【大模型入门】LangChain超详细教程(基础知识 + RAG实战项目 + Agent实战项目)
本文摘要: 本文详细介绍了LangChain框架的安装配置、核心功能及实际应用案例。主要内容包括: LangChain安装与配置 通过pip安装核心包及扩展组件 API密钥环境变量配置方法 系统环境验证步骤 RAG检索增强生成技术 完整工作流程:索引构建→检索→增强→生成 向量数据库原理与应用 本地知识库更新方案(含MD5去重) LangChain核心组件 大语言模型调用(阿里云/本地Ollama
目录
一、安装
1、安装langchain
终端输入以下指令进行安装
pip install langchain langchain-community langchain-ollama dashscope chromadb📦 包说明列表
langchain: 核心包
langchain-community: 社区支持包,提供了更多的第三方模型调用(阿里云千问模型就需要这个包)
langchain-ollama: Ollama支持包,支持调用ollama托管部署的本地模型
dashscope: 阿里云通义千问的Python SDK
chromadb: 轻量向量数据库(后续使用)
安装后输入python进入编译器环境,再输入import langchain,如果没有报错,说明langchain 1.2.1版本安装成功

2、配置API_KEY
我用的是mac,下面演示mac系统如何配置环境变量。
终端输入下面指令
# 1. 打开配置文件 nano ~/.zshrc # 2. 在文件末尾添加 export OPENAI_API_KEY="你的API密钥" export DASHSCOPE_API_KEY="你的API密钥" # 3. 保存并退出(Ctrl+X → Y → Enter) # 4. 重新加载配置 source ~/.zshrc验证配置:
echo $DASHSCOPE_API_KEY$ echo $OPENAI_API_KEY注意:环境变量需要重启pycharm才会生效。
二、RAG 检索增强生成
1、什么是RAG?
RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。
- 当大模型需要回答问题时,不是仅依赖自身训练时学到的知识,而是实时从外部知识库中检索相关文档,然后将检索到的信息与大模型的知识结合,生成更准确、更实时的答案。
- 简单来说,RAG就像是给大模型配备了一个【实时知识助手】——当模型遇到不知道或不确定的问题时,会先去查资料,再基于查到的资料来回答。
(1)核心步骤
1. 数据预处理与索引构建(Indexing)【离线阶段】
发生在用户提问之前,目的是将海量的非结构化文档(如PDF、Word、网页等)转化为机器可以快速检索的结构化数据。
加载:从指定路径(本地或网络)读取文档。
切分:将长文档切割成语义连贯的短文本片段。这是关键步骤,因为大模型有上下文长度限制,且过长的文本会稀释关键信息。
向量化:使用嵌入模型将文本片段转换为高维向量。语义相似的文本在向量空间中距离更近。
存储:将向量存入向量数据库(如Chroma等),建立索引。
2. 检索(Retrieval)
当用户提出问题时,系统从知识库中寻找最相关的信息。
查询向量化:将用户的自然语言问题转换为向量。
相似性搜索:在向量数据库中搜索与问题向量最相似的Top-K个文本片段。
重排序:有时会使用更精细的模型对检索结果进行二次排序,确保最相关的信息排在最前面。
3. 增强(Augmentation)
将检索到的外部知识与用户的原始问题进行整合,形成最终的提示词(Prompt)。
上下文构建:将检索到的Top-K个文本片段拼接起来,作为上下文。
提示词工程:设计一个包含指令、上下文和问题的模板。例如:
“请基于以下参考信息回答问题。如果参考信息不足以回答问题,请说明你不知道。\n\n参考信息:{Retrieved Context}\n\n问题:{User Query}”
4. 生成(Generation)
将构建好的提示词发送给大语言模型,生成最终答案。
LLM推理:大模型基于提示词中的指令和上下文进行推理。
输出:生成自然语言答案,并通常要求附带引用来源,方便用户追溯答案的出处。
(2)核心价值
- 解决知识实效性问题:大模型的训练数据有截止时间,RAG可以接入最新文档,让模型输出与时俱进。
- 降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
- 无需重新训练模型:相比微调,RAG只需更新知识库,成本更低、效率更高。
2、向量
向量就是文本的【数学身份证它把一段文字的语义信息】,转换成一串固定长度的数字列表,让计算机能看懂文字的含义并做相似度计算。
- 向量的余弦相似度越大,说明向量方向越接近,两点之间的距离越小
- 向量的维度表示一段文本在多个抽象语义特征方面的强度
- 维度数代表模型用多少个抽象语义特征来描述文本
- 维度越多,做语义匹配越精准
- 但性能压力也会增大

3、Langchain组件
(1)调用大语言模型
【1】阿里云服务调用
from langchain_community.llms.tongyi import Tongyi model = Tongyi(model="qwen-max") res = model.invoke(input="椰奶面包好吃吗?") print(res)【2】本地ollama调用
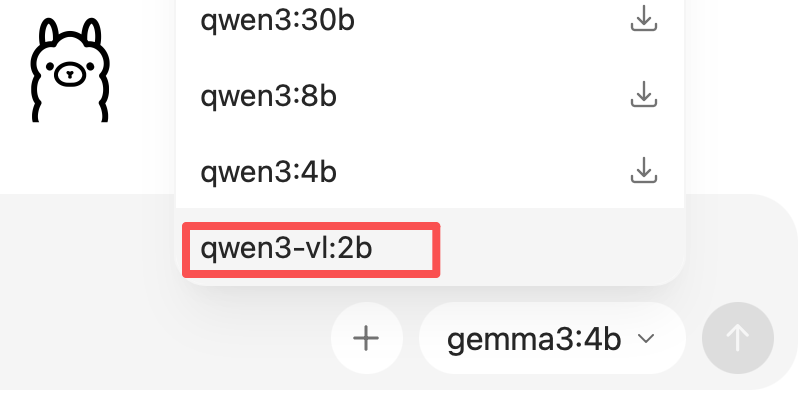
from langchain_ollama import OllamaLLM model = OllamaLLM(model="qwen3-vl:2b") res = model.invoke(input="蛋挞好吃吗?") print(res)注意这里调用的模型,要提前在ollma下载好
(2)流式调用
- invoke方法:一次型返回完整结果
- stream方法:逐段返回结果,流式输出
from langchain_community.llms.tongyi import Tongyi model = Tongyi(model="qwen-max") res = model.stream(input="椰奶面包好吃吗?") for chunk in res: print(chunk,end="",flush=True) # flush=True:立即刷新输出缓冲区,让内容立即显示from langchain_ollama import OllamaLLM model = OllamaLLM(model="qwen3-vl:2b") res = model.stream(input="椰奶面包好吃吗?") for chunk in res: print(chunk,end="",flush=True) # flush=True:立即刷新输出缓冲区,让内容立即显示
(3)调用聊天模型
聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
AIMessage:就是 AI 输出的消息,可以是针对问题的回答。【OpenAI库中的 assistant 角色】
HumanMessage:由用户给出的信息发送给 LLMs 的提示信息。【OpenAI库中的 user 角色】
SystemMessage:可以用于指定模型具体所处的环境和背景,如角色扮演等。可以在这里给出具体的指示,比如“作为游戏策划师”。【OpenAI库中的 system 角色】
【1】静态形式:一步到位,直接得到Message类的类对象
from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.messages import SystemMessage, HumanMessage, AIMessage chat = ChatTongyi(model="qwen3-max") messages = [ SystemMessage(content="你是王者荣耀的游戏策划师"), HumanMessage(content="给朵莉亚设计一个新系列皮肤"), AIMessage(content="风格大概是迪士尼公主系列"), HumanMessage(content="根据上面的风格进行设计") ] # 流式输出 for chunk in chat.stream(messages): print(chunk.content, end="", flush=True) # flush=True:立即刷新输出缓冲区,让内容立即显示【2】动态形式:需要在运行时,由LangChain内部机制转换为Message类对象
from langchain_community.chat_models.tongyi import ChatTongyi chat = ChatTongyi(model="qwen3-max") messages = [ ("system","你是王者荣耀的游戏策划师"), ("human","给朵莉亚设计一个新系列皮肤"), ("ai","风格大概是迪士尼公主系列"), ("human","根据上面的风格进行设计") ] # 流式输出 for chunk in chat.stream(messages): print(chunk.content, end="", flush=True) # flush=True:立即刷新输出缓冲区,让内容立即显示由于是动态,需要转换步骤所以简写形式支持内部填充{变量}占位可在运行时填充具体值(后续学习提示词模板时用到)

(4)调用嵌入模型
【1】阿里云服务调用
from langchain_community.embeddings import DashScopeEmbeddings # 默认text-embeddings-v1 model = DashScopeEmbeddings() print(model.embed_query("朵莉亚")) print(model.embed_documents(["朵莉亚","瑶","少司缘"]))【2】本地ollama调用
首先在ollama中下载嵌入模型
在终端输入指令,下载嵌入模型
ollama pull qwen3-embedding:0.6bfrom langchain_ollama import OllamaEmbeddings # 默认text-embeddings-v1 model = OllamaEmbeddings(model="qwen3-embedding:0.6b") print(model.embed_query("朵莉亚")) print(model.embed_documents(["朵莉亚","瑶","少司缘"]))
方式
LLMs大语言模型
聊天模型
文本嵌入模型
阿里云千问
from langchain_community.llms.tongyi import Tongyi
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddingsOllama本地模型
from langchain_ollama import OllamaLLM
from langchain_ollama import ChatOllama
from langchain_ollama import OllamaEmbeddings方法
invoke(批量)
stream(流式)
invoke(批量)
stream(流式)
embed_query(单次转换)embed_documents(批量转换)
(5)提示词模板
提示词模板的核心作用:
- 将用户输入、上下文信息和系统指令标准化格式化,确保每次调用模型时提示词结构一致
- 避免硬编码,使用占位符(如 {variable})动态注入内容
- 创建可复用的模板,便于批量修改和版本管理。
- 通过结构化提示引导模型完成特定任务(如分类、总结、翻译等)。
- 整合历史对话、外部知识和当前查询。
区别
format
invoke
功能
纯字符串替换,解析占位符生成提示词
Runnable 接口标准方法,解析占位符生成提示词
返回值
字符串
PromptValue 类对象
传参
.format(k=v, k=v, ...)
.invoke({"k": v, "k": v, ...})解析
支持解析
{}占位符支持解析
{}占位符和MessagesPlaceholder结构化占位符【1】PromptTemplate
通用提示词模板,支持动态注入信息
from langchain_core.prompts import PromptTemplate from langchain_community.llms.tongyi import Tongyi prompt_template = PromptTemplate.from_template( "我的邻居姓{lastname},刚生了{gender},帮我取个名字,简单回答。" ) model = Tongyi(model="qwen-max") chain = prompt_template | model res = chain.invoke(input={"lastname":"李","gender":"女儿"}) print(res)【2】FewShotPromptTemplate
支持基于模板注入任意数量的示例信息
FewShotPromptTemplate类对象构建的5个核心参数:
example_prompt:示例数据的提示词模板。
examples:示例数据,类型为list,list内套字典。
prefix:示例数据前的内容。
suffix:示例数据后的内容。
input_variables:列表类型,指定需要在prefix或suffix中注入的变量名称列表。
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate from langchain_community.llms.tongyi import Tongyi # 示例的模板 example_template = PromptTemplate.from_template("单词: {word}, 反义词: {antonym}") # 示例的动态数据注入 要求是list内部套字典 examples_data = [ {"word": "大", "antonym": "小"}, {"word": "上", "antonym": "下"} ] # 创建少样本提示模板 fewShotTemplate = FewShotPromptTemplate( example_prompt=example_template, # 示例数据的模板 examples=examples_data, # 示例的数据(用来注入动态数据的),list内套字典 prefix="告知我单词的反义词,我提供如下的示例:", # 示例之前的提示词 suffix="基于前面的示例告知我,{input_word}的反义词是?", # 示例之后的提示词 input_variables=['input_word'] # 声明在前缀或后缀中所需要注入的变量名 ) # 调用模板并传入输入参数 result = fewShotTemplate.invoke(input={"input_word": "左"}).to_string() print(result) model = Tongyi(model="qwen-max") print(model.invoke(input=result))【3】ChatPromptTemplate
支持注入任意数量的历史会话信息
from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder # 创建聊天提示模板 chat_prompt_template = ChatPromptTemplate.from_messages( [ ("system", "你是一个边塞诗人,可以作诗。"), # 系统角色设定 MessagesPlaceholder("history"), # 历史对话占位符 ("human", "请再来一首唐诗"), # 用户当前请求 ] ) # 历史对话数据 history_data = [ ("human", "你来写一个唐诗"), ("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"), ("human", "好诗再来一个"), ("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"), ] # 将历史数据注入提示模板并转换为字符串 prompt_text = chat_prompt_template.invoke({"history": history_data}).to_string() # 创建聊天模型 model = ChatTongyi(model="qwen3-max") # 调用模型生成回复 res = model.invoke(prompt_text) # 打印结果 print(res.content)
4、Chain的使用
(1)什么是Chain链?
【将组件串联,上一个组件的输出作为下一个组件的输入】是 Langchain 链的核心工作原理
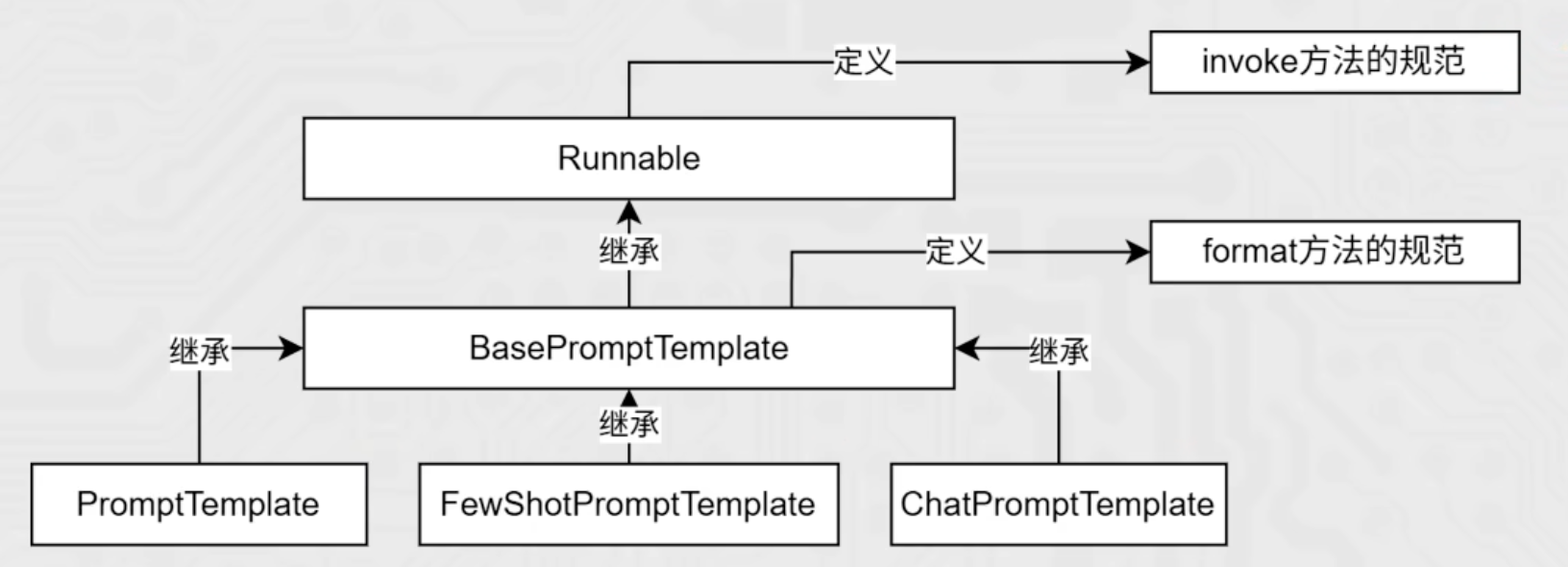
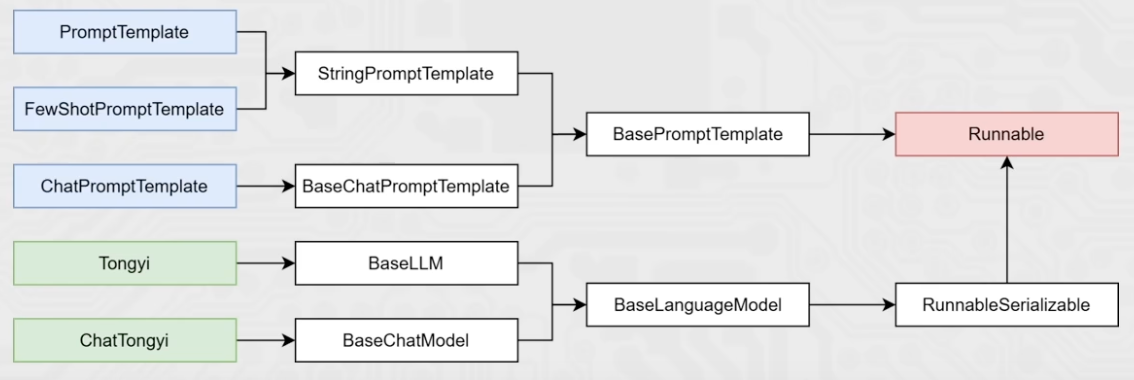
chain = prompt_template | model | mode2 | mode3Runnable子类对象才能入链。目前所学习到的组件,均是Runnale接口的子类,如下类的继承关系:
- LangChain中链是一种将各个组件串联在一起,按顺序执行,前一个组件的输出作为下一个组件的输入。
- 可以通过 “|” 符号来让各个组件形成链
- 成链的各个组件,需是Runnable接口的子类
- 形成的链是RunnableSerializable子类(RunnableSequence类型)
- 可通过链调用 invoke 或 stream 触发整个链条的执行
(2)或运算符 | 的重写
Chain链支持
a | b | c | d这种任意长度的链式组合【1】为什么能实现这种无限连接?
- a | b执行时,a.__or__(b)返回一个新的Chain对象
- 这个新对象本身也带有 __or__方法
- 所以 (a | b) | c可以继续执行,依此类推
- 也就是说,LangChain通过或运算符重载,实现任意长度的链式组合
【2】底层逻辑:或运算符重载如何实现?
Test 类 - 基础示例
class Test(object): """ Test类:基础组件类,模拟LangChain中的Prompt、Model等组件 """ def __init__(self, name): self.name = name # 将传入的name参数保存为实例属性 def __str__(self): """ 重写__str__方法:定义对象的字符串表示形式 当使用print()或str()时调用此方法 示例:print(a) 将输出 "a" 而不是默认的内存地址 """ return self.name def __or__(self, other): """ 重写__or__方法:定义管道运算符 | 的行为 当执行 a | b 时,Python会自动调用 a.__or__(b) 示例: a = Test("a"); b = Test("b") result = a | b # 调用a.__or__(b) # result现在是MySequence对象,包含[a, b] 这模仿了LangChain中:prompt | model 的链式组合 """ return MySequence(self, other) # 创建并返回MySequence对象MySequence 类 - 序列组合器
class MySequence(object): """ MySequence类:序列组合器 作用:收集通过 | 管道运算符连接的多个组件,并支持执行 类比:类似LangChain中的RunnableSequence,是工作流的容器 """ def __init__(self, *args): """ 初始化方法 - 支持可变参数 *args: 可变数量的位置参数,可以接收任意数量的组件 """ self.sequence = [] # 初始化空列表,用于存储所有组件 for arg in args: # 遍历传入的所有参数 self.sequence.append(arg) # 将每个参数添加到序列列表中 def __or__(self, other): """ 重写__or__方法:定义MySequence对象的 | 运算符行为 关键区别(与Test类的__or__对比): - Test.__or__:转换模式(返回新对象) - MySequence.__or__:累积模式(修改自身并返回self) 示例: seq = MySequence(a, b) # sequence = [a, b] seq = seq | c # 调用seq.__or__(c) # 1. seq.sequence.append(c) → sequence变为[a, b, c] # 2. return self → 返回同一个seq对象 """ self.sequence.append(other) # 将新组件追加到现有序列 return self # 返回自身,支持连续链式调用 def run(self): """ 执行方法:按顺序处理序列中的所有组件 功能:遍历self.sequence列表,对每个组件执行操作 当前实现:简单地打印每个组件(通过__str__方法) """ for arg in self.sequence: # 遍历序列中的每个组件 print(arg) # 打印组件(调用组件的__str__方法)测试类
if __name__ == "__main__": a = Test("a") b = Test("b") c = Test("c") d = a | b | c d.run() print(type(d))运行结果
a b c <class '__main__.MySequence'>运行流程
a | b | c → 触发三次__or__调用 → 最终得到MySequence对象 → 执行run()方法 ↓ ↓ ↓ ↓ Test("a") → Test.__or__(b) → MySequence([a,b]) → 追加c → MySequence([a,b,c]) → 遍历打印上述代码展示了运算符重载如何实现链式API设计,这正是LangChain等框架底层的工作原理。
【3】与LangChain对比
特性
示例代码
LangChain实现
管道运算符
|
|
返回类型
MySequence对象
RunnableSequence对象
执行方式
调用
.run()调用
.invoke()/.run()
(3)Runnable接口
Runnable是 LangChain 绝大多数核心组件继承的抽象基类,位于 langchain_core.runnables中。
Runnable通过重写 __or__方法,使得用户能用简洁的 |语法将任意组件无缝组合成顺序执行的 RunnableSequence链,这是 LangChain 链的核心机制。
在 LangChain 中,可以使用管道操作符(
|)来连接不同组件,形成链式调用,例如:chain = prompt | model。底层原理:
Runnable基类重写了魔术方法__or__。当使用|时,实际上是在调用这个特殊方法。
通过
|连接两个Runnable对象后,得到的chain变量类型是RunnableSequence(它是RunnableSerializable的一个子类)。无论后续用
|继续添加多少个新组件,得到的永远是一个RunnableSequence。这就是构成 LangChain 链的基础架构。
(4)输出解析器
【1】StrOutputParser
❗️ 经典错误:想要实现多轮对话,用第一次模型生成的名字作为输入,第二次再问模型相关问题
chain = prompt | model | model
- 本意想实现的流程是:
- prompt 接收用户输入,生成一个完整的问题(如“我邻居姓张,刚生了女儿,请起名”)。
- 第一个 model 接收这个问题,并输出一个名字(比如“张丽丽”)。
- 第二个 model 接收这个名字,进行后续处理。
- 但实际上,LangChain 是这样执行的:
- prompt接收 {"lastname": "张", "gender": "女儿"},输出一个文本字符串。
- 第一个 model 接收这个文本字符串,进行思考,然后输出一个 AIMessage对象(这是LangChain中封装模型响应的标准对象)。
- 第二个 model 试图接收这个 AIMessage对象,但它不认识。它期望接收的是文本字符串或 PromptValue(如提示词模板的输出)。所以它报错了:
- ValueError: Invalid input type <class 'AIMessage'>. Must be a PromptValue, str, or list of ...
- 简单说:链在第一步和第二步之间的数据类型不匹配。喂给第二个模型的是【模型的聊天记录】,而不是【文本问题】。
💡 解决方法
StrOutputParser是LangChain内置的简单字符串解析器
可以将AIMessage解析为简单的字符串,符合了模型invoke方法要求(可传入字符串,不接收AIMessage类型)
是Runnable接口的子类(可以加入链)
parser = StrOutputParser() # 1. 创建这个解析器 chain = prompt | model | parser | model # 2. 把它插在两个模型中间

【2】JsonOutputParser
上面我们构建的多模型链,但这种方法并不标准。比如第一个模型生成的答案【张丽丽】,通过StrOutputParser转换为字符串给下一个模型,但是并没有携带提示词,下一个模型就会一头雾水不知道要回答什么。
标准处理流程如下:
初始输入 → 提示词模板 → 模型 → 数据处理 → 提示词模板 → 模型 → 解析器 → 结果
- 上一个模型的输出结果,应该作为提示词模版的输入,构建下一个提示词,用来二次调用模型。
- 提示词模板的输入要求是:dict 字典类型
- 将模型输出的AIMessage → 转为字典dict → 注入第二个提示词模板中,形成新的提示词(PromptValue对象)
- StrOutputParser不满足(AIMessage → Str)
- 更换Json0utputParser(AIMessage → Dict(JSON))
from langchain_core.output_parsers import StrOutputParser from langchain_core.output_parsers import JsonOutputParser from langchain_core.prompts import PromptTemplate from langchain_community.chat_models.tongyi import ChatTongyi str_parser = StrOutputParser() # 用于提取最终纯文本 json_parser = JsonOutputParser() # 用于解析JSON格式的模型输出 model = ChatTongyi(model="qwen3-max") first_prompt = PromptTemplate.from_template( "我邻居姓:{lastname},刚生了{gender},请起名,并封装到JSON格式返回给我," "要求key是name,value就是起的名字。请严格遵守格式要求" ) second_prompt = PromptTemplate.from_template( "姓名{name},请帮我解析含义。" ) chain = first_prompt | model | json_parser | second_prompt | model | str_parser res: str = chain.invoke({"lastname": "张", "gender": "女儿"}) print(res) print(type(res))用户输入 ↓ [first_prompt] → 拼接出完整请求(如:“我邻居姓:张,刚生了女儿,请起名...”) ↓ [model] → 生成JSON格式的回复(如:`{"name": "张婉儿"}`) ↓ [json_parser] → 解析JSON,提取出值 `"张婉儿"` ↓ [second_prompt] → 拼接出新请求(“姓名张婉儿,请帮我解析含义。”) ↓ [model] → 生成对名字含义的解析(AIMessage对象) ↓ [str_parser] → 提取出纯文本回复 ↓ 最终结果 (res: str)
【3】多模型链 输入与输出要求
模型
- 输入:PromptValue / 字符串 / 序列(BaseMessage、list、tuple、str、dict)。
- 输出:AIMessage
提示词模板
- 输入:字典dict
- 输出:PromptValue对象
StrOutputParser
- 输入:AIMessage
- 输出:str
JsonOutputParser
- 输入:AIMessage
- 输出:dict
【4】自定义输出解析器
当
StrOutputParser和JsonOutputParser不够用时,可以用RunnableLambda这个万用接口,打造一个完全符合需求的工具。RunnableLambda类是Langchain内置的,将普通函数等转换为Runnable接口实例,方便自定义函数加入chain。
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.runnables import RunnableLambda model = ChatTongyi(model="qwen3-max") str_parser = StrOutputParser() first_prompt = PromptTemplate.from_template( "我邻居姓:{lastname},刚生了{gender},请帮忙起名字,仅告知我名字,不要额外信息。" ) second_prompt = PromptTemplate.from_template( "姓名{name},请帮我解析含义。" ) # 自定义处理函数:将AIMessage转换为字典格式 # 入参:AIMessage -> 输出:dict({"name": "xxx"}) my_func = RunnableLambda(lambda ai_msg: {"name": ai_msg.content}) chain = first_prompt | model | my_func | second_prompt | model | str_parser for chunk in chain.stream({"lastname": "张", "gender": "女孩"}): print(chunk, end="", flush=True)如果要在链中加入自定义函数,可以选择:
- 将函数封装入RunnableLambda类对象,其是Runnable接口实例,可以直接入链
- 直接将函数入链,函数会自动转换为RunnableLambda对象
(5)Memory会话记忆
【1】临时记忆
RunnableWithMessageHistory + InMemoryChatMessageHistory = 让对话链拥有临时记忆能力。
- RunnableWithMessageHistory:在原有链的基础上创建带有历史记录功能的新链(新Runnable实例)
from langchain_core.runnables.history import RunnableWithMessageHistory # 通过RunnableWithMessageHistory获取一个新的带有历史记录功能的chain conversation_chain = RunnableWithMessageHistory( some_chain, # 被附加历史消息的Runnable,通常是chain None, # 获取指定会话ID的历史会话的函数 input_messages_key="input", # 声明用户输入消息在模板中的占位符 history_messages_key="chat_history" # 声明历史消息在模板中的占位符 )
- InMemoryChatMessageHistory:为历史记录提供内存存储(临时)
# 获取指定会话ID的历史会话记录函数 chat_history_store = {} # 存放多个会话ID所对应的历史会话记录 # 函数传入为会话ID(字符串类型) # 函数要求返回BaseChatMessageHistory的子类 # BaseChatMessageHistory类专用于存放某个会话的历史记录 # InMemoryChatMessageHistory是官方自带的基于内存存放历史记录的类 def get_history(session_id): if session_id not in chat_history_store: # 返回一个新的实例 chat_history_store[session_id] = InMemoryChatMessageHistory() return chat_history_store[session_id]完整代码展示:
from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.chat_history import InMemoryChatMessageHistory from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnableWithMessageHistory # 定义一个打印提示词的辅助函数 def print_prompt(full_prompt): print("="*20, full_prompt.to_string(), "="*20) return full_prompt # 1. 初始化模型 model = ChatTongyi(model="qwen3-max") # 2. 定义提示词模板 # 注:模板中包含了 {chat_history} 和 {input} 两个占位符 prompt = ChatPromptTemplate.from_messages( [ ("system", "你需要根据对话历史回应用户问题。对话历史:"), MessagesPlaceholder("chat_history"), ("human", "请回答如下问题,{input}") ] ) # 3. 构建基础链 (base_chain) # 流程:提示词 -> 打印提示词 -> 模型 -> 字符串解析器 base_chain = prompt | print_prompt | model | StrOutputParser() # 4. 定义历史记录存储和获取函数 chat_history_store = {} # 用于存储多个会话的历史记录 def get_history(session_id): if session_id not in chat_history_store: # 如果没有该会话的历史记录,创建一个新的内存存储实例 chat_history_store[session_id] = InMemoryChatMessageHistory() return chat_history_store[session_id] # 5. 创建带记忆功能的链 RunnableWithMessageHistory conversation_chain = RunnableWithMessageHistory( base_chain, # 被包装的基础链 get_history, # 获取历史记录的函数 input_messages_key="input", # 用户输入在模板中的键名 history_messages_key="chat_history" # 历史记录在模板中的键名 ) # 6. 主程序入口 if __name__ == '__main__': # 配置当前会话的 ID session_config = {"configurable": {"session_id": "user_001"}} # 第一次调用 print(conversation_chain.invoke({"input": "小明有一只猫"}, session_config)) # 第二次调用 print(conversation_chain.invoke({"input": "小刚有两只狗"}, session_config)) # 第三次调用 print(conversation_chain.invoke({"input": "共有几只宠物?"}, session_config))调用过程:
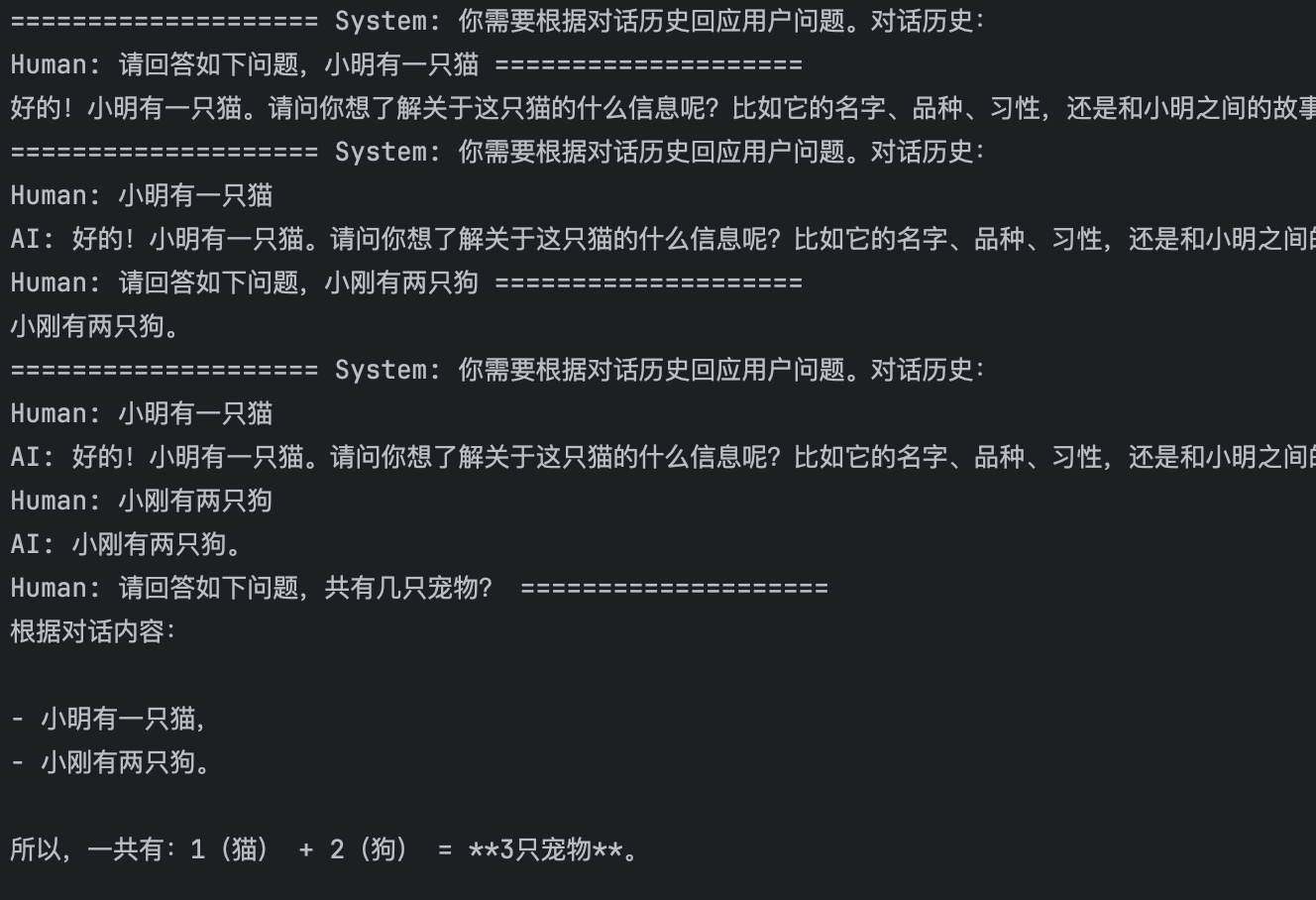
1、第一次调用:
"小明有一只猫"
传入数据:
{"input": "小明有一只猫"},配置session_id="user_001"。获取历史:系统调用
get_history("user_001")。因为是第一次,内存里没有,所以创建了一个空的历史记录对象。拼接提示词:
{chat_history}空
{input}"小明有一只猫"最终发送给模型的提示词:
"你需要根据对话历史回应用户问题。对话历史:[空]。用户当前输入:小明有一只猫,请给出回应"
保存历史:系统自动将这次对话(用户说“小明有一只猫”,AI回“好的,我知道了”)存入
user_001的历史记录中。2、第二次调用:
"小刚有两只狗"
传入数据:
{"input": "小刚有两只狗"},配置session_id="user_001"。获取历史:系统调用
get_history("user_001")。这次内存里有数据了,返回刚才保存的记录。拼接提示词:
{chat_history}"用户: 小明有一只猫 AI: 好的,我知道了。"
{input}-> "小刚有两只狗"最终发送给模型的提示词:
"你需要根据对话历史回应用户问题。对话历史:[小明有一只猫...我知道了]。用户当前输入:小刚有两只狗,请给出回应"
保存历史:系统将这次对话追加到历史记录中(现在历史里有两条记录)。
3、第三次调用:
"共有几只宠物?"
传入数据:
{"input": "共有几只宠物?"},配置session_id="user_001"。获取历史:系统再次调用
get_history("user_001"),返回包含前两次对话的完整记录。拼接提示词:
{chat_history}"用户: 小明有一只猫 AI: 好的,我知道了。 用户: 小刚有两只狗 AI: 好的,我也记住了。"
{input}"共有几只宠物?"最终发送给模型的提示词:
"你需要根据对话历史回应用户问题。对话历史:[前两次对话内容]。用户当前输入:共有几只宠物?,请给出回应"
模型回复:因为模型看到了完整的上下文,它能够正确推理出答案"一共有3只宠物。"
【2】长期记忆
之前的
InMemoryChatMessageHistory是临时的,程序重启数据就没了。解决方案则是自定义FileChatMessageHistory类,将聊天记录持久化存储到本地文件中。
FileChatMessageHistory
存储方式:基于文件存储会话记录。
文件命名:以
session_id作为文件名。隔离性:不同的
session_id对应不同的文件。
FileChatMessageHistory继承自BaseChatMessageHistory,必须实现以下 3 个核心方法:
add_messages:添加消息。将新消息追加到文件中。messages:获取消息。从文件中读取所有历史消息。clear:清除消息。清空文件内容。
FileChatMessageHistory模板:import os import json from typing import Sequence, List from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict """ 基于文件存储的聊天历史记录类 继承自 BaseChatMessageHistory,实现将聊天记录持久化存储到本地文件 """ class FileChatMessageHistory(BaseChatMessageHistory): """ 初始化 FileChatMessageHistory 实例 """ def __init__(self, session_id, storage_path): self.session_id = session_id # 当前会话的唯一标识符 self.storage_path = storage_path # 文件存储的根目录 # 构建完整的文件路径:存储路径 + 会话ID作为文件名 self.file_path = os.path.join(self.storage_path, self.session_id) # 确保存储目录存在,如果不存在则创建(exist_ok=True表示目录已存在时不报错) os.makedirs(os.path.dirname(self.file_path), exist_ok=True) """ 【1】添加新消息 messages:参数的名字,代表要添加的消息。 :Sequence[BaseMessage]:类型注解,表示messages参数应是一个Sequence AIMessage、HumanMessage、SystemMessage 都是BaseMessage的子类 -> None:类型注解,表示这个方法不返回任何值 """ def add_messages(self, messages: Sequence[BaseMessage]) -> None: # 1.获取已有的所有消息(调用 messages 属性) all_messages = list(self.messages) # self.messages 会调用 @property 修饰的 messages 方法 # 2.将新的消息追加到已有消息列表后面 all_messages.extend(messages) # 3.格式转换:将【消息 -> 字典】,以便序列化为JSON # 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典 new_messages = [message_to_dict(message) for message in all_messages] """ 等价于: new_messages = [] for message in all_messages: d = message_to_dict(message) new_messages.append(d) """ # 4.将数据写入文件 with open(self.file_path, "w", encoding="utf-8") as f: json.dump(new_messages, f) """ 【2】获取当前会话的所有消息 -> List[BaseMessage]:类型注解,表示这个方法应该返回什么类型的数据 使用 @property 装饰器,让这个方法可以通过 self.messages访问 """ @property def messages(self) -> list[BaseMessage]: # 当前文件内: list[字典] try: with open(self.file_path, "r", encoding="utf-8") as f: # 文件内存储的是 list[字典],每个字典代表一条消息 messages_data = json.load(f) # 返回值就是:list[字典] # 格式转换:将【字典 -> 消息】 # 官方message_from_dict:字典 -> 单个消息对象(BaseMessage类实例) return messages_from_dict(messages_data) except FileNotFoundError: # 如果文件不存在(首次创建或已被删除),返回空列表 return [] """ 【3】清空当前会话的所有聊天记录 """ def clear(self) -> None: with open(self.file_path, "w", encoding="utf-8") as f: # 将一个空列表写入文件,相当于清空所有消息 json.dump([], f)完整代码示例:
结合临时记忆的代码,稍作修改
import os import json from typing import Sequence, List from langchain_community.chat_models import ChatTongyi from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables import RunnableWithMessageHistory """ 基于文件存储的聊天历史记录类 继承自 BaseChatMessageHistory,实现将聊天记录持久化存储到本地文件 """ class FileChatMessageHistory(BaseChatMessageHistory): """ 初始化 FileChatMessageHistory 实例 """ def __init__(self, session_id, storage_path): self.session_id = session_id # 当前会话的唯一标识符 self.storage_path = storage_path # 文件存储的根目录 # 构建完整的文件路径:存储路径 + 会话ID作为文件名 self.file_path = os.path.join(self.storage_path, self.session_id) # 确保存储目录存在,如果不存在则创建(exist_ok=True表示目录已存在时不报错) os.makedirs(os.path.dirname(self.file_path), exist_ok=True) """ 【1】添加新消息 messages:参数的名字,代表要添加的消息。 :Sequence[BaseMessage]:类型注解,表示messages参数应是一个Sequence AIMessage、HumanMessage、SystemMessage 都是BaseMessage的子类 -> None:类型注解,表示这个方法不返回任何值 """ def add_messages(self, messages: Sequence[BaseMessage]) -> None: # 1.获取已有的所有消息(调用 messages 属性) all_messages = list(self.messages) # self.messages 会调用 @property 修饰的 messages 方法 # 2.将新的消息追加到已有消息列表后面 all_messages.extend(messages) # 3.格式转换:将【消息 -> 字典】,以便序列化为JSON # 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典 new_messages = [message_to_dict(message) for message in all_messages] """ 等价于: new_messages = [] for message in all_messages: d = message_to_dict(message) new_messages.append(d) """ # 4.将数据写入文件 with open(self.file_path, "w", encoding="utf-8") as f: json.dump(new_messages, f) """ 【2】获取当前会话的所有消息 -> List[BaseMessage]:类型注解,表示这个方法应该返回什么类型的数据 使用 @property 装饰器,让这个方法可以通过 self.messages访问 """ @property def messages(self) -> list[BaseMessage]: # 当前文件内: list[字典] try: with open(self.file_path, "r", encoding="utf-8") as f: # 文件内存储的是 list[字典],每个字典代表一条消息 messages_data = json.load(f) # 返回值就是:list[字典] # 格式转换:将【字典 -> 消息】 # 官方message_from_dict:字典 -> 单个消息对象(BaseMessage类实例) return messages_from_dict(messages_data) except FileNotFoundError: # 如果文件不存在(首次创建或已被删除),返回空列表 return [] """ 【3】清空当前会话的所有聊天记录 """ def clear(self) -> None: with open(self.file_path, "w", encoding="utf-8") as f: # 将一个空列表写入文件,相当于清空所有消息 json.dump([], f) """ ======================= 下面是调用chain链代码 ================================= """ # 定义一个打印提示词的辅助函数 def print_prompt(full_prompt): print("=" * 20, full_prompt.to_string(), "=" * 20) return full_prompt # 1.初始化模型 model = ChatTongyi(model="qwen3-max") # 2.定义提示词模板 # 注:模板中包含了 {chat_history} 和 {input} 两个占位符 prompt = ChatPromptTemplate.from_messages( [ ("system", "你需要根据对话历史回应用户问题。对话历史:"), MessagesPlaceholder("chat_history"), ("human", "请回答如下问题,{input}") ] ) # 3.构建基础链 (base_chain) # 流程:提示词 -> 打印提示词 -> 模型 -> 字符串解析器 base_chain = prompt | print_prompt | model | StrOutputParser() # 4.获取历史记录的函数 def get_history(session_id): # 调用文件存储模板 return FileChatMessageHistory(session_id,"./chat_history") # 5.创建带记忆功能的链 RunnableWithMessageHistory conversation_chain = RunnableWithMessageHistory( base_chain, # 被包装的基础链 get_history, # 获取历史记录的函数 input_messages_key="input", # 用户输入在模板中的键名 history_messages_key="chat_history" # 历史记录在模板中的键名 ) # 6. 主程序入口 if __name__ == '__main__': # 配置当前会话的 ID session_config = {"configurable": {"session_id": "user_001"}} # 第一次调用 print(conversation_chain.invoke({"input": "小明有一只猫"}, session_config)) # 第二次调用 print(conversation_chain.invoke({"input": "小刚有两只狗"}, session_config)) # 第三次调用 print(conversation_chain.invoke({"input": "共有几只宠物?"}, session_config))
为了保证代码可读性,可以把长期会话记忆模板单拎出来,在主函数引用即可
(6)文档加载器
文档加载器提供了一套标准接口,用于将不同来源(如 CSV、PDF 或 JSON等)的数据读取为 LangChain 的文档格式。这确保了无论数据来源如何,都能对其进行一致性处理。
文档加载器均继承于BaseLoader类
返回Document类型的对象
load方法:一次性批量加载(返回list内含Document对象),如内容过多可能list太大,出现内存溢出问题
lazy_load方法:得到生成器对象,可用for循环依次获取单个Document对象,适用于大文档避免内存不下
【1】CSVLoader
from langchain_community.document_loaders import CSVLoader loader = CSVLoader( file_path="./data/stu.csv", csv_args={ "delimiter": ",", # 指定分隔符 "quotechar": '"', # 指定带有分隔符文本的引号包围是单引号还是双引号 # 如果数据原本有表头,就不要下面的代码,如果没有可以使用 "fieldnames": ['name', 'age', 'gender', '爱好'] }, encoding="utf-8" # 指定编码为UTF-8 ) # 批量加载 .load() -> [Document, Document, ...] documents = loader.load() for document in documents: print(type(document), document) # 懒加载 .lazy_load() 迭代器[Document] for document in loader.lazy_load(): print(document)【2】JSONLoader
使用 JSONLoader 需要额外安装:
pip install jqjq是一个跨平台的json解析工具,LangChain底层对JSON的解析就是基于jq工具实现的。将JSON数据的信息抽取出来,封装为Document对象,抽取时依赖jq_schema语法。
{ "name": "周杰轮", "age": 11, "hobby": ["唱", "跳", "RAP"], "other": { "addr": "深圳", "tel": "12332112321" } }
. 表示整个JSON对象
[] 表示数组
.name 表示抽取周杰轮
.hobby 表示抽取爱好数组
.hobby[1] 或 .hobby.[1] 表示抽取跳
.other.addr 表示抽取地址深圳
[ {"name": "周杰轮", "age": 11, "gender": "男"}, {"name": "蔡依临", "age": 12, "gender": "女"}, {"name": "王力鸿", "age": 11, "gender": "男"} ]
.[]. 得到3个字典
.[].name 表示抽取全部的name,即得到3个name信息
from langchain_community.document_loaders import JSONLoader loader = JSONLoader( file_path="./data/stu_json_lines.json", jq_schema=".name", text_content=False, # (非必须)告知JSONLoader 抽取的内容不是字符串 json_lines=True # (非必须)告知JSONLoader 这是一个JSONLines文件(每一行都是一个独立的标准JSON) ) document = loader.load() print(document)【3】TextLoader
TextLoader 作用:读取文本文件(如.txt),将全部内容放入一个Document对象中。
但如果文本文件很大,全部存入一个Document对象显然不合适,因此可以采用文档分割器。
递归字符文本分割器 RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader from langchain_text_splitters import RecursiveCharacterTextSplitter loader = TextLoader( "../data/text.txt", encoding="utf-8", ) docs = loader.load() splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 分段的最大字符数 chunk_overlap=50, # 分段之间允许重叠的字符数 # 文本分段依据 separators=["\n\n", "\n", ".", "!", "?", " ", ""], # 字符统计依据(函数) length_function=len, ) split_docs = splitter.split_documents(docs)完整代码:
loader = TextLoader(file_path="./data/text.txt", encoding="utf-8") docs = loader.load() # [Document] splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 分段的最大字符数 chunk_overlap=50, # 分段之间允许重叠的字符数 # 文本自然段落分隔的依据符号 separators=["\n\n", "\n", ".", "!", "?", ".", "!", "?", " ", ""], length_function=len, # 统计字符的依据函数 ) split_docs = splitter.split_documents(docs) for doc in split_docs: print("="*20) print(doc) print("="*20)【4】PDFLoader
PyPDFLoader加载器,依赖PyPDF库,所以,需要安装它:
pip install pypdfPyPDFLoader 按照如下代码即可快速加载PDF中的文字内容:
from langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader( file_path="", # 文件路径必填 mode='page', # 读取模式,可选page(按页面划分不同Document)和single(单个Document) password='password', # 文件密码 )
5、向量存储
(1)内存向量存储
from langchain_core.vectorstores import InMemoryVectorStore from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.document_loaders import CSVLoader vector_store = InMemoryVectorStore( embedding=DashScopeEmbeddings() ) loader = CSVLoader( file_path="./data/info.csv", encoding="utf-8", source_column="source", # 指定本条数据的来源是哪里 ) documents = loader.load() # 向量存储的 增删、检索 vector_store.add_documents( documents=documents, # 被添加的文档,类型: list[Document] ids=["id"+str(i) for i in range(1, len(documents)+1)] # 给添加的文档提供id(字符串) ) # 删除 传入[id, id...] vector_store.delete(["id1", "id2"]) # 检索 返回类型list[Document] result = vector_store.similarity_search( query: "Python是不是简单易学呀", k: 3 # 检索的结果要几个 ) print(result)
(2)外部向量数据库
from langchain_chroma import Chroma from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.document_loaders import CSVLoader # Chroma 向量数据库(轻量级) vector_store = Chroma( collection_name="test", # 当前向量存储起个名字,类似数据库的表名称 embedding_function=DashScopeEmbeddings(), # 嵌入模型 persist_directory="./chroma_db" # 指定数据存放的文件夹 ) loader = CSVLoader( file_path="./data/info.csv", encoding="utf-8", source_column="source", # 指定本条数据的来源是哪里 ) documents = loader.load() # 向量存储的 增删、检索 vector_store.add_documents( documents=documents, # 被添加的文档,类型: list[Document] ids=["id"+str(i) for i in range(1, len(documents)+1)] # 给添加的文档提供id(字符串) ) # 删除 传入[id, id...] vector_store.delete(["id1", "id2"]) # 检索 返回类型list[Document] result = vector_store.similarity_search( query: "Python是不是简单易学呀", k: 3 # 检索的结果要几个 ) print(result)
(3)基于向量检索构建chain链
流程:
- 初始化模型
- 创建提示词模板
- 配置本地向量数据库
- 提前准备向量数据库信息
- 检索向量数据库,获得匹配信息
- 将用户提问和匹配信息一同封装到提示词模板中提问模型
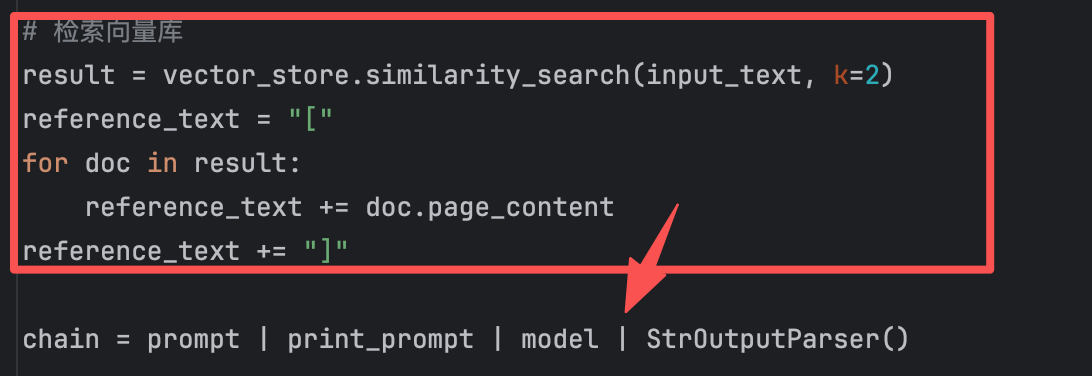
model = ChatTongyi(model="qwen3-max") prompt = ChatPromptTemplate.from_messages( [ ("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"), ("user", "用户提问: {input}") ] ) vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4")) # 准备向量库的数据 # add_texts 传入一个 list[str] vector_store.add_texts(["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哦"]) input_text = "怎么减肥?" def print_prompt(prompt): print(prompt.to_string()) print("="*20) return prompt # 检索向量库 result = vector_store.similarity_search(input_text, k=2) reference_text = "[" for doc in result: reference_text += doc.page_content reference_text += "]" chain = prompt | print_prompt | model | StrOutputParser() res = chain.invoke({"input": input_text, "context": reference_text}) print(res)
(4)向量检索器入链
如何将向量检索器加入chain链?
Langchain中向量存储对象,有一个方法:as_retriever,可以返回一个Runnable接口的子类实例对象,而我们知道:只有Runnable子类对象才能入链。因此我们将原来的向量检索方法稍加改动:
# 原来的向量检索 result = vector_store.similarity_search(input_text, k=2) # 改动后 retriever = vector_store.as_retriever(search_kwargs={"k": 2})那是不是改动后,chain链可以直接这样写呢?
chain = retriever | prompt | print_prompt | model | Str0OutputParser()其实这样写是错误的,因为retriever的输出格式与prompt的输入格式不匹配。
retriever - 向量检索
输入:用户的提问 【str】
输出:向量库的检索结果 【list[Document]】
prompt - 提示词模板
输入:用户的提问 + 向量库的检索结果 【dict】
输出:完整的提示词 【PromptValue】
可以看到retriever的输出结果是【向量库的检索结果】,格式是【list[Document]】,而prompt的输入结果是【用户的提问 + 向量库的检索结果】,格式是【dict】。
为了解决格式不匹配的问题,我们可以改造chain链:
chain = ( {"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | model | Str0OutputParser() )其中
- RunnablePassthrough()是一个 Runnable对象,作用是:原样传递输入数据,因为只有Runnable子类对象才能入链,所以RunnablePassthrough()的作用其实是为了用户输入可以入链(否则字符串格式无法入链)
- format_func的作用是:把retriever的输出【list[Document]】格式化成【str】,这样整体{"input": RunnablePassthrough(), "context": retriever | format_func}即包含【用户的提问 + 向量库的检索结果】,格式为【dict】
完整代码:
model = ChatTongyi(model="qwen3-max") prompt = ChatPromptTemplate.from_messages( [ ("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"), ("user", "用户提问: {input}") ] ) vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4")) # 准备向量库的数据 # add_texts 传入一个 list[str] vector_store.add_texts(["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哦"]) input_text = "怎么减肥?" def print_prompt(prompt): print(prompt.to_string()) print("="*20) return prompt # 检索向量库 # 向量存储对象:as_retriever,可以返回一个Runnable接口的子类实例对象 retriever = vector_store.as_retriever(search_kwargs={"k": 2}) def format_func(docs: list[Document]): if not docs: return "无相关参考资料" formatted_str = "[" for doc in docs: formatted_str += doc.page_content formatted_str += "]" return formatted_str chain = ( {"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | model | StrOutputParser() ) res = chain.invoke(input_text) print(res)
三、RAG项目实战
本次项目以“某东商品衣服”为例,以衣服属性构建本地知识。使用者可以自由更新本地知识,用户问题的答案也是基于本地知识生成的。

1、离线功能
(1)文本上传web功能
创建一个新项目
""" 基于Streamlit完成web网页上传服务 pip install streamlit """ import streamlit as st # 添加网页标题 st.title("知识库更新服务")想要运行网页,需要先右键复制项目的绝对路径
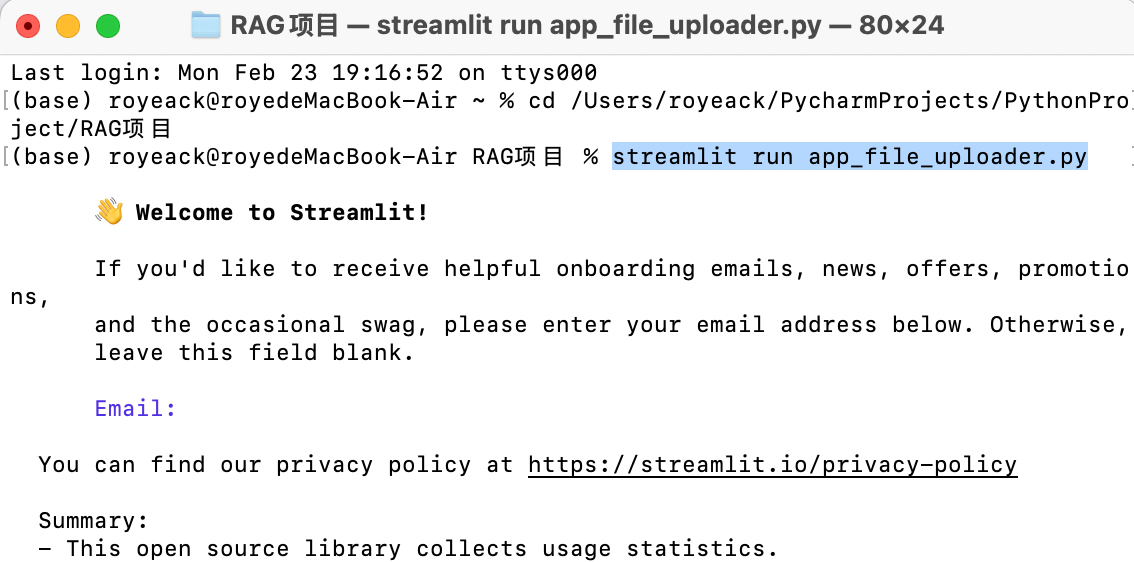
打开终端,通过cd命令进入项目的绝对路径,接着输入下面的命令
streamlit run app_file_uploader.py
这样就会弹出网页
接着我们继续制作一个简单的上传文件功能
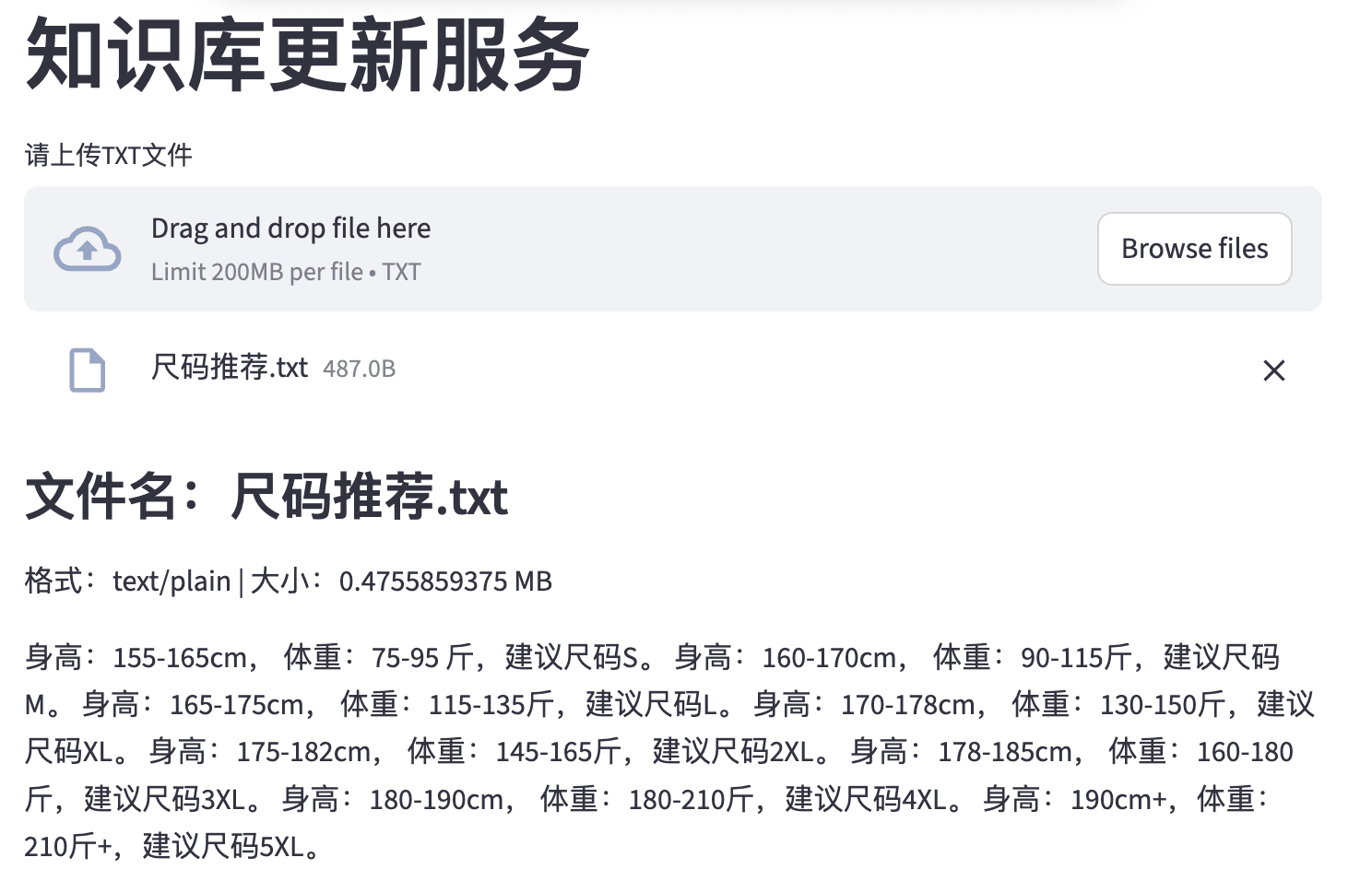
""" 基于Streamlit完成web网页上传服务 pip install streamlit """ import streamlit as st # 添加网页标题 st.title("知识库更新服务") # 上传文件 uploader_file = st.file_uploader( "请上传TXT文件", type=['txt'], accept_multiple_files=False, # False表示仅接收一个文件 ) if uploader_file is not None: # 提取文件信息 file_name = uploader_file.name file_type = uploader_file.type file_size = uploader_file.size/1024 st.subheader(f"文件名:{file_name}") st.write(f"格式:{file_type} | 大小:{file_size} MB") # 获得文件内容 text = uploader_file.getvalue().decode("utf-8") st.write(text)
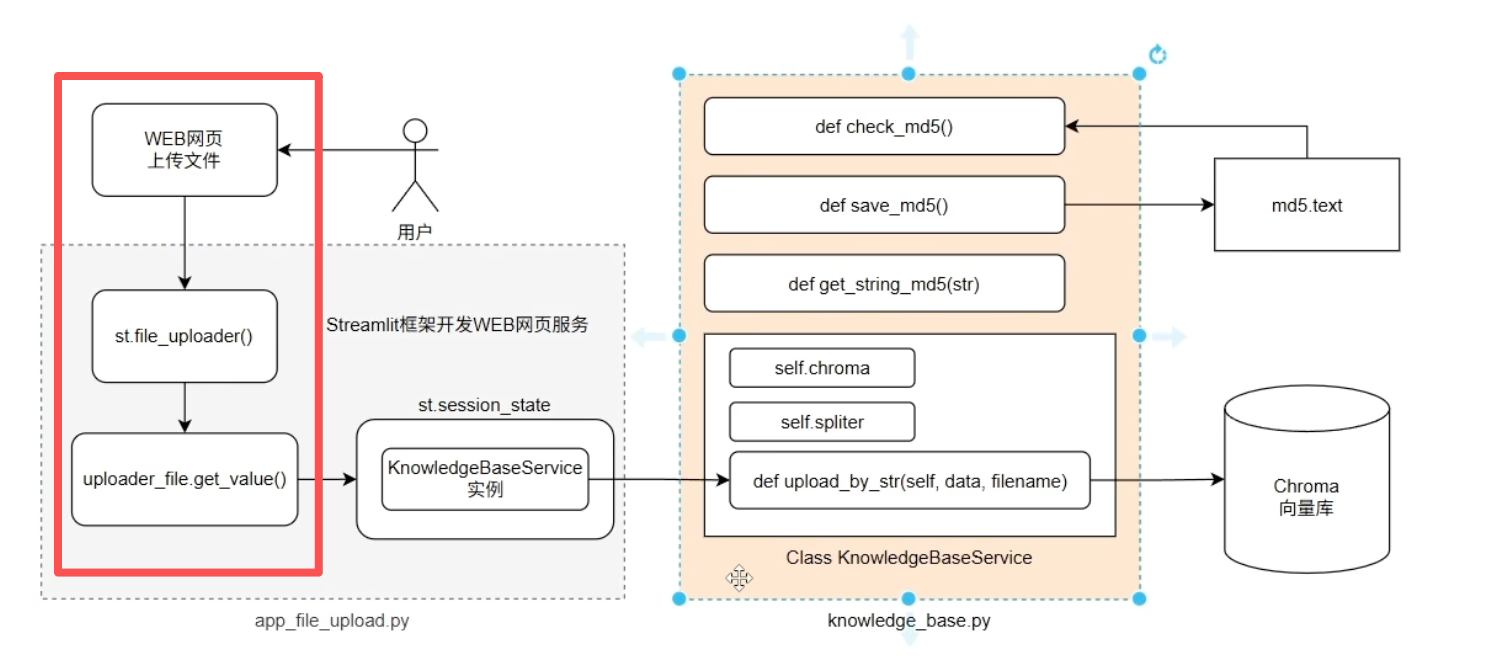
(2)文件去重:md5
md5是一种广泛使用的数据指纹算法,核心作用是为数据生成一段固定长度的唯一指纹。通过计算并比较两个文件的md5值,可以验证它们是否完全相同——即使一个文件只被修改了一个字节,产生的MD5值也会截然不同。
我们的项目要求上传的文件不能重复,因此可以采用md5进行文件去重。
创建一个新文件
为了实现文件去重校验,我们需要实现3个函数:
- check_md5:检查传入的md5字符串是否被处理过
- save_md5:将传入的md5字符串记录到文件中保存
- get_string_md5:将传入的字符串转换为md5字符串
""" 检查传入的md5字符串是否已经被处理过 return False【md5未处理过】 True【md5已处理过】 """ def check_md5(md5_str: str): if not os.path.exists(config.md5_path): # 说明该配置文件不存在,创建该配置文件 open(config.md5_path,'w',encoding='utf-8').close() return False else: # 说明该配置文件存在,在配置文件中查找是否存在该md5 # 存在说明该md5已被处理过,返回True # 不存在说明该md5未被处理过,返回False for line in open(config.md5_path,'r',encoding='utf-8').readlines(): line = line.strip() # 处理字符串前后空格和回车 if line == md5_str: return True return False """ 将传入的md5字符串,记录到文件保存 """ def save_md5(md5_str: str): # a 追加模式:写入的内容会被添加到文件的末尾 with open(config.md5_path,'a',encoding='utf-8') as f: f.write(md5_str + '\n') """ 将传入的字符串转换为md5字符串 """ def get_string_md5(input_str: str,encoding='utf-8'): # 将字符串转换为bytes字节数组 str_bytes = input_str.encode(encoding) # 创建md5对象 md5_obj = hashlib.md5(str_bytes) # 得到md5对象 md5_obj.update(str_bytes) # 更新内容(传入要转换的字节数组) md5_hex = md5_obj.hexdigest() # 得到md5的十六进制字符串 return md5_hex
(3)知识库更新功能
上面已经完成了实现md5的校验存储,接着我们需要完成知识库离线更新功能。
同样是在knowledge_base.py文件下编写代码
我们需要实现2个函数:
- 初始化函数init,其中包含:
- 向量存储的实例Chroma向量库对象
- 文本分割器对象
- 向量库存储函数:
- 获取文本的md5字符串 get_string_md5()
- 判断该文本是否存在向量库中 check_md5()
- 如果文本字数超过文本分割阈值,进行文本切分
- 存储切割好的文本块到向量库中(metadata记录每一个文本块的相关信息)
""" 实现知识库更新功能 """ class KnowledgeBaseService(object): def __init__(self): # 如果【数据库本地存储文件夹】不存在则创建 os.makedirs(config.persist_directory, exist_ok=True) # 向量存储的实例Chroma向量库对象 self.chroma = Chroma( collection_name= config.collection_name, # 数据库表名 embedding_function = DashScopeEmbeddings(model="text-embedding-v4"), persist_directory = config.persist_directory, # 数据库本地存储文件夹 ) # 文本分割器对象 self.spliter = RecursiveCharacterTextSplitter( chunk_size = config.chunk_size, # 分割后文本段最大长度 chunk_overlap = config.chunk_overlap, # 连续文本段之间的字符重叠数量 separators = config.separators, # 自然段落划分符号 length_function = len, # 使用Python自带的len函数做长度统计依据 ) # 将传入的文本进行向量化,存入向量数据库 def upload_by_str(self, data:str, filename): # 获取md5字符串 md5_hex = get_string_md5(data) # 判断该文本是否在知识库中 if check_md5(md5_hex): return "[跳过]内容已经存在知识库中!" #【1】文本分割:如果字符串长度大于文本分割的阈值,则进行文本切分 if len(data) > config.max_split_char_number: knowledge_chunks: list[str] = self.spliter.split_text(data) else: knowledge_chunks = [data] # [data]是 Python 中创建一个只包含一个元素的列表的写法 # 记录该文本的相关信息 metadata = { "source": filename, "create_time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"), "operator": "容也", } #【2】存储文本到向量库中 self.chroma.add_texts( knowledge_chunks, # 要存储的文本块列表 metadatas = [metadata for _ in knowledge_chunks], # 文本的相关信息 # [metadata for _ in knowledge_chunks] # 作用:为knowledge_chunks列表中的每一个文本块,都复制一份相同的元数据(metadata字典) ) # 将存储成功的字符串md5值存入md5.text save_md5(md5_hex) return "[成功]内容已经成功载入向量库!"config_data.py文件内容如下:
md5_path = "./md5.text" # Chroma collection_name = "rag" persist_directory = "./chroma_db" # spliter chunk_size = 1000 chunk_overlap = 100 separators = ["\n\n","\n",".","!","?","。","!","?"," ",""] max_split_char_number = 1000 # 文本分割的阈值接着进行测试:
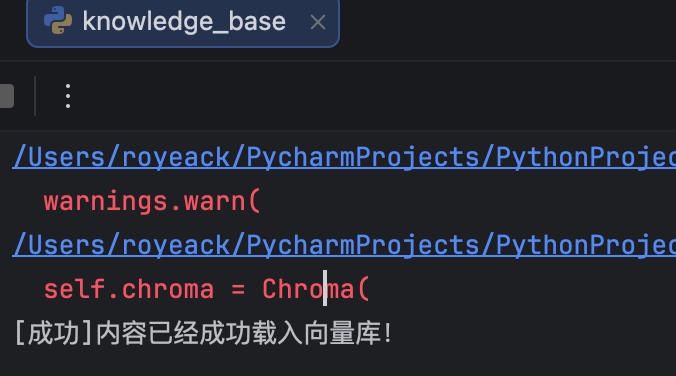
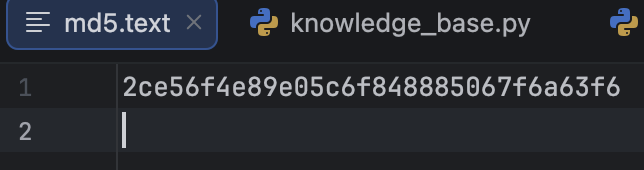
if __name__ == "__main__": service = KnowledgeBaseService() r = service.upload_by_str("棉花糖","testfile") print(r)第一次运行项目,可以看到存储成功的提示,并且可以在md5.text文件中看到,“棉花糖”对应的md5字符串已经被成功存储
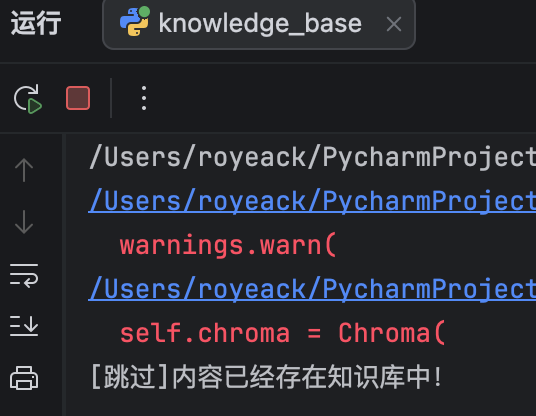
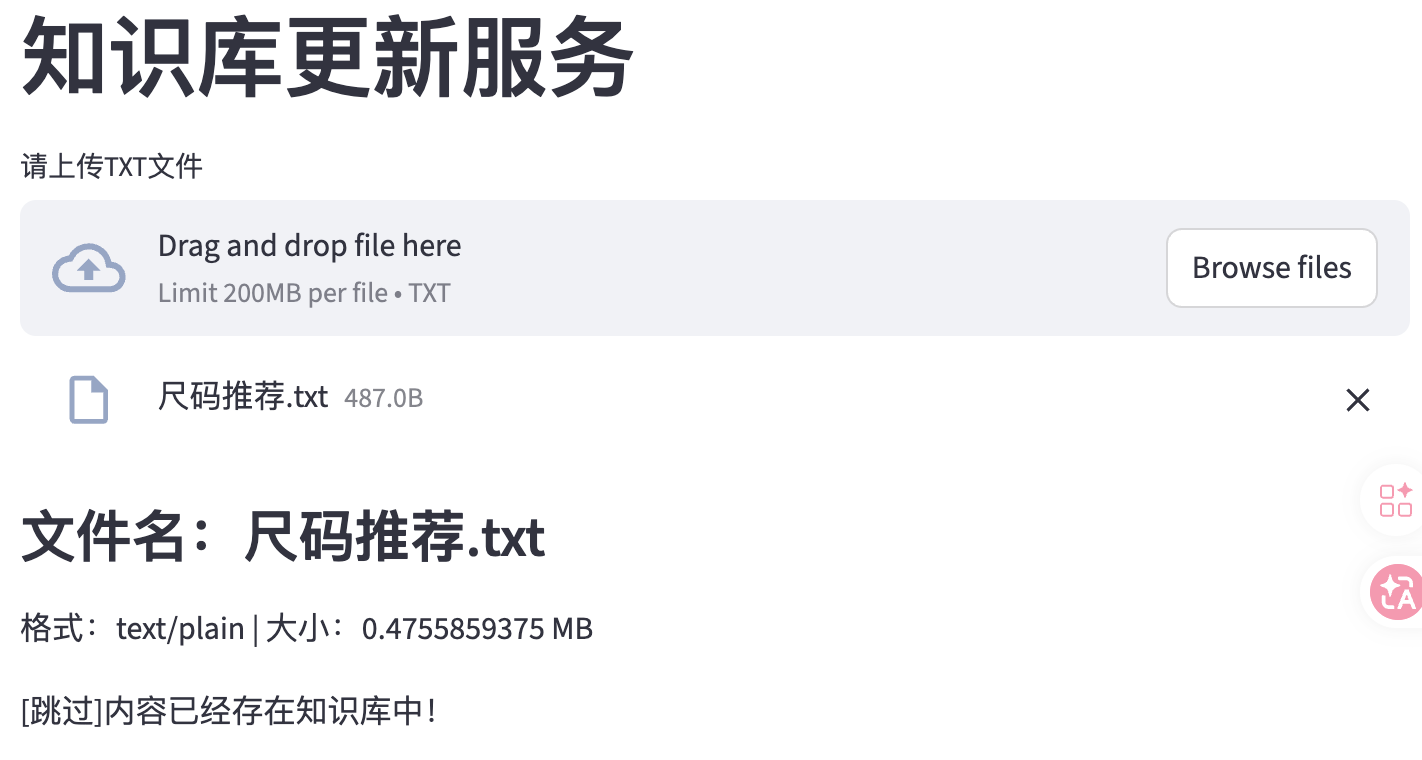
再次运行项目,接收到内容已经存在知识库中的提示,说明md5文本去重功能也没有问题
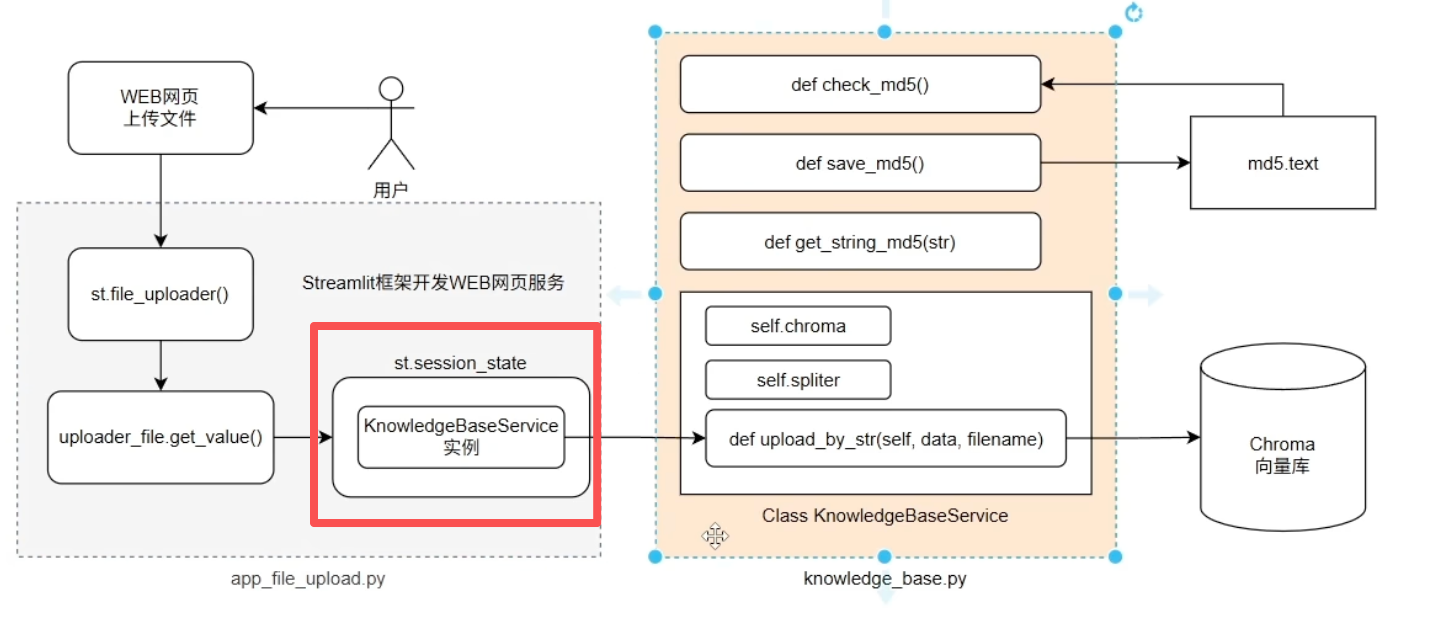
(4)离线流程整合实现
上面实现了RAG离线流程的3部分功能:web文件上传、md5文件去重、知识库更新
最后我们需要将这3部分功能串联起来
Streamlit有一个特性:当web页面元素发生变化,则代码重新执行一遍。这意味着页面状态默认不会被保留,每次交互都相当于重新加载了页面。
在文件上传的场景中,每次上传文件都会触发脚本的完整重新运行,这样就会出现问题:无论上传多少个文件,脚本每次重启都会忘记之前的所有记录,导致最终只处理并保留了最后一个文件。
要让 Streamlit 记住状态,需要主动将需要跨执行周期保存的数据存入特定的状态管理对象中,比如
st.session_state。为了保证我们创建的实例KnowledgeBaseService()被记住,而不是被Streamlit刷新掉
❗️注意:实例KnowledgeBaseService()就是知识库更新的代码
在app_file_uploader.py文件中,添加如下代码:
# Streamlit有一个特性:当web页面元素发生变化,则代码重新执行一遍 # st.session_state:在Streamlit脚本的多次重新执行之间,持久化保存数据和对象 # 脚本每次重新执行时,都会直接复用这个已存在的KnowledgeBaseService()实例,而不是重新创建一个新的 if "service" not in st.session_state: st.session_state["service"] = KnowledgeBaseService() res = st.session_state["service"].upload_by_str(text,file_name)app_file_uploader.py文件完整代码如下:
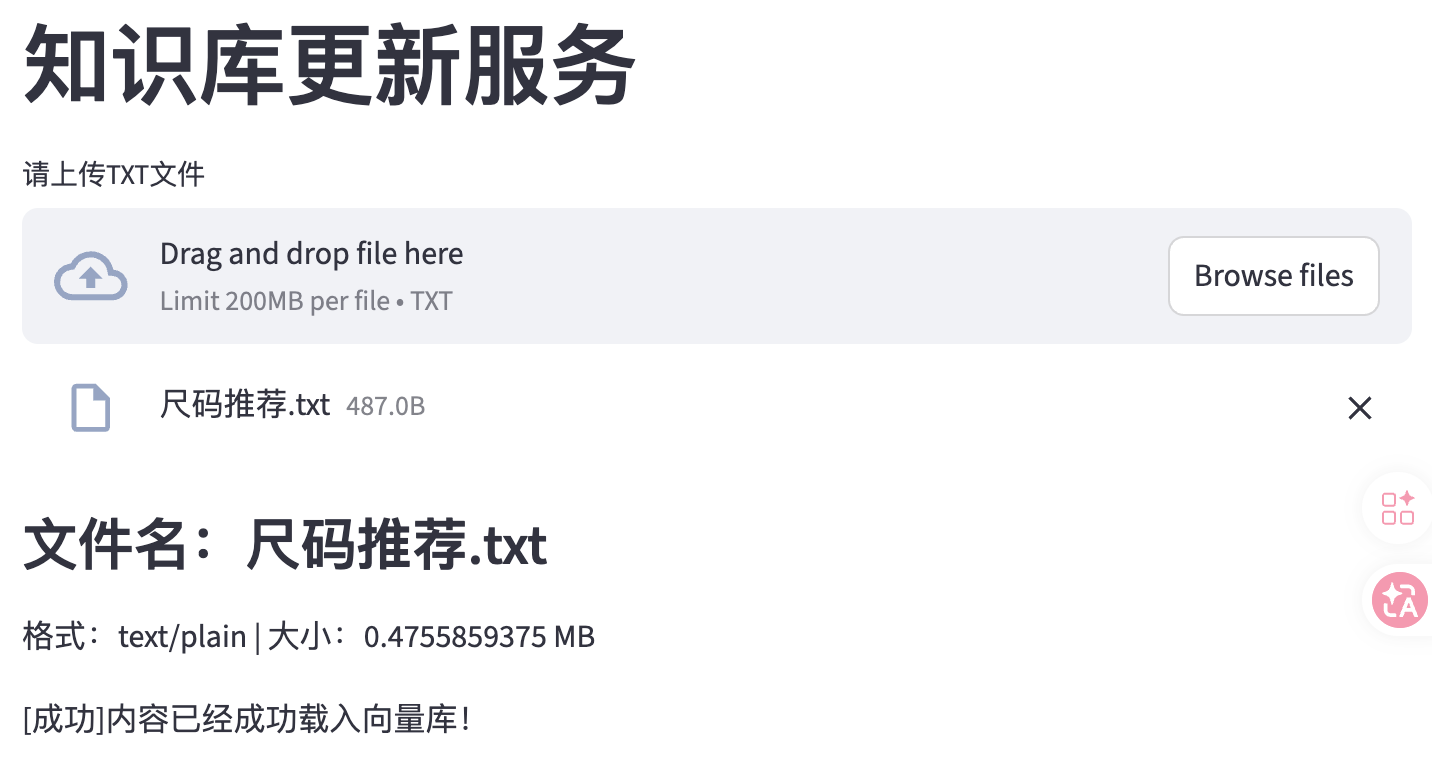
""" 基于Streamlit完成web网页上传服务 pip install streamlit """ import time import streamlit as st from knowledge_base import KnowledgeBaseService # 添加网页标题 st.title("知识库更新服务") # 上传文件 uploader_file = st.file_uploader( "请上传TXT文件", type=['txt'], accept_multiple_files=False, # False表示仅接收一个文件 ) # Streamlit有一个特性:当web页面元素发生变化,则代码重新执行一遍 # st.session_state:在Streamlit脚本的多次重新执行之间,持久化保存数据和对象 # 脚本每次重新执行时,都会直接复用这个已存在的KnowledgeBaseService()实例,而不是重新创建一个新的 if "service" not in st.session_state: st.session_state["service"] = KnowledgeBaseService() # 如果文件非空,提取文件信息 if uploader_file is not None: # 提取文件信息 file_name = uploader_file.name file_type = uploader_file.type file_size = uploader_file.size/1024 st.subheader(f"文件名:{file_name}") st.write(f"格式:{file_type} | 大小:{file_size} MB") # 获得文件内容 text = uploader_file.getvalue().decode("utf-8") # 在spinner内的代码执行过程中,会有转圈动画 with st.spinner("载入知识库中……"): time.sleep(1) # 通过st.session_state["service"]获取同一个服务实例KnowledgeBaseService(),调用其的上传方法。 res = st.session_state["service"].upload_by_str(text,file_name) st.write(res)再次刷新页面并上传文件进行测试
上传同样的文件会出现提示
(5)代码总结
【1】app_file_uploader.py
""" 基于Streamlit完成web网页上传服务 pip install streamlit """ import time import streamlit as st from knowledge_base import KnowledgeBaseService # 添加网页标题 st.title("知识库更新服务") # 上传文件 uploader_file = st.file_uploader( "请上传TXT文件", type=['txt'], accept_multiple_files=False, # False表示仅接收一个文件 ) # Streamlit有一个特性:当web页面元素发生变化,则代码重新执行一遍 # st.session_state:在Streamlit脚本的多次重新执行之间,持久化保存数据和对象 # 脚本每次重新执行时,都会直接复用这个已存在的KnowledgeBaseService()实例,而不是重新创建一个新的 if "service" not in st.session_state: st.session_state["service"] = KnowledgeBaseService() # 如果文件非空,提取文件信息 if uploader_file is not None: # 提取文件信息 file_name = uploader_file.name file_type = uploader_file.type file_size = uploader_file.size/1024 st.subheader(f"文件名:{file_name}") st.write(f"格式:{file_type} | 大小:{file_size} MB") # 获得文件内容 text = uploader_file.getvalue().decode("utf-8") # 在spinner内的代码执行过程中,会有转圈动画 with st.spinner("载入知识库中……"): time.sleep(1) # 通过st.session_state["service"]获取同一个服务实例KnowledgeBaseService(),调用其的上传方法。 res = st.session_state["service"].upload_by_str(text,file_name) st.write(res)【2】knowledge_base.py
""" 知识库 """ import hashlib import os import datetime from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import Chroma from langchain_text_splitters import RecursiveCharacterTextSplitter import config_data as config """ 检查传入的md5字符串是否已经被处理过 return False【md5未处理过】 True【md5已处理过】 """ def check_md5(md5_str: str): if not os.path.exists(config.md5_path): # 说明该配置文件不存在,创建该配置文件 open(config.md5_path,'w',encoding='utf-8').close() return False else: # 说明该配置文件存在,在配置文件中查找是否存在该md5 # 存在说明该md5已被处理过,返回True # 不存在说明该md5未被处理过,返回False for line in open(config.md5_path,'r',encoding='utf-8').readlines(): line = line.strip() # 处理字符串前后空格和回车 if line == md5_str: return True return False """ 将传入的md5字符串,记录到文件保存 """ def save_md5(md5_str: str): # a 追加模式:写入的内容会被添加到文件的末尾 with open(config.md5_path,'a',encoding='utf-8') as f: f.write(md5_str + '\n') """ 将传入的字符串转换为md5字符串 """ def get_string_md5(input_str: str,encoding='utf-8'): # 将字符串转换为bytes字节数组 str_bytes = input_str.encode(encoding) # 创建md5对象 md5_obj = hashlib.md5(str_bytes) # 得到md5对象 md5_obj.update(str_bytes) # 更新内容(传入要转换的字节数组) md5_hex = md5_obj.hexdigest() # 得到md5的十六进制字符串 return md5_hex """ 实现知识库更新功能 """ class KnowledgeBaseService: def __init__(self): # 如果【数据库本地存储文件夹】不存在则创建 os.makedirs(config.persist_directory, exist_ok=True) # 向量存储的实例Chroma向量库对象 self.chroma = Chroma( collection_name= config.collection_name, # 数据库表名 embedding_function = DashScopeEmbeddings(model="text-embedding-v4"), persist_directory = config.persist_directory, # 数据库本地存储文件夹 ) # 文本分割器对象 self.spliter = RecursiveCharacterTextSplitter( chunk_size = config.chunk_size, # 分割后文本段最大长度 chunk_overlap = config.chunk_overlap, # 连续文本段之间的字符重叠数量 separators = config.separators, # 自然段落划分符号 length_function = len, # 使用Python自带的len函数做长度统计依据 ) # 将传入的文本进行向量化,存入向量数据库 def upload_by_str(self, data:str, filename): # 获取md5字符串 md5_hex = get_string_md5(data) # 判断该文本是否在知识库中 if check_md5(md5_hex): return "[跳过]内容已经存在知识库中!" #【1】文本分割:如果字符串长度大于文本分割的阈值,则进行文本切分 if len(data) > config.max_split_char_number: knowledge_chunks: list[str] = self.spliter.split_text(data) else: knowledge_chunks = [data] # [data]是 Python 中创建一个只包含一个元素的列表的写法 # 记录该文本的相关信息 metadata = { "source": filename, "create_time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"), "operator": "容也", } #【2】存储文本到向量库中 self.chroma.add_texts( knowledge_chunks, # 要存储的文本块列表 metadatas = [metadata for _ in knowledge_chunks], # 文本的相关信息 # [metadata for _ in knowledge_chunks] # 作用:为knowledge_chunks列表中的每一个文本块,都复制一份相同的元数据(metadata字典) ) # 将存储成功的字符串md5值存入md5.text save_md5(md5_hex) return "[成功]内容已经成功载入向量库!"【3】config_data.py
md5_path = "./md5.text" # Chroma collection_name = "rag" persist_directory = "./chroma_db" # spliter chunk_size = 1000 chunk_overlap = 100 separators = ["\n\n","\n",".","!","?","。","!","?"," ",""] max_split_char_number = 1000 # 文本分割的阈值
2、在线功能
(1)向量检索功能
创建文件vector_stores.py
目的:传入向量嵌入模型,并返回向量检索器用于加入chain链
""" 向量检索 """ from langchain_chroma import Chroma import config_data as config class VectorStoreService: def __init__(self,embedding): # 嵌入模型的传入 self.embedding = embedding self.vector_store = Chroma( collection_name = config.collection_name, embedding_function = self.embedding, persist_directory = config.persist_directory, ) # 返回向量检索器,方便加入chain def get_retriever(self): # {"k",config.similarity_threshold}:表示检索返回匹配的文档数量 return self.vector_store.as_retriever(search_kwargs = {"k":config.similarity_threshold})
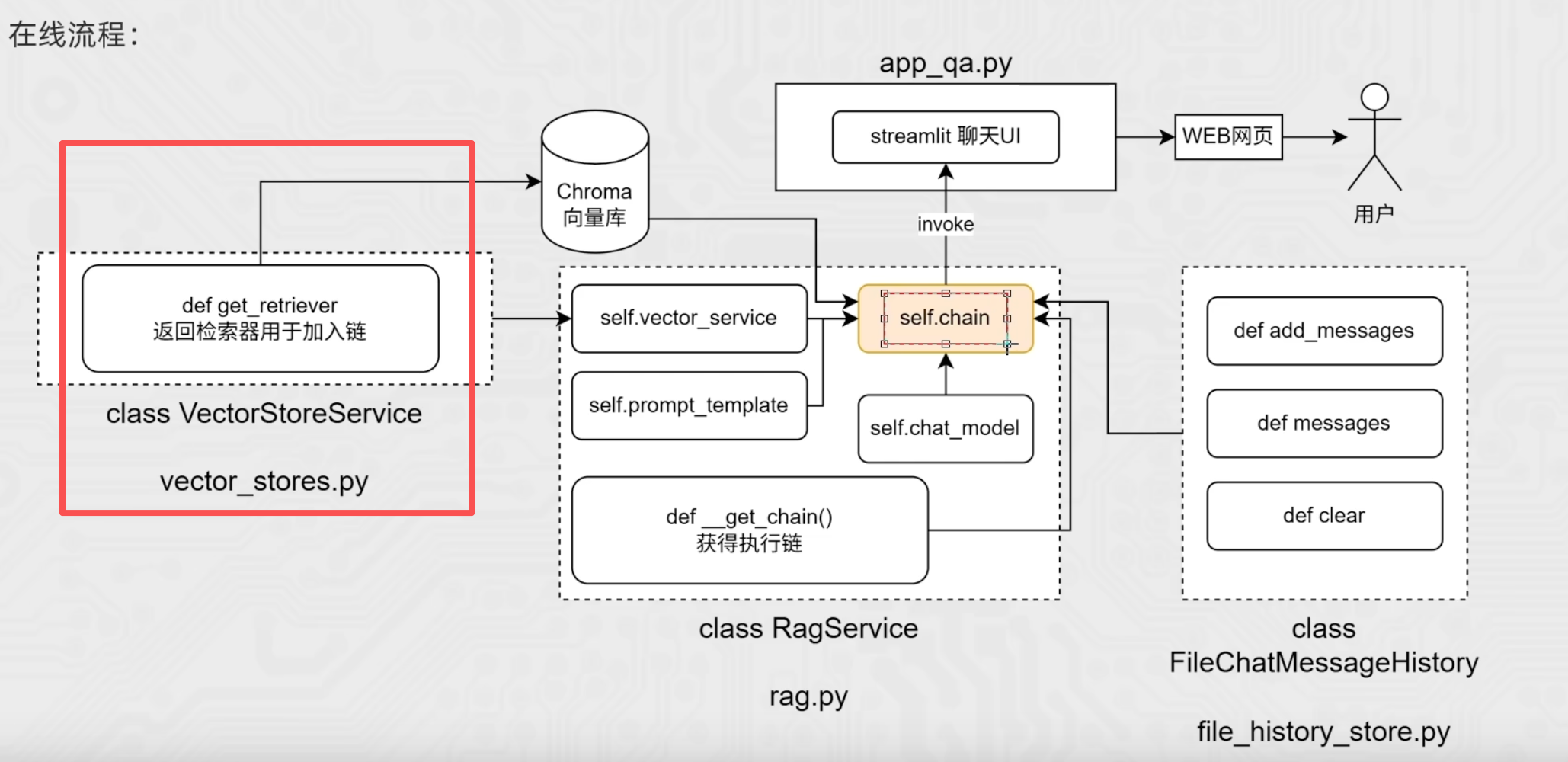
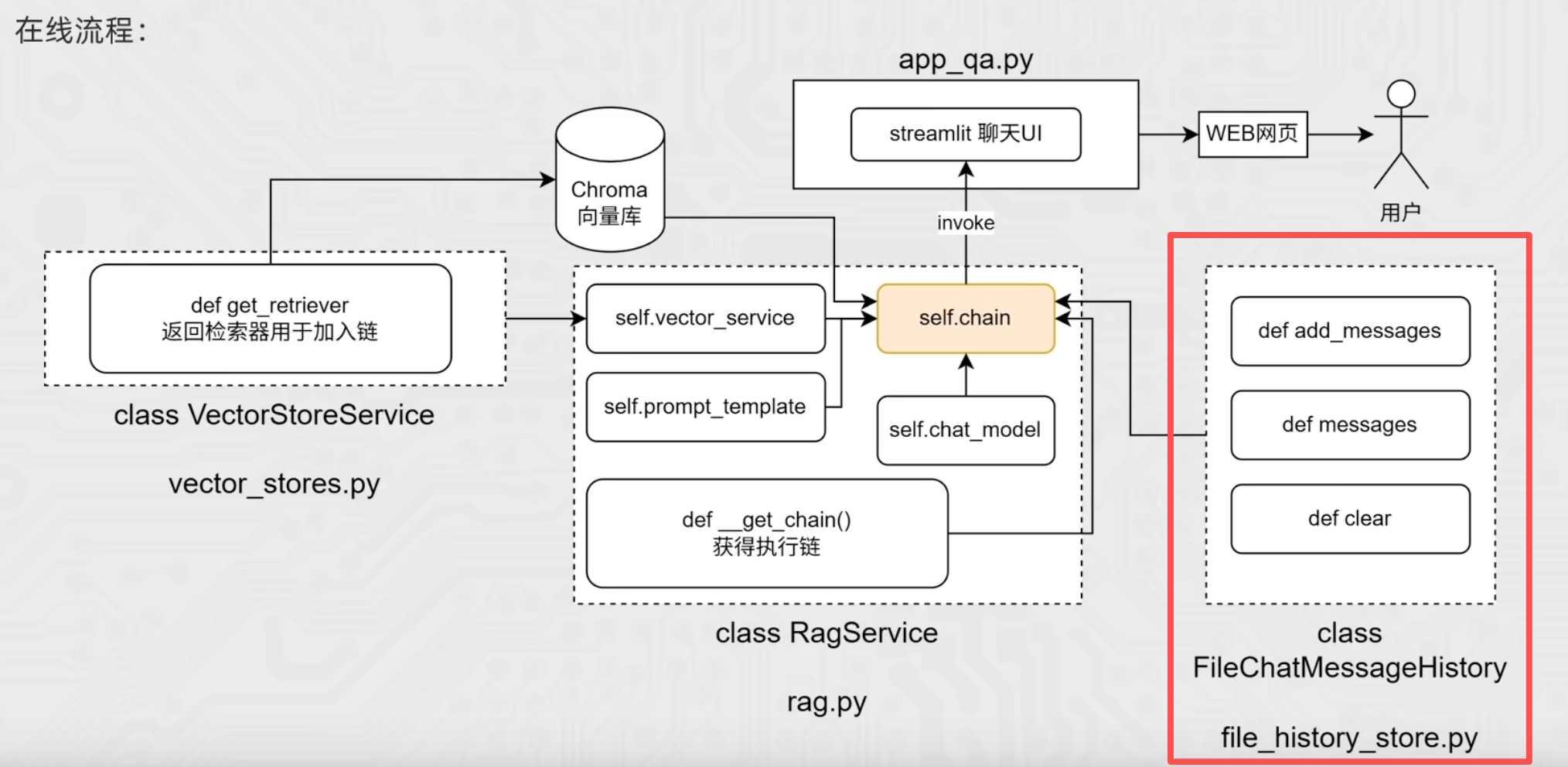
(2)RAG核心代码:chain链
这一部分就是我们前面所学的chain链搭建
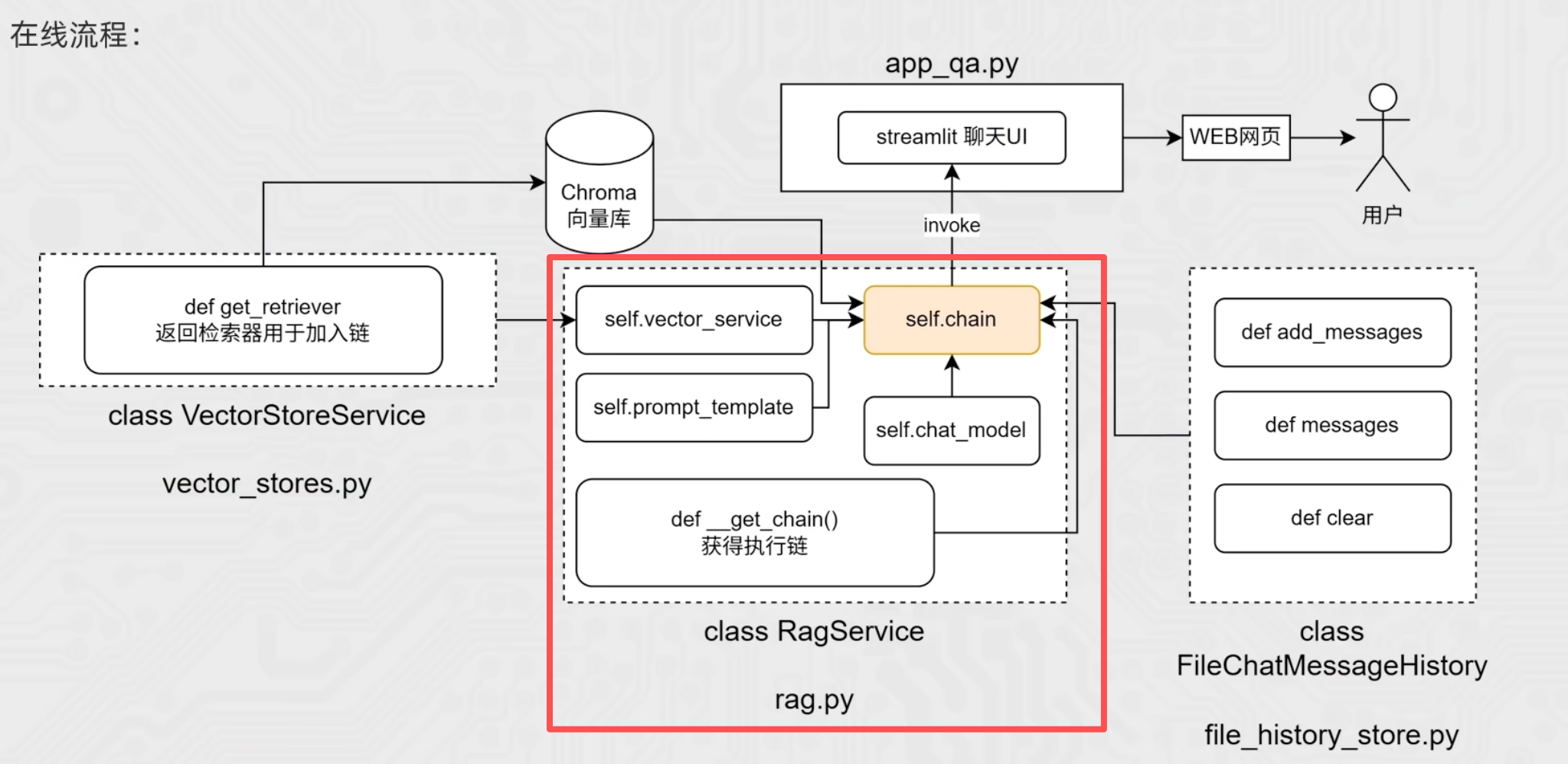
创建文件rag.py
- 首先初始化:嵌入模型、提示词模板、聊天模型、chain链
- 在_get_chain()方法中搭建最终执行链
- 注意向量检索器入链因为格式问题,不能简单地将链写成:chain = retriever | prompt
- 而需要参考我们之前学习的【向量检索器入链】这一小节,对chain链进行改造
实现代码如下:
""" rag核心代码:chain链的实现 """ from langchain_community.chat_models import ChatTongyi from langchain_community.embeddings import DashScopeEmbeddings from langchain_core.documents import Document from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, format_document from langchain_core.runnables import RunnablePassthrough from vector_stores import VectorStoreService import config_data as config class RagService: def __init__(self): # 嵌入模型 self.vector_service = VectorStoreService( embedding = DashScopeEmbeddings(model = config.embedding_model_name) ) # 提示词模板 self.prompt_template = ChatPromptTemplate.from_messages( [ ("system", "以我提供的已知参考资料为主," "简洁和专业的回答用户问题。参考资料:{context}。"), ("user", "请回答用户提问:{input}") ] ) # 聊天模型 self.chat_model = ChatTongyi(model = config.chat_model_name) self.chain = self._get_chain() # 获取最终执行链 def _get_chain(self): # 获取检索器对象 retriever = self.vector_service.get_retriever() # 格式转换:把retriever的输出【list[Document]】格式化成【str】 def format_document(docs: list[Document]): if not docs: return "无相关资料" formatted_str = "" for doc in docs: formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n" return formatted_str """ retriever的输出内容是:向量库的检索结果,格式是list[Document] 而prompt提示词模板的输入内容是:用户提问+向量库的检索结果,格式是dict 如果chain链直接写成:chain = retriever | prompt 显然格式和内容都对接不上 因此需要对chain链进行改造: 1.RunnablePassthrough()是一个Runnable对象,作用是:原样传递输入数据,因为只有Runnable子类对象才能入链,所以RunnablePassthrough()的作用其实是为了用户输入可以入链(否则字符串格式无法入链) 2.format_func的作用是:把retriever的输出【list[Document]】格式化成【str】,这样整体{"input": RunnablePassthrough(), "context": retriever | format_func}即包含【用户的提问 + 向量库的检索结果】,格式为【dict】 """ chain = ( { "input": RunnablePassthrough(), "context": retriever | format_document() } | self.prompt_template | self.chat_model | StrOutputParser() ) return chain
(3)历史会话记录功能
创建文件file_history_store.py
我们将之前学过的【会话记忆 - 长期记忆】中代码复制出来,获得file_history_story.py的完整代码:
""" 基于文件存储的聊天历史记录模板 继承自 BaseChatMessageHistory,实现将聊天记录持久化存储到本地文件 """ import os import json from typing import Sequence from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.messages import message_to_dict, BaseMessage, messages_from_dict # 获取历史记录的函数 def get_history(session_id): # 调用文件存储模板 return FileChatMessageHistory(session_id,"./chat_history") class FileChatMessageHistory(BaseChatMessageHistory): """ 初始化 FileChatMessageHistory 实例 """ def __init__(self, session_id, storage_path): self.session_id = session_id # 当前会话的唯一标识符 self.storage_path = storage_path # 文件存储的根目录 # 构建完整的文件路径:存储路径 + 会话ID作为文件名 self.file_path = os.path.join(self.storage_path, self.session_id) # 确保存储目录存在,如果不存在则创建(exist_ok=True表示目录已存在时不报错) os.makedirs(os.path.dirname(self.file_path), exist_ok=True) """ 【1】添加新消息 messages:参数的名字,代表要添加的消息。 :Sequence[BaseMessage]:类型注解,表示messages参数应是一个Sequence AIMessage、HumanMessage、SystemMessage 都是BaseMessage的子类 -> None:类型注解,表示这个方法不返回任何值 """ def add_messages(self, messages: Sequence[BaseMessage]) -> None: # 1.获取已有的所有消息(调用 messages 属性) all_messages = list(self.messages) # self.messages 会调用 @property 修饰的 messages 方法 # 2.将新的消息追加到已有消息列表后面 all_messages.extend(messages) # 3.格式转换:将【消息 -> 字典】,以便序列化为JSON # 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典 new_messages = [message_to_dict(message) for message in all_messages] """ 等价于: new_messages = [] for message in all_messages: d = message_to_dict(message) new_messages.append(d) """ # 4.将数据写入文件 with open(self.file_path, "w", encoding="utf-8") as f: json.dump(new_messages, f) """ 【2】获取当前会话的所有消息 -> List[BaseMessage]:类型注解,表示这个方法应该返回什么类型的数据 使用 @property 装饰器,让这个方法可以通过 self.messages访问 """ @property def messages(self) -> list[BaseMessage]: # 当前文件内: list[字典] try: with open(self.file_path, "r", encoding="utf-8") as f: # 文件内存储的是 list[字典],每个字典代表一条消息 messages_data = json.load(f) # 返回值就是:list[字典] # 格式转换:将【字典 -> 消息】 # 官方message_from_dict:字典 -> 单个消息对象(BaseMessage类实例) return messages_from_dict(messages_data) except FileNotFoundError: # 如果文件不存在(首次创建或已被删除),返回空列表 return [] """ 【3】清空当前会话的所有聊天记录 """ def clear(self) -> None: with open(self.file_path, "w", encoding="utf-8") as f: # 将一个空列表写入文件,相当于清空所有消息 json.dump([], f)接下来我们将修改rag.py代码,根据前面所学的【长期会话记忆】,将原有的chain链改造成带有历史记录功能的增强链。
chain = ( { "input": RunnablePassthrough(), "context": retriever | format_document } | self.prompt_template | self.chat_model | StrOutputParser() ) # 带有历史会话记忆功能的增强链 conversation_chain = RunnableWithMessageHistory( chain, get_history, input_messages_key="input", history_messages_key="history", ) return conversation_chain并修改提示词模板
# 提示词模板 self.prompt_template = ChatPromptTemplate.from_messages( [ ("system", "以我提供的已知参考资料为主," "简洁和专业的回答用户问题。参考资料:{context}。"), ("system", "并且我提供用户的对话历史记录如下:"), MessagesPlaceholder("history"), ("user", "请回答用户提问:{input}") ] )加入测试运行:
if __name__ == "__main__": # session_id 配置 session_config = { "configurable": { "session_id": "user_001", } } res = RagService().chain.invoke({"input": "我身高170厘米,尺码推荐"}, session_config) print(res)【1】增强chain链的格式转换问题(细节)
然而仅仅完成上面的修改,运行后仍会报错,原因是:
增强链conversation_chain中的RunnableWithMessageHistory,其输入要求是特定的字典dict格式:{"input" : "你好"},根据下面的数据流向图:
【改动1】需要在基础chain链的retriever前添加一个格式转换函数,使RunnableWithMessageHistory的输出和retriever的输入格式匹配:
# 格式转换1:将增强链中的RunnableWithMessageHistory输出的dict → str def format_for_retriever(value: dict) -> str: return value["input"] # 返回用户提问的问题,即返回键input的值
完成改动1,运行后仍然报错
实际上经过format_document()的输出格式如下图:
history字段实际上包含在input里,所以我们只需要把history抽取出来,重新封装即可
【改动2】需要在基础chain链的prompt_template前添加一个格式转换函数,使输出和prompt_template的输入格式匹配:
# 格式转换2:将format_document的输出:{'input':{'input':'','history':''},'context':""} # 抽取出{input, context, history} def format_for_prompt_template(value): new_value = {} new_value["input"] = value["input"]["input"] new_value["context"] = value["context"] new_value["history"] = value["input"]["history"] return new_value
经过这2处改动,历史会话增强链就能成功运行了,完整的rag.py代码:
""" rag核心代码:chain链的实现 """ from langchain_community.chat_models import ChatTongyi from langchain_community.embeddings import DashScopeEmbeddings from langchain_core.documents import Document from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, format_document, MessagesPlaceholder from langchain_core.runnables import RunnablePassthrough, RunnableWithMessageHistory, RunnableLambda from file_history_store import get_history from vector_stores import VectorStoreService import config_data as config class RagService: def __init__(self): # 嵌入模型 self.vector_service = VectorStoreService( embedding = DashScopeEmbeddings(model = config.embedding_model_name) ) # 提示词模板 self.prompt_template = ChatPromptTemplate.from_messages( [ ("system", "以我提供的已知参考资料为主," "简洁和专业的回答用户问题。参考资料:{context}。"), ("system", "并且我提供用户的对话历史记录如下:"), MessagesPlaceholder("history"), ("user", "请回答用户提问:{input}") ] ) # 聊天模型 self.chat_model = ChatTongyi(model = config.chat_model_name) self.chain = self._get_chain() # 获取最终执行链 def _get_chain(self): # 获取检索器对象 retriever = self.vector_service.get_retriever() # 格式转换:把retriever的输出【list[Document]】格式化成【str】 def format_document(docs: list[Document]): if not docs: return "无相关资料" formatted_str = "" for doc in docs: formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n" return formatted_str # 格式转换1:将增强链中的RunnableWithMessageHistory输出的dict → str def format_for_retriever(value: dict) -> str: return value["input"] # 返回用户提问的问题,即返回键input的值 # 格式转换2:将format_document的输出:{'input':{'input':'','history':''},'context':""} # 抽取出{input, context, history} def format_for_prompt_template(value): new_value = {} new_value["input"] = value["input"]["input"] new_value["context"] = value["context"] new_value["history"] = value["input"]["history"] return new_value """ retriever的输出内容是:向量库的检索结果,格式是list[Document] 而prompt提示词模板的输入内容是:用户提问+向量库的检索结果,格式是dict 如果chain链直接写成:chain = retriever | prompt 显然格式和内容都对接不上 因此需要对chain链进行改造: 1.RunnablePassthrough()是一个Runnable对象,作用是:原样传递输入数据,因为只有Runnable子类对象才能入链,所以RunnablePassthrough()的作用其实是为了用户输入可以入链(否则字符串格式无法入链) 2.format_func的作用是:把retriever的输出【list[Document]】格式化成【str】,这样整体{"input": RunnablePassthrough(), "context": retriever | format_func}即包含【用户的提问 + 向量库的检索结果】,格式为【dict】 """ chain = ( { "input": RunnablePassthrough(), "context": RunnableLambda(format_for_retriever) | retriever | format_document } | RunnableLambda(format_for_prompt_template) | self.prompt_template | self.chat_model | StrOutputParser() ) # 带有历史会话记忆功能的增强链 conversation_chain = RunnableWithMessageHistory( chain, get_history, input_messages_key="input", history_messages_key="history", ) return conversation_chain if __name__ == "__main__": # session_id 配置 session_config = { "configurable": { "session_id": "user_001", } } res = RagService().chain.invoke({"input": "我身高170厘米,尺码推荐"}, session_config) print(res)





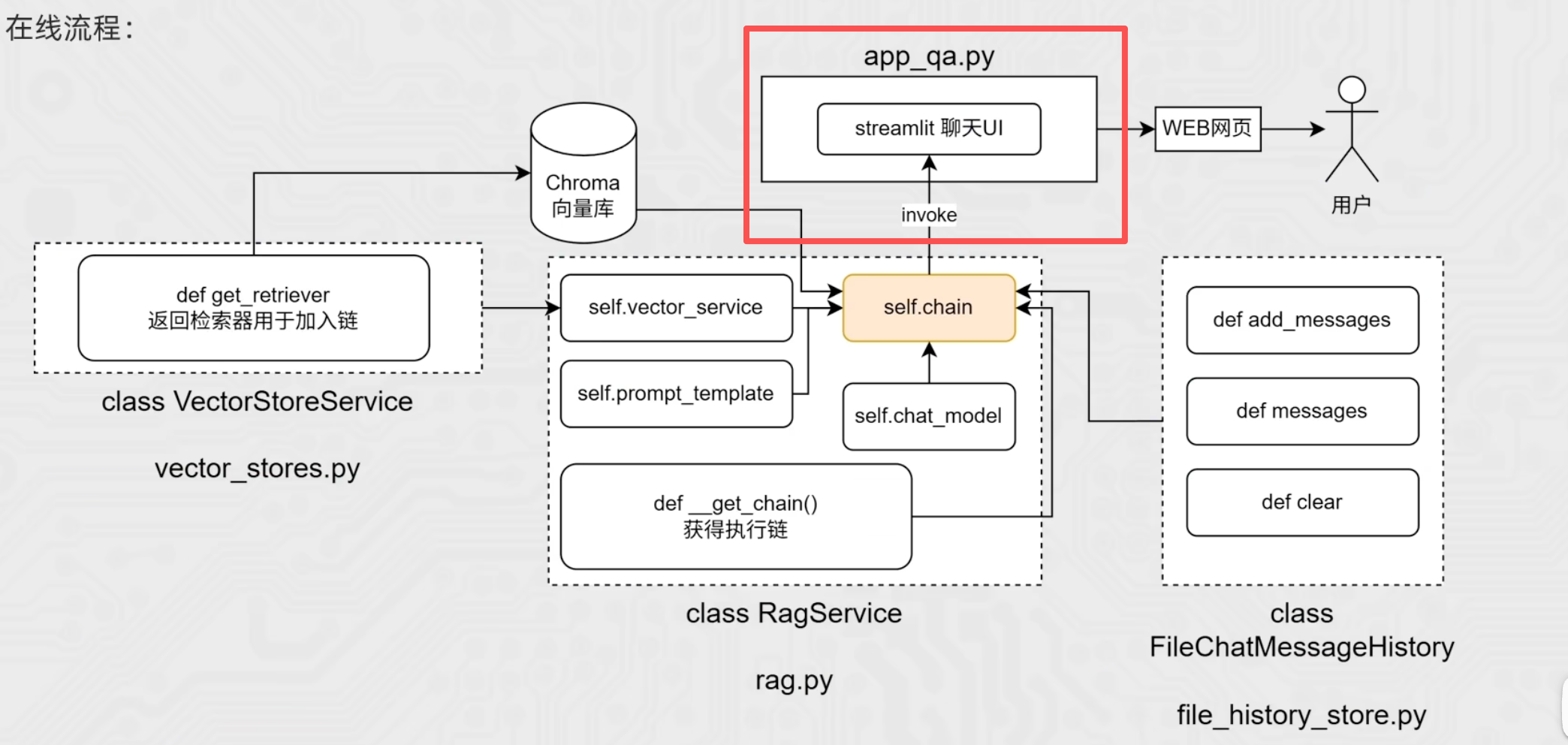
(4)聊天页面开发
新建文件app_qa.py
终端启动streamlit
先利用streamlit搭建一个初始的聊天页面框架
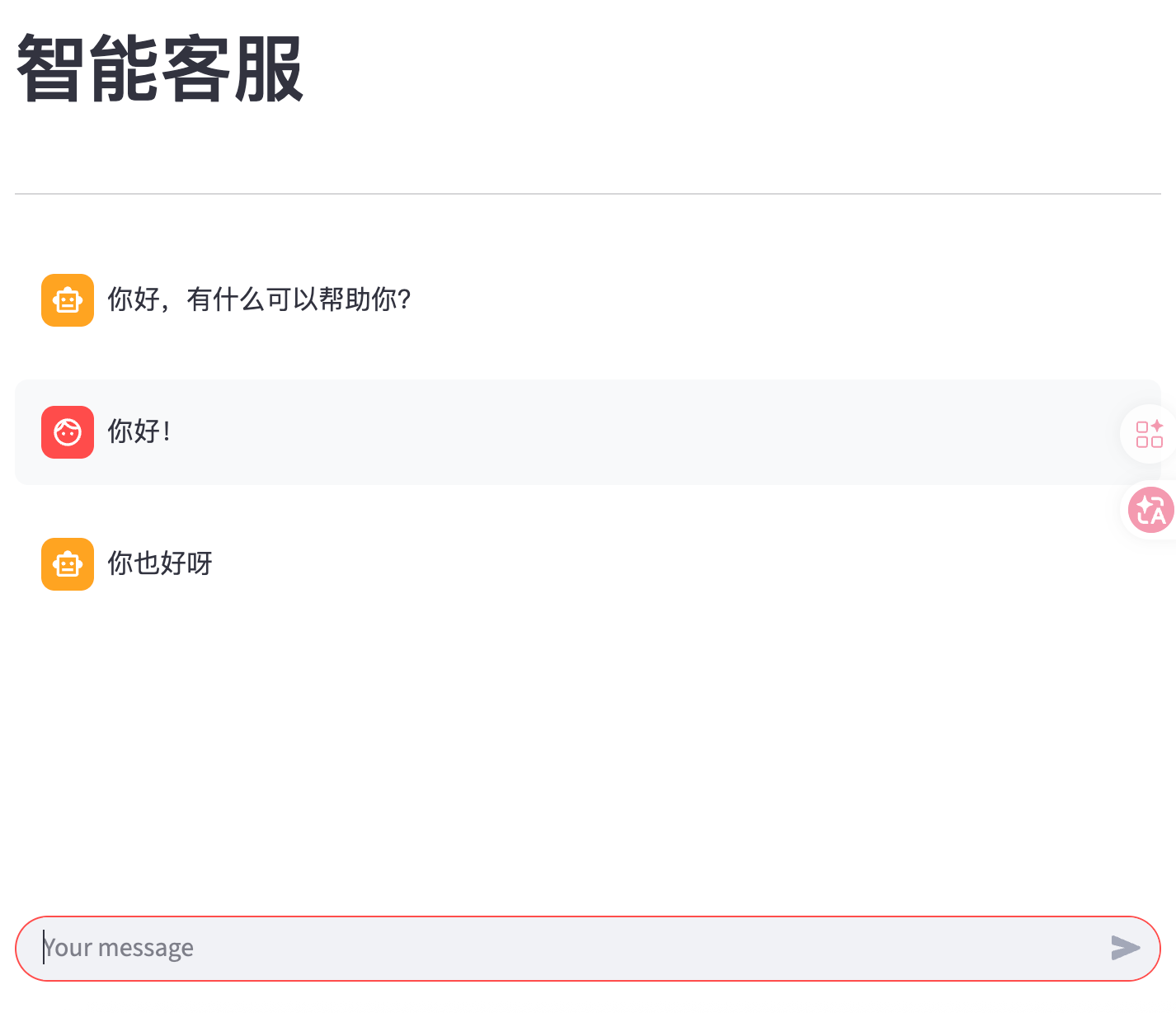
import streamlit as st import time # 标题 st.title("智能客服") st.divider() # 分隔符 # 初始化聊天记录 (session_state用于在页面刷新时保持数据) if "message" not in st.session_state: st.session_state["message"] = [{"role": "assistant", "content": "你好,有什么可以帮助你?"}] # 渲染已有的聊天记录 # 遍历session_state中存储的所有消息 for message in st.session_state["message"]: st.chat_message(message["role"]).write(message["content"]) # st.chat_message():根据角色显示对应的消息气泡 # .write():在气泡内写入消息内容 # 在页面最下方提供用户输入栏 prompt = st.chat_input() # 当用户输入内容并按下回车后,执行以下代码 if prompt: # 在页面显示用户的提问 st.chat_message("user").write(prompt) # 将这条用户消息存入聊天记录 st.session_state["message"].append({"role": "user", "content": prompt}) with st.spinner("AI思考中..."): time.sleep(1) # 在页面显示AI的回复 st.chat_message("assistant").write("你也好呀") # 将AI的回复存入聊天记录 st.session_state["message"].append({"role": "assistant", "content": "你也好呀"})
【1】一次性输出invoke
接下来我们要将前面写好的RAG功能与该页面相结合:
【复习】streamlit的特性是:当web页面元素发生变化,则代码重新执行一遍,而session_state用于在页面刷新时保持数据,因此我们调用之前编写的RagService()时,通过st.session_state["rag"]的方式存储起来,这样web页面即使发生变化,也不需要重建RagService()对象。
代码如下:
import streamlit as st import time from rag import RagService import config_data as config # 标题 st.title("智能客服") st.divider() # 分隔符 rag_service = RagService() # 初始化聊天记录 (session_state用于在页面刷新时保持数据) if "message" not in st.session_state: st.session_state["message"] = [{"role": "assistant", "content": "你好,有什么可以帮助你?"}] # 维护rag实例对象(session_state用于在页面刷新时保持数据) if "rag" not in st.session_state: st.session_state["rag"] = RagService() # 渲染已有的聊天记录 # 遍历session_state中存储的所有消息 for message in st.session_state["message"]: st.chat_message(message["role"]).write(message["content"]) # st.chat_message():根据角色显示对应的消息气泡 # .write():在气泡内写入消息内容 # 在页面最下方提供用户输入栏 prompt = st.chat_input() # 当用户输入内容并按下回车后,执行以下代码 if prompt: # 在页面显示用户的提问 st.chat_message("user").write(prompt) # 将这条用户消息存入聊天记录 st.session_state["message"].append({"role": "user", "content": prompt}) with st.spinner("AI思考中..."): # 调用rag的chain链,获取ai回复 res = st.session_state["rag"].chain.invoke({"input": prompt}, config.session_config) # 在页面显示AI的回复 st.chat_message("assistant").write(res) # 将AI的回复存入聊天记录 st.session_state["message"].append({"role": "assistant", "content": res})此时再运行,可以看到AI能够结合向量库的资料进行回答
【2】流式输出stream
再复习一下:
- invoke方法:一次型返回完整结果
- stream方法:逐段返回结果,流式输出
我们需要改造代码,使AI实现流式输出
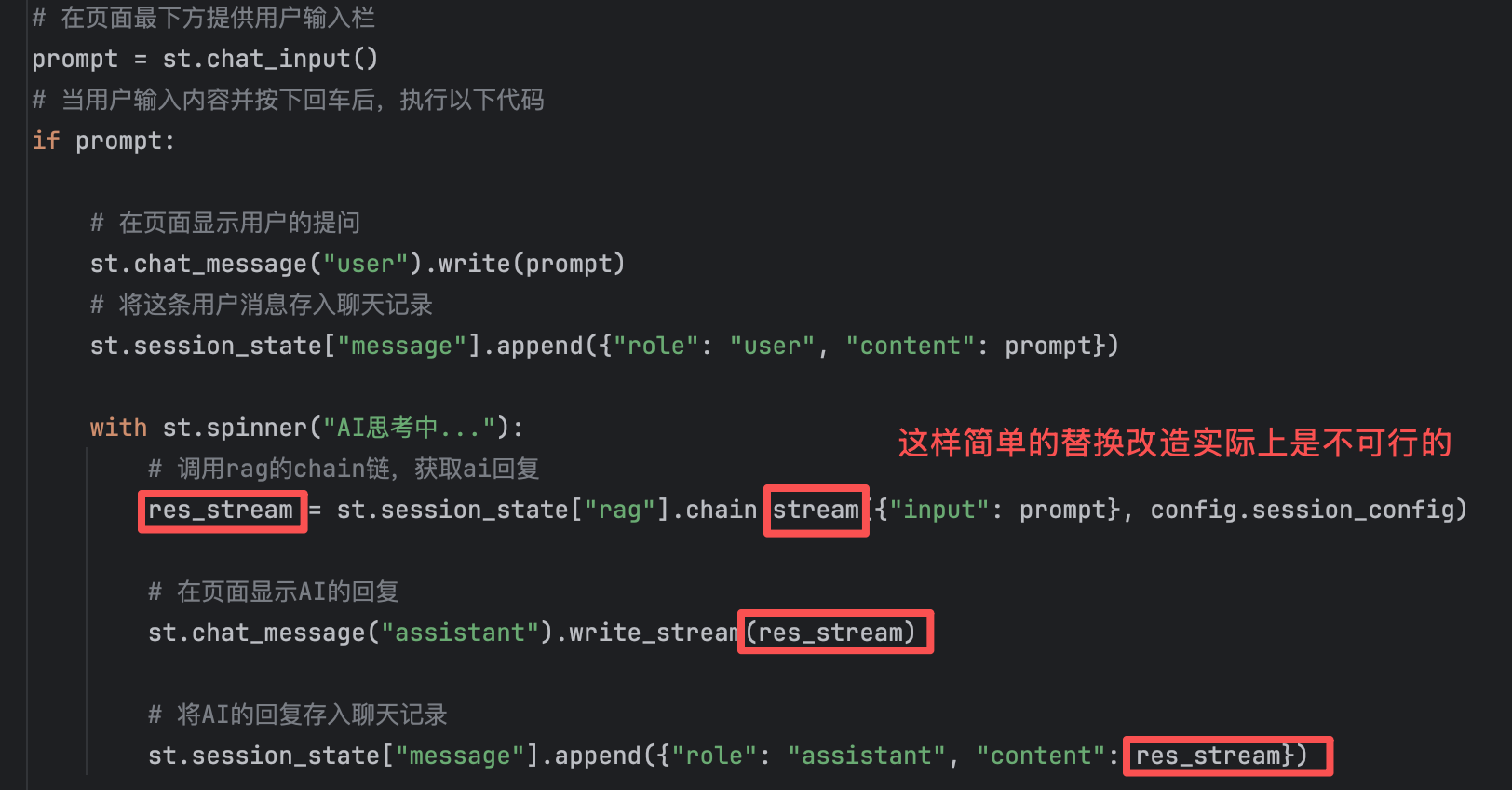
按惯性思维考虑,是不是只需要把invoke方法替换成stream方法即可?但这样实际是不可行的,会出现类型不匹配的问题。
前两步的替换是没有问题的,关键是第三步【历史回复存储】存在问题
st.session_state["message"].append({"role": "assistant", "content": res_stream})
- 错误原因:st.session_state["message"]通常用于存储聊天记录。如果直接把 res_stream(即生成器对象)存进去,下次刷新页面时,程序试图读取 message时会得到一个无法被打印的对象,(因为res_stream是生成器,只能被消费一次)从而导致报错。
- 修正逻辑:需要创建一个列表,通过自定义函数将流中的内容拼接成完整的字符串,然后再存入列表,最后将列表存入 session_state。
改造后的代码:
if prompt: # 在页面显示用户的提问 st.chat_message("user").write(prompt) # 将这条用户消息存入聊天记录 st.session_state["message"].append({"role": "user", "content": prompt}) # 创建一个list,用于存储AI的流式回复 ai_res_list = [] with st.spinner("AI思考中..."): # 调用rag的chain链,获取ai流式回复 res_stream = st.session_state["rag"].chain.stream({"input": prompt}, config.session_config) # 用于捕获流式响应内容:一边从生成器获取数据并yield出去,一边将数据存入缓存列表 def capture(generator, cache_list): for chunk in generator: cache_list.append(chunk) yield chunk # yield:生成器逐步产生内容,当函数执行到 yield时:暂停执行,返回一个值,下次调用时:从上次暂停处继续 # 在页面显示AI的回复 st.chat_message("assistant").write_stream(capture(res_stream, ai_res_list)) # 将AI的回复存入聊天记录 st.session_state["message"].append({"role": "assistant", "content": "".join(ai_res_list)}) # "".join(ai_res_list) 拼接列表元素为字符串 # ["a","b","c"] "".join(list) -> abc # ["a","b","c"] ",".join(list) -> a,b,c为什么要用
capture函数?
res_stream是一次性的生成器,但我们需要:
用
write_stream()显示内容用
"".join()存储内容如果先显示,生成器就空了,无法存储;如果先存储,就无法显示
解决方案:
capture函数
在数据流经时复制一份到
ai_res_list同时让数据继续流向
write_stream()(通过yield逐步返回给write_stream)运行项目,成功实现流式输出!


四、Agent 智能体
1、什么是Agent?
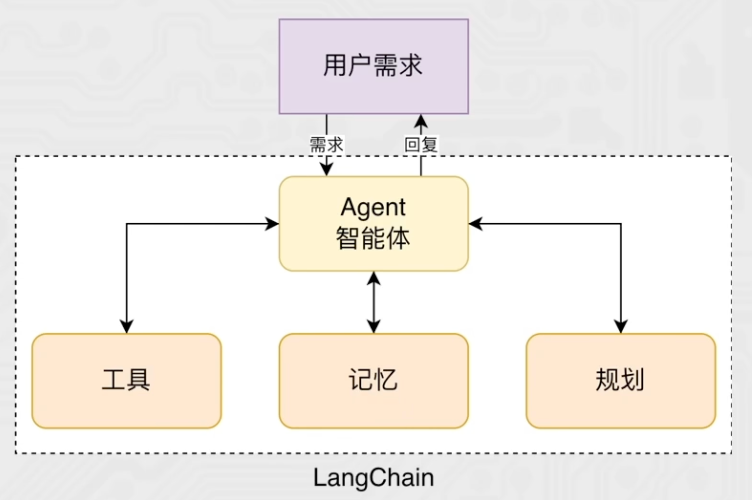
智能体(Agent) 是一种能够自主规划、决策、执行任务的组件,核心是让LLM根据任务需求,选择并调用工具,完成单靠模型自身无法解决的复杂问题。
没有Agent时,LLM 只能基于自身训练数据回答问题,遇到需要实时数据、复杂计算、外部工具调用的场景就会卡壳。
有了Agent后,LLM 就像一个指挥官,能思考任务步骤 → 选择合适工具 → 执行工具调用 → 根据结果调整策略,直到完成任务。
也就是说,Agent不仅仅能够回答你提出的问题,还能够用行动帮你解决问题。
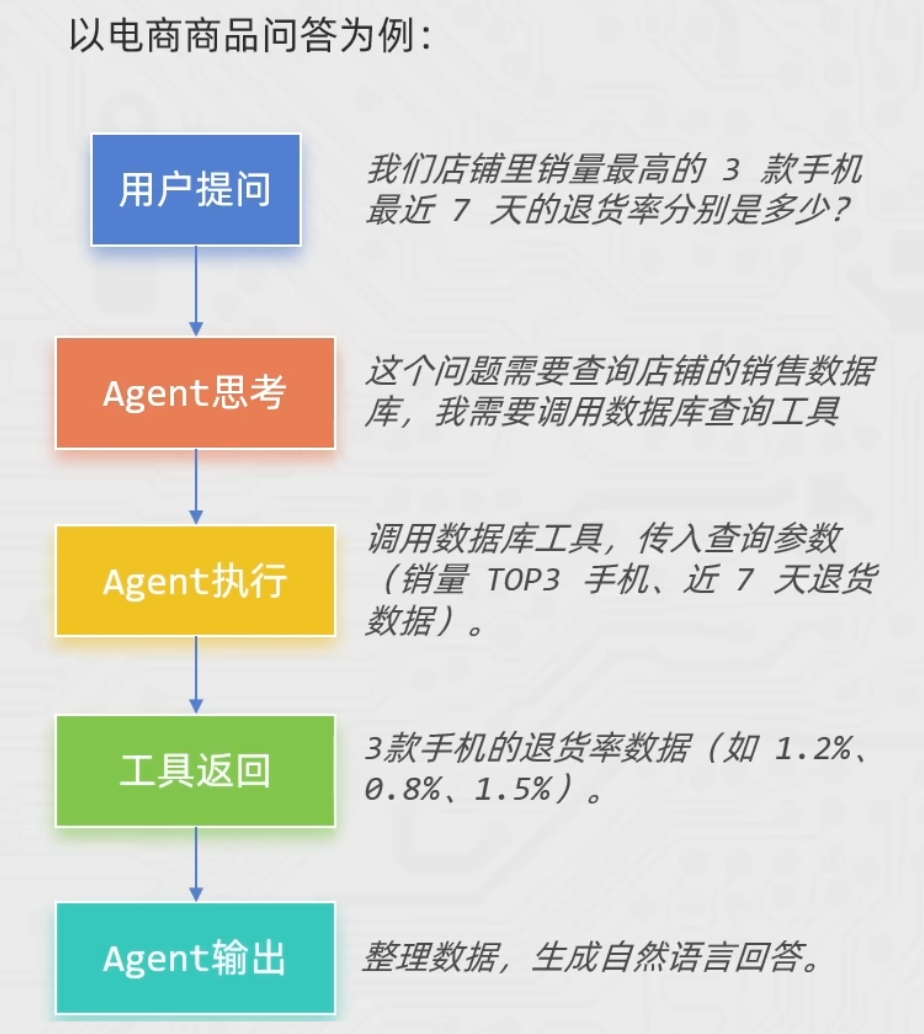
(1)ReAct模式
ReAct 是 Reasoning(推理)+ Acting(行动) 的缩写,是Agent的核心框架。它的核心思想是让 Agent 像人类一样,通过“思考问题 → 制定策略 → 执行行动 → 验证结果”的循环流程,解决仅靠模型自身无法完成的复杂问题。
🔄 ReAct 的循环流程
思考
- 分析问题,判断现有信息是否足够。
- 明确下一步:是否需要调用外部工具获取更多信息。
行动
执行思考阶段制定的策略。
基于模型决策结果,调用工具获取信息。
观察
获取行动的结果,提取有效信息。
判断工具是否正常工作,为下一轮思考提供信息。
(再)思考 → (再)行动 → (再)观察 → 循环往复直到结束
如果任务未完成,回到思考阶段,根据新信息调整策略,继续循环。
直到任务完成,输出最终结果。
2、middleware中间件
中间件是在请求/响应处理流程中,对请求或响应进行拦截、增强、监控、日志记录等操作的组件。
在 LangChain 框架中,中间件通过钩子(Hooks)机制实现拦截,允许在不修改核心逻辑的前提下,对 Agent的执行过程进行扩展(如日志、权限校验、性能监控、缓存、重试等)。
(1)中间件类型
LangChain 中间件分为节点式钩子和 包装式钩子两类:
1. 节点式钩子(执行点顺序拦截)
在特定执行阶段前后进行拦截:
before_agent:Agent 执行之前拦截。
after_agent:Agent 执行之后拦截。
before_model:模型执行之前拦截。
after_model:模型执行之后拦截。2. 包装式钩子(针对工具/模型的调用拦截)
在工具或模型的每一次调用过程中进行拦截:
wrap_tool_call:每个工具调用时拦截。
wrap_model_call:每个模型调用时拦截。(2)自定义中间件
from langchain.agents import create_agent, AgentState from langchain.agents.middleware import before_agent, after_agent, before_model, after_model, wrap_model_call, \ wrap_tool_call from langchain_community.chat_models.tongyi import ChatTongyi from langchain_core.tools import tool from langgraph.runtime import Runtime @tool(description="查询天气,传入城市名称字符串,返回字符串天气信息") def get_weather(city: str) -> str: return f"{city}天气:晴天" """ 1. agent执行前 2. agent执行后 3. model执行前 4. model执行后 5. 工具执行中 6. 模型执行中 """ @before_agent def log_before_agent(state: AgentState, runtime: Runtime) -> None: # agent执行前会调用这个函数并传入state和runtime两个对象 print(f"[before agent]agent启动,并附带{len(state['messages'])}消息") @after_agent def log_after_agent(state: AgentState, runtime: Runtime) -> None: print(f"[after agent]agent结束,并附带{len(state['messages'])}消息") @before_model def log_before_model(state: AgentState, runtime: Runtime) -> None: print(f"[before_model]模型即将调用,并附带{len(state['messages'])}消息") @after_model def log_after_model(state: AgentState, runtime: Runtime) -> None: print(f"[after_model]模型调用结束,并附带{len(state['messages'])}消息") @wrap_model_call def model_call_hook(request, handler): print("模型调用啦") return handler(request) @wrap_tool_call def monitor_tool(request, handler): print(f"工具执行:{request.tool_call['name']}") print(f"工具执行传入参数:{request.tool_call['args']}") return handler(request) agent = create_agent( model=ChatTongyi(model="qwen3-max"), tools=[get_weather], middleware=[log_before_agent, log_after_agent, log_before_model, log_after_model, model_call_hook, monitor_tool] ) res = agent.invoke({"messages": [{"role": "user", "content": "北京今天的天气如何,如何穿衣"}]}) print("**********\n", res)

五、Agent 项目实战
智扫通Agent项目是一个面向消费者的智能客服系统,旨在为用户提供全周期的扫地机器人相关服务。
(1)智能问答服务:
处理购买前的产品咨询(如功能、价格、对比等)。
解决购买后的使用问题(如操作指导、故障处理、维护建议等)。
基于RAG技术,从知识库中检索准确信息并生成自然语言回答,确保响应及时且可靠。
(2)使用报告与优化建议生成:
针对已购买用户,自动分析扫地机器人的使用数据(如清洁频率、耗材状态、错误日志等)。
生成个性化报告,总结使用情况并提供优化建议(如清洁计划调整、部件更换提醒等)。
支持用户主动查询报告或系统定期推送,帮助用户最大化产品价值。
(1)工具类开发
【1】路径工具
功能:提供相对路径,可获得绝对路径
为所有模块提供统一的路径基准点
避免因运行目录不同导致的路径混乱问题
""" 为整个工程提供统一的绝对路径 """ import os def get_project_root() -> str: """ 获取工程所在的根目录 :return: 字符串根目录 """ # 当前文件的绝对路径 current_file = os.path.abspath(__file__) # 获取工程的根目录,先获取文件所在的文件夹绝对路径 current_dir = os.path.dirname(current_file) # 获取工程根目录 project_root = os.path.dirname(current_dir) return project_root def get_abs_path(relative_path: str) -> str: """ 传递相对路径,得到绝对路径 :param relative_path: 相对 :return: 绝对路径 """ project_root = get_project_root() return os.path.join(project_root, relative_path) if __name__ == '__main__': print(get_abs_path("config/config.txt"))【2】日志工具
功能:提供统一的日志记录工具,支持控制台输出和文件保存
Handler:Handler定义了日志记录的输出位置,每个Handler对应一个输出目标,同一个Logger可以有多个Handler。
- StreamHandler - 控制台输出处理器
作用:将日志输出到控制台(标准输出)
输出位置:终端/命令行界面
FileHandler - 文件输出处理器
作用:将日志写入文件
输出位置:指定的日志文件
Handler的三大配置
# 1. 设置日志级别 - 控制哪些级别的日志会被处理 console_handler.setLevel(logging.INFO) # 只处理INFO及以上级别的日志 # 2. 设置格式 - 定义日志的输出格式 console_handler.setFormatter(DEFAULT_LOG_FORMAT) # 3. 绑定到Logger - 将处理器添加到日志器 logger.addHandler(console_handler)完整代码:
""" 日志配置模块 功能:提供统一的日志记录工具,支持控制台输出和文件保存 """ import logging from utils.path_tool import get_abs_path import os from datetime import datetime # 日志保存的根目录 LOG_ROOT = get_abs_path("logs") # 确保日志的目录存在 os.makedirs(LOG_ROOT, exist_ok=True) # 日志的格式配置 error info debug DEFAULT_LOG_FORMAT = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s' ) """ %(asctime)s - 日志记录的时间(自动生成的时间戳) %(name)s - 记录器的名称(通常是模块名) 示例:agent.core、data_processor %(levelname)s - 日志级别 示例:INFO、DEBUG、WARNING、ERROR、CRITICAL %(filename)s:%(lineno)d - 源代码文件名和行号 示例:agent.py:127(表示agent.py文件的第127行) %(message)s - 用户实际记录的日志消息内容 【示例】2026-03-01 14:30:25,123 - agent.core - INFO - agent.py:127 - 开始处理用户请求 """ # 获取配置好的日志记录器 def get_logger( name: str = "agent", # 日志器名称,默认为"agent" console_level: int = logging.INFO, # 控制台日志级别,默认为INFO file_level: int = logging.DEBUG, # 文件日志级别,默认为DEBUG log_file: str = None, # 自定义日志文件路径,默认按日期自动生成 ) -> logging.Logger: # 返回:logging.Logger对象,可直接使用logger.info()等方法记录日志 logger = logging.getLogger(name) # 创建指定名称的日志器 logger.setLevel(logging.DEBUG) # 避免重复添加Handler(防止多次调用时重复创建) # 如果已经创建了handler,就不需要再重复创建了,直接跳过下面的代码 if logger.handlers: return logger # 1. 控制台Handler - 用于实时查看日志 console_handler = logging.StreamHandler() # 创建控制台处理器 console_handler.setLevel(console_level) # 设置控制台输出级别 console_handler.setFormatter(DEFAULT_LOG_FORMAT) # 应用格式 logger.addHandler(console_handler) # 将处理器添加到日志器 # 2. 文件Handler - 用于持久化存储日志 if not log_file: # 如果未指定日志文件,则按日期自动生成 # 生成格式如:agent_20260301.log log_file = os.path.join(LOG_ROOT, f"{name}_{datetime.now().strftime('%Y%m%d')}.log") # 创建文件处理器,指定UTF-8编码支持中文 file_handler = logging.FileHandler(log_file, encoding='utf-8') file_handler.setLevel(file_level) # 设置文件记录级别 file_handler.setFormatter(DEFAULT_LOG_FORMAT) # 应用格式 logger.addHandler(file_handler) # 将处理器添加到日志器 return logger # 快捷获取日志器 logger = get_logger() if __name__ == '__main__': logger.info("信息日志") logger.error("错误日志") logger.warning("警告日志") logger.debug("调试日志")【3】配置文件工具
config_handler.py通过以下步骤访问YAML配置文件:
1. 路径生成:
- 使用
get_abs_path("config/rag.yml")获取配置文件的绝对路径。2. 文件读取:
使用
open(config_path, "r", encoding=encoding)以只读模式打开配置文件,指定编码为utf-8。3. YAML解析:
使用
yaml.load(f, Loader=yaml.FullLoader)将读取到的YAML文件内容解析为Python对象(通常是字典或列表)。4. 全局变量初始化:
在模块导入时,立即调用各个配置加载函数,并将返回的解析后的配置对象赋值给全局变量,如
rag_conf、chroma_conf、prompts_conf和agent_conf。5. 配置访问:
在其他模块中,可以通过导入这个模块并访问这些全局变量来获取配置信息。例如,通过
rag_conf["chat_model_name"]访问rag.yml中chat_model_name字段的值。""" YAML配置文件加载模块 功能:加载和管理Agent项目中的各种配置文件,支持YAML格式的配置解析 """ import yaml from utils.path_tool import get_abs_path # 加载RAG相关配置 def load_rag_config(config_path: str=get_abs_path("config/rag.yml"), encoding: str="utf-8"): with open(config_path, "r", encoding=encoding) as f: return yaml.load(f, Loader=yaml.FullLoader) # 使用yaml.load解析YAML内容 # Loader=yaml.FullLoader 使用完整的加载器,支持所有YAML特性 # 加载Chroma向量数据库相关配置 def load_chroma_config(config_path: str=get_abs_path("config/chroma.yml"), encoding: str="utf-8"): with open(config_path, "r", encoding=encoding) as f: return yaml.load(f, Loader=yaml.FullLoader) # 加载提示词Prompt模板配置 def load_prompts_config(config_path: str=get_abs_path("config/prompts.yml"), encoding: str="utf-8"): with open(config_path, "r", encoding=encoding) as f: return yaml.load(f, Loader=yaml.FullLoader) # 加载Agent核心配置 def load_agent_config(config_path: str=get_abs_path("config/agent.yml"), encoding: str="utf-8"): with open(config_path, "r", encoding=encoding) as f: return yaml.load(f, Loader=yaml.FullLoader) # 在模块导入时立即加载所有配置,提供全局访问 rag_conf = load_rag_config() # RAG配置对象 chroma_conf = load_chroma_config() # Chroma配置对象 prompts_conf = load_prompts_config() # 提示词配置对象 agent_conf = load_agent_config() # Agent核心配置对象 if __name__ == '__main__': print(rag_conf["chat_model_name"])【4】文件处理工具
""" 文件处理工具 """ import os import hashlib from utils.logger_handler import logger from langchain_core.documents import Document from langchain_community.document_loaders import PyPDFLoader, TextLoader # 获取文件的md5的十六进制字符串 def get_file_md5_hex(filepath: str): if not os.path.exists(filepath): logger.error(f"[md5计算]文件{filepath}不存在") return if not os.path.isfile(filepath): logger.error(f"[md5计算]路径{filepath}不是文件") return md5_obj = hashlib.md5() # MD5算法具有累积性:可以分多次输入数据,最终结果与一次性输入所有数据相同 # 如果文件过大,则分块进行更新md5值操作,分块得到的md5值与直接传入整个文件得到的md5值一样 chunk_size = 4096 # 4KB分片,避免文件过大爆内存 try: with open(filepath, "rb") as f: # 必须二进制读取 while chunk := f.read(chunk_size): md5_obj.update(chunk) """ chunk = f.read(chunk_size) while chunk: md5_obj.update(chunk) chunk = f.read(chunk_size) """ md5_hex = md5_obj.hexdigest() # 转化为16进制 return md5_hex except Exception as e: logger.error(f"计算文件{filepath}md5失败,{str(e)}") return None # 返回文件夹内的文件列表(允许的文件后缀) def listdir_with_allowed_type(path: str, allowed_types: tuple[str]): files = [] if not os.path.isdir(path): # 检查路径是否为有效文件夹 logger.error(f"[listdir_with_allowed_type]{path}不是文件夹") return allowed_types for f in os.listdir(path): if f.endswith(allowed_types): # 检查文件是否以允许的后缀结尾 files.append(os.path.join(path, f)) # 将文件的完整路径(目录路径+文件名)添加到结果列表 return tuple(files) # 将结果列表转换为元组并返回,元组不可变更安全 def pdf_loader(filepath: str, passwd=None) -> list[Document]: return PyPDFLoader(filepath, passwd).load() def txt_loader(filepath: str) -> list[Document]: return TextLoader(filepath, encoding="utf-8").load()【5】提示词加载工具
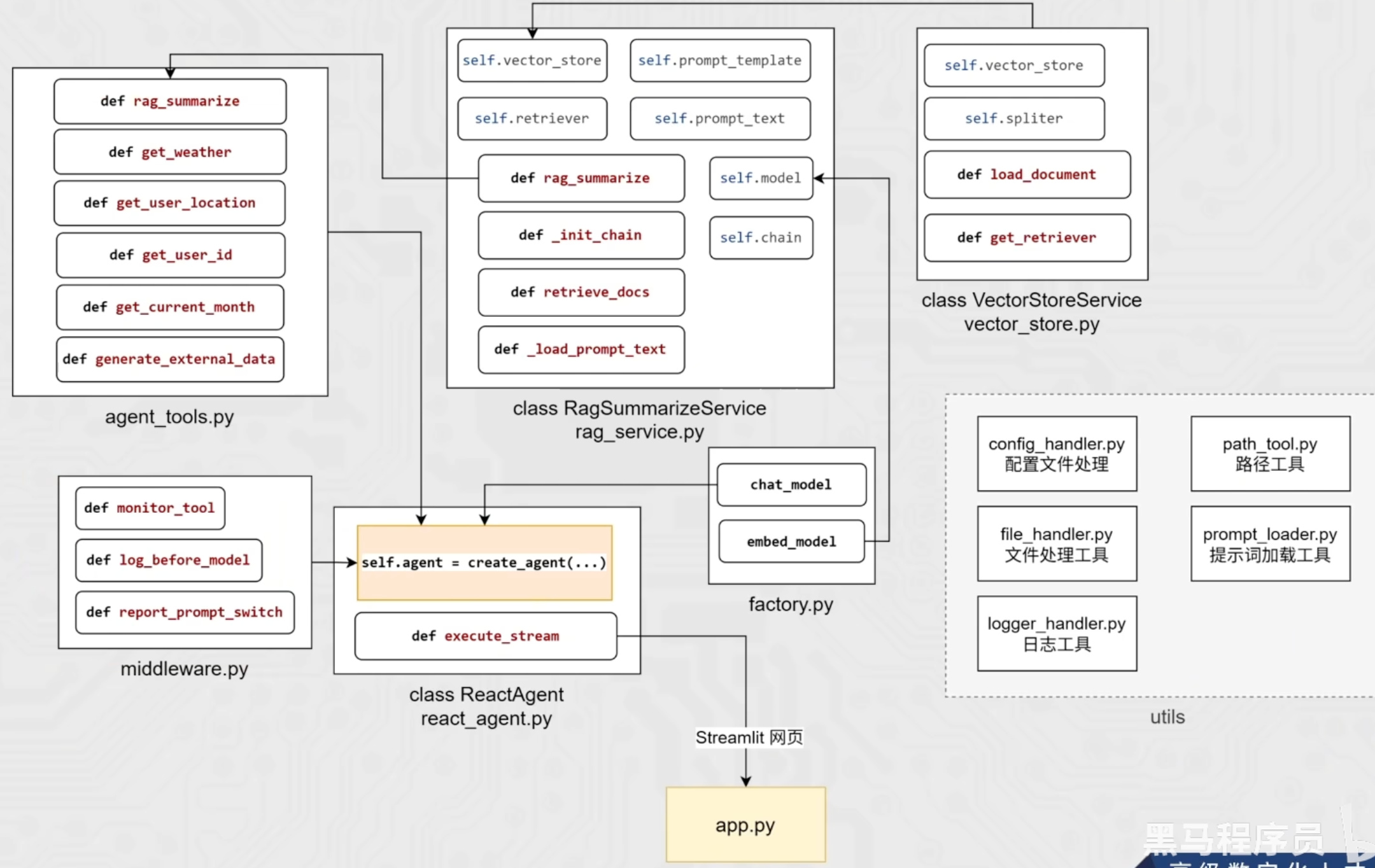
""" 系统提示词加载模块 本模块提供了从配置文件中加载不同类型提示词的功能。 主要用于加载系统提示词、RAG总结提示词以及报告生成提示词。 主要功能: 1. load_system_prompts() - 加载主系统提示词 2. load_rag_prompts() - 加载RAG总结提示词 3. load_report_prompts() - 加载报告生成提示词 """ from utils.config_handler import prompts_conf from utils.path_tool import get_abs_path from utils.logger_handler import logger # 加载主系统提示词 # 从配置文件中读取主提示词文件路径,并读取文件内容 def load_system_prompts(): try: # 获取主提示词文件路径的绝对路径 system_prompt_path = get_abs_path(prompts_conf["main_prompt_path"]) except KeyError as e: logger.error(f"[load_system_prompts]在yaml配置项中没有main_prompt_path配置项") raise e try: # 以UTF-8编码读取提示词文件内容 return open(system_prompt_path, "r", encoding="utf-8").read() except Exception as e: logger.error(f"[load_system_prompts]解析系统提示词出错,{str(e)}") raise e # 加载RAG总结提示词 # 从配置文件中读取RAG总结提示词文件路径,并读取文件内容。 def load_rag_prompts(): try: rag_prompt_path = get_abs_path(prompts_conf["rag_summarize_prompt_path"]) except KeyError as e: logger.error(f"[load_rag_prompts]在yaml配置项中没有rag_summarize_prompt_path配置项") raise e try: return open(rag_prompt_path, "r", encoding="utf-8").read() except Exception as e: logger.error(f"[load_rag_prompts]解析RAG总结提示词出错,{str(e)}") raise e # 加载报告生成提示词 # 从配置文件中读取报告生成提示词文件路径,并读取文件内容 def load_report_prompts(): try: report_prompt_path = get_abs_path(prompts_conf["report_prompt_path"]) except KeyError as e: logger.error(f"[load_report_prompts]在yaml配置项中没有report_prompt_path配置项") raise e try: return open(report_prompt_path, "r", encoding="utf-8").read() except Exception as e: logger.error(f"[load_report_prompts]解析报告生成提示词出错,{str(e)}") raise e if __name__ == '__main__': print(load_report_prompts())有了以上5种工具类的准备,后续Agent项目开发会变得更加方便!
还有一些config、prompts文件资料,在资料中,复制即可
(2)向量存储功能
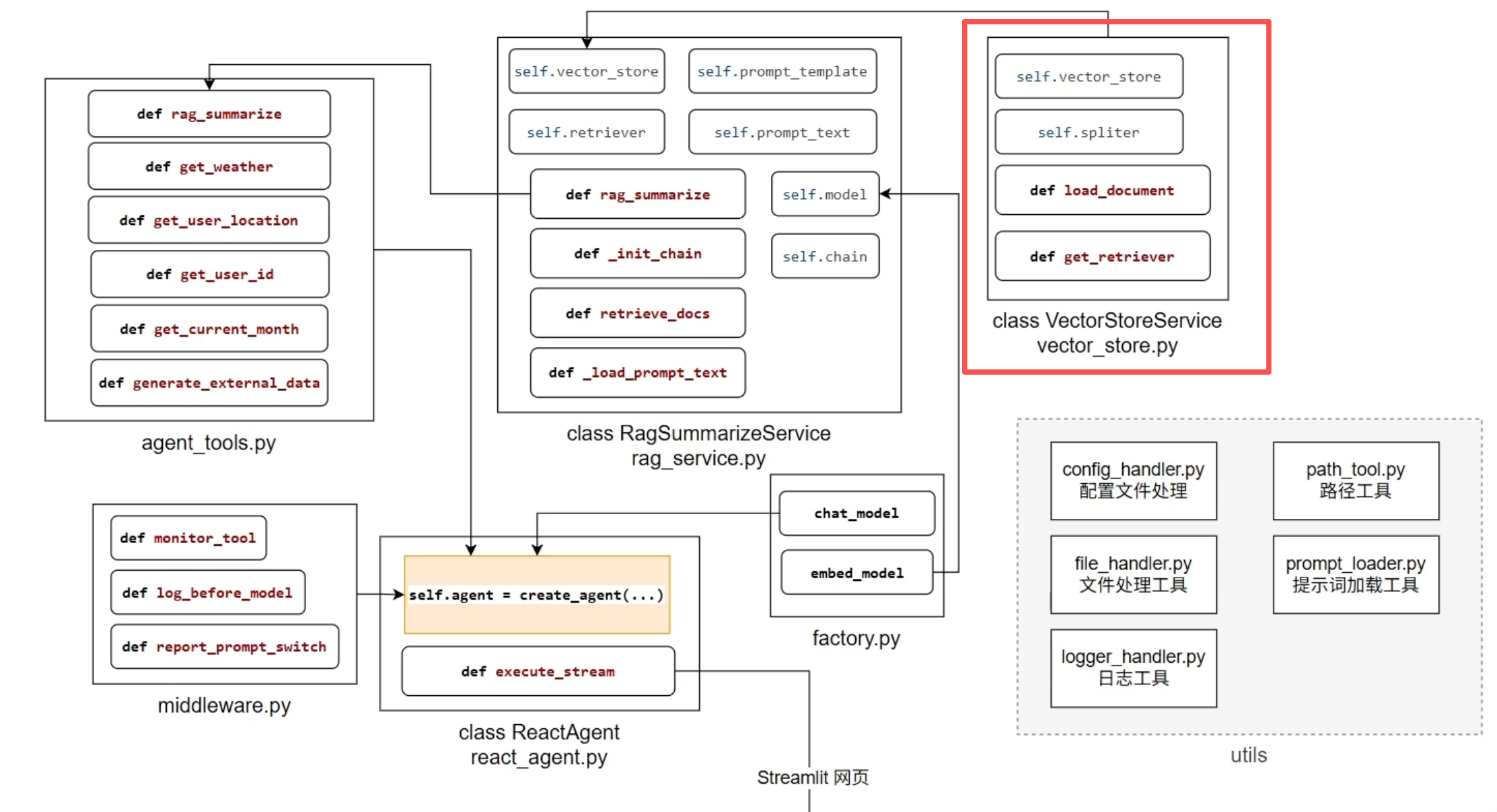
📍 VectorStoreService 工作流程总结
1、初始化阶段
创建向量数据库连接
配置集合名称(collection_name)
设置嵌入模型(embedding_function)
指定持久化存储路径(persist_directory)
初始化文本分割器
设置文本块大小(chunk_size)
设置块重叠大小(chunk_overlap)
定义分割符列表(separators)
2、文档加载流程
1. 扫描数据文件夹 ↓ 2. 筛选允许的文件类型(txt/pdf) ↓ 3. 计算文件MD5值 get_file_md5_hex(path) ↓ 4. 检查MD5是否已处理(去重)check_md5_he ↓ 5. 加载文档内容 get_file_documents ↓ 6. 分割文本为块 split_document: list[Document] = self.spliter.split_documents(documents) ↓ 7. 向量化并存储 self.vector_store.add_documents(split_document) ↓ 8. 记录MD5(防止重复处理)save_md5_hexvector_store.py完整代码:
from langchain_chroma import Chroma from langchain_core.documents import Document from utils.config_handler import chroma_conf from model.factory import embed_model from langchain_text_splitters import RecursiveCharacterTextSplitter from utils.path_tool import get_abs_path from utils.file_handler import pdf_loader, txt_loader, listdir_with_allowed_type, get_file_md5_hex from utils.logger_handler import logger import os """ 向量存储服务类,用于管理文档的向量化存储和检索 主要功能包括:文档加载、分块处理、向量化存储和相似性检索 """ class VectorStoreService: def __init__(self): # 初始化向量数据库连接 self.vector_store = Chroma( collection_name = chroma_conf["collection_name"], # 集合名称 embedding_function = embed_model, # 嵌入模型 persist_directory = chroma_conf["persist_directory"], # 持久化存储路径 ) # 初始化文本分割器 self.spliter = RecursiveCharacterTextSplitter( chunk_size = chroma_conf["chunk_size"], # 文本块大小 chunk_overlap = chroma_conf["chunk_overlap"], # 文本块重叠大小 separators = chroma_conf["separators"], # 分割符列表 length_function = len, ) # 获取检索器对象 def get_retriever(self): return self.vector_store.as_retriever(search_kwargs={"k": chroma_conf["k"]}) # 从数据文件夹内读取数据文件,转为向量存入向量库,要计算文件的MD5做去重 def load_document(self): # 【1】检查文件的MD5值是否已处理过 True表示已处理过,False表示未处理 def check_md5_hex(md5_for_check: str): # 如果MD5存储文件不存在,创建空文件 if not os.path.exists(get_abs_path(chroma_conf["md5_hex_store"])): # 创建文件 open(get_abs_path(chroma_conf["md5_hex_store"]), "w", encoding="utf-8").close() return False # md5 没处理过 # 否则打开MD5存储文件,逐行搜索传入的md5_for_check值是否存在,存在说明md5处理过,否则说明没处理过 with open(get_abs_path(chroma_conf["md5_hex_store"]), "r", encoding="utf-8") as f: for line in f.readlines(): line = line.strip() if line == md5_for_check: return True # md5 处理过 return False # md5 没处理过 # 【2】保存已处理文件的MD5值 def save_md5_hex(md5_for_check: str): with open(get_abs_path(chroma_conf["md5_hex_store"]), "a", encoding="utf-8") as f: f.write(md5_for_check + "\n") # a模式:追加写入MD5值 # 【3】根据文件类型加载文档内容 def get_file_documents(read_path: str): if read_path.endswith("txt"): return txt_loader(read_path) if read_path.endswith("pdf"): return pdf_loader(read_path) return [] # 扫描某个路径下的所有文件,只筛选出特定扩展名的文件列表 allowed_files_path: list[str] = listdir_with_allowed_type( get_abs_path(chroma_conf["data_path"]), tuple(chroma_conf["allow_knowledge_file_type"]), ) # 示例:allowed_files_path = [ # "/完整路径/data/报告.txt", # "/完整路径/data/说明书.pdf" # ] # 遍历所有允许的文件 for path in allowed_files_path: # 获取文件的MD5值 md5_hex = get_file_md5_hex(path) # 检查文件是否已处理过 if check_md5_hex(md5_hex): logger.info(f"[加载知识库]{path}内容已经存在知识库内,跳过") continue try: documents: list[Document] = get_file_documents(path) # 检查文档内容是否有效 if not documents: logger.warning(f"[加载知识库]{path}内没有有效文本内容,跳过") continue # 分割文档为块 split_document: list[Document] = self.spliter.split_documents(documents) if not split_document: logger.warning(f"[加载知识库]{path}分片后没有有效文本内容,跳过") continue # 将内容存入向量库 self.vector_store.add_documents(split_document) # 记录这个已经处理好的文件的md5,避免下次重复加载 save_md5_hex(md5_hex) logger.info(f"[加载知识库]{path} 内容加载成功") except Exception as e: # exc_info为True会记录详细的报错堆栈,如果为False仅记录报错信息本身 logger.error(f"[加载知识库]{path}加载失败:{str(e)}", exc_info=True) continue if __name__ == '__main__': vs = VectorStoreService() vs.load_document() retriever = vs.get_retriever() res = retriever.invoke("迷路") for r in res: print(r.page_content) print("-"*20)其中,嵌入模型的初始化通过工厂模式实现组件解耦。创建独立的
factory.py文件封装模型创建逻辑,该工厂类统一负责大语言模型和嵌入模型的实例化工作。其他服务类(如向量存储服务)通过依赖注入方式引入所需模型实例,直接从配置文件中读取模型配置参数。这种架构确保了业务逻辑与模型实现的分离:当需要更换底层模型时,仅需在配置文件中更新模型名称或参数,无需修改任何业务代码。
这种设计实现了配置驱动的模型管理,提升了系统的可维护性和可扩展性,是符合企业级应用规范的最佳实践。
factory.py代码如下:
from abc import ABC, abstractmethod from typing import Optional from langchain_core.embeddings import Embeddings from langchain_community.chat_models.tongyi import BaseChatModel from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.chat_models.tongyi import ChatTongyi from utils.config_handler import rag_conf """ 模型工厂模式实现 用于创建和管理大语言模型及嵌入模型的工厂类 """ class BaseModelFactory(ABC): # 抽象基础模型工厂类 定义模型创建的通用接口 @abstractmethod def generator(self) -> Optional[Embeddings | BaseChatModel]: """ 生成模型实例的抽象方法 子类必须实现此方法 Returns: Optional[Embeddings | BaseChatModel]: 返回嵌入模型或聊天模型实例 返回类型为可选,可能返回None """ pass # 聊天模型工厂类 用于创建聊天/生成式语言模型实例 class ChatModelFactory(BaseModelFactory): def generator(self) -> Optional[Embeddings | BaseChatModel]: return ChatTongyi(model=rag_conf["chat_model_name"]) # 嵌入模型工厂类 用于创建文本嵌入模型实例 class EmbeddingsFactory(BaseModelFactory): def generator(self) -> Optional[Embeddings | BaseChatModel]: return DashScopeEmbeddings(model=rag_conf["embedding_model_name"]) chat_model = ChatModelFactory().generator() embed_model = EmbeddingsFactory().generator()最后我们运行vector_store.py,成功把data目录下的文档存入向量数据库中:
(3)RAG总结功能
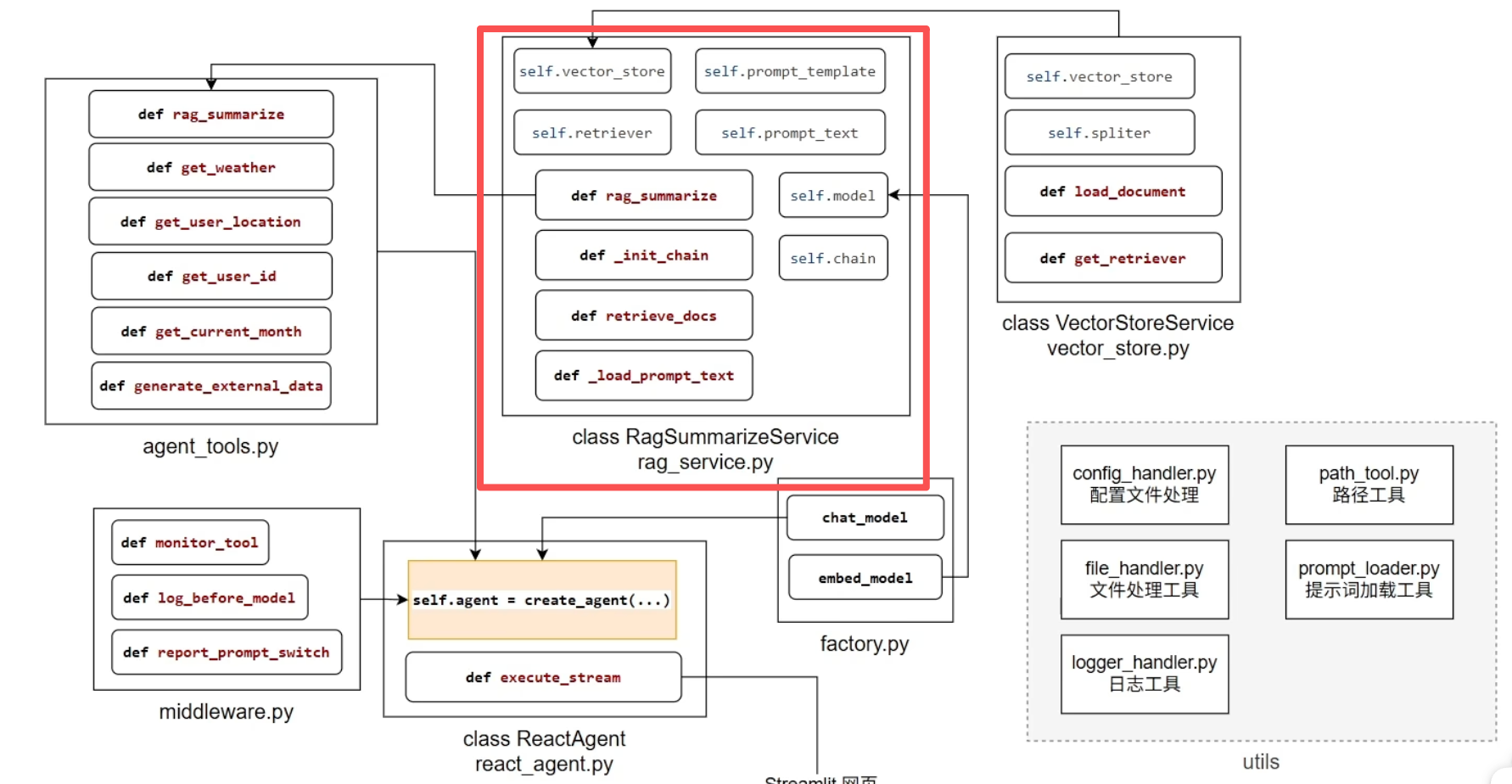
RagSummarizeService工作流程总结
1、初始化
# 创建RagSummarizeService实例时: 1. 初始化向量存储服务 2. 创建检索器(retriever) 3. 加载提示词模板 4. 获取聊天模型实例 5. 构建处理链2、创建chain链
chain = ( prompt_template # 模板:填充变量 | print_prompt # 调试:打印完整提示词 | model # 模型:大语言模型 | StrOutputParser()# 解析:输出转为字符串 )3、RAG总结执行流程
用户提问 ↓ rag_summarize("小户型适合哪些扫地机器人") ↓ 【1】检索相关文档 ↓ retriever.invoke("小户型适合哪些扫地机器人") ↓ 返回:list[Document] (格式化的参考文档列表) ↓ 【2】格式化上下文 ↓ for doc in documents: context += f"【参考资料1】: 内容:{doc.page_content} | 元数据:{doc.metadata}" ↓ 【3】调用模型链生成回复 ↓ chain.invoke({ "input": "小户型适合哪些扫地机器人", "context": "【参考资料1】: 内容:xxx扫地机器人... | 元数据:{...}" }) ↓ 返回:模型生成的总结回答rag_service.py完整代码如下:
""" RAG总结服务类 基于RAG的问答总结服务 工作流程:用户提问 -> 搜索参考资料 -> 提交给模型 -> 生成总结回复 """ from langchain_core.documents import Document from langchain_core.output_parsers import StrOutputParser from rag.vector_store import VectorStoreService from utils.prompt_loader import load_rag_prompts from langchain_core.prompts import PromptTemplate from model.factory import chat_model # 调试函数:打印提示词模板 用于开发时查看完整的提示词格式 def print_prompt(prompt): print("="*20) print(prompt.to_string()) print("="*20) return prompt class RagSummarizeService(object): def __init__(self): # 向量存储服务 - 用于文档检索 self.vector_store = VectorStoreService() # 检索器 - 负责相似性搜索 self.retriever = self.vector_store.get_retriever() # 提示词 - 加载RAG专用的提示模板文本 self.prompt_text = load_rag_prompts() # 提示模板 - 将文本模板转为可格式化对象 self.prompt_template = PromptTemplate.from_template(self.prompt_text) # 聊天模型 - 用于生成回复 self.model = chat_model self.chain = self._init_chain() def _init_chain(self): chain = self.prompt_template | print_prompt | self.model | StrOutputParser() return chain # 检索相关文档 从向量库中查找与查询最相关的文档 def retriever_docs(self, query: str) -> list[Document]: return self.retriever.invoke(query) # RAG总结主方法 完整的检索增强生成流程 def rag_summarize(self, query: str) -> str: #【1】检索相关文档 context_docs = self.retriever_docs(query) #【2】把retriever的输出【list[Document]】格式化成【str】 context = "" counter = 0 for doc in context_docs: counter += 1 # 格式化每篇参考资料,包含内容和元数据 context += f"【参考资料{counter}】: 参考资料:{doc.page_content} | 参考元数据:{doc.metadata}\n" #【3】调用模型链生成回复 return self.chain.invoke( { "input": query, "context": context, } ) if __name__ == '__main__': rag = RagSummarizeService() print(rag.rag_summarize("小户型适合哪些扫地机器人"))
(4)Agent 工具实现
Agent工具一览
- rag_summarize(): 从向量存储检索参考资料并进行摘要生成
- fetch_external_data(): 从外部CSV文件获取特定用户+月份的详细使用记录
- get_weather(): 获取城市天气信息(目前是模拟数据)
- get_user_location(): 随机返回用户所在城市
- get_user_id(): 随机返回用户ID
- get_current_month(): 随机返回月份
- fill_context_for_report(): 触发报告生成的上下文注入
import os from utils.logger_handler import logger from langchain_core.tools import tool from rag.rag_service import RagSummarizeService import random from utils.config_handler import agent_conf from utils.path_tool import get_abs_path rag = RagSummarizeService() user_ids = ["1001", "1002", "1003", "1004", "1005", "1006", "1007", "1008", "1009", "1010",] month_arr = ["2025-01", "2025-02", "2025-03", "2025-04", "2025-05", "2025-06", "2025-07", "2025-08", "2025-09", "2025-10", "2025-11", "2025-12", ] external_data = {} # 记录外部文件records.csv的最后修改时间 EXTERNAL_DATA_LAST_MODIFIED_TIME = None @tool(description="从向量存储中检索参考资料") def rag_summarize(query: str) -> str: return rag.rag_summarize(query) @tool(description="获取指定城市的天气,以消息字符串的形式返回") def get_weather(city: str) -> str: return f"城市{city}天气为晴天,气温26摄氏度,空气湿度50%,南风1级,AQI21,最近6小时降雨概率极低" @tool(description="获取用户所在城市的名称,以纯字符串形式返回") def get_user_location() -> str: return random.choice(["深圳", "合肥", "杭州"]) @tool(description="获取用户的ID,以纯字符串形式返回") def get_user_id() -> str: return random.choice(user_ids) @tool(description="获取当前月份,以纯字符串形式返回") def get_current_month() -> str: return random.choice(month_arr) # 从外部数据文件external-records.csv加载数据,并将其组织成嵌套字典结构 def generate_external_data(): """ 返回格式: { "user_id": { "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} ... }, "user_id": { "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} ... }, ... } """ global external_data, EXTERNAL_DATA_LAST_MODIFIED_TIME # 从配置中获取外部数据文件的路径 external_data_path = get_abs_path(agent_conf["external_data_path"]) if not os.path.exists(external_data_path): raise FileNotFoundError(f"外部数据文件{external_data_path}不存在") # 获取当前文件的最后修改时间 external_file_mtime = os.path.getmtime(external_data_path) # 检查是否需要重新加载数据的条件 need_reload = False if not external_data: # 如果内存字典为空,则需要进行首次加载 need_reload = True elif external_file_mtime > EXTERNAL_DATA_LAST_MODIFIED_TIME: # 如果文件被修改的时间晚于上次字典更新的时间,说明文件已更新,需要重新加载 need_reload = True if need_reload: # 如果外部数据文件external-records.csv发生更新,则需要清空字典,重新填充 external_data.clear() # 修改字典更新时间 EXTERNAL_DATA_LAST_MODIFIED_TIME = external_file_mtime with open(external_data_path, "r", encoding="utf-8") as f: # [1:] 从第一行开始读,跳过表头行 for line in f.readlines()[1:]: arr: list[str] = line.strip().split(",") # 解析CSV行中的各个字段,并去除可能的引号 user_id: str = arr[0].replace('"', "") feature: str = arr[1].replace('"', "") efficiency: str = arr[2].replace('"', "") consumables: str = arr[3].replace('"', "") comparison: str = arr[4].replace('"', "") time: str = arr[5].replace('"', "") # 如果该用户是第一次添加 if user_id not in external_data: external_data[user_id] = {} """ 将用户在某个月份的数据存入嵌套字典 存储格式: "user_id": { "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} "month" : {"特征": xxx, "效率": xxx, ...} ... }, """ external_data[user_id][time] = { "特征": feature, "效率": efficiency, "耗材": consumables, "对比": comparison, } @tool(description="从外部系统中【获取指定用户在指定月份的使用记录】,以纯字符串形式返回,如果未检索到返回空字符串") def fetch_external_data(user_id: str, month: str) -> str: generate_external_data() try: return external_data[user_id][month] except KeyError: logger.warning(f"[fetch_external_data]未能检索到用户:{user_id}在{month}的使用记录数据") return "" @tool(description="无入参,无返回值,调用后触发中间件自动为报告生成的场景动态注入上下文信息,为后续提示词切换提供上下文信息") def fill_context_for_report(): return "fill_context_for_report已调用" if __name__ == '__main__': print("=== 第一次调用 ===") result1 = fetch_external_data("1001", "2025-01") print(f"结果: {result1}") print(f"外部字典大小: {len(external_data)}") print("\n=== 第二次调用 ===") result2 = fetch_external_data("1001", "2025-01") print(f"结果: {result2}") print(f"外部字典大小: {len(external_data)}")
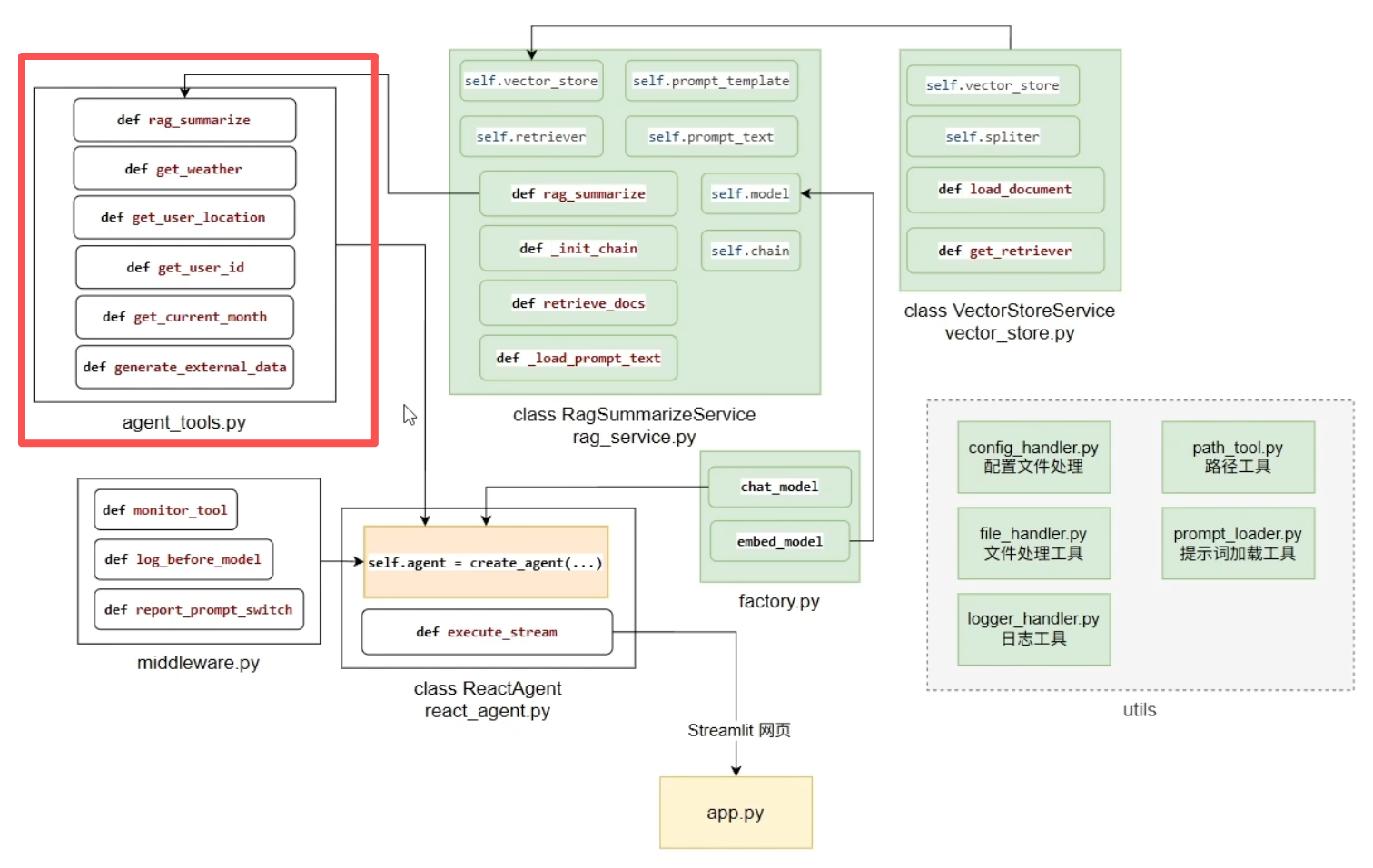
(5)中间件middleware
1、monitor_tool - 工具调用监控中间件
用户提问 → Agent思考 → 决定调用工具 → [中间件记录] → 实际调用工具 → [中间件记录结果] → 继续处理2、log_before_model - 模型调用前日志中间件
...处理过程 → 准备调用LLM → [中间件记录输入] → 调用LLM → 获取回复3、report_prompt_switch - 动态提示词切换中间件
普通问题 → 使用系统提示词 → 一般性回答 ↓ 检测到报告任务 → 设置report标志 → 下一次模型调用自动切换 → 使用报告专用提示词 → 格式化报告❓ 如何实现提示词动态切换?
在prompts文件夹下的main_prompt.txt中,我们能看到
4. 【报告生成强约束】 若明确判断用户核心需求为生成 / 查询个人使用报告,需严格遵循「获取用户 ID→获取报告月份→调用 fill_context_for_report 工具→调用 fetch_external_data 工具」的固定执行流程,fill_context_for_report 为报告生成的必调用前置工具,未调用该工具禁止执行后续的 fetch_external_data 工具调用及报告生成操作。若明确判断用户核心需求为生成/查询个人使用报告,需严格遵循「获取用户 ID→获取报告月份→调用 fill_context_for_report 工具→调用 fetch_external_data 工具」的固定执行流程📍过程:当Agent调用
fill_context_for_report工具时,monitor_tool中间件会立即识别到这个调用,并将报告状态位设为True。随后,在生成提示词前,report_prompt_switch中间件检测到状态位为True,自动将提示词模板切换为load_report_prompts()。流程如下:
# 初始调用Agent context={"report": False} # 开始时 ↓ # 检测到用户请求"生成使用报告" ↓ # Agent决定调用报告工具 tool_call["name"] == "fill_context_for_report" ↓ # monitor_tool中间件检测到 @wrap_tool_call if request.tool_call['name'] == "fill_context_for_report": request.runtime.context["report"] = True # ✅ 修改为True ↓ # 后续模型调用 # report_prompt_switch中间件检测 is_report = request.runtime.context.get("report", False) # 现在为True ↓ # report_prompt_switch中间件切换为报告专用提示词 return load_report_prompts()middleware.py完整代码:
from typing import Callable from utils.prompt_loader import load_system_prompts, load_report_prompts from langchain.agents import AgentState from langchain.agents.middleware import wrap_tool_call, before_model, dynamic_prompt, ModelRequest from langchain.tools.tool_node import ToolCallRequest from langchain_core.messages import ToolMessage from langgraph.runtime import Runtime from langgraph.types import Command from utils.logger_handler import logger # 装饰器wrap_tool_call用于包装工具调用,在调用工具前后添加监控日记逻辑 @wrap_tool_call def monitor_tool( # 包含工具调用请求的数据结构,如工具名称、参数等 request: ToolCallRequest, # 执行的函数本身 handler: Callable[[ToolCallRequest], ToolMessage | Command], ) -> ToolMessage | Command: # 工具执行的监控 logger.info(f"[tool monitor]执行工具:{request.tool_call['name']}") logger.info(f"[tool monitor]传入参数:{request.tool_call['args']}") try: result = handler(request) # 执行实际工具调用 logger.info(f"[tool monitor]工具{request.tool_call['name']}调用成功") # 特殊处理:当调用报告填充工具时,在运行时上下文中标记报告状态 if request.tool_call['name'] == "fill_context_for_report": request.runtime.context["report"] = True return result except Exception as e: logger.error(f"工具{request.tool_call['name']}调用失败,原因:{str(e)}") raise e # 装饰器before_model用于在模型调用前执行 @before_model def log_before_model( state: AgentState, # 整个Agent智能体中的状态记录 runtime: Runtime, # 记录了整个执行过程中的上下文信息 ): # 在模型执行前输出日志 logger.info(f"[log_before_model]即将调用模型,带有{len(state['messages'])}条消息。") logger.debug(f"[log_before_model]{type(state['messages'][-1]).__name__} | {state['messages'][-1].content.strip()}") return None # 装饰器dynamic_prompt用于动态生成提示词 @dynamic_prompt # 每一次在生成提示词之前,调用此函数 def report_prompt_switch(request: ModelRequest): # 动态切换提示词 is_report = request.runtime.context.get("report", False) # 从运行时上下文获取报告标志 if is_report: return load_report_prompts() # 是报告生成场景,返回报告生成提示词内容 return load_system_prompts() # 默认返回系统基础提示词模板
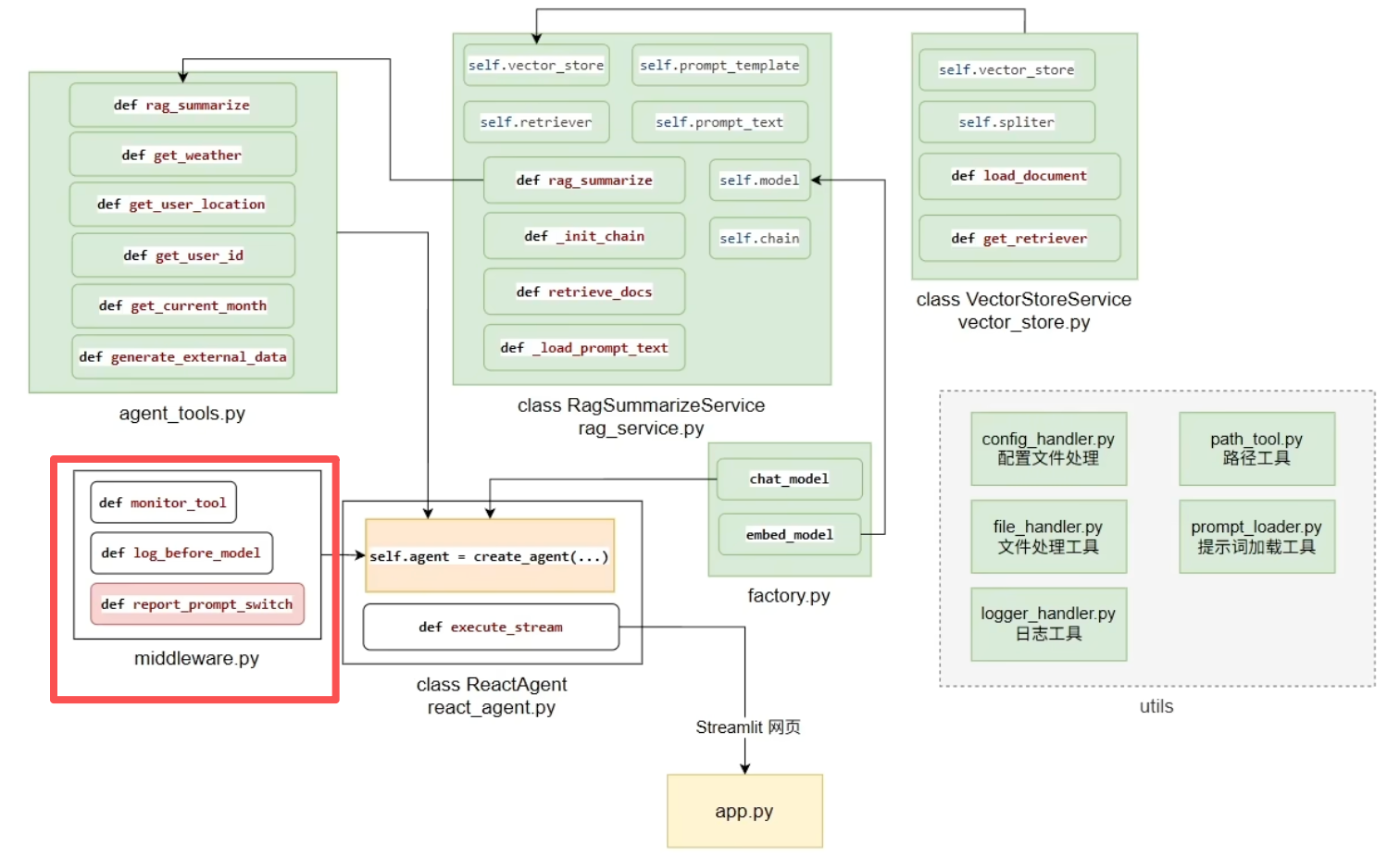
(6)Agent创建
基于ReAct框架的Agent实现,具备工具调用、中间件监控、动态提示词切换、流式输出等功能
from langchain.agents import create_agent from model.factory import chat_model from utils.prompt_loader import load_system_prompts from agent.tools.agent_tools import (rag_summarize, get_weather, get_user_location, get_user_id, get_current_month, fetch_external_data, fill_context_for_report) from agent.tools.middleware import monitor_tool, log_before_model, report_prompt_switch # ReactAgent类定义,实现一个基于ReAct框架的智能体 class ReactAgent: def __init__(self): self.agent = create_agent( # 使用的语言模型 model=chat_model, # 系统提示词,定义Agent的角色和行为准则 system_prompt=load_system_prompts(), # 可用工具列表,使Agent能够执行特定功能 tools=[rag_summarize, get_weather, get_user_location, get_user_id, get_current_month, fetch_external_data, fill_context_for_report], # 中间件列表,用于增强Agent的监控和调控能力 middleware=[monitor_tool, log_before_model, report_prompt_switch], ) def execute_stream(self, query: str): # 准备输入数据,格式化用户查询 input_dict = { "messages": [ {"role": "user", "content": query}, ] } # 返回Agent的响应 - 流式输出 # 第三个参数context就是上下文runtime中的信息,就是我们做提示词切换的标记 for chunk in self.agent.stream(input_dict, stream_mode="values", context={"report": False}): """ stream_mode="values" - 流式模式 "values"模式:返回Agent状态的完整快照 "messages":只返回新生成的消息 "actions":返回Agent的决策动作 context={"report": False} # 初始设置为False,表示非报告模式 """ latest_message = chunk["messages"][-1] # 获取最新生成的消息 if latest_message.content: # 以生成器形式返回内容,添加换行符 yield latest_message.content.strip() + "\n" if __name__ == '__main__': agent = ReactAgent() for chunk in agent.execute_stream("给我生成我的使用报告"): print(chunk, end="", flush=True)测试:
给我生成我的使用报告 2026-03-03 08:21:55,448 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有1条消息。 我需要为您生成个人使用报告。首先,我需要获取您的用户ID和报告月份,然后调用相关工具来生成报告。 1009 2026-03-03 08:21:58,649 - agent - INFO - middleware.py:19 - [tool monitor]执行工具:get_user_id 2026-03-03 08:21:58,649 - agent - INFO - middleware.py:20 - [tool monitor]传入参数:{} 2026-03-03 08:21:58,650 - agent - INFO - middleware.py:24 - [tool monitor]工具get_user_id调用成功 2026-03-03 08:21:58,650 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有3条消息。 2026-03-03 08:22:01,470 - agent - INFO - middleware.py:19 - [tool monitor]执行工具:get_current_month 2026-03-03 08:22:01,470 - agent - INFO - middleware.py:20 - [tool monitor]传入参数:{} 2026-03-03 08:22:01,471 - agent - INFO - middleware.py:24 - [tool monitor]工具get_current_month调用成功 2026-03-03 08:22:01,472 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有5条消息。 现在我已获取到您的用户ID为1009。接下来,我需要确定报告的月份。由于您没有指定具体月份,我将使用当前月份来生成报告。 2025-11 在生成报告前,我需要调用fill_context_for_report工具来为报告生成场景注入必要的上下文信息。 fill_context_for_report已调用 2026-03-03 08:22:04,796 - agent - INFO - middleware.py:19 - [tool monitor]执行工具:fill_context_for_report 2026-03-03 08:22:04,796 - agent - INFO - middleware.py:20 - [tool monitor]传入参数:{} 2026-03-03 08:22:04,797 - agent - INFO - middleware.py:24 - [tool monitor]工具fill_context_for_report调用成功 2026-03-03 08:22:04,798 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有7条消息。 现在我将获取您在2025年11月的扫地机器人使用记录。 {"特征": "80㎡两居 | 养宠 | 仿实木", "效率": "宠物毛发清理:91%\\n自动回充成功率:95%", "耗材": "胶刷缠绕:无\\n滤网寿命:剩余40天", "对比": "养宠家庭中清洁效率前20%"} 2026-03-03 08:22:08,043 - agent - INFO - middleware.py:19 - [tool monitor]执行工具:fetch_external_data 2026-03-03 08:22:08,044 - agent - INFO - middleware.py:20 - [tool monitor]传入参数:{'user_id': '1009', 'month': '2025-11'} 2026-03-03 08:22:08,047 - agent - INFO - middleware.py:24 - [tool monitor]工具fetch_external_data调用成功 2026-03-03 08:22:08,047 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有9条消息。 2026-03-03 08:22:10,898 - agent - INFO - middleware.py:19 - [tool monitor]执行工具:rag_summarize 2026-03-03 08:22:10,898 - agent - INFO - middleware.py:20 - [tool monitor]传入参数:{'query': '养宠家庭扫地机器人维护保养建议'} 为了提供更专业的保养建议,我需要查询一些关于扫地机器人维护的专业知识。 ==================== 你是专注于"基于参考资料总结"的AI助手,需结合用户提问和向量检索到的参考资料,生成简洁准确的概括回答。 ### 输入信息 1. 用户提问:养宠家庭扫地机器人维护保养建议 2. 参考资料(在下一个###之前内容均为参考资料): ### 严格遵守以下约束(违反将导致回答无效) 1. 内容合规:禁止包含违法、侵权、攻击性信息; 2. 事实准确:回答必须完全基于参考资料中的信息,不编造、不添加未提及的内容,不做主观推断; 3. 语言要求:仅用中文回答,语气客观、简洁,不冗余; 4. 聚焦提问:严格围绕用户原始提问总结,不扩充问题范围、不额外追问、不构造新query; 5. 格式要求:仅输出概括内容本身,以纯文本字符串形式呈现,不封装为字典、列表、JSON等任何结构,不附带额外说明。 ==================== 养宠家庭使用扫地机器人需定期清理滚刷和边刷,防止宠物毛发缠绕;及时清空尘盒并清洗滤网,避免异味和细菌滋生;检查传感器是否被毛发或灰尘遮挡,确保正常导航;建议每周至少维护一次,以维持机器高效运行。 2026-03-03 08:22:14,435 - agent - INFO - middleware.py:24 - [tool monitor]工具rag_summarize调用成功 2026-03-03 08:22:14,436 - agent - INFO - middleware.py:42 - [log_before_model]即将调用模型,带有11条消息。 # 黑马程序员扫地机器人使用情况报告与保养建议 ## 用户使用概况 - **用户ID**: 1009 - **报告月份**: 2025年11月 - **家庭环境**: 80㎡两居室,养宠家庭,地面材质为仿实木地板 ## 使用效率分析 - **宠物毛发清理效率**: 91%(表现优秀) - **自动回充成功率**: 95%(表现优秀) - **行业对比**: 在养宠家庭中清洁效率排名前20% ## 耗材状态 - **滚刷状态**: 无毛发缠绕(状态良好) - **滤网寿命**: 剩余40天(建议在到期前及时更换) ## 专业保养建议 ### 针对养宠家庭的特别维护建议 1. **定期清理滚刷和边刷**:虽然当前滚刷无缠绕,但建议每周至少检查一次,防止宠物毛发积累影响清洁效果。 2. **尘盒与滤网维护**:及时清空尘盒并清洗滤网,避免因宠物毛发和皮屑积累导致异味和细菌滋生。您的滤网还有40天寿命,请提前准备更换。 3. **传感器检查**:定期检查机器人的传感器是否被毛发或灰尘遮挡,确保导航系统正常工作,维持95%的高回充成功率。 4. **维护频率**:建议每周至少进行一次全面维护,以保持当前优秀的清洁效率(91%)。 ### 环境适配建议 - 仿实木地板表面光滑,适合扫地机器人工作,但请注意及时清理可能划伤地板的硬物。 - 养宠家庭建议增加清洁频率,特别是在宠物换毛季节,可考虑设置每日自动清扫。 ## 总结 您当前的扫地机器人使用状况良好,各项指标均处于优秀水平。继续保持定期维护习惯,可延长机器使用寿命并维持高效清洁性能。特别提醒在滤网寿命到期前(约40天后)及时更换,以确保最佳过滤效果。
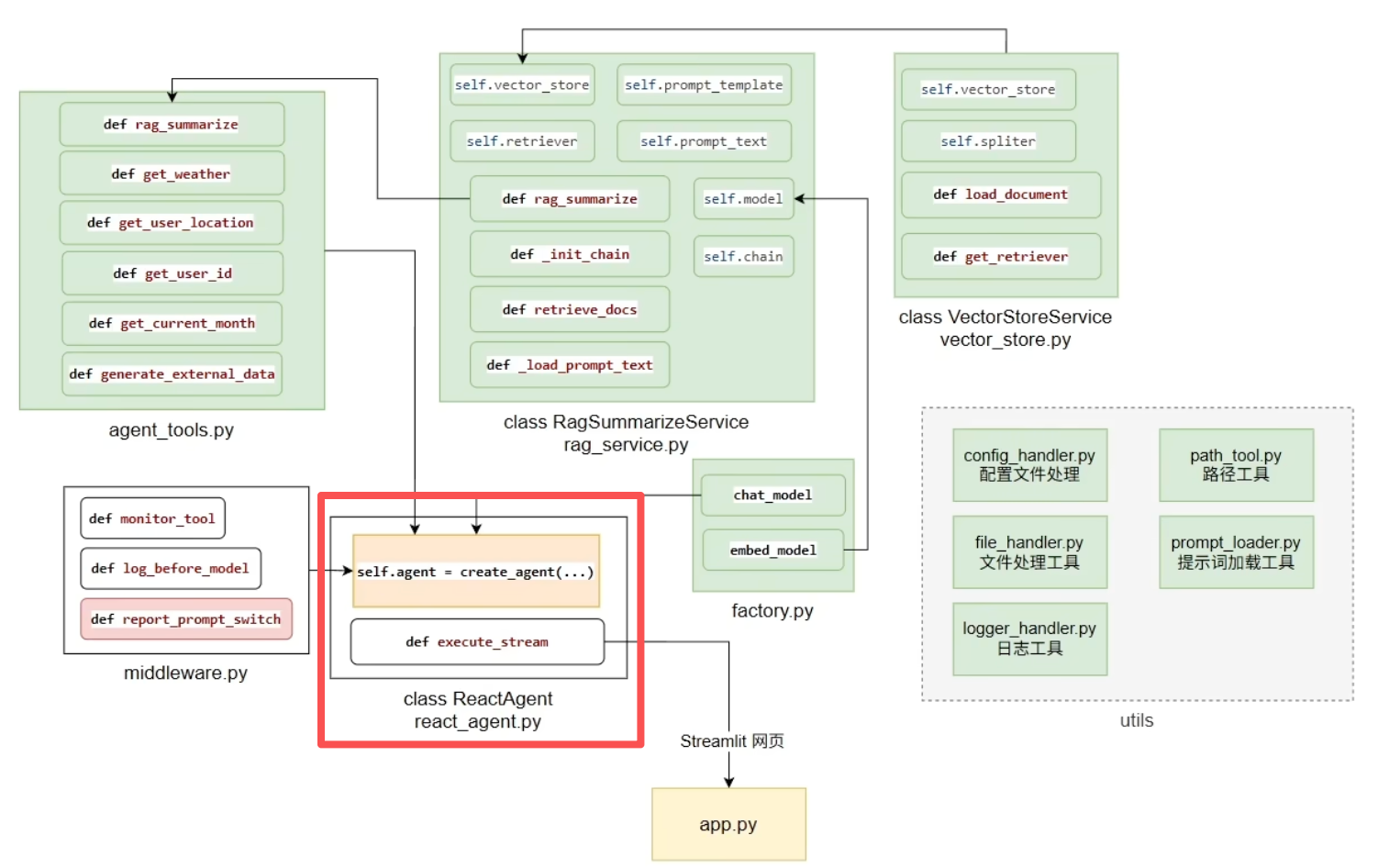
(7)用户界面开发
import time import streamlit as st from agent.react_agent import ReactAgent """ 用户网页开发 """ # 标题 st.title("智扫通机器人智能客服") st.divider() # 添加分隔线 # 初始化会话状态 - 确保Agent只在首次运行时创建 if "agent" not in st.session_state: st.session_state["agent"] = ReactAgent() # 初始化消息历史 - 存储对话记录 if "message" not in st.session_state: st.session_state["message"] = [] # 显示历史对话记录 for message in st.session_state["message"]: st.chat_message(message["role"]).write(message["content"]) # 创建用户输入框,位于页面底部 prompt = st.chat_input() if prompt: # 显示用户消息 st.chat_message("user").write(prompt) # 将用户消息添加到历史记录 st.session_state["message"].append({"role": "user", "content": prompt}) # 存储AI回复的完整内容 response_messages = [] with st.spinner("智能客服思考中..."): # 调用Agent的流式执行方法 res_stream = st.session_state["agent"].execute_stream(prompt) # res_stream是生成器,只能被消费1次 # 需要创建一个列表,通过自定义函数capture将流中的内容拼接成完整的字符串,然后再存入列表,最后将列表存入 session_state def capture(generator, cache_list): """ 生成器包装函数,用于: 1. 缓存流式输出的完整内容 2. 控制输出速度,实现逐字显示效果 """ for chunk in generator: cache_list.append(chunk) for char in chunk: time.sleep(0.01) yield char # yield:生成器逐步产生内容 # 显示AI助手回复,使用流式输出效果 st.chat_message("assistant").write_stream(capture(res_stream, response_messages)) # 将AI的完整回复保存到对话历史 st.session_state["message"].append({"role": "assistant", "content": response_messages[-1]}) # 刷新页面,更新显示 st.rerun()启动方式:
1、复制项目文件夹的绝对路径
2、终端cd指令转入项目文件夹并执行指令
streamlit run app.py
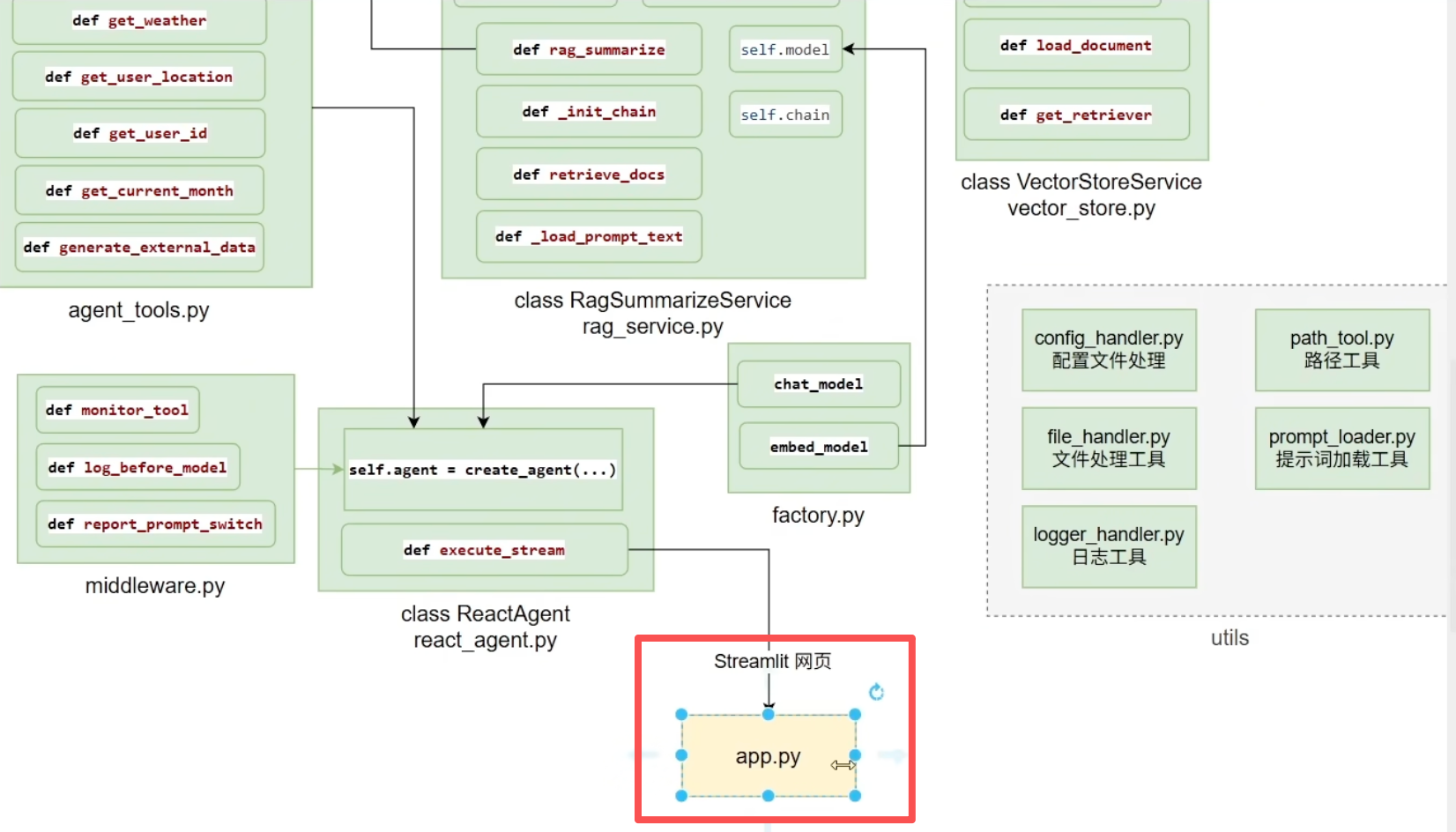
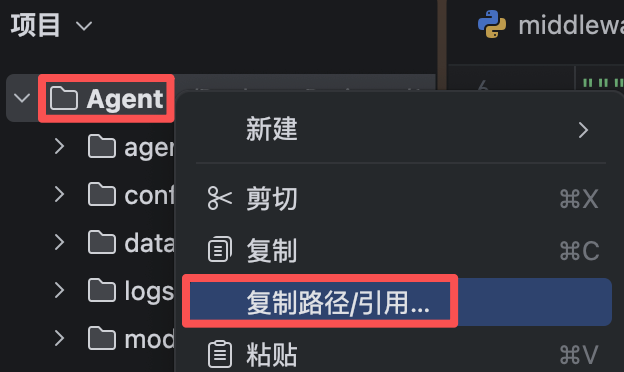
测试一下:
完结撒花!
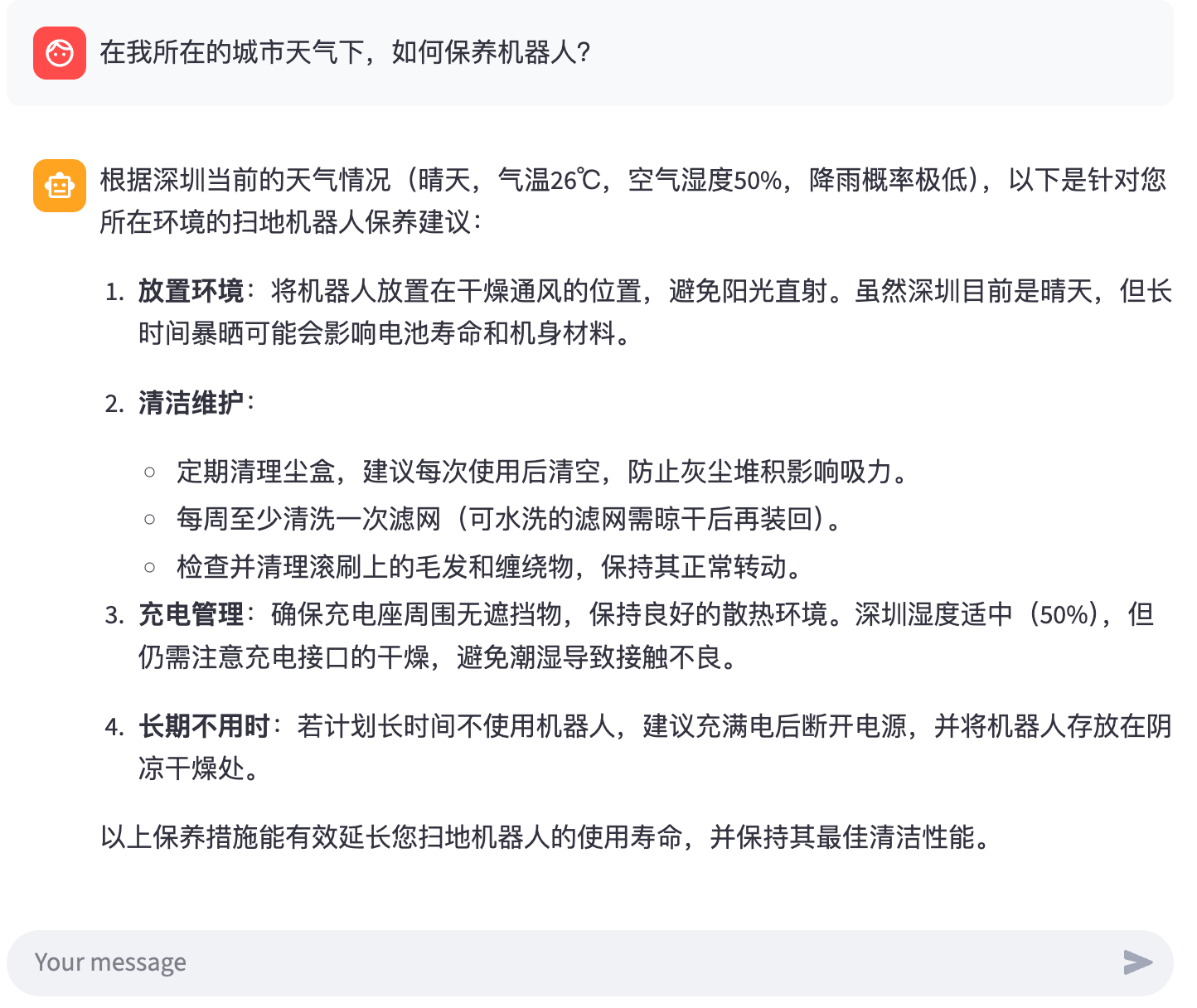

注意:该Agent项目并没有实现历史会话存储功能,后续有时间会继续完善开发该项目!
历史会话存储功能开发可参考前面的RAG项目

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)