第147篇:深度学习识别DGA恶意域名(LSTM模型+Attention机制踩坑全记录)
由于安全人员通常无法掌握具体的 DGA 生成算法及规律,因此难以提前预测僵尸网络可能采用的恶意域名,DGA 每日可生成海量候选域名,数量大且生存周期短,安全机构就需要将每天生成的大量伪随机域名全都加入到恶意库中,这显然是不现实的,这也正是黑客利用其规避传统黑名单检测机制的原因所在。之前在北京时写的TensorFlow老版本LSTM程序需要安装各种依赖,此时发现keras总是安装不成功,最终还是使用

Part1 前言
大家好,我是ABC_123。最近抽出时间把之前一些未完成的技术工作整理收尾,一直想把DGA域名的识别功能加进蓝队分析取证工具箱中,于是找到了自己2017年在北京时的一些关于DGA域名识别方面的一些半成品,没想到时间已经过去了8年。当时尝试使用纯 Java 编程算法进行识别,但效果并不理想。后来改用谷歌出品的 TensorFlow 深度学习框架进行处理,识别准确度有明显提升,至少能够满足批量检测 DGA 域名的需求。

Part2 前置基础知识
-
DGA域名概念
近年来,僵尸网络、加密勒索软件、木马C2、恶意广告和钓鱼基础设施的控制者为了规避监管和打击、确保僵尸网络控制通道畅通,普遍采用 DGA(Domain Generation Algorithm,域名生成算法)作为通信域名的动态化手段。该技术使黑客的C2不再使用唯一的固定域名,而是根据特定种子在不同时间依据构造好的算法批量生成大量伪随机域名,攻击者仅需提前注册其中极少部分,即可完成对僵尸网络的远程控制。由于安全人员通常无法掌握具体的 DGA 生成算法及规律,因此难以提前预测僵尸网络可能采用的恶意域名,DGA 每日可生成海量候选域名,数量大且生存周期短,安全机构就需要将每天生成的大量伪随机域名全都加入到恶意库中,这显然是不现实的,这也正是黑客利用其规避传统黑名单检测机制的原因所在。
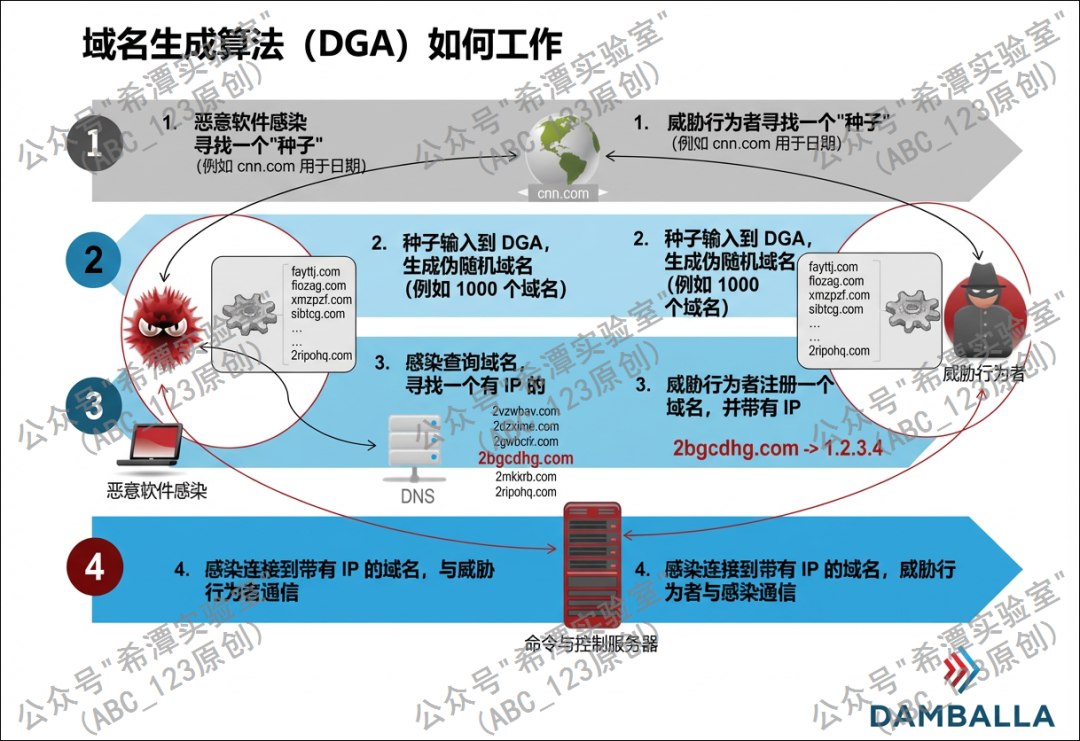
-
深度学习LSTM算法
LSTM(长短期记忆网络)并非普通的神经网络,它是 RNN(循环神经网络)的一种特殊变体,其诞生的核心使命就是为了攻克一般 RNN 模型难以处理的"长期依赖"(Long-Term Dependency) 难题。 在处理像 DGA 域名这样由一连串字符组成的序列时,普通模型往往面临"读了后面忘前面"的困境。然而,LSTM 通过刻意的内部结构设计有效规避了这一缺陷。LSTM 在结构中引入"输入门、遗忘门、输出门"三类门控单元,使模型能够选择性地记忆或遗忘信息,并在适当时机输出关键特征。凭借这一机制,LSTM 能够有效捕获长序列中的上下文关系,在 DGA 域名检测、文本分类、自然语言理解等任务中具备显著优势。

对于RNN和LSTM的区别,我们打个比方,想象我们在玩一个"传话游戏",RNN 的记忆传递就像是在做乘法。假设 RNN 的记忆力不是完美的,每传递一次,它只能保留 90% (0.9) 的信息,相当于数学上叫梯度消失,相当于每个人只能记住上一位说的话内容的 90%。比如,第 1 人说:“域名开头是 baidu”;到第 10 个人,还能模糊听出 “bai…”;到第 50 个人,它可能变成了:“后面是 xasrtlk……我忘了开头是什么”。用简单的数学表示,大致如下。类似于如下情况:
第 1 步: 0.9 (还不错)第 2 步: 0.9×0.9=0.81第 3 步: 0.9×0.9×0.9=0.729 ...第 50 步: 0.950≈0.005(几乎忘干净了)结果: 读到一个长域名的最后时,原本的信息只剩下 0.005 了,这就等于完全忘了开头是什么。所以在 RNN 眼里,DGA长域名开头的信息对结果没有任何影响。信息随着时间步不断递减,远处的信息几乎无法正确传递,对长序列模型“长程依赖”无能为力。
LSTM 模型不会机械地每一步都“乘以 0.9”,它会主动选择“保存”或“遗忘”(现在的记忆 = (旧记忆×1) + 新信息)。它在“传话链”中额外安排了一个笔记本与三个管理者(即输入门、遗忘门和输出门)。当新信息到来时,它会判断哪些值得写进笔记本、哪些应该被擦掉,并在需要的时候再把笔记内容读出来。因此,即便信息需要跨越几十甚至上百个时间步,关键内容依然能够被长期保存,不会像 RNN 那样在中途逐渐衰减。每个人再接到信息时,不是直接开口往下说,而是由遗忘门决定“旧消息哪些应该删掉”(擦掉笔记内容)、由输入门决定“新来的信息是否值得写进笔记本”、由输出门决定“是否要把笔记内容读出来告诉下一个人”
LSTM模型对比效果: 即便过了 50 步,只要那个开关一直是 1(代表“这段话很重要,别忘”),那个旧记忆就会原封不动地被加里面,不会因为连乘而变小。像把纸条放进塑封袋,比口耳相传更稳定。
第 1 步: 记住了"百度",把"百度"写在便签上并贴好;...第 50 步: 依然是"百度" + "后面乱七八糟的字符"。即使后面又有人接着说了一大堆乱七八糟的信息,你仍能准确拿出那张便签说:"最开始是百度"。第 1 个人说:"域名开头是 baidu",LSTM 会觉得这是核心信息,于是写在本子上并锁好;...第 50 个人:他还能从笔记本中拿出最早的内容说,"最开始是 baidu"。后面即便有人说:"然后后面是 xqw8zsadjkw…"。只要遗忘门判断“不重要”,原先的记忆就不会被擦掉。LSTM 可以主动决定记忆、遗忘,避免信息被被动衰减,能处理长序列依赖,比 RNN 更“聪明”。当它仍是线性传递,只能靠笔记本缓解。
-
Attention机制
Attention 机制最初源于图像处理中为了降低计算开销而对关键像素区域进行聚焦的思想,在 DGA 域名检测中,它有效弥补了传统 LSTM 将长序列压缩为固定长度向量导致信息丢失的缺陷。通过引入 Attention 层,模型不再单向依赖 LSTM 读到末尾时的“模糊记忆”,而是能够计算所有输入字符的权重并生成全局上下文向量,从而自动对域名中通过算法生成的关键字符组合进行划重点和加权求和;这种机制让模型在处理复杂长域名时能精准聚焦最具区分度的特征,实验证明加入非线性 Attention后,二分类任务的误报率会显著降低,极大地提升了模型识别恶意 DGA 域名的准确性与稳定性。
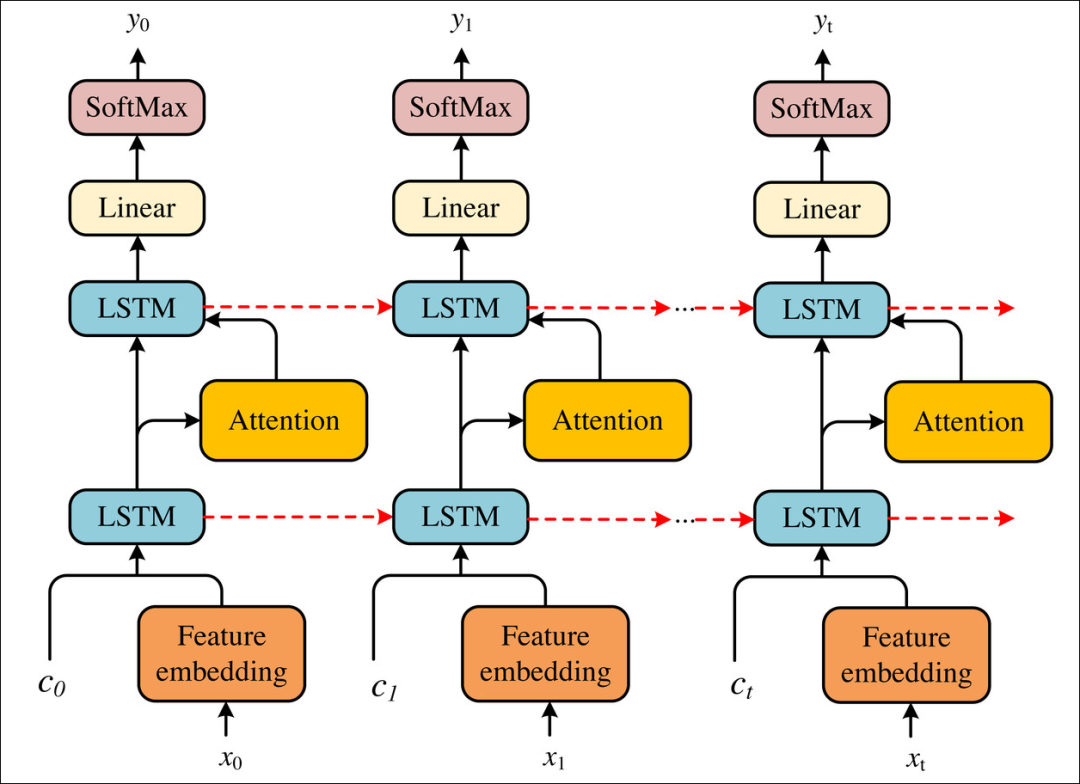
我们继续用传话游戏举例子,传统 LSTM 的玩法是:大家排成一列,一个人一句话地往后传,最后只能听到队伍最后一人的总结。而 Attention 机制则改变了这个规则:它允许你不再只听最后一个人,而是回到所有 50 个说过话的人那里听听他们各自说了什么;按照你认为重要程度给每句话打一个权重分,信息越重要分越高;再把“每句话 × 权重”加起来,得到一个重点提炼后的最终信息。开头、第 20 个、第 35 个信息,只要有用都能直接取用,长距离不再需要依赖口耳传递,从而大幅提升学习效率。
Part3 踩坑与问题解决
-
第1个问题:算力环境准备
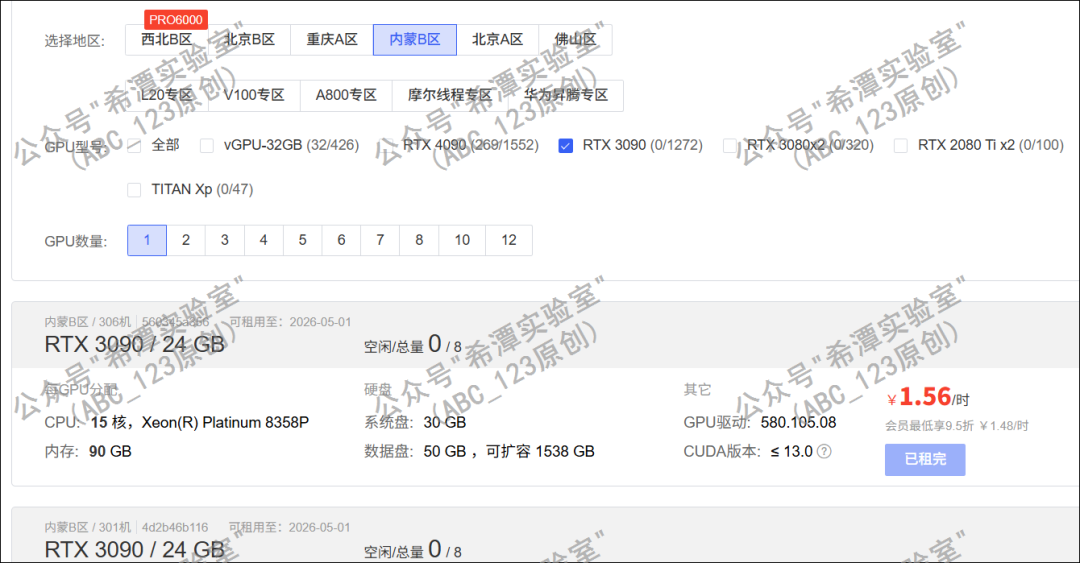
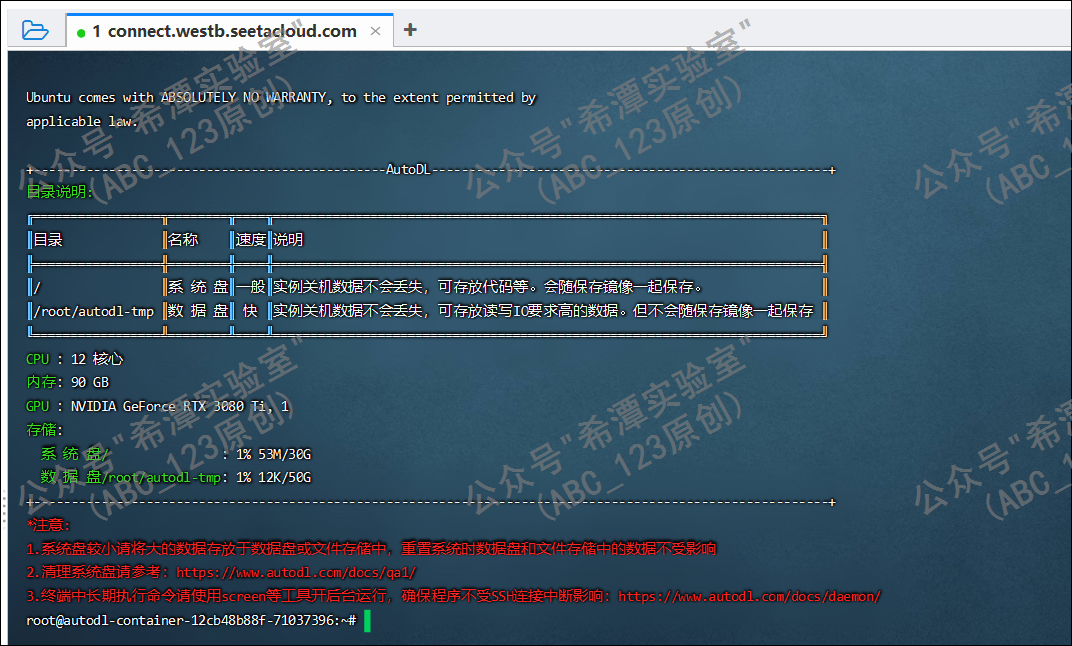
参考github的LSTM+Attention模型的开源实现,改进python代码调用TensorFlow进行计算,放在我家里的一台旧电脑上用CPU来算,算了一天一夜也没算完。最终无奈选择了一家GPU算力云,综合性价比选用 RTX 3090 /24 GB,一个小时1.56元,最后发现总共花费了不到2个小时计算完成,物美价廉。
-
第2个问题:TensorFlow版本与Keras报错
之前在北京时写的TensorFlow老版本LSTM程序需要安装各种依赖,此时发现keras总是安装不成功,最终还是使用最新版本的TensorFlow来安装,并将代码中的报错进行了逐一修改,然后安装在服务器上。可是怎么安装怎么报错,最后采用miniconda环境安装成功。
wget https://repo.anaconda.com/miniconda/Miniconda3-py38_23.11.0-2-Linux-x86_64.sh配置清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/conda config --set show_channel_urls yespip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simpleconda remove -n dga --all -yconda create -n dga python=3.8 -yconda activate dgapip install tensorflow[and-cuda]==2.13.0还是这种方法好用,简单几步安装完成。然后运行以下代码,查看环境安装是否正确。
python -c "import tensorflow as tf; import keras; print('TensorFlow:', tf.__version__); print('Keras:', keras.__version__)"
nohup python main.py 0 1024 10 train.txt models/binary_model.h5 > train.log 2>&1 &-
第3个问题:训练样本集有问题
既然使用LSTM+Attention模型识别DGA域名,那必然要准备DGA域名样本及白名单的正常域名样本,在这里踩了一个大坑。一开始发现模型总是识别不准,发现是样本出了问题。我用的样本都是从github上下载的,但是这些样本可能来源不准确,白名单域名里,我手工打开一看,里面就有几个恶意域名;同样DGA域名列表内,也有一些白名单域名,如yahoo等。所以大家从网上下载样本时,一定手工打开看看,是否正确,如果样本不正确,那深度学习的结果肯定也是不准确的。
-
第4个问题:训练集windows换行符
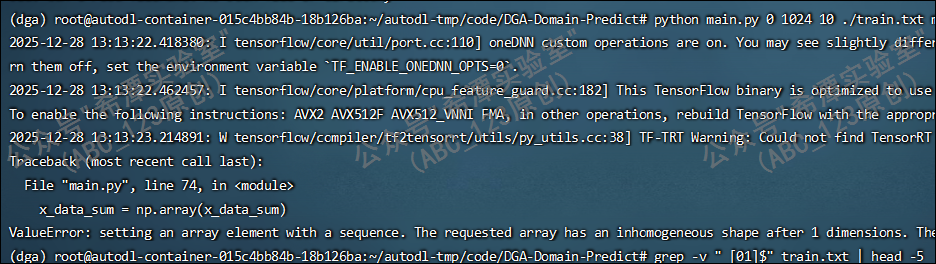
将DGA域名识别的python代码运行,刚运行就报错了,百思不得其解。经过反复查找发现,自己生成的416万行的训练集里面居然有3行文本末尾有个windows的换行符\r,导致格式错误,全部替换为Unix的 \n 之后,重新运行。
-
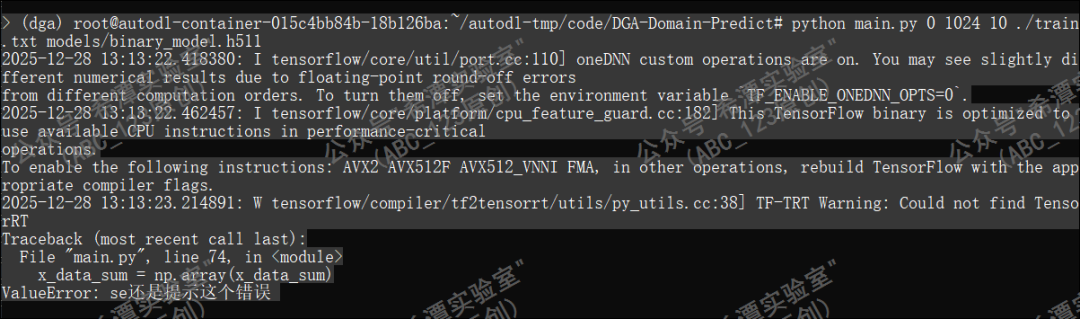
第5个问题:numpy版本兼容性问题
程序重新运行,又了ValueError错误,这是numpy版本兼容性问题。旧版 numpy (< 1.24)会自动创建 dtype=object 数组,允许不等长;新版 numpy (≥ 1.24)则更严格,默认尝试创建规则数组,长度不一致就报错。将x_data_sum = np.array(x_data_sum)更换为 x_data_sum = np.array(x_data_sum, dtype=object);dtype=object 明确告诉 numpy:这是一个对象数组,每个元素可以是不同长度的列表。

-
第6个问题:epochs与batch_size参数设置问题
通常batch_size 批处理大小,epochs 代表训练轮数。假设需要背诵一本100页的单词书,1个epoch相当于把书从第 1 页翻到第 100 页,完整看一遍;10 个 epochs相当于把整本书反复看 10 遍;batch_size = 1024 相当于每次看 1024 个单词,然后复习巩固一下。而本次使用LSTM + Attenion模型的训练集是416万条域名, 最终确定 batch_size的值设置为1024、epochs的值设置为10 ;相当于每次学习 1024 个域名,学完 416 万条 = 1 个 epoch(约 4000 批次),总共重复学 10 遍。第 1 遍初步认识,记住一部分;第 2-3 遍加深印象,纠正错误;第 5-10 遍基本掌握,趋于稳定;这个值也不是越大越好,太多遍容易造成死记硬背,产生过拟合,遇到新题反而不会。
python main.py 0 1024 10 train.txt models/binary_model.h5对于上述命令行,是否要把10换成50?我们可以先用 10 epochs 完成一次训练,观察最后几轮的 loss,如果loss已经趋于平稳,不再明显下降,说明已经收敛。此时测试模型效果,如果准确率已经很高(>95%),就不需要增加epochs。如果在 10 个 epochs 后 loss 仍在明显下降,则可以考虑适度提升至 15–20 轮,但一般不需要 50。如果增大 epochs 后反而效果变差,说明产生了过拟合,反而要减少次数。
-
第7个问题:生成的模型转为java调用
由于是python生成的DGA域名识别模型,不能直接被java调用,于是使用写一个python程序转换成java的TensorFlow库可以识别的,然后调用java去识别。
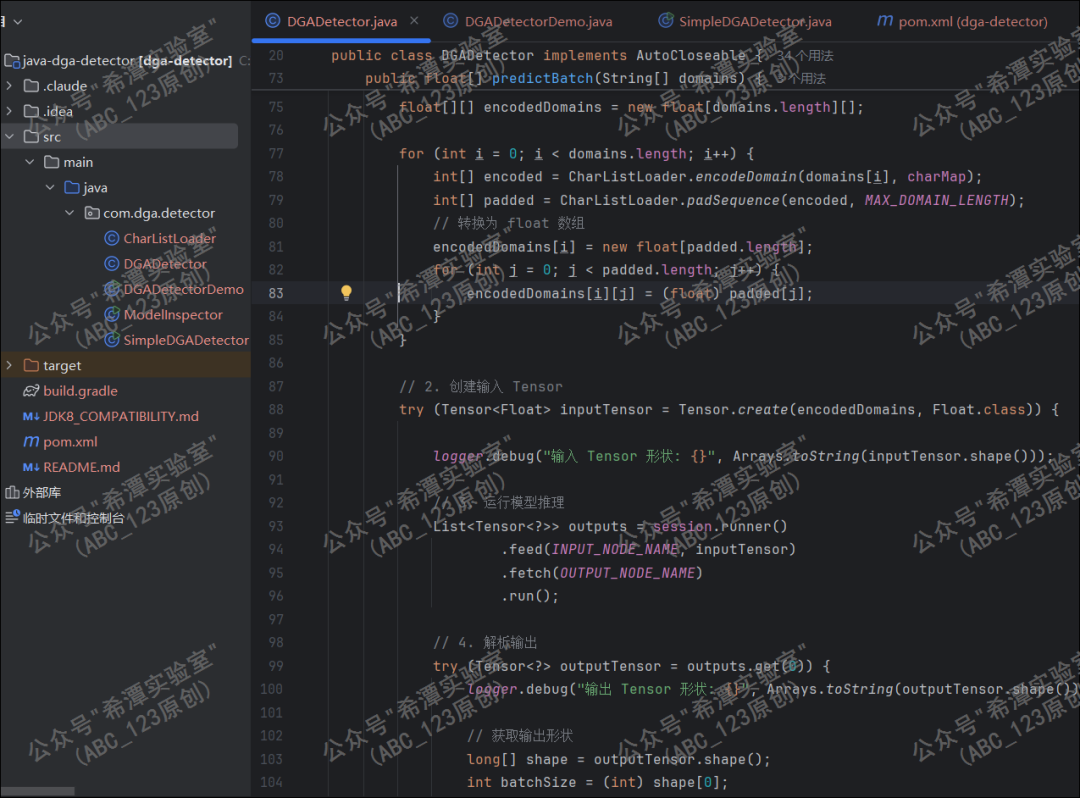
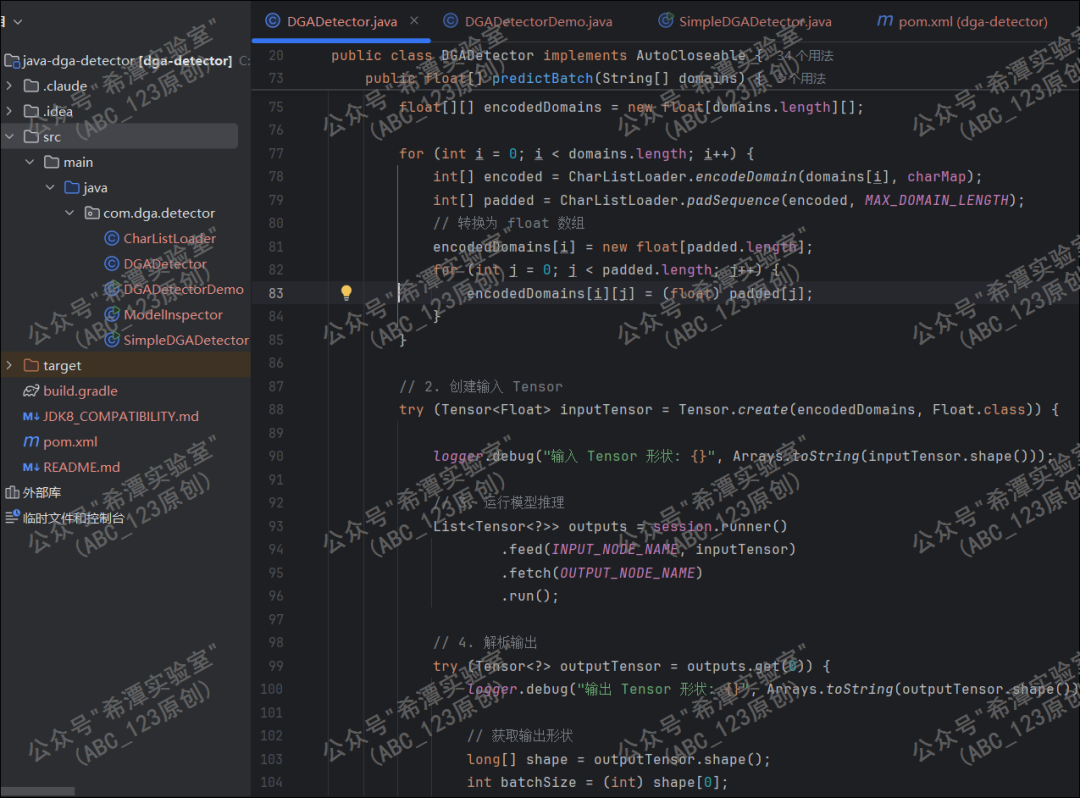
最终使用写好的java代码,调用转换好的模型识别,发现报错,经过各种排查错误发现,Java的TensorFlow1.15.0库不支持TensorFlow2.x版本训练好的模型,但是TensorFlow 2.x又不支持JDK1.8 ,毕竟蓝队分析工具箱还是基于jdk1.8开发的,所以我们还要继续解决这一问题。
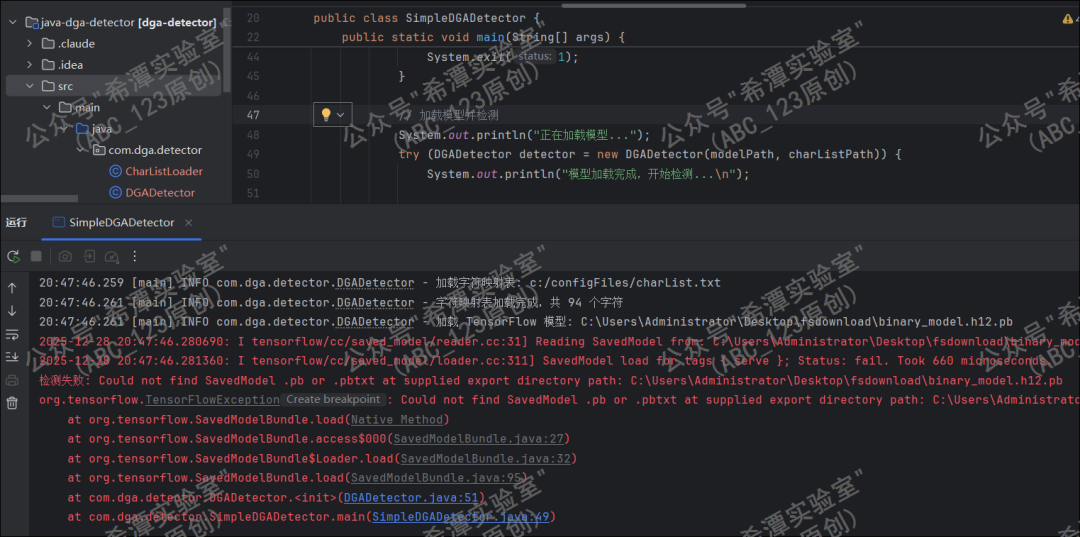
-
第8个问题,高版本模型与JDK1.8兼容问题
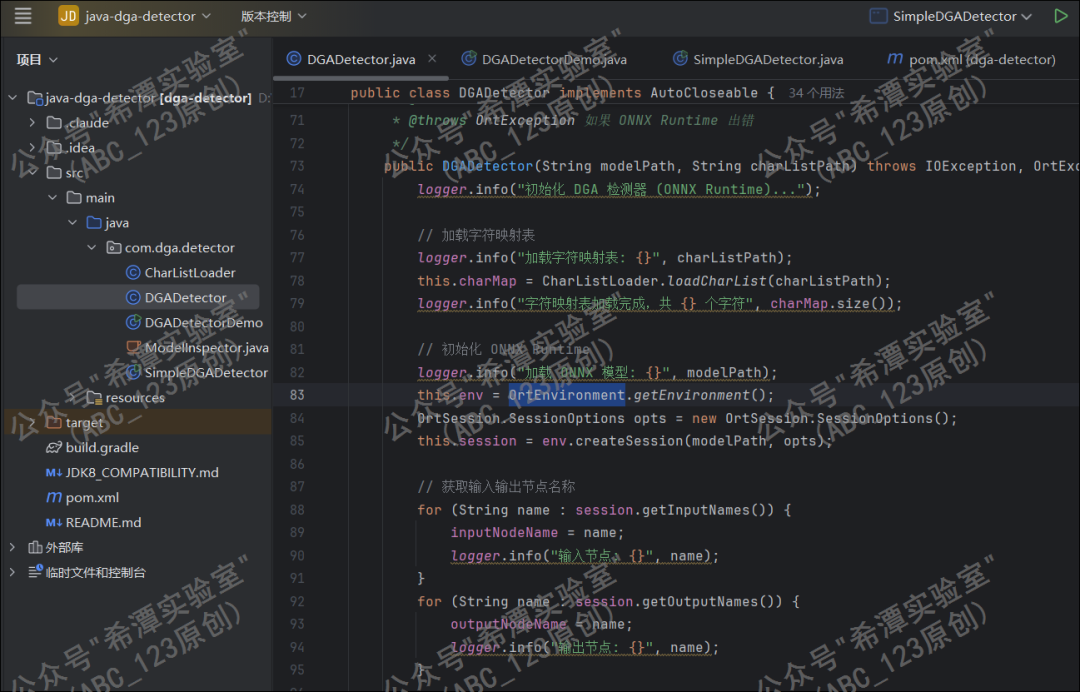
TensorFlow2.x版本至少需要JDK11版本才可以支持,但是想要融合进蓝队分析取证工具箱,就需要想办法进行兼容,原本想着把2.x模型转换一下,转成TensorFlow1.15.x支持的形式,但是难度太大。最终经过查找,发现可以更换为onnxruntime1.15.1库,该库很好地支持jdk1.8,而且兼容TensorFlow2.x生成的模型。
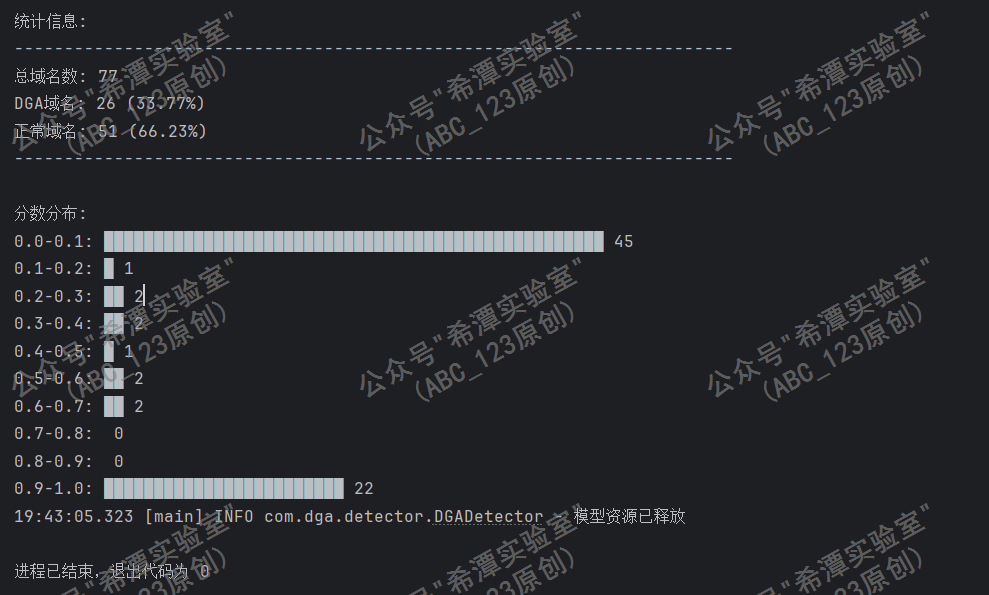
至此,所有踩坑环节结束,太难了!
Part3 总结
1. 深度学习LSTM+Attention模型对于识别DGA域名有显著提升,但是据说XGBoost框架识别效果更加,改天测试一下。
2. 大家有好的建议,欢迎给我留言。为了便于技术交流,现已建立微信群"希水涵-信安技术交流群",欢迎您的加入。


公众号专注于网络安全技术分享,包括APT事件分析、红队攻防、蓝队分析、渗透测试、代码审计等,每周一篇,99%原创,敬请关注。
Contact me: 0day123abc#gmail.com
OR 2332887682#qq.com
(replace # with @)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)