【labelme/labelimg 转 Yolov11/v8】将 xml/json 矩形标注转 YOLO 训练数据格式(含一键划分train、val、test + 训练示例)
目录
本文将着重讲述标注数据向Yolo数据格式的转化,并重新梳理了 labelme/labelimg 打标签、转换Yolo训练格式、一键划分数据集、模型训练的全过程。
一、代码功能
-
自动文件匹配:智能匹配图片和标签文件,支持多种图片格式(jpg/png/webp)
-
数据验证:自动跳过无效标注(非矩形标注、无效坐标等)
-
类别自动映射:根据标注文件自动生成
classes.txt -
灵活划分比例:支持自定义训练集/验证集/测试集比例
-
完整日志输出:显示处理进度和最终统计信息
-
随机种子支持:保证可重复的实验结果
-
高效处理:使用 Pathlib 和 shutil 进行高效文件操作
-
动态选择解析方法:根据标注文件的后缀(
.json或.xml)动态选择对应的解析方法。
二、数据准备
1)labelme/labelimg 矩形标注准备
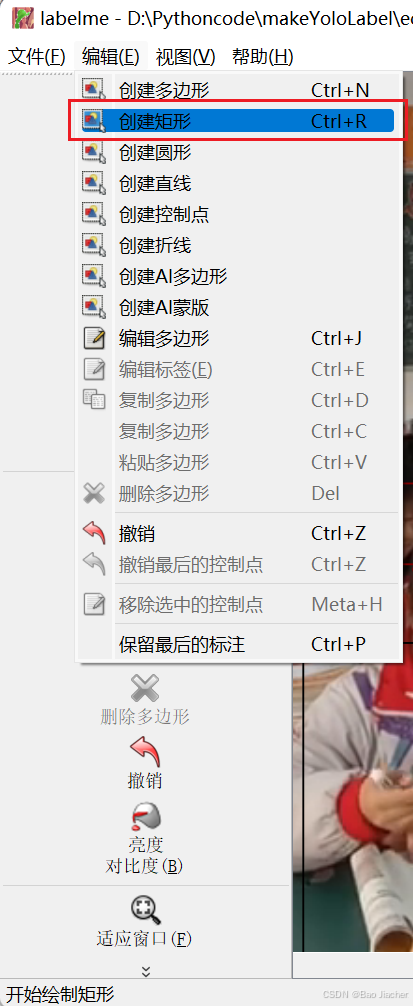
先用 labelme/labelimg 的矩形工具框选分类对象,注意是下图中所示的“创建矩形”。
2)符合程序识别的文件结构准备
标注完成数据之后的文件结构如下,要求文件夹A下必须有两个子文件夹,其名称严格为 images、labels:
文件夹A/
├── images/
│ ├── 001.jpg
│ ├── 002.png
│ └── 003.webp
└── labels/
├── 001.json
├── 002.json
└── 003.json其中,images 文件夹存放各种类型的图片,labels 文件夹存放 json/xml 格式的标注文件。
三、代码运行
下述代码只需要在 if __name__ == "__main__" : 中进行修改即可:
import json
import random
import shutil
from pathlib import Path
from sklearn.model_selection import train_test_split
import xml.etree.ElementTree as ET
class LabelmeToYOLOConverter:
def __init__(self, class_map=None):
self.class_map = class_map or {}
self.reverse_class_map = {v: k for k, v in self.class_map.items()}
def process_dataset(self,
input_dir: str,
output_dir: str,
test_ratio: float = 0.15,
val_ratio: float = 0.15,
seed: int = 42):
"""主处理函数
参数:
input_dir: 原始数据集路径(文件夹A)
output_dir: 输出路径(文件夹B)
test_ratio: 测试集比例 (0-1)
val_ratio: 验证集比例 (0-1)
seed: 随机种子
"""
# 初始化路径
input_path = Path(input_dir)
output_path = Path(output_dir)
# 验证参数
self._validate_ratios(test_ratio, val_ratio)
# 准备目录结构
self._create_dirs(output_path)
# 获取匹配的文件对
matched_pairs = self._find_matching_pairs(input_path)
print(f"找到 {len(matched_pairs)} 个有效数据对")
# 自动生成类别映射(如果未提供)
if not self.class_map:
self._generate_class_map(matched_pairs, output_path)
# 划分数据集
splits = self._split_dataset(matched_pairs, test_ratio, val_ratio, seed)
# 处理每个子集
self._process_splits(splits, output_path)
# 保存类别映射
self._save_class_map(output_path)
print("转换完成!")
return {
'class_map': self.class_map,
'splits_size': {k: len(v) for k, v in splits.items()}
}
def _validate_ratios(self, test_ratio, val_ratio):
"""验证比例参数有效性"""
if not (0 <= test_ratio < 1 and 0 <= val_ratio < 1):
raise ValueError("比例参数必须在 [0, 1) 范围内")
if (test_ratio + val_ratio) >= 1:
raise ValueError("测试集和验证集比例之和不能超过 1")
def _create_dirs(self, output_path):
"""创建输出目录结构"""
for subset in ['train', 'val', 'test']:
(output_path / 'images' / subset).mkdir(parents=True, exist_ok=True)
(output_path / 'labels' / subset).mkdir(parents=True, exist_ok=True)
def _find_matching_pairs(self, input_path):
"""匹配图片和标注文件"""
image_dir = input_path / 'images'
label_dir = input_path / 'labels'
images = {f.stem: f for f in image_dir.glob('*')
if f.is_file() and f.suffix.lower() in ['.jpg', '.jpeg', '.png', '.webp']}
# 支持 .xml 标注文件
labels = {f.stem: f for f in label_dir.glob('*')
if f.is_file() and f.suffix.lower() in ['.json', '.xml']}
common_stems = set(images.keys()) & set(labels.keys())
return [(images[stem], labels[stem]) for stem in common_stems]
def _generate_class_map(self, matched_pairs, output_path):
"""自动生成类别映射"""
all_labels = set()
for _, label_path in matched_pairs:
# 根据文件后缀选择解析方法
if label_path.suffix.lower() == '.json':
data = self._parse_labelme(label_path)
elif label_path.suffix.lower() == '.xml':
data = self._parse_xml(label_path)
else:
continue # 跳过不支持的文件格式
for ann in data['annotations']:
all_labels.add(ann['label'])
self.class_map = {label: idx for idx, label in enumerate(sorted(all_labels))}
self.reverse_class_map = {v: k for k, v in self.class_map.items()}
def _parse_labelme(self, json_path):
"""解析LabelMe标注文件"""
with open(json_path, 'r') as f:
data = json.load(f)
image_size = (data['imageWidth'], data['imageHeight'])
annotations = []
for shape in data['shapes']:
if shape['shape_type'] != 'rectangle':
continue # 跳过非矩形标注
label = shape['label']
points = shape['points']
x1, y1 = points[0]
x2, y2 = points[1]
annotations.append({
'label': label,
'points': [(x1, y1), (x2, y2)]
})
return {
'image_size': image_size,
'annotations': annotations
}
def _parse_xml(self, xml_path):
"""解析 Pascal VOC 格式的 XML 文件"""
tree = ET.parse(xml_path)
root = tree.getroot()
image_size = None
annotations = []
for size_node in root.findall('size'):
image_width = int(size_node.find('width').text)
image_height = int(size_node.find('height').text)
image_size = (image_width, image_height)
for obj_node in root.findall('object'):
label = obj_node.find('name').text
bndbox = obj_node.find('bndbox')
x1 = int(bndbox.find('xmin').text)
y1 = int(bndbox.find('ymin').text)
x2 = int(bndbox.find('xmax').text)
y2 = int(bndbox.find('ymax').text)
annotations.append({
'label': label,
'points': [(x1, y1), (x2, y2)]
})
return {
'image_size': image_size,
'annotations': annotations
}
def _split_dataset(self, pairs, test_ratio, val_ratio, seed):
"""划分数据集"""
random.seed(seed)
pairs = random.sample(pairs, len(pairs)) # 打乱顺序
# 第一次拆分:测试集
split_idx = int(len(pairs) * (1 - test_ratio))
train_val, test = pairs[:split_idx], pairs[split_idx:]
# 第二次拆分:验证集
split_idx = int(len(train_val) * (1 - val_ratio / (1 - test_ratio)))
train, val = train_val[:split_idx], train_val[split_idx:]
return {
'train': train,
'val': val,
'test': test
}
def _process_splits(self, splits, output_path):
"""处理各个子集"""
for subset_name, pairs in splits.items():
print(f"处理 {subset_name} 集 ({len(pairs)} 个样本)")
for img_path, label_path in pairs:
# 复制图片
output_img_dir = output_path / 'images' / subset_name
shutil.copy(img_path, output_img_dir / img_path.name)
# 转换标注
if label_path.suffix.lower() == '.json':
annotation_data = self._parse_labelme(label_path)
elif label_path.suffix.lower() == '.xml':
annotation_data = self._parse_xml(label_path)
else:
continue # 跳过不支持的文件格式
output_label_path = output_path / 'labels' / subset_name / f"{img_path.stem}.txt"
self._convert_to_yolo(annotation_data, output_label_path)
def _convert_to_yolo(self, annotation_data, output_path):
"""转换单个文件到YOLO格式"""
img_w, img_h = annotation_data['image_size']
with open(output_path, 'w') as f:
for ann in annotation_data['annotations']:
# 获取类别ID
class_id = self.class_map.get(ann['label'], -1)
if class_id == -1:
continue
x1, y1 = ann['points'][0]
x2, y2 = ann['points'][1]
# 坐标归一化
x_center = ((x1 + x2) / 2) / img_w
y_center = ((y1 + y2) / 2) / img_h
width = abs(x2 - x1) / img_w
height = abs(y2 - y1) / img_h
# 写入文件
f.write(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
def _save_class_map(self, output_path):
"""保存类别映射文件"""
with open(output_path / 'classes.txt', 'w') as f:
for label, idx in sorted(self.class_map.items(), key=lambda x: x[1]):
f.write(f"{label}\n")
# 使用示例
if __name__ == "__main__":
# 自定义类别映射(根据你的标注分类设置)
custom_class_map = {
'汽车': 0,
'行人': 1,
'建筑': 2
}
# 初始化转换器
converter = LabelmeToYOLOConverter(class_map=custom_class_map)
# 设置参数
params = {
"input_dir": "./文件夹A", # 确保文件夹A的目录下有images和labels这两个子文件夹
"output_dir": "./文件夹B", # 文件夹B可以不事先创建,程序会自动创建
"test_ratio": 0.15, # 测试集占全集的比例
"val_ratio": 0.15, # 验证集占全集的比例
"seed": 42 # 随机种子对数据集洗牌
}
# 执行转换
result = converter.process_dataset(**params)
# 输出统计信息
print("\n转换结果统计:")
print(f"类别映射:{result['class_map']}")
print(f"数据集划分:{result['splits_size']}")最终得到文件夹B,是 Yolov11/v8 可识别的形式:
文件夹B/
├── classes.txt
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/那么拿到这个数据集后,如何让 Yolo 识别出来并对其训练呢? 下文详细介绍。
四、Yolov11/v8 yaml 配置文件(可跳过)
拿到 Yolo 可识别的数据集后首先需要配置 yaml 文件(test.yaml):
path: datasets # 文件夹B的地址
train: images/train # 文件夹B下训练集的相对地址(不修改)
val: images/val # 文件夹B下验证集的相对地址(不修改)
test: images/test # 文件夹B下测试集的相对地址(不修改)
nc: 8 # 标签标注的类别数量,这里为例标注了8个类别
# 这里存放8个类别的具体标签
# 注意前后次序需要严格按照 classes.txt 文件的次序来
names:
[
"dx",
"dk",
"tt",
"zt",
"js",
"zl",
"xt",
"jz",
]
有了 yaml 配置文件,我们就可以直接让 data=test.yaml 让 Yolo 训练了。在 Jupyter 运行下述代码即可训练(配合 wandb 记录训练的过程):
!yolo detect train data=test.yaml model=yolo11n.pt pretrained=False project=test name=yolov11n epochs=80 batch=16 device=0由于我的本地算力有限,所以在 featurize 租了 RTX3060 云显卡训练 Yolo 模型:
Featurize:4090显卡只需1.87元/小时https://featurize.cn?s=19df5c703fac44b4a13e3a6fad3bcb96![]() https://featurize.cn?s=19df5c703fac44b4a13e3a6fad3bcb96我大概有 9000 张训练图片,训练1.378小时训练完毕。这是训练完毕的结果:
https://featurize.cn?s=19df5c703fac44b4a13e3a6fad3bcb96我大概有 9000 张训练图片,训练1.378小时训练完毕。这是训练完毕的结果:
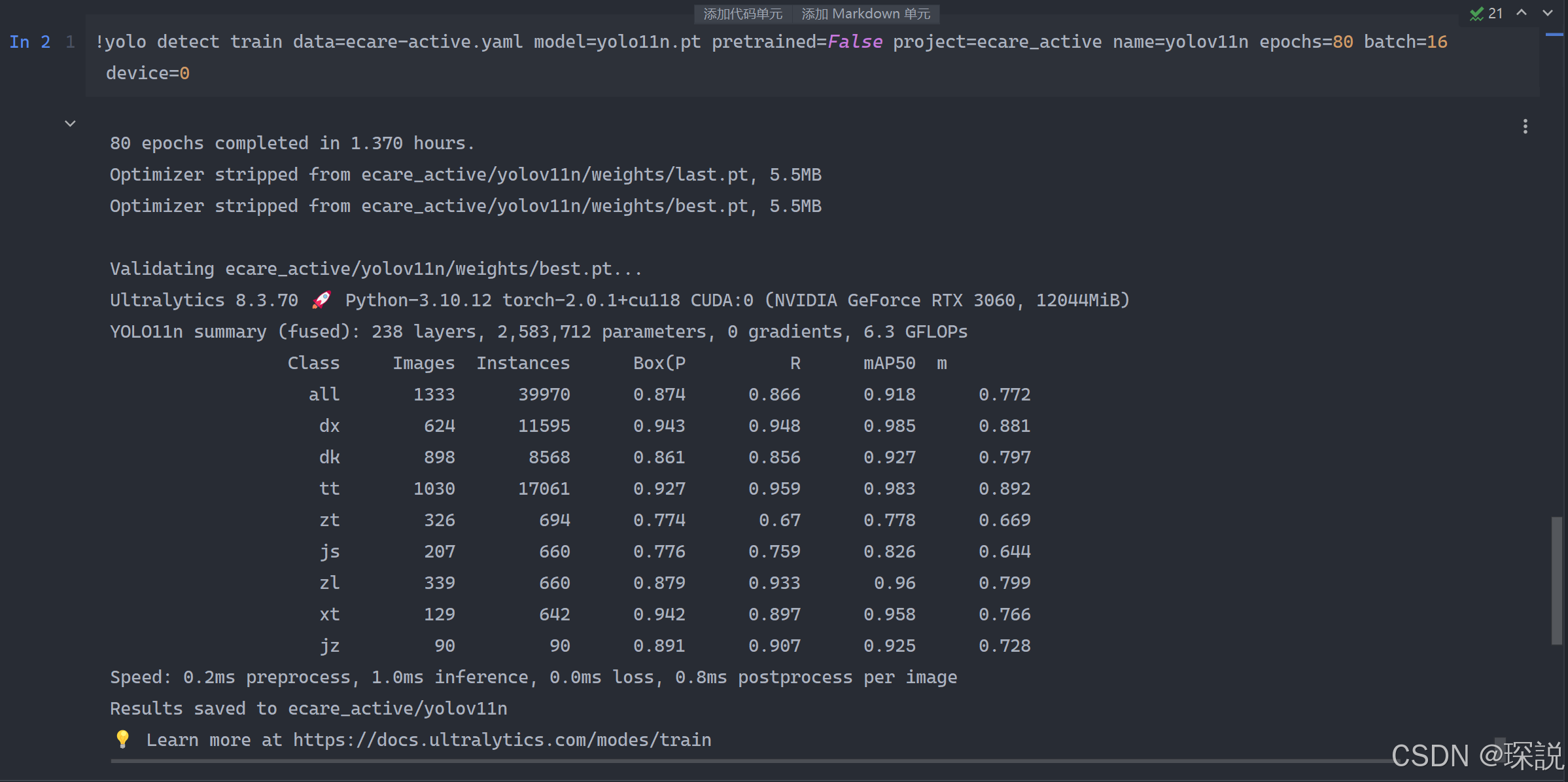
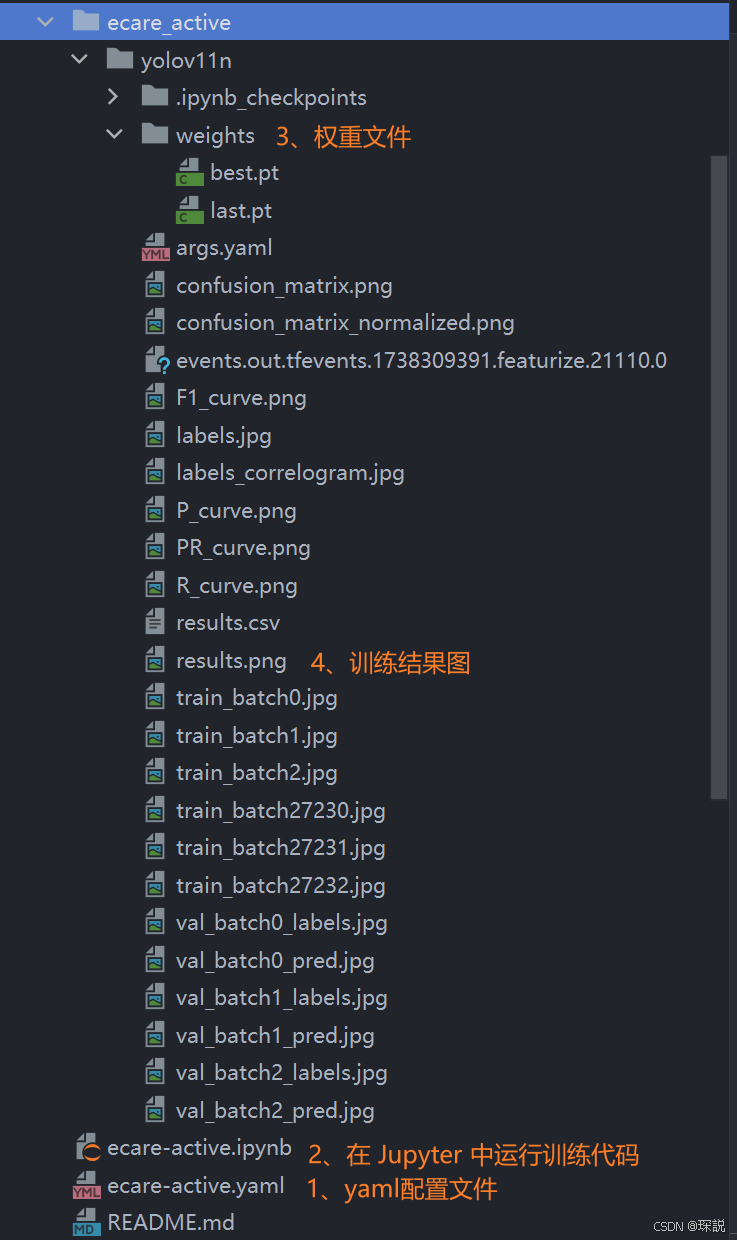
最终得到训练的结果(含回召率、准确率等信息)和权重文件:
由于模型训练这部分不是本文的重点,介绍较为粗略,因此如有疑问欢迎评论区留言。
五、注意事项
-
确保 LabelMe/LabelImg 标注均为矩形(rectangle类型)
-
图片和标签文件名需严格对应(如:001.jpg 对应 001.json)
-
建议在转换前备份原始数据
-
首次运行时建议使用小比例参数测试(如--test_ratio 0.1 --val_ratio 0.1)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)