图卷积神经网络GCN详解
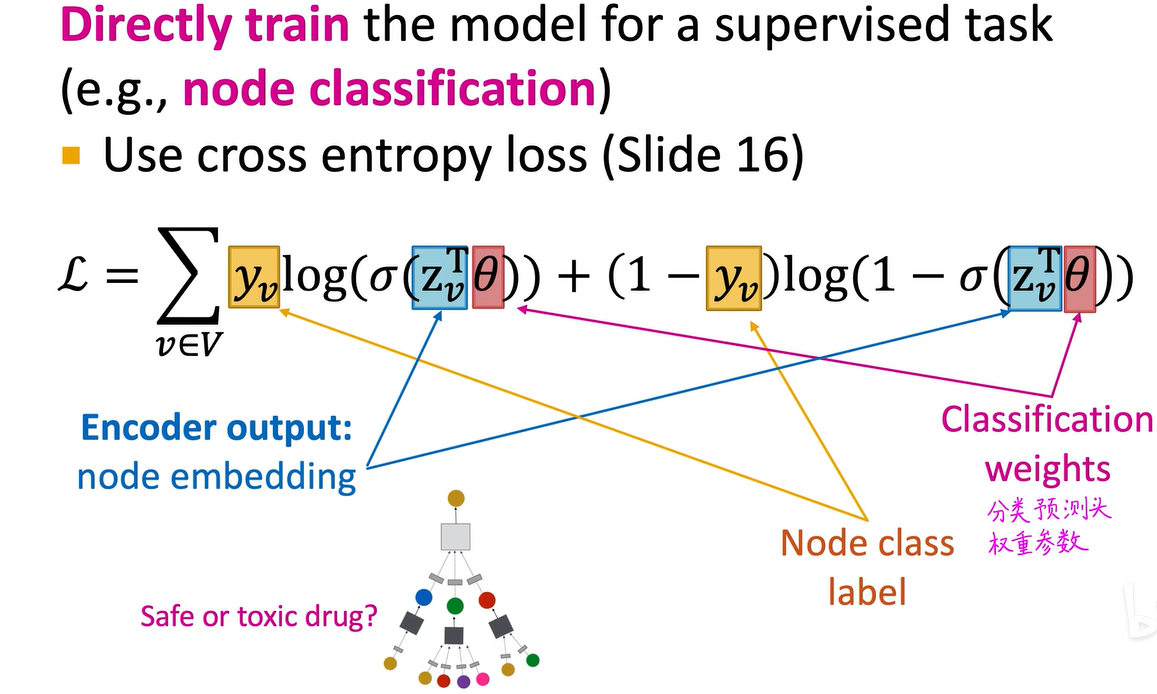
神经网络中的权重可通过监督学习,或者无监督学习(也叫自监督学习)方式获得。对于监督学习任务,比如半监督学习节点分类,如已知部分节点类别,可构建损失函数。比如以v节点为例,将其输入图卷积神经网络得到嵌入,再加预测头预测是否发生欺诈,将预测结果与真实结果比对,算出如交叉熵损失函数(用于分类任务),目标是迭代优化神经网络权重,使交叉熵损失函数最小化,这是训练过程。若是无监督学习且没有节点标签,可借鉴。
本讲介绍了最简单的一类图神经网络:图卷积神经网络(GCN) 包括:消息传递计算图、聚合函数、数学形式、Normalized Adjacency 矩阵推导、计算图改进、损失函数、训练流程、实验结果。 图神经网络相比传统方法的优点:归纳泛化能力、参数量少、利用属性特征和节点标签等。 图神经网络和CNN、Transformer等其它神经网络的异同。
1.计算图
GCN有时也代表图神经网络,这是一种非常重要的图神经网络算法。在上一讲,我们讲解了图神经网络的综述、学习路径、应用领域、应用场景,以及将深度学习神经网络应用在图数据结构上的困难和挑战。今天我们将正式学习一种具体的图卷积神经网络GCN,讲解其计算图、聚合函数、数学形式。在下一讲,我们将讲解另外两种图神经网络,分别是GraphSAGE和GAT,然后归纳出一个图神经网络的通用框架。除了这一讲算法讲解之外,在后边我们还会进行GCN论文的逐句精读,以及代码实战。

GCN的原始论文名为《Semi-Supervised Classification with Graph Convolutional Neural Networks》,即用GCN解决半监督节点分类问题。在一个图中,我标注了一些点,想用已标注的点去预测其他点的类别。例如,已知一些客户发生了信用卡欺诈,我想预测其他可能发生信用卡欺诈的客户。代码实战中,我们将使用NetworkX、PyG和DGL这三个图机器学习和图神经网络的库来实现GCN。因此,我们将分别从动图、算法、直观理解、论文代码等多个角度理解GCN算法,这样才能学得透彻。
回顾一下上一节课我们讲的内容,图机器学习解决的是由节点和连接组成的图数据的数据挖掘问题。它解决的任务可以分成节点层面、连接层面、子图层面和全图层面。节点层面,比如判断一个用户节点是否会发生信用卡欺诈;连接层面,比如两个节点之间是否可能会建立连接,像社交网络中的两个人;子图层面是用户的社群聚类;全图层面是全图的分类或生成一个新的图,比如判断一个分子是否有毒、气味是否刺鼻,或者生成一个新的药物分子、新的青霉素或蛋白质的结构。
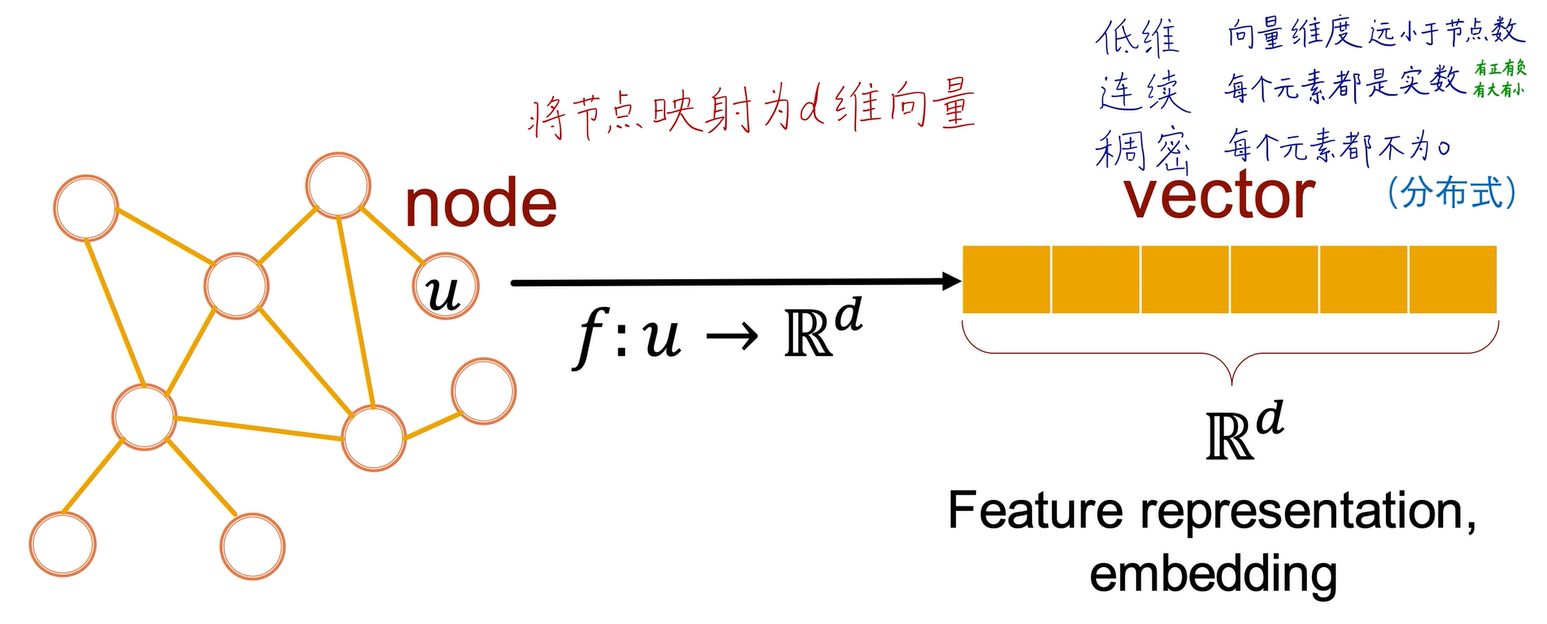
所有图机器学习问题都可以用图神经网络来解决。图神经网络的基本原理是把图中的节点编码映射成一个低维、连续、稠密的d维向量。比如d是128或256,把图中的每一个节点编码成一个256维的向量,这个向量是低维、连续、稠密的,能够反映节点在原图的连接和属性关系。两个节点对应的两个向量在d维空间的相似度就能够反映这两个节点在原图之间的相似度。所以我们要学习的就是这个大f函数,把图输入给这个f函数,这个函数就会输出每一个节点的Embedding。
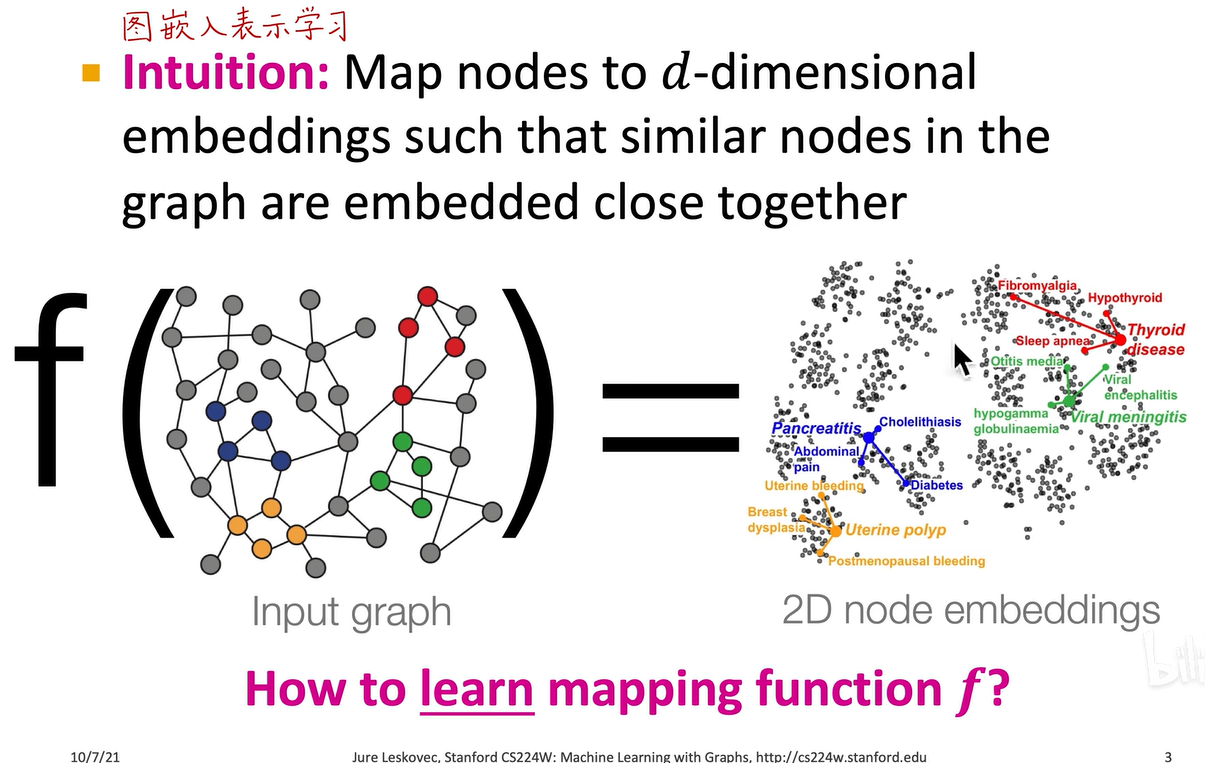
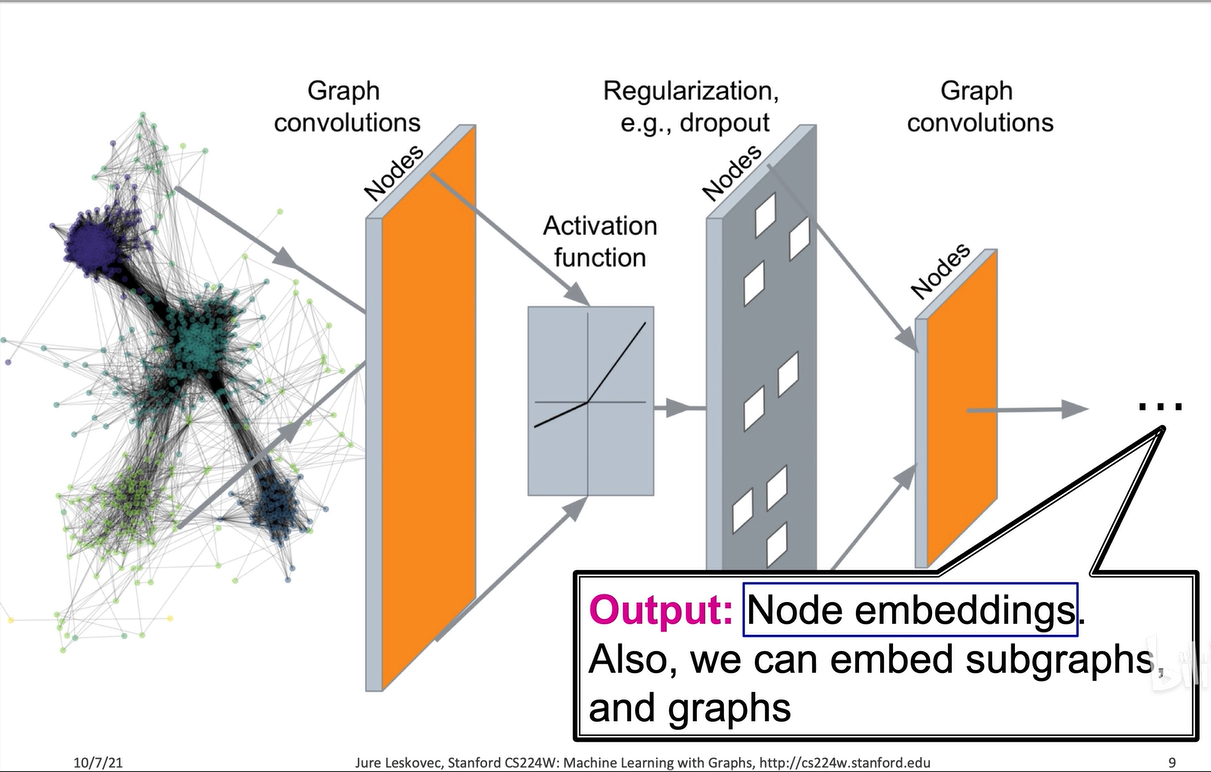
在d维空间的嵌入中,向量之间的距离能够反映结点在原图之间的距离和关系。有了节点的嵌入,就可以获得全图或子图的嵌入,进而解决各种图学习问题,如节点分类、连接预测、全图分类和社群聚类等,这些都可以通过节点嵌入向量附加预测头来解决,但前提是节点嵌入向量的质量要足够高,足以反映节点的信息和语义,这正是图神经网络的任务。
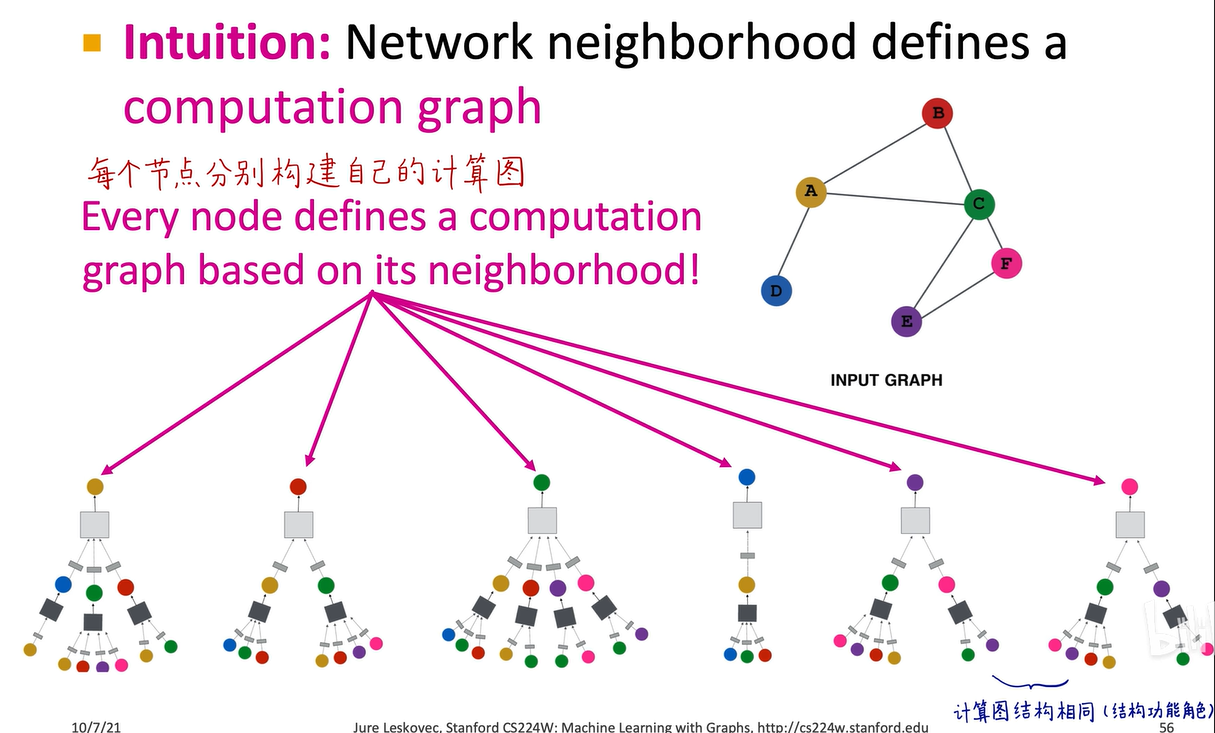
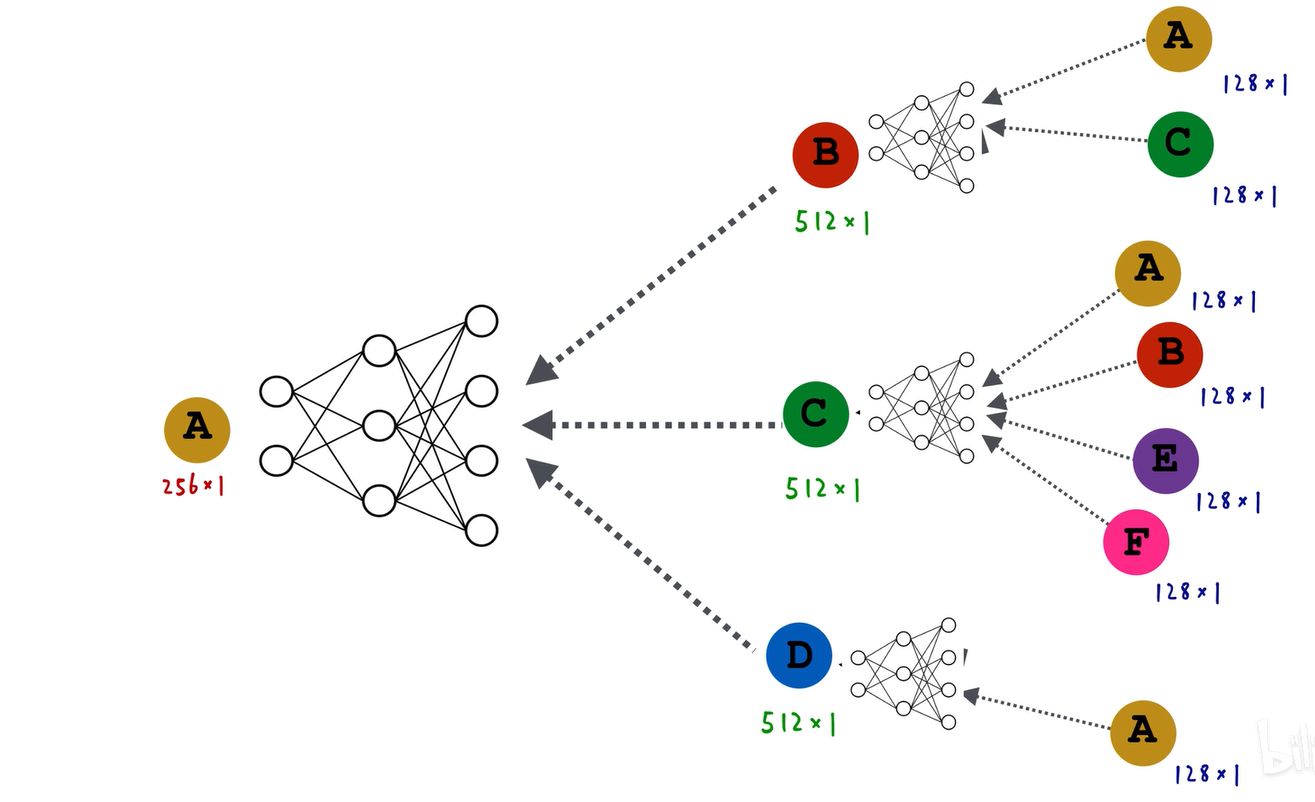
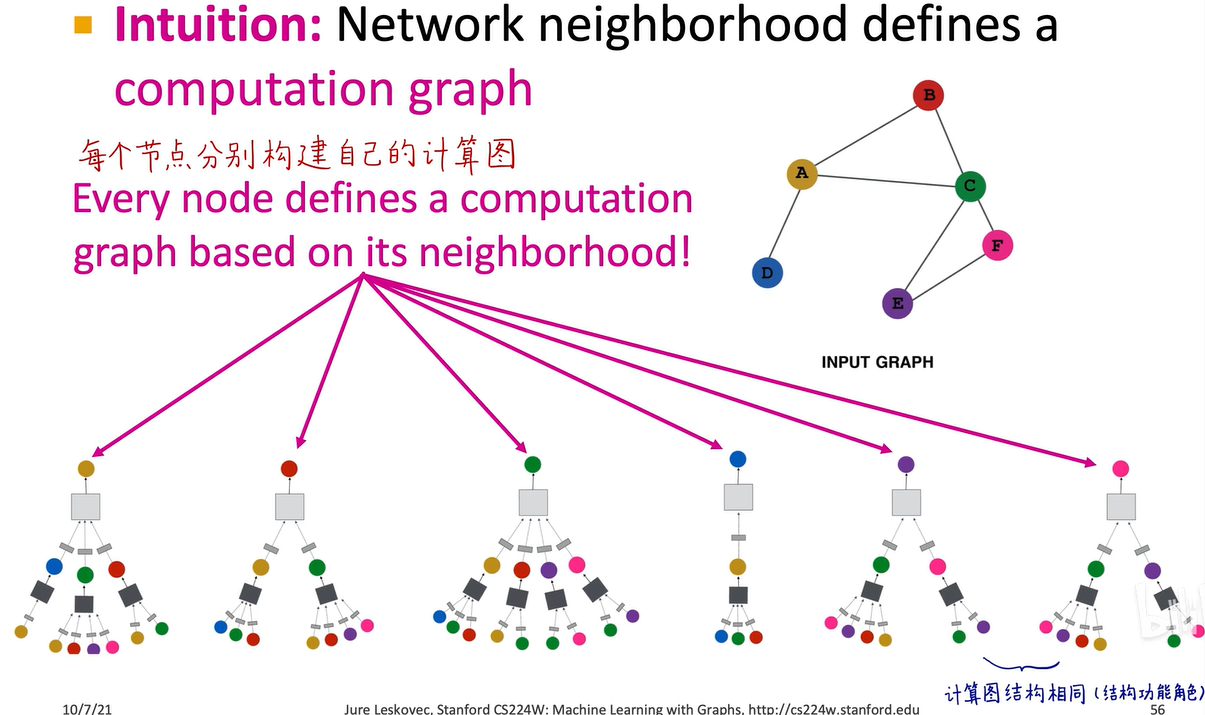
我们先来看图卷积神经网络的计算图,在上一讲中,我们提到对于图这种复杂且无标注点、锚点、参考点和顺序的结构,不能直接将邻接矩阵输入到神经网络中,也不能直接将图输入到卷积神经网络中,而是需要通过消息传递的框架构建一个局部邻域的计算图。
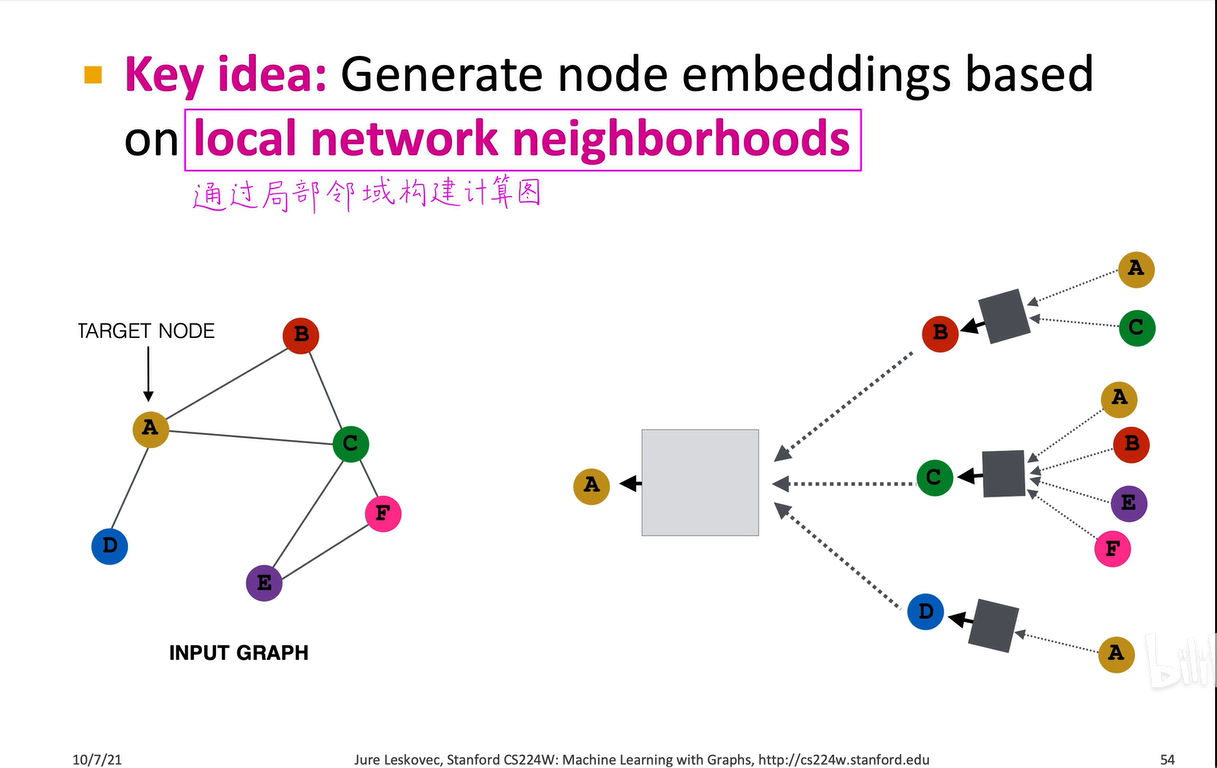
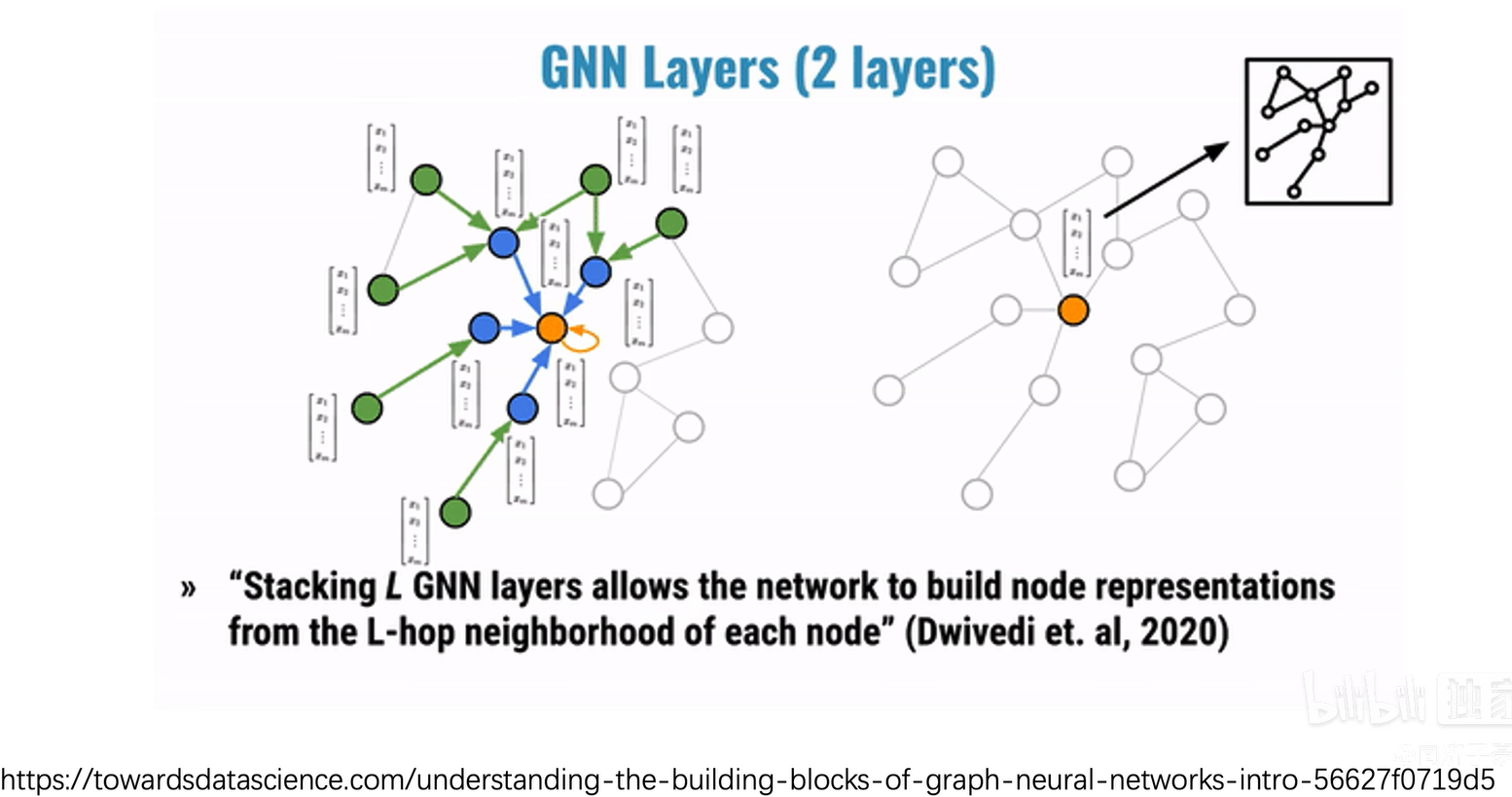
比如这是原图,a结点的计算图就是它的一阶邻域bcd三个节点。再看a节点邻居的邻居,即邻居的一阶领域,b结点的一阶领域是a和c,c结点的一阶领域是a、b、e、f,d节点的一阶领域是a,这样就构建出了a节点两层图神经网络的消息传递计算图。在这个阶段,图中的所有黑色盒子代表第一个神经网络,即这三个黑盒子共享一套神经网络的权重,所有白色盒子代表第二个神经网络。
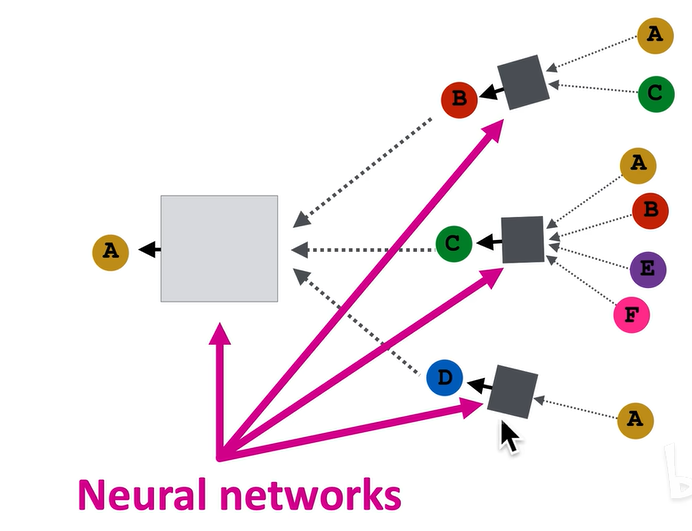
同一个神经网络在这个计算图中出现了两次,每一层对应一个神经网络。
每个节点可以分别构建自己的计算图。训练图神经网络时,每个计算图就是一个样本,可以使用mini batch,比如batch_size=8即每个batch包含八个这样的计算图,输入到神经网络中进行迭代预测,即完成一步或称为一个iteration。
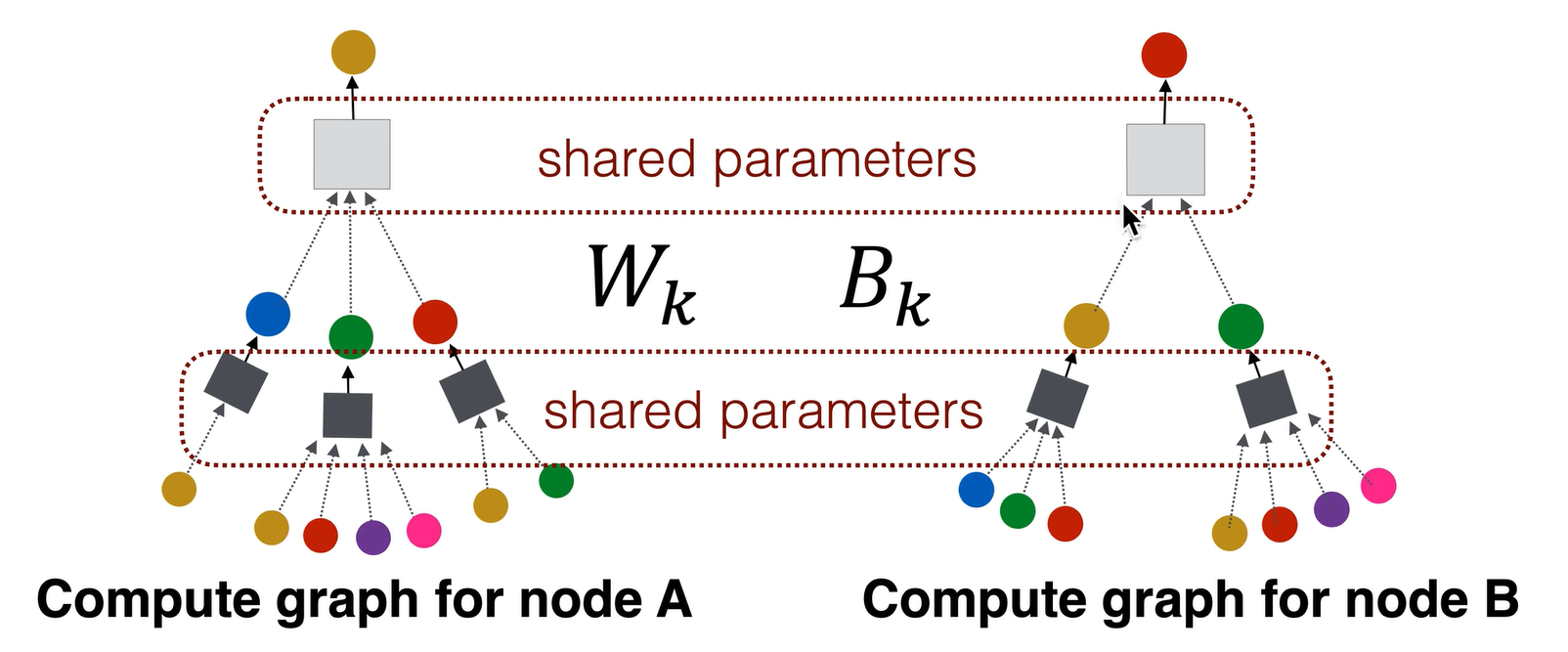
在计算图中,所有的黑色盒子共享一套权重和参数,所有的白色盒子在两层神经网络中也共享一套参数。在两层神经网络里面实际上只有两个神经网络需要训练,图神经网络的层数是指计算图的层数,而不是神经网络本身的层数。
比如这里有两层计算图,所以图神经网络是两层。而黑盒子里的神经网络可以很深,可以有128层、512层甚至更多,但这些层数并不构成图神经网络的层数。我们上次课也讲过,图神经网络理论上可以任意深,对于一个节点我们可以考虑它的邻居的邻居的邻居...,但根据六度空间理论,全世界60亿人只需通过六个人就可以互相认识,所以如果你的图神经网络到六层,理论上你就可以获得全世界所有人的信息了。
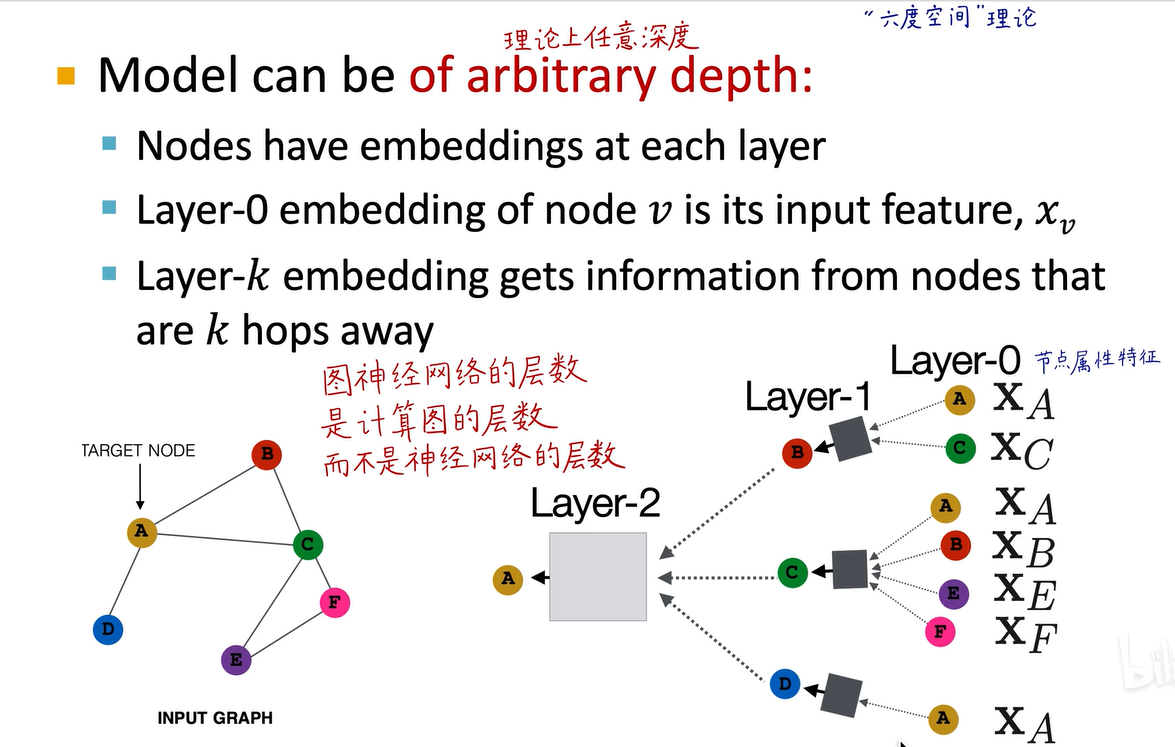
在第一层输入到图神经网络中的是结点的属性特征,这些特征是训练集中样本自带的,不需要学习或计算,是天然得到的,比如一个用户的年龄、婚姻状况、学历、收入等属性特征。我们的目标是输入所有节点的属性特征,通过层层的消息传递和信息的汇聚,得到节点最终的Embedding,即语义的嵌入向量,这就是刚刚所说的表示学习要学到的低维、连续、稠密的embedding嵌入向量。
一层图神经网络对应一个hop的neighborhood,k层则对应k hop neighborhood。一层就是我的一阶邻居,两层就是我的邻居的邻居,三层就是我的邻居的邻居的邻居,层数越多,邻居个数也越多,我的感受范围或receptive field就越大。
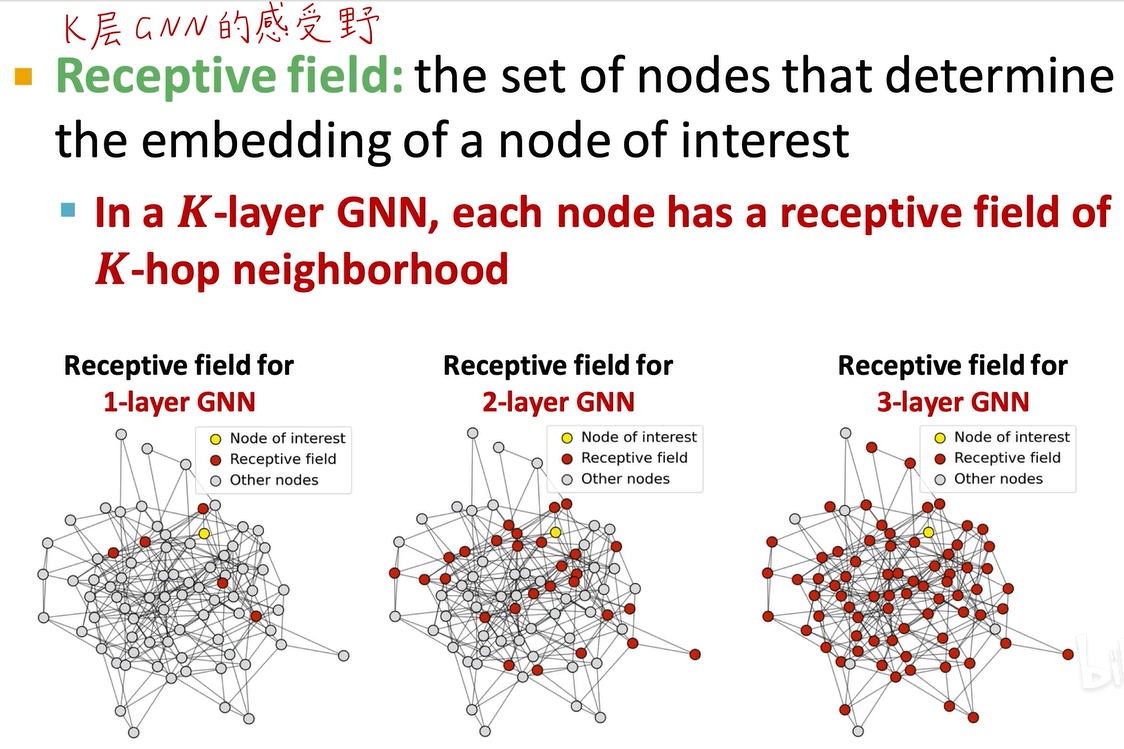
下图是一个博客,由李牧老师推荐。我们可以看到,层数越多,邻居的邻居的邻居就越多,能覆盖到的节点也越多,感受范围也就越大。上次课我们讲过,图神经网络不能无限加深。因为如果太深,所有节点的计算图最后都会很相似,会产生过平滑over smoothing问题,所有节点的嵌入都会收敛到同一个值,即所有节点的embedding都一样,这是我们不想看到的。所以图神经网络不能过深,一般两层或三层就足够了。
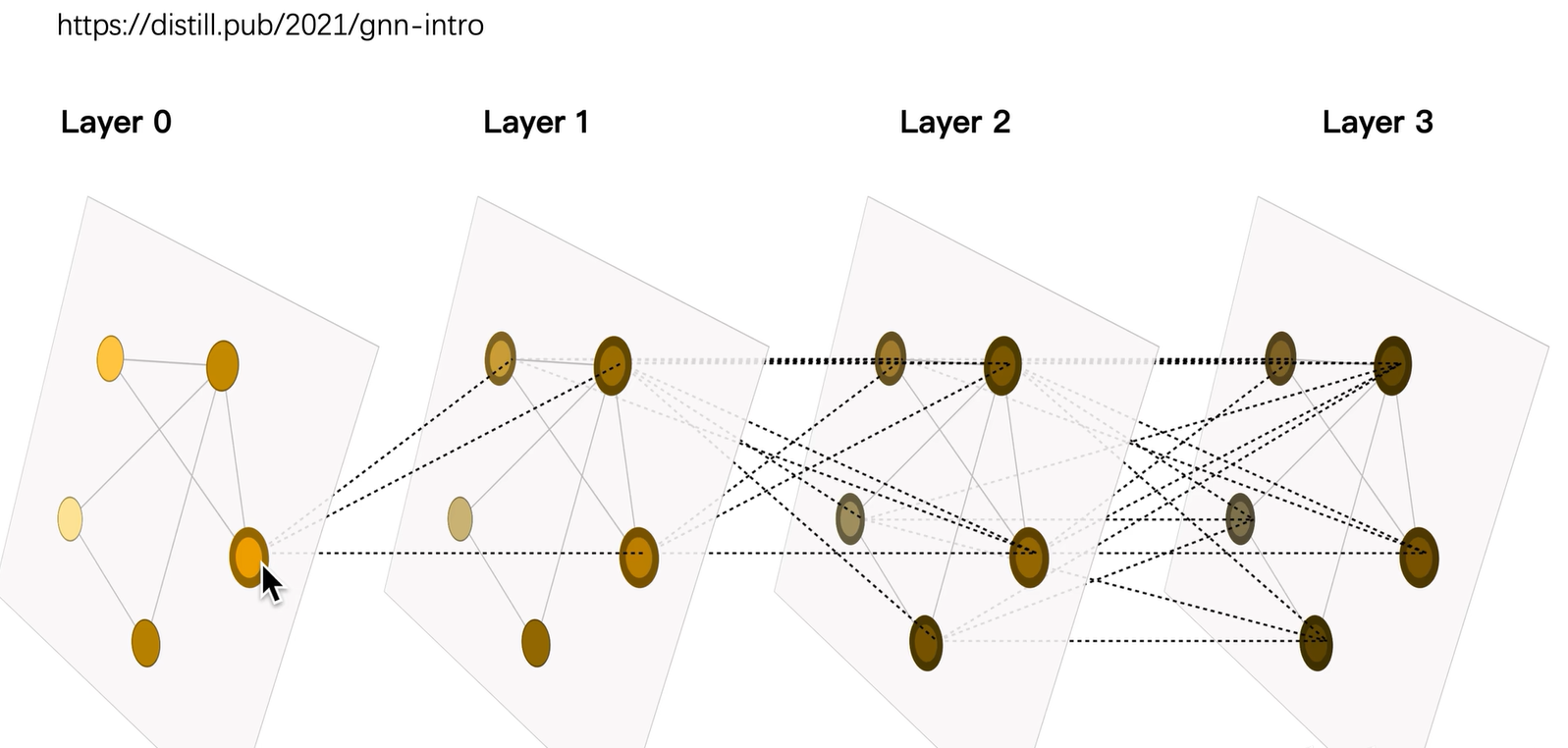
下面也是一个动图,展示了通过消息传递框架,每个节点有其属性特征,周围邻居的信息传递到这个节点上,该节点自己也可以连向自己。通过这样层层的消息传递,计算图的原理就得到了该节点最终的embedding。
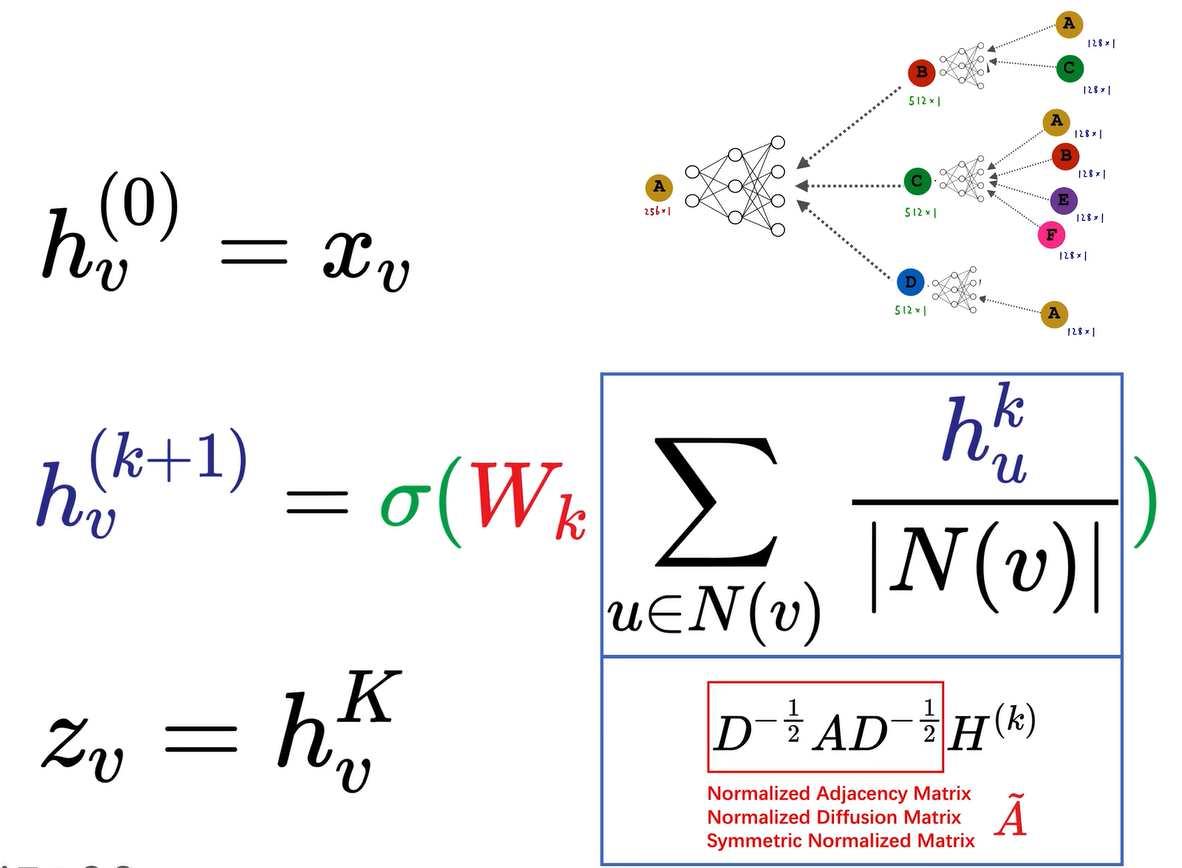
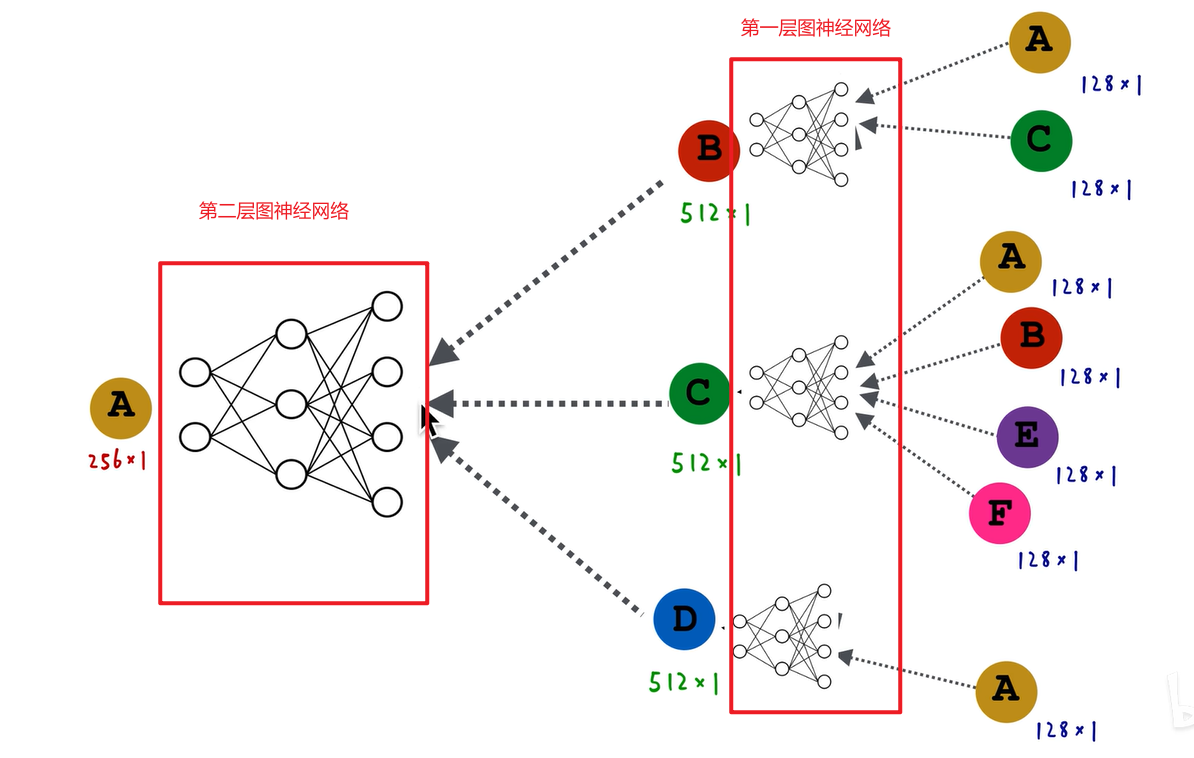
以图卷积神经网络为例,假设每个结点都有128维的属性特征。我们先计算b结点的embedding,即a和c的128维向量逐元素求平均,得到一个新的128维向量,然后输入到一个黑盒子里,输入128维,输出512维,得到b结点的向量。对于c结点,把abef四个结点的128维属性特征逐元素求平均,得到一个新的128维向量,然后输入到黑盒子里,输入128维,输出512维,得到c结点的嵌入。对于d结点,直接把a结点的128维embedding输入到黑盒子里,输入128维,输出512维,得到一个512维的embedding。这就是图卷积神经网络的第一层。
第二层则是把bcd这三个512维的向量逐元素求平均,得到一个新的512维的向量,然后输入到一个白盒子里,白盒子神经网络输入512维的向量,输出256维的向量,就得到了a结点的embedding,我们以a结点最终的embedding作为a结点的输出。
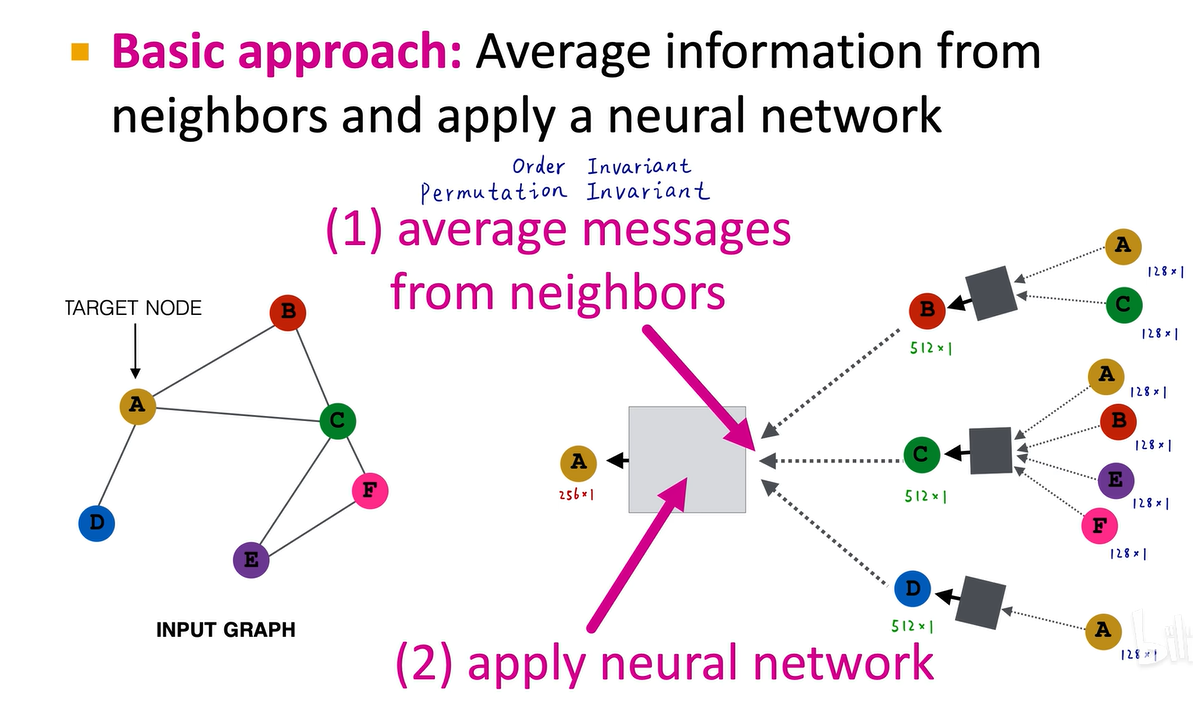
求平均操作是order invariant的,与顺序无关,因为求平均就是把所有元素加起来,而加法满足交换律。类似的操作还有求128个元素的最大值或求和等。求平均、求和、求最大这三个操作都是order invariant,都是permutation invariant。我们希望图神经网络具有顺序不变性,因此在一个图卷积中需要找到这样的操作。
那么这个黑盒子里边到底是什么呢?可以是最简单的一个多层感知器,或者说全连接神经网络。在所示的图卷积神经网络中,计算图包含两个神经网络,一个是黑盒子,包含三个小的部分,还有一个白盒子,是这个大的部分。我们需要训练这两个神经网络的权重。如果神经网络训练好了,我们直接将各种结点计算图中第一层结点的属性特征输入进来,即128位的向量输入进来,通过神经网络就能够得到最终a结点的embedding。因此,我们先用反向传播去训练,再用前向预测去预测。
现在我们要把整个计算图写成数学公式,以数学的形式表达出来。这里边的神经网络,即全连接神经网络,我们可以调整输入和输出的神经元的维度。比如说刚刚的输入是512,输出是256,那我们就可以输出256个神经元,256个神经元的输出就构成一个256维的向量,x就可以人工去调节一个神经网络的输出的数据结构和维度。
2.数学形式
数学形式怎么表示呢?我们可以用这三个公式来表示。
首先在第零层,第零层的嵌入就是每个节点的属性特征,即128维的向量。所以v结点在第零层的嵌入,即v结点的属性特征,我们用x来表示。如果节点没有属性特征怎么办?我们可以强行把128维全部设成1,或者说设成one hot的形式。
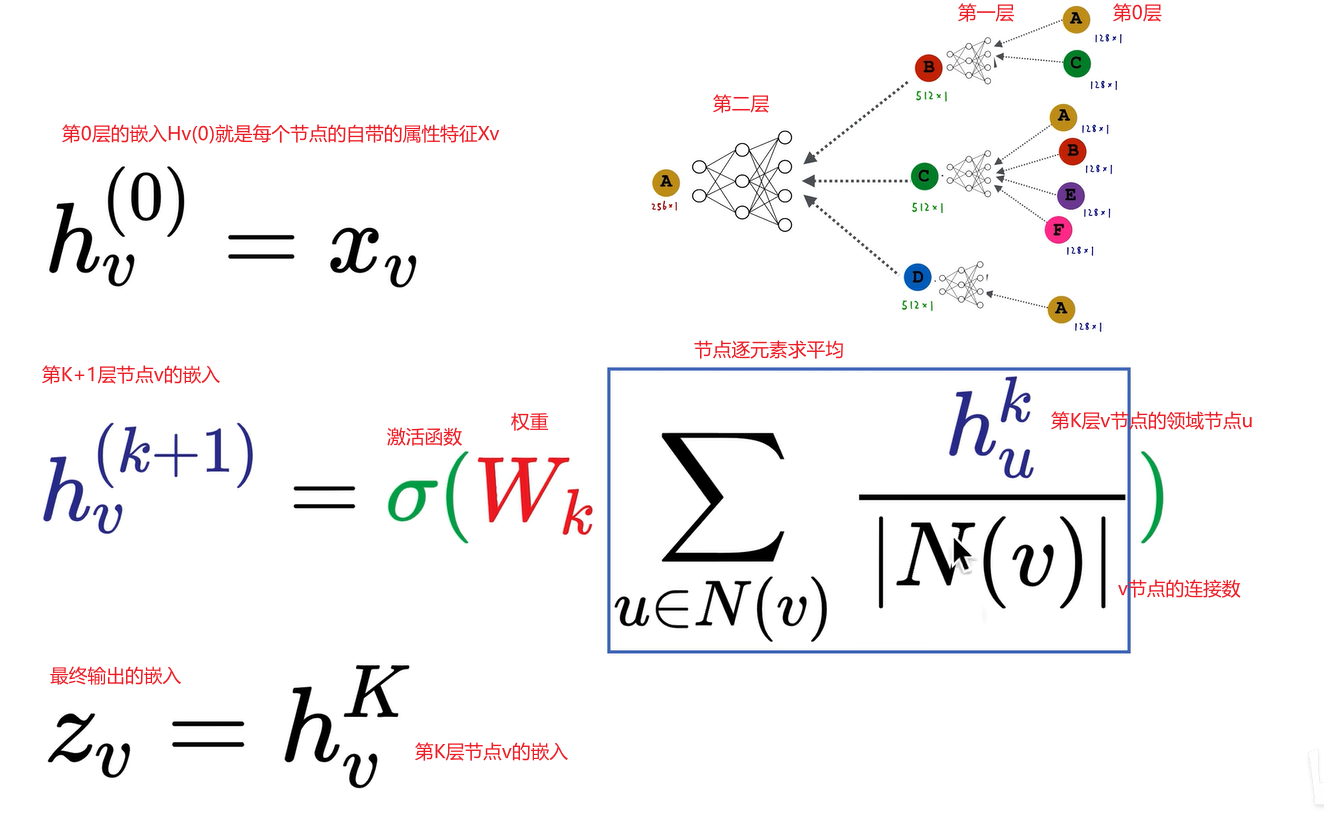
第二个公式非常重要。K+1层v结点的嵌入是由第k层v结点的邻域节点u来计算出来的。先进行元素的求和,先找到v结点的所有邻居结点,比如说我们以c结点为例,abef这四个节点,我们把四个节点上一层的嵌入求和加起来。然后再除以c点的连接数,即4个节点,求和再除以连接数,是一个求平均的过程。整个过程中,对这128位的向量逐元素求平均,得到的也是一个128维的向量。我们把这128维的向量新的向量输入到这个神经网络中,Wk是它的权重。然后再经过一个激活函数,可以是relu、sigmoid、tanh,还可以是switch,即各种神经网络的激活函数都可以,从而得到k+1层v结点的嵌入。蓝框内的内容极为核心,它完成的是对图中四个、两个或一个节点逐元素求平均,然后输入到神经网络中,再经过非线性激活的过程,这是一个递归过程。
图示中我们的神经网络有两层,即图神经网络有两层计算图,k等于二,我们以第二层a结点输出的256维向量作为v结点的z,即最终输出的embedding。这个式子非常重要,这个式子就是将计算图表示为数学形式,即迭代递归的数学形式,其中蓝框内的求平均操作是最重要的,它是order invariant的,即顺序不变,无论结点编号如何变化,操作相同。
此公式略显混乱,我们更倾向于用矩阵表示,通过线性代数,用矩阵表示会更为简洁。下面是用矩阵表示的形式:
若将第k层所有节点的嵌入写成一个大H矩阵,则大H矩阵中每个节点的嵌入就是一行。即第一个公式
我们可以对大H矩阵左乘一个邻接矩阵,或左乘邻接矩阵的第v行,以提取出v结点的邻域结点的嵌入向量。即第二个公式
例如,对于刚刚的c结点,其邻域有abef,我们左乘C结点那一行的邻接矩阵,即可获得abef四个节点的嵌入,即大H矩阵的一个子矩阵。这一行的邻接矩阵就得到了v节点的邻域embedding,这是一个求和过程。那么求平均怎么办呢?我们找到一个对角矩阵D,第一行第一列是第一个节点的连接数,第二行第二列是第二个节点的连接数......其逆矩阵则是给每个元素求倒数。
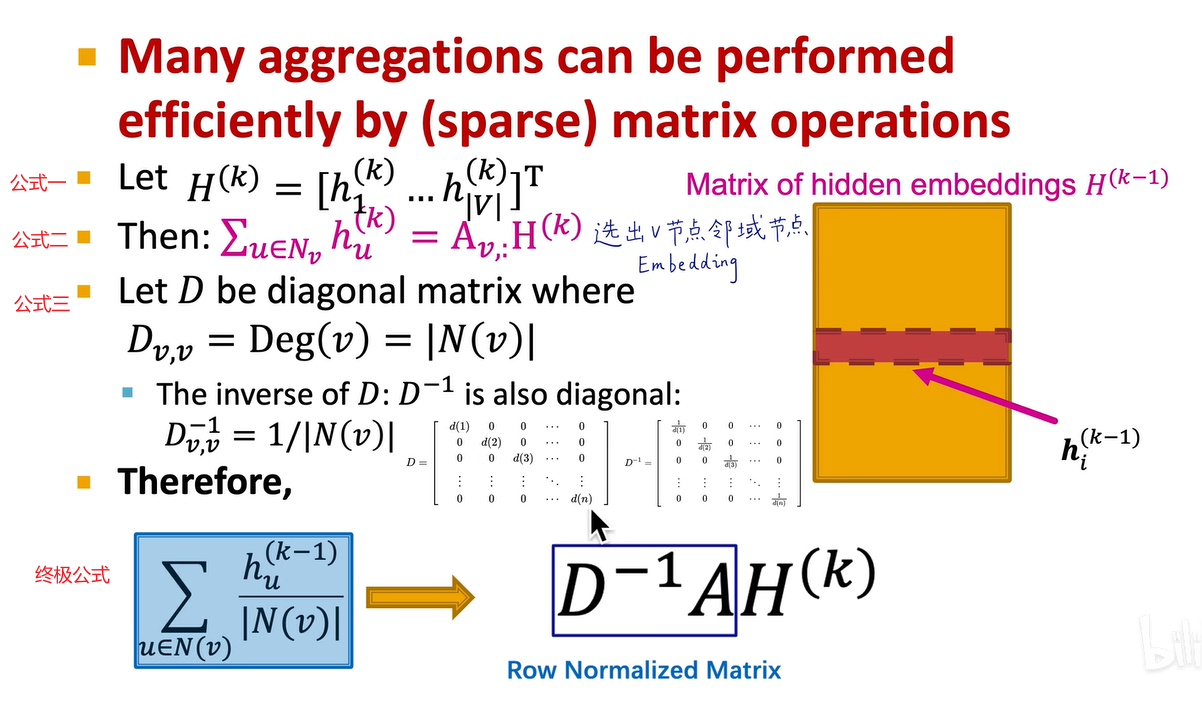
我们可以写成左乘一个邻接矩阵,再左乘D的逆矩阵,这样就完成了求平均的过程。相当于左乘A矩阵是求和过程,再左乘D的逆矩阵是求平均过程。因此,我们可以将刚刚式子中的蓝框部分写成上面的矩阵的形式:它们是完全对应的,该矩阵形式称之为row normalized matrix,其最大特征值为一。
我们以具体代码为例,还是这个图,我们可以将其导入到network x中,它可以自动生成邻接矩阵,但我这里偷懒,直接写出了邻接矩阵,如下:它表示某两个节点之间是否相连,如果相连则为1,不相连则为0。例如,a结点和b结点之间相连,而a结点和e结点之间不相连。其主对角线上为零,表示没有自连接。
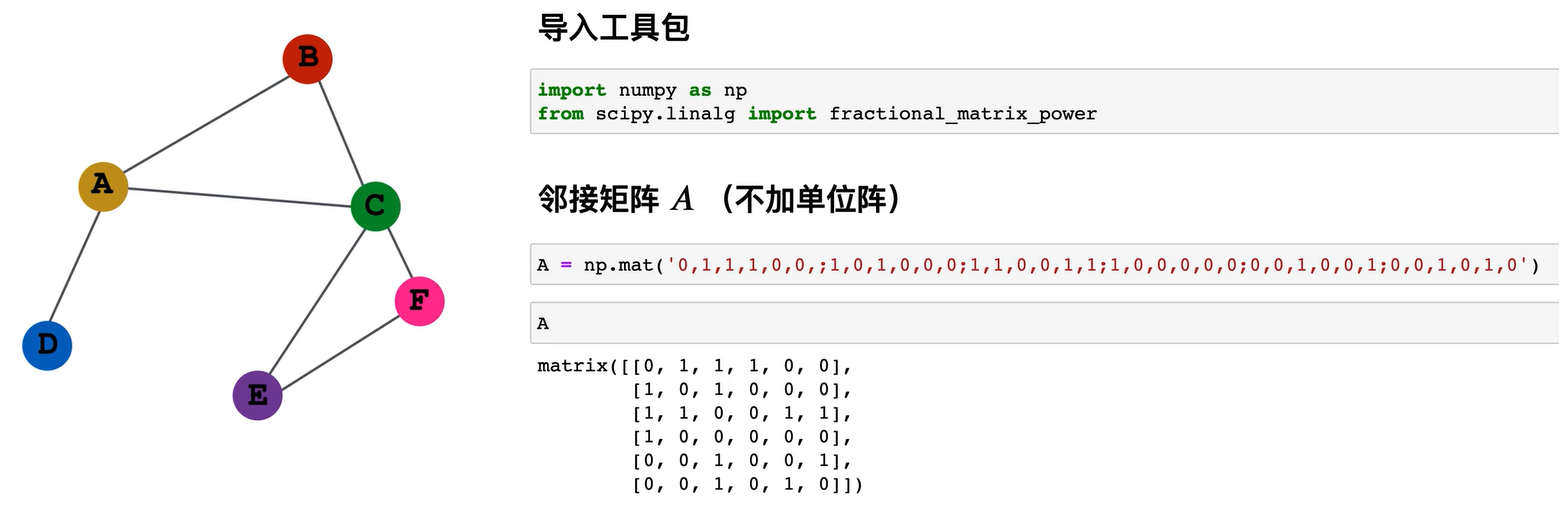


但是上面这个矩阵有个问题就是它只是按照每个节点的度去强行求平均的。比如说a节点是一个女神,bcde是它的舔狗,那么女神她是强行的把bcd三个节点给她的信息求平均的,她没有考虑每一个信息的重要程度。你看c节点,它是一个渣男,它连了四个节点,而d结点,它是一个专一的同学,它只连了a结点,所以如果我们按照这个矩阵作为这个边的权重的话,是不科学的,明显d来的质量会更高,而c结点来的质量会更低,但是a结点会强行的把它们求平均,按照自己的度去求平均,按照自己的连接数去求平均,没有考虑对方结点的连接数,所以这个矩阵有一点不科学。上面这种不可靠的矩阵被称为Row Normalized Matrix行归一化矩阵。
那如果是D的逆矩阵,左乘A矩阵的话,上面这个矩阵的转置,把第一行变成第一列,第二行变成第二列,第三行变成第三列,效果是一样的,还是没有考虑对方的连接数。所以我们想办法对它做一些改进,用ronomlize matrix就会存在这个问题。那怎么改进呢?可以把临界矩阵左乘一个D的逆矩阵,再右乘一个D的逆矩阵,在python里边直接用numpy,就可以把多个矩阵相乘。结果很不错,每个节点的权重不同,例如0.0833333是如何得出的呢?其分子为1,分母为a的连接数乘以c的连接数,即3*4=12,即12分之1,由此得出该值。我们对这个结果很满意,因为它综合考虑了自身的连接数和对方的连接数。

对于bcd节点,d节点的信息权重更高,因为d节点非常专一,只关注a节点;而c节点则较为随意,因此c节点的权重降低;b节点的权重则介于a和c、d之间。因此,这个矩阵更为科学。这种矩阵被称作Naively Symmetric Normalize Matrix。
但这个矩阵存在一个问题,其特征值在负一到一之间。如果一个矩阵的特征值在负一到一之间,这意味着什么?意味着它对应的线性变换会使输入的向量幅值变小,但我们不希望幅值变小。
矩阵,它代表了一种线性变换,可以是剪切、缩放或旋转。如果一个向量左乘一个矩阵后方向发生变化,则说明该向量不是该矩阵的特征向量。如果一个向量在经过矩阵变换后方向不变,就像现在这个向量,那么这个向量就是该矩阵的特征向量,其缩放的倍数就是矩阵的特征值。一个矩阵可能有不止一个特征向量和特征值,每个特征值都对应一个特征向量。虽然大部分向量进行线性变换后方向都会变,但也有少部分向量方向不变,这些向量就是该矩阵的特征向量,其长度的变化幅度由矩阵的特征值决定。
我们刚刚提到,如果矩阵的特征值在负一到一之间,那么输入的向量在经过该矩阵的线性变换后,长度会变小,幅值会变小。我们不希望幅值变小,那怎么办呢?

即A邻接矩阵左乘D的负二分之一次方,再右乘D的负二分之一次方。这个值0.28867513是如何得出的呢?分子为1,分母为根号三乘以根号四,即a的连接数开根号乘以c的连接数。这个矩阵也满足我们刚刚所说的每个连接的权重不同。而且这个矩阵的最大特征值等于一,经过这个矩阵变换后的向量长度不会缩小,这正是我们要的最优效果。这个矩阵被称为Symmetric Normalize Matrix对称归一化邻接矩阵,作为我们最终的胜出者。
若两个节点相连,在此矩阵中,它们的权重值为Di节点连续数开根号乘Dj节点连续数开根号分之一。若两个节点彼此唯一相连,则此矩阵中的值较高;若两个节点彼此相连但它们的邻接节点又有很多,则他们之间的联系权重较低。
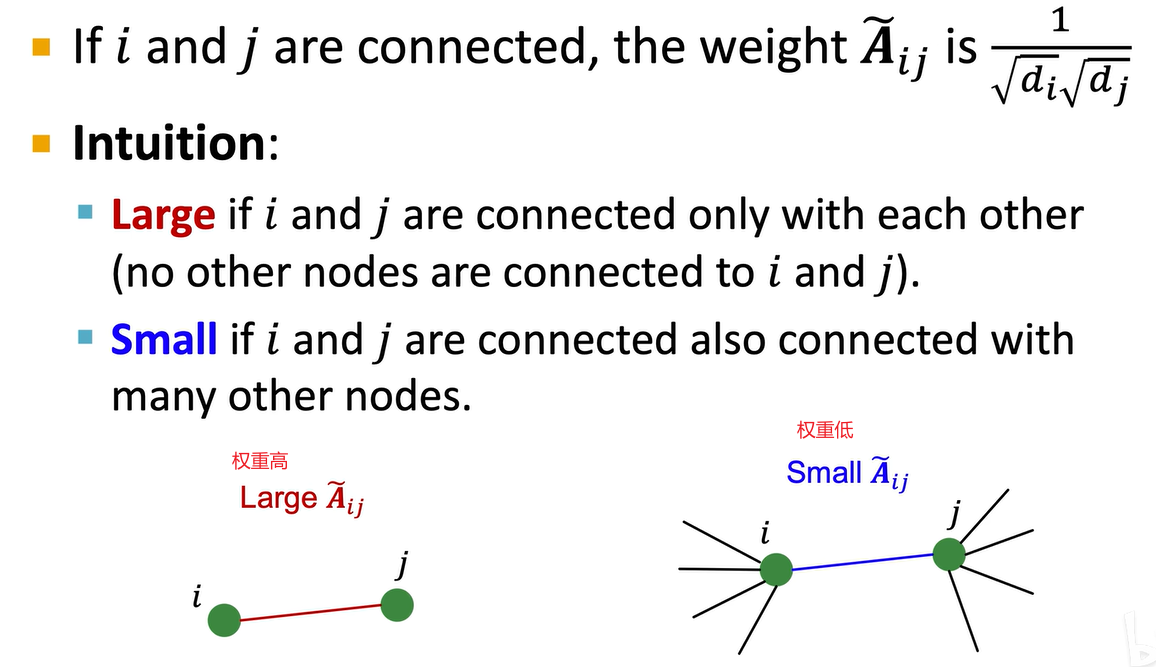
如果一个向量左乘一个A矩阵,代表对向量进行线性变换,信息变换后,向量的方向没变,长度变为原来的拉姆达倍,则证明此矩阵的特征值为拉姆达,特征向量为v向量。
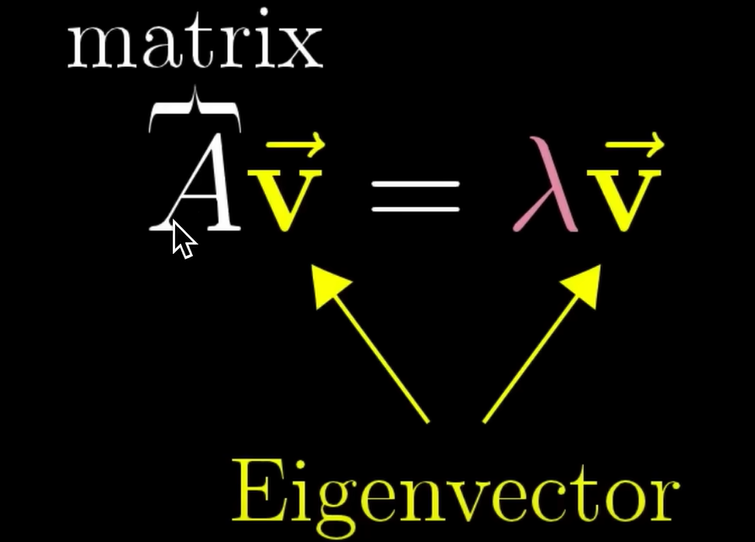
还有一点,我们可以由normalized adjacency matrix计算normalized laplacian matrix。
对邻居的嵌入求和再除以连边数求平均的过程,我们从最初蓝框的数学公式形式写成了矩阵的表述形式,即左乘row normalize matrix形式,但该矩阵未考虑对方的连接数。现在我们组成的是normalized adjacency matrix,该矩阵具备一系列良好性质,也被称作normalized diffusion matrix和symmetric normalized matrix。
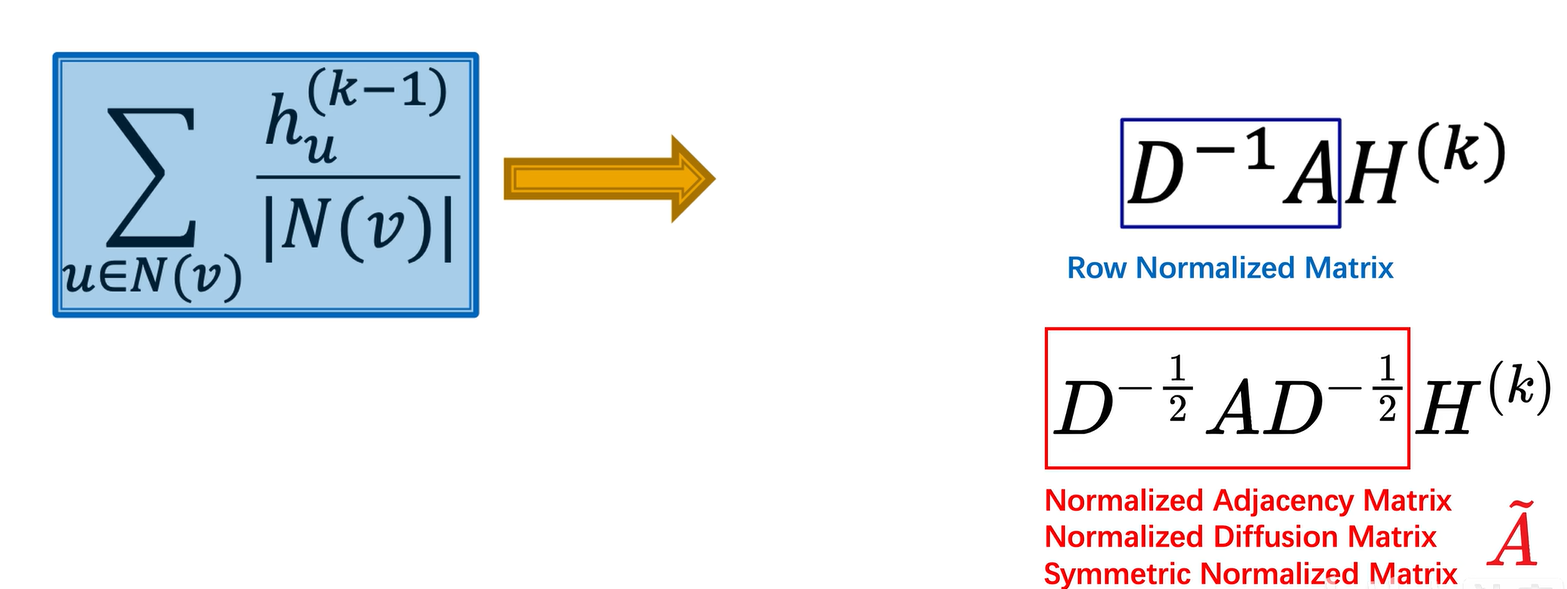
该公式一定要记牢,在各类图神经网络论文中都会看到,即D的负二分之一次方乘A矩阵再乘D的负二分之一次方。很多同学不明白这个公式的意义,但它非常重要。A矩阵其实就是邻接矩阵,只不过邻接矩阵中的权值不再是一或零,而是根据连接数和对方连接数计算得出的新权值。只要图已构建完成,红框里的矩阵normalized diffusion matrix,就是给定的、固定的,不需要学习。
现在,我们可以把它的数学形式写成这样,把蓝框里逐元素求平均的公式写成H矩阵左乘红框这个矩阵,这也是图卷积论文里提到的。L+1层的嵌入是由L层的嵌入算出的。L层的嵌入左乘一个normalized diffusion matrix,然后经过神经网络权重Wk和非线性激活函数,就得到了一层gcn网络的原理。可学习的参数是神经网络的权重矩阵Wk,而不是左边的normalized diffusion matrix。图一旦确定,左边的矩阵是给定的。

在人民邮电出版社的这本书里,也给出了一个类似公式:k+1层的嵌入怎么算呢?是由第k层的嵌入左乘normalized diffusion matrix,然后再经过神经网络的权重层,然后再经过非线性激活函数的激活,就得到了后面的公式。

3.计算图的改进
现在,我们基本上把图卷积神经网络的数学形式搞明白了,但这个计算图是否可以再改进一下呢?答案可以的。
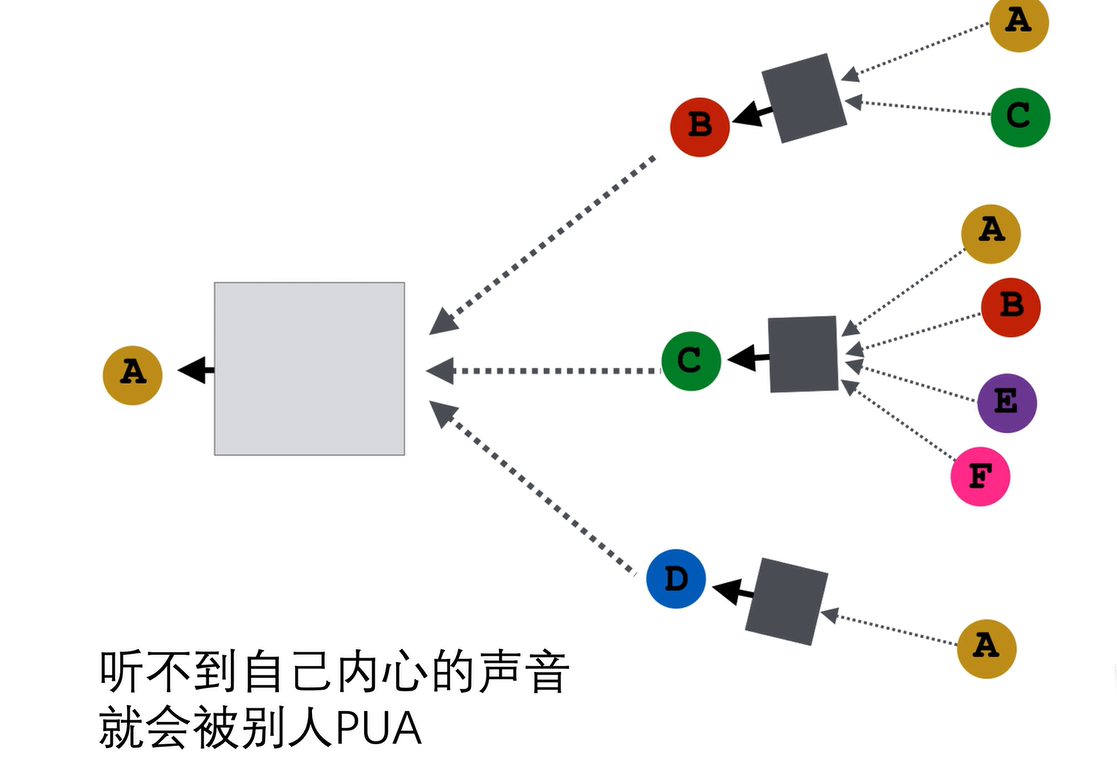
因为这个计算图有个大问题:a结点只能看到bcd节点给它的信息,听不到自己内心的声音。所以在计算图中,我们给每一个节点都加入一个连接,这个连接应该是无向的或者有向的无所谓,让它能够听到自己内心的声音,每个节点都对自己说话,计算图就改变了。
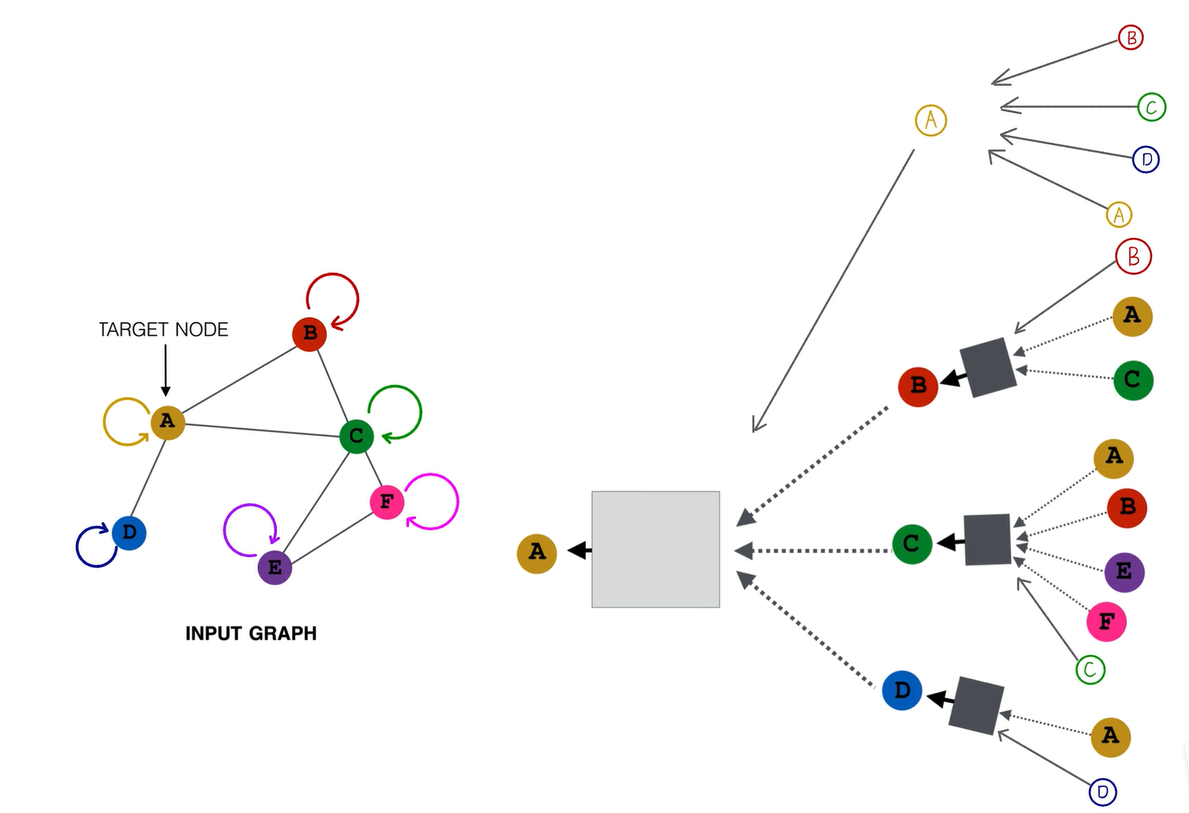
A节点的第一层就变成了abcd四个节点,a节点的一阶邻居也是abcd四个节点,b节点、C节点、D节点也都能听到上一层它们自己的内心声音,计算图就变成了这样。这就是图卷积最终形式的计算图,这张图非常重要,值得你暂停下来研究至少五分钟。
此时的邻接矩阵,主对角线全部变成了1,原来的邻接矩阵加一个单位阵,因为自己和自己有连接了,称之为self loop,所以主对角线也自己和自己相连了。
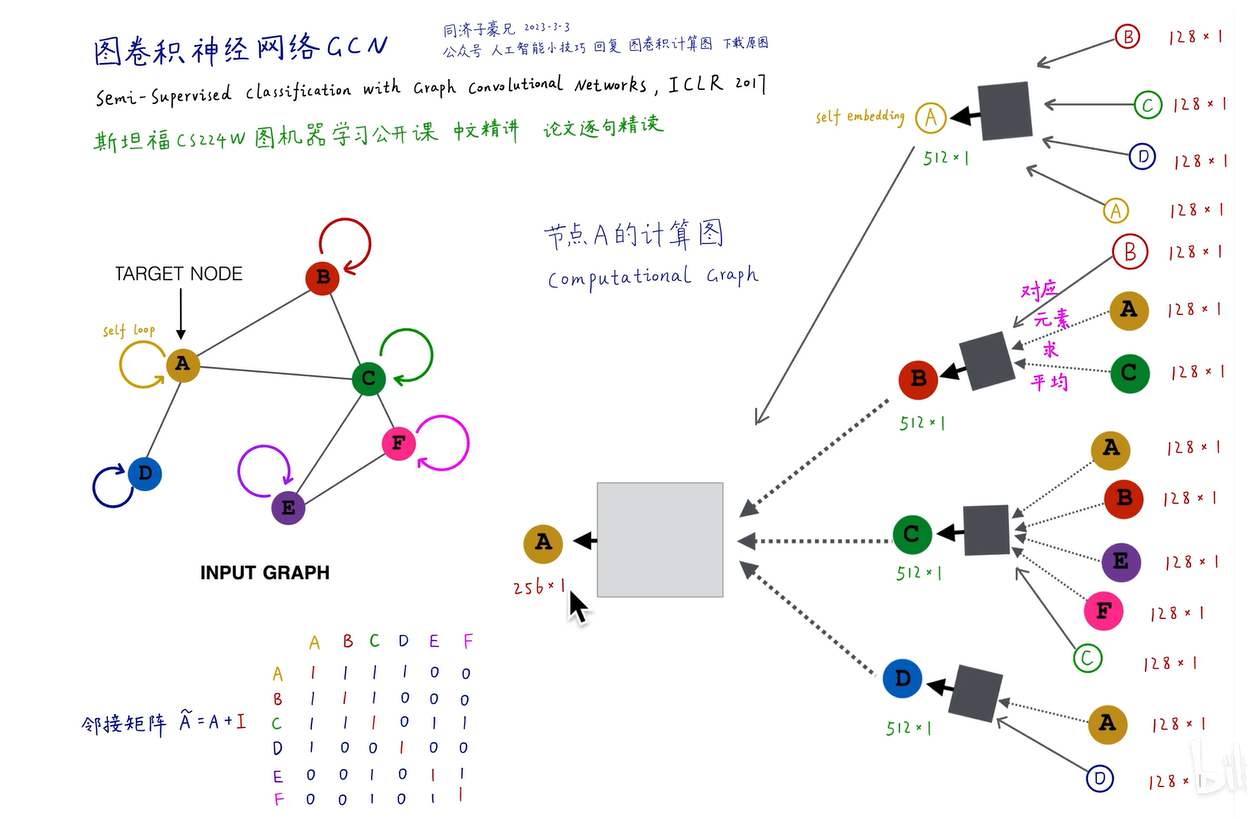
然后在a节点的Embedding怎么算呢?是由上一层的邻域和它上一层的自己的嵌入来算的。上一层自己的嵌入称之为self embedding,是这四个512维的向量逐元素求平均输入到白色神经网络里边,输出256维的向量。那a节点的512维的self embedding怎么算呢?由abcd四个节点的属性特征128维的输入到黑色神经网络里边,也是逐元素求平均,然后输入到黑色神经网络里边,输入128维,输出512维。得到的下边的这三个节点也是多了一个节点来参加求平均的过程,在第一层或者叫第零层。第零层最右边这些节点全部都是128维的属性特征,然后输入到黑色神经网络里边,这四个黑色神经网络都是全连接共享的同一个神经网络,其他的都一样了。所以这个图是最终形式的图卷积神经网络的形式。
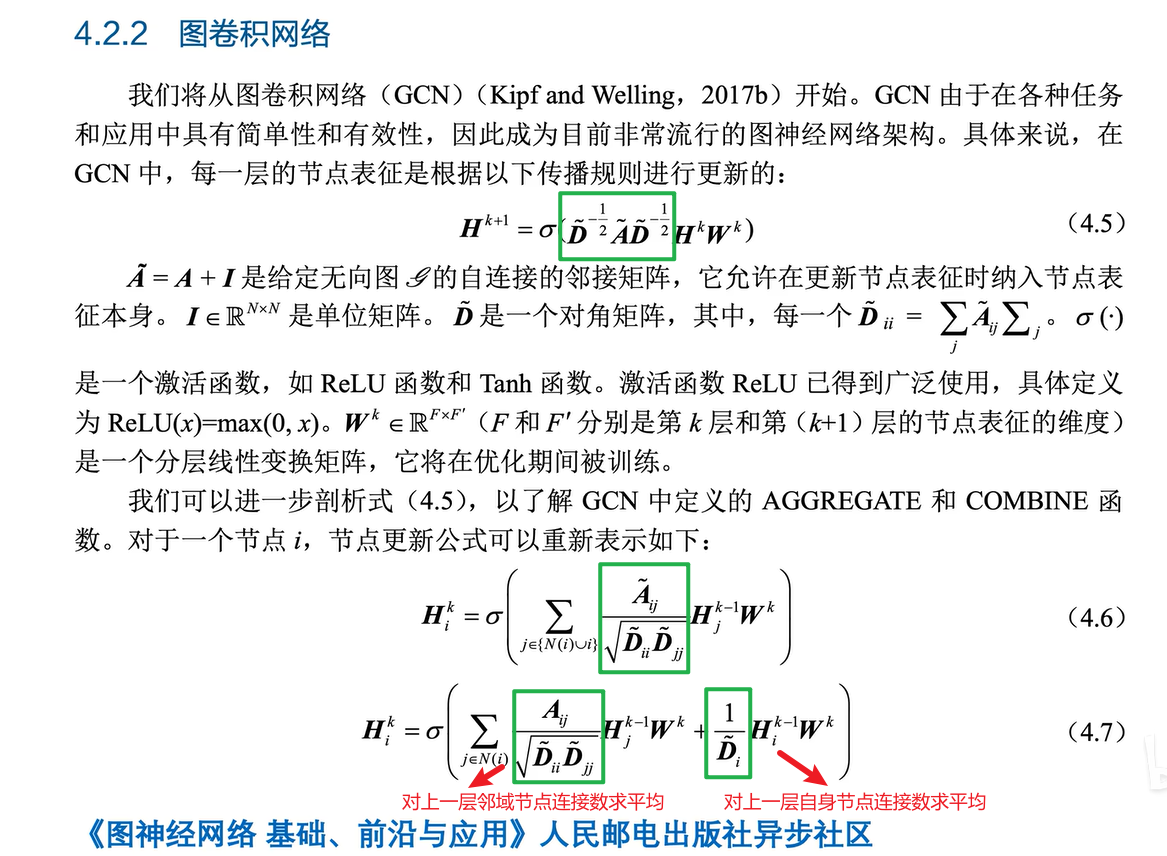
公式4.5、4.6、4.7都是等价的,4.5公式就是标准的normalized diffusion matrix格式,是一个泛化的写法;进一步表述是4.6和4.7格式,而4.6和4.7公式表示:不但考虑了邻域节点Embedding的传递还考虑了自身节点Embedding的传递;公式4.7是根据4.6又进一步的展开写法,将上一层邻域节点的影响与上一层自身节点的影响分开来写。
还可以进一步扩展,即邻域节点用一套权重Wk,而self embedding再使用另一套权重Bk,其他式子相同。即节点v的k+1层的Embedding是由k层邻域节点u的Embedding和k层自身节点的Embedding所共同决定的。
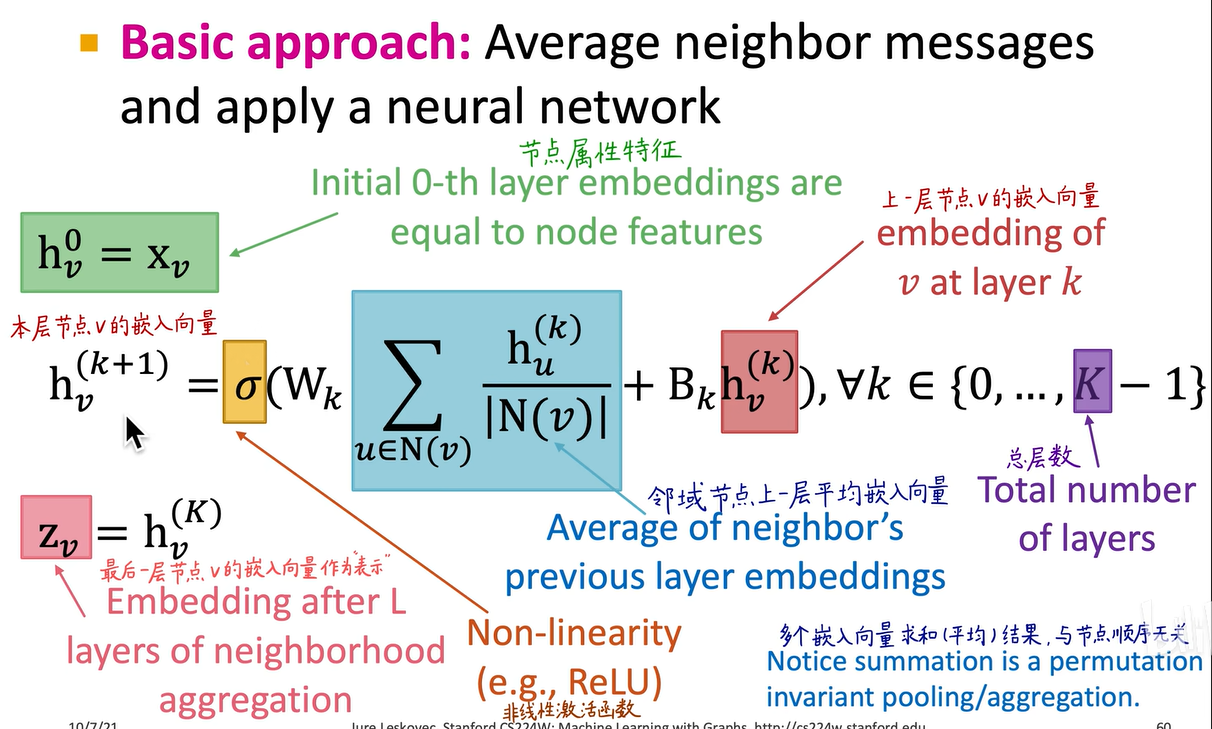
其实是一样的,Wk和Bk是第k层图神经网络需学习的权重参数。注意这不是恒等映射,也不是残差连接。若不加Bk权重,直接加上v节点在第k层的嵌入(Self embedding),就变成恒等映射残差连接,但这里不是残差连接,不像resnet那样。
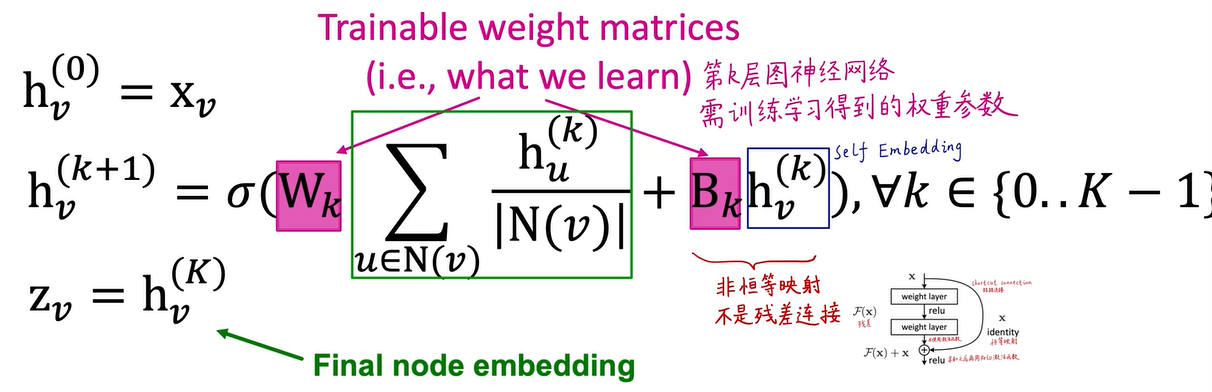
最终形式就是这样,红色是邻域信息汇聚,蓝色是自己信息转换。不仅要听别人评价,自己也要有清晰认识。

当然,A~矩阵就是咱们说的normalized adjacency matrix,它是稀疏矩阵,可加各种稀疏矩阵运算技巧。但稀疏矩阵在gpu上运算一直是工程上难题,也是很多大厂工程师努力解决的问题。
4.训练图神经网络
数学形式讲完了,计算图搭好了,神经网络架构也说清楚了,那该如何训练这个图神经网络呢?需要定义一个损失函数去学习和优化。神经网络中的权重可通过监督学习,或者无监督学习(也叫自监督学习)方式获得。

对于监督学习任务,比如半监督学习节点分类,如已知部分节点类别,可构建损失函数。比如以v节点为例,将其输入图卷积神经网络得到嵌入,再加预测头预测是否发生欺诈,将预测结果与真实结果比对,算出如交叉熵损失函数(用于分类任务),目标是迭代优化神经网络权重,使交叉熵损失函数最小化,这是训练过程。若是无监督学习且没有节点标签,可借鉴deep walk的思路,直接用图自身结构作为监督标注。我们希望原图中直接相连的两个点,其学习到的向量嵌入尽可能接近。
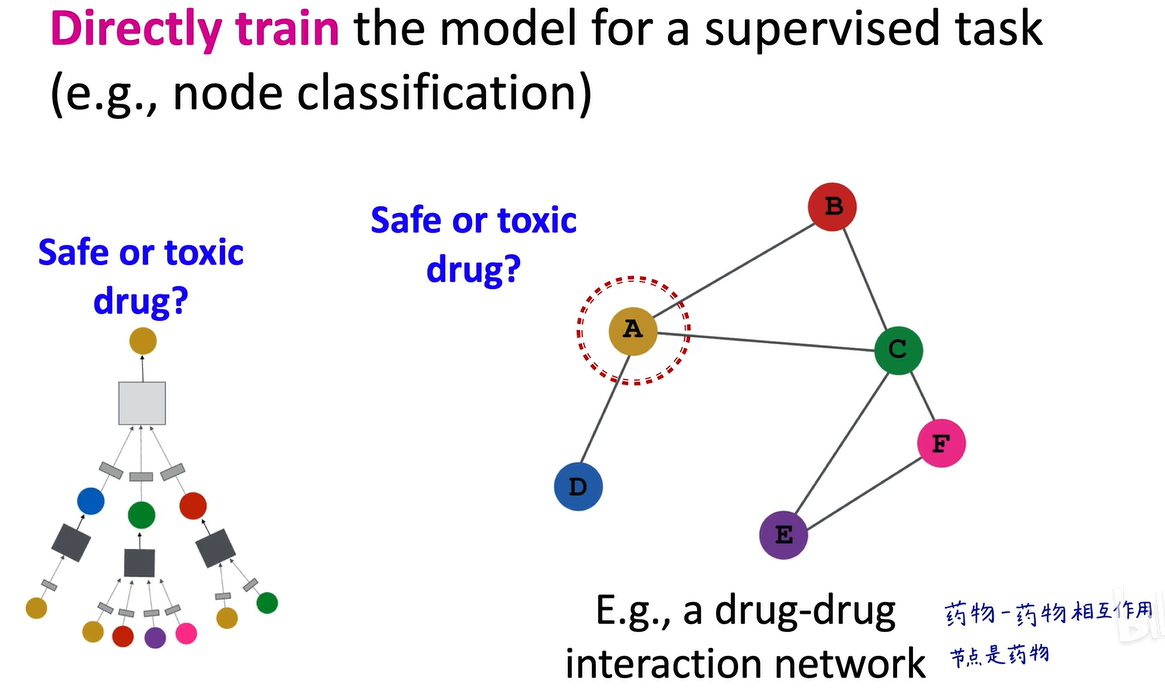
接下来具体说明,我们先看监督学习,例如,在药物相互作用网络中,每个节点代表一种药物,我们想要进行节点分类,判断每个节点是否有毒。对于每个药物,判断其是否有毒,然后标注已知有毒和已知无毒的药物,去构建计算图,将每个计算图视为一个样本。将样本输入图卷积神经网络,得到嵌入向量,再连接分类头获得预测结果,将预测结果与真实标注结果比对,计算交叉熵损失函数。我们的目标是调整神经网络权重,使交叉熵损失函数最小化。关于交叉熵损失函数的推导,在前面的深度学习基础视频中有详细讲解,我还做了详细笔记。
下图是GCN论文中的插图,目标是输入带属性特征的图,经过图卷积神经网络后,获得每个节点的嵌入。嵌入比属性特征质量更高,变为语义嵌入,具有低维、连续、稠密的特点。然后,使用嵌入向量连接预测头进行分类。我们可以将嵌入向量降维到二维空间,观察不同类别的节点在二维空间中的分布,很可能线性可分,因此可以添加一个线性分类预测头进行分类。在D维空间中,向量的相似度反映了对应节点在原图中的相似度。
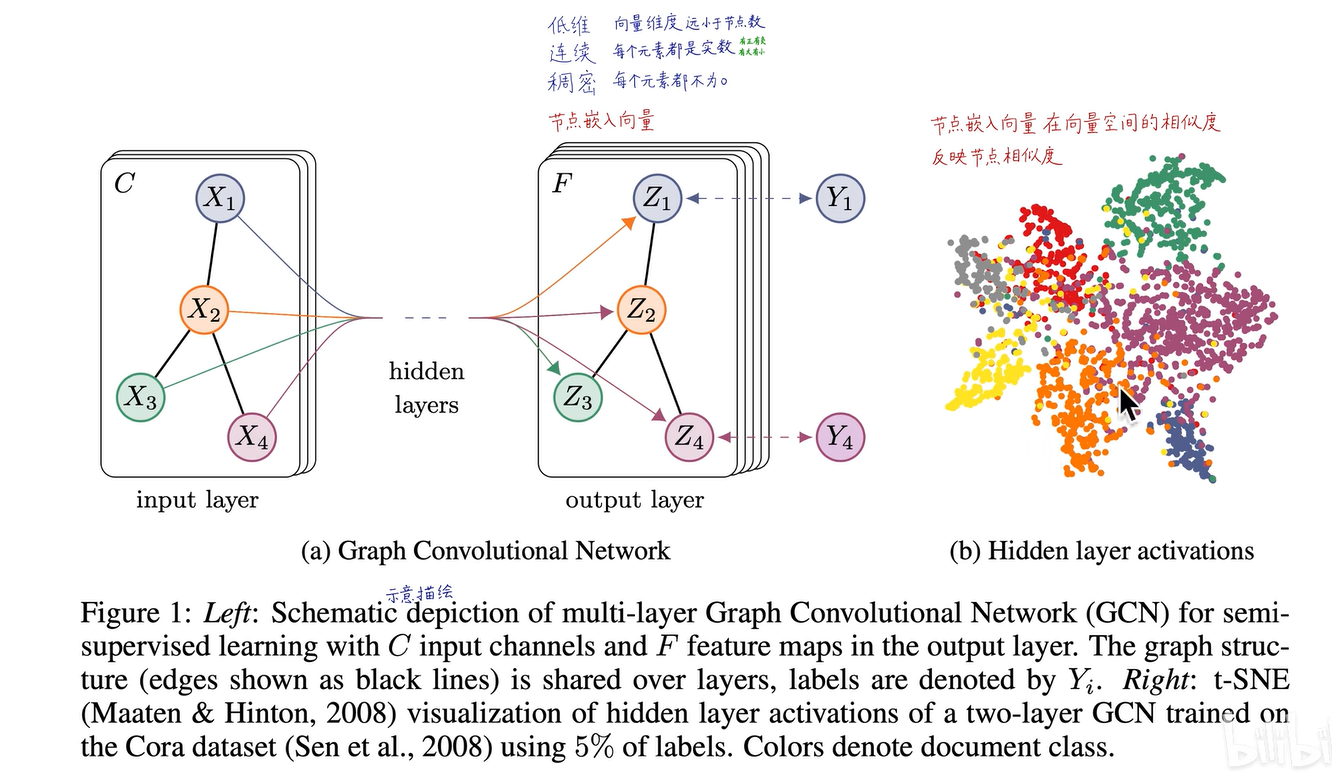
下面是GCN官网给出的视频。在训练过程中,可以看到这四类节点被逐渐分开,证明GCN的嵌入向量质量很高,在D维空间中将这四类节点变得线性可分。我们只需添加一个四分类的线性分类层,就可以进行节点分类。如果是多个类别的话。效果就是这样,在训练过程中,D维向量的质量逐渐提高,在D维空间中变得越来越线性可分。最终,我们得到了高质量的D维向量。可以使用D维向量进行各种图学习任务,如节点分类、连接预测、社群检测、全图分类。
以上是监督学习,我们再看无监督学习。如果没有节点标注,我们就用图自身的结构作为自监督的标注。将两个节点分别输入图神经网络,得到两个d维向量,然后直接计算这两个d维向量的点乘(数量积),对应的就是这两个向量的余弦相似度。我们希望这两个向量的余弦相似度能反映这两个节点在原图中的关系。若两个节点直接相连,我们希望这两个d维向量的数量积越大越好,越接近于1越好。或者,若在某个随机游走序列中,这两个节点都被采样到同一个随机游走序列中,我们也希望这两个向量的数量级越大越好。如何定义两个节点相似?可以直接看,若两个节点直接相连,就视为相似;也可以看它们是否在同一个随机游走序列中被采样到,就认定它们相似。

这里涉及编码器和解码器,编码器神经网络将节点变成向量,解码器计算两个向量的数量积,得出余弦相似度,解码器会算出一个标量。我们的目标是,如果两个节点相似,解码器得到的标量就大;如果两个节点不相似,标量就低。所以,这就是一种自监督或无监督的学习方式。
5.图神经网络的优点
优点非常多,在之前我们讲的DeepWalk、node2vec,struc2vec等基于随机游走的方法中,我们直接优化的目标并非神经网络,而是每个节点的d维向量。我们需要迭代优化每个向量的每个值,使式子成立,损失函数最小化。因此,参数量其实非常大。如果有全中国14亿人,每个人有256个维度的向量,那么参数个数就是14亿个乘256,非常臃肿。

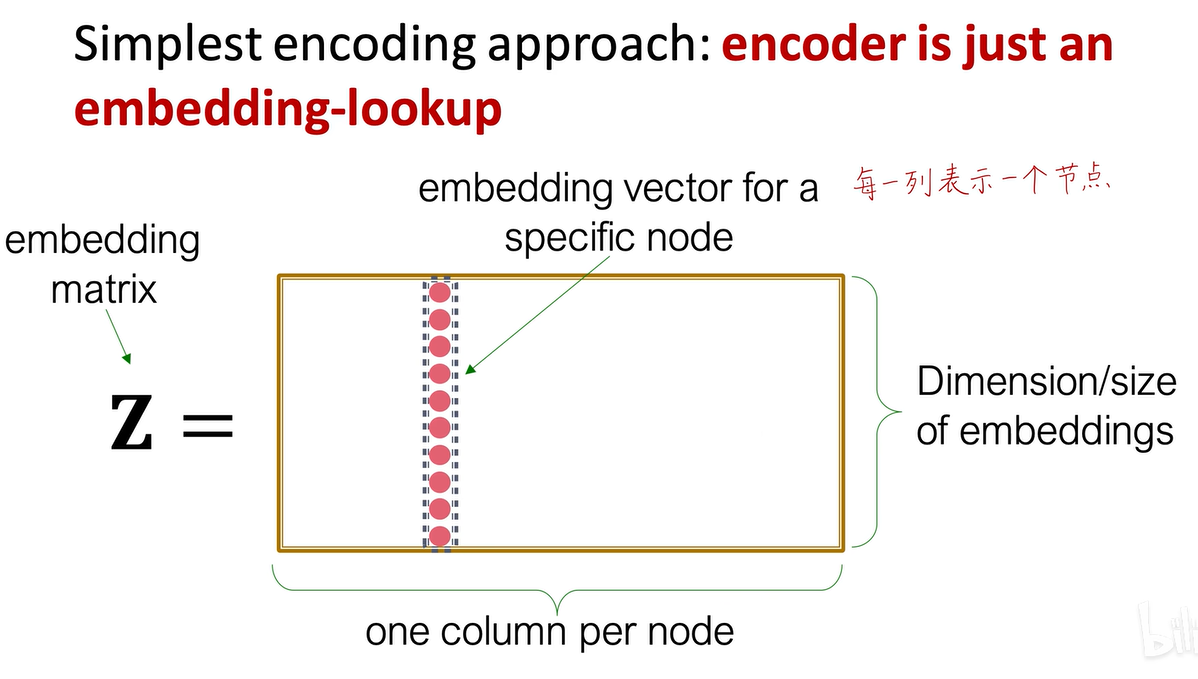
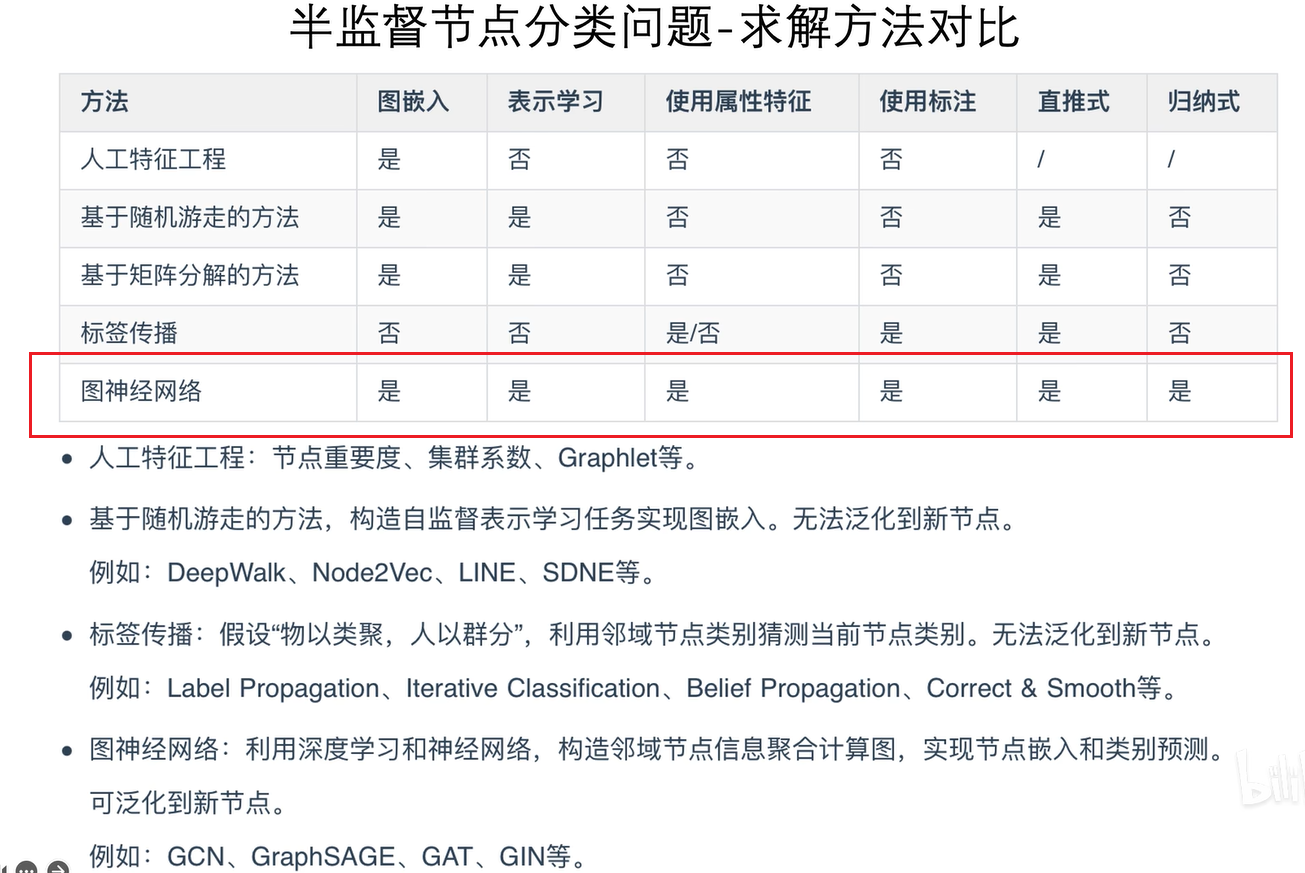
这张表每一列表示一个节点的向量,而且是直推式学习(用于预测的节点在训练时已经见过),即transductive learning。就像这14亿人的节点都在这里,不管你后续要做什么预测任务,你还是要看这张表,这张表在训练时见过,预测时还要用,所以它是直推式学习,无法泛化到新节点。

图神经网络则是归纳式学习,即inductive learning,它可以泛化到新节点。用于预测的节点在训练时根本没见过。不管我们今天讲的GCN,还是后边讲的graphSAGE,GAT、GIN都可以用于归纳式学习,这才符合人工智能要达到的核心目标——泛化到新的节点、新的样本和新的场景中。
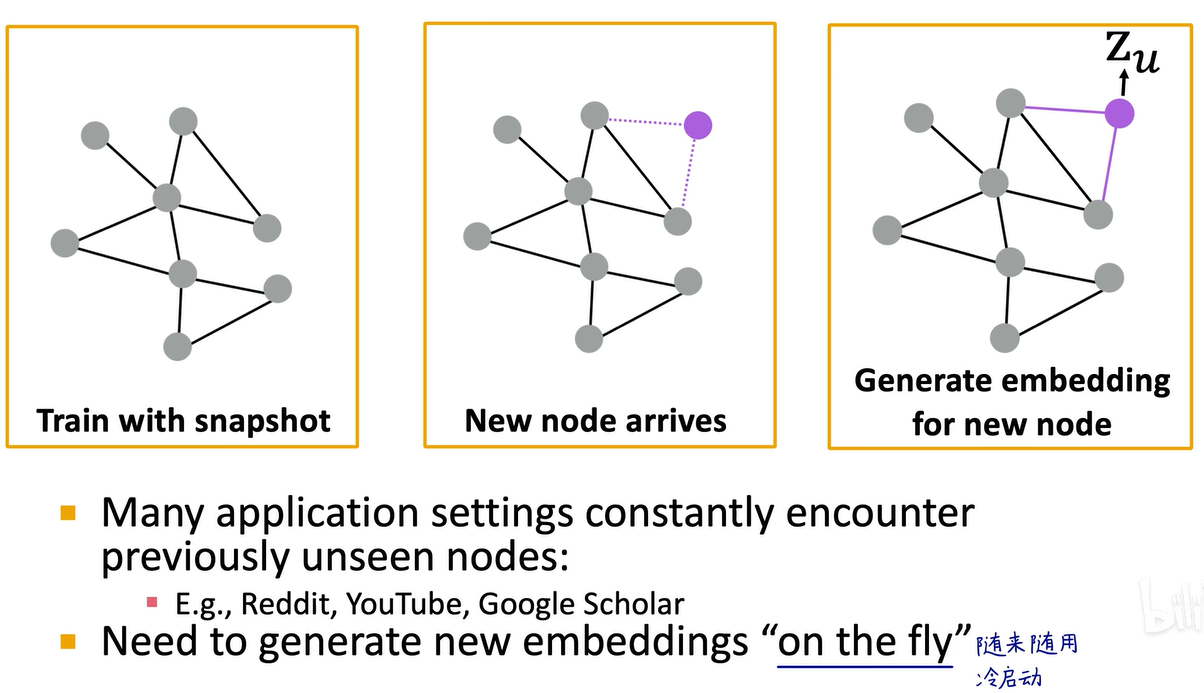
而之前我们讲的DeepWalk和node2vec,如果来了一个新节点加入到图中,比如来了一个新的社交网络好友,我们没法立马获得这个新节点的嵌入向量,我们需要重新采样随机游走序列,再优化一次才能得到新节点的嵌入向量,它是直推式的,无法泛化。对于图神经网络而言,一旦五号节点和二号节点建立好友关系,我们立即可以获得五号节点的属性特征和计算图,直接运行训练好的图神经网络,即可马上得到五号节点的嵌入向量。因此,图神经网络可以进行归纳式学习,能够泛化到新节点。
此外,图神经网络通过计算图的范式可以获得功能结构、角色信息。例如,两个节点可能相隔甚远,但它们具有相同的结构功能或角色。比如,马六甲海峡和巴拿马运河分别位于地球的两端,但它们都发挥着交通要道的功能。图神经网络能够捕捉这样的关系,并通过计算图的范式进行识别。再比如,唐太宗李世民和明成祖朱棣在历史上相隔数百年,但他们在功能结构和角色方面相似,图神经网络也能捕获这样的关系。传统的deep walk和node2vec无法捕捉这样的关系,因为随机游走序列的覆盖范围有限。随机游走序列有一个最大长度,无法从唐朝跨越到明朝,或从马六甲海峡跨越到巴拿马运河,因此无法学到这些信息,而图神经网络通过计算图的范式可以识别和学习到这样的特征。
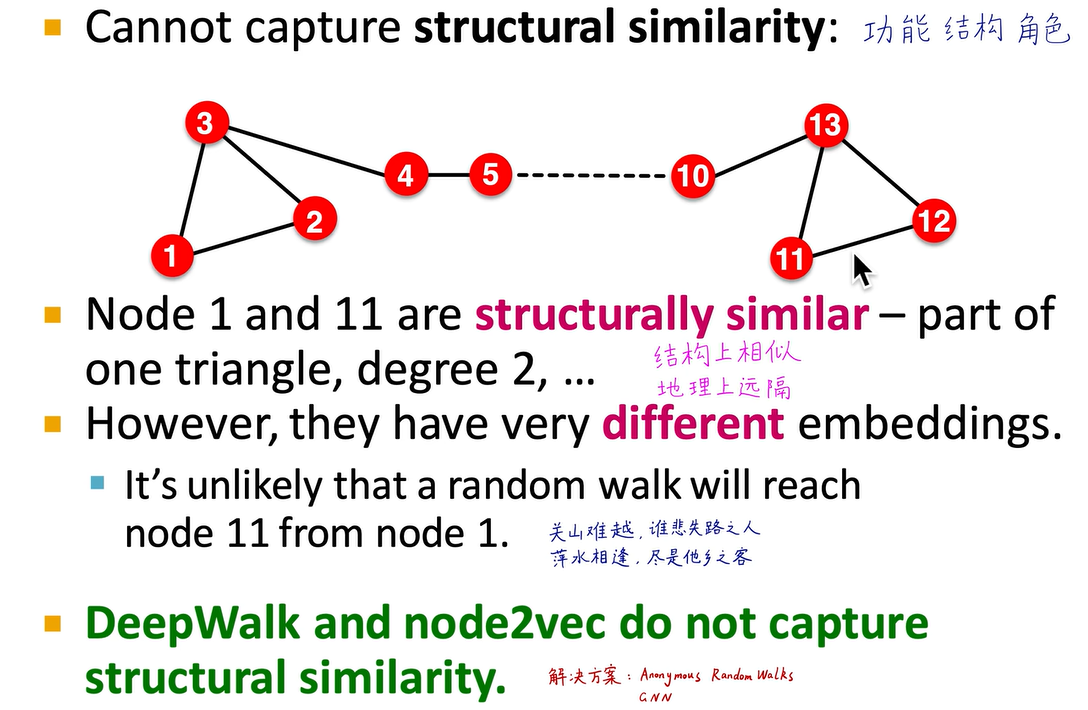
每个节点都构建自己的计算图,比如紫色节点和粉色节点的计算图非常相似,这反映了它们的结构、功能和角色信息。一个节点是中枢、核心节点还是外围、边缘节点,或是桥接节点,都可以通过图神经网络看出来。
图神经网络还有一个非常好的优点:在之前的DeepWalk和node2vec中,它们只使用了图本身的连接信息,没有利用节点的属性特征或标注信息。而在图神经网络中,这些信息得到了充分利用。节点的属性特征非常重要,例如,在银行风控的图神经网络中,每个用户的收入、学历、年龄、婚姻状态、工作单位以及征信信息都是判定其是否可能发生贷款欺诈或信用卡欺诈的重要特征。而之前的这些方法都是无监督的,没有用到这些属性特征和标注,图神经网络则充分利用了这些特征。
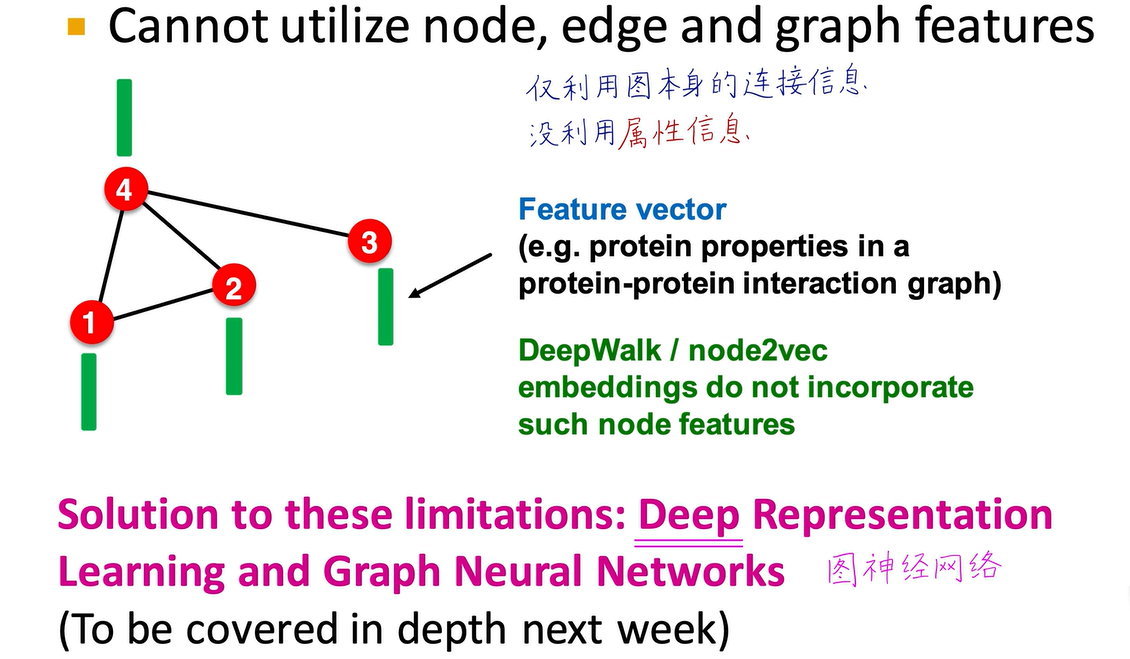

除了节点本身之外,连接子图、全图都可以有属性特征,图神经网络在这方面可以大显身手。如果是多模态特征,即既有图像、视频,又有文本、音频,那么这些属性特征就更具有数据挖掘的潜力和价值,也只有图神经网络能够完成这样的任务。
总结一下之前的这些方法(包括DeepWlak、Node2Vec、Line),其缺点包括:

1.每个节点的嵌入向量都需要单独训练,参数量大且没有参数共享,容易导致过拟合。
2.直推式学习,无法泛化到新图和新节点。
3.没有用到节点的属性特征和标注信息。
而图神经网络很好的解决了这三个缺点,特别是可以泛化到新节点的特性,我们可以在一些旧节点上训练图神经网络,当新节点出现时,可以马上获得其嵌入和预测结果,这在推荐系统中被称为冷启动,例如新注册一个APP时,系统会询问我们对哪些领域和博主感兴趣,然后,系统可以根据用户刚注册时填写的信息,马上安排推荐系统,这就是冷启动,随来随用。无论是好友的社交网络、谷歌的学术关系、抖音的点赞、关注、收藏、转发,还是电商的购买、加入购物车,新用户来时都可以马上看到推荐系统的结果,这就是对新节点的泛化。
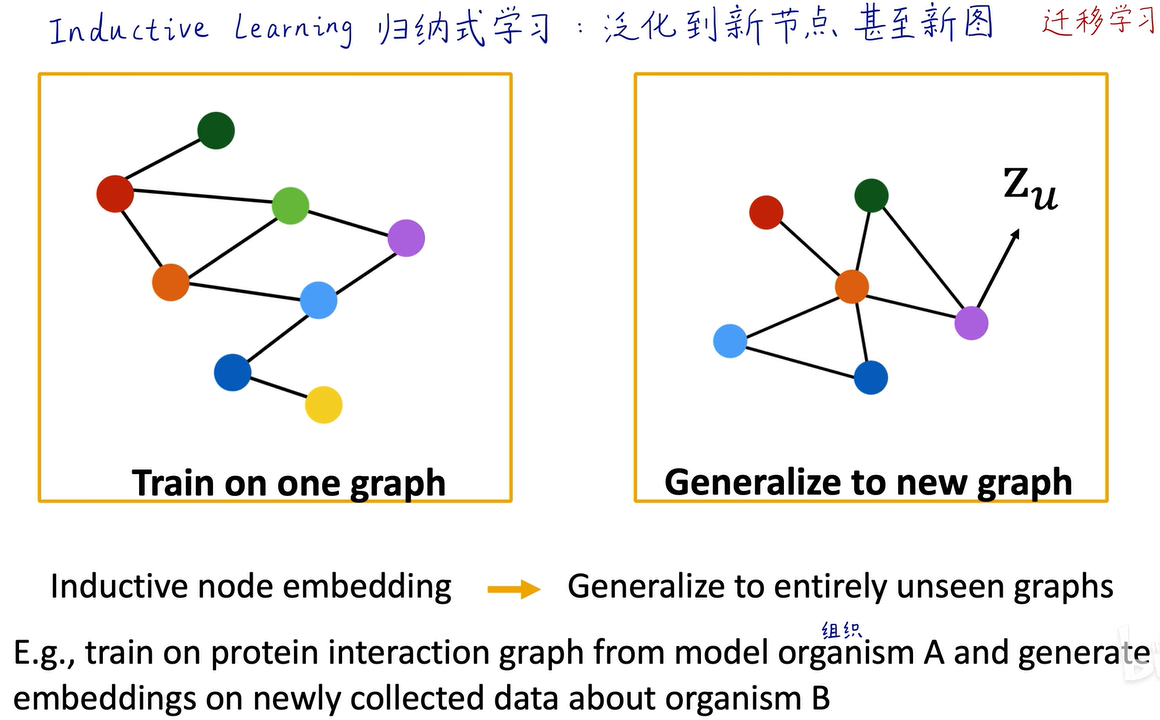
图神经网络还可以在图的层面上进行泛化,比如在爬行动物的图上训练一个蛋白质网络,是否可以直接用在两栖类图中,在旧图上学习到的图神经网络,是否可以直接用在新的图上进行预测。比如,我把美国的经济和交易网络训练成一个图神经网络,然后把它用在中国的社交关系里边进行预测,这很可能也是可行的。所以,图神经网络不仅可以在节点层面进行泛化,也可以在全图层面进行归纳式学习,这是我们非常喜欢的一个特点。因为人工智能很大一部分就是要做迁移学习,在GCN的原始论文中(下图),它在四个主流数据集上进行了图节点分类的跑分,GCN远胜于传统方法,我们之前就讲过DeepWalk、Label Propagation、迭代分类等,它们都败给了GCN。为什么呢?因为这些方法都没有利用到节点的属性特征和标注信息,而GCN是有监督的,并且用到了这些有价值的信息。
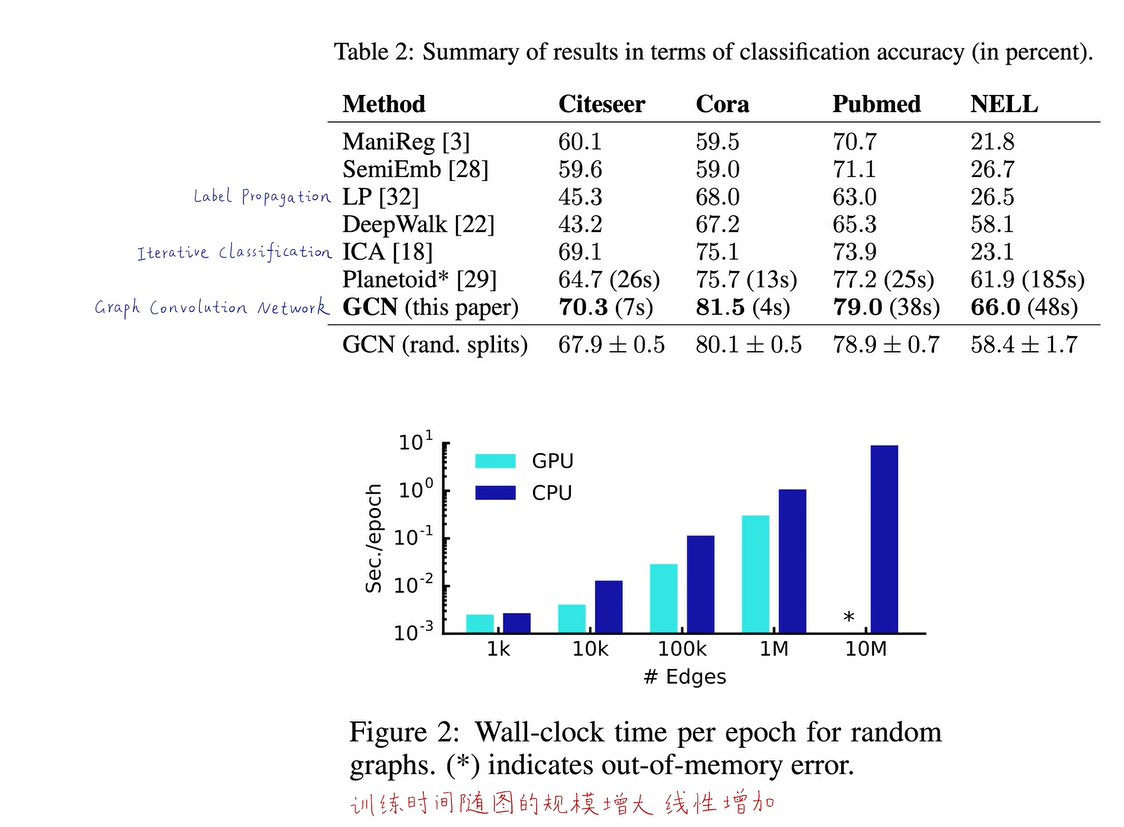
而且,GCN的训练时间随图的规模增大而线性增加,横轴和纵轴都是对数坐标系,也就是说这个算法复杂度是线性的,这也是我们非常喜欢的一种算法。它不会出现指数或多项式等非常复杂的算法,可以被应用到各种复杂的场景中,可扩展性非常好。
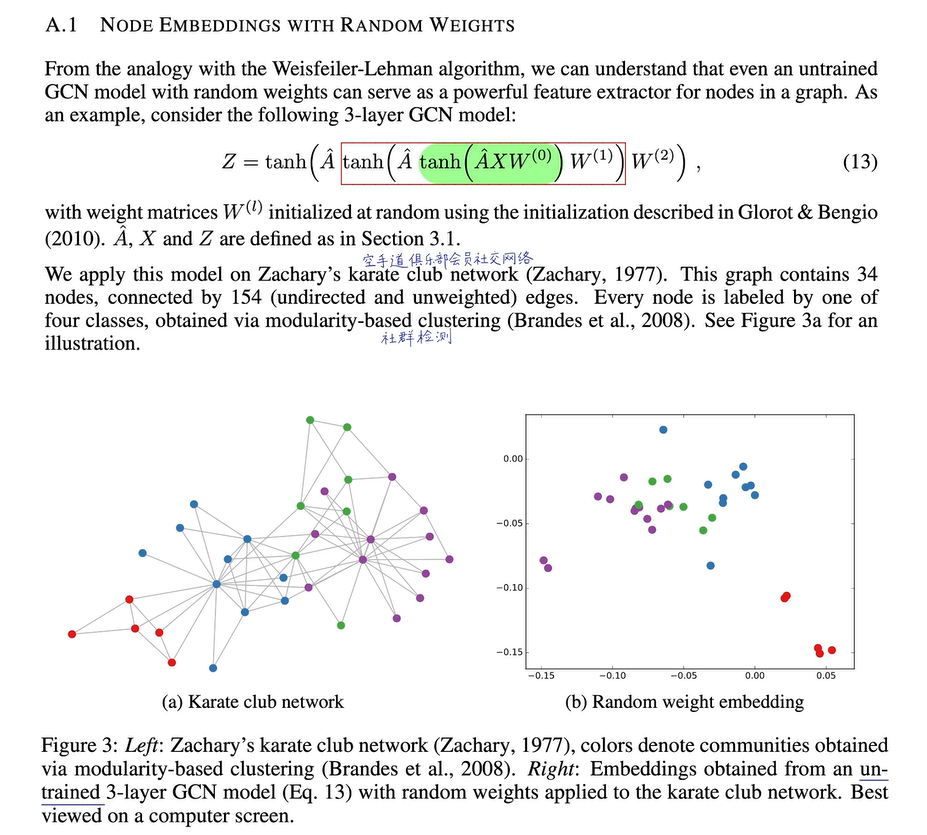
在GCN的原始论文中还提到了一个细节(上图),它搭建了一个三层的GCN网络,绿色是第一层,红框是第二层,整个是第三层。它把一个没有训练过、权重完全随机初始化的网络用在了空手道俱乐部的图上,将节点及其计算图直接输入到未经训练的随机初始化神经网络中,查看每个节点的嵌入向量在降维到二维后的表现。你会发现效果非常好,尽管神经网络尚未训练,但它已能将这四个节点区分开,这证明了其表示能力、拟合能力或区分能力非常强。关于图神经网络的表达能力,这也是我们后续将专门讲解的内容。一个未经训练的神经网络就已有如此高的表示能力,其潜力自然是巨大的,就像一位六岁的围棋神童,有些人即使一辈子学围棋,穷尽棋谱,也可能下不过那位六岁的围棋神童。有些事情的上限在很早就已确定。图神经网络的前途无量,就像那位六岁的围棋神童一样。
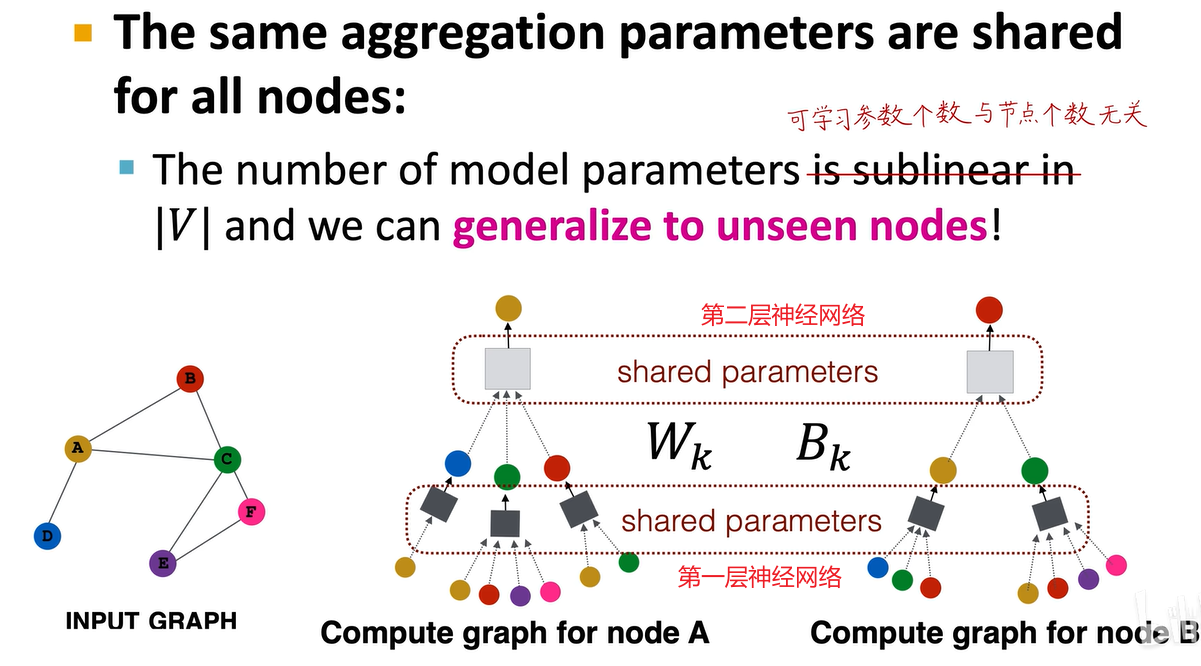
而且,图神经网络的所有计算图都共享神经网络结构,参数也是共享的。我们讲了这么多,图神经网络最终只需要训练两个神经网络:黑色和白色。两层图卷积神经网络,只需要训练这两个神经网络。因此,其可学习参数的数量与节点数量无关。无论是输入全中国14亿人的社交网络,还是全世界60亿人的社交网络,都只需要训练这两个神经网络。其可学习参数是固定的,易于训练,并且具有泛化能力。我们可以手动修改每个神经网络的结构,只要满足其输入和输出的维度一致即可。这并不难训练。
所以,回到我们之前课程讲的这张图,神经网络既是图嵌入,又是表示学习,使用了属性特征和节点标注;既可以用于直推式学习,也可以用于归纳式学习。因此,它是一个万金油方法,优于我们之前讲的所有半监督节点分类方法。
总结一下神经网络的优点:
第一是深度学习和神经网络本身的拟合学习能力非常强,因此通过它表示学习得到的节点嵌入向量质量非常高。
第二就是它站在深度学习的肩膀上,在深度学习领域,特别是自然语言处理或计算机视觉领域,任何前沿进展都可以被直接应用到图神经网络领域。因此,在深度学习领域已经卷得如火如荼的各种成果,如sota、跑分、trick等,都可以在图神经网络中进行优化。
第三它是归纳式学习,可以泛化到新节点乃至新图。
第四是它参数量少,所有的计算图都共享卷积神经网络的权重。
第五它既利用了节点的属性特征,又利用了节点的标注类别,可以区分节点的结构、功能、角色,比如一个节点是桥接节点、中枢核心节点还是外围边缘节点,都可以区分出来。
第六它只需寥寥六层即可让全世界任何两个人之间相互影响,这是一个非常好的特性。

6.GNN与其他神经网络的区别
学到这里我们思考一下:图神经网络和其他神经网络有什么区别呢?比如与卷积神经网络CNN以及transformer有什么区别?
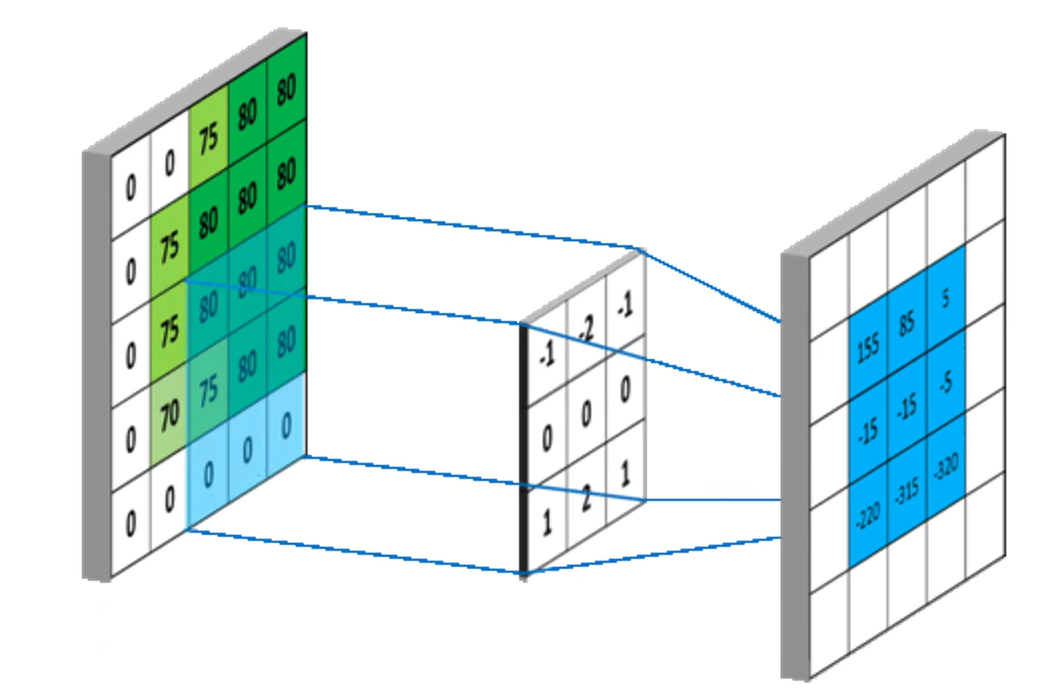
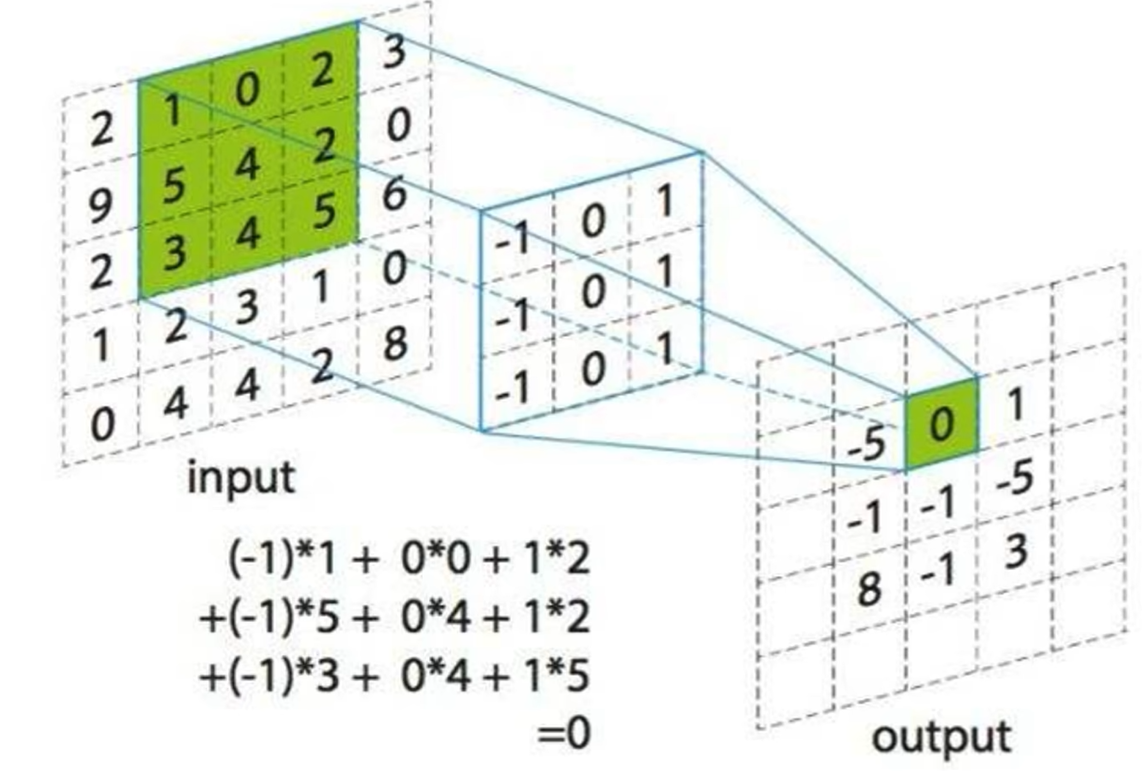
CNN我们知道,卷积神经网络使用卷积核在原图上滑动,将原图的像素和卷积核的权重对应位置相乘(两个矩阵求点积),结果填在右边的特征图上,这个卷积的过程大家很熟悉。
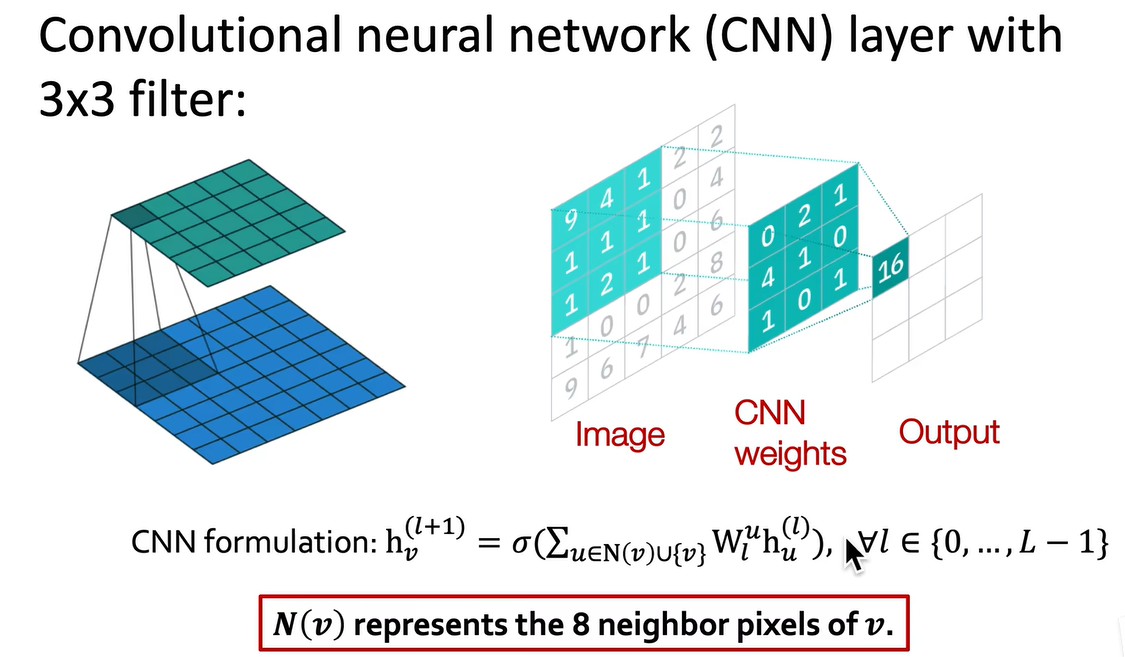
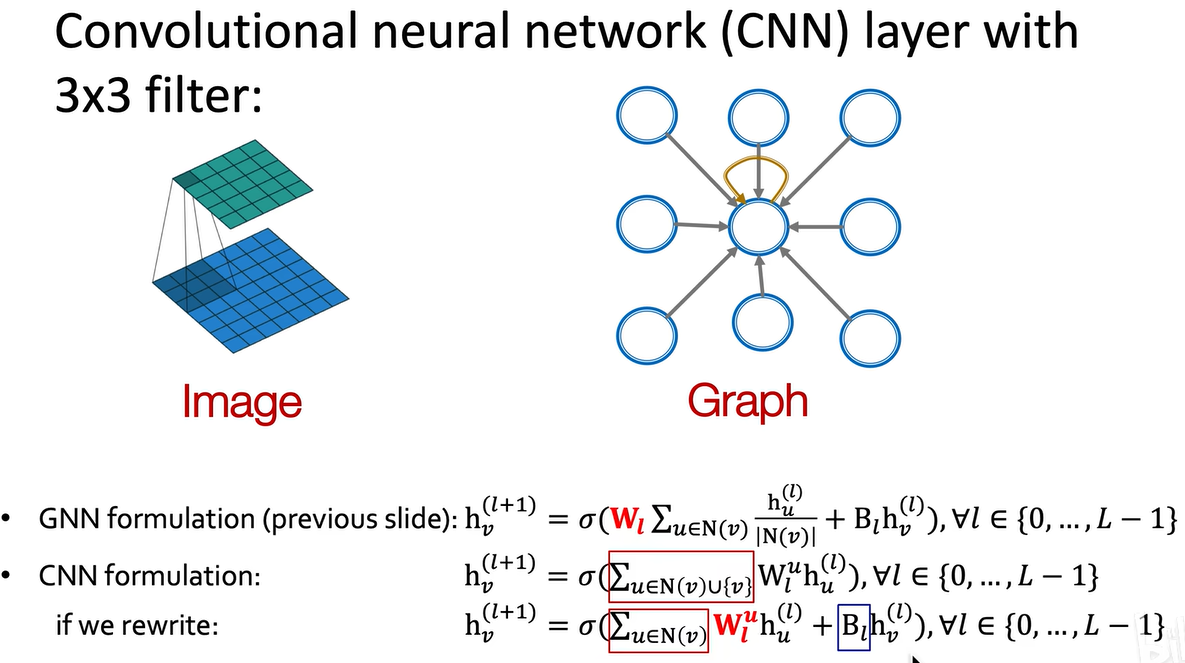
其实,卷积神经网络也可以被看作图神经网络,在数字图像处理中,一个像素周围有八个邻居,称为八领域。卷积神经网络对八领域的信息进行汇总,就是把八个邻居的节点分别乘以八个邻居对应位置的卷积核的权重,再加上自己的特征乘以自己的权重,就可以写成和图神经网络完全相同的形式。


在卷积神经网络中,不同位置的领域需要学习到不同的权重,但在图卷积网络中,卷积核的权重由normalized adjacency matrix预定义,不需要学习,而CNN的卷积核需要学习。CNN可以被看作固定邻域、固定顺序的特例,它不是置换不变性的,如果打乱像素或邻域顺序,而权重不打乱,输出结果会受影响,但在图卷积网络中无所谓,GNN具备顺序不变性。
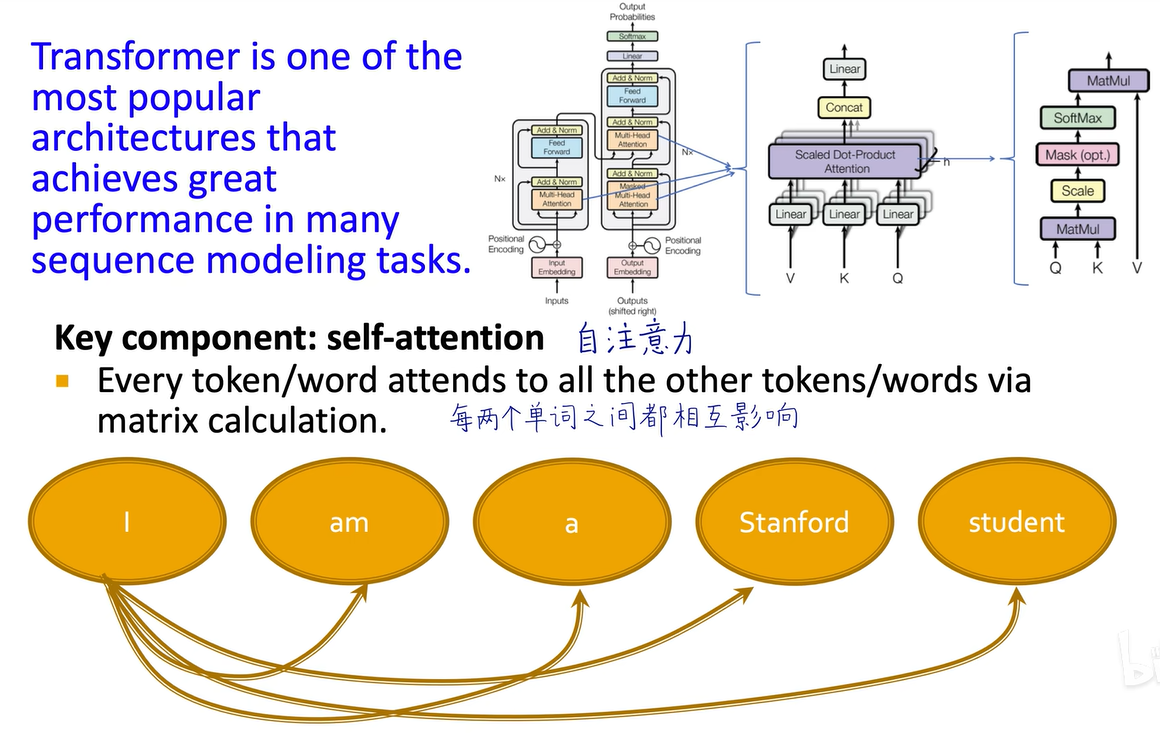
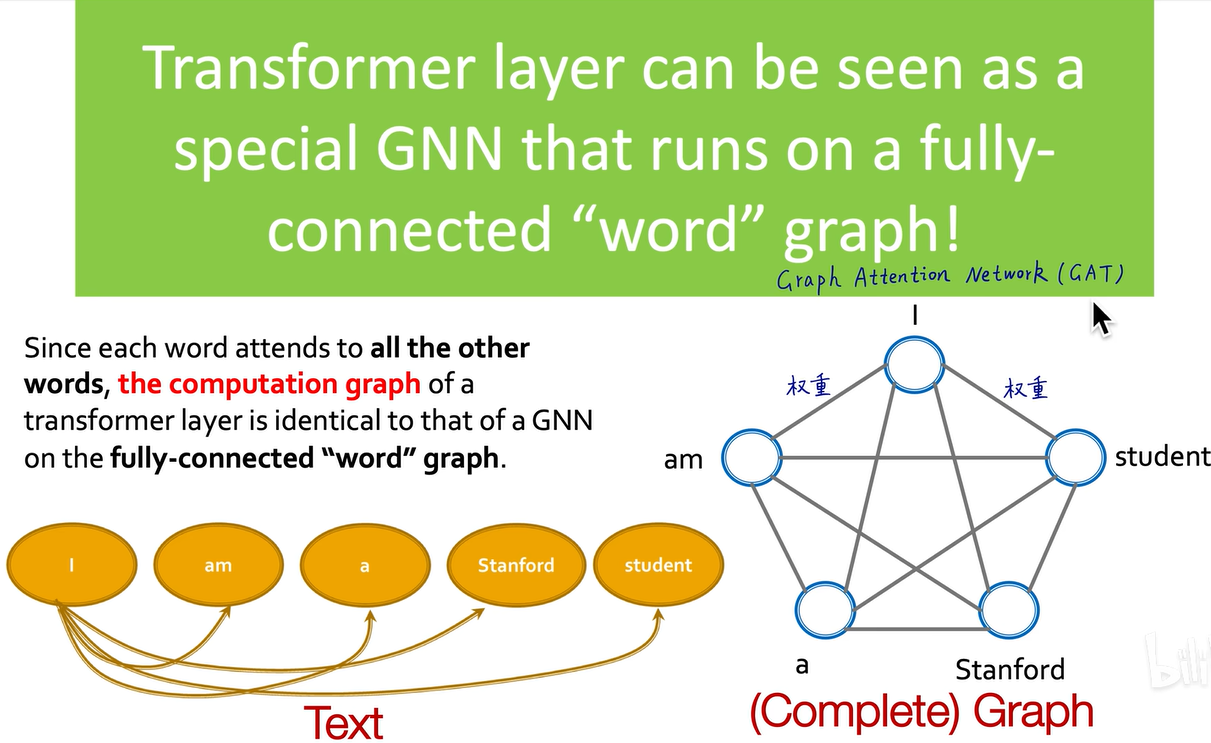
Transformer的本质是自注意力,使得一句话或一个序列中每两个单词之间都可以互相影响,每两个单词之间都可以有注意力权重。可以把它抽象成一个全连接的图,每两个单词之间、每两个节点之间都会有一个连接,所以transformer也可以被看作全连接词图上的一个图神经网络。这个权重本身也是可以学习的,我们在后面会看graph attention network,但在图卷积网络中是由normalized adjacency matrix定义的。
总结一下:
我们讲了图卷积神经网络GCN,它是一个麻雀虽小、五脏俱全的图神经网络,很多时候我们讲图神经网络GNN讲的就是图卷积神经网络GCN。
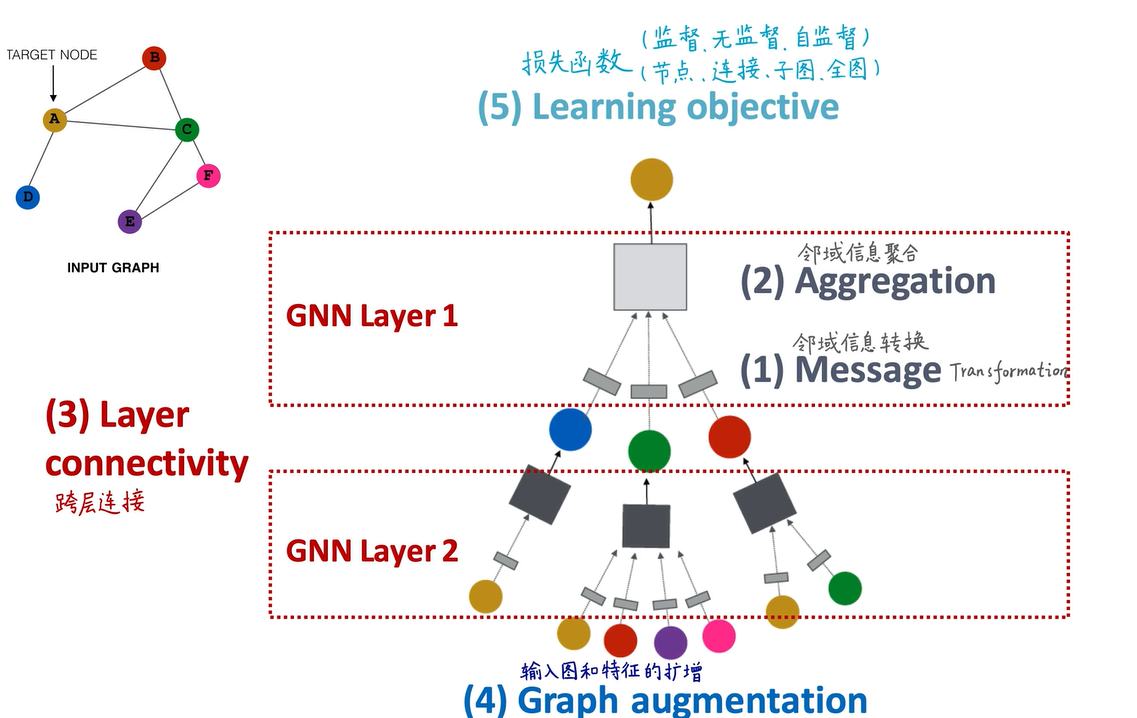
首先我们讲了它的计算图、聚合函数就是求平均,还有它的数学形式及如何求解。下一讲我们会看另外两种图神经网络GraphSAGE和GAT,最终归纳出GNN的一个通用框架。在GNN领域有很多技巧可以自己去探索,比如信息可以先进行message transformation消息传递,然后再进行aggregation聚合。在GCN里聚合用求平均的函数,也可以换成其他函数。
第三点,层和层之间在GCN里没有任何联系、没有信息交流,但我们可以像ResNet一样,加入一些跨层的连接,让这些底层节点,即离我远的、不能再远的节点,对我的近邻也产生一些联系、产生一些影响。
第四点,我输入的图未必就是计算图,计算图是如何求出的呢?不一定要根据输入的原始图去确定,可以对结构和属性特征进行扩增,或者进行一些特征工程,或者进行一些采样,不一定需要这三个节点,可能只要蓝色节点和绿色节点,可以进行一些采样,
接着是构建损失函数。分别针对监督学习、无监督学习、自监督学习,针对节点、连接子图、全图层面的问题,构造不同的损失函数。
这节课信息量非常大,希望大家下去认真复习,多看几遍。GCN的核心,除了那张图之外,还有mean aggregation,并且它可以表示成矩阵的形式,即normalized diffusion matrix,这块是我们今天讲的最重要的内容,希望大家下去好好复盘、好好吸收。
附录内容


鲁迅先生说“无穷的远方,无数的人们都和我有关”,完美诠释了图神经网络这一特点。
天雨虽宽,不润无根之草;佛法无边,只度有缘之人。
参考链接:
https://github.com/TommyZihao/zihao_course/tree/main/CS224W
GCN论文:Semi-Supervised Classification with Graph Convolutional Networks, ICLR 2017
关键词: Machine Learning, Deep Learning, Neural Networks, Graph Neural Networks, GNN, Graph Convolutional Neural Networks, GCN, Knowledge Graph

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)