基于MATLAB深度确定性策略梯度DDPG强化学习RL的车辆横向控制
基于MATLAB深度确定性策略梯度DDPG强化学习RL的车辆横向控制简介:基于DDPG的车辆横向控制,输入是车辆状态和跟踪误差等信息,输出是前轮转向角。该代码模型既可以先执行训练代理,然后保存训练好的代理;也可以尝试加载预先训练好的代理文件,验证控制效果。
·
基于MATLAB深度确定性策略梯度DDPG强化学习RL的车辆横向控制
简介:基于DDPG的车辆横向控制,输入是车辆状态和跟踪误差等信息,输出是前轮转向角。该代码模型既可以先执行训练代理,然后保存训练好的代理;也可以尝试加载预先训练好的代理文件,验证控制效果。
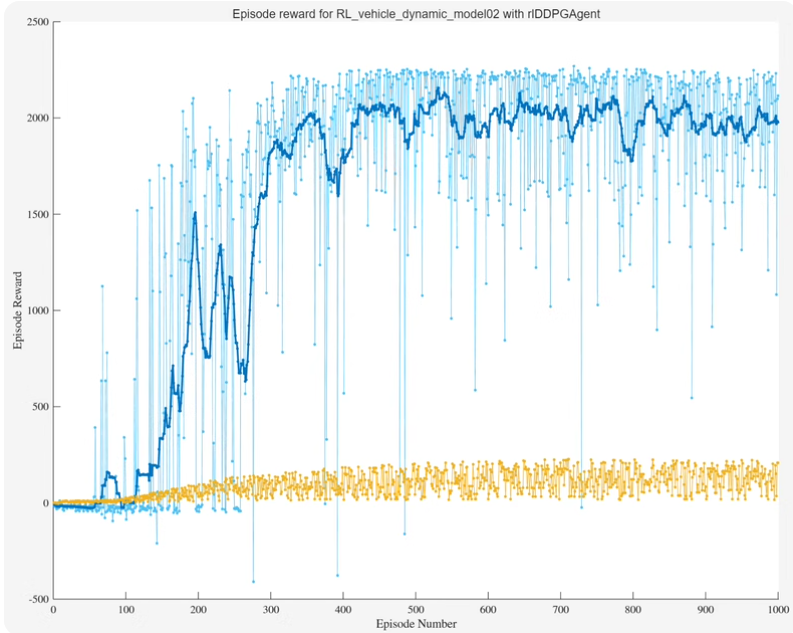
以下文字及示例代码仅供参考
文章目录
基于深度确定性策略梯度(DDPG)的强化学习在自动驾驶车辆的横向控制中具有广泛的应用。DDPG是一种结合了深度Q网络(DQN)和确定性策略梯度(DPG)的算法,适用于连续动作空间的问题。以下是一个使用MATLAB实现DDPG进行车辆横向控制的基本框架和示例代码。
1. 环境设置
首先,我们需要定义一个环境来模拟车辆的运动和控制。这个环境应该包括车辆的动力学模型、状态表示以及奖励函数。
classdef VehicleEnvironment
properties
state % 当前状态 [x, y, theta, v]
targetPath % 目标路径
currentIndex % 当前目标点索引
end
methods
function obj = VehicleEnvironment()
% 初始化车辆状态
obj.state = [0, 0, 0, 1]; % x, y, theta (方向), v (速度)
obj.targetPath = [0:0.1:10; sin(0:0.1:10)]'; % 示例路径
obj.currentIndex = 1;
end
function nextState = step(obj, action)
% 根据动作更新状态
dt = 0.1; % 时间步长
steeringAngle = action(1); % 动作是方向盘转角
acceleration = action(2); % 加速或减速
% 简单的车辆动力学模型
obj.state(3) = obj.state(3) + tan(steeringAngle) * dt / 2; % 更新方向
obj.state(4) = obj.state(4) + acceleration * dt; % 更新速度
obj.state(1) = obj.state(1) + obj.state(4) * cos(obj.state(3)) * dt; % 更新x坐标
obj.state(2) = obj.state(2) + obj.state(4) * sin(obj.state(3)) * dt; % 更新y坐标
nextState = obj.state;
% 检查是否到达下一个目标点
if norm(obj.state(1:2) - obj.targetPath(obj.currentIndex, :)) < 0.5
obj.currentIndex = obj.currentIndex + 1;
if obj.currentIndex > size(obj.targetPath, 1)
obj.currentIndex = size(obj.targetPath, 1);
end
end
end
function reward = getReward(obj)
% 计算当前状态的奖励
distanceToPath = norm(obj.state(1:2) - obj.targetPath(obj.currentIndex, :));
reward = -distanceToPath; % 距离越小越好
end
function isDone = isTerminal(obj)
% 判断是否达到终止条件
isDone = (obj.currentIndex == size(obj.targetPath, 1));
end
end
end
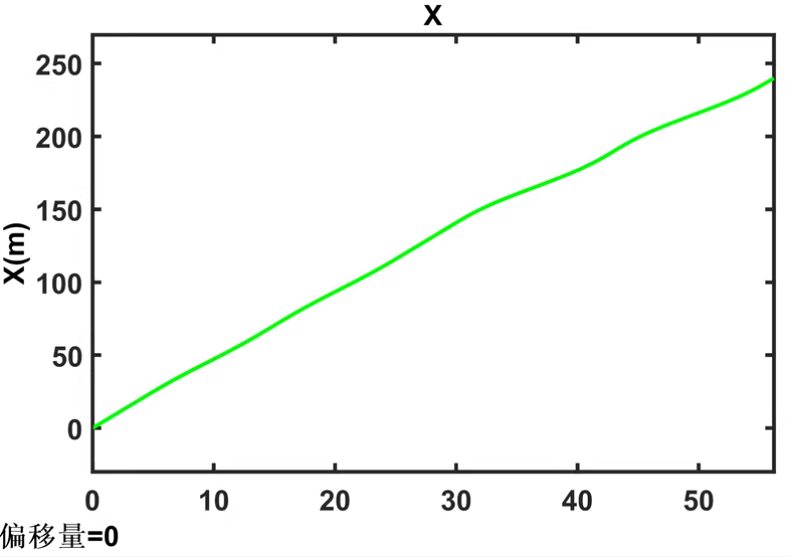
2. DDPG算法实现
接下来,我们实现DDPG算法,包括Actor和Critic网络的构建、经验回放和训练过程。
% 设置参数
numEpisodes = 100;
maxSteps = 200;
batchSize = 64;
gamma = 0.99;
tau = 0.001;
% 创建环境
env = VehicleEnvironment();
% 创建Actor和Critic网络
actorNet = createActorNetwork();
criticNet = createCriticNetwork();
% 初始化经验回放
replayBuffer = [];
% 训练循环
for episode = 1:numEpisodes
currentState = env.state;
totalReward = 0;
for step = 1:maxSteps
% 获取动作
action = predict(actorNet, currentState);
% 执行动作并获取新状态和奖励
nextState = env.step(env, action);
reward = env.getReward(env);
isDone = env.isTerminal(env);
% 存储经验
replayBuffer(end+1,:) = {currentState, action, reward, nextState, isDone};
% 更新当前状态
currentState = nextState;
totalReward = totalReward + reward;
% 如果达到终止条件,结束本回合
if isDone
break;
end
% 随机抽样并训练
if length(replayBuffer) >= batchSize
batch = datasample(replayBuffer, batchSize);
% 这里需要实现DDPG的训练步骤,包括Critic和Actor的更新
% ...
end
end
% 输出每回合的总奖励
fprintf('Episode %d, Total Reward: %.2f\n', episode, totalReward);
end
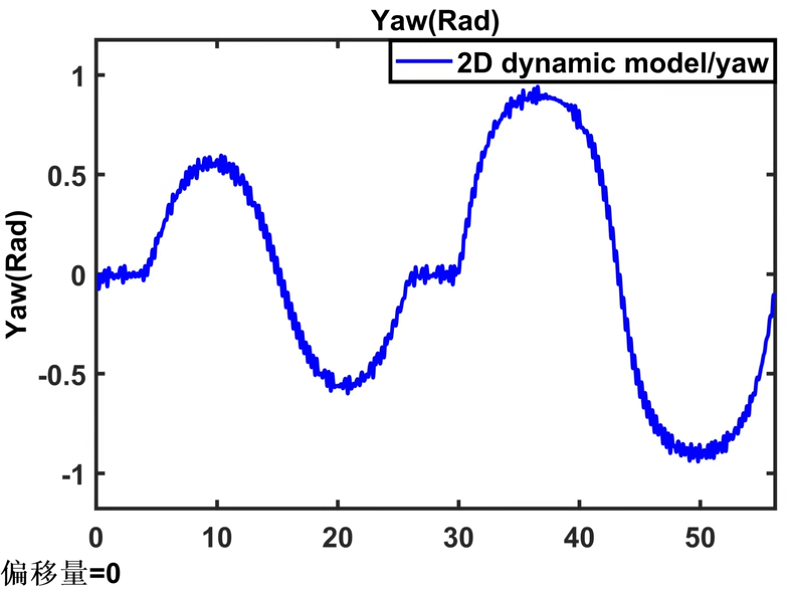
3. 网络构建
最后,我们需要定义Actor和Critic网络的结构。这里可以使用MATLAB的Deep Learning Toolbox来创建神经网络。
function net = createActorNetwork()
layers = [
featureInputLayer(4)
fullyConnectedLayer(400)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(2)
tanhLayer];
net = dlnetwork(layers);
end
function net = createCriticNetwork()
layers = [
featureInputLayer(4)
fullyConnectedLayer(400)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(1)];
net = dlnetwork(layers);
end
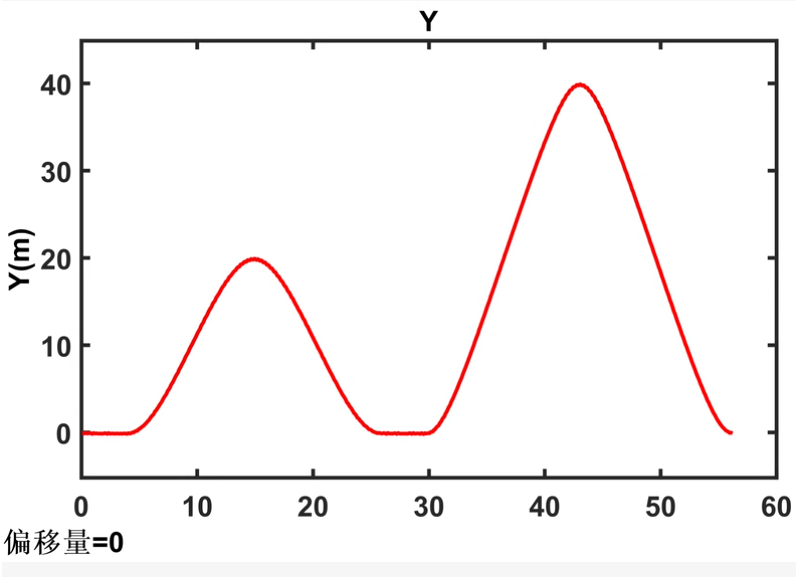
以上代码提供了一个基本的框架,您可以根据具体需求进行调整和优化。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)