自己动手写深度学习框架(神经网络训练的原理)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 大家说神经网络的训练,本身是一个黑盒操作,主要一部分原因就是其中的训练,很多时候没有办法做出合理性解释。也就是说,不知道为什么要按照这个方向去进行收敛,这个方向收敛对最终特征的形成有什么作用,很多时候都是不知道的。假设有这么一个模型,即y=f(x)。这个函数,或者说模型,其实是预先
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
大家说神经网络的训练,本身是一个黑盒操作,主要一部分原因就是其中的训练,很多时候没有办法做出合理性解释。也就是说,不知道为什么要按照这个方向去进行收敛,这个方向收敛对最终特征的形成有什么作用,很多时候都是不知道的。假设有这么一个模型,即y=f(x)。这个函数,或者说模型,其实是预先设定好的框架。但是里面的参数是未知的,我们有的只是一堆数据,当下的工作就是用这堆数据把模型里面的参数训练好,使得它最大程度上符合y=f(x)的要求。
1、从数据中学习
不管是简单的方程,还是复杂的方程,使用神经网络的目的都是为了训练里面的参数。并且,相比较传统的y=f(x)来说,神经网络的方程,参数要多得多,可能是几百万、几亿个。这么多的参数,是不可能人工去拟合的,只能靠很多很多的数据去训练获得。所以,本质上神经网络是一种数据驱动式的学习方式。
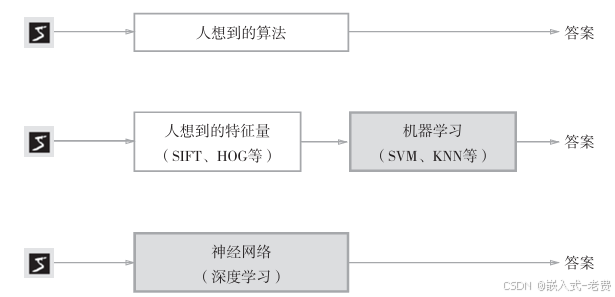
如上图所说,最早的学习,都是人工去直接建模,想办法解决。后来变成了人工设计特征,利用svm这些算法去进行分类处理。最新的神经网络,则直接让机器自己去寻找特征。这就是所谓的端到端,说的就是输入和输出之间,没有人为参与的痕迹。
大家看到的卷积,比如之前所说的 (784)*(784*m)*(m*n)*(n*p)*...*(z*10) * (10*1),中间不停地变换和修正,就是一个找特征的过程。至于是不是真的存在可解释的特征,这一点待定。
2、构建残差方程
要想让神经网络训练起来,那么有必要构建一个残差方程。这个残差方程,有的地方叫损失函数,其实是一个意思。就是说,我们构建的方程,必须要保证预测结果和实际结果的误差最小。用数学方程表示,你可以是绝对值最小,可以是平方差最小,可以是四方差最小等等,这都是可以的。只是目前都习惯用均方误差来构建残差方程。
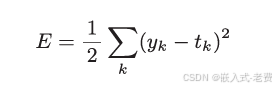
当前,还有一种交叉熵,也是出现在很多场合使用的。
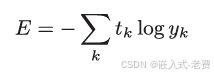
前面我们说过,很多时候,神经网络的训练都是一批一批进行。这里的一批,就是从训练数据找出若干个进行训练,那么这样的话,上面的交叉熵就会变成这样,
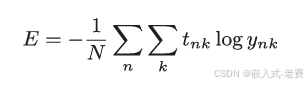
有了这个残差方程,我们的神经网络训练就算有了一个基础和目标。因为训练的最终目的,就是为了让预测结果和实际结果,尽量地吻合。
3、梯度下降
既然准备好了残差方程,那么怎么解这个残差方程呢,答案就是梯度下降的办法。所谓的梯度,就是对应参数的导数。什么是梯度下降呢,就是说参数调整的方向,要和当前的梯度值相反,当然中间还有一个学习率、初始值的问题。
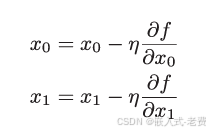
某一个点,如果当前的梯度值 > 0,代表它正处在增长的方向,那么这个时候参数就要往左移动一下。但是,如果当前的梯度值 < 0,代表它正处在下降的方向,那么这个时候参数就要往右移动一下。y=f(x)当中一般有多少参数需要训练,就要进行多少次梯度的计算。
当然梯度是神经网络的概念,从数学的角度来说,梯度就是导数的意思。
4、直接法求解导数
导数,如果用数学的概念,就是某个参数在某一个方向的切线,或者是切面,或者是更高维度的某个微分结果。如果是比较简单的函数,类似于y=wx+b,那么方程对x的导数就是w本身。或者y=x**2,那么导数就是2x本身,不再是一个常数了。
当然,计算导数不会这么简单。如果中间出现套娃的情况,怎么处理呢?比如y=t**2,t = wx+b,这种情况下怎么对x求导?
遇到这种情况,其实也不用紧张,我们一般是先对t进行求导,然后t对x进行求导,这样两个数相乘,就是y对x的求导结果。比如这里,y对x的求导结果就是2(wx+b)*w。
5、数值法求导
除了直接法求导之外,还可以通过数值法进行求导。还是上面y=t**2,t=wx+b的例子,这种情况下,可以让x=x+delta_x,看看y发生了多大的改变,这个时候,delta_y/delta_x就是我们所需要的导数,
def numerical_diff1(f,x):
h=10e-50
return (f(x+h)-f(x))/h但是实际运行的时候,我们会发现,但数据位于(-e-6,e-6)之间的时候,都会被认为是0,所以这个方程需要进行修改成这样,
def numerical_diff(f,x):
h=1e-4
return (f(x+h)-f(x))/h6、偏导数的求解
当方程当中多于一个参数的时候,就要求解偏导数。偏导数看上去复杂,其实只要把其他参数在计算的时候,看成是常量即可。比如,如果y=x0*x1,那么y对x0的导数就是x1,y对x1的导数就是x0,就是这个道理。
再举一个例子,如果y=x0**2+x1**2,这种情况下,y对x0的导数就是2x0,对x1的导数就是2x1,和对方参数完全没有关系。当然这是直接法求解偏导数,如果是数值法,其实也是可以求解出来的。
7、再从偏导数回到残差方程
我们一路从残差方程讲到偏导数,本质上还是要把概念弄清楚,最终还是为了求解残差方程。相信有了这一路的讲解,至少可以解决简单的残差方程问题,比如某一个曲线的匹配。类似于下面这段代码,就是一段曲线的匹配,
# -*- coding: utf-8 -*-
"""
Gradient descent fitting for quadratic curve:
y = k1 * x^2 + k2 * x + k3
Compatible with Python 2 and Python 3
"""
import time
import numpy as np
import matplotlib.pyplot as plt
def fit_quadratic_gd(x, y, lr=1e-4, epochs=5000, verbose=True):
"""
Fit parameters k1, k2, k3 for y = k1*x^2 + k2*x + k3 using gradient descent.
Args:
x: 1D numpy array
y: 1D numpy array
lr: learning rate
epochs: number of iterations
verbose: print training info
Returns:
k1, k2, k3, loss_history
"""
x = np.asarray(x, dtype=float)
y = np.asarray(y, dtype=float)
n = len(x)
# Initialize parameters
k1, k2, k3 = 0.0, 0.0, 0.0
loss_history = []
for epoch in range(epochs):
# Forward
y_pred = k1 * x**2 + k2 * x + k3
error = y_pred - y
loss = np.mean(error**2)
loss_history.append(loss)
# Gradients
grad_k1 = (2.0 / n) * np.sum(error * x**2)
grad_k2 = (2.0 / n) * np.sum(error * x)
grad_k3 = (2.0 / n) * np.sum(error)
# Parameter update
k1 -= lr * grad_k1
k2 -= lr * grad_k2
k3 -= lr * grad_k3
if verbose and (epoch % max(1, epochs // 10) == 0 or epoch < 10):
print("epoch %5d loss=%.6f k1=%.6f k2=%.6f k3=%.6f" %
(epoch, loss, k1, k2, k3))
return k1, k2, k3, np.array(loss_history)
if __name__ == "__main__":
# Generate sample data
np.random.seed(int(time.time()))
x = np.linspace(-5, 5, 100)
true_k1, true_k2, true_k3 = 0.5, -1.2, 3.0
y_true = true_k1 * x**2 + true_k2 * x + true_k3
y = y_true + np.random.normal(0, 1.0, size=x.shape)
# Fit
k1, k2, k3, loss_hist = fit_quadratic_gd(x, y, lr=1e-4, epochs=100000)
print("\nFitted parameters:")
print("k1 = %.6f, k2 = %.6f, k3 = %.6f" % (k1, k2, k3))
# Plot result
plt.figure(figsize=(8, 4))
plt.scatter(x, y, s=10, label="data")
plt.plot(x, y_true, 'g--', label="true")
plt.plot(x, k1 * x**2 + k2 * x + k3, 'r', label="fit")
plt.legend()
plt.show()
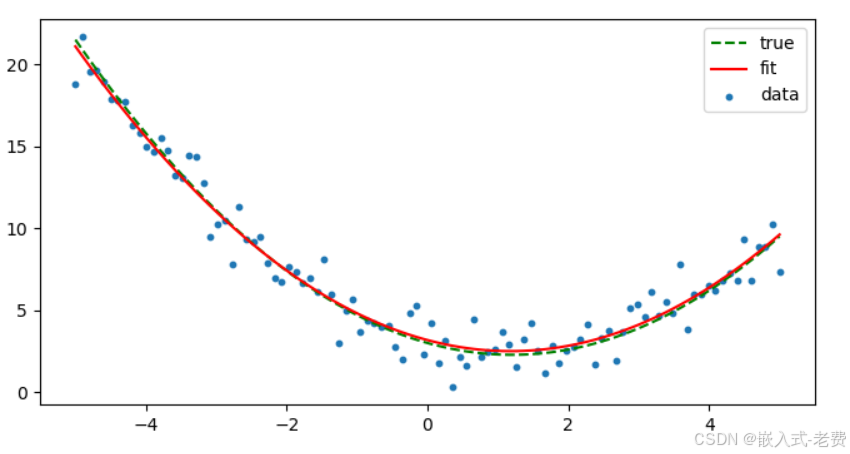
运行起来,效果就是这样的,
对应的训练过程就是这样的,
C:\Users\feixiaoxing\Desktop\python_ai\exer>C:\Python27\python curve.py
epoch 0 loss=79.119580 k1=0.017962 k2=-0.002021 k3=0.001444
epoch 1 loss=75.874032 k1=0.035454 k2=-0.004038 k3=0.002857
epoch 2 loss=72.793869 k1=0.052489 k2=-0.006051 k3=0.004240
epoch 3 loss=69.870567 k1=0.069078 k2=-0.008062 k3=0.005594
epoch 4 loss=67.096043 k1=0.085233 k2=-0.010069 k3=0.006919
epoch 5 loss=64.462632 k1=0.100966 k2=-0.012072 k3=0.008217
epoch 6 loss=61.963061 k1=0.116287 k2=-0.014072 k3=0.009488
epoch 7 loss=59.590434 k1=0.131207 k2=-0.016069 k3=0.010732
epoch 8 loss=57.338212 k1=0.145738 k2=-0.018062 k3=0.011951
epoch 9 loss=55.200191 k1=0.159888 k2=-0.020052 k3=0.013144
epoch 10000 loss=1.685333 k1=0.572827 k2=-1.188331 k3=1.803164
epoch 20000 loss=1.122635 k1=0.525252 k2=-1.188331 k3=2.528632
epoch 30000 loss=1.026787 k1=0.505617 k2=-1.188331 k3=2.828047
epoch 40000 loss=1.010460 k1=0.497513 k2=-1.188331 k3=2.951621
epoch 50000 loss=1.007679 k1=0.494168 k2=-1.188331 k3=3.002622
epoch 60000 loss=1.007206 k1=0.492788 k2=-1.188331 k3=3.023672
epoch 70000 loss=1.007125 k1=0.492218 k2=-1.188331 k3=3.032359
epoch 80000 loss=1.007111 k1=0.491983 k2=-1.188331 k3=3.035945
epoch 90000 loss=1.007109 k1=0.491886 k2=-1.188331 k3=3.037425
Fitted parameters:
k1 = 0.491846, k2 = -1.188331, k3 = 3.038035
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 34
34 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)