深度学习(鱼书)day11--卷积神经网络(前三节)
本文介绍了卷积神经网络(CNN)的基本结构和工作原理。CNN通过引入卷积层和池化层解决了全连接网络忽视数据空间结构的问题。卷积层使用滤波器进行局部特征提取,保持输入数据的形状,并通过填充和步幅控制输出大小。池化层则通过最大池化等方式缩小空间维度,增强模型对微小变化的鲁棒性。CNN采用4维数据(批处理、通道、高、宽)进行运算,并支持批量处理提高效率。文中详细阐述了卷积运算的计算过程、3维数据处理方法
深度学习(鱼书)day11–卷积神经网络(前三节)
卷积神经网络(Convolutional Neural Network,CNN)。CNN被用于图像识别、语音识别等各种场合。
一、整体结构
CNN和之前介绍的神经网络一样,可以像乐高积木一样通过组装层来构建。不过,CNN中新出现了卷积层(Convolution层)和池化层(Pooling层)。相邻层的所有神经元之间都有连接,这称为全连接(fully-connected)。另外,我们用Affine层实现了全连接层。如果使用这个Affine层,一个5层的全连接的神经网络就可以通过图7-1所示的网络结构来实现。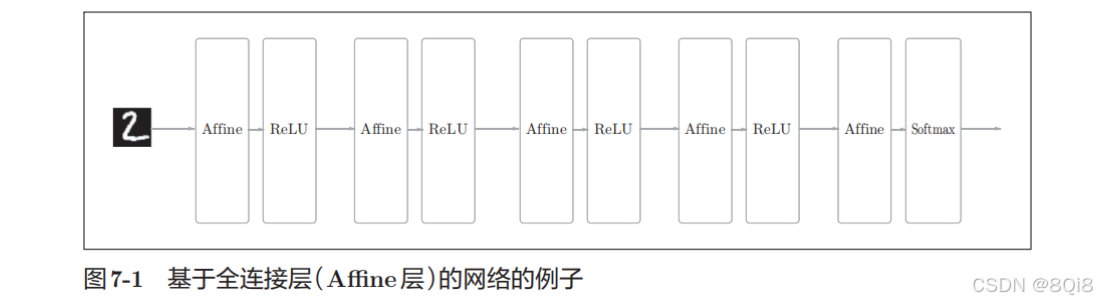
这里堆叠了4层“Affine-ReLU”组合,然后第5层是Affine层,最后由Softmax层输出最终结果(概率)。
CNN的一个例子: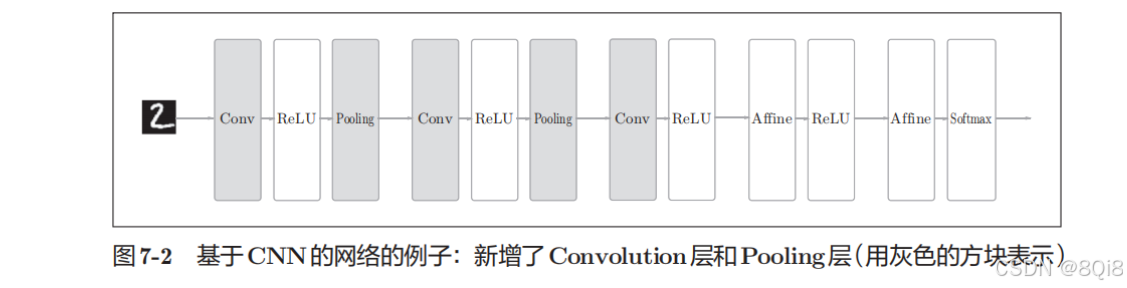
CNN 中新增了 Convolution 层 和 Pooling 层。CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling层有时会被省略)。这可以理解为之前的“Affine - ReLU”连接被替换成了“Convolution - ReLU -(Pooling)”连接。
二、卷积层
-
全连接层存在的问题
全连接层的问题:数据的形状被“忽视”了。 比如,输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。
图像是3维形状,这个形状中应该含有重要的空间信息。比如,空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等,3维形状中可能隐藏有值得提取的本质模式。
而卷积层可以保持形状不变。 当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。
CNN 中,有时将卷积层的输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。
-
卷积运算
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。我们来看一个具体的例子:
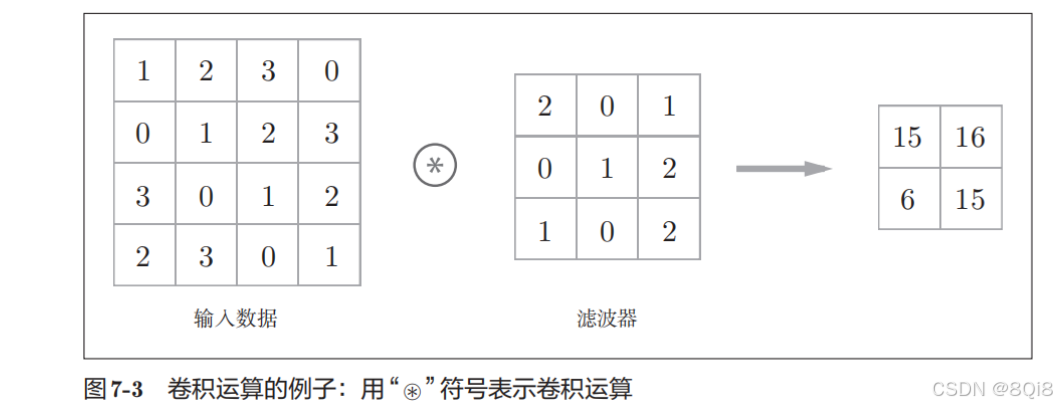
卷积运算对输入数据应用滤波器。假设用(height, width)表示数据和滤波器的形状,则在本例中,输入大小是(4, 4),滤波器大小是(3, 3),输出大小是(2, 2)。另外,有的文献中也会用“核”这个词来表示这里所说的“滤波器”。
运算顺序:
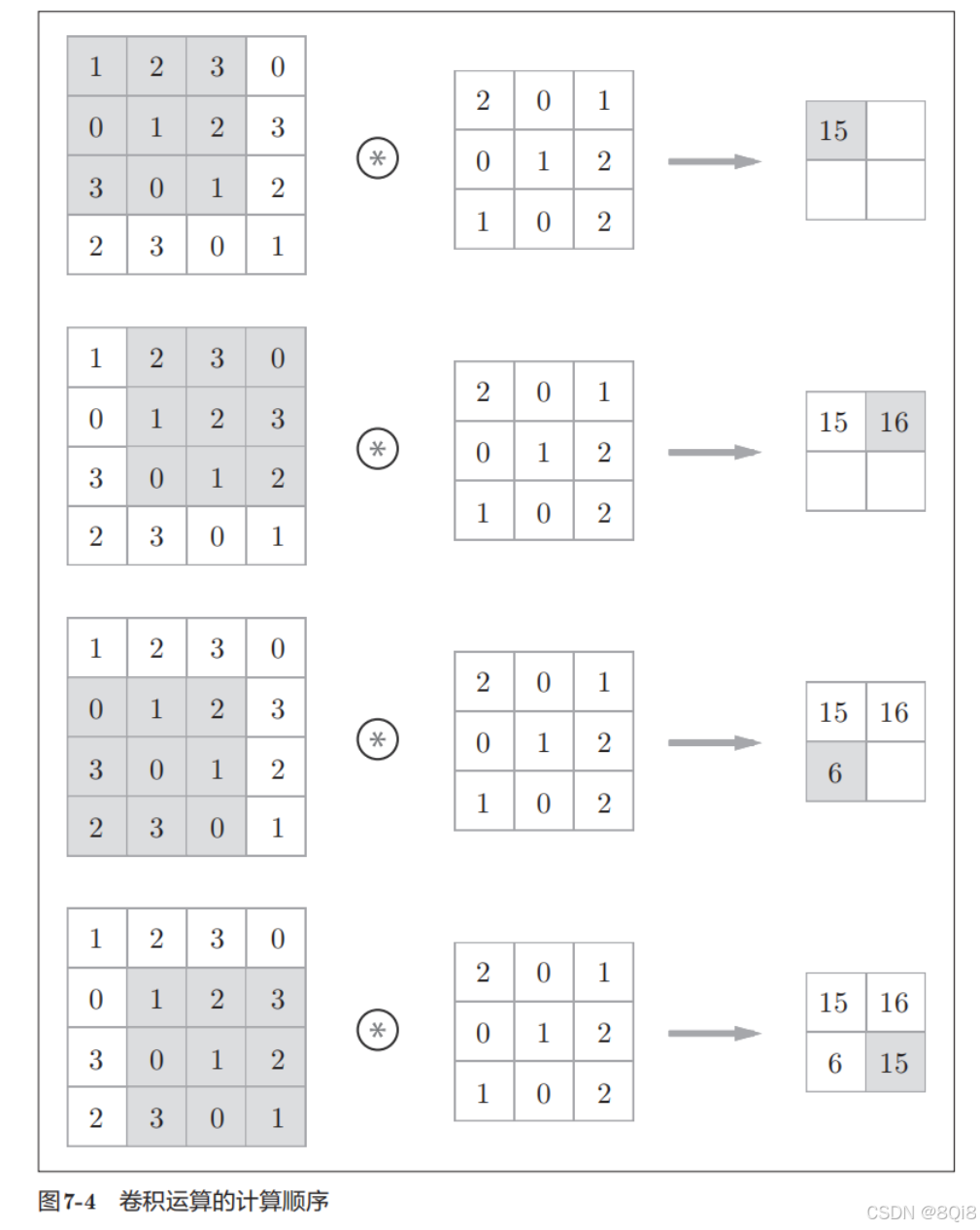
对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用。这里所说的窗口是指图7-4中灰色的3 × 3的部分。如图7-4所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
在全连接的神经网络中,除了权重参数,还存在偏置。CNN中,滤波器的参数就对应之前的权重。CNN中也存在偏置。图7-3的卷积运算的例子一直展示到了应用滤波器的阶段。包含偏置的卷积运算的处理流如图7-5所示。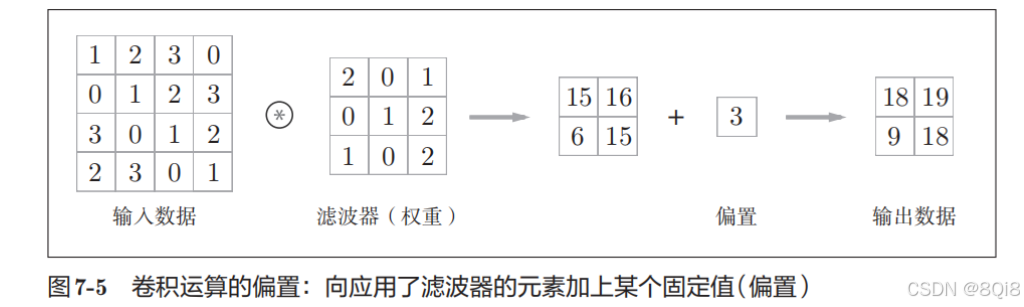
如图7-5所示,向应用了滤波器的数据加上了偏置。偏置通常只有1个(1 × 1),这个值会被加到应用了滤波器的所有元素上。
-
填充
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding),是卷积运算中经常会用到的处理。比如,在图7-6的例子中,对大小为(4, 4)的输入数据应用了幅度为1的填充。“幅度为1的填充”是指用幅度为1像素的0填充周围。
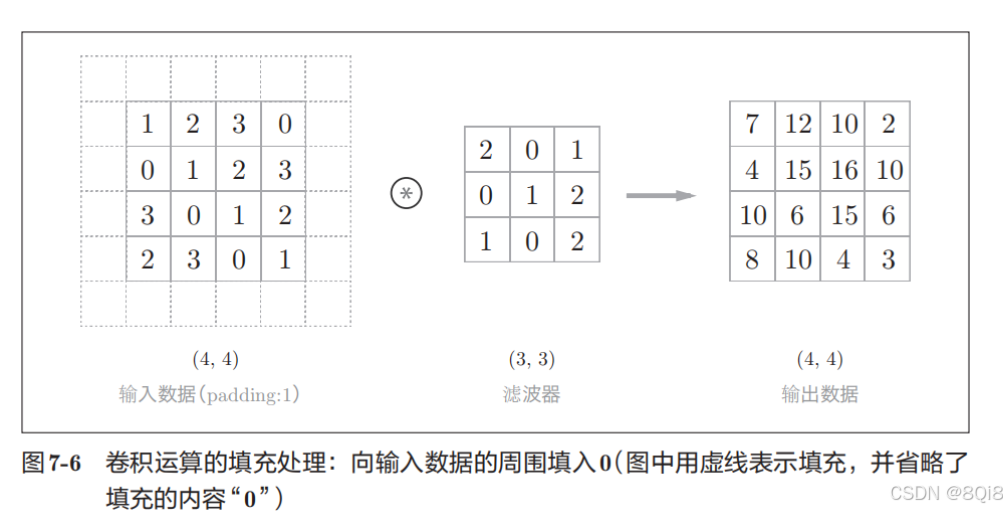
这个例子中将填充设成了1,不过填充的值也可以设置成2、3等任意的整数。
使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网络中会成为问题。因为如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用卷积运算。在刚才的例子中,将填充的幅度设为 1,那么相对于输入大小(4, 4),输出大小也保持为原来的(4, 4)。因此,卷积运算就可以在保持空间大小不变的情况下将数据传给下一层。
-
步幅
应用滤波器的位置间隔称为步幅(stride)。之前的例子中步幅都是1,如果将步幅设为2,则如图7-7所示,应用滤波器的窗口的间隔变为2个元素。
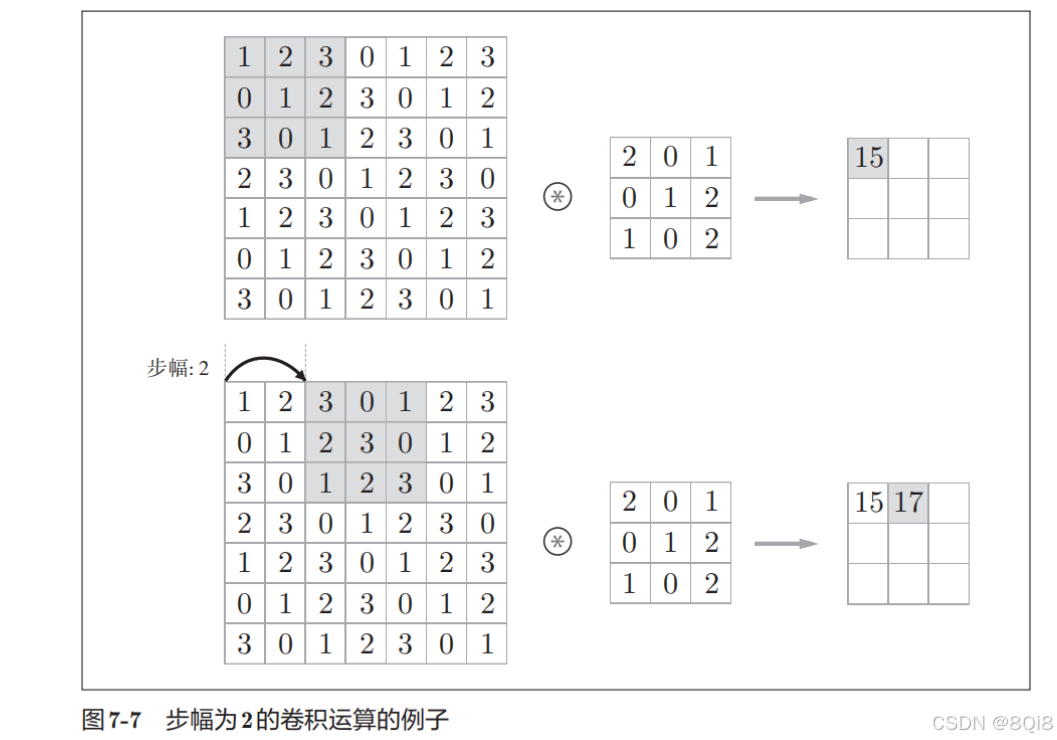
综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。
对于填充和步幅,计算输出大小:
假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S
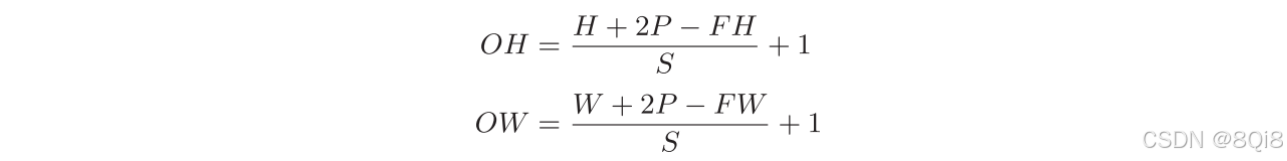
所设定的值必须使式子可以除尽。根据深度学习的框架的不同,当值无法除尽时,有时会向最接近的整数四舍五入,不进行报错而继续运行。
-
3维数据的卷积运算
这里以3通道的数据为例,展示了卷积运算的结果。和2维数据时(图7-3的例子)相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。
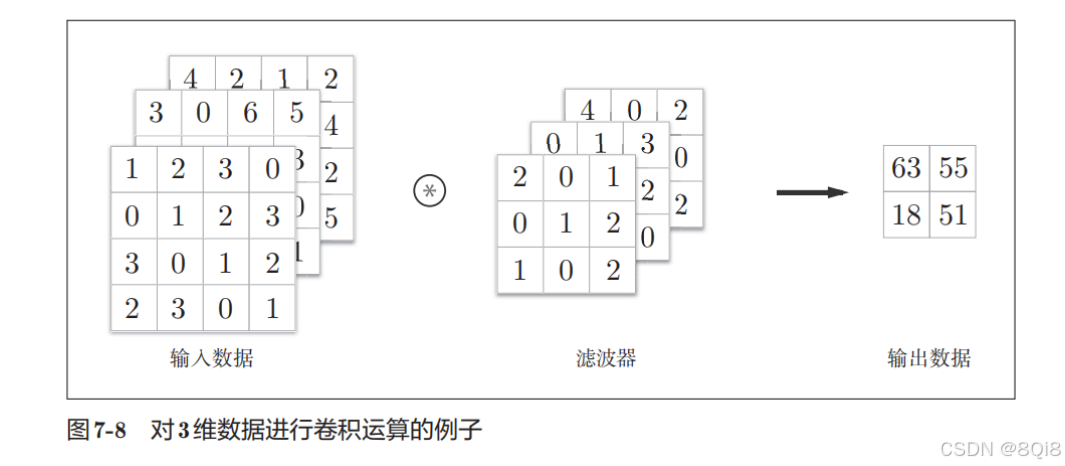
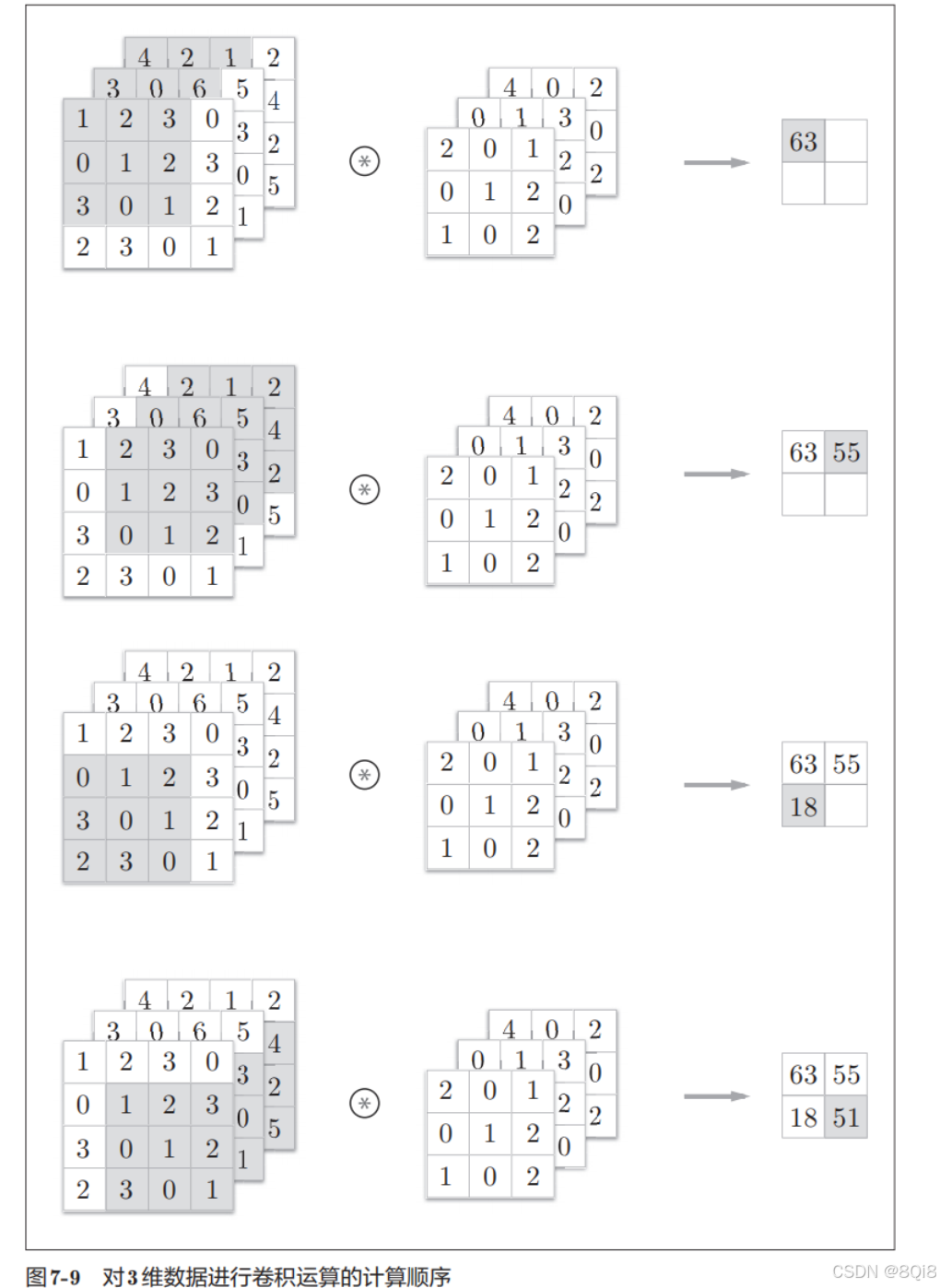
输入数据和滤波器的通道数要设为相同的值。 滤波器大小可以设定为任意值(不过,每个通道的滤波器大小要全部相同)。这个例子中滤波器大小为(3, 3),但也可以设定为(2, 2)、(1, 1)、(5, 5)等任意值。
- 结合方块思考
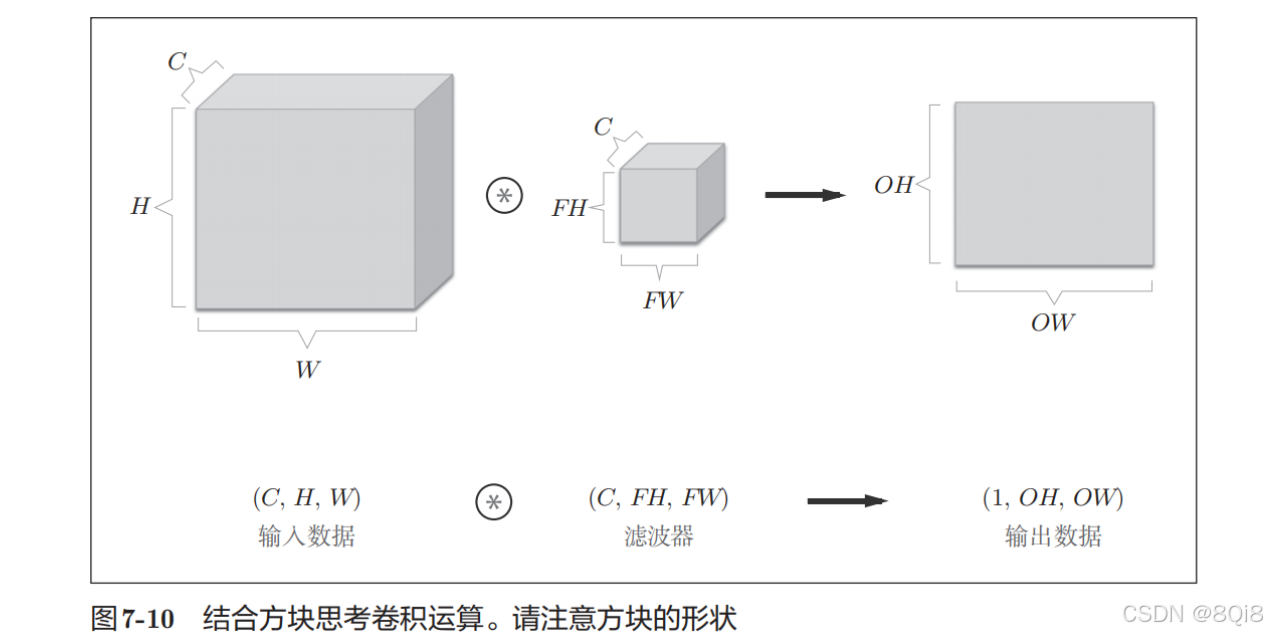
在这个例子中,数据输出是1张特征图。所谓1张特征图,换句话说,就是通道数为1的特征图。
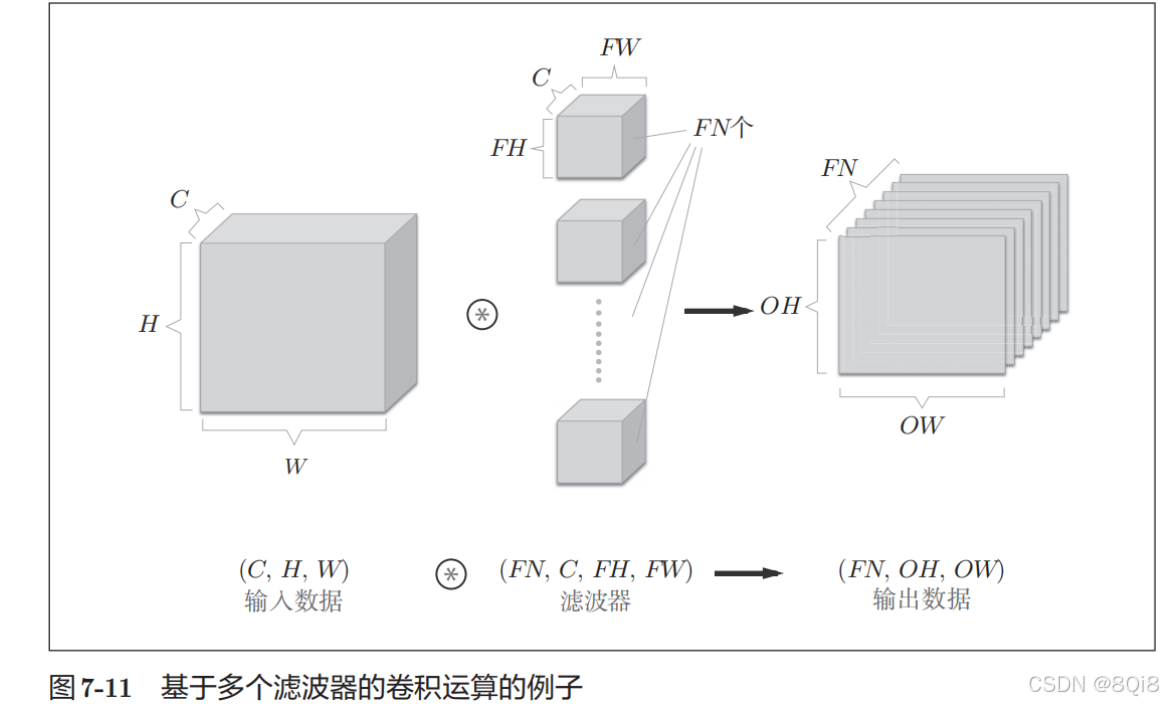
通过应用FN个滤波器,输出特征图也生成了FN个。如果将这FN个特征图汇集在一起,就得到了形状为(FN, OH, OW)的方块。
作为4维数据,滤波器的权重数据要按(output_channel, input_channel, height, width)的顺序书写。比如,通道数为3、大小为5 × 5的滤波器有20个时,可以写成(20, 3, 5, 5)。
卷积运算中(和全连接层一样)存在偏置。在图7-11的例子中,如果进一步追加偏置的加法运算处理,则结果如下面的图7-12所示。图7-12中,每个通道只有一个偏置。这里,偏置的形状是(FN, 1, 1),滤波器的输出结果的形状是(FN, OH, OW)。这两个方块相加时,要对滤波器的输出结果(FN, OH, OW)按通道加上相同的偏置值。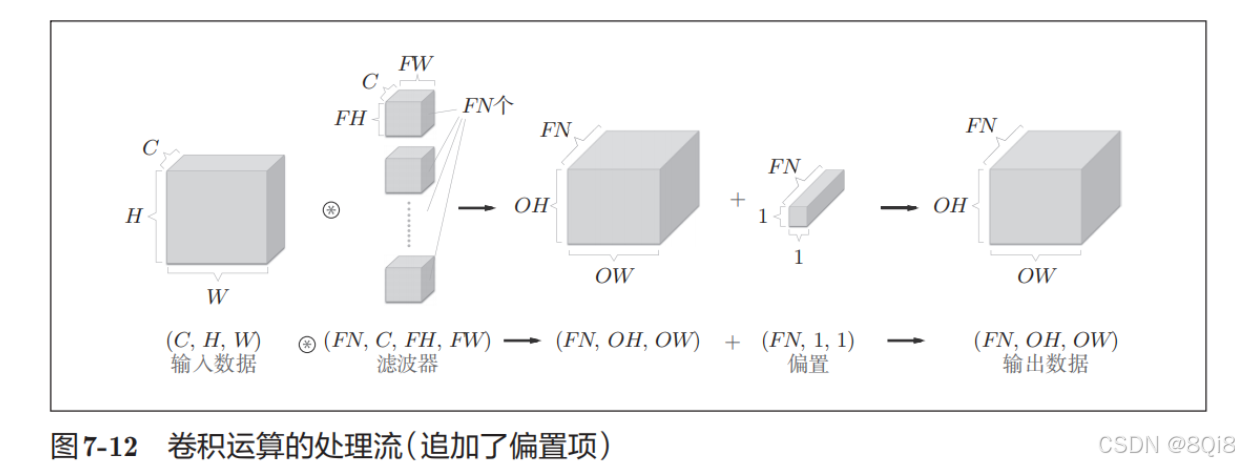
-
批处理
将在各层间传递的数据保存为4维数据。具体地讲,就是按(batch_num, channel, height, width)的顺序保存数据。
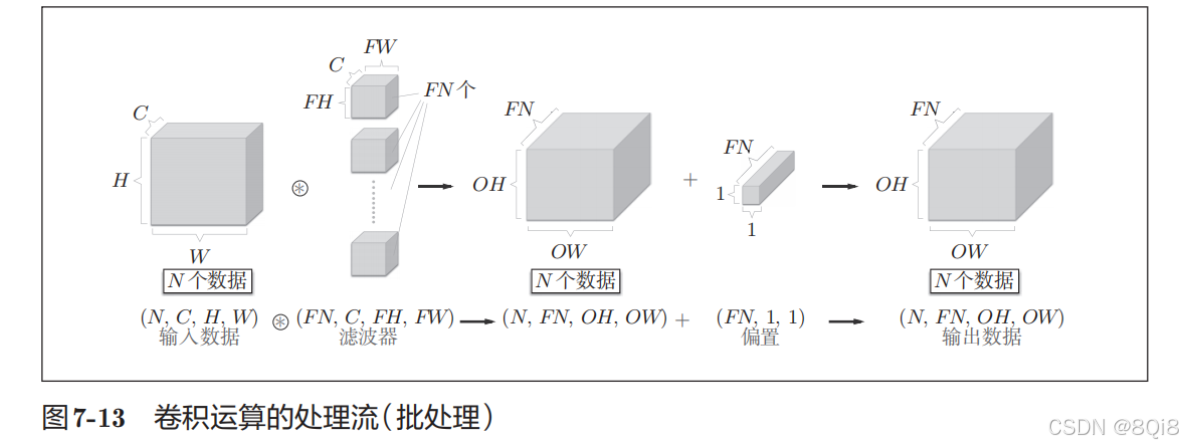
网络间传递的是4维数据,对这N个数据进行了卷积运算。也就是说,批处理将N次的处理汇总成了1次进行。
三、池化层
池化是缩小高、长方向上的空间的运算。比如,如图7-14所示,进行将2 × 2的区域集约成1个元素的处理,缩小空间大小。例子是按步幅2进行2 × 2的Max池化时的处理顺序。“Max池化”是获取最大值的运算,“2 × 2”表示目标区域的大小。
一般来说,池化的窗口大小会和步幅设定成相同的值。
除了Max池化之外,还有Average池化等。相对于Max池化是从目标区域中取出最大值,Average池化则是计算目标区域的平均值。在图像识别领域,主要使用Max池化。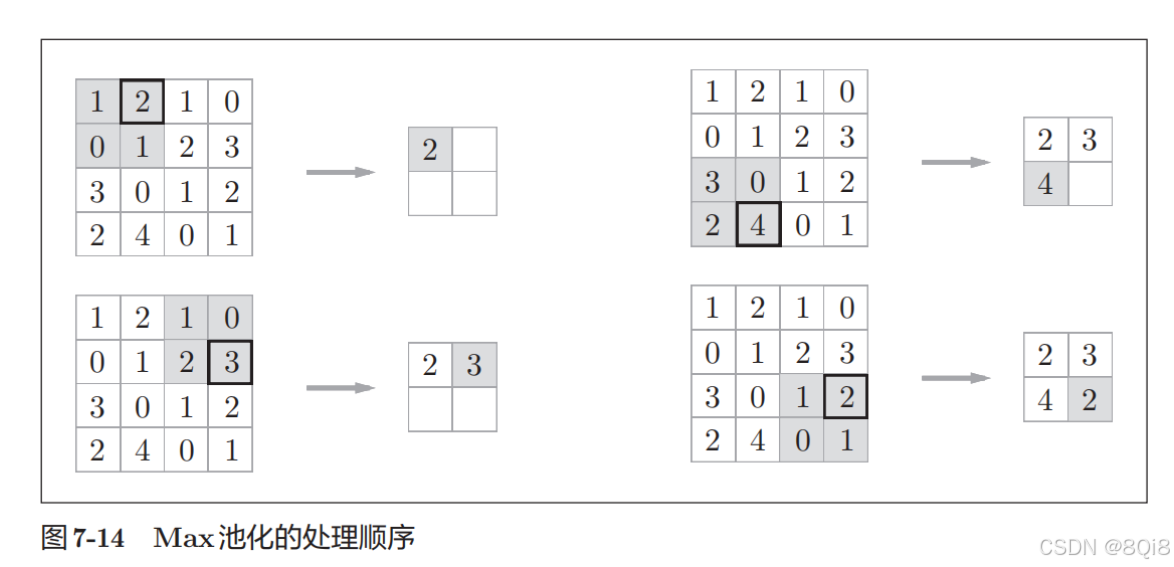
-
池化层的特征
-
没有要学习的参数
-
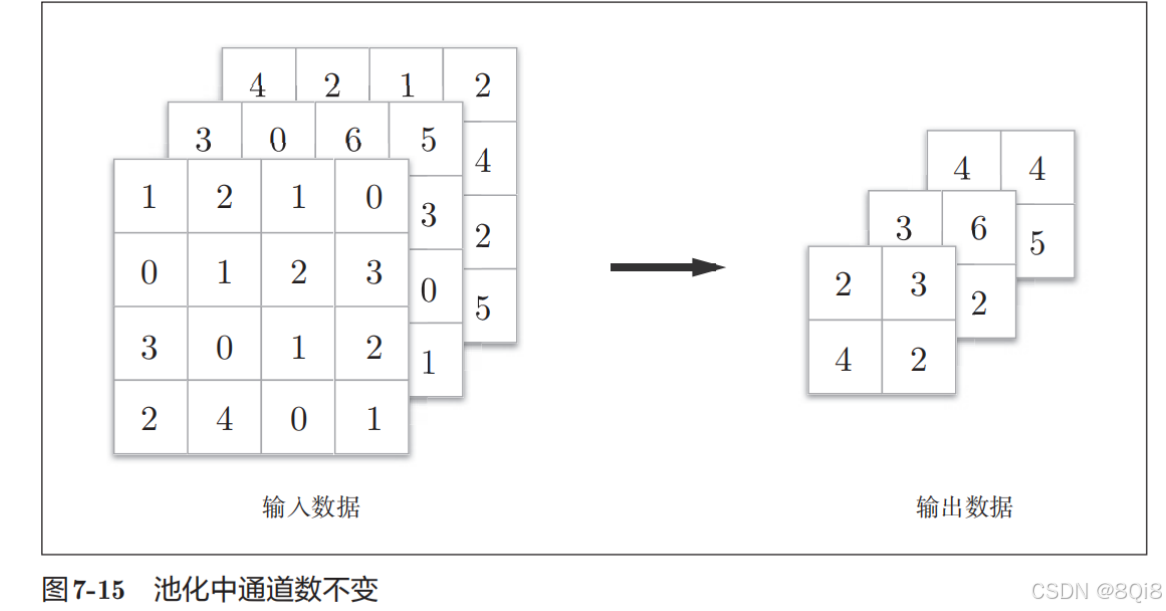
通道数不发生变化
-
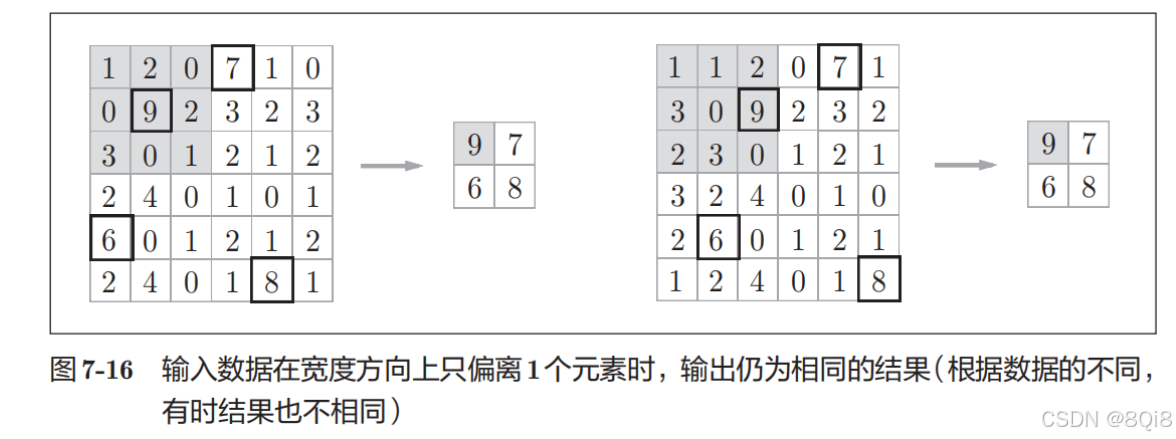
对微小的位置变化具有鲁棒性(健壮):输入数据发生微小偏差时,池化仍会返回相同的结果。
-

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)