一文了解强化学习
分布式系统可以让机械臂尝试抓取不同的物体,盘子里面物体的形状是不同的,这样就可以让机械臂学到一个统一的动作,然后针对不同的抓取物都可以使用最优的抓取算法。不同的环境中,奖励也是不同的。环境有自己的函数来更新状态,在智能体的内部也有一个函数来更新状态。当智能体的状态与环境的状态等价的时候,即当智能体能够观察到环境的所有状态时,我们称这个环境是完全可观测的(fully observed)。但是有一种情
强化学习基础
强化学习概述
强化学习,英文名为reinforcement learning,简称RL,其想要解决的问题是智能体(agent)如何在复杂环境(environment)下最大化其能获得的奖励。
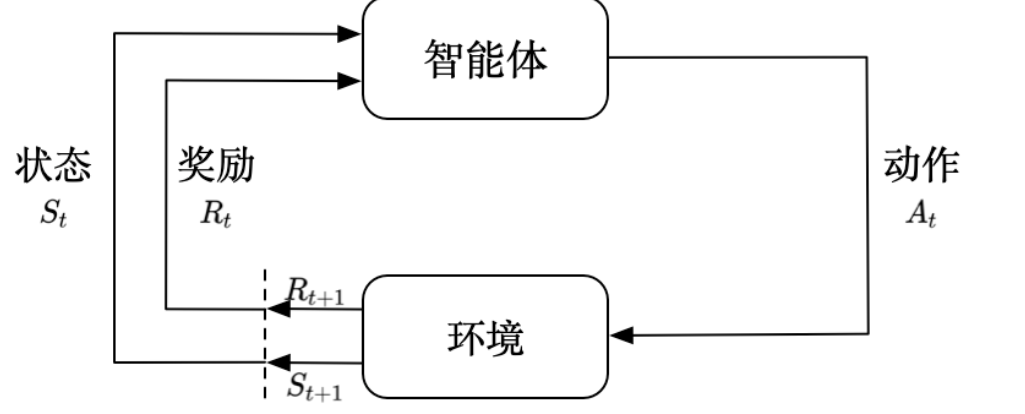
一般来说,强化学习分成两个主要部分:智能体和环境,在整个强化学习过程中,智能体会与环境交互。当智能体从环境获得某个状态后,其会利用该状态输出一个动作(action),这个动作将会在环境中被执行,而环境则会根据智能体采取的动作输出下一个状态以及对当前的动作进行评分。
智能体的目的就是尽可能的从环境中获得奖励。
强化学习的一些具体应用
其实强化学习已经在机器人应用中有了非常多的体现,尤其是我们拥有更多算力之后,可以做更多次的训练,每次训练中,智能体都从环境中获得很多信息并在环境中取得更多的奖励。
常见的例如:
机械臂抓取
把强化学习应用到机械臂自动抓取需要大量的预演,所以我们可以使用多个机械臂进行训练。分布式系统可以让机械臂尝试抓取不同的物体,盘子里面物体的形状是不同的,这样就可以让机械臂学到一个统一的动作,然后针对不同的抓取物都可以使用最优的抓取算法。因为抓取的物 体形状的差别很大,所以使用一些传统的抓取算法不能把所有物体都抓起来。传统的抓取算法对每一个物体都需要建模,这样是非常费时的。但通过强化学习,我们可以学到一个统一的抓取算法,其适用于不同的物体。
机械臂翻魔方
OpenAI 在 2018 年的时候设计了一款带有“手指”的机械臂,它可以通过翻动手指使得手中的木块达到预期的设定。人的手指其实非常灵活,怎么使得机械臂的手指也具有这 样灵活的能力一直是个问题。OpenAI 先在一个虚拟环境里面使用强化学习对智能体进行训练,再把它应 用到真实的机械臂上。这在强化学习里面是一种比较常用的做法,即我们先在虚拟环境里面得到一个很好 的智能体,然后把它应用到真实的机器人中。这是因为真实的机械臂通常非常容易坏,而且非常贵,一般情况下没办法大批量地购买。

序列决策
强化学习研究的问题是智能体与环境交互的问题。
奖励
奖励是由环境给的一种标量的反馈信号(scalar feedback signal),这种信号可显示智能体在某一步采取某个策略的表现如何。强化学习的目的就是最大化智能体可以获得的奖励,智能体在环境里面存在的目的就是最大化它的期望的累积奖励(expected cumulative reward)。不同的环境中,奖励也是不同的。这里给大家举一些奖励的例子。
(1)比如一个象棋选手,他的目的是赢棋,在最后棋局结束的时候,他就会得到一个正奖励(赢)或者负奖励(输)。
(2)在股票管理里面,奖励由股票获取的奖励与损失决定。
序列决策
在一个强化学习环境里面,智能体的目的就是选取一系列的动作来最大化奖励,所以这些选取的动作必须有长期的影响。但在这个过程里面,智能体的奖励其实是被延迟了的,就是我们现在选取的某一步动作,可能要等到很久后才知道这一步到底产生了什么样的影响。好比下象棋的过程中,只有一盘下完了我们才知道这盘棋的输赢。
强化学习里面一个重要的课题就是近期奖励和远期奖励的权衡 (trade-off),研究怎么让智能体取得更多的远期奖励。
在与环境的交互过程中,智能体会获得很多观测。针对每一个观测,智能体会采取一个动作,也会得到一个奖励。所以历史是观测、动作、奖励的序列:
Ht=o1,a1,r1,…,ot,at,rt
智能体在采取当前动作的时候会依赖于它之前得到的历史,所以我们可以把整个游戏的状态看成关于这个历史的函数:
St=f(Ht)
状态和观测有什么关系?
状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。在深度强化学习中,我们几乎总是用实值的向量、矩阵或者更高阶的张量来表示状态和观测。例如, 我们可以用 RGB 像素值的矩阵来表示一个视觉的观测,可以用机器人关节的角度和速度来表示一个机器人的状态。
环境有自己的函数来更新状态,在智能体的内部也有一个函数来更新状态。当智能体的状态与环境的状态等价的时候,即当智能体能够观察到环境的所有状态时,我们称这个环境是完全可观测的(fully observed)。在这种情况下面,强化学习通常被建模成一个马尔可夫决策过程 (Markov decision process,MDP)的问题。
但是有一种情况是智能体得到的观测并不能包含环境运作的所有状态,因为在强化学习的设定里面, 环境的状态才是真正的所有状态。比如智能体在玩 black jack 游戏,它能看到的其实是牌面上的牌。
我们并没有得到游戏内部里面所有的运作状态。也就是当智能体只能看到部分的观测,我们就称这个环境是部分可观测的(partially observed)。 在这种情况下,强化学习通常被建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)的问题。部分可观测马尔可夫决策过程是马尔可夫决策过程的一种泛化。 部分可观测马尔可夫决策过程依然具有马尔可夫性质,但是假设智能体无法感知环境的状态,只能知道部分观测值。
点击古月居 - ROS机器人知识分享社区可查看全文。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)