职业人群体检数据分析及可视化展示
使用Matplotlib绘制误差棒图,将工作年限分为5个组(0-5年、5-10年、10-15年、15-20年、20年以上),展示不同工作年限分组下各体检指标的平均值及标准差。本数据集为职业人群体检数据,包含1112条有效记录,主要字段包括:性别、是否吸烟、是否饮酒、开始从事某工作年份、体检年份、淋巴细胞计数、白细胞计数、血小板计数等。本数据集为职业人群体检数据,包含1112条有效记录,主要字段包括
1.1 数据集概述
本数据集为职业人群体检数据,包含1112条有效记录,主要字段包括:性别、是否吸烟、是否饮酒、开始从事某工作年份、体检年份、淋巴细胞计数、白细胞计数、血小板计数等。通过对这些体检指标进行统计分析,可以了解职业人群的健康状况分布特征。
1.2 基本统计分析
对数据集中的数值型指标(淋巴细胞计数、白细胞计数、血小板计数)进行了基本统计分析,包括最大值、最小值、求和、均值、方差、标准差等统计量。
统计结果摘要:
- 淋巴细胞计数:均值3.85,标准差60.62,范围0.34-2018.00
- 白细胞计数:均值6.18,标准差12.04,范围1.30-404.00
- 血小板计数:均值202.77,标准差58.93,范围2.90-463.00
1.3 可视化工具选择
本数据集的可视化分析采用了以下三种工具:
- Matplotlib:用于基础图表绘制,如饼图、误差棒图
- Seaborn:用于高级统计图表,如分组柱状图、配对图
- Pyecharts:用于交互式高级图表,如3D散点图
1.4 图形种类
本数据集共生成5种不同类型的可视化图表:
1. Matplotlib饼图 - 性别分布
2. Seaborn分组柱状图 - 不同性别各指标平均值对比(对比分析图)
3. Matplotlib误差棒图 - 不同工作年限分组指标平均值
4. Seaborn配对图 - 多变量关系分析
5. Pyecharts 3D散点图 - 三个体检指标三维关系分析
1.5 数据分析及可视化过程
图1-1:性别分布饼图
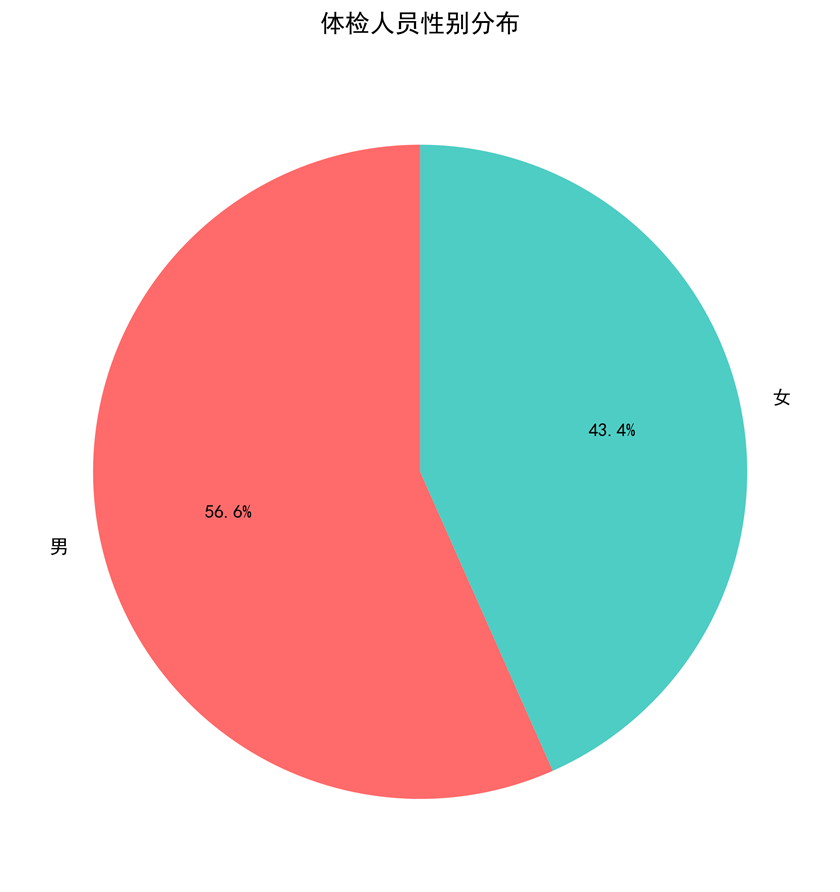
图1-1 性别分布饼图
图表说明: 使用Matplotlib绘制饼图,展示体检人员的性别分布情况。通过饼图可以直观地看出男女比例,为后续的性别对比分析提供基础。
核心代码:
gender_counts = df['性别'].value_counts()
fig, ax = plt.subplots(figsize=(8, 8))
colors = ['#FF6B6B', '#4ECDC4']
wedges, texts, autotexts = ax.pie(gender_counts.values, labels=gender_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90,
textprops={'fontsize': 12, 'fontweight': 'bold'})
ax.set_title('体检人员性别分布', fontsize=16, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart1_pie.png'), dpi=300, bbox_inches='tight')
图1-2:不同性别各指标平均值对比分组柱状图
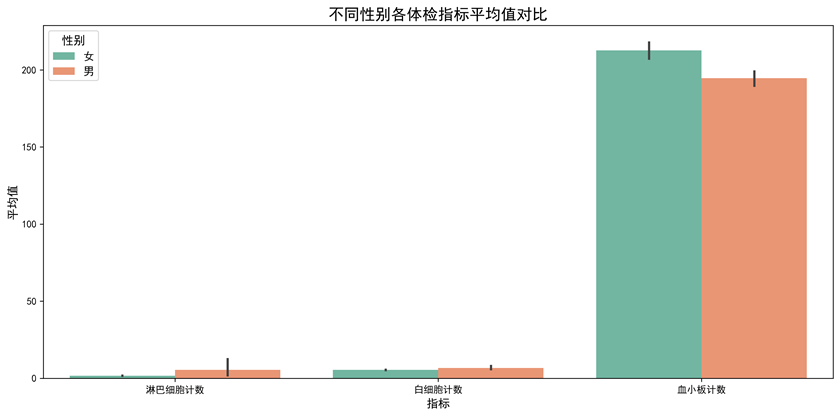
图1-2 不同性别各指标平均值对比
图表说明: 使用Seaborn绘制分组柱状图,对比分析不同性别在三个体检指标(淋巴细胞计数、白细胞计数、血小板计数)上的平均值差异。这是本数据集的对比分析图,通过分组柱状图可以清晰地看出性别对体检指标的影响。
核心代码:
df_melted = df[['性别'] + numeric_cols].melt(id_vars=['性别'],
value_vars=numeric_cols,
var_name='指标',
value_name='数值')
plt.figure(figsize=(12, 6))
sns.barplot(data=df_melted, x='指标', y='数值', hue='性别', palette='Set2')
plt.title('不同性别各体检指标平均值对比', fontsize=16, fontweight='bold')
plt.xlabel('指标', fontsize=12)
plt.ylabel('平均值', fontsize=12)
plt.legend(title='性别', title_fontsize=12, fontsize=11)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart2_grouped_bar.png'), dpi=300, bbox_inches='tight')
图1-3:不同工作年限分组指标平均值误差棒图
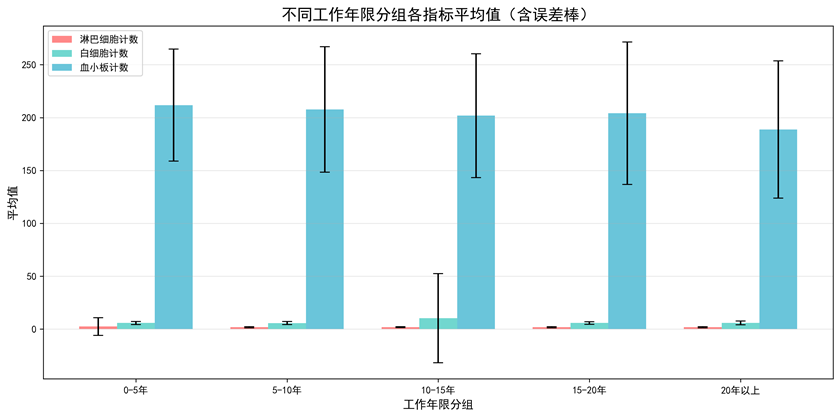
图1-3 不同工作年限分组指标平均值
图表说明: 使用Matplotlib绘制误差棒图,将工作年限分为5个组(0-5年、5-10年、10-15年、15-20年、20年以上),展示不同工作年限分组下各体检指标的平均值及标准差。误差棒显示了数据的离散程度,有助于了解工作年限对健康指标的影响。
核心代码:
df['工作年限分组'] = pd.cut(df['工作年限'], bins=[0, 5, 10, 15, 20, 50],
labels=['0-5年', '5-10年', '10-15年', '15-20年', '20年以上'])
df_work = df[df['工作年限分组'].notna()].copy()
fig, ax = plt.subplots(figsize=(12, 6))
x_pos = np.arange(len(df_work['工作年限分组'].cat.categories))
width = 0.25
for i, col in enumerate(numeric_cols):
means = []
stds = []
for group in df_work['工作年限分组'].cat.categories:
group_data = df_work[df_work['工作年限分组'] == group][col].dropna()
if len(group_data) > 0:
means.append(group_data.mean())
stds.append(group_data.std())
else:
means.append(0)
stds.append(0)
ax.bar(x_pos + i*width, means, width, yerr=stds, label=col,
alpha=0.8, capsize=5, color=['#FF6B6B', '#4ECDC4', '#45B7D1'][i])
ax.set_xlabel('工作年限分组', fontsize=12)
ax.set_ylabel('平均值', fontsize=12)
ax.set_title('不同工作年限分组各指标平均值(含误差棒)', fontsize=16, fontweight='bold')
ax.set_xticks(x_pos + width)
ax.set_xticklabels(df_work['工作年限分组'].cat.categories)
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart3_errorbar.png'), dpi=300, bbox_inches='tight')
图1-4:多变量关系配对图
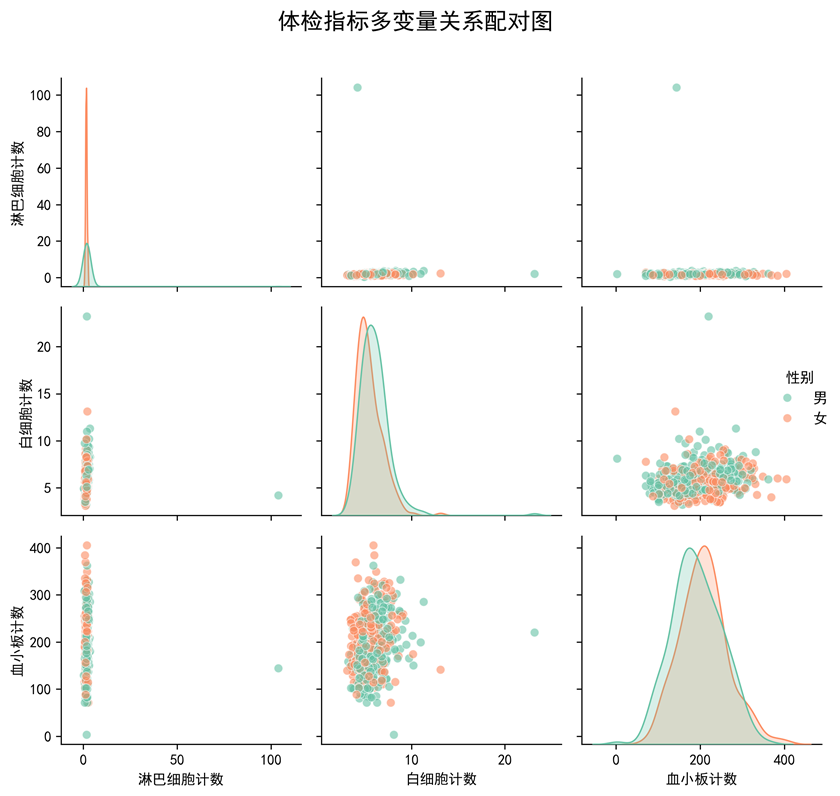
图1-4 多变量关系配对图
图表说明: 使用Seaborn绘制配对图(Pair Plot),展示三个体检指标之间的相关性和分布关系。配对图包含散点图矩阵和对角线上的密度分布图,可以同时观察多个变量之间的两两关系,并按性别进行颜色区分。
核心代码:
df_sample = df[numeric_cols + ['性别']].dropna().sample(min(500, len(df)), random_state=42)
plt.figure(figsize=(12, 10))
sns.pairplot(df_sample[numeric_cols + ['性别']], hue='性别',
palette='Set2', diag_kind='kde', plot_kws={'alpha': 0.6})
plt.suptitle('体检指标多变量关系配对图', fontsize=16, fontweight='bold', y=1.02)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart4_pairplot.png'), dpi=300, bbox_inches='tight')
图1-5:三个体检指标三维关系3D散点图
图1-5 三个体检指标三维关系3D散点图
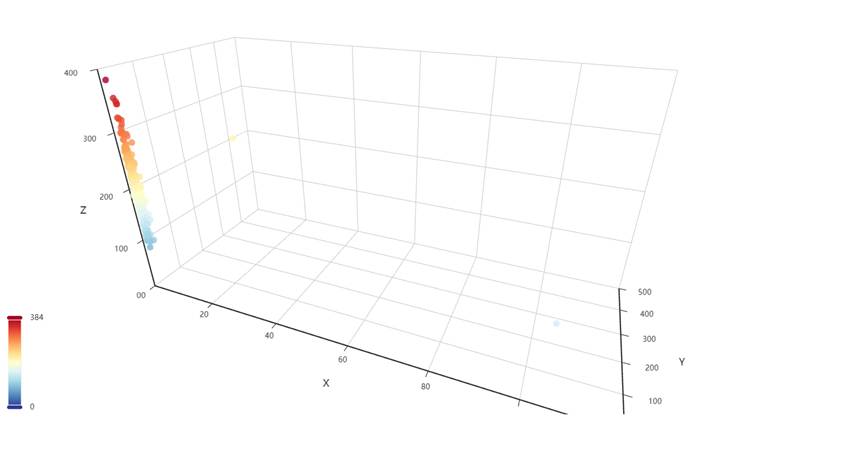
图表说明: 使用Pyecharts绘制3D散点图,这是本数据集的高级图表。将淋巴细胞计数、白细胞计数、血小板计数三个指标分别映射到X、Y、Z三个坐标轴,形成三维空间中的散点分布。图表支持交互式旋转和缩放,可以通过颜色映射观察血小板计数的数值范围,并按性别(男/女)用不同系列区分数据点。3D散点图能够直观地展示三个体检指标之间的三维关系,有助于发现数据中的潜在模式和异常值。
核心代码:
df_3d = df[numeric_cols + ['性别']].dropna().copy()
df_3d_sample = df_3d.head(300)
male_data = df_3d_sample[df_3d_sample['性别'] == '男']
female_data = df_3d_sample[df_3d_sample['性别'] == '女']
scatter3d = (
Scatter3D(init_opts=opts.InitOpts(theme=ThemeType.MACARONS, width="1200px", height="700px"))
.add(
series_name="男性",
data=[
[row['淋巴细胞计数'], row['白细胞计数'], row['血小板计数']]
for _, row in male_data.iterrows()
],
xaxis3d_opts=opts.Axis3DOpts(
name="淋巴细胞计数",
type_="value",
min_=0,
max_=df_3d_sample['淋巴细胞计数'].max() * 1.1
),
yaxis3d_opts=opts.Axis3DOpts(
name="白细胞计数",
type_="value",
min_=0,
max_=df_3d_sample['白细胞计数'].max() * 1.1
),
zaxis3d_opts=opts.Axis3DOpts(
name="血小板计数",
type_="value",
min_=0,
max_=df_3d_sample['血小板计数'].max() * 1.1
),
grid3d_opts=opts.Grid3DOpts(width=100, height=100, depth=100),
)
.add(
series_name="女性",
data=[
[row['淋巴细胞计数'], row['白细胞计数'], row['血小板计数']]
for _, row in female_data.iterrows()
],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="体检指标三维关系分析(3D散点图)", pos_left="center"),
visualmap_opts=opts.VisualMapOpts(
max_=df_3d_sample['血小板计数'].max(),
range_color=[
"#313695", "#4575b4", "#74add1", "#abd9e9", "#e0f3f8",
"#ffffcc", "#fee090", "#fdae61", "#f46d43", "#d73027", "#a50026",
],
),
)
)
scatter3d.render(os.path.join(output_dir, "health_chart5_scatter3d.html"))
1.6 分析总结
通过对职业人群体检数据的分析,我们得出以下主要结论:
- 性别分布:体检人员中男女比例相对均衡,为后续的性别对比分析提供了良好的数据基础。
- 性别差异:通过分组柱状图可以看出,不同性别在体检指标上存在一定差异,这为健康管理提供了性别化的参考依据。
- 工作年限影响:误差棒图显示不同工作年限分组下的体检指标存在差异,工作年限可能对健康状况产生影响。
- 指标相关性:配对图揭示了三个体检指标之间的相关关系,有助于理解各指标之间的内在联系。
- 三维关系:3D散点图提供了三个指标的三维视角,能够发现二维图表难以观察到的数据模式和异常值。
本数据集的分析采用了多种可视化工具和图表类型,从不同角度全面展示了职业人群的体检数据特征,为健康管理和风险评估提供了数据支持。
1.1 数据集概述
本数据集为职业人群体检数据,包含1112条有效记录,主要字段包括:性别、是否吸烟、是否饮酒、开始从事某工作年份、体检年份、淋巴细胞计数、白细胞计数、血小板计数等。通过对这些体检指标进行统计分析,可以了解职业人群的健康状况分布特征。
1.2 基本统计分析
对数据集中的数值型指标(淋巴细胞计数、白细胞计数、血小板计数)进行了基本统计分析,包括最大值、最小值、求和、均值、方差、标准差等统计量。
统计结果摘要:
- 淋巴细胞计数:均值3.85,标准差60.62,范围0.34-2018.00
- 白细胞计数:均值6.18,标准差12.04,范围1.30-404.00
- 血小板计数:均值202.77,标准差58.93,范围2.90-463.00
1.3 可视化工具选择
本数据集的可视化分析采用了以下三种工具:
- Matplotlib:用于基础图表绘制,如饼图、误差棒图
- Seaborn:用于高级统计图表,如分组柱状图、配对图
- Pyecharts:用于交互式高级图表,如3D散点图
1.4 图形种类
本数据集共生成5种不同类型的可视化图表:
1. Matplotlib饼图 - 性别分布
2. Seaborn分组柱状图 - 不同性别各指标平均值对比(对比分析图)
3. Matplotlib误差棒图 - 不同工作年限分组指标平均值
4. Seaborn配对图 - 多变量关系分析
5. Pyecharts 3D散点图 - 三个体检指标三维关系分析
1.5 数据分析及可视化过程
图1-1:性别分布饼图
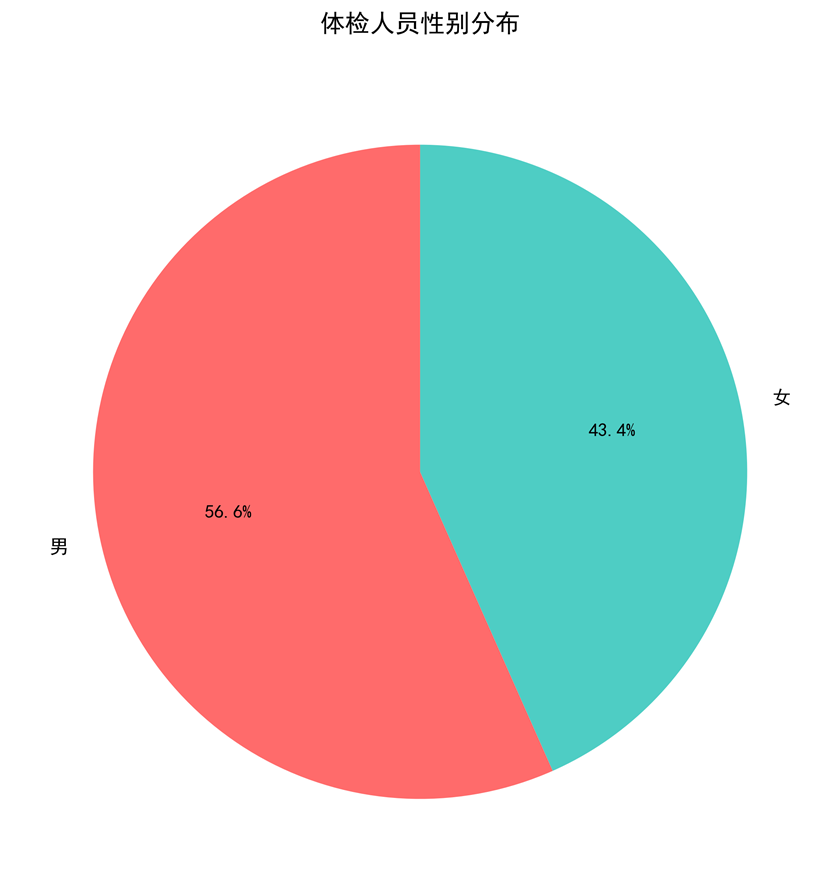
图1-1 性别分布饼图
图表说明: 使用Matplotlib绘制饼图,展示体检人员的性别分布情况。通过饼图可以直观地看出男女比例,为后续的性别对比分析提供基础。
核心代码:
gender_counts = df['性别'].value_counts()
fig, ax = plt.subplots(figsize=(8, 8))
colors = ['#FF6B6B', '#4ECDC4']
wedges, texts, autotexts = ax.pie(gender_counts.values, labels=gender_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90,
textprops={'fontsize': 12, 'fontweight': 'bold'})
ax.set_title('体检人员性别分布', fontsize=16, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart1_pie.png'), dpi=300, bbox_inches='tight')
图1-2:不同性别各指标平均值对比分组柱状图
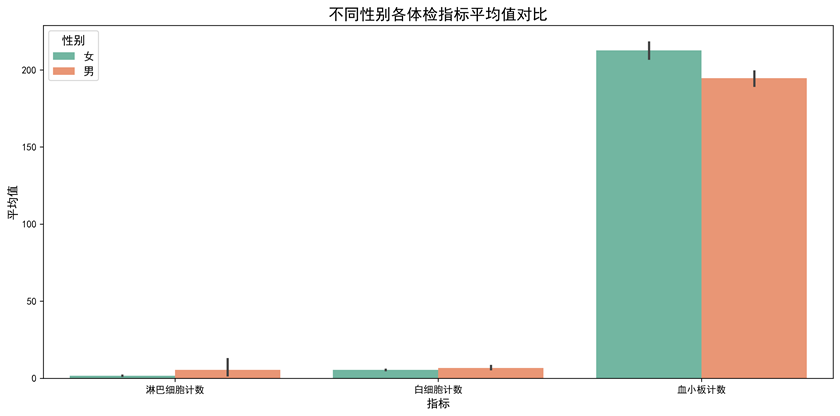
图1-2 不同性别各指标平均值对比
图表说明: 使用Seaborn绘制分组柱状图,对比分析不同性别在三个体检指标(淋巴细胞计数、白细胞计数、血小板计数)上的平均值差异。这是本数据集的对比分析图,通过分组柱状图可以清晰地看出性别对体检指标的影响。
核心代码:
df_melted = df[['性别'] + numeric_cols].melt(id_vars=['性别'],
value_vars=numeric_cols,
var_name='指标',
value_name='数值')
plt.figure(figsize=(12, 6))
sns.barplot(data=df_melted, x='指标', y='数值', hue='性别', palette='Set2')
plt.title('不同性别各体检指标平均值对比', fontsize=16, fontweight='bold')
plt.xlabel('指标', fontsize=12)
plt.ylabel('平均值', fontsize=12)
plt.legend(title='性别', title_fontsize=12, fontsize=11)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart2_grouped_bar.png'), dpi=300, bbox_inches='tight')
图1-3:不同工作年限分组指标平均值误差棒图
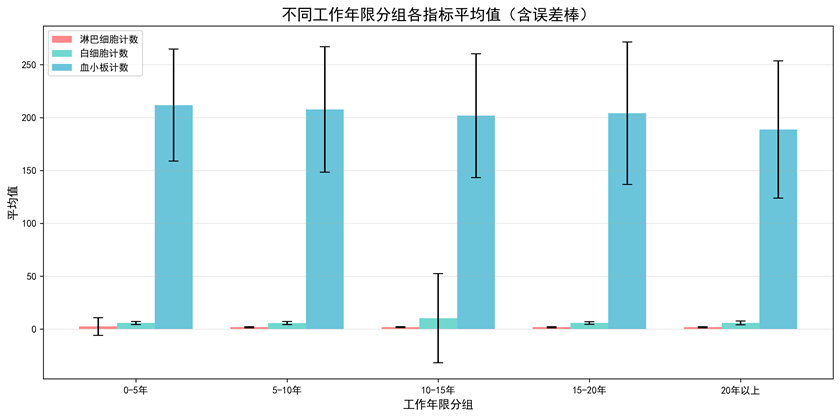
图1-3 不同工作年限分组指标平均值
图表说明: 使用Matplotlib绘制误差棒图,将工作年限分为5个组(0-5年、5-10年、10-15年、15-20年、20年以上),展示不同工作年限分组下各体检指标的平均值及标准差。误差棒显示了数据的离散程度,有助于了解工作年限对健康指标的影响。
核心代码:
df['工作年限分组'] = pd.cut(df['工作年限'], bins=[0, 5, 10, 15, 20, 50],
labels=['0-5年', '5-10年', '10-15年', '15-20年', '20年以上'])
df_work = df[df['工作年限分组'].notna()].copy()
fig, ax = plt.subplots(figsize=(12, 6))
x_pos = np.arange(len(df_work['工作年限分组'].cat.categories))
width = 0.25
for i, col in enumerate(numeric_cols):
means = []
stds = []
for group in df_work['工作年限分组'].cat.categories:
group_data = df_work[df_work['工作年限分组'] == group][col].dropna()
if len(group_data) > 0:
means.append(group_data.mean())
stds.append(group_data.std())
else:
means.append(0)
stds.append(0)
ax.bar(x_pos + i*width, means, width, yerr=stds, label=col,
alpha=0.8, capsize=5, color=['#FF6B6B', '#4ECDC4', '#45B7D1'][i])
ax.set_xlabel('工作年限分组', fontsize=12)
ax.set_ylabel('平均值', fontsize=12)
ax.set_title('不同工作年限分组各指标平均值(含误差棒)', fontsize=16, fontweight='bold')
ax.set_xticks(x_pos + width)
ax.set_xticklabels(df_work['工作年限分组'].cat.categories)
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart3_errorbar.png'), dpi=300, bbox_inches='tight')
图1-4:多变量关系配对图
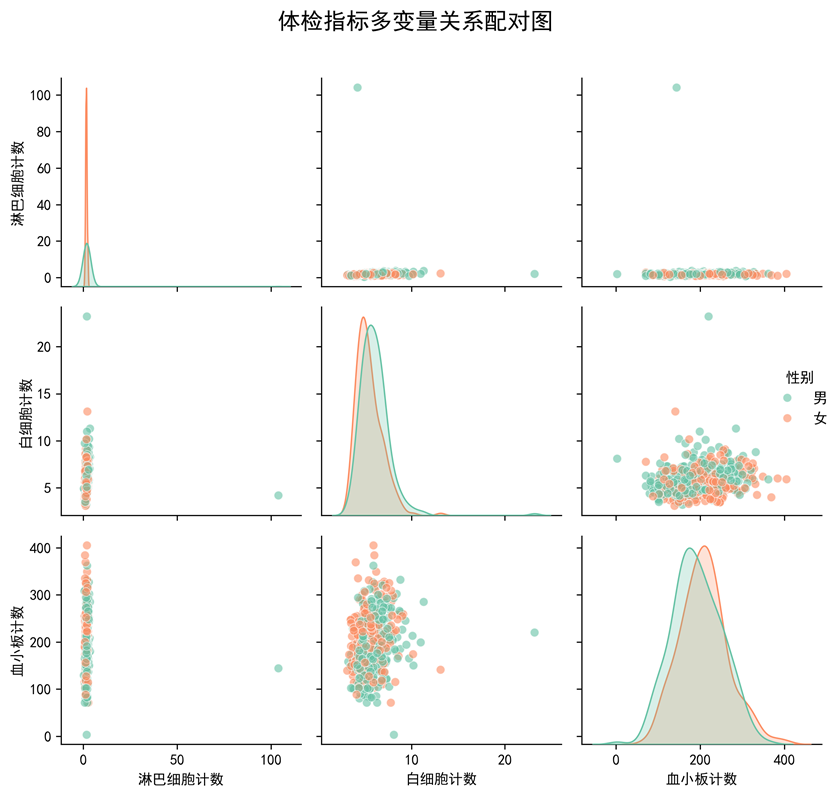
图1-4 多变量关系配对图
图表说明: 使用Seaborn绘制配对图(Pair Plot),展示三个体检指标之间的相关性和分布关系。配对图包含散点图矩阵和对角线上的密度分布图,可以同时观察多个变量之间的两两关系,并按性别进行颜色区分。
核心代码:
df_sample = df[numeric_cols + ['性别']].dropna().sample(min(500, len(df)), random_state=42)
plt.figure(figsize=(12, 10))
sns.pairplot(df_sample[numeric_cols + ['性别']], hue='性别',
palette='Set2', diag_kind='kde', plot_kws={'alpha': 0.6})
plt.suptitle('体检指标多变量关系配对图', fontsize=16, fontweight='bold', y=1.02)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'health_chart4_pairplot.png'), dpi=300, bbox_inches='tight')
图1-5:三个体检指标三维关系3D散点图
图1-5 三个体检指标三维关系3D散点图
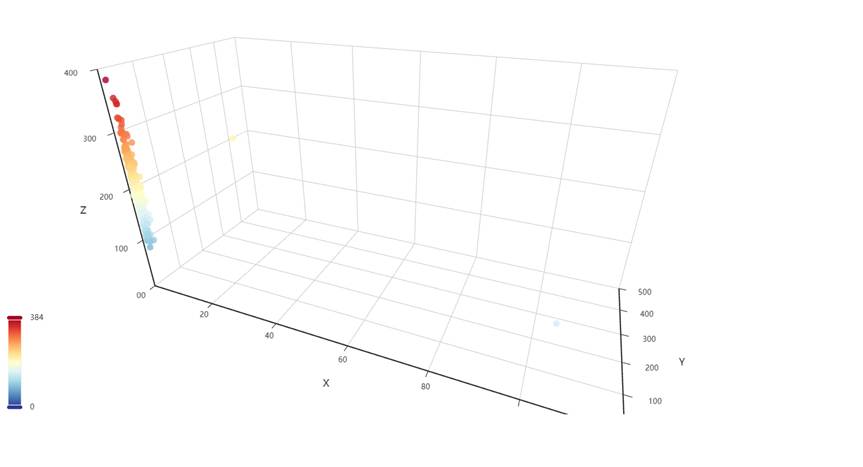
图表说明: 使用Pyecharts绘制3D散点图,这是本数据集的高级图表。将淋巴细胞计数、白细胞计数、血小板计数三个指标分别映射到X、Y、Z三个坐标轴,形成三维空间中的散点分布。图表支持交互式旋转和缩放,可以通过颜色映射观察血小板计数的数值范围,并按性别(男/女)用不同系列区分数据点。3D散点图能够直观地展示三个体检指标之间的三维关系,有助于发现数据中的潜在模式和异常值。
核心代码:
df_3d = df[numeric_cols + ['性别']].dropna().copy()
df_3d_sample = df_3d.head(300)
male_data = df_3d_sample[df_3d_sample['性别'] == '男']
female_data = df_3d_sample[df_3d_sample['性别'] == '女']
scatter3d = (
Scatter3D(init_opts=opts.InitOpts(theme=ThemeType.MACARONS, width="1200px", height="700px"))
.add(
series_name="男性",
data=[
[row['淋巴细胞计数'], row['白细胞计数'], row['血小板计数']]
for _, row in male_data.iterrows()
],
xaxis3d_opts=opts.Axis3DOpts(
name="淋巴细胞计数",
type_="value",
min_=0,
max_=df_3d_sample['淋巴细胞计数'].max() * 1.1
),
yaxis3d_opts=opts.Axis3DOpts(
name="白细胞计数",
type_="value",
min_=0,
max_=df_3d_sample['白细胞计数'].max() * 1.1
),
zaxis3d_opts=opts.Axis3DOpts(
name="血小板计数",
type_="value",
min_=0,
max_=df_3d_sample['血小板计数'].max() * 1.1
),
grid3d_opts=opts.Grid3DOpts(width=100, height=100, depth=100),
)
.add(
series_name="女性",
data=[
[row['淋巴细胞计数'], row['白细胞计数'], row['血小板计数']]
for _, row in female_data.iterrows()
],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="体检指标三维关系分析(3D散点图)", pos_left="center"),
visualmap_opts=opts.VisualMapOpts(
max_=df_3d_sample['血小板计数'].max(),
range_color=[
"#313695", "#4575b4", "#74add1", "#abd9e9", "#e0f3f8",
"#ffffcc", "#fee090", "#fdae61", "#f46d43", "#d73027", "#a50026",
],
),
)
)
scatter3d.render(os.path.join(output_dir, "health_chart5_scatter3d.html"))
1.6 分析总结
通过对职业人群体检数据的分析,我们得出以下主要结论:
- 性别分布:体检人员中男女比例相对均衡,为后续的性别对比分析提供了良好的数据基础。
- 性别差异:通过分组柱状图可以看出,不同性别在体检指标上存在一定差异,这为健康管理提供了性别化的参考依据。
- 工作年限影响:误差棒图显示不同工作年限分组下的体检指标存在差异,工作年限可能对健康状况产生影响。
- 指标相关性:配对图揭示了三个体检指标之间的相关关系,有助于理解各指标之间的内在联系。
- 三维关系:3D散点图提供了三个指标的三维视角,能够发现二维图表难以观察到的数据模式和异常值。
本数据集的分析采用了多种可视化工具和图表类型,从不同角度全面展示了职业人群的体检数据特征,为健康管理和风险评估提供了数据支持。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)