深度学习分类任务常用评估指标——总结(重点)
一、分类模型指标1 准确率和错误率(该指标评价的前提样本分布平衡)准确率和错误率既可用于二分类也可用于多分类: 下述公式是准确率、错误率针对二分类情况时候的计算公式1.1准确率(该指标评价的前提样本分布平衡)针对 所有类别 ,计算acc,其计算公式如下:理解: 在样本(测试集)中所有预测正确的类别个数 与 所有样本的比值,它是针对所有的类别计算的。精确率和准确率是比较容易混淆的两个评估指标,两者是
一、分类模型指标
1 准确率和错误率(该指标评价的前提样本分布平衡)
准确率和错误率既可用于二分类也可用于多分类: 下述公式是准确率、错误率针对二分类情况时候的计算公式
1.1 准确率(该指标评价的前提样本分布平衡)
针对 所有类别 ,计算acc,其计算公式如下: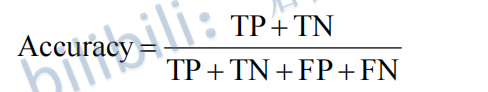
理解: 在样本(测试集)中所有预测正确的类别个数 与 所有样本的比值,它是针对所有的类别计算的。
精确率和准确率是比较容易混淆的两个评估指标,两者是有区别的。精确率是一个二分类指标,而准确率能应用于多分类,其计算公式为(对分类):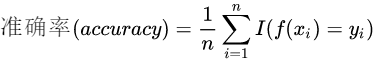
1.2 错误率(该指标评价的前提样本分布平衡)
针对 所有类别 ,计算errorrate,其计算公式如下: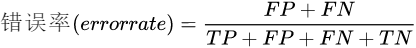
理解:它与准确率acc是一对相反的指标。
2. 精确率、召回率、准确率、错误率和F函数(该指标评价的前提样本分布平衡)
2.1 精确率和召回率
精确率和召回率主要用于二分类问题(从其公式推导也可看出),结合混淆矩阵有
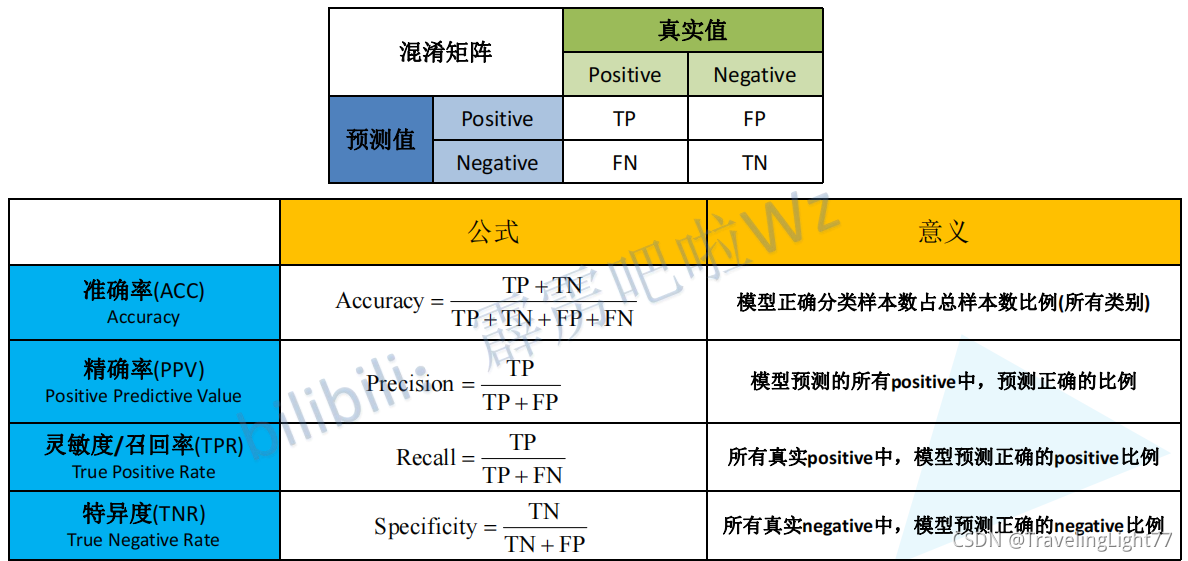
上述计算公式中的Positive与Negative是预测标签,True与false代表预测正误;
(1)精确率计算公式如下: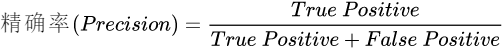
理解: 从预测的角度评价模型,在模型预测所有正例中,预测正确的正例 所占的 比例。
(2)召回率计算公式如下: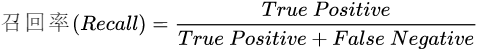
理解: 从实际的样本角度评价模型,在实际样本(数据集)中的所有正例,被模型召回预测正确的正例个数 所占的 比例。
要注意,精确率和召回率是二分类指标,不适用多分类,由此得到P-R曲线以及ROC曲线均是二分类评估指标(因为其横纵轴指标均为二分类混淆矩阵计算得到),而 准确率适用于多分类评估。(可以将多分类问题转换为二分类问题进行求解,将关注的类化为一类,其他所有类化为一类)
理想情况下,精确率和召回率两者都越高越好。然而事实上这两者在某些情况下是矛盾的,精确率高时,召回率低;精确率低时,召回率高;关于这个性质通过观察PR曲线不难观察出来。比如在搜索网页时,如果只返回最相关的一个网页,那精确率就是100%,而召回率就很低;如果返回全部网页,那召回率为100%,精确率就很低。因此在不同场合需要根据实际需求判断哪个指标跟重要。
上图分析一下: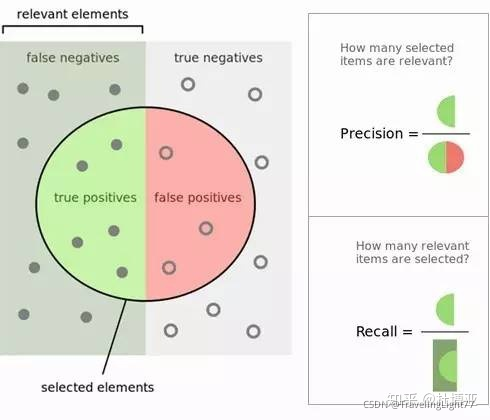
- recall是相对 真实的答案而言: true positive / golden set 。假设测试集里面有100个正例,你的模型能预测覆盖到多少,如果你的模型预测到了40个正例,那你的recall就是40%。
- precision是相对你自己的模型预测而言:true positive /retrieved set。假设你的模型一共预测了100个正例,而其中80个是对的正例,那么你的precision就是80%。我们可以把precision也理解为,当你的模型作出一个新的预测时,它的confidence score 是多少,或者它做的这个预测是对的的可能性是多少。
- 一般来说呢,鱼与熊掌不可兼得。如果你的模型很贪婪,想要覆盖更多的sample,那么它就更有可能犯错。在这种情况下,你会有很高的recall,但是较低的precision。如果你的模型很保守,只对它很sure的sample作出预测,那么你的precision会很高,但是recall会相对低。
这样一来呢,我们可以选择只看我们感兴趣的class,就是minority class的precision,recall来评价模型的好坏。
2.2 F函数(反应模型的稳健性):
F1函数是一个常用指标,F1值是精确率和召回率的调和均值,即
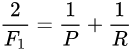
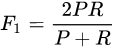
F值可泛化为对精确率和召回率赋不同权值进行加权调和: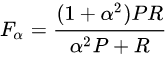
利用 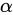 给P和R赋予不同的权重,若 \alpha = 1 则为F1值。
给P和R赋予不同的权重,若 \alpha = 1 则为F1值。

F1-score适用于二分类问题
下面是两个场景:
-
地震的预测对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
-
嫌疑人定罪基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
3. ROC曲线、PR曲线(样本分布不需要平衡)
当样本不平衡时候,以上指标:精确率和召回率评价模型,并不全面。这时候采用ROC曲线与AUC指标进行评价——ROC和AUC仅适合二分类问题
3.1 PR曲线
我们以召回率R为横轴、以精确率P为纵轴,能够画出P-R曲线,如下图: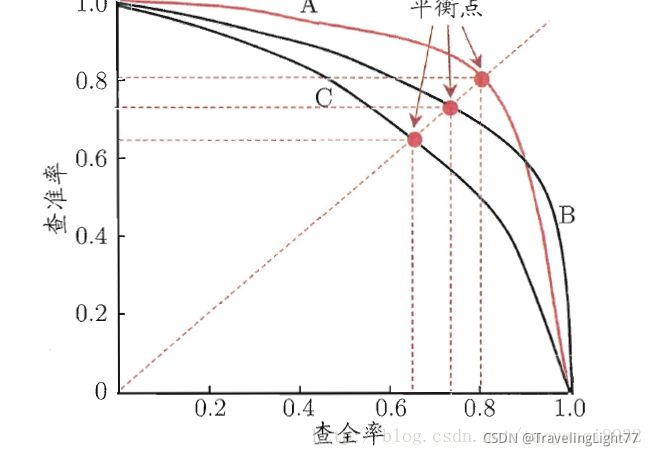
从上图不难发现,precision与Recall的折中(trade off),曲线越靠近右上角性能越好,曲线下的面积叫AP分数,能在一定程度上反应模型的精确率和召回率都很高的比例。但这个值不方便计算,综合考虑精度与召回率一般使用F1函数或者AUC值(因为ROC曲线很容易画,ROC曲线下的面积也比较容易计算).
先看平滑不平滑,在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(红线比黑线好);
F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于P-R曲线就好象AUC对于ROC一样。一个数字比一条线更方便调模型。
注:既然Precision与Recall都是二分类指标,则PR曲线也必然是二分类指标,虽然可以将precision、Recall及PR曲线应用到多分类,但是这种情况相当于是多分类转换为二分类情况分析(将关注的类视为一类,将其他所有类化为一类)
3.2 ROC曲线
在众多的机器学习模型中,很多模型输出的是预测概率,而使用精确率、召回率这类指标进行模型评估时,还需要对预测概率设分类阈值,比如预测概率大于阈值为正例,反之为负例。这使得模型多了一个超参数,并且这超参数会影响模型的泛化能力。
接受者操作特征(Receiver Operating Characteristic, ROC)曲线不需要设定这样的阈值,ROC曲线纵坐标是真正率,横坐标是假正率,如下图,去对应的计算公式为: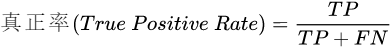
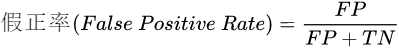
同时,TPR与FPR又有其他名称,如下:
- sensitivity = recall = true positive rate
- specificity = 1- false positive rate
假设我们的minority class,也就是正例,是1。反例,为0。Y^\hat{Y}Y^是真实label Y的估计(estimate)。
看出来没有,sensitivity和specificity是条件于真实label Y的概率的。我们讲这个叫条件概率嘛。那么意思就是说,无论Y的真实概率是多少,都不会影响sensitivity和specificity。也就是说,这两个metric是不会受imbalanced data 影响的,那就很客观了啊,是不是!而precision呢,就会随着你的测试集里面的正反比例而变化哦。
另外值得注意的是, AUC的计算方法同时考虑了学习器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器做出合理的评价。AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价学习器性能的一个原因。
例如在癌症预测的场景中,假设没有患癌症的样本为正例,患癌症样本为负例,负例占比很少(大概0.1%),如果使用准确率评估,把所有的样本预测为正例便可以获得99.9%的准确率。但是如果使用AUC,把所有样本预测为正例,TPR为1,FPR为1。这种情况下学习器的AUC值将等于0.5,成功规避了样本不均衡带来的问题。
这个曲线就是以true positive rate 和 false positive rate为轴,取不同的threshold点画的啦。有人问了,threshold是啥子哦。这么说吧,每个分类器作出的预测呢,都是基于一个probability score的。一般默认的threshold呢都是0.5,如果probability>0.5,那么这个sample被模型分成正例了哈,反之则是反例。
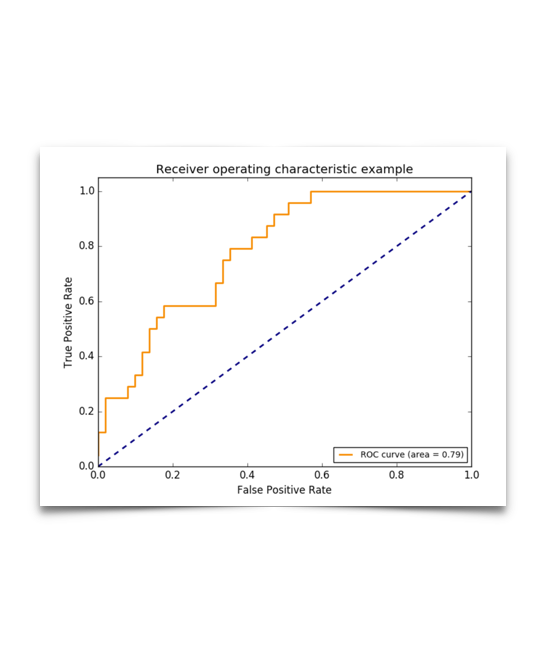
ROC曲线和P-R曲线有些类似,ROC曲线越靠近左上角性能越好。左上角坐标为(0, 1),即FPR=0,TPR=1,根据FPR和TPR公可以得知,此时FN=0, FP=0,模型对所有样本分类正确,绘制ROC曲线很简单,首先对所有样本按预测概率排序,以每条样本的预测概率为阈值,计算相应的FPR和TPR,然后线段连接。
当数据量少时,绘制的ROC曲线不平滑;当数据量大时,绘制的ROC曲线会趋于平滑。
一般来说呢,最优的threshold就是橙色曲线离蓝色虚线(基准线)最远的一点啦,或者橙色曲线上离左上角最近的一点,再或者是根据用户自己定义的cost function来的。
一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。
1) 主要作用
- ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响。
- 有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
- 可以对不同的学习器比较性能。将各个学习器的ROC曲线绘制到同一坐标中,直观地鉴别优劣,靠近左上角的ROC曲所代表的学习器准确性最高。
2)优点
该方法简单、直观、通过图示可观察分析方法的准确性,并可用肉眼作出判断。ROC曲线将真正例率和假正例率以图示方法结合在一起,可准确反映某种学习器真正例率和假正例率的关系,是检测准确性的综合代表。
在生物信息学上的优点:ROC曲线不固定阈值,允许中间状态的存在,利于使用者结合专业知识,权衡漏诊与误诊的影响,选择一个更加的阈值作为诊断参考值。
4. AUC
4.1 什么是AUC
AUC是一个模型评价指标,只能用于 二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,accuracy,precision。如果你经常关注数据挖掘比赛,比如kaggle,那你会发现AUC和logloss基本是最常见的模型评价指标。为什么AUC和logloss比accuracy更常用呢?因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了accuracy的计算。使用AUC或者logloss可以避免把预测概率转换成类别。
AUC是Area under curve的首字母缩写。AUC就是ROC曲线下的面积,衡量学习器优劣的一种性能指标。
ROC曲线下各部分的面积求和而得。假定ROC曲线是由坐标为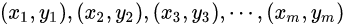
的点按序连接而形成,则AUC可估算为【微分梯形计算法(上底+下底)×高/2】: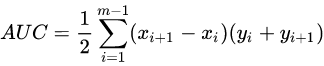
4.2 AUC的意义
即AUC是指随机给定一个正样本和一个负样本,分类器输出该正样本为正的那个概率值 比 分类器输出该负样本为正的那个概率值要大的可能性。
根据这个解释,如果我们完全随机的对样本分类,那么AUC应该接近0.5。(所以一般训练出的模型,AUC>0.5,如果AUC=0.5,这个分类器等于没有效果,效果与完全随机一样,如果AUC<0.5,则可能是标签标注错误等情况造成);
另外值得注意的是,AUC的计算方法同时考虑了学习器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器做出合理的评价。AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价学习器性能的一个原因。
此外,AUC和Wilcoxon Test of Ranks等价;AUC还和基尼(Gini)系数有联系,满足
4.3 AUC的计算方法:
AUC的计算方法有多种,从物理意义角度理解,AUC计算的是ROC曲线下的面积(微分梯形面积法):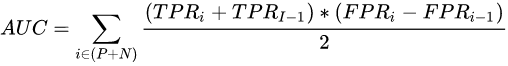
从概率意义角度理解,AUC考虑的是样本的排序质量,它与排序误差有密切关系,可得到计算公式:
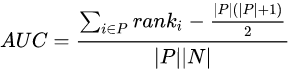
其中,rank为样本排序位置从1开始, |P| 为正样本数, |N| 为负样本数。
最后,我们在讨论一下:在多分类问题下能不能使用ROC曲线来衡量模型性能?
我的理解: ROC曲线用**在多分类中是没有意义的**。只有在二分类中Positive和Negative同等重要时候,适合用ROC曲线评价。如果确实需要在多分类问题中用ROC曲线的话,可以转化为多个“一对多”的问题。即把其中一个当作正例,其余当作负例来看待,画出多个ROC曲线。

总结
- 精确率(Precision)是指在所有系统判定的“真”的样本中,确实是真的的占比,就是TP/(TP+FP)。
- 召回率(Recall)是指在所有确实为真的样本中,被判为的“真”的占比,就是TP/(TP+FN)。
- TPR(True Positive Rate)的定义,跟Recall一样。
- FPR(False Positive Rate),又被称为“Probability of False
Alarm”,就是所有确实为“假”的样本中,被误判真的样本,或者FP/(FP+TN) - F1值是为了综合考量精确率和召回率而设计的一个指标,一般公式为取P和R的harmonic
mean:2PrecisionRecall/(Precision+Recall)。 - ROC=Receiver Operating Characteristic,是TPR vs
FPR的曲线;与之对应的是Precision-Recall Curve,展示的是Precision vs Recall的曲线。
对于二分类问题的模型评价选择:
- 一般可以采用准确率Acc进行评价
- 1)当样本 分布平衡时:
混淆矩阵——精确率、召回率、F1-score
也可以采用AUC值进行评价 - 2)当样本分布 不平衡时:
混淆矩阵评价不好,这时候要采用AUC指标进行评价,AUC(就是ROC曲线的面积)越接近1越好。
要注意,精确率和召回率是二分类指标,不适用多分类,由此得到P-R曲线以及ROC曲线(AUC)均是二分类评估指标(因为其横纵轴指标均为二分类混淆矩阵计算得到),而 准确率适用于多分类评估。(可以将多分类问题转换为二分类问题进行求解,将关注的类化为一类,其他所有类化为一类)
参考
https://blog.csdn.net/weixin_44010756/article/details/112426263
https://blog.csdn.net/weixin_44010756/article/details/112434606

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)