP_RATIO)
if expanded.shape[0] < 4:
continue
expanded[:,0] = np.clip(expanded[:,0], 0, orig_w-1)
expanded[:,1] = np.clip(expanded[:,1], 0, orig_h-1)
boxes.append(expanded)
# ---------- 绘制矩形 ----------
for box in boxes:
x, y, w, h = cv2.boundingRect(box) # 最小外接矩形
cv2.rectangle(orig_img, (x,y), (x+w, y+h), (0,255,0), 2)
# ---------- 保存 ----------
cv2.imwrite(SAVE_PATH, orig_img)
print(f"检测到文本框数量: {len(boxes)}")
print(f"结果已保存到: {os.path.abspath(SAVE_PATH)}")
cv2.imshow("Detected Text Boxes", orig_img)
cv2.waitKey(0)
cv2.destroyAllWindows()

7.2 QT c++版本部署文本检测模型
环境配置参考qt运行onnxRuntime模型,加载模型生成环境异常
ONNX Runtime Exception: Load model from ./inference.onnx failed:D:\a_work\1\s\onnxruntime\core\graph\model.cc:111 onnxruntime::Model::Model Unknown model file format version.
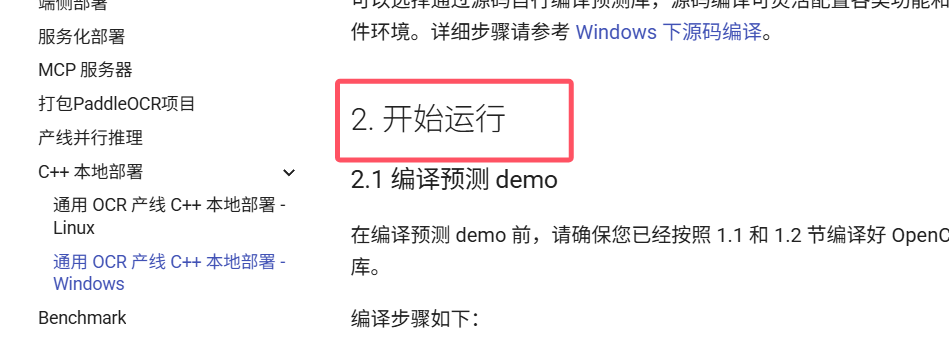
我的c++的onnxRuntime是1.8.1版本的,导出模型的版本是1.18.0,估计是太老了,升级一下,直接统一换到1.18.0,升级后程序报错,找到错误删除constexpr
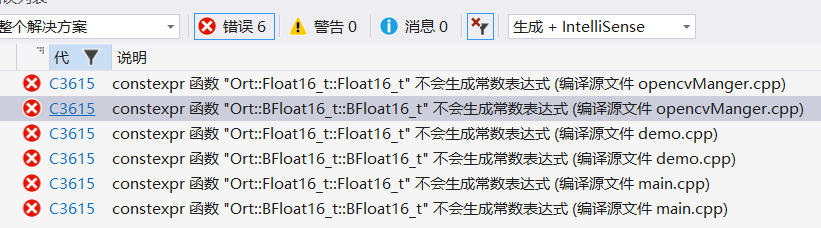

使用以下代码完成文本检测和显示,可以看到结果还不错,检测时间cpu170ms, gpu25ms
#pragma once
#include <opencv2/opencv.hpp>
// ONNX Runtime C++ API
#define ORT_DISABLE_FP16
#include <onnxruntime_cxx_api.h> // C++ 封装接口
#include <chrono> // 用于高精度计时
#include <iostream>
#include <QObject>
// 辅助函数:简单的 Sigmoid
static float sigmoid(float x) {
return 1.0f / (1.0f + std::exp(-x));
}
void opencvManger::getFontDect(const std::string& IMG_PATH)
{
const std::string SAVE_PATH = "./result.jpg";
const std::wstring MODEL_PATH = L"./inference.onnx"; // 确保路径正确
// 与 Python 配置保持一致
const int INPUT_W = 640;
const int INPUT_H = 640;
const float MIN_AREA = 300.0f;
const float BINARY_THRESH_MIN = 0.2f;
const float BINARY_THRESH_MAX = 0.6f;
// C++模拟 Unclip 的膨胀系数
// Python 是多边形偏移,C++ 这里用形态学膨胀模拟,数值可能需要微调
// 如果 Python ratio 是 1.5,这里 kernel size 设为 3~5 左右通常效果接近
const int UNCLIP_DILATE_ITERATIONS = 15;
try {
// ==================== 1. 初始化 ORT ====================
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "DBNet");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(4);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC);
try {
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
}
catch (...) {
std::cout << "⚠️ CUDA not available, fallback to CPU" << std::endl;
}
Ort::Session session(env, MODEL_PATH.c_str(), session_options);
Ort::AllocatorWithDefaultOptions allocator;
// 获取输入输出节点名
auto input_name_ptr = session.GetInputNameAllocated(0, allocator);
auto output_name_ptr = session.GetOutputNameAllocated(0, allocator);
const char* input_names[] = { input_name_ptr.get() };
const char* output_names[] = { output_name_ptr.get() };
// ==================== 2. 图片读取与预处理 (对齐 Python) ====================
cv::Mat image = cv::imread(IMG_PATH); // BGR 格式
if (image.empty()) {
std::cerr << "Error: Image not found." << std::endl;
return;
}
int orig_h = image.rows;
int orig_w = image.cols;
// Resize
cv::Mat resized_img;
cv::resize(image, resized_img, cv::Size(INPUT_W, INPUT_H));
// 归一化 (0-1) & HWC -> CHW
// 注意:Python代码并没有减均值除方差,只是 / 255.0,且保持 BGR
std::vector<float> input_tensor_values;
input_tensor_values.reserve(INPUT_W * INPUT_H * 3);
// 遍历顺序:Channel -> Height -> Width (CHW)
// OpenCV 默认是 BGR,分别提取 B, G, R 通道
for (int c = 0; c < 3; c++) {
for (int h = 0; h < INPUT_H; h++) {
for (int w = 0; w < INPUT_W; w++) {
// at<cv::Vec3b> 返回的是 BGR
float pixel = resized_img.at<cv::Vec3b>(h, w)[c];
input_tensor_values.push_back(pixel / 255.0f);
}
}
}
std::array<int64_t, 4> input_shape = { 1, 3, INPUT_H, INPUT_W };
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, input_tensor_values.data(), input_tensor_values.size(), input_shape.data(), input_shape.size()
);
//计时
//auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
auto start_e2e = std::chrono::high_resolution_clock::now();
// ==================== 3. 推理 ====================
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
// ==================== 4. 后处理 ====================
float* floatarr = output_tensors[0].GetTensorMutableData<float>();
// DBNet 输出通常是 1x1xHxW
cv::Mat pred_map(INPUT_H, INPUT_W, CV_32F, floatarr);
// 4.1 Sigmoid 处理
for (int i = 0; i < pred_map.rows * pred_map.cols; ++i) {
pred_map.at<float>(i) = sigmoid(pred_map.at<float>(i));
}
// 4.2 Resize 回原图尺寸
cv::Mat pred_resized;
cv::resize(pred_map, pred_resized, cv::Size(orig_w, orig_h));
// 4.3 自适应阈值 (对齐 Python 逻辑)
// Python: mean_val = pred_map_resized.mean()
// Python: binary_thresh = clip(mean_val * 1.5, 0.2, 0.6)
cv::Scalar mean_scalar = cv::mean(pred_resized);
float mean_val = static_cast<float>(mean_scalar[0]);
float binary_thresh = std::max(BINARY_THRESH_MIN, std::min(BINARY_THRESH_MAX, mean_val * 1.5f));
// 二值化
cv::Mat binary_map;
// 注意:OpenCV threshold 需要 0-255 的输入或者 CV_32F 对比
// 这里 pred_resized 是 CV_32F (0.0-1.0),binary_thresh 也是 float
cv::threshold(pred_resized, binary_map, binary_thresh, 255, cv::THRESH_BINARY);
binary_map.convertTo(binary_map, CV_8U);
// 4.4 Unclip 模拟 (形态学膨胀)
// Python 使用多边形偏移,C++ 简单版使用 mask 膨胀
cv::Mat dilated_map;
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::dilate(binary_map, dilated_map, kernel, cv::Point(-1, -1), UNCLIP_DILATE_ITERATIONS);
// 4.5 查找轮廓
std::vector<std::vector<cv::Point>> contours;
cv::findContours(dilated_map, contours, cv::RETR_LIST, cv::CHAIN_APPROX_SIMPLE);
// ==================== 4.6 查找最大轮廓 ====================
double max_area = 0.0;
std::vector<cv::Point> max_contour; // 用于存储最大轮廓
for (const auto& cnt : contours)
{
double area = cv::contourArea(cnt);
//过滤小于最小面积的轮廓
if (area < MIN_AREA) continue;
//如果当前轮廓比已知的最大面积还大
if (area > max_area)
{
max_area = area;
max_contour = cnt; //最大轮廓
}
}
// ==================== 4.7 绘制最大轮廓的最小外接矩形 ====================
int box_count = 0;
if (!max_contour.empty()) //有一个有效的轮廓
{
//使用minAreaRect,会找到包裹面积的旋转矩形
cv::RotatedRect rotated_rect = cv::minAreaRect(max_contour);
//获取旋转矩形的4个顶点
cv::Point2f vertices[4];
rotated_rect.points(vertices);
//准备绘制多边形
std:vector<cv::Point> box_points;
for (int i = 0; i < 4; i++)
{
box_points.push_back(vertices[i]);//自动从Point2f转为Point
}
//绘制多边形(使用polylines而不是rectangle)
cv::polylines(image, box_points, true, cv::Scalar(0, 255, 0), 2);
}
auto end_e2e = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> e2e_ms = end_e2e - start_e2e;
// ==================== 5. 保存结果 ====================
cv::imwrite(SAVE_PATH, image);
std::cout << "time" << e2e_ms.count() << "ms" << endl;
std::cout << "Result saved to " << SAVE_PATH << std::endl;
}
catch (const Ort::Exception& e) {
std::cerr << "ONNX Runtime Error: " << e.what() << std::endl;
}
catch (const std::exception& e) {
std::cerr << "Error: " << e.what() << std::endl;
}
}

7.3 文本识别模型转onnx
训练模型
python tools/train.py -c configs/rec/PP-OCRv5/PP-OCRv5_mobile_rec.yml -o Global.pretrained_model=./model/PP-OCRv5_mobile_rec_pretrained.pdparams Train.dataset.data_dir=../train_data/rec Train.dataset.label_file_list=[../train_data/rec/train.txt] Eval.dataset.data_dir=../train_data/rec Eval.dataset.label_file_list=[../train_data/rec/val.txt]
生成推理模型
python tools/export_model.py -c configs/rec/PP-OCRv5/PP-OCRv5_mobile_rec.yml -o Global.pretrained_model=output/PP-OCRv5_mobile_rec/latest.pdparams Global.save_inference_dir="./PP-OCRv5_mobile_rec_infer/"
可视化结果验证,终端查看结果
python tools\infer\predict_rec.py --image_dir "../train_data/rec/test/" --rec_model_dir "./PP-OCRv5_mobile_rec_infer/" --use_gpu true
导出onnx模型
paddlex --paddle2onnx --paddle_model_dir ./PP-OCRv5_mobile_rec_infer --onnx_model_dir ./output/PP-OCRv5_mobile_rec --opset_version 13
文本识别同时会在推理文件夹导出一个字典文件,我们到时候需要使用它
查看配置文件,输入尺寸统一为[3, 48, 320],使用python代码验证onnx模型效果,检测正确
import cv2
import numpy as np
import onnxruntime
import os
# ================= 配置 =================
MODEL_PATH = "./tools/rec_inference.onnx" # ONNX 模型路径,改成你的路径
DICT_PATH = "./tools/ppocr_keys.txt" # 字典路径(每行一个字符),改成你的路径
IMG_PATH = "./tools/2.jpg" # 待识别图片路径,改成你的路径
# PaddleOCR v5_mobile_rec 的默认输入尺寸
IMG_H = 48
IMG_W = 320
# =========================================
# ---------- 加载字典 ----------
def load_dict(dict_path):
"""
加载字符字典文件,返回包含 blank 在内的字符列表。
PaddleOCR 的 CTC 解码中通常把 index=0 作为 blank。
因此我们把字典组织为:["blank", char1, char2, ...]
"""
with open(dict_path, 'r', encoding="utf-8") as f:
keys = [line.strip() for line in f.readlines() if line.strip() != ""]
# 在最前面加一个占位 'blank',对应类别 0
dict_character = ["blank"] + keys
return dict_character
dict_character = load_dict(DICT_PATH)
# ---------- CTC 解码(Best path decoding) ----------
def ctc_decode(preds):
"""
对网络输出做简单的 best-path CTC 解码(去掉 blank,合并重复)
preds: numpy array, shape = [seq_len, num_classes] (即单条样本)
返回:解码后的字符串(unicode)
说明:
- preds[t] 是长度为 num_classes 的向量(通常未经过 softmax 或 已经是概率)
- 我们使用 argmax 取每个时间步最可能的类别索引
- index 0 被视为 blank,跳过不输出
- 合并连续重复的字符(重复字符只输出一次)
"""
# 每个时间步取得分最大的类别索引
preds_idx = preds.argmax(axis=1) # shape: [seq_len]
prev = -1
result = ""
for idx in preds_idx:
# 跳过 blank(0),并且合并重复
if idx != prev and idx != 0:
# 直接用 dict_character[idx]:因为我们在字典最前面加了 'blank' -> index 对齐
result += dict_character[idx-1]
prev = idx
return result
# ---------- 预处理(复现 PaddleOCR RecResizeImg 行为) ----------
def preprocess(img, imgH=IMG_H, imgW=IMG_W):
"""
输入:BGR 图像(H, W, 3)
步骤:
1. 计算等比例缩放到高度 imgH,宽度按比例计算,限制不超过 imgW
2. 将缩放结果放在左上角,右侧用 255 填充到宽度 imgW(Paddle 的 padding 策略)
3. 转为 float -> 归一化 (img/255 -> (img-0.5)/0.5)
4. HWC -> CHW, 增加 batch 维度,返回 float32 张量,shape = [1,3,imgH,imgW]
"""
# 原始尺寸
h, w = img.shape[:2]
ratio = w / float(h)
# 目标宽度 = min(int(imgH * ratio), imgW)
target_w = min(int(imgH * ratio), imgW)
# 等比例 resize 到 (target_w, imgH)
resized = cv2.resize(img, (target_w, imgH))
# 创建一个全白图(Paddle 用 255 填充)
padded = np.ones((imgH, imgW, 3), dtype=np.float32) * 255.0
# 将缩放后的图像放在左上角
padded[:, :target_w, :] = resized
# 转 float 并做归一化:/255 -> (x - 0.5) / 0.5
padded = padded.astype(np.float32) / 255.0
padded = (padded - 0.5) / 0.5
# HWC -> CHW
padded = padded.transpose(2, 0, 1)
# 增加 batch 维度
input_tensor = np.expand_dims(padded, axis=0).astype(np.float32)
# 调试信息(确认输入 shape)
# 期望: (1, 3, IMG_H, IMG_W)
print("Preprocess: input tensor shape =", input_tensor.shape)
return input_tensor
# ---------- 初始化 ONNX 运行时 ----------
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
session = onnxruntime.InferenceSession(MODEL_PATH, providers=providers)
# 注意:有的模型输入名不是 "x",可以打印 session.get_inputs() 确认
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
print("ONNX model input name:", input_name, "output name:", output_name)
# ---------- 主流程 ----------
if __name__ == "__main__":
# 读取图片(BGR)
img = cv2.imread(IMG_PATH)
if img is None:
raise FileNotFoundError(f"图片不存在: {IMG_PATH}")
# 预处理 -> 得到 shape 为 (1,3,IMG_H,IMG_W) 的张量
img_input = preprocess(img, IMG_H, IMG_W)
# 推理(ONNXRuntime)
# 注意:确保传入的数据类型为 np.float32,shape 与模型期望相同
out = session.run(None, {input_name: img_input})
# 通常输出是 shape [1, seq_len, num_classes](但也有模型输出 [1, num_classes, seq_len] 的变体)
pred = out[0]
print("Raw model output shape:", pred.shape)
# 如果输出是 [1, num_classes, seq_len],需要转置为 [1, seq_len, num_classes]
if pred.ndim == 3 and pred.shape[1] == len(dict_character):
# 很少见:输出为 [B, C, T] -> 转为 [B, T, C]
pred = pred.transpose(0, 2, 1)
print("Transposed model output to shape:", pred.shape)
# 去掉 batch 维度 -> [seq_len, num_classes]
pred_single = pred[0]
#(可选)如果模型输出是 logits 而不是 softmax,ctc_decode 使用 argmax 也可行;
# 如需更稳健可先做 softmax: probs = softmax(pred_single, axis=1)
# 但 argmax 不受 softmax 单调性影响,故此处不必强制 softmax。
# 解码
result = ctc_decode(pred_single)
print("识别结果:", result)

7.4 QT C++部署文本识别模型
需要把opencv的HWC转换为CHW格式,并且把输出的一维tensor的变成二维的[0.1,0.2,0.3,0.4] -> [0.1,0.2],[0.3,0.4],方便计算最大概率得到class
//单张文本识别
vector<string> load_dict(const std::string& path)
{
vector<string> dict;
dict.push_back("blank");
std::ifstream infile(path);
string line;
while (getline(infile, line))
{
if (!line.empty())
{
dict.push_back(line);
}
}
return dict;
}
void opencvManger::getFontRec(const string & imgPath)
{
const int IMG_H = 48;
const int IMG_W = 320;
const std::wstring strModelPath = L"./model/rec_inference.onnx";
std::string dict_path = "./model/ppocr_keys.txt";
// 1. 加载字典
vector<string> dict = load_dict(dict_path);
// 2.onnx初始化
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "Rec");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(4);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC);
try
{
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
}
catch (...) {
std::cout << "⚠️ CUDA not available, fallback to CPU" << std::endl;
}
Ort::Session session(env, strModelPath.c_str(), session_options);
Ort::AllocatorWithDefaultOptions allocator;
//获取节输入输出节点名称
auto strInputName = session.GetInputNameAllocated(0, allocator);
auto strOutputName = session.GetOutputNameAllocated(0, allocator);
const char* cInputNames[] = { strInputName.get() };
const char* cOutputNames[] = { strOutputName.get() };
// 3. 读取图片(BGR,图像预处理
cv::Mat img = cv::imread(imgPath);
if (img.empty()) {
cout << "图片读取失败!" << endl;
return;
}
int h = img.rows;
int w = img.cols;
float ratio = w * 1.0f / h;
int target_w = min(int(IMG_H * ratio), IMG_W);
//resize,高度固定为48,宽度按比例
cv::Mat resized;
cv::resize(img, resized, cv::Size(target_w, IMG_H));
//Paddling,初始化为255,宽度在扩充到320
cv::Mat padded(IMG_H, IMG_W, CV_32FC3, cv::Scalar(255, 255, 255));
resized.convertTo(resized, CV_32FC3);
resized.copyTo(padded(cv::Rect(0, 0, target_w, IMG_H)));
// Normalize
padded /= 255.0f;
padded = (padded - 0.5f) / 0.5f;
//转换为tensor HWC ->CHW ,opencv img[H][W][C]
std::vector<float> inputTensorValue;
inputTensorValue.reserve(IMG_H * IMG_W * 3);
int idx = 0;
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < IMG_H; i++)
{
for (int j = 0; j < IMG_W; j++)
{
inputTensorValue.push_back(padded.at<cv::Vec3f>(i, j)[c]);
}
}
}
// 4.模型推理 输入形状 [1,3,48,320]
std::array<int64_t, 4> inputShape = { 1,3,IMG_H,IMG_W };
size_t inputTensorSize = inputTensorValue.size();
//创建ONNX输入
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value inputOrt = Ort::Value::CreateTensor<float>(memoryInfo, inputTensorValue.data(),inputTensorSize, inputShape.data(), inputShape.size());
//推理
auto outputTensor = session.Run(
Ort::RunOptions{ nullptr },
cInputNames,
&inputOrt,
1,
cOutputNames,
1
);
//5.解析输出: shape = [1,T,C]
float* pOutput = outputTensor[0].GetTensorMutableData<float>();
auto outShape = outputTensor[0].GetTensorTypeAndShapeInfo().GetShape();
int T = outShape[1];
int C = outShape[2];
vector<vector<float>> preds(T, vector<float>(C));
//把一维的变成二维的[0.1,0.2,0.3,0.4] -> [0.1,0.2],[0.3,0.4]
for (int t = 0; t < T; t++)
{
for (int c = 0; c < C; c++)
{
preds[t][c] = pOutput[t*C + c];
}
}
//6.CTC 解码
string result;
int prev = -1;
for (int i = 0; i < preds.size(); i++)
{
int idx = max_element(preds[i].begin(), preds[i].end()) - preds[i].begin();
if (idx != prev && idx != 0)
{
result += dict[idx];
}
prev = idx;
}
cout << result << endl;
}
7.5 文本检测与文本识别连同部署
整体代码如下
#pragma once
#include <opencv2/opencv.hpp>
// ONNX Runtime C++ API
#define ORT_DISABLE_FP16
#include <onnxruntime_cxx_api.h> // C++ 封装接口
#include <chrono> // 用于高精度计时
#include <iostream>
#include <QObject>
#include <vector>
using namespace std;
using namespace cv;
class ocrManger : public QObject
{
Q_OBJECT
public:
static ocrManger* getInstance();
//禁止拷贝和赋值
ocrManger(const ocrManger&) = delete;
ocrManger& operator = (const ocrManger&) = delete;
std::string runOCR(const std::string& imgPath); // 整体流程:检测+识别
private:
static ocrManger* m_pInstance;
// ====== ONNX Runtime 基础对象(全局只能一个 Env)======
Ort::Env env;
Ort::SessionOptions sessionOptions;
//========检测模型==========
Ort::Session* m_detSession;
std::string m_strDetInputName;
std::string m_strDetOutputName;
//========识别模型==========
Ort::Session* m_recSession;
std::string m_strRecInputName;
std::string m_strRecOutputName;
std::vector<std::string> m_recDict;
private:
//构造函数私有化
explicit ocrManger(QObject *parent = nullptr);
//=======内部功能函数========
cv::Mat detecTextBox(const cv::Mat& img, cv::Rect& box);
std::string recoginizeText(const cv::Mat& roi);
std::vector<std::string> loadDict(const std::string& path);
};
#include "ocrManger.h"
#include <string>
#include <vector>
#include <fstream>
//类外实例化
ocrManger* ocrManger::m_pInstance = nullptr;
// 与 Python 配置保持一致
const int DET_INPUT_W = 640;
const int DET_INPUT_H = 640;
const int REC_INPUT_W = 320;
const int REC_INPUT_H = 48;
const float MIN_AREA = 100.0f;
const float BINARY_THRESH_MIN = 0.2f;
const float BINARY_THRESH_MAX = 0.6f;
// 定义常用的 ImageNet 均值和方差 (PaddleOCR 和大多数 DBNet 都用这个)
const float mean_vals[3] = { 0.485f, 0.456f, 0.406f };
const float std_vals[3] = { 0.229f, 0.224f, 0.225f };
// C++模拟 Unclip 的膨胀系数
// Python 是多边形偏移,C++ 这里用形态学膨胀模拟,数值可能需要微调
// 如果 Python ratio 是 1.5,这里 kernel size 设为 3~5 左右通常效果接近
const int UNCLIP_DILATE_ITERATIONS = 20;
const std::string SAVE_PATH = "./result.jpg";
// 辅助函数:Sigmoid
static float sigmoid(float x) {
return 1.0f / (1.0f + exp(-x));
}
/***********************************************
* @功能描述 : 构造函数,初始化onnx环境
***********************************************/
ocrManger::ocrManger(QObject* parent) : QObject(parent)
{
//初始化 ONNX Runtime 环境
this->env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "OCR");
sessionOptions.SetIntraOpNumThreads(4);
sessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC);
//尝试启用 CUDA 加速
try
{
OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0);
}
catch (...)
{
std::cout << "⚠️ CUDA not available, fallback to CPU" << std::endl;
}
Ort::AllocatorWithDefaultOptions allocator;
try
{
//====加载检测模型====
m_detSession = new Ort::Session(env, L"./model/det_inference.onnx", sessionOptions);
m_strDetInputName = m_detSession->GetInputNameAllocated(0, allocator).get();
m_strDetOutputName = m_detSession->GetOutputNameAllocated(0, allocator).get();
}
catch (const std::exception& e) {
std::cerr << "Failed to load DET model: " << e.what() << std::endl;
}
try
{
//====加载识别模型====
m_recSession = new Ort::Session(env, L"./model/rec_inference.onnx", sessionOptions);
m_strRecInputName = m_recSession->GetInputNameAllocated(0, allocator).get();
m_strRecOutputName = m_recSession->GetOutputNameAllocated(0, allocator).get();
}
catch (const std::exception& e) {
std::cerr << "Failed to load REC model: " << e.what() << std::endl;
}
//====加载字典====
m_recDict = loadDict("./model/ppocr_keys.txt");
if (m_recDict.empty()) std::cerr << "Warning: Dictionary is empty!" << std::endl;
std::cout << "OCR system initialized.\n";
}
/***********************************************
* @功能描述 : 运行ocr流程
***********************************************/
std::string ocrManger::runOCR(const std::string & imgPath)
{
cv::Mat img = cv::imread(imgPath);
if (img.empty())
{
return "";
}
// 1) 检测框 获得包含文字的矩形框 (box) 和 二值化掩码 (binmap)
cv::Rect box;
cv::Mat binmap = detecTextBox(img, box);
if (box.area() < 10)
{
cout << "No valid text detectd\n";
return "";
}
//裁剪 ROI 根据检测框从原图中抠出文字区域
cv::Mat roi = img(box).clone();
cv::imshow("Debug ROI", roi);
//2) 识别
string text = recoginizeText(roi);
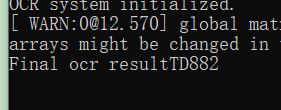
cout << "Final ocr result" << text << endl;
return text;
}
cv::Mat ocrManger::detecTextBox(const cv::Mat & img, cv::Rect & box)
{
//缩放和归一化
int originW = img.cols;
int originH = img.rows;
cv::Mat resizedImg;
cv::resize(img, resizedImg, cv::Size(DET_INPUT_W, DET_INPUT_H));
std::vector<float> inputTensorValues;
inputTensorValues.reserve(DET_INPUT_W*DET_INPUT_H * 3);
// 遍历顺序:Channel -> Height -> Width (CHW)
// OpenCV 默认是 BGR,分别提取 B, G, R 通道
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < DET_INPUT_H; i++)
{
for (int j = 0; j < DET_INPUT_W; j++)
{
float pixel = resizedImg.at<cv::Vec3b>(i, j)[c];
inputTensorValues.push_back((pixel / 255.0f - mean_vals[c]) / std_vals[c]);
}
}
}
//创建tensor
std::array<int64_t, 4> inputShape = { 1,3,DET_INPUT_H,DET_INPUT_W };//数据格式
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value inputTensor = Ort::Value::CreateTensor<float>(
memoryInfo,
inputTensorValues.data(),
inputTensorValues.size(),
inputShape.data(),
inputShape.size()
);
//开始推理,,DBNet 输出通常是 1x1xHxW
const char* inputNames[] = { m_strDetInputName.c_str() };
const char* outputNames[] = { m_strDetOutputName.c_str() };
auto outputTensor = m_detSession->Run(
Ort::RunOptions{ nullptr },
inputNames,
&inputTensor,
1,
outputNames,
1
);
//后处理
float* pOutput = outputTensor[0].GetTensorMutableData<float>();
cv::Mat predMap(DET_INPUT_H, DET_INPUT_W, CV_32F, pOutput);
//Sigmoid
for (int i = 0; i < predMap.rows * predMap.cols; i++)
{
predMap.at<float>(i) = sigmoid(predMap.at<float>(i));
}
//缩放回原图
cv::Mat predResized;
cv::resize(predMap, predResized, cv::Size(originW, originH));
//自适应阈值(对齐 Python 逻辑)
// Python: mean_val = pred_map_resized.mean()
// Python: binary_thresh = clip(mean_val * 1.5, 0.2, 0.6)
cv::Scalar mean_scalar = cv::mean(predResized);
float meanVal = static_cast<float>(mean_scalar[0]);
float binary_thresh = std::max(BINARY_THRESH_MIN, std::min(BINARY_THRESH_MAX, meanVal * 1.5f));
// 二值化
cv::Mat binaryMap;
cv::threshold(predResized, binaryMap, binary_thresh, 255, cv::THRESH_BINARY);
binaryMap.convertTo(binaryMap, CV_8U);
//Unclip 模拟 (形态学膨胀)
// Python 使用多边形偏移,C++ 简单版使用 mask 膨胀
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::dilate(binaryMap, binaryMap, kernel, cv::Point(-1, -1), UNCLIP_DILATE_ITERATIONS);
//查找轮廓
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binaryMap, contours, cv::RETR_LIST, cv::CHAIN_APPROX_SIMPLE);
double maxArea = 0.0;
box = cv::Rect(0, 0, 0, 0);
for (const auto& cnt : contours) {
double area = cv::contourArea(cnt);
if (area > MIN_AREA && area > maxArea) { // 过滤太小的噪点
maxArea = area;
box = cv::boundingRect(cnt);
}
}
// 返回二值图供外部进行更精细的操作
return binaryMap;
}
/***********************************************
* @功能描述 : 文本识别
***********************************************/
std::string ocrManger::recoginizeText(const cv::Mat & roi)
{
if (roi.empty()) return "";
//高度固定为 48,宽度按比例缩放,最大不超过 320
int h = roi.rows;
int w = roi.cols;
float ratio = w * 1.0f / h;
int target_w = std::min(int(REC_INPUT_H * ratio), REC_INPUT_W);
// 保证 target_w 至少为1
target_w = std::max(target_w, 1);
// 创建一个 48x320 的灰色底图 (0.5f 对应归一化后的0)
cv::Mat resized;
cv::resize(roi, resized, cv::Size(target_w, REC_INPUT_H));
cv::Mat padded(REC_INPUT_H, REC_INPUT_W, CV_32FC3, cv::Scalar(0.5f, 0.5f, 0.5f)); // 归一化后的0通常是灰
// 转换为浮点并归一化
resized.convertTo(resized, CV_32FC3);
resized /= 255.0f;
resized = (resized - 0.5f) / 0.5f;
// 将缩放后的图贴到 padding 图的左边
resized.copyTo(padded(cv::Rect(0, 0, target_w, REC_INPUT_H)));
//HWC -> CHW 转换
std::vector<float> inputTensorValues;
inputTensorValues.reserve(REC_INPUT_H * REC_INPUT_W * 3);
for (int c = 0; c < 3; c++) {
for (int i = 0; i < REC_INPUT_H; i++) {
for (int j = 0; j < REC_INPUT_W; j++) {
inputTensorValues.push_back(padded.at<cv::Vec3f>(i, j)[c]);
}
}
}
std::array<int64_t, 4> inputShape = { 1, 3, REC_INPUT_H, REC_INPUT_W };
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value inputTensor = Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorValues.size(), inputShape.data(), inputShape.size()
);
// 3. Inference
const char* inputNames[] = { m_strRecInputName.c_str() };
const char* outputNames[] = { m_strRecOutputName.c_str() };
auto outputTensor = m_recSession->Run(
Ort::RunOptions{ nullptr },
inputNames,
&inputTensor,
1,
outputNames,
1
);
// 模型输出形状通常是 [1, TimeSteps, NumClasses]
float* pOutput = outputTensor[0].GetTensorMutableData<float>();
auto outShape = outputTensor[0].GetTensorTypeAndShapeInfo().GetShape(); // [1, T, C]
int T = outShape[1];
int C = outShape[2];
std::string resultText;
int prev_idx = -1;
for (int t = 0; t < T; t++) {
// ArgMax
int max_idx = 0;
float max_val = -FLT_MAX;
for (int c = 0; c < C; c++) {
float val = pOutput[t * C + c];
if (val > max_val) {
max_val = val;
max_idx = c;
}
}
// CTC Logic: Drop duplicate neighbors and blank (index 0)
if (max_idx != prev_idx && max_idx != 0) {
if (max_idx < m_recDict.size()) {
resultText += m_recDict[max_idx];
}
}
prev_idx = max_idx;
}
return resultText;
}
/***********************************************
* @功能描述 : 从txt中读取字符对应字典
***********************************************/
std::vector<std::string> ocrManger::loadDict(const std::string & path)
{
vector<std::string> dict;
dict.push_back("blank");
std::ifstream infile(path);
string line;
while (getline(infile, line))
{
if (!line.empty())
{
dict.push_back(line);
}
}
return dict;
}
//获取单例对象
ocrManger* ocrManger::getInstance()
{
if (m_pInstance == nullptr)
{
m_pInstance = new ocrManger();
}
return m_pInstance;
}
能够识别出文字,但是检测的模型训练的不太好,有时候检测不到,需要加些扰动和缩放感觉
遇到问题
1.AssertionError: The length of ratio_list should be the same as the file_list.
去掉’','[../train_data/det/train.txt]'变为[../train_data/det/train.txt]
2.验证时候爆显存
打开配置文件,关闭使用gpuuse-gpu=false
3.OpenCV was not compiled with the freetype module (opencv_freetype) !
4.X版本的opencv都没有,需要自己编译,官方写的很详细,参考官方就行参考链接

4.opencv部分库下载失败
打开build文件夹下,有一个download_with_curl.sh,里边是下载的链接
使用科学上网,下载链接,把文件放入对应文件夹

保存的时候名字前缀对应,直接替换就行
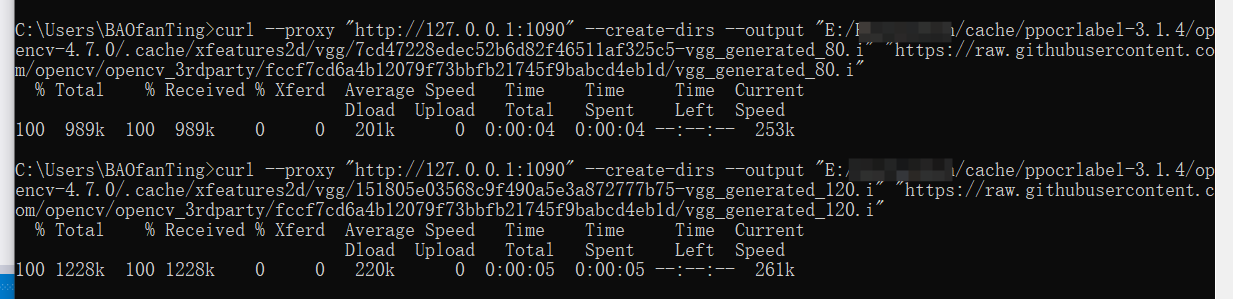
推荐使用以下方式,复制到cmd下载
curl --proxy "http://127.0.0.1:端口号" --create-dirs --output "E:/RuiYanTech/cache/ppocrlabel-3.1.4/opencv-4.7.0/.cache/xfeatures2d/boostdesc/98ea99d399965c03d555cef3ea502a0b-boostdesc_binboost_128.i" "https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_binboost_128.i"
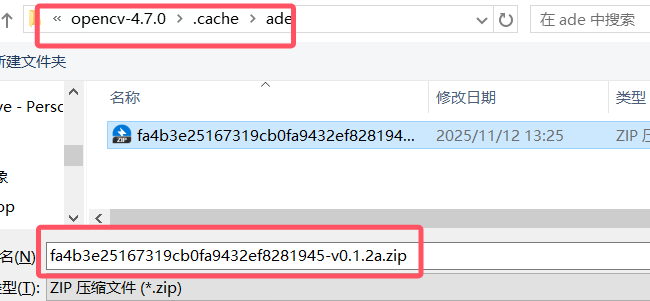
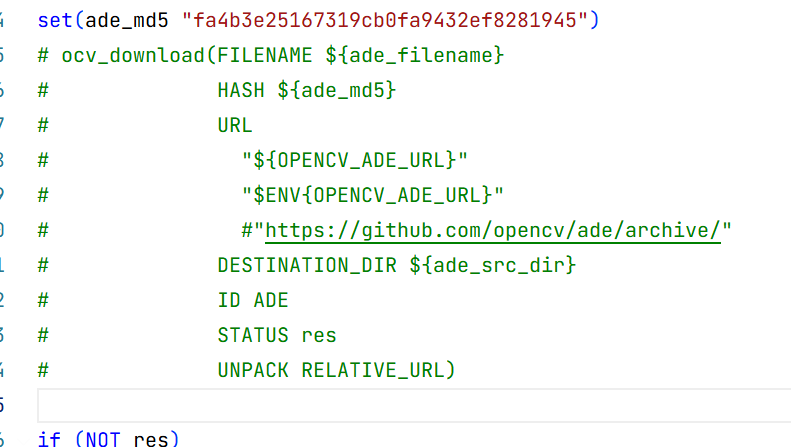
5.opencv编译No SOURCES given to target: ade
自行下载下载v0.1.2a.zip 替换名字放入
并将opencv-4.7.0\modules\gapi\cmake\DownloadADE.cmake的下载函数注释,再次config就能够编译通过了
6.检测到“_ITERATOR_DEBUG_LEVEL”的不匹配项: 值“2”不匹配值“0”(algorithm.obj 中)
生成opencv时报错,需要确保所有项目(opencv_world 和 harfbuzz)都使用相同的配置(Debug 或 Release)
7.onnx模型转换失败
运行后发现模型为0kb,转换失败
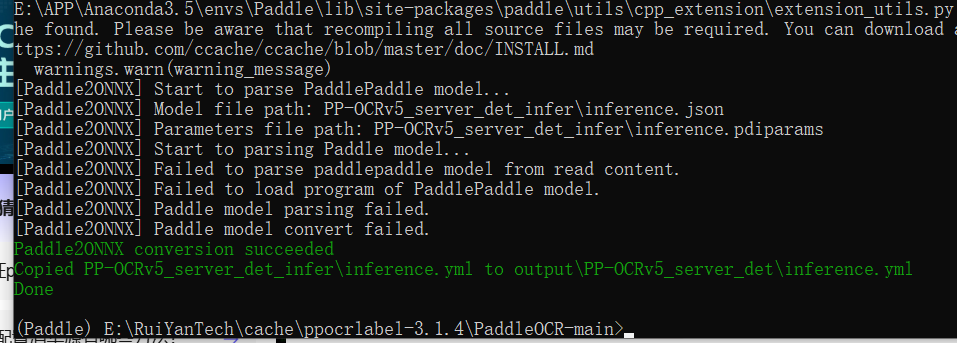
查询了相关资料,是导出模型的时候少了文件,新版的paddle改了只导出json,不使用.pdmodel,目前好像还没有修复这个bug,推荐使用小于3.0版本的paddle

8.onnxRuntime加载onnx模型生成环境报异常
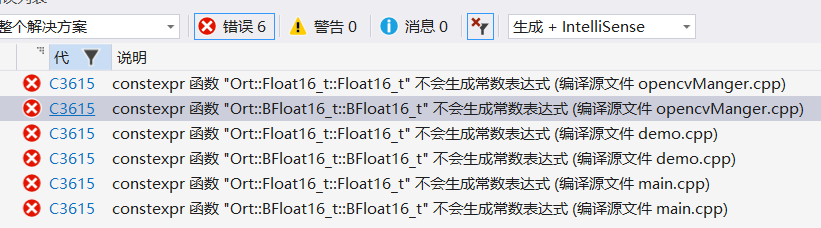
ONNX Runtime Exception: Load model from ./inference.onnx failed:D:\a_work\1\s\onnxruntime\core\graph\model.cc:111 onnxruntime::Model::Model Unknown model file format version.
我的c++的onnxRuntime是1.8.1版本的,导出模型的版本是1.18.0,估计是太老了,升级一下,直接统一换到1.18.0
升级后报错,找到错误删除constexpr

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)