yolov8训练模型,数据集自己制作
其实使用别人已经写好的预处理模型,来训练自己的模型。我们只需要准备好对应的数据集,告诉模型我们的数据集存放的路径,标签的分类和类别,根据自己的电脑的配置,训练自己的模型。其实对于我们开发者来说,确实比较简单,但是需要深入的学习,就需要研究其源码。背后的原理其实就是CNN。
1、制作自己的数据集
可以去一些免费的数据集网站上面去搜索免费的数据集,这里我们是自己从0开始制作数据集。在此,使用一种偷懒的方式来获取对应的图片。就是在网上找一个视频,通过opencv解析视频里面的图片,就可以获取到对应的图片。此方法,只适合学习。
解析代码:
需要opencv库的支持
pip install opencv-python==4.5.1.48# -*- coding: utf-8 -*-
# Auther : qiutiejun
# Date : 2024/12/10 16:36
# File : analysis.py
# 解析视频,提取图片,文件操作,使用opencv解析
import cv2
import os
# 打开视频文件
video = cv2.VideoCapture('wukong.mp4')
filename = 'make_img'
# 检查视频是否成功打开
if not video.isOpened():
print('视频文件没有找到')
else:
frame_count =0
# 创建文件夹
if not os.path.exists(filename):
os.makedirs(filename)
while True:
ret , frame = video.read()
if not ret:
break
frame_count+=1
if frame_count%50==0:
frame_filename = os.path.join(filename, f"frame_{frame_count:04d}.png")
print(frame_filename)
cv2.imwrite(frame_filename,frame)
print(f"总共生成{frame_count/50}张图片")
print('程序执行结束')
video.release()
运行代码会生成对应的图片:
2、数据标注
这里会出现一个问题,需要特别注意。
我自己使用的是python版本是3.8,安装labelimg时候,出现以下问题:
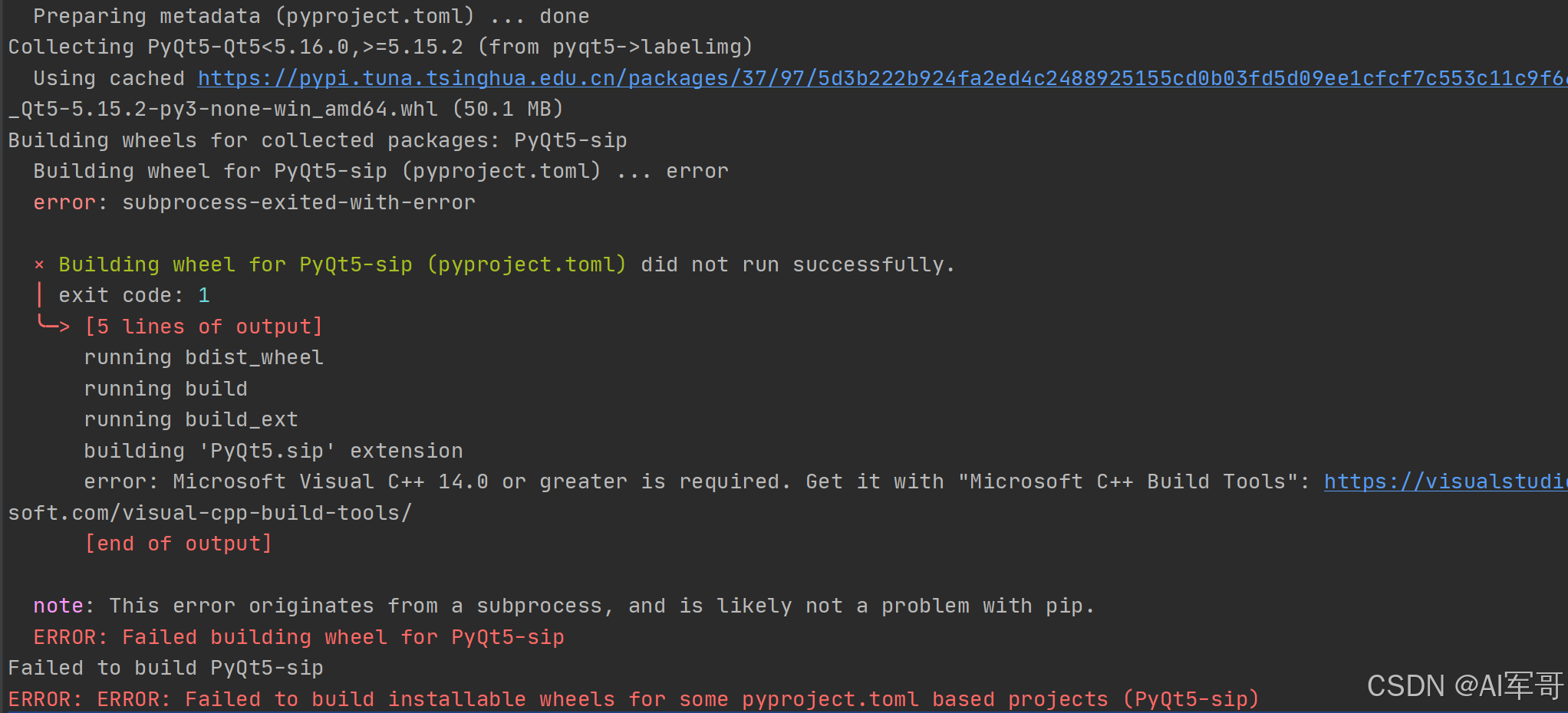
解决办法:
python版本修改为3.9版本即可。
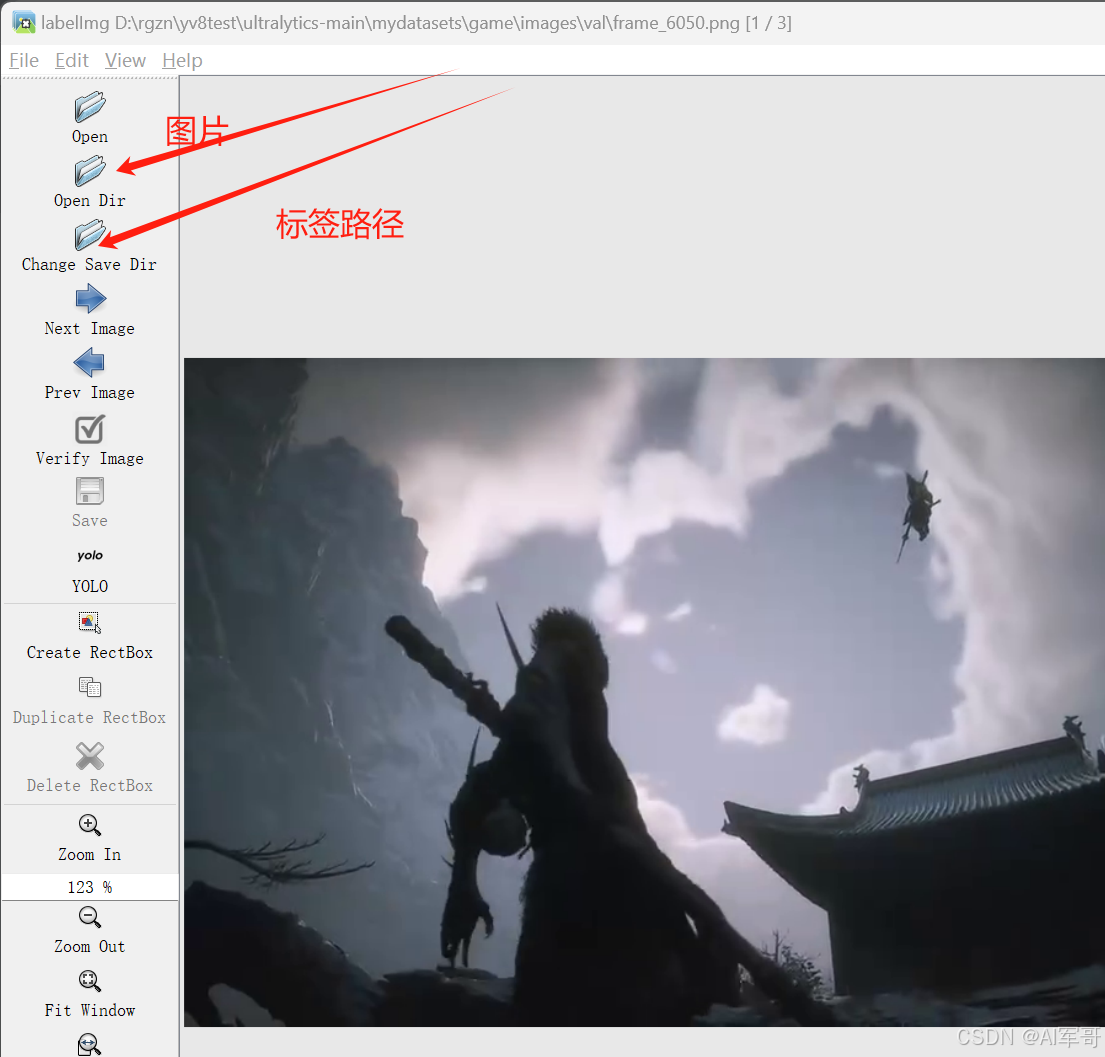
输入labelimg打开窗口
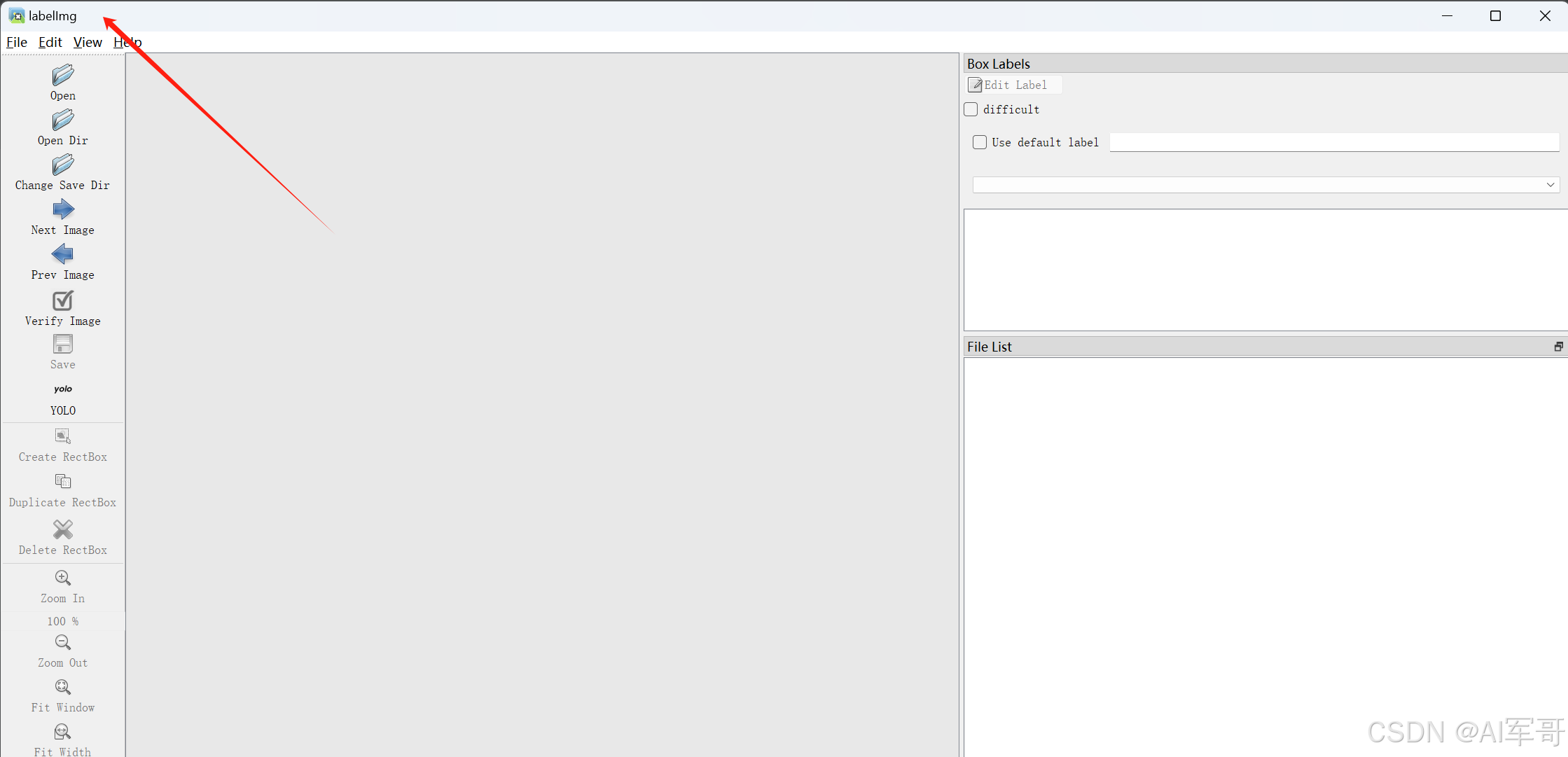
到此工具准备完成,接下来重点讲解数据标注工作。
个人觉得,对于程序本身来说,环境相比程序来说,个人觉得环境配置很重要。所以在创建环境的时候,对应python的版本很重要。如果选择python是3.9的版本,有可能会出现以下错误。
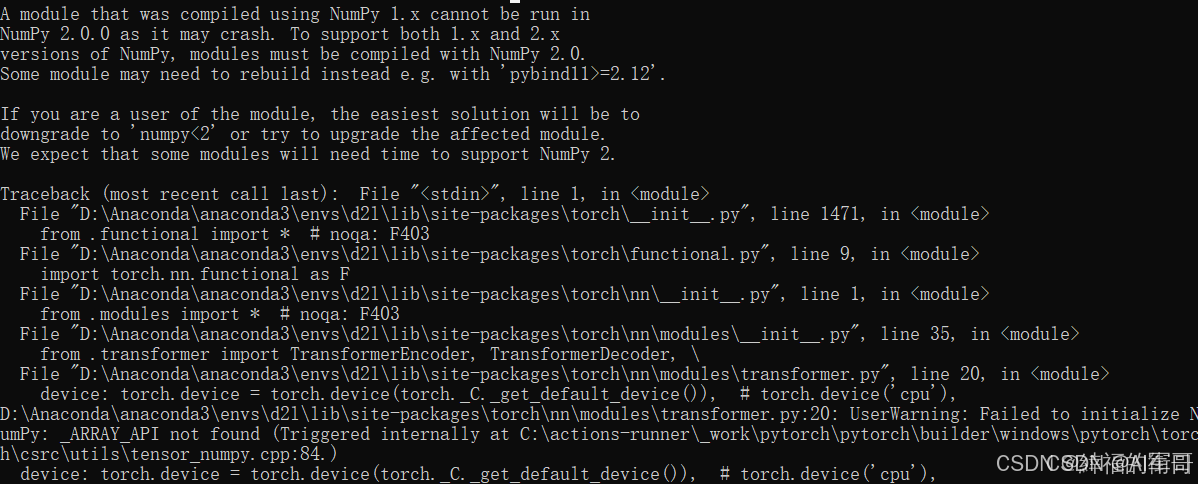
很明显是numpy的版本的问题,所以需要降低numpy的版本,解决方案如下:
pip install numpy==1.25.0
目录结构如下:
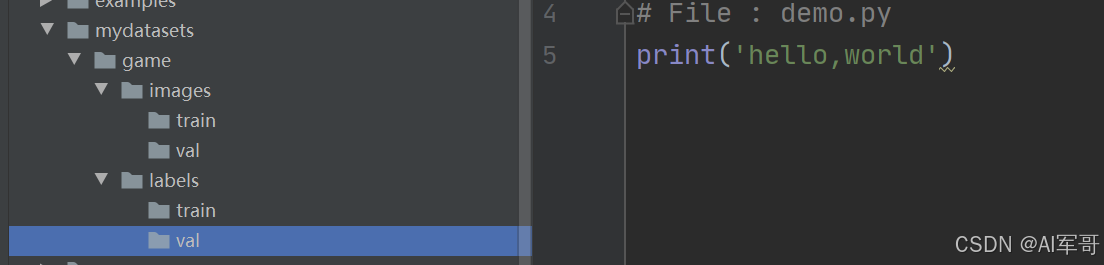
images下面存放训练和验证数据集的图片
labels下面存放训练和验证数据集的标签,需要一一对应。
这里需要注意的几个地方:
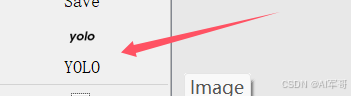
1、下面箭头指示的地方,一定要选择YOLO(总共有三种选项)
2、Open Dir 选择图片打开路径,默认会把标注好的图片存放到这个文件夹
3、Change Save Dir 指定txt文件输出的位置,也就是标注数据保存的位置,选择输出位置。这个也很重要。
4、每次标注好数据之后,记得按ctrl+s按键
示例代码:
原图:
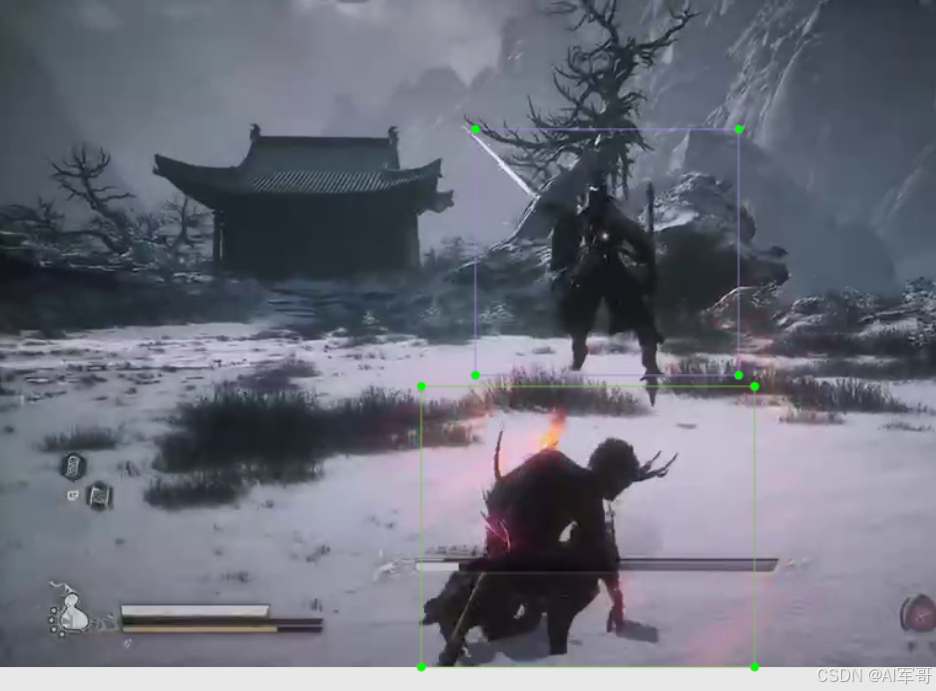
标注图:
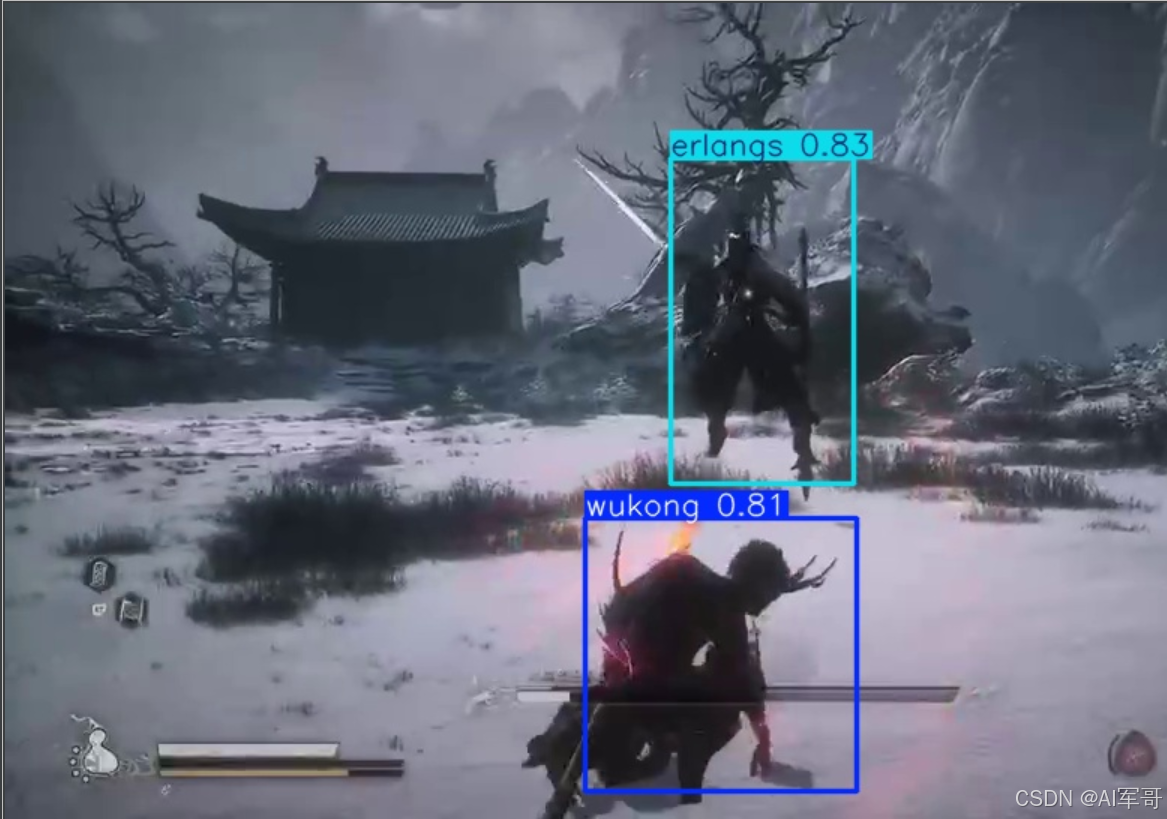
预测结果图
标签数据:
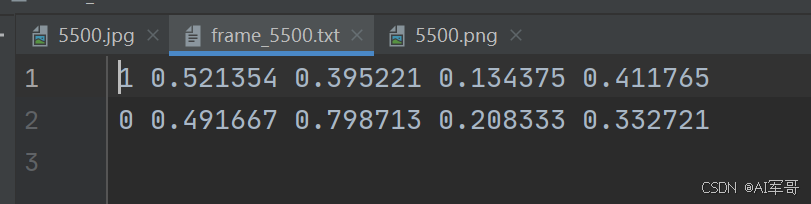
需要注意的是:图片位置和标签位置一定要一一对应。
3、模型训练前准备
- 我需要告诉程序我们的数据集在什么地方?(文件位置:ultralytics/cfg/datasets目录)。复制coco8.yaml或者coco128.yaml都可以,这个位置的配置文件就是配置数据集的目录结构的。我的命名是my_data.yaml文件,如果确实路径搞不清楚的化,简易大家使用绝对路径。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/detect/coco8/
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:\\rgzn\\yv8test\\ultralytics-main\\mydatasets\\game # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
#test: # test images (optional)
# Classes
names:
0: wukong
1: erlangs
2: dog
3: fuzi
4: huo
# 5: bus
# 6: train
# 7: truck
# 8: boat
# 9: traffic light
# 10: fire hydrant
# 11: stop sign
# 12: parking meter
# 13: bench
# 14: bird
# 15: cat
# 16: dog
# 17: horse
# 18: sheep
# 19: cow
# 20: elephant
# 21: bear
# 22: zebra
# 23: giraffe
# 24: backpack
# 25: umbrella
# 26: handbag
# 27: tie
# 28: suitcase
# 29: frisbee
# 30: skis
# 31: snowboard
# 32: sports ball
# 33: kite
# 34: baseball bat
# 35: baseball glove
# 36: skateboard
# 37: surfboard
# 38: tennis racket
# 39: bottle
# 40: wine glass
# 41: cup
# 42: fork
# 43: knife
# 44: spoon
# 45: bowl
# 46: banana
# 47: apple
# 48: sandwich
# 49: orange
# 50: broccoli
# 51: carrot
# 52: hot dog
# 53: pizza
# 54: donut
# 55: cake
# 56: chair
# 57: couch
# 58: potted plant
# 59: bed
# 60: dining table
# 61: toilet
# 62: tv
# 63: laptop
# 64: mouse
# 65: remote
# 66: keyboard
# 67: cell phone
# 68: microwave
# 69: oven
# 70: toaster
# 71: sink
# 72: refrigerator
# 73: book
# 74: clock
# 75: vase
# 76: scissors
# 77: teddy bear
# 78: hair drier
# 79: toothbrush
#
## Download script/URL (optional)
#download: https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip
- 配置模型训练的标签数量,同样的道理,为了保证不影响原程序的运行效果,我们还是重新赋值一份yolov8.yaml----------->my_yolov8.yaml文件,只需要将分类修改为本次自己数据集的分类。默认是80,我这一次是5个分类。所以最终修改为5。nc:5
- 以上工作完成之后,我们就可以开始训练自己的模型了。
4、模型训练
start_train.py
# 模型训练
from ultralytics import YOLO
# 查找配置文件
model = YOLO("D:\\rgzn\\yv8test\\ultralytics-main\\ultralytics\\cfg\\models\\v8\\my_yolov8.yaml")
# 加载预训练模型
model = YOLO('yolov8n.pt')
# 训练模型
results = model.train(data="D:\\rgzn\\yv8test\\ultralytics-main\\ultralytics\\cfg\\datasets\\my_data.yaml",
epochs=100,batch=8,device='cpu',workers=0,imgsz=640)
results = model.val()
model.train参数说明:
YOLO 模型的训练设置包括在训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和精度。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器的选择、损失函数以及训练数据集的组成也会对训练过程产生影响。通过对这些设置进行仔细调整和实验,对于优化性能至关重要。
| Argument | Default | Description |
| model | None | 指定用于训练的模型文件。接受 .pt 预训练模型的路径或 .yaml 配置文件的路径。对于定义模型结构或初始化权重是必不可少的。 |
| data | None | 数据集配置文件的路径(例如,coco8.yaml)。该文件包含数据集特定的参数,包括训练和验证数据的路径、类别名称以及类别数量。 |
| epochs | 100 | 训练周期的总数。每个周期代表对整个数据集的完整遍历。调整次值可以影响训练时长和模型性能 |
| batch | 16 | 数据集配置文件的路径(例如,coco8.yaml)。该文件包含数据集特定的参数,包括训练和验证数据的路径、类别名称以及类别数量。 |
| imgsz | 640 |
训练目标图片大小。所有图像在输入模型之前都会调整这个尺寸。 会影响模型的准确度和计算复杂度 |
| save | True | 启用保存训练检查点和最终模型权重,对于恢复训练或者模型部署非常有用 |
| workers | 8 | 数据加载的工作线程数量(如果是多 GPU 训练,则按 RANK 计算)。影响数据预处理和输入模型的速度,在多 GPU 设置中尤为有用。cpu加以给0 |
| optimizer | auto | 择训练的优化器。选项包括 SGD、Adam、AdamW、NAdam、RAdam、RMSProp 等,或者 auto 以根据模型配置自动选择。影响收敛速度和稳定性。 |
训练完成之后,会在runs目录下面保存一个最好的模型和一个最后一次的模型
6、模型预测
就是使用自己训练好的模型,来验证模型的好坏
start_pre.py
# 预测
from ultralytics import YOLO
model = YOLO("D:\\rgzn\\yv8test\\ultralytics-main\\runs\detect\\train4\\weights\\best.pt")
model.predict(source='wukong.mp4',show=True,save=True)预测结果会保存在 runs -->detect---->predict目录下面

到此,模型训练结束:
7、总结
其实使用别人已经写好的预处理模型,来训练自己的模型。我们只需要准备好对应的数据集,告诉模型我们的数据集存放的路径,标签的分类和类别,根据自己的电脑的配置,训练自己的模型。其实对于我们开发者来说,确实比较简单,但是需要深入的学习,就需要研究其源码。背后的原理其实就是CNN。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)