Python数据分析_Pandas_分组_5
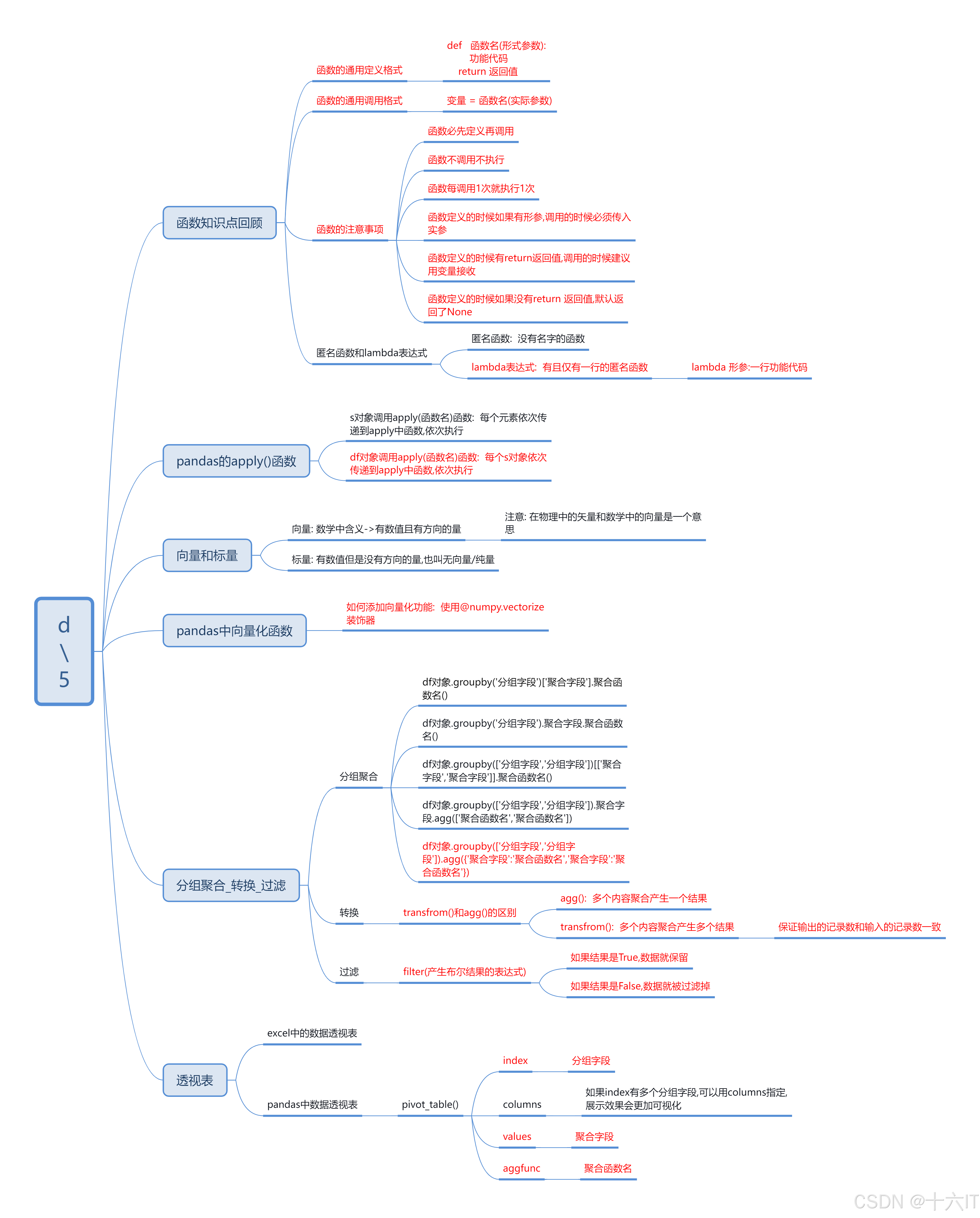
apply自定义函数向量化函数及Lambda表达式分组操作相关分组聚合分组转换分组过滤DataFrameGroupBy对象介绍概述当Pandas自带的API不能满足需求, 例如: 我们需要遍历的对Series中的每一条数据/DataFrame中的一列或一行数据做相同的自定义处理, 就可以使用Apply自定义函数apply函数可以接收一个自定义函数, 可以将DataFrame的行/列数据传递给自定义
·
文章目录
-
-
-
- 内容大纲介绍
- apply自定义函数
-
- Series的apply方法
- DataFrame的apply方法
- apply应用练习
- 1.向量化函数
- 2.Lambda表达式
- 3.分组聚合
- 4.分组转换
- 5.分组过滤
- 6.DataFrameGroupby
- 7.数据透视表
-
- 01_apply函数应用.py
- 02_分组聚合_转换_过滤.py
-
内容大纲介绍
- apply自定义函数
- 向量化函数及Lambda表达式
- 分组操作相关
- 分组聚合
- 分组转换
- 分组过滤
- DataFrameGroupBy对象介绍
apply自定义函数
Series的apply方法
-
概述
- 当Pandas自带的API不能满足需求, 例如: 我们需要遍历的对Series中的每一条数据/DataFrame中的一列或一行数据做相同的自定义处理, 就可以使用Apply自定义函数
- apply函数可以接收一个自定义函数, 可以将DataFrame的行/列数据传递给自定义函数处理
- apply函数类似于编写一个for循环, 遍历行/列的每一个元素,但比使用for循环效率高很多
-
代码演示
import pandas as pd # 1. 准备数据 df = pd.DataFrame({'a': [10, 20, 30], 'b': [20, 30, 40]}) df # 2. 创建1个自定义函数. def my_func(x): # 求平方 return x ** 2 def my_func2(x, e): # 求x的e次方 return x ** e # 3. apply方法有一个func参数, 把传入的函数应用于Series的每个元素 # 注意, 把 my_func 传递给apply的时候,不要加上小括号. df['a'].apply(my_func) # 传入函数对象. df['a'].apply(my_func2, e = 2) # 传入函数对象, e次幂(这里是平方) df['a'].apply(my_func2, e = 3) # 传入函数对象, e次幂(这里是立方)
DataFrame的apply方法
-
格式
-
df.apply(func, axis = )
axis = 0 按列传递数据 传入一列数据(Series)
axis = 1 按行传递数据 传入一列数据(Series)
-
-
代码演示
# 1. 把上面创建的 my_func, 直接应用到整个DataFrame中 df.apply(my_func) # my_func函数会作用到 df对象的每一个值. # 2. 报错, df对象是直接传入一列数据的, 并不是 一个值一个值传入的 def avg_3(x, y, z): return (x + y + z) / 3 df.apply(avg_3) # 3. 演示 df对象, 到底传入啥. def my_func3(x): print(x) print(f'x的数据类型是: {type(x)}') # 每次传入 1 列 # df.apply(my_func3, axis=0) # 0(默认): 列, 1: 行 # 每次传入 1 行 df.apply(my_func3, axis=1) # 0(默认): 列, 1: 行
apply应用练习
-
需求1: 计算泰坦尼克数据中, 每列的null值总数, 缺失值占比, 非缺失值占比
# 1. 加载数据 titanic = pd.read_csv('data/titanic_train.csv') titanic.info() # 2. 该数据集有891行,15列, 其中age 和 deck 两列中包含缺失值 # 2.1 定义函数, 计算: 数据中有多少null 或 NaN值 def count_missing(col): # 计算一列中, 缺失值的个数. return pd.isnull(col).sum() # 2.2 缺失值占比 def prop_missing(col): # 缺失值总数 / 该列数据总数 return count_missing(col) / col.size # 2.3 非缺失值占比 def prop_complete(col): # 缺失值总数 / 该列数据总数 return 1 - prop_missing(col) # 3. 调用上述的函数. titanic.apply(count_missing) # 不要加小括号, 传入的是: 函数对象. titanic.apply(prop_missing) # 不要加小括号, 传入的是: 函数对象. titanic.apply(prop_complete) # 不要加小括号, 传入的是: 函数对象. -
需求2: 统计泰坦尼克 的数据中, 各年龄段总人数.
# 1. 定义函数, 实现把 年龄 转成 年龄段 def cut_age(age): if age < 18: return '未成年' elif 18 <= age < 40: return '青年' elif 40 <= age < 60: return '中年' elif 60 <= age < 81: return '老年' else: return '未知' # 2. 调用上述的函数. titanic['Age'].apply(cut_age) # 3. 统计每个年龄段, 共有多少人. titanic['Age'].apply(cut_age).value_counts() -
需求3: 统计VIP 和 非VIP的客户总数
# 定义函数, 判断是否是VIP客户 # 条件: 乘客船舱等级为 1 并且 名字中带 'Master', 'Dr' 或者 'Sir' def get_vip(x): if x['Pclass'] == 1 and ('Master' in x['Name'] or 'Dr' in x['Name'] or 'Sir' in x['Name']): return 'VIP' else: return 'Normal' # axis = 1, 表示以行的方式传入. titanic.apply(get_vip, axis=1).value_counts()
1.向量化函数
-
分析代码
def avg_test2(x,y): if x==20: return np.NaN else: return (x+y)/2 avg_test2(df['a'],df['b']) -
报错原因
- 上面的方法调用之所以报错, 就是因为if 需要传入的是 一个True/False .
- 但是我们传入的是一个 True/False 组成的Series 此时if 不能做出判断, 抛出了错误
- 想让上面的代码正常的执行, 我们需要把 Series里的每一个值遍历的传递给if 做多次判断,
- 此时必须要自己写for循环, 可以通过 np.vectorize(avg_test2) 这种方式,
- 把这个方法变成一个向量化的方法(会遍历每一个值(分量)多次调用这个方法)
-
具体代码演示
import numpy as np import pandas as pd # 1. 创建1个df对象 df = pd.DataFrame({'a': [10, 20, 30], 'b': [20, 30, 40]}) # 2. 查看数据 df # 3. 创建自定义函数. def avg_2(x, y): return (x + y) / 2 # 4. 调用自定义函数. avg_2(df['a'], df['b']) # 5. 修改上述的函数. @ np.vectorize # 装饰器方式实现向量化 def avg_2_mod(x, y): if x == 20: # 报错, x是向量(一列数据), 20是标量(1个数据) return np.NAN else: return (x + y) / 2 avg_2_mod(df['a'], df['b']) # 如果是装饰器方式实现了向量化操作, 则这里不会报错. # 6. 使用 np.vectorize 将函数向量化. # 写法1: 通过 np.vectorize(要被向量化的函数名) 方式实现. avg_2_mod_vec = np.vectorize(avg_2_mod) avg_2_mod_vec(df['a'], df['b'])
2.Lambda表达式
-
背景
- 当函数比较简单的时候, 没有必要创建一个def 一个函数, 可以使用lambda表达式创建匿名函数
-
格式
lambda 形参列表 : 函数体 -
代码演示
df.apply(lambda x: x + 1) df.apply(lambda x: x.isnull().sum()) df.apply(lambda x: x.mean())
3.分组聚合
-
概述
- 在SQL中我们经常使用 GROUP BY 将某个字段,按不同的取值进行分组,
- 在pandas中也有groupby函数, 分组之后,每组都会有至少1条数据, 将这些数据进一步处理,
- 返回单个值的过程就是聚合,比如分组之后计算算术平均值, 或者分组之后计算频数,都属于聚合
-
代码演示
-
基础写法
# 1. 读取数据. import pandas as pd df = pd.read_csv('data/gapminder.tsv', sep='\t') df.head() # 2. 需求1: 对 year 分组, 求每年的平均寿命 # 2.1 代码实现 df.groupby('year').lifeExp.mean() # 2.2 分析上述代码原理, 先查看year数据, 有几个值. df['year'].unique() # 2.3 计算第1组(年)的 平均寿命, 依次类推, 计算每组的平均值即可. df[df['year'] == 1952]['lifeExp'].mean() df[df.year == 1952].lifeExp.mean() # 效果同上. # 3. 需求2: 统计每个大洲, 平均寿命. # 3.1 代码实现上述需求 df.groupby('continent').lifeExp.mean() # 3.2 也可以用 agg函数. df.groupby('continent').lifeExp.agg('mean') # 效果同上. df.groupby('continent').agg({'lifeExp': 'mean'}) # 效果同上. df.groupby('continent').aggregate({'lifeExp': 'mean'}) # 效果同上. # 3.3 也可以使用Numpy库的mean()函数 import numpy as np df.groupby('continent').agg({'lifeExp': np.mean}) # 效果同上. # 3.4 分组之后, 也可以通过调用 describe()函数, 查看具体的统计信息. df.groupby('continent').lifeExp.describe() -
调用自定义函数
# 4.自定义函数, 如果想在聚合的时候, 使用非Pandas或其他库提供的计算,可以自定义函数然后在aggregate中调用它 # 4.1 自定义函数, 计算平均值. def my_mean(col): # df传入的是一列(Series对象), 直接计算: 该列和 / 该列总数 即可. return col.sum() / col.size # 4.2 调用自定义函数. df.groupby('year').lifeExp.agg(my_mean) # 5. 计算每年平均寿命 和 数据集整体的平均寿命的差值. # 5.1 自定义函数, 参1: 某列数据. 参2: 数据集整体的平均寿命 def my_mean_diff(s, global_mean): return s.mean() - global_mean # 5.2 调用函数. # 计算平均值 global_mean = df['lifeExp'].mean() # 调用函数 df.groupby('year').lifeExp.agg(my_mean_diff, global_mean) -
同时传入多个函数
# 6. 同时传入多个函数 # 分组之后想计算多个聚合函数,可以把它们全部放入一个Python列表,然后把整个列表传入agg或aggregate中 # 需求: 按年计算lifeExp 的非零个数,平均值和标准差 df.groupby('year').lifeExp.agg([np.count_nonzero, np.mean, np.std]) # 分组之后,可以对多个字段用不同的方式聚合 df.groupby('year').agg({'lifeExp':'mean','pop':'median','gdpPercap':'median'})
-
4.分组转换
-
概述
- transform 需要把DataFrame中的值传递给一个函数, 而后由该函数"转换"数据。
- 即: aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量
-
代码演示
-
需求1: 计算z-score(也叫: z分数, 标准分数)
# 需求1: 计算z-score(也叫: z分数, 标准分数), 即: (x - 平均值) / 标准差 def my_zscore(x): # (每一组的值 - 当前组的平均值) / 当前组的标准差 return (x-x.mean())/x.std() # 按年分组 计算z-score df.groupby('year').lifeExp.transform(my_zscore) # 查看数据集条目数, 跟之前transform处理之后的条目数一样 df.shape # 1704行, 6列 -
需求2: transform 分组填充缺失值
不同性别填充的缺失值, 是各自性别的总消费平均值
# 需求2: transform 分组填充缺失值 # 之前介绍了填充缺失值的各种方法,对于某些数据集,可以使用列的平均值来填充缺失值。 # 某些情况下,可以考虑将列进行分组,分组之后取平均再填充缺失值 # 1. 加载数据, tips = 小费的数据, 字段为: 总账单, 小费, 性别, 是否抽烟, 周几, 什么餐(午餐, 晚餐), 几个人(一起吃饭) # sample(): 随机抽样的, 参1: 抽几条数据, 参2: 随机种子, 如果种子一样, 每次抽取的数据都是一样的. tips_10 = pd.read_csv('data/tips.csv').sample(10, random_state = 42) # 2. 构建缺失值 # np.random.permutation 将序列乱序 tips_10.loc[np.random.permutation(tips_10.index)[:4], 'total_bill'] = np.NaN tips_10 # 3. 查看缺失情况 count_sex = tips_10.groupby('sex').count() count_sex # 4. 定义函数填充缺失值 def fill_na_mean(x): # 计算每组的 小费平均值, 利用均值填充缺失值. return x.fillna(x.mean()) # 5. 根据性别进行分组, 对总消费的缺失值做自定义处理, 使用了分组转换. tips_10.groupby('sex').total_bill.transform(fill_na_mean)
分组转换跟SQL中的窗口函数中的聚合函数作用一样
- 可以把每一条数据和这个数据所属的组的一个聚合值在放在一起, 可以根据需求进行相应计算
-
5.分组过滤
-
概述
- 使用groupby方法还可以过滤数据
- 调用filter 方法,传入一个返回布尔值的函数,返回False的数据会被过滤掉
-
代码演示
# 需求: 根据就餐人数进行分组, 过滤掉条目数少于30条的组 # 1. 使用小费数据 tips = pd.read_csv('data/tips.csv') # 2. 查看用餐人数 tips['size'].value_counts() # 3. 人数为1、5和6人的数据比较少,考虑将这部分数据过滤掉 tips_filtered = tips.groupby('size').filter(lambda x: x['size'].count() > 30) # 4. 查看结果 tips_filtered['size'].value_counts() # 5. 合并版写法 tips.groupby('size').filter(lambda x: x['size'].count() > 30)['size'].value_counts()
6.DataFrameGroupby
-
概述
- 调用了groupby方法之后, 就会返回一个DataFrameGroupby对象
-
代码演示
# 1. 准备数据 tips_10 = pd.read_csv('data/tips.csv').sample(10,random_state = 42) # 2. 调用groupby 创建分组对象, 按性别分组 grouped = tips_10.groupby('sex') # 3. 查看grouped grouped # grouped是一个DataFrameGroupBy对象 # 4. 通过groups属性查看计算过的分组 grouped.groups # 5. 上面返回的结果是DataFrame的索引,实际上就是原始数据的行数 # 在DataFrameGroupBy对象基础上,直接就可以进行aggregate,transform计算了 grouped.mean() # 6. 上面结果直接计算了按sex分组后,所有列的平均值,但只返回了数值列的结果,非数值列不会计算平均值 # 通过get_group选择分组 female = grouped.get_group('Female') female # 7. 通过groupby对象,可以遍历所有分组 # 相比于在groupby之后使用aggregate、transform和filter,有时候使用for循环解决问题更简单 for sex_group in grouped: # print(sex_group) # 返回的是元组形式, 索引0: 分组名, 索引1: 该分组的信息. print(sex_group[1]) # 只看该分组的信息 # 细节: DataFrameGroupBy对象直接传入索引,会报错 # grouped[0] # 报错 # 8. 多个字段分组, 例如: 按性别 和 用餐时间 分别计算小费数据的平均值. tips_10.groupby(['sex', 'time']).mean() # 不把分组字段作为索引列. tips_10.groupby(['sex', 'time'], as_index=False).mean()
7.数据透视表
-
透视表概述
- 数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。
- 所进行的计算与数据跟数据透视表中的排列有关。之所以称为数据透视表,是因为可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据。
- 另外,如果原始数据发生更改,则可以更新数据透视表。在使用Excel做数据分析时,透视表是很常用的功能,Pandas也提供了透视表功能,对应的API为pivot_table
-
透视表pivot_table函数介绍
- pandas有两个pivot_table函数
- pandas.pivot_table
- pandas.DataFrame.pivot_table
- pandas.pivot_table 比 pandas.DataFrame.pivot_table 多了一个参数data,data就是一个dataframe,实际上这两个函数相同
- pivot_table参数中最重要的四个参数 :
- values: 要做聚合操作的列名
- index: 行索引, 传入原始数据的列名, 这一列中每个取值会作为透视表结果的1个行索引.
- columns: 列索引, 传入原始数据的列名, 这一列中每个取值会作为透视表结果的1列.
- aggfunc: 聚合函数
- pandas有两个pivot_table函数
01_apply函数应用.py
#%%
# 导包
import pandas as pd
import numpy as np
#%% md
# # 定义加减乘除四大函数
#%%
# 1.先定义函数
def func1(x, n=2):
return x + n
def func2(x, n=2):
return x - n
def func3(x, n=2):
return x * n
def func4(x, n=2):
return x / n
#%% md
# # apply应用到Series对象
#%%
# 需求: 将s对象中数据乘以2
# 创建s对象
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
s
#%%
# 2.再调用函数
# 方式1: 手动调用一个个调用
print(func1(s[0]))
print(func1(s[1]))
print(func1(s[2]))
print(func2(s[0]))
print(func2(s[1]))
print(func2(s[2]))
print(func3(s[0]))
print(func3(s[1]))
print(func3(s[2]))
print(func4(s[0]))
print(func4(s[1]))
print(func4(s[2]))
#%%
# 方式2: 手动遍历同时调用
for i in s:
print(func1(i, n=3))
for i in s:
print(func2(i, n=3))
for i in s:
print(func3(i, n=3))
for i in s:
print(func4(i, n=3))
#%%
# 方式3: pandas中的apply函数
# 注意: apply函数的参数是函数名没有括号(),返回值是新的Series对象
print(s.apply(func1, n=4))
print(s.apply(func2, n=4))
print(s.apply(func3, n=4))
print(s.apply(func4, n=4))
#%% md
# # lambda表达式
#%%
print(s.apply(lambda x: x + 2))
print(s.apply(lambda x: x - 2))
print(s.apply(lambda x: x * 2))
print(s.apply(lambda x: x / 2))
#%% md
# # apply应用df对象
#%%
# 创建df对象
df = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60], 'C': [70, 80, 90]})
df
#%%
# df应用apply函数
# 注意: 默认func函数拿到的第一个参数是Series对象
df.apply(func1, n=3)
#%%
# s应用apply函数
# 注意: 默认func函数拿到的第一个参数是Series中每个元素
s.apply(func1, n=3)
#%%
#%%
# 假设有一个函数如下
def func(x, y, z):
return (x + y + z) / 3
#%%
s.apply(func) # 报错,x依次代表每个元素10,20,30
df.apply(func) # 报错,x代表每个Series对象
#%%
# 计算df的平均值
def avg_3_apply(x):
return (x[0] + x[1] + x[2]) / 3
#%%
# s调用avg_3_apply函数
s.apply(avg_3_apply) # 报错,x依次代表每个元素10,20,30,所以不能单独根据索引再拿值
#%%
# df调用apply函数,x代表每个Series对象,默认是案例列
df.apply(avg_3_apply)
df.apply(avg_3_apply, axis='columns')
#%% md
# # lambda表达式
#%%
# 创建df对象
df = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60], 'C': [70, 80, 90]})
df
#%%
print(df.apply(lambda x: x + 2))
print(df.apply(lambda x: x - 2))
print(df.apply(lambda x: x * 2))
print(df.apply(lambda x: x / 2))
print(df.apply(lambda x: x.mean()))
print(df.apply(lambda x: x.max()))
print(df.apply(lambda x: x.min()))
print(df.apply(lambda x: x.sum()))
print(df.apply(lambda x: x.count()))
#%% md
# # apply应用
#%%
# 加载数据
df = pd.read_csv('数据集/titanic_train.csv')
df.info()
#%%
# 需求: 定义函数计算df的缺失值数量
# 定义函数
def missing_value(s):
return s.isnull().sum()
# 调用函数
df.apply(missing_value)
#%%
# 需求: 定义函数计算缺失值占比
# 定义函数
def missing_value_ratio(s):
return missing_value(s) / s.size
# 调用函数
df.apply(missing_value_ratio)
#%%
# 需求: 定义函数计算非缺失值占比
# 定义函数
def non_missing_value_ratio(s):
return 1 - missing_value_ratio(s)
# 调用函数
df.apply(non_missing_value_ratio)
#%% md
# # 向量化函数
#%%
# 创建df对象
df = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60], 'C': [70, 80, 90]})
df
#%%
# 回顾装饰器概念:在不改变原有函数基础上,为函数添加新的功能!
# 语法糖方式添加@np.vectorize,作用是将函数向量化
# 再添加@np.vectorize
@np.vectorize
# 先定义函数
def avg2(x, y):
if x == 20:
return np.NAN
else:
return (x + y) / 2
#%%
# 调用函数
avg2(df['A'], df['B']) # 默认报错,添加了@np.vectorize装饰器后就可以了
#%%
# python中两个列表相加
l1 = [10, 20, 30]
l2 = [40, 50, 60]
new_l = []
for i in range(len(l1)):
avg = (l1[i] + l2[i]) / 2
new_l.append(avg)
new_l
#%%
02_分组聚合_转换_过滤.py
#%%
# 1.导包
import pandas as pd
import numpy as np
#%% md
# # 回顾分组聚合操作
#%%
# 2.加载文件
df = pd.read_csv("数据集/gapminder.tsv", sep='\t')
#%%
df
#%%
# 3.了解数据
df.info()
df.describe()
df.isnull().sum()
#%%
# 4.分析数据
# 需求1: 求每个年份的平均寿命
df.groupby('year')['lifeExp'].mean()
df.groupby('year').lifeExp.mean()
df.groupby(['year'])[['lifeExp']].mean()
df.groupby(['year']).agg({'lifeExp': 'mean'})
df.groupby(['year']).agg({'lifeExp': np.mean})
# 注意:agg中可以单独传递多个函数名
df.groupby(['year']).lifeExp.agg(np.mean)
df.groupby(['year']).lifeExp.agg([np.mean, np.max, np.min])
df.groupby(['year']).lifeExp.aggregate([np.mean, np.max, np.min])
# 透视表方式
df.pivot_table(index='year', values='lifeExp', aggfunc='mean')
#%%
# 练习: 求每个年份每个大洲的平均寿命,平均GDP
df.groupby(['year', 'continent']).agg({'lifeExp': np.mean, 'gdpPercap': np.mean})
df.groupby(['year', 'continent']).agg({'lifeExp': 'mean', 'gdpPercap': 'mean'})
#%%
# 需求2: 获取所有年份
df.year.unique()
#%%
# 需求3: 单独获取1952年的平均寿命
df.groupby('year')['lifeExp'].mean()[1952]
df.groupby('year').lifeExp.mean()[1952]
# 注意: 在join或者groupby之前,能先过滤就先过滤!!!
df[df.year == 1952]['lifeExp'].mean()
df[df.year == 1952].lifeExp.mean()
#%%
# 注意: 分组后可以使用各种内置函数查看信息,比如describe()
df.groupby('year').lifeExp.describe()
#%% md
# # 自定义聚合函数
#%%
# 为什么要自定义函数? 如果现有的不能满足需求,再自定义函数
# 需求: 模仿已有的mean()等函数,自定义一个my_mean()函数
def my_mean(values):
# 平均数=总和/总个数
# 先计算总和
sum = 0
for value in values:
sum += value
# 再计算总个数
cnt = len(values)
# 计算平均数
avg = sum / cnt
return avg
# 测试自定义的函数
my_mean([1, 2, 3, 4, 5])
#%%
# 需求: 使用自定义的聚合函数求每年的平均寿命
df.groupby('year').lifeExp.agg(my_mean)
#%% md
# # transfrom转换函数
#%%
df[df.year == 1952] # 142条数据
#%%
# 需求: 求1952年的平均寿命
# 方式1: 原来的agg得到结果就1个
df[df.year == 1952].groupby('year').lifeExp.agg(my_mean)
#%%
# 方式2: transform得到的结果是142个
df[df.year == 1952].groupby('year').lifeExp.transform(my_mean)
#%% md
# ## transform综合练习
#%%
# 利用transform填充缺失值
# 加载数据
tips_df = pd.read_csv("数据集/tips.csv", sep=',')
tips_df.info()
#%%
# sample()采样10条记录 random_state是随机种子
tips10 = tips_df.sample(10, random_state=1)
tips10
#%%
# permutation()随机索引
np.random.permutation(tips10.index)
#%%
# 因为数据中没有缺失值,先构建缺失值
tips10.loc[np.random.permutation(tips10.index)[0:4], 'total_bill'] = np.nan
tips10
#%%
# 查看缺失值的个数
tips10.groupby('sex').count()
tips10.isnull().sum()
#%%
# 需求: 填充缺失值
new_tips10 = tips10.groupby('sex').total_bill.transform(lambda x: x.fillna(x.mean()))
new_tips10
#%%
# 填充后再次查看缺失值的个数
new_tips10.isnull().sum()
#%%
# 把刚刚填充好的数据替换到原来的数据中
tips10['fill_total_bill'] = new_tips10
tips10
#%% md
# # filter()过滤
#%%
# 1.加载数据
df = pd.read_csv("数据集/tips.csv", sep=',')
#%%
# 2.了解数据
df.info()
df.head()
df.groupby('sex').count()
#%%
# 3.分析数据
# 需求1: 查看用餐人数分布
df.groupby('size').count()
#%%
# 需求2: 把分组后统计用餐人数小于30的数据过滤掉
# 注意: filter()函数的功能是传入一个返回布尔值的函数,自动判断出True和False,最后自动过滤掉False的数据,返回True的数据
new_df = df.groupby('size').filter(lambda x: x['size'].count() >= 30)
#%%
# 验证需求2的结果是否已经把size是1,5,6的数据过滤了
new_df['size'].value_counts()
#%% md
# # 分组对象
#%%
# 1.加载数据
df = pd.read_csv("数据集/tips.csv", sep=',')
#%%
# 随机抽样10条数据
tips10 = df.sample(10, random_state=1)
tips10
#%%
# 根据性别分组,获取分组对象
dfg = tips10.groupby('sex')
#%%
# 单独获取性别为female的数据
dfg.get_group('Female')
#%%
# 单独获取性别为male的数据
dfg.get_group('Male')
#%%
# 获取每组的平均total_bill
dfg.mean()
dfg.total_bill.mean()
#%%
# 获取每组的第一条数据
dfg.first()
#%%
# 获取每组的最后一条数据
dfg.last()
#%%
# 查看分组对象中的数据
# 数据格式: (分组的列名,分组的索引)
dfg.groups
#%%
# 遍历分组对象,获取每个分组的详细数据
# 数据格式: ("分组列名",分组df详细数据)
for g in dfg:
print(g)
#%%
for g in dfg:
print(type(g))
print(len(g))
print(g[0], type(g[0]))
print(g[1], type(g[1]))
#%% md
# # 多个分组情况
#%%
# 1.加载数据
df = pd.read_csv("数据集/tips.csv", sep=',')
# 随机抽样10条数据
tips10 = df.sample(10, random_state=1)
tips10
#%%
# 需求: 按照性别和用餐时间分组,计算平均值
group_avg = df.groupby(['sex', 'time'])[['size']].mean()
group_avg
#%%
# 查看分组聚合结果中行索引
group_avg.index
#%%
# 查看分组聚合结果中列标签
group_avg.columns
#%%
# T转置操作(类似于hive中行列转换)
group_avg2 = group_avg.T
group_avg2
#%%
# 查看分组聚合结果中行索引
group_avg2.index
#%%
# 查看分组聚合结果中列标签
group_avg2.columns
#%%
# reset_index()重置行索引
group_avg3 = group_avg.reset_index()
group_avg3
#%%
# 分组时直接使用as_index=False
group_avg4 = tips10.groupby(['sex', 'time'], as_index=False)[['size']].mean()
group_avg4
#%% md
# # 数据透视表
#%%
# 1.加载数据
df = pd.read_csv("数据集/tips.csv", sep=',')
#%%
# 使用透视表计算每个性别,每个时间点,平均人数
# 方式1: index中直接指定多个分组字段,values中指定要聚合的字段,aggfunc指定聚合函数
df.pivot_table(index=['sex', 'time'], values='size', aggfunc='mean')
#%%
# 方式2: 把index中其中一个分组字段,放到columns中,values中指定要聚合的字段,aggfunc指定聚合函数
df.pivot_table(index='sex', columns='time', values='size', aggfunc='mean')
#%%
# 问题: pivot_table()表中的columns参数就是透视表中的列,对不对? 不对

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)