鲁鹏教授《计算机视觉与深度学习》课程笔记与思考 ——03. 线性分类器(下):损失、正则与优化
本文梳理了线性分类器训练的核心要点:1)多类SVM损失函数的最小值特性与工程验证方法;2)正则项通过约束参数防止过拟合,超参数λ平衡拟合与泛化;3)梯度下降的优化逻辑及数值/解析两种计算方式;4)数据集划分与预处理的重要性。文章强调从理论到实践的思维转变:接受迭代优化而非追求完美解、重视工程验证细节、数据准备优先于模型复杂度。这些训练逻辑为后续CNN等复杂模型奠定基础。
在上一篇笔记中,我梳理了鲁鹏教授课程中 “图像分类任务核心难点” 与 “线性分类器基础逻辑”,从 “图像如何表示”“线性分类器公式定义” 到 “多类 SVM 损失初步计算”,初步搭建了 “数据驱动分类系统” 的框架。而这一讲,课程聚焦线性分类器的 “训练核心”—— 如何通过损失函数量化误差、如何用正则项约束模型、如何靠优化算法更新参数,这些内容是 “让模型从‘不会’到‘会’” 的关键,也是后续神经网络训练的底层逻辑。在此,我将结合课程案例与自己的实践思考,整理成笔记,与同方向学习者交流。
课程链接:
目录
五、学习感悟:从 “理论公式” 到 “工程实践” 的认知升级
一、损失函数的深入解析:从 “定性判断” 到 “定量计算”

上一篇提到 “损失函数是模型的‘裁判’,告诉模型预测得好不好”,而这一讲中,教授通过多类 SVM 损失(折页损失 / Hinge Loss)的细节拆解,让我理解了 “损失函数如何实现定量度量”,以及 “如何用损失验证代码正确性”—— 这些工程化细节,是从 “理论” 到 “实践” 的关键一步。
1. 多类 SVM 损失的核心特性:最值与物理意义

多类 SVM 损失的公式在上一篇已初步介绍(对所有错误类别计算max(0, 错误类别得分 - 真实类别得分 + 1)并求和),而课程进一步剖析了它的两个核心特性:
- 最小值:0
当 “真实类别得分比所有错误类别得分高 1 分以上” 时,所有max(0, ·)的结果均为 0,总损失为 0。这意味着模型对该样本的分类 “完全符合预期”—— 不仅预测正确,且正确类别与错误类别的区分度足够高(如 “车” 样本得分 4.3,错误类别 “鸟”“猫” 得分分别为 - 1.2、-3.1,真实得分比错误类别高 5 分以上,损失为 0)。 - 最大值:无穷大
若模型对样本的预测完全错误(如把 “猫” 预测为 “车”,且 “车” 的得分极高、“猫” 的得分极低),则错误类别得分 - 真实类别得分 + 1的结果会趋近于无穷大,总损失也随之无穷大。这对应 “模型性能极差” 的场景,需紧急调整参数。
2. 一个关键的工程验证:初始参数为 0 时的损失值
课程提到一个 “新手必知” 的代码验证技巧:当线性分类器的权重(W)和偏置(b)全部设为 0 时,所有类别的得分均为 0,此时多类 SVM 损失的计算结果是 “类别数 - 1”。
以 CIFAR-10 数据集(10 个类别)为例:
对任意样本,真实类别得分与错误类别得分均为 0,每个错误类别的损失计算为max(0, 0 - 0 + 1) = 1,共 9 个错误类别,因此单个样本的损失为 9;若数据集有 N 个样本,总损失即为 N×9,平均损失为 9。
“这个验证能快速判断代码是否正确 —— 若初始参数为 0 时损失不是‘类别数 - 1’,说明损失函数的循环逻辑、类别遍历或公式实现有误。” 我在后续实践中亲测有效:曾因漏写 “错误类别排除真实类别” 的判断,导致初始损失为 10(包含了真实类别与自身的对比),通过这个验证快速定位了 bug。
3. 常见疑问:损失函数的 “细节差异” 是否影响结果?
课程中,教授针对初学者常混淆的两个问题做了解答,这也帮我厘清了之前的困惑:
- 疑问 1:若损失计算时包含 “真实类别与自身对比”(即 j=yi),会有什么影响?
此时会多一项max(0, 真实类别得分 - 真实类别得分 + 1) = 1,单个样本的损失会增加 1。但这属于 “固定偏移”—— 所有样本的损失都增加 1,对参数更新的方向(梯度)无影响,仅量级变化,最终优化结果一致。但工程中通常会排除自身对比,避免不必要的计算。 - 疑问 2:总损失是否必须除以样本数(求平均)?
不除以样本数会让总损失放大 N 倍(N 为样本数),但梯度的方向不变(仅量级放大 N 倍)。若同步调整学习率(如原学习率 ×1/N),最终优化结果完全一致。工程中求平均更直观(损失值范围固定,便于监控训练过程),但非强制要求。 - 疑问 3:将 “普通多类 SVM 损失(Hinge Loss)” 替换为 “平方 Hinge Loss”,会有什么影响? 分类误差越大,损失被放大得越明显(比如原损失 2,平方后变 4);参数更新的梯度会随误差增大而增强;优点是更关注严重错分的样本,缺点是易被噪声样本干扰。

常见问题
二、正则项与超参数:给模型 “加约束”,避免 “走极端”
上一篇结尾提到 “超参数是模型训练的前置配置”,而这一讲中,教授通过 “为什么需要正则项” 的问题,引出了 “模型泛化能力” 的核心 —— 正则项的本质是 “给模型参数加约束,避免模型过度依赖某部分特征,从而提升泛化能力”。
1. 引子:为什么损失为 0 的参数不唯一?
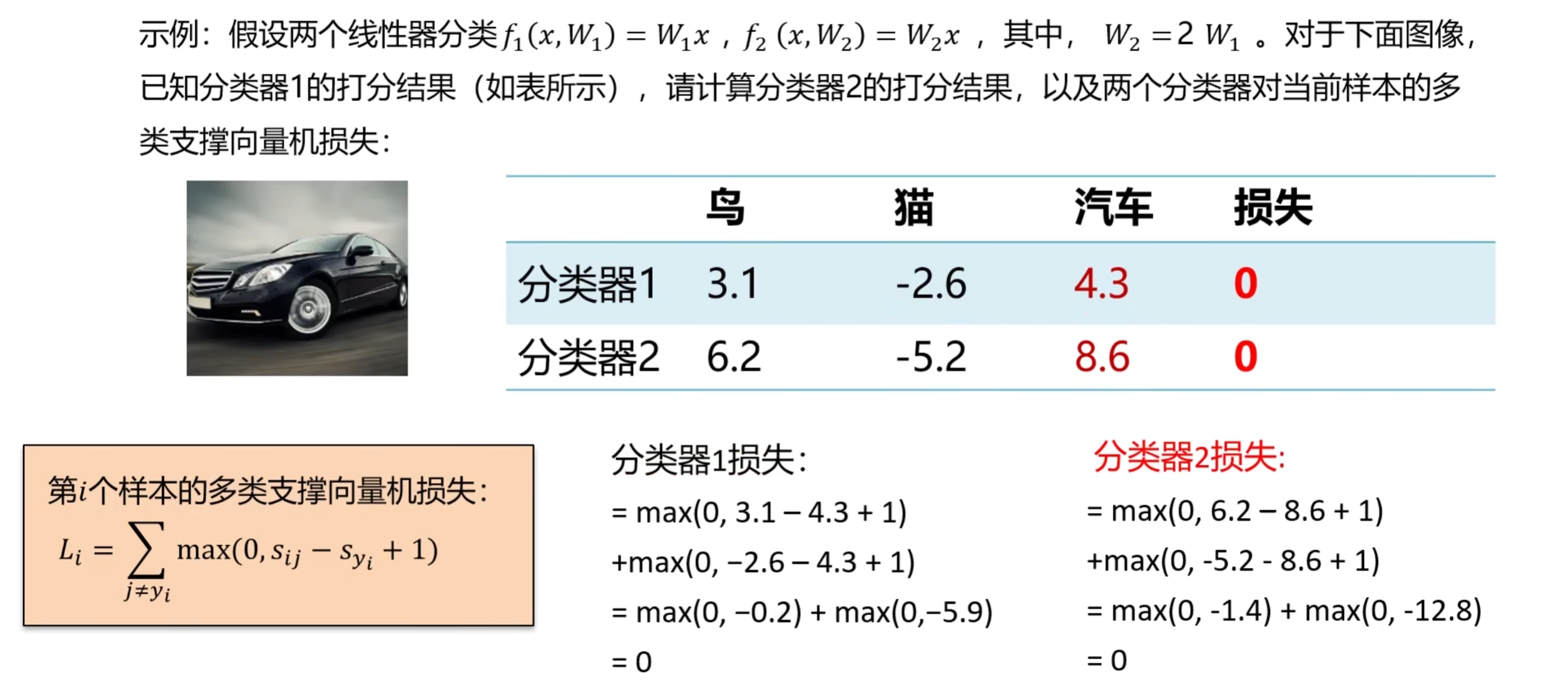
假设有两个线性分类器,参数分别为 W₁和 W₂=2×W₁(偏置 b 均为 0)。对任意样本 x,W₂×x = 2×(W₁×x),即所有类别的得分均为 W₁的 2 倍。此时,多类 SVM 损失的计算结果完全相同(因为 “得分差” 的比例不变)—— 两个分类器的损失均为 0,但参数不同。
这意味着:仅靠损失函数,无法确定唯一的最优参数。而实际任务中,我们需要 “唯一且泛化能力强” 的参数,这就需要正则项。
2. 正则项的核心作用:约束参数,提升泛化
正则项(Regularization)是总损失的 “第二部分”,公式为:
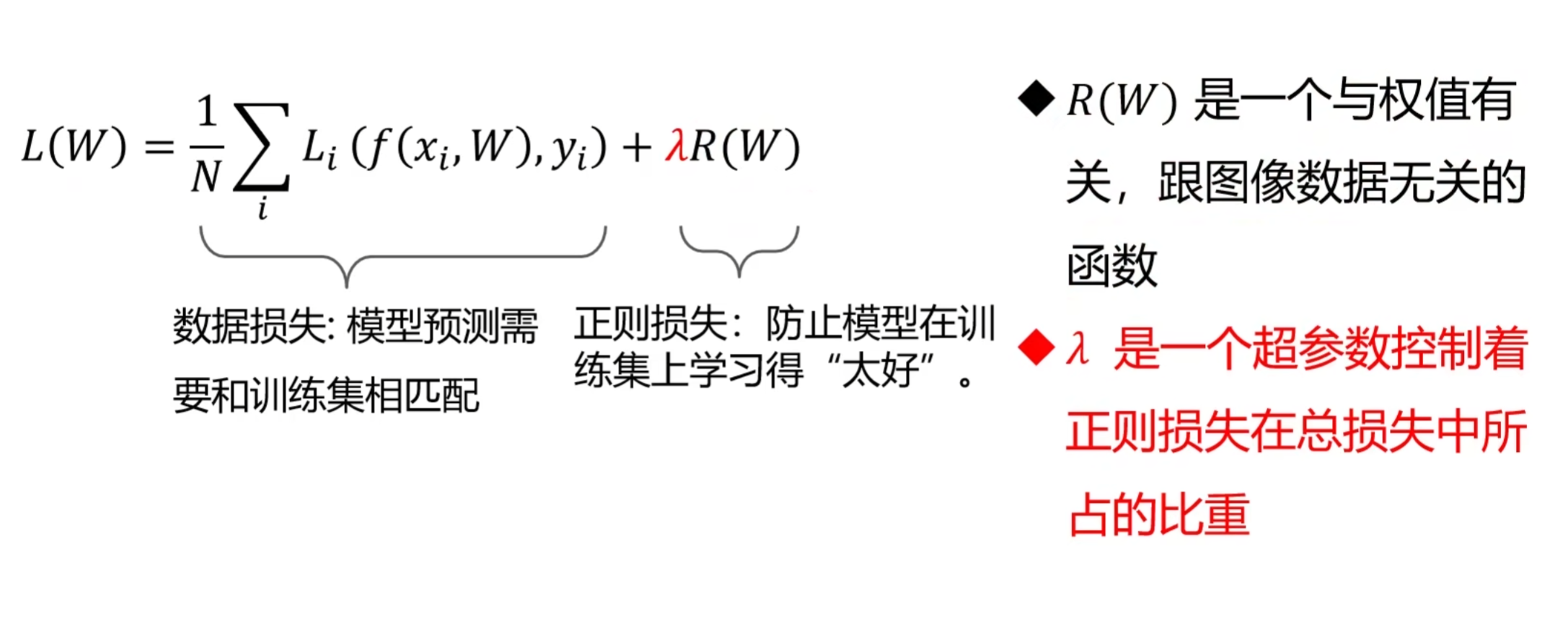
其中,λ 是超参数,控制正则损失的权重;正则损失通常是参数的 “惩罚项”,常见的有 L₂正则、L₁正则等。

课程重点讲解了L₂正则(最常用):

L₂正则损失 = ∑(Wᵢⱼ²)(对权重矩阵的所有元素求平方和),其核心作用有两个:
- 作用 1:让参数唯一化
回到上述例子,W₁的 L₂正则损失为∑(W₁ᵢⱼ²),W₂的 L₂正则损失为∑((2W₁ᵢⱼ)²)=4×∑(W₁ᵢⱼ²)。总损失中,W₂的正则损失是 W₁的 4 倍,因此总损失 W₂ > 总损失 W₁,模型会选择 W₁作为最优参数 —— 正则项打破了 “参数不唯一” 的僵局。 - 作用 2:防止过拟合,提升泛化能力
L₂正则会 “惩罚大数值的参数”,鼓励参数值分散(即每个特征的权重都较小,而非某几个特征的权重极大)。这样做的好处是:模型不会过度依赖某几个特征(如 “猫” 分类不会只依赖 “耳朵形状” 这一个特征),当测试集中的特征有轻微噪声(如耳朵被部分遮挡)时,模型仍能正确分类 —— 这就是 “泛化能力提升” 的本质。
补充:R (W) 为何是关于 W 的函数?设计意义是什么?
在总损失公式(见上图)中,R(W) 是正则损失项,它被设计为 “仅与模型参数 W 相关的函数”,既不依赖输入图像 x,也不关联真实标签 y,这种设计的核心意义有 3 点:
- 聚焦 “参数约束” 的核心目标
正则项的作用是 “约束模型参数的行为”(而非拟合数据)—— 比如避免参数 W 的数值过大、过度依赖少数特征。因此它不需要数据参与,仅需针对参数 W 本身做惩罚(例如 L2 正则的 R(W)=∑(W₁ᵢⱼ²),就是对 W 所有元素的平方和求和)。 - 解决 “参数不唯一” 的问题
如之前提到的 “W 和 2W 对应相同数据损失” 的情况,R(W) 会让不同参数的正则损失产生差异(比如 W 的 L2 正则损失是 ∑(Wᵢⱼ²),2W 则是 4∑(Wᵢⱼ²)),最终让总损失的最优解唯一。 - 引导模型 “偏好简单规律”
正则项对大数值 W 的惩罚,会迫使模型依赖 “分散的、小权重的特征”(而非少数大权重特征),本质是让模型学习 “更通用的简单规律”—— 这恰好契合 “奥卡姆剃刀原理”,能有效避免模型在训练集上 “死记硬背”(过拟合),提升对新数据的泛化能力。
“过拟合的模型就像死记硬背的学生,把训练集的‘题目’(样本)全记住了,但遇到新题目(测试集)就不会;正则项就像老师要求‘理解原理而非死记’,让学生(模型)学会‘举一反三’。” 这个类比让我瞬间理解了正则项与过拟合的关系。
3. 超参数 λ:平衡 “数据拟合” 与 “模型约束”
超参数 λ(Lambda)是 “控制正则项强度” 的关键,其取值直接影响模型性能:
- 当 λ=0 时:正则项失效,总损失 = 数据损失。此时模型仅追求 “在训练集上拟合得最好”,可能出现过拟合(参数值极大,过度依赖部分特征)。
- 当 λ→∞时:正则项主导总损失,模型会让参数 W 趋近于 0(以最小化正则损失)。此时模型几乎无法拟合数据,预测性能极差(所有类别得分接近 0,随机猜测)。
- 合理 λ:需在 “数据拟合” 与 “模型约束” 间找平衡(如 λ=0.01、0.1、1 等),通常通过验证集调优确定(后续会讲)。
这里需要区分 “超参数” 与 “模型参数”(上一篇表格的补充):
超参数 λ 是 “人工设定的配置”,训练过程中不会更新;而模型参数 W、b 是 “模型自主学习的知识”,训练过程中会通过优化算法不断更新。初学者常混淆两者,实际上:超参数决定 “模型如何学”,模型参数决定 “模型学到了什么”。
三、优化算法:让模型 “自主调整参数” 的核心逻辑
有了损失函数(量化误差)和正则项(约束参数),下一步就是 “如何调整参数 W、b,让总损失最小”—— 这就是优化算法的任务。课程重点讲解了 “梯度下降”(一阶优化算法),这是深度学习中最基础、最常用的优化方法。
1. 优化目标:找到 “让总损失最小” 的参数

从数学角度,优化的目标是找到参数 W、b,使得总损失 L (W,b) 最小。由于 L (W,b) 是 “参数的函数”(输入是参数,输出是损失),我们需要找到这个函数的 “最小值点”。
“大多数情况下,我们无法直接求解‘损失函数导数为 0’的解析解(因为损失函数复杂,含 max 等非光滑项),因此需要通过‘迭代’的方式逐步逼近最小值点 —— 梯度下降就是这样一种迭代算法。”
2. 梯度下降的核心思想:“沿梯度负方向下山”
梯度下降的逻辑可以用 “下山” 类比:
假设你站在山上(当前参数对应的损失值),想要最快到达山脚(最小损失),最直观的做法是 “沿着当前位置最陡的下坡方向走一步”—— 这个 “最陡的下坡方向” 就是 “损失函数在当前参数处的梯度负方向”。

具体到参数更新,步骤如下:
- 计算梯度(数值法、解析法):对总损失 L (W,b) 求关于 W 和 b 的偏导数(∂L/∂W、∂L/∂b),即 “当前参数处的梯度”,反映 “参数变化对损失的影响方向和幅度”。
- 更新参数:按以下公式调整 W 和 b:
W = W - α × (∂L/∂W)
b = b - α × (∂L/∂b)
其中,α(Alpha)是 “学习率”(另一个重要超参数),控制 “每一步走多远”(下山时每一步的步长)。 - 重复迭代:重复 “计算梯度→更新参数” 的过程,直到损失不再下降(或下降到阈值),此时参数接近最小值点。
关键细节:
- 梯度方向:梯度∂L/∂W 的方向是 “损失增加最快的方向”,因此我们需要沿 “梯度负方向” 更新参数(即 “损失减少最快的方向”)。
- 学习率 α:α 过大会导致 “步长太大,错过最小值点”(下山时一步跨到对面山坡,甚至更远);α 过小会导致 “收敛太慢,训练时间过长”(下山时一步只走几厘米,很久才能到山脚)。因此 α 也需要通过验证集调优(如 α=0.001、0.01 等)。
3. 梯度计算的两种方式:数值法 vs 解析法
梯度的计算是梯度下降的核心,课程介绍了两种常用方式:
- 数值法(有限差分法):
原理是 “通过微小扰动参数,计算损失变化量,近似梯度”。例如,对参数 Wᵢⱼ,计算 L (Wᵢⱼ+ε, b) - L (Wᵢⱼ-ε, b),再除以 2ε(ε 是极小值,如 1e-5),得到∂L/∂Wᵢⱼ的近似值。
优点:实现简单,无需推导复杂公式(适合验证);缺点:计算量大(参数维度高时,如 W 是 3072×10,需扰动 30720 次,每次都要计算损失),精度低(近似值)。 - 解析法(反向传播):
原理是 “通过微积分推导损失函数对参数的偏导数公式,直接计算梯度”。例如,对多类 SVM 损失 + L₂正则的总损失,可推导出∂L/∂W 的具体公式,代入参数即可得到精确梯度。
优点:计算速度快(一次推导,多次复用),精度高(精确值);缺点:需要推导偏导数公式(对数学基础有要求,容易出错)。
工程实践中,通常用 “解析法计算梯度,数值法验证梯度正确性”(即 “梯度检查”)—— 这是避免 “梯度计算错误导致模型不收敛” 的重要手段。
4. 梯度下降的改进:随机梯度下降与小批量梯度下降
传统梯度下降(批量梯度下降)的问题是 “每次迭代需计算所有样本的梯度”,当样本量极大时(如百万级),计算速度极慢。课程介绍了两种改进方案:
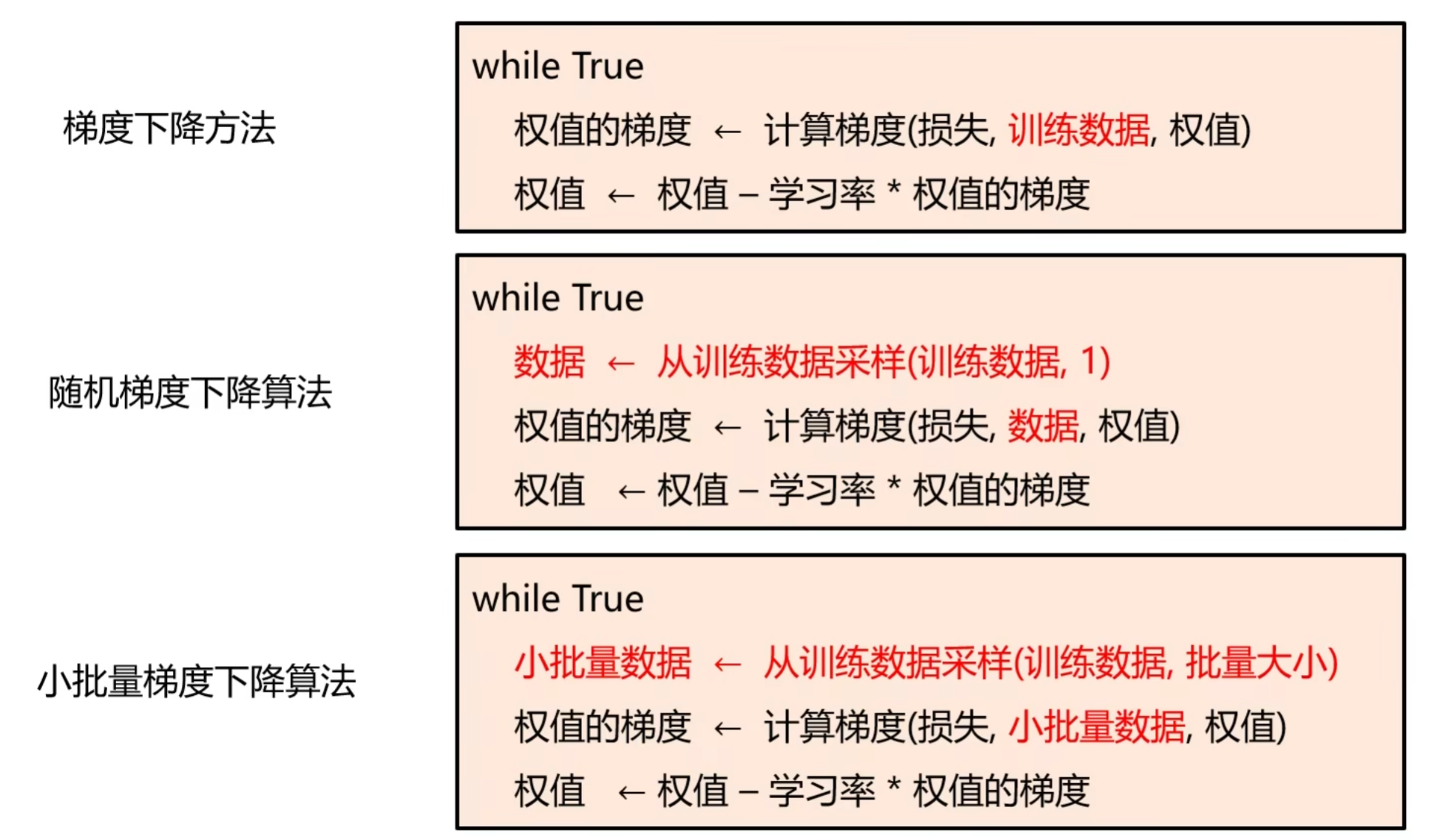
- 随机梯度下降(SGD):
每次迭代仅随机选择 1 个样本,计算该样本的梯度并更新参数。优点是速度快(每次计算量小),缺点是梯度噪声大(单个样本的梯度波动大,损失曲线震荡剧烈)。 - 小批量梯度下降(Mini-batch SGD):
每次迭代选择 “一小批样本”(如 32、64、128 个样本),计算这批样本的平均梯度并更新参数。优点是 “速度快” 与 “梯度稳定” 兼顾(批量越大,梯度越稳定,但速度越慢),是当前深度学习中最常用的优化方式。
课程中用 CIFAR-10 举例:
若批量大小为 64,训练集共 50000 个样本,则每次迭代处理 64 个样本,1 个 “epoch”(遍历完所有训练样本)需 50000/64≈782 次迭代。这种方式既能保证梯度的稳定性,又能充分利用 GPU 并行计算(批量样本可同时计算),训练效率大幅提升。
四、数据集划分与预处理:为模型训练 “扫清障碍”
优化算法需要 “高质量的数据” 才能训练出好模型,因此课程最后讲解了 “数据集划分” 与 “数据预处理”—— 这是 “模型训练前的必要准备”,很多初学者忽视这一步,导致模型性能不佳。
1. 数据集划分:训练集、验证集、测试集的作用
为了 “正确评估模型泛化能力”,通常将数据集划分为三部分:
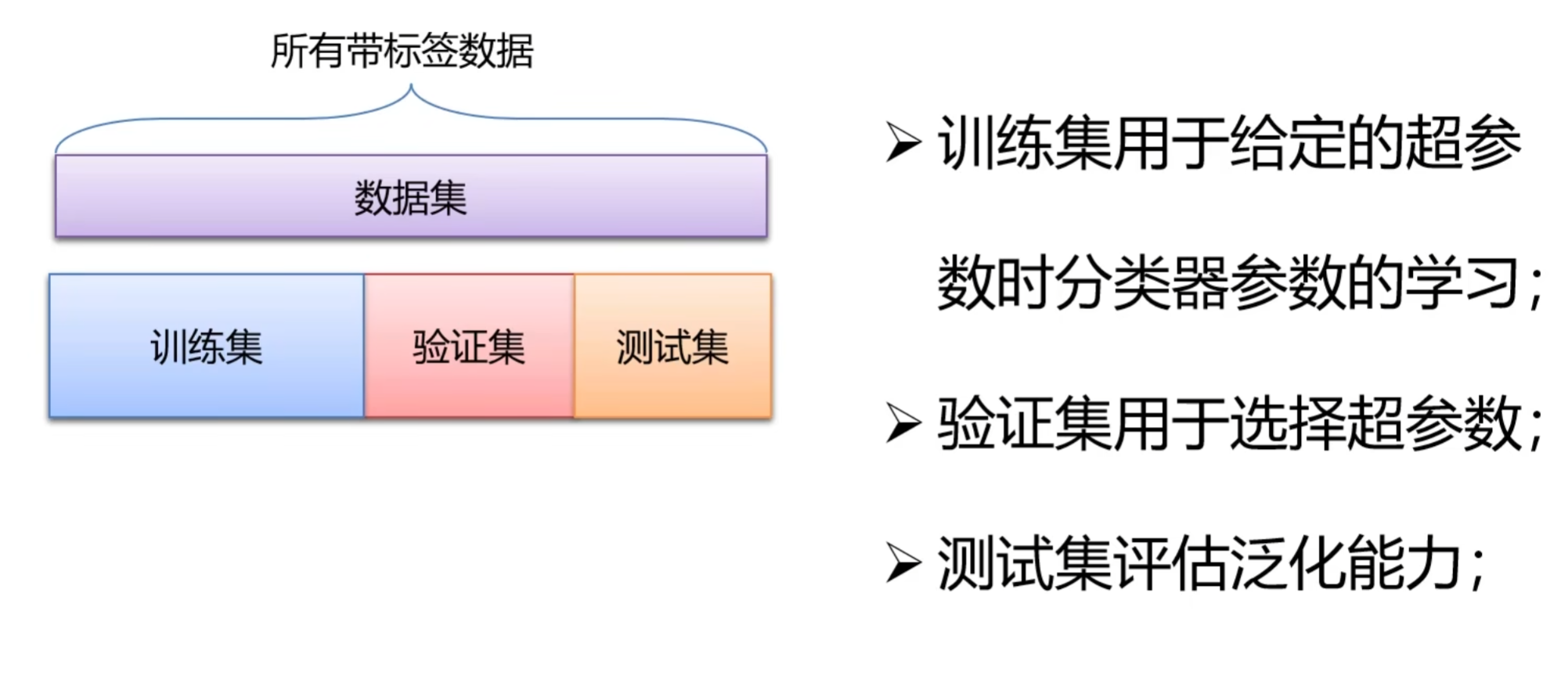
- 训练集(Training Set):占比 60%-80%,用于模型学习参数(W、b)。模型在训练集上通过优化算法不断调整参数,最小化总损失。
- 验证集(Validation Set):占比 10%-20%,用于超参数调优(如 λ、α、批量大小等)。例如,用不同 λ 训练多个模型,选择 “在验证集上损失最小” 的 λ 作为最优超参数。
教授强调:“验证集不能参与模型训练(即不能用于更新参数),否则会导致超参数‘过拟合’验证集 —— 模型在验证集上表现好,但在新数据上表现差。” - 测试集(Test Set):占比 10%-20%,用于最终评估模型泛化能力。测试集是 “模型从未见过的数据”,其评估结果能反映模型在真实场景中的性能。绝对不能用测试集调优超参数(否则评估结果失真)。
特殊情况:当数据量较小时(如仅有 1000 个样本),无法划分出独立的验证集,此时可采用 “k 折交叉验证”(k-fold Cross Validation):
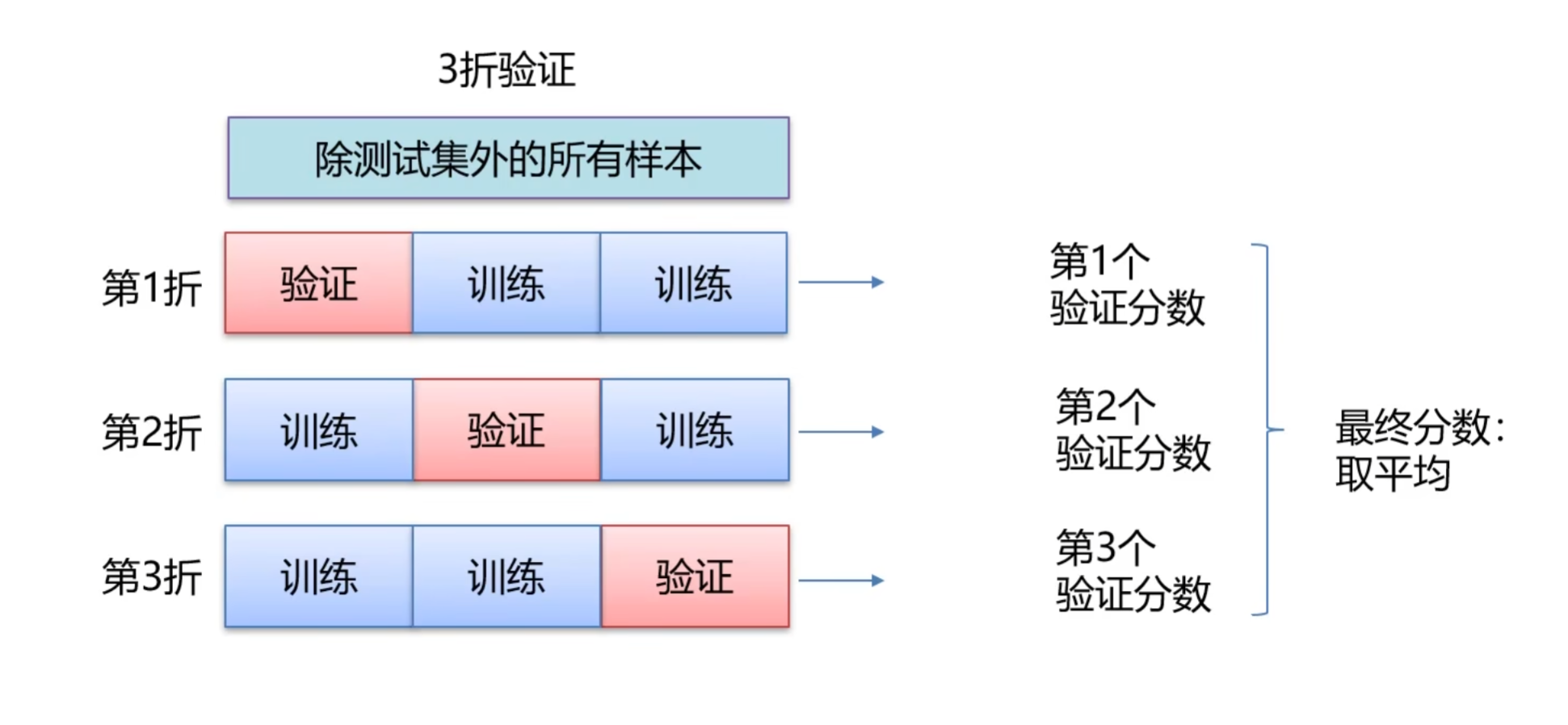
将数据集分为 k 份(如 k=3),每次用 k-1 份作为训练集,1 份作为验证集,重复 k 次,取 k 次验证结果的平均值作为超参数的评估指标。这种方式能充分利用有限数据,避免 “验证集随机划分导致的评估误差”。
2. 数据预处理:让数据 “更适合模型学习”
原始图像数据(如像素值 0-255)可能存在 “量级差异大、分布不均” 等问题,影响模型训练效率(如梯度下降收敛慢)。课程介绍了 CV 中常用的 4 种预处理方法:
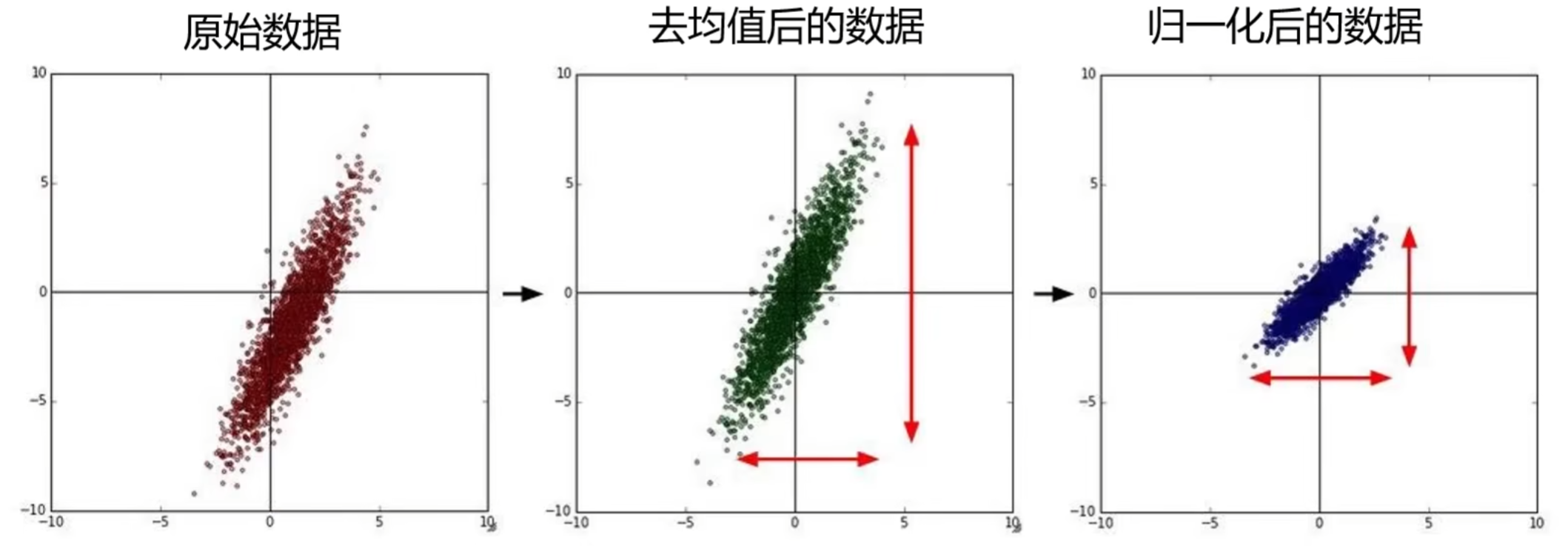
- 去均值(Mean Subtraction):
对所有样本的每个像素通道(如 RGB 的 R 通道),计算训练集的平均值,然后每个样本的对应通道像素值减去该平均值。
作用:让数据 “中心化”(均值为 0),避免某一通道的像素值整体偏高 / 偏低,导致参数更新偏向该通道。例如,CIFAR-10 的 R 通道均值为 123.68,G 通道为 116.77,B 通道为 103.93,每个样本的 R/G/B 通道分别减去对应均值。 - 归一化(Normalization):
对去均值后的数据,除以每个通道的标准差(或最大值与最小值的差),让所有通道的像素值 “量级一致”(如都落在 [-1,1] 或 [0,1] 范围内)。
作用:消除 “通道间量级差异” 的影响。例如,若 R 通道像素值 0-255,G 通道 0-100,模型会过度关注 R 通道(因为其数值变化对损失影响更大),归一化后可避免这种情况。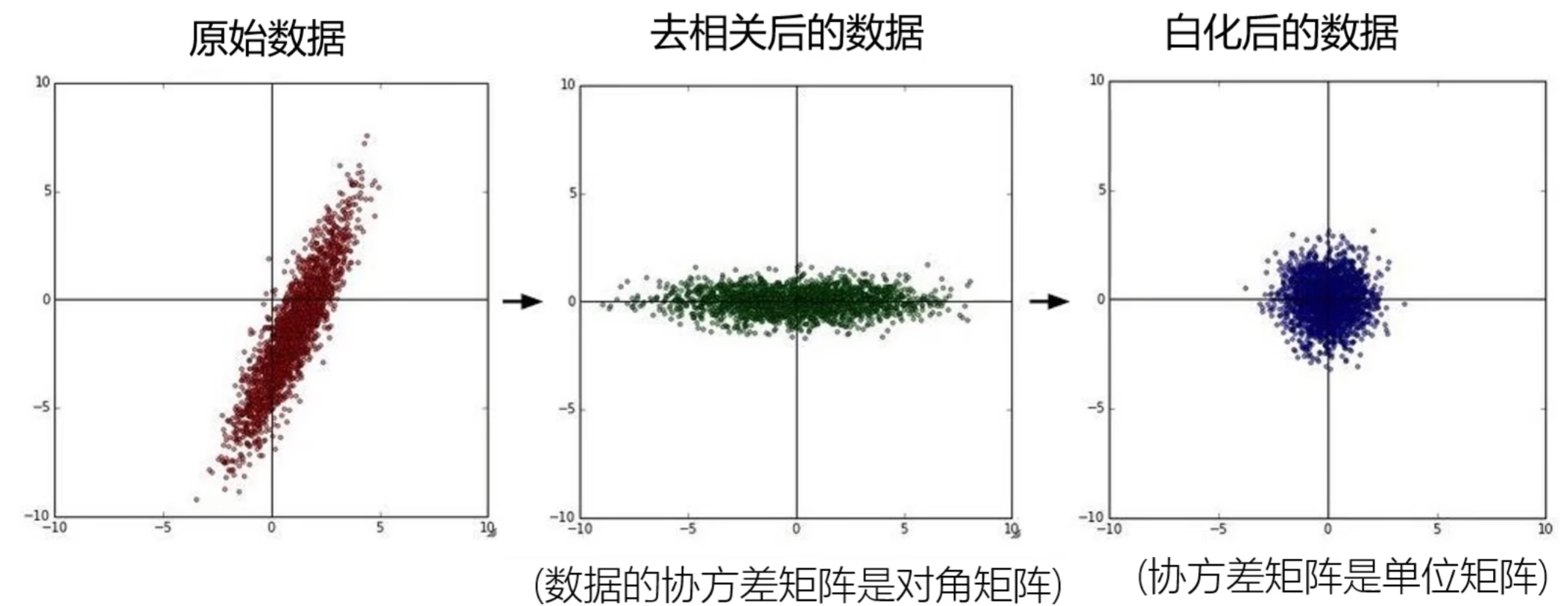
- 去相关(Decorrelation):
通过主成分分析(PCA)等方法,将数据转换到 “主成分空间”,消除特征间的相关性(如像素间的冗余信息)。
作用:降低数据维度,减少冗余信息,提升训练效率。但深度学习中,CNN 可自动学习特征相关性,因此去相关较少使用。 - 白化(Whitening):
在去相关的基础上,让每个主成分的方差为 1。作用:进一步标准化数据分布,让模型在各方向上的学习速率一致。但白化计算复杂,且可能引入噪声,实际应用中不如去均值和归一化常用。
“对线性分类器和 CNN 而言,去均值 + 归一化是最基础、最有效的预处理方法,几乎是工程中的‘标配’。初学者无需追求复杂的预处理,先做好这两步,就能解决大部分数据分布问题。”
五、学习感悟:从 “理论公式” 到 “工程实践” 的认知升级
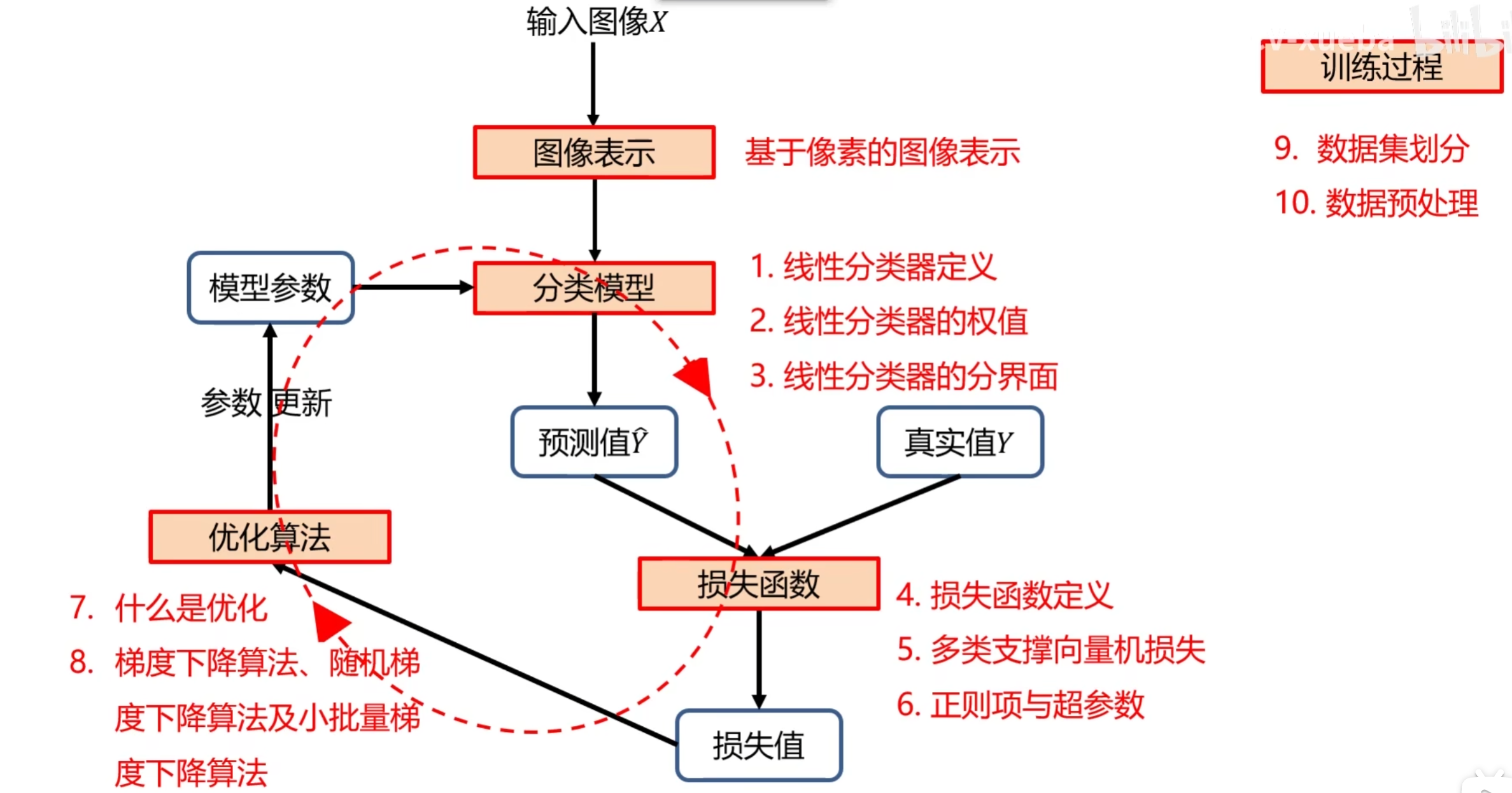
这一讲的内容让我从 “理解线性分类器的逻辑” 深入到 “掌握线性分类器的训练流程”,最大的收获是三个 “思维转变”:
1. 从 “追求完美公式” 到 “接受迭代优化”
最初我以为 “优化算法能找到全局最优解”,但课程中教授指出:“深度学习中,我们通常追求‘局部最优解’而非‘全局最优解’—— 因为复杂模型的损失函数有无数个局部最优解,而大多数局部最优解的性能差异很小,足够满足实际需求。” 这让我明白:优化的核心是 “通过迭代逐步改进”,而非 “一次性找到完美参数”—— 这种 “迭代思维” 是工程实践中的关键。
2. 从 “忽视细节” 到 “关注工程验证”
课程中提到的 “初始参数为 0 时的损失验证”“梯度检查” 等细节,让我意识到:理论公式正确不代表代码实现正确,工程中需要 “通过具体指标验证代码正确性”。例如,我曾因忘记在损失函数中加入正则项,导致模型过拟合(训练集损失极低,测试集损失极高),后来通过 “对比有无正则项的损失变化” 才定位问题。这些细节看似琐碎,却是 “从理论到实践” 的必经之路。
3. 从 “单一关注模型” 到 “重视数据准备”
之前我误以为 “模型越复杂,性能越好”,但课程中 “数据集划分” 和 “预处理” 的讲解让我明白:“高质量的数据比复杂的模型更重要”—— 若数据划分不合理(如测试集包含训练样本),即使模型再复杂,评估结果也毫无意义;若数据未预处理(如像素值 0-255),梯度下降会收敛极慢,甚至无法收敛。这种 “数据优先” 的思维,是后续做 CV 项目的重要指导原则。
结语
鲁鹏教授的 “线性分类器(下)”,完整梳理了 “损失函数→正则项→优化算法→数据准备” 的训练闭环,让我不仅掌握了线性分类器的训练细节,更理解了 “深度学习模型训练的通用逻辑”—— 这些逻辑(如损失量化误差、正则约束参数、梯度下降更新)同样适用于后续的 CNN、Transformer 等复杂模型。
下一篇笔记中,我将继续梳理课程的下一部分内容 —— 卷积神经网络(CNN)的基础原理,包括 “卷积层如何提取特征”“池化层的作用” 等核心知识点。如果有同方向的学习者对 “梯度下降实现”“正则项调优” 有疑问,欢迎在评论区交流 —— 计算机视觉的学习之路,需要我们在理论与实践的碰撞中不断深化认知。
补充:
这个链接是斯坦福大学 CS231n 课程的线性分类器交互式演示工具地址:http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/
它是 CS231n(计算机视觉与深度学习)课程配套的可视化工具,能直观演示线性分类器的权重模板、决策边界、损失变化等核心概念 —— 比如可以手动调整权重,实时看到分类结果和损失的变化,很适合入门时辅助理解线性分类器的工作逻辑。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)