自己动手写深度学习框架(用labelImg标记样本)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 学习深度学习之前,以为自己大部分时间都是在做算法。但是做了之后,才发现自己大部分时间都在清洗数据。和算法相比较,数据本身的价值,可能要比算法还要大。而且除了数据之外,嵌入式部署也是非常重要的,反而是算法,大部分时间就是微调,很少会对网络做大的改动。
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
学习深度学习之前,以为自己大部分时间都是在做算法。但是做了之后,才发现自己大部分时间都在清洗数据。和算法相比较,数据本身的价值,可能要比算法还要大。而且除了数据之外,嵌入式部署也是非常重要的,反而是算法,大部分时间就是微调,很少会对网络做大的改动。
1、什么时候需要标记图片
如果只是分类功能,那么不需要使用标记软件进行标记。只有处理检测和分类的时候,特别是yolo分类的时候,才需要手动去标记图片。
2、labelImg怎么下载
这里下载的时候,需要注意一个事情,那就是下载的时候,不要直接使用pip3去下载labelImg软件。这样下载得到的软件,会发现标记的时候,很容易程序闪退。反而,我们需要做的,就是直接从下面这个地址下载exe软件,直接使用即可。
https://github.com/heartexlabs/labelImg/releases3、使用方法
labelImg的使用方法比较简单。首先,我们一般提前选择好有哪些分类,类似于这样,
dog
person
cat
tv
car
meatballs
marinara sauce
tomato soup
chicken noodle soup
french onion soup
chicken breast
ribs
pulled pork
hamburger
cavity接着打开labelImg,选择指定的目录,就可以开始标记图片了。软件会帮助我们打开目录下的第一张图片。这个时候,可以选择一下标记文件存放的位置、以及标记文件的格式。
说到标记文件格式,它可以是xml的标记格式,也可以是yolo的标记格式。接下来,就可以开始选择标记图片了,选择标记的时候,鼠标至上而下,从左到右拖动选择即可,停下来之后,会有一个提示框,提醒我们选择的类别,
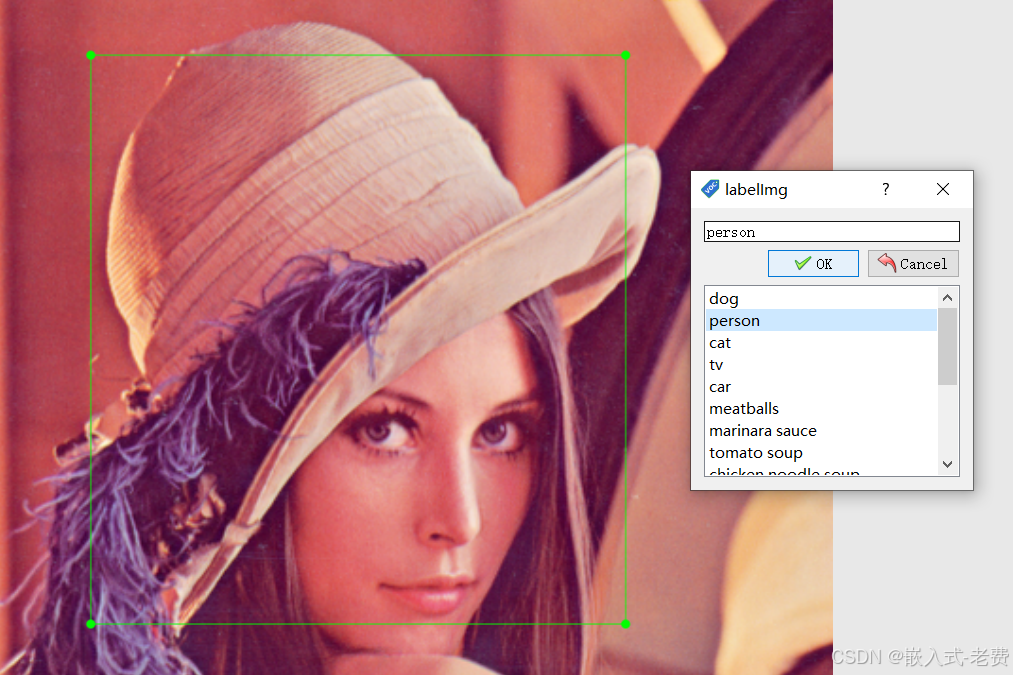
设定好之后就可以选择下一张图片。当然,一张图片上,可能有很多的类别,我们只要去一个、一个标记即可。这个时候,在之前设定的目录上,也会生成一个txt文件,保存我们标记的结果。图片和标记结果是一一对应的。这样不停地标记图片,就可以不停得到我们想要的标记结果了。
4、标记中的负样本
实际操作的时候,有一种负样本需要注意下。那就是客户的实际场景中,要搜集一些背景相同,但是没有roi物体的图片。并且一般来说,正样本和负样本达到1:2,这样才能达到比较好的训练效果。负样本也不是随便添加的,最好取材于真实的场景,和正样本一样,都是切实存在的,只是没有标的物而已。此外,负样本的数量不易过少,至少1:1以上。
5、样本不够的情形
目前如果样本不够,基本只能通过噪声、旋转、偏移、缩放等方法,来扩充样本数量了。当然最终还是希望由真实的样本参与训练,一开始样本实在不够,可以通过数学的方法凑上去也行。后续慢慢补上就可以了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)