香港大学强化学习驱动连续环境具身导航!VLN-R1:基于强化微调的视觉语言导航
VLN-R1通过整合LVLM和强化学习微调,为连续环境中的视觉语言导航提供了一种有效的解决方案
·

- 作者:Zhangyang Qi1,2^{1,2}1,2, Zhixiong Zhang2^{2}2, Yizhou Yu1^{1}1, Jiaqi Wang2^{2}2, Hengshuang Zhao1^{1}1
- 单位:1^{1}1香港大学,2^{2}2上海AI实验室
- 论文标题:VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning
- 论文链接:https://arxiv.org/abs/2506.17221
- 项目主页:https://vlnr1.github.io/
- 代码链接:https://github.com/Qi-Zhangyang/GPT4Scene-and-VLN-R1
主要贡献

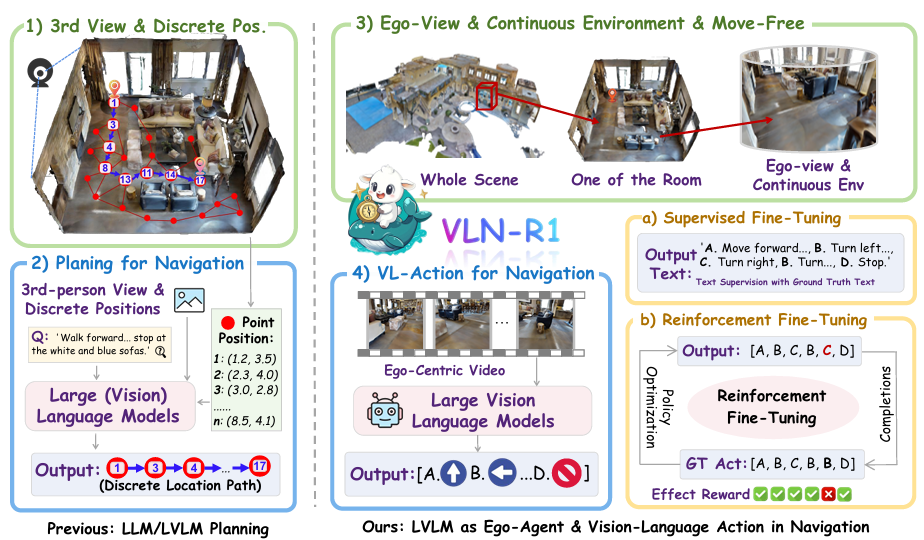
- 提出VLN-R1框架:利用大型视觉语言模型(LVLM)处理第一视角视频流,从而实现连续环境中的视觉语言导航。与以往基于离散导航图的方法不同,VLN-R1能够生成连续的导航动作,更接近真实世界中的导航场景。
- 构建VLN-Ego数据集:为了训练LVLM进行连续导航任务,构建了VLN-Ego数据集。该数据集基于Habitat模拟器生成,包含第一视角视频流以及对应的未来动作预测。这个数据集为LVLM的训练提供了丰富的视觉和语言信息,有助于模型学习如何根据视觉输入和语言指令生成正确的导航动作。
- 创新训练方法:VLN-R1采用了两阶段的训练方法。首先,通过监督微调(SFT)使模型的动作序列文本预测与专家演示对齐;然后,利用强化微调(RFT)进一步优化模型,特别是引入了基于Group Relative Policy Optimization(GRPO)的训练策略和Time-Decayed Reward(TDR)机制。
研究背景

- 视觉语言导航的重要性:
- VLN是具身人工智能中的一个核心挑战,它要求智能体能够理解自然语言指令,并在三维环境中进行导航。
- 这项任务不仅需要智能体具备语言理解能力,还需要其能够实时做出决策,以适应不断变化的环境。
- 现有方法的局限性:
- 以往的研究通常依赖于离散的拓扑图来进行路径规划,这种方法限制了智能体在未见或连续环境中的泛化能力。
- 此外,一些方法需要额外的传感器信息,如深度图和导航图,这在实际应用中可能会受到限制。
- 还有些方法虽然使用了大型语言模型(LLM),但它们仍然受限于预定义的导航图,无法实现真正意义上的具身导航。
研究方法
VLN-Ego数据集构建
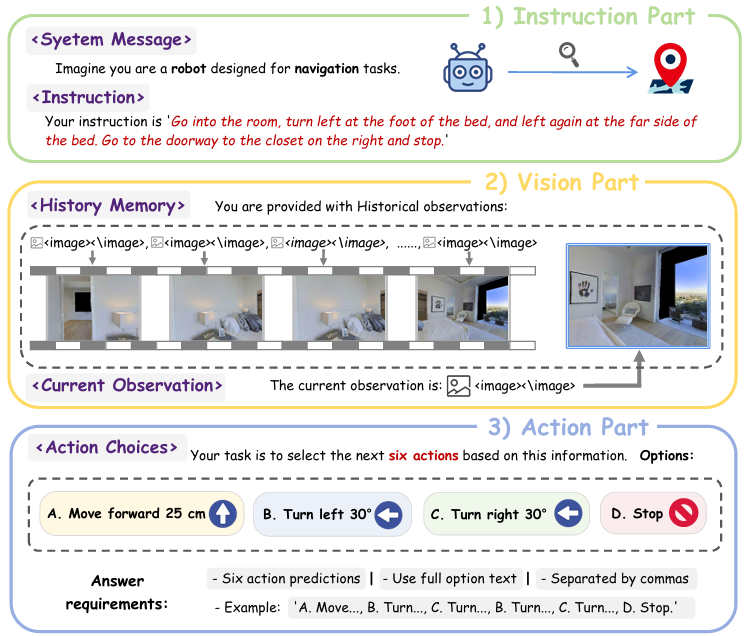
- 数据来源:Habitat模拟器中的Matterport3D场景(90个场景,分训练/验证/测试集)。
- 标注设计:每条样本包含三部分:
- 指令文本:自然语言导航指令(如"绕过餐桌,左转进入走廊")。
- 视觉输入:历史帧(Long-Short Memory采样)+当前帧。
- 动作标注:未来6步动作序列(如"A.前进25cm, B.左转30°")。
- 采样策略:长短期记忆(Long-Short Memory)平衡近期细节与长期上下文。短期部分采用高密度采样,长期部分采用低密度采样,兼顾局部细节与整体上下文。
监督微调
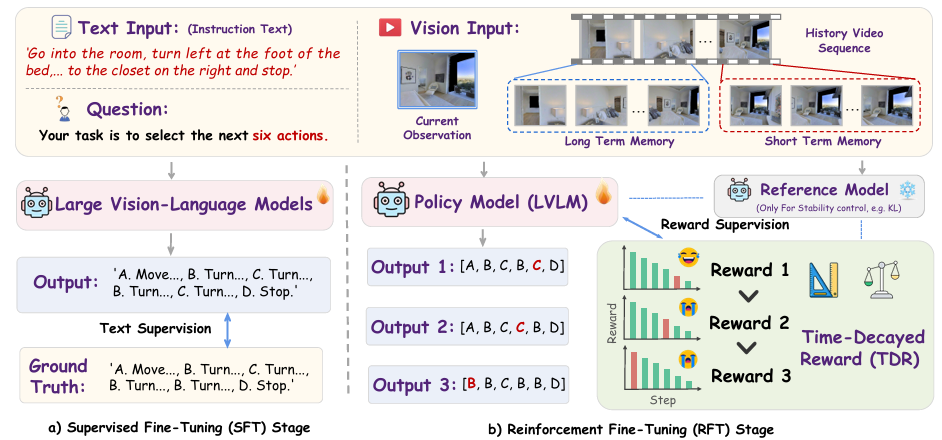
将导航任务形式化为序列预测问题,在每个时间步输入语言指令 III、历史帧序列 HtH_tHt、当前观察帧 vtv_tvt,模型预测接下来的动作序列 A^t:t+n−1\hat{A}_{t:t+n-1}A^t:t+n−1。使用交叉熵损失对预测动作编号与描述进行监督训练:
LSFT=−∑k=0n−1∑j=1LklogP(wj∗∣w1:j−1∗,Ht,vt,I) L_{SFT} = -\sum_{k=0}^{n-1}\sum_{j=1}^{L_k} \log P(w^*_j|w^*_{1:j-1}, H_t, v_t, I) LSFT=−k=0∑n−1j=1∑LklogP(wj∗∣w1:j−1∗,Ht,vt,I)
其中 LkL_kLk 为第 kkk 步动作的token数,监督模型联合学习动作类别和动作文本表达。
强化学习微调
在SFT基础上,引入强化学习以提升模型在长时序导航中的稳健性与前瞻性:
- GRPO策略优化:通过相对奖励对一组生成结果进行排序,提升高质量策略。
- TDR机制设计:奖励函数定义如下:
Rnav=∑k=0n−1γk⋅I[αt+k=αt+k∗] R_{nav} = \sum_{k=0}^{n-1} \gamma^k \cdot \mathbb{I}[\alpha_{t+k} = \alpha^*_{t+k}] Rnav=k=0∑n−1γk⋅I[αt+k=αt+k∗]
其中 γk\gamma^kγk 表示对第 kkk 步动作的衰减因子,I[⋅]\mathbb{I}[\cdot]I[⋅] 为指示函数。该机制优先强化前期正确决策,提升整体导航成功率。
实验与结果
实验设置
- 模型:Qwen2-VL-2B 与 Qwen2-VL-7B;
- 数据:SFT使用180万样本,RFT使用20K样本(R2R+RxR);
- 评估:在VLN-CE设置下的R2R与RxR任务,使用SR、OS、SPL、NE、TL等指标;
- 硬件:使用8张A800 GPU,配合Deepspeed ZeRO-3优化器。
实验结果
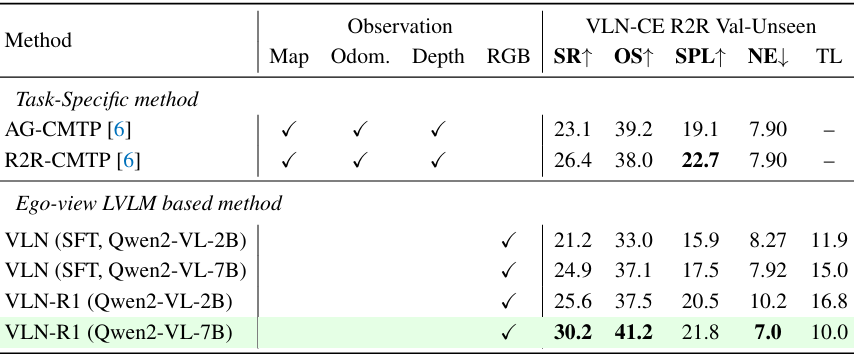
- R2R任务(Val-Unseen):VLN-R1在无深度图、地图等条件下实现SR=30.2(7B模型),显著超过传统模型;
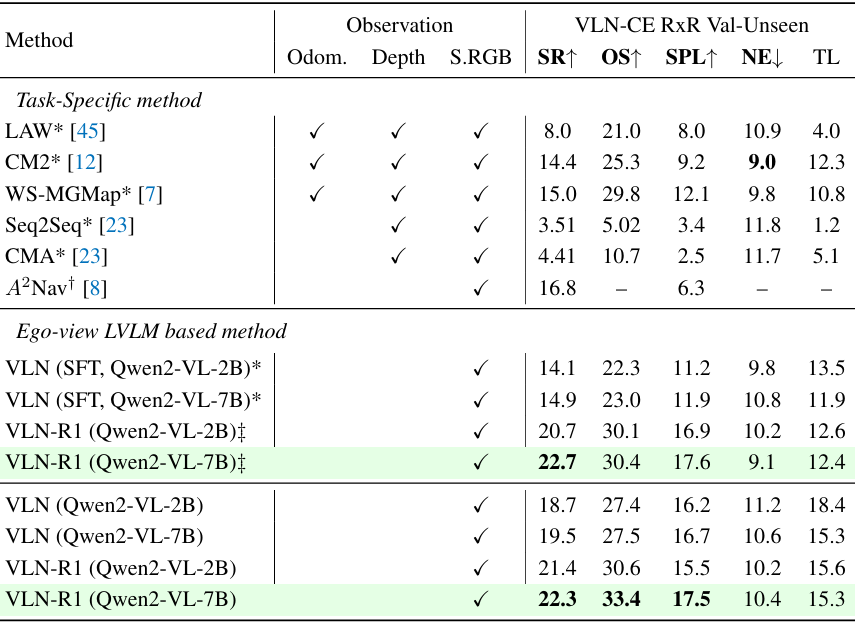
- RxR任务(Val-Unseen):仅使用10K样本RFT即在RxR上优于完全监督模型,体现出强跨域适应能力;
- 2B模型经RFT后可达7B模型的SFT性能,说明RFT能有效提升小模型性能。

消融实验
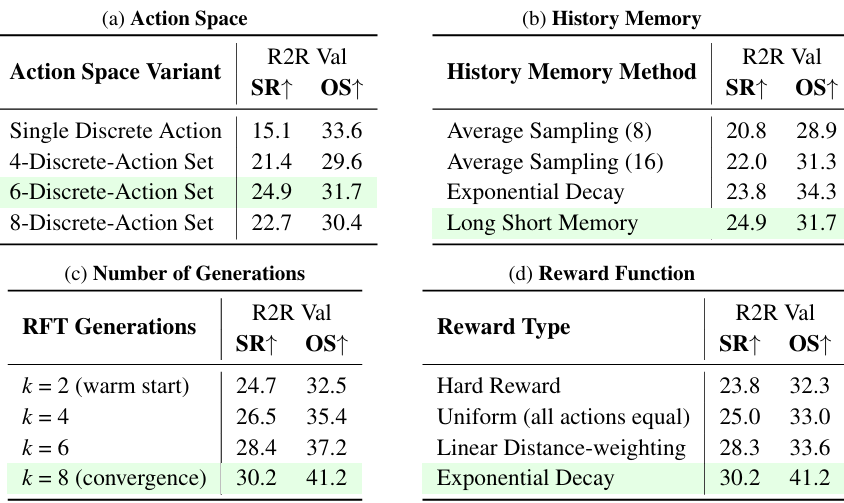
- 动作空间设计:实验结果表明,预测未来6个动作的设置能够取得最佳性能。仅预测单个动作的设置会导致性能显著下降,因为这种设置无法考虑未来步骤之间的依赖关系。
- 历史记忆方法:长短期记忆采样策略在帧选择方面表现最佳,能够有效地平衡当前观察与历史上下文。
- RFT的超参数:实验还探讨了RFT阶段的超参数设置,包括生成次数和奖励函数。结果表明,8次生成能够使模型达到收敛,并且TDR机制在奖励函数中表现最为有效。
结论与未来工作
- 结论:
- VLN-R1通过整合LVLM和强化学习微调,为连续环境中的视觉语言导航提供了一种有效的解决方案。
- 该方法在模拟环境中取得了SOTA性能,并且在跨领域适应方面表现出色。
- 此外,RFT能够使小型模型匹配大型模型的性能,这对于资源有限的实际应用具有重要意义。
- 未来工作:
- 尽管VLN-R1在模拟环境中取得了显著成果,但其在现实世界中的泛化能力仍有待验证。
- 未来的工作可以探索在更复杂的现实环境中进行评估,以及扩展动作空间以实现更精细的导航控制。
- 此外,还可以研究如何将该方法应用于其他具身AI任务,如具身问答(EQA)等,以进一步拓展LVLM在具身AI领域的应用。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)