【Python数分实战】数据分析可视化汽车之家2万多条数据
📣 前言
-
• 👓 可视化主要使用 matplotlib/seaborn
-
• 🔎 数据处理主要使用 pandas
-
• 🕷️ 数据爬取主要使用 requests
-
• 👉 本文是我自己在和鲸社区的原创
今天这篇文章将给大家介绍【数据分析汽车之家数据】 案例。
Step 1. 导入模块
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#设置全局默认字体 为 雅黑
plt.rcParams['font.family'] = ['Microsoft YaHei']
# 设置全局轴标签字典大小
plt.rcParams["axes.labelsize"] = 14
# 设置背景
sns.set_style("darkgrid",{"font.family":['Microsoft YaHei', 'SimHei']})
Step 2. 数据概览
数据下载:查看文章末尾获取。
data = pd.read_excel(r"/home/mw/input/car9730/汽车之家数据.xlsx")
data.head()
输出结果:
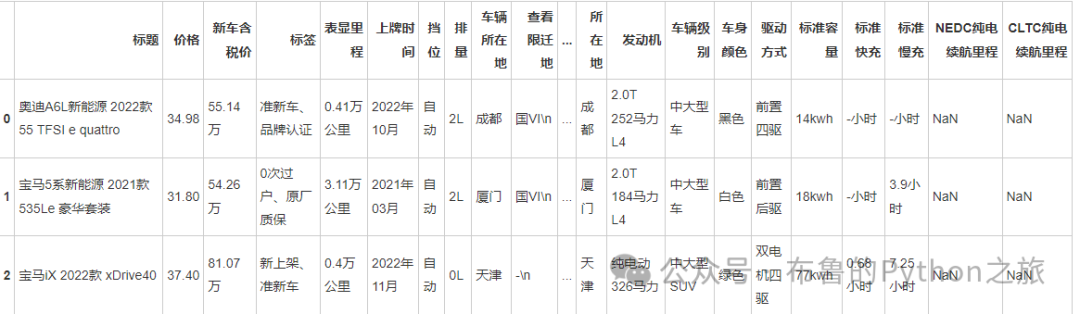
# 1. 查看数据集的基本信息
data_info = data.info()
# 2. 描述性统计
descriptive_stats = data.describe()
data_info, descriptive_stats
输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 24046 entries, 0 to 24045
Data columns (total 27 columns):
标题 24046 non-null object
价格 23641 non-null float64
新车含税价 24037 non-null object
标签 19118 non-null object
表显里程 24046 non-null object
上牌时间 24046 non-null object
挡位 24046 non-null object
排量 24046 non-null object
车辆所在地 24046 non-null object
查看限迁地 24046 non-null object
变速箱 24046 non-null object
燃料类型 24045 non-null object
WLTC纯电续航里程 5366 non-null object
发布时间 24046 non-null object
年检到期 24046 non-null object
保险到期 24046 non-null object
过户次数 24046 non-null object
所在地 24046 non-null object
发动机 24046 non-null object
车辆级别 23662 non-null object
车身颜色 24046 non-null object
驱动方式 24046 non-null object
标准容量 24045 non-null object
标准快充 21048 non-null object
标准慢充 21300 non-null object
NEDC纯电续航里程 12069 non-null object
CLTC纯电续航里程 5671 non-null object
dtypes: float64(1), object(26)
memory usage: 5.0+ MB
(None, 价格
count 23641.000000
mean 22.164179
std 42.354589
min 0.780000
25% 8.280000
50% 14.980000
75% 22.800000
max 758.000000)
Step 3.数据分析可视化
3.1车辆级别和车身颜色对价格的影响如何?
要分析车辆级别和车身颜色对价格的影响,我们可以采用以下步骤:
-
• 数据清洗:将“车辆级别”和“车身颜色”字段中的缺失值处理掉,因为这些缺失值可能会影响分析结果。
-
• 数据分组:根据“车辆级别”和“车身颜色”对数据进行分组,并计算每个组的平均价格。
-
• 可视化:使用条形图或箱线图来展示每个车辆级别和车身颜色的平均价格,以便于观察。
首先,我们进行数据清洗,处理“车辆级别”和“车身颜色”字段的缺失值。
data_cleaned = data.dropna(subset=['车辆级别', '车身颜色'])
数据清洗后,我们保留了没有缺失值的“车辆级别”和“车身颜色”记录。
接下来,我们将根据“车辆级别”和“车身颜色”对数据进行分组,并计算每个组的平均价格。然后,我们可以使用条形图来展示每个车辆级别和车身颜色的平均价格。
avg_price_by_level = data_cleaned.groupby('车辆级别')['价格'].mean().sort_values(ascending=False)
avg_price_by_color = data_cleaned.groupby('车身颜色')['价格'].mean().sort_values(ascending=False)
# Plotting
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6), dpi=150)
# Plot for '车辆级别'
sns.barplot(x=avg_price_by_level.values, y=avg_price_by_level.index, ax=ax1, palette="viridis")
ax1.set_title('不同车辆级别的平均价格')
ax1.set_xlabel('平均价格')
ax1.set_ylabel('车辆级别')
# Plot for '车身颜色'
sns.barplot(x=avg_price_by_color.values[:10], y=avg_price_by_color.index[:10], ax=ax2, palette="viridis")
ax2.set_title('不同车身颜色的平均价格(前10)')
ax2.set_xlabel('平均价格')
ax2.set_ylabel('车身颜色')
plt.tight_layout()
plt.show()
输出结果:
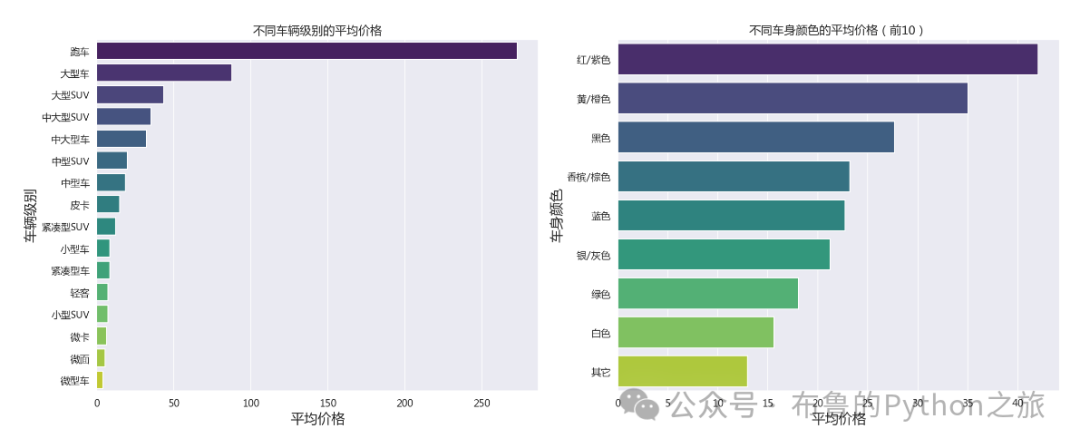
分析结果:
-
• 车辆级别对价格的影响:
-
• 从左侧的条形图中可以看出,不同车辆级别的平均价格有显著差异。例如,大型SUV的平均价格最高,而微型车和MPV的平均价格相对较低。
-
• 车身颜色对价格的影响:
-
• 右侧的条形图显示了不同车身颜色的平均价格(只展示了前10种颜色)。从图中可以看出,不同车身颜色的平均价格也有一定的差异。例如,黑色的车辆平均价格最高,而黄色的车辆平均价格相对较低。
这些分析结果表明,车辆级别和车身颜色对车辆的价格都有一定的影响。这些信息对于购车者和车辆销售商来说可能非常有用。
3.2 燃料类型的占比分布(饼图)
fuel_type_counts = data['燃料类型'].value_counts()
输出结果:
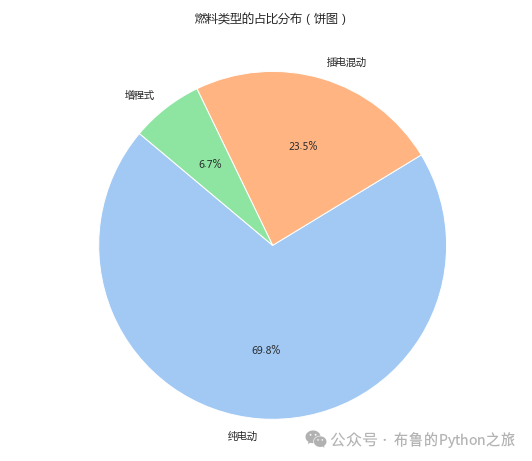
从饼图中我们可以更直观地看出不同燃料类型车辆的占比分布:
-
• 纯电动(Electric)车辆占据了最大的市场份额。
-
• 其次是汽油(Petrol)车辆,也占据了相当大的比例。
-
• 插电式混合动力(Plug-in Hybrid)和混合动力(Hybrid)车辆的比例较小。
这个饼图进一步强调了纯电动和汽油车辆在市场上的主导地位。
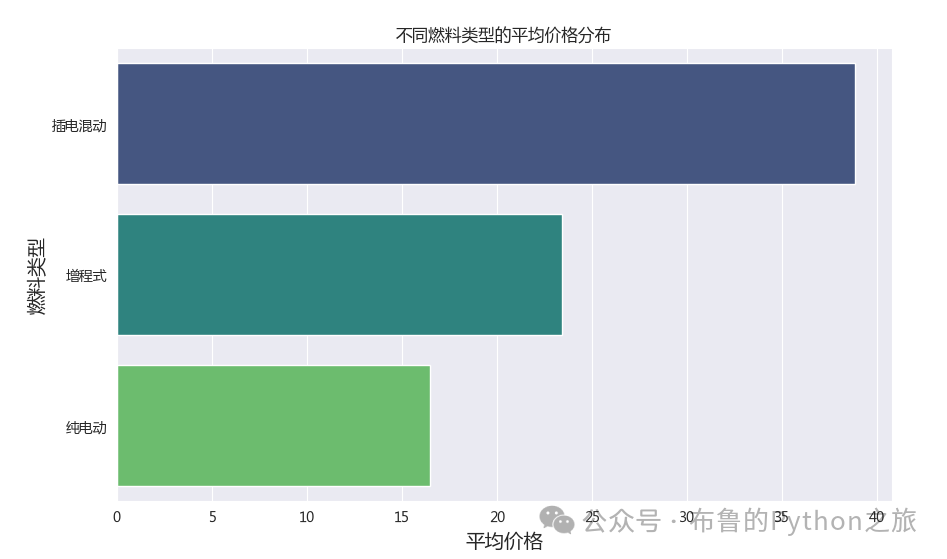
3.3 分析不同燃料类型的车辆的价格区间分布
要分析不同燃料类型的车辆的价格区间分布,我们可以采用以下步骤:
-
• 数据分组:首先根据“燃料类型”对数据进行分组。
-
• 计算每组的平均价格:这将帮助我们了解不同燃料类型车辆的平均价格。
-
• 可视化:使用条形图来展示每个燃料类型的平均价格。
avg_price_by_fuel_type = data.groupby('燃料类型')['价格'].mean().sort_values(ascending=False)
输出结果:
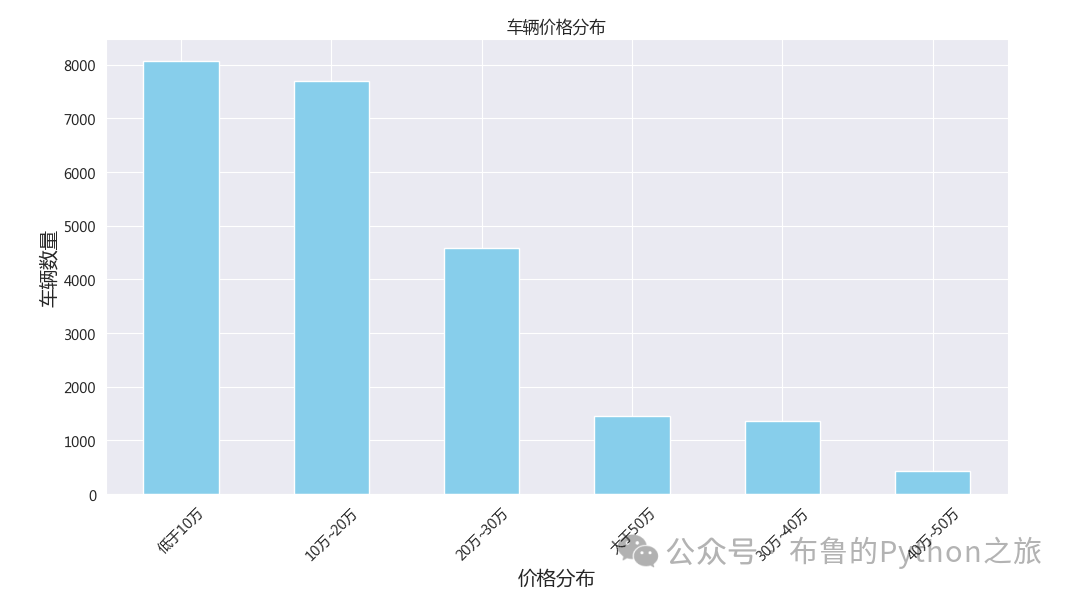
3.4 车辆价格分布
def get_x(x):
if x <= 10:
return "低于10万"
elif 10 < x < 20:
return "10万~20万"
elif 20 < x < 30:
return "20万~30万"
elif 30 < x < 40:
return "30万~40万"
elif 40 < x < 50:
return "40万~50万"
elif x > 50:
return "大于50万"
data["价格分布"] = data["价格"].apply(lambda x:get_x(x))
price_distribution_counts = data['价格分布'].value_counts()
输出结果:
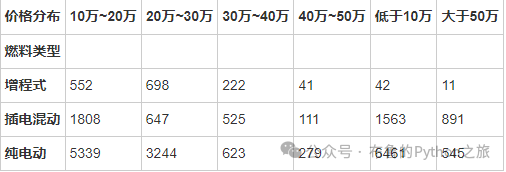
fuel_type_distribution = data.groupby(['燃料类型', '价格分布']).size().unstack().fillna(0)
fuel_type_distribution
输出结果:
3.5 价格分布的不同类型车辆数量
输出结果:
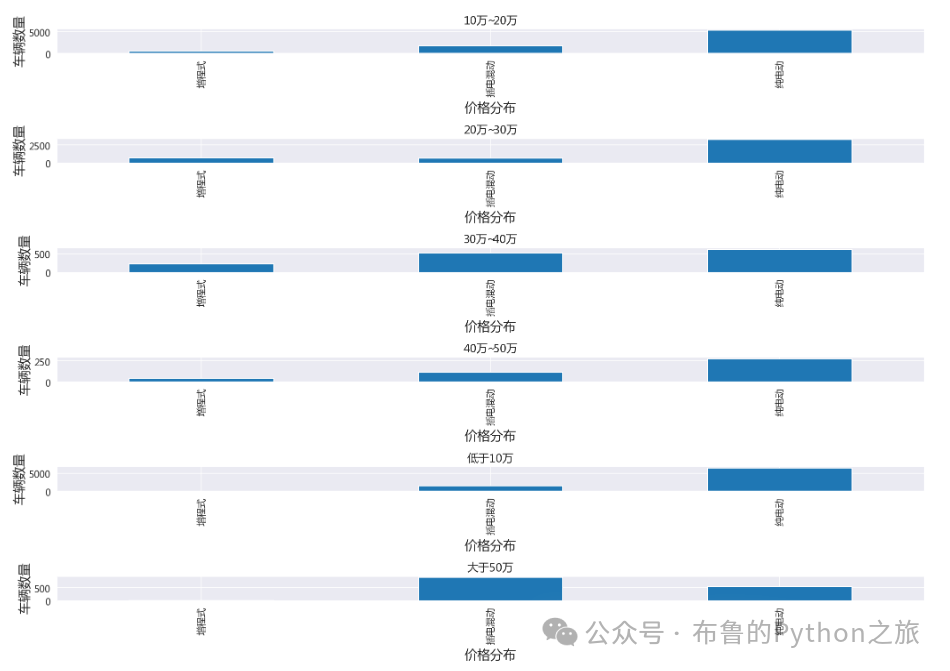
可视化了不同燃料类型的价格分布。每个子图代表一种燃料类型的价格分布。从这些图表中,我们可以清楚地看到不同燃料类型车辆在不同价格区间的分布情况。
# 找到每种燃料类型中车辆数最多的价格分布
max_distribution = fuel_type_distribution.idxmax()
# 找到每种燃料类型中最常见价格分布的车辆数量
max_counts = fuel_type_distribution.max()
# 将结果组合成一个DataFrame
max_distribution_df = pd.DataFrame({
'燃料类型': max_distribution.index, # 燃料类型
'最常见价格区间': max_distribution.values, # 最常见的价格区间
'车辆数量': max_counts # 车辆数量
})
max_distribution_df
输出结果:
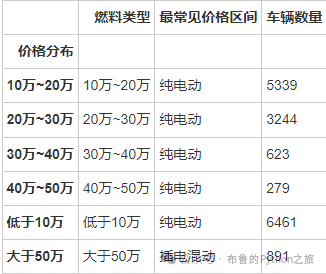
从上面的表格中,我们可以看到:
-
• 对于纯电动车辆,车辆数量最多的价格区间是“低于10万”。
-
• 对于插电混动车辆,车辆数量最多的价格区间是“大于50万”。
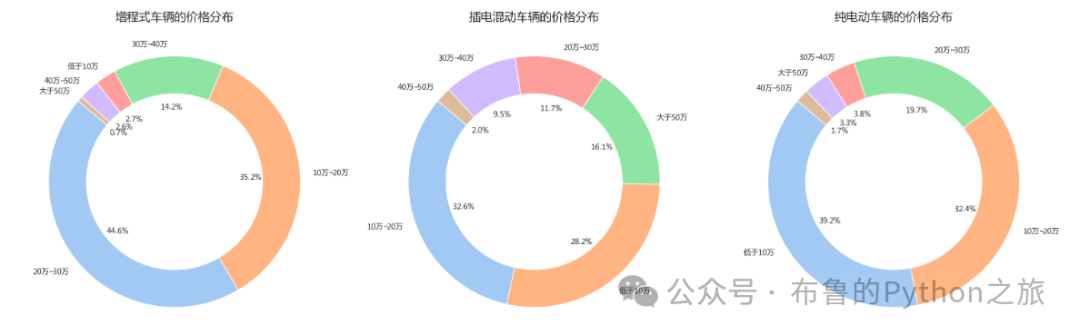
3.6 不同车型的价格分布
data_1 = data[data["燃料类型"] == "增程式"]
data_2 = data[data["燃料类型"] == "插电混动"]
data_3 = data[data["燃料类型"] == "纯电动"]
data_1_by_fuel_type = data_1['价格分布'].value_counts()
data_2_by_fuel_type = data_2['价格分布'].value_counts()
data_3_by_fuel_type = data_3['价格分布'].value_counts()
完整代码👇
https://www.heywhale.com/mw/project/65ff9e895d033872325bf1a0
ps:访问链接点击【在线运行】即可查看完整代码,且不需要担心环境配置问题
数据获取方式
关注公众号获取联系方式
- END -
以上就是本期为大家整理的全部内容了,喜欢的朋友可以点赞、点在看也可以分享让更多人知道。
👆 关注**「布鲁的Python之旅」**第一时间收到更新

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)