神经网络与深度学习基础(二):多层感知机 与 BP算法
而分类问题,由于问题建模时引入了sigmod函数与概率思想,其构造的代价函数为非线性的,难以得到解析解,只能使用求偏导梯度下降的方法逐步求解,计算量大。为解决分类问题中,求偏导计算量大的问题,研究者开发了一种感知机模型:受生物神经元之间连接加强的过程(即Hebb规则)的启发,不求偏导而是直接使用输入输出的乘积作为参数变化值,同样可以取得良好的分类效果,大大降低了计算的复杂性。那么问题来了,多层感知
1. 前文回顾
在“神经网络与深度学习基础(一)”中,我们解决了机器学习中的线性回归与分类问题。其中线性回归问题存在解析解,可以直接得到线性回归结果。而分类问题,由于问题建模时引入了sigmod函数与概率思想,其构造的代价函数为非线性的,难以得到解析解,只能使用求偏导梯度下降的方法逐步求解,计算量大。
为解决分类问题中,求偏导计算量大的问题,研究者开发了一种感知机模型:受生物神经元之间连接加强的过程(即Hebb规则)的启发,不求偏导而是直接使用输入输出的乘积作为参数变化值,同样可以取得良好的分类效果,大大降低了计算的复杂性。这个案例的成功,让人们认识到神经元模型的强大潜力。
2. 多层感知机
2.1 遇到的问题
在上个博客中,我们使用感知机简单的解决了线性分类问题。分类结果大致如下图所示:

其特点是可以通过一条直线(或平面、超平面),实现样本二分类。我们称其解决的这种问题为线性分类问题。但是,要解决的分类问题,不都是通过直线就可以解决的,这类问题称为线性不可分问题,最经典的就是XOR(异或问题):

可以看到在坐标图上,根本无法通过一条直线将和
的点区分。似乎面对线性不可分问题,之前用的感知机模型(如下图所示)无能为力。
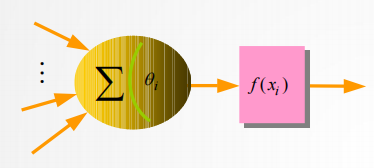
2.2 如何解决问题
为什么感知机无法解决线性不可分问题?仔细想想其实大概能清楚:
感知机模型是参考简化的神经元模型得到的,其对输入的样本各个坐标分量进行线性加权求和,最后通过一个sign非线性函数得到分类的0,1结果。其中真正对输入信息处理的过程是线性加权求和,完全不含有非线性内容的。最后输出结果时,用了一下sign函数,但这个函数只是用来对已经处理后的信息进行区分,对输入信息处理没有影响。既然输入信息处理中都没有非线性的内容,如何能够解决线性不可分问题呢?
感知机中输出端有sign函数,那我们如何能够利用起来这个非线性函数来解决线性不可分问题呢?
2.3 多层感知机解决问题
如果将感知机串联起来,那不就代表着sign函数不止在输出端出现,还出现在输入信息处理过程中了?(这里只是我的个人对于,多层感知机这个算法如何被想到的一种思路梳理。也可以有其他理解,比如sign事件触发角度等)
而由此就得到了多层感知机算法(多层前馈神经网络,多层感知机就是一种基础的神经网络):
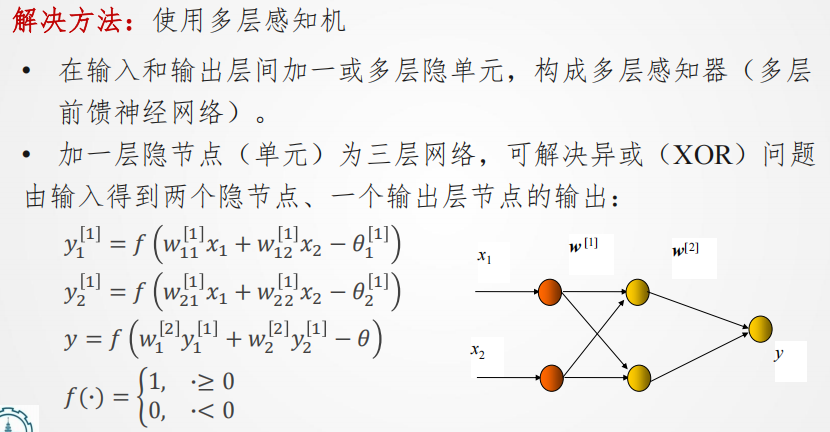
可得到(注意变量的表示方法,用了比较多角标,分别代表第几层,第几个感知机,第几个参数这个需要自己梳理记得牢一点):
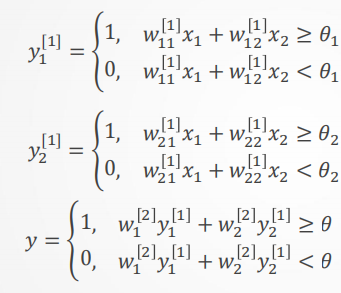
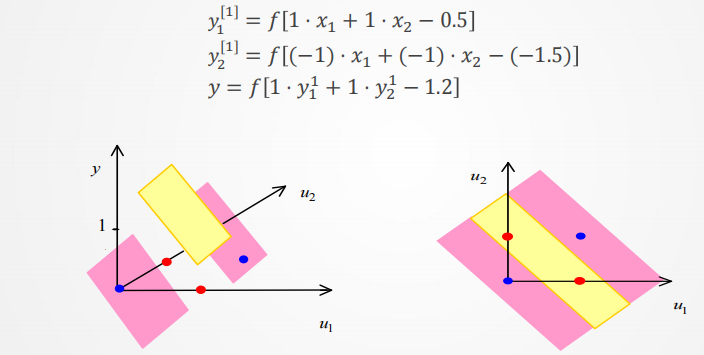
而当参数取这么一组值时(此时取值就是尝试出来的),就可完成这个分类问题:
那么问题来了,多层感知机算法确实可以解决XOR问题,那对于其他的线性不可分问题能不能解决呢,这个多层感知机的上限有多高呢?对于这个问题研究者们已经给出了答案:对于其他线性不可分问题也可以解决,上限非常高,严谨来说可以总结为两条定理:

其中阈值节点就是sign作为激活函数,S型节点就是sigmod函数。
3. BP算法
3.1 一个概念:多层前馈神经网络
多层感知机是一种多层前馈网络,由多层神经网络构成,每层网络将输出传递给下一层网络。神经元间的权值连接仅出现在相邻层之间,不出现在其他位置。如果每一个神经元都连接到上一层的所有神经元(除输入层外),则成为全连接网络。
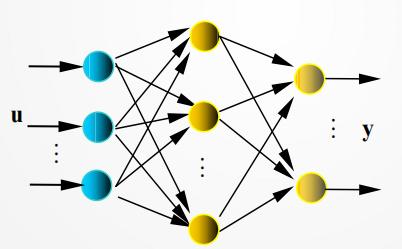
3.2 遗留的问题
在2.3中,我们通过多层前馈神经网络(多层感知机,MLP)解决了XOR问题,同时也得到了两个定理。定理中似乎向我们说明,有了MLP,我们将几乎可以解决所有问题!但是,当我们真正去解决问题时却发现,MLP中存在了大量的未知参数待确定。或许可以使用Hebb规则来进行参数的调整,但是Hebb规则缺乏数学逻辑的严谨性,且面对大量参数容易出现不收敛问题。MLP是有很大的上限,但是这个上限应该如何发挥出来呢?
3.3 BP算法
多层前馈网络的反向传播 (BP)学习算法,简称BP算法,是有导师的学习(也就是事先有个标签标注着样本属于哪一类),它是梯度下降法在多层前馈网中的应用。
BP算法所针对的网络结构为:见3.1图,𝐮(或𝐱 )、𝐲是网络的输入、输出向量,神经元用节点表示,网络由输入层、隐层和输出层节点组成,隐层可一层,也可多层(图中是单隐层),前层至后层节点通过权联接。由于用BP学习算法,所以常称BP神经网络。算法实现流程可简述为:
- 已知网络的输入/输出样本,即导师信号。
- 正向传播是输入信号从输入层经隐层,传向输出层,若输出层得到了期望的输出,则学习算法结束;否则,转至反向传播。
- 反向传播是将误差(样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层节点的权值和阈值,使误差减小。
而参数调整的具体推导可以看书的“4.7.3 反向传播”部分,关键在于链式求导法则的应用。这里粘贴一下ppt中的推导,这里写的比较简单易懂:

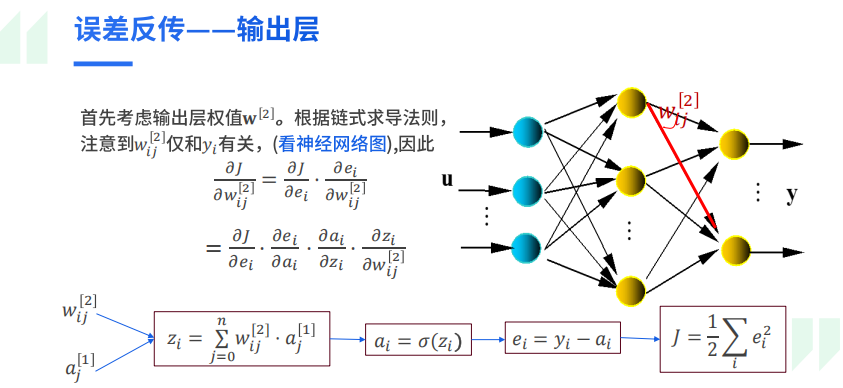
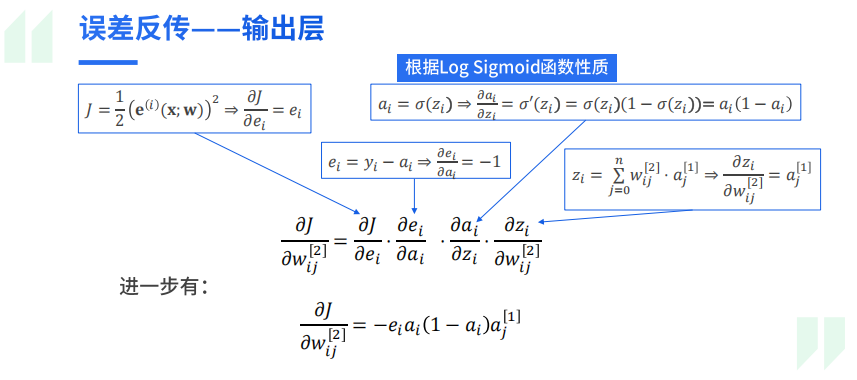

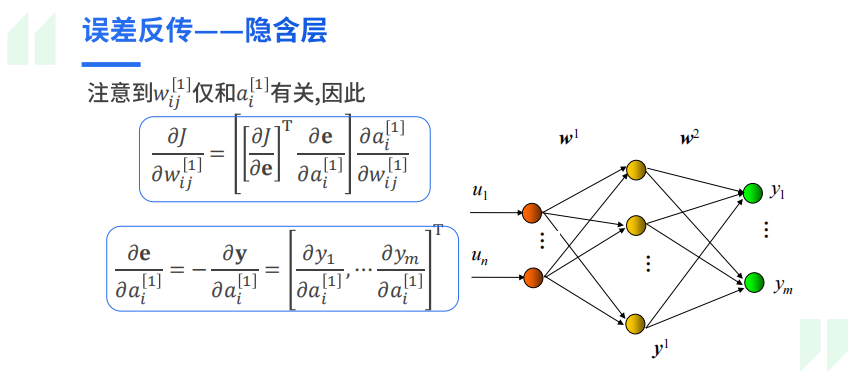

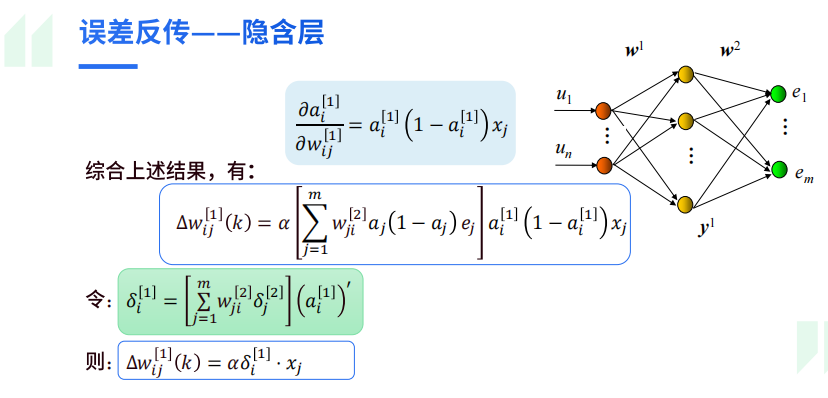

3.4 BP算法性能优化
这里列出对于BP算法的优化方法:
模型初始化方法:(1)简单方法:在[-1,1]通过均匀分布或高斯分布选取权重初值。(2)使用Xavier初始化参数初始化方法,实现各层的输出方差尽量相等。其分布为均匀分布,满足:
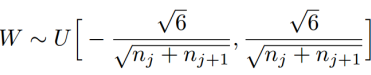
权重衰减:为防止过拟合和权值震荡,加入新的指标函数项:
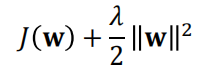
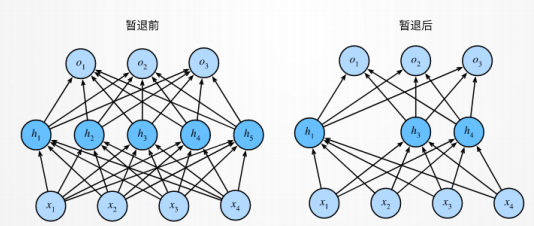
Dropout(暂退):在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
动量法:可有效改善收敛速度,以及避免一些陷入局部极小值
自适应算法:AdaGrad,Adam等
4. 总结
本章在第一章感知机的基础上介绍了多层感知机问题,获得了解决线性不可分问题的方法。同时学习了BP算法,实现对于多层前馈神经网络(多层感知机)的参数迭代调整。最后介绍了一些BP算法性能优化的方法。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)