深度学习YOLO实战:16、YOLO数据集从获取到格式应用
前言
在使用 YOLO 模型做目标检测之前,一个绕不开的关键环节就是准备高质量的数据集。数据和模型的关系,就像燃料和发动机——优质的数据能让模型学得更准、用起来更稳。所以我们不能急于求成,而是要从数据的来源、收集方法到组织形式都仔细规划,为模型训练打下扎实基础。
数据来源
构建数据集的第一步,就是找到合适的数据来源。好的数据不仅要质量高,还要贴近你的实际任务场景。通常我们可以从以下几类来源入手:
公开数据集
如果你要做的是通用目标检测任务,完全可以借助已有的公开数据集,它们已经过专业整理和标注,能省去不少力气。下面这几个比较常用:
- COCO(Common Objects in Context):COCO 数据集规模非常大,包含了超过33万张图像、80个常见类别,每张图都有边界框、分割掩码等丰富的标注信息。正因为内容全面、标注质量高,它已经成为目标检测、实例分割等任务中最常用的基准数据集之一。
- PASCAL VOC(Visual Object Classes):PASCAL VOC 是一个比较经典的数据集,包括20个目标类别,比如人、车、自行车等。虽然数据量没有COCO那么大,但在目标检测算法发展的早期阶段被广泛使用,至今仍常被用来做模型对比测试。
- Roboflow Universe:Roboflow Universe 可以理解为计算机视觉领域的“数据集超市”,是目前全球最大的开源视觉数据平台之一。它汇集了超过5亿张图像、上百万个数据集以及大量训练好的模型,覆盖工业质检、物流、医疗等多个特殊场景,非常适合需要定制化数据的任务。
自定义数据集
如果你的检测目标比较特殊,比如工业零件缺陷、特定场所的设施等,公开数据集可能不够用,这时候就得自己动手做数据集了。常用方法包括:
- 摄像头拍摄:根据任务场景,直接用摄像头采集图像是最直接的方式。比如在产线上用高清工业相机拍产品图做缺陷检测,或者用手机、普通摄像头采集现场图像。
- 网络爬虫:通过编写爬虫程序,可以从图片网站、搜索引擎或公开图库中批量抓取和目标类别相关的图像。这种方式获取效率高,但要注意图片版权和内容合规性。
- 数据标注:原始图像必须经过标注才能用于训练。你可以用人工标注,也可以借助一些半自动标注工具(比如LabelImg、CVAT)。标注时要明确目标的类别和位置(边界框),有些任务可能还需要分割掩码或关键点等信息。
数据增强
除了收集真实数据,我们还能用数据增强技术自动生成更多训练样本,这样能显著提升模型对角度、光照、尺度等变化的适应能力。常用的增强手段包括:
- 旋转:将图像旋转一定角度(如90°、180°),让模型学会识别不同方向的目标。
- 缩放:对图像做放大或缩小,模拟目标远近变化带来的尺度差异。
- 裁剪:随机截取图像中的某个区域,训练模型关注目标的不同局部位置。
- 颜色调整:通过改变图像的亮度、对比度、饱和度等,模仿不同光照和拍摄条件。
数据集目录结构规范
想让YOLO模型顺畅地读取数据,第一步就是给数据集一个“整洁的房间”——也就是一个清晰、规范的目录结构。这不仅方便我们自己管理数据,更能省去很多在训练时调试数据路径的麻烦。一个结构良好的数据集通常会长成这样:
数据集根目录/
├── images/ # 存放所有图片
│ ├── train/ # 训练集图片
│ └── val/ # 验证集图片
├── labels/ # 存放所有标签文件
│ ├── train/ # 训练集标签
│ └── val/ # 验证集标签
├── LICENSE # 许可证文件(可选)
└── README.md # 说明文档(可选)
1. 数据集根目录
这是整个数据集的“大本营”,所有其他文件夹和文件都放在这里面。你可以根据项目给它起个合适的名字,比如 缺陷检测数据集_v1,做到一目了然。
2. 图片目录images/ 目录专门用来存放所有的图像文件。为了把训练和评估用的数据分开,我们通常会在里面再建两个子文件夹:
- train/:存放用于训练的图片。模型就是通过学习这些图片来认识目标的。
- val/:存放用于验证的图片。这些图片在训练过程中用来定期检验模型学得怎么样,防止它只会“死记硬背”训练集。
3. 标签目录labels/目录则存放所有与图片对应的标签文件。在目标检测中,标签文件通常为.txt格式,里面精确记录了每个目标的类别和边界框位置。它的子目录结构和images/是一一对应的: - train/:存放训练集图片对应的标签文件。每个标签文件(如
image_001.txt)都对应着images/train/里的一张图片(如image_001.jpg)。 - val/:同样,存放验证集图片对应的标签文件。
数据集配置文件(.yaml)
准备好数据集之后,我们还需要给YOLO模型一张“导航地图”,也就是数据集配置文件(通常以 .yaml 为后缀)。这个文件虽然小,但作用非常关键——它会明确告诉模型:训练和验证用的图片、标签分别在哪里,以及数据集中到底有哪些类别。没有它,模型训练就无从谈起。
数据集配置文件的结构
一个标准的.yaml配置文件主要包含三大块内容:数据集根目录、图片路径和类别名称。
数据集根目录路径
path 字段用于设定数据集的根目录。你可以使用绝对路径,也可以使用相对路径,这为在不同环境中使用提供了灵活性。
# 数据集根目录路径
path: /home/user/projects/datasets/coco8 # 方式1:绝对路径
# 或者
path: ./datasets/coco8 # 方式2:相对路径
# 或者
path: coco8 # 方式3:预置数据集名称
路径类型详解:
- 绝对路径:从系统根目录开始的完整路径
- 示例:
/home/user/datasets/coco8或C:\Users\user\datasets\coco8 - 特点:精确指向,但在不同环境间迁移需要修改
- 示例:
- 相对路径:相对于当前工作目录的路径
- 示例:
./datasets/coco8或../datasets/coco8 - 特点:以
./或../开头,便于项目移植
- 示例:
- 预置数据集名称:YOLO框架内置的默认路径
- 示例:
coco8、coco128、voc等 - 特点:直接使用名称,指向框架安装目录下的预置数据集路径
- 实际路径:
ultralytics/datasets/coco8
- 示例:
图片路径配置
train 和 val 字段分别用来定义训练集和验证集图片的具体位置。请注意,这里设置的路径是相对于上面 path 目录的。
# 图片路径配置(相对于path的路径)
train: images/train # 训练集图片路径
val: images/val # 验证集图片路径
test: # 测试集图片路径(可选)
- 训练集路径:模型学习时看的图片就来自这里。
- 验证集路径:模型在训练过程中,会定期用这里的图片来评估自己的表现。
- 测试集路径:这个字段是可选的,如果你的数据集包含专门的测试集,可以在这里指定。
类别定义
names 字段是一个字典,它建立了类别ID和类别名称的对应关系。标签文件里记录的正是这些ID,模型最终输出的是这些名称。
# 类别定义
names:
0: person
1: bicycle
2: car
# ... 其他类别
44: spoon
45: bowl
46: banana
# ... 更多类别
- 类别ID:从0开始的整数,必须连续且与标签文件中的ID一致。
- 类别名称:最好使用清晰、无歧义的英文单词或缩写。
完整示例:coco8.yaml
把上面三个部分组合起来,就是一个完整的配置文件:
# 数据集根目录路径
path: coco8 # 可以是绝对路径或相对路径
# 图片路径配置(相对于path的路径)
train: images/train # 训练集图片路径
val: images/val # 验证集图片路径
test: # 测试集图片路径(可选)
# 类别定义
names:
0: person
1: bicycle
2: car
# ... 其他类别
44: spoon
45: bowl
46: banana
# ... 更多类别
重要说明与常见误区
理解以下三点,可以避免绝大多数配置错误:
path是锚点:它定义了所有路径的起点。train/val是相对路径:它们不是从系统根目录,也不是从当前目录开始,而是从path指向的目录开始计算。例如,上面的配置中,训练集图片的实际路径是./datasets/coco8/images/train/。- 标签路径自动关联:你不需要在.yaml文件里指定标签的位置。YOLO有一套默认规则:它会自动将
images/train替换为labels/train,并在该目录下寻找与图片文件同名的.txt标签文件。
标签文件的自动关联规则
YOLO通过一套简单的命名和目录规则,自动为每张图片找到其对应的标签文件。
规则很简单:
- 图片放在
images/{train,val}/目录下。 - 标签放在
labels/{train,val}/目录下。 - 图片和标签必须具有完全相同的文件名(仅扩展名不同)。
举个例子:
假设你的训练集里有一张图片,路径为:./datasets/coco8/images/train/000000000009.jpg
那么YOLO模型会自动去以下路径寻找它的标签:./datasets/coco8/labels/train/000000000009.txt
这种“镜像”式的目录结构设计,使得路径管理非常清晰,只需要在.yaml文件中配置好图片路径,模型就能自动处理好一切。
YOLO标签格式详解
在 YOLO 模型中,每一张用于训练的图片都必须对应一个同名的标签文件(.txt 格式)。这个文件就像是给模型的“标准答案”,告诉它图片中每个目标的具体位置和类别。模型通过对比自己的预测和这些“标准答案”来不断学习和调整。
YOLO 标签文件的核心格式
每个标签文件(.txt)可能包含多行,每一行代表图片中的一个目标实例。这一行数据遵循一个固定的格式:
<class_id> <cx> <cy> <width> <height>
字段详细说明
为了更好地理解,我们可以把这一行数据想象成对目标的一个精简描述:
<class_id>(类别ID)- 是什么:一个整数(例如 0, 1, 2…),代表目标的类别。
- 从哪里来:这个数字与你之前在数据集配置文件(.yaml)的
names字段里定义的顺序完全对应。比如,如果names里0: person,那么标签里的0就代表“人”。
<cx> <cy>(中心点坐标)- 是什么:目标边界框中心点的 X 和 Y 坐标。
- 关键特性:它们是归一化后的坐标,意思是其数值在 0 到 1 之间。具体计算方法是:
(中心点x坐标 / 图片宽度)和(中心点y坐标 / 图片高度)。这样做是为了让模型不受图片具体尺寸的影响。
<width> <height>(边界框尺寸)- 是什么:目标边界框的宽度和高度。
- 关键特性:它们同样是归一化后的尺寸,数值范围也是 0 到 1。计算方法是:
(边界框宽度 / 图片宽度)和(边界框高度 / 图片高度)。
示例:从标签到边界框
让我们通过一张真实的图片和它的标签文件,完整地走一遍解码过程,看看YOLO是如何通过一行数字“看到”图片中的物体的。
图片与标签文件
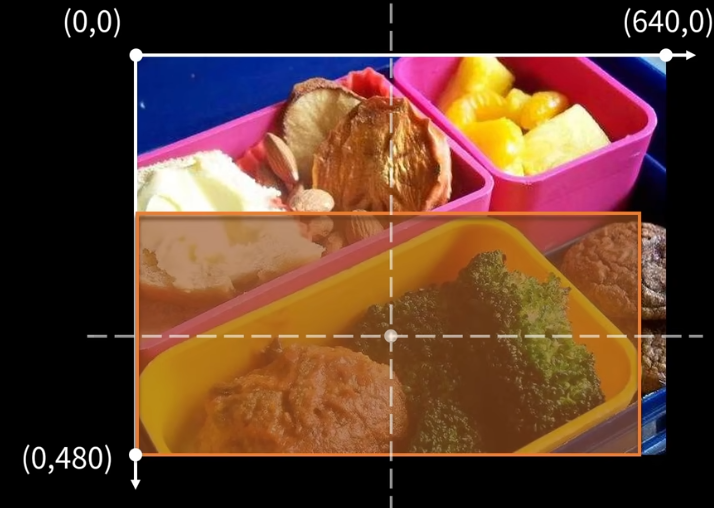
这是我们的一张训练图片,图片尺寸为 640x480 像素:

它的同名标签文件(.txt)内容如下,每一行都代表图片中的一个目标:
45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.0969375
49 0.773148 0.129802 0.0907344 0.0972292
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.0792187 0.148063 0.148062
解码第一个目标
我们以第一行 45 0.479492 0.688771 0.955609 0.5955 为例,进行解码。
第一步:识别类别
- 标签开头是
45。我们去数据集的YAML配置文件中查找names字段:
names:
0: person
... # 中间类别省略
44: spoon
45: bowl # 找到了!
46: banana
...
- 结论:这个目标是一个 碗 (bowl)。
第二步:计算实际像素坐标和尺寸
我们将归一化坐标乘以图片的实际尺寸,得到像素值:
- 中心点 (cx, cy):
cx = 640 * 0.479492 ≈ 306.87像素cy = 480 * 0.688771 ≈ 330.61像素
- 尺寸 (width, height):
w = 640 * 0.955609 ≈ 611.59像素h = 480 * 0.5955 = 285.84像素
第三步:还原边界框的角点坐标
在图像处理中,我们通常用左上角 (x1, y1) 和右下角 (x2, y2) 来绘制矩形。
- 左上角 x1:
cx - w/2 = 306.87 - 611.59/2 ≈ 1.08像素 - 左上角 y1:
cy - h/2 = 330.61 - 285.84/2 ≈ 187.69像素 - 右下角 x2:
cx + w/2 = 306.87 + 611.59/2 ≈ 612.67像素 - 右下角 y2:
cy + h/2 = 330.61 + 285.84/2 ≈ 473.53像素
请注意:计算出的
x1(1.08) 接近于0,而x2(612.67) 大于图片宽度(640),w(611.59) 也非常接近图片宽度(640)。这表示这个“碗”的边界框几乎与图片同宽,是一个很大的、位于画面中央的物体。这在我们的示例图片中是符合事实的。
在训练中使用数据集
当我们准备好数据集和对应的配置文件(.yaml)后,下一步就是要在训练脚本中正确地指向它。这个过程就像是给导游一张地图,模型会根据这份“地图”去找到所有的训练“素材”。
训练脚本中的数据集配置
在YOLO的训练脚本中,我们通过 data 这个关键参数来指定数据集配置文件的路径。这是一个完整的训练示例:
from ultralytics import YOLO
if __name__ == "__main__":
# 加载一个预训练模型
model = YOLO("yolo11n.pt")
# 开始训练
model.train(
data="coco8.yaml", # 核心:告诉模型去哪里找数据
epochs=100,
imgsz=640,
batch=16,
device=0, # 使用GPU 0
workers=4, # 设置数据加载的线程数
)
如何指定配置文件的路径
你可以根据配置文件存放的位置,用以下几种方式来指定路径:
-
使用内置数据集名(最方便)
如果你使用的是Ultralytics官方提供的内置数据集(如coco8.yaml,coco128.yaml),直接写文件名即可,YOLO会自动在它的内置目录里找到。model.train(data="coco8.yaml") # 直接使用内置数据集 -
使用绝对路径(最可靠)
如果配置文件在你系统的特定位置,使用完整路径绝对错不了。model.train(data="/home/user/projects/datasets/my_custom_data.yaml") -
使用相对路径(很常见)
如果配置文件就在你的项目目录里,使用相对于当前运行脚本的路径。model.train(data="./datasets/my_custom_data.yaml")重要提示:使用相对路径时,请确保你的当前工作目录是正确的。如果你在项目的根目录下运行脚本,那么
./datasets/就能正确指向;如果你在别的子目录下运行,路径就可能出错。
预置数据集在哪里?
YOLO(特别是Ultralytics版本)贴心地为我们准备了许多常用数据集的配置文件。它们通常安装在你的Python环境下的 ultralytics 包目录里。
查找预置数据集路径的方法:
你可以在终端中运行以下命令来快速定位(以Unix系统为例):
find /home/你的用户名 -name "coco8.yaml" 2>/dev/null
通常,它们会出现在类似下面的路径中:
/home/你的用户名/.local/lib/python3.8/site-packages/ultralytics/cfg/datasets/
常见的预置数据集
这些预置文件非常适合用来做快速测试和学习:
coco8.yaml:COCO数据集的极简8张图片版,适合一分钟内跑通训练流程。coco128.yaml:COCO数据集的128张图片子集,适合初步验证模型效果。coco.yaml:完整的COCO数据集配置,用于正式的大型模型训练。voc.yaml:经典的PASCAL VOC数据集配置。
实战示例
场景一:使用内置数据集进行快速测试
如果你想快速验证你的环境是否配置正确,用 coco8 是最佳选择。
model.train(
data="coco8.yaml", # 直接调用内置迷你数据集
epochs=10,
imgsz=640
)
场景二:使用你自己的数据集
当你用自己的数据训练时,只需将 data 参数指向你自己的.yaml文件。
model.train(
data="/home/your_project/datasets/缺陷检测_v1.yaml", # 指向你的自定义配置文件
epochs=100,
imgsz=640
)
关键提醒:
确保你的.yaml文件中的 path、train、val 路径设置正确,并且图片和标签文件严格按照之前讲的目录结构存放。这是训练能够成功启动的基石。如果遇到“找不到图片”的错误,第一件事就是检查这些路径。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)