计算机毕业设计Springboot基于Hadoop的租房数据分析系统 基于Spring Boot与Hadoop的房屋租赁数据智能分析平台 Spring Boot驱动的Hadoop租房数据洞察系统
该系统通过数据采集、分析、可视化和用户推荐等功能,全面覆盖了租房市场的核心需求。它不仅为租户提供了便捷的房源查找和决策支持,也为房东和租赁机构提供了市场洞察和运营管理工具。通过数据安全与隐私保护措施,系统确保了用户信息的安全。此外,多用户支持和系统管理功能进一步提升了系统的实用性和稳定性,使其成为租房市场中一个高效、智能的数据分析平台。注:完成的毕业设计程序以下面的的环境软件、功能图和界面为准。
计算机毕业设计Springboot基于Hadoop的租房数据分析系统yj48wak5
(配套有源码 程序 mysql数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联xi 可分享
随着城市化进程的加速,租房市场日益庞大且复杂。海量的租房数据分散在各个平台,缺乏有效的整合与分析,这不仅给租户寻找合适房源带来困难,也给房东和租赁机构的决策支持带来挑战。为了更好地挖掘租房数据中的价值,提升租房市场的透明度和效率,我们提出了一个基于Spring Boot和Hadoop的租房数据分析系统。该系统旨在通过强大的数据处理能力和智能分析算法,为用户提供全面、精准的租房数据洞察。
系统功能
-
数据采集与整合:从多个租房平台实时采集数据,包括房源信息、租金价格、房屋位置、配套设施等,并进行清洗和标准化处理,确保数据的准确性和一致性。
-
数据分析与可视化:提供多维度的数据分析功能,如租金趋势分析、区域热度分析、户型偏好分析等。通过直观的图表和地图展示,帮助用户快速了解租房市场的动态。
-
用户画像与推荐:根据用户的历史行为和偏好,构建用户画像,并为其推荐符合需求的房源,提升用户体验。
-
数据安全与隐私保护:采用先进的加密技术,确保用户数据的安全性和隐私性,防止数据泄露。
-
系统管理与维护:提供系统管理功能,包括用户管理、数据备份与恢复、系统监控等,确保系统的稳定运行。
-
多用户支持:支持房东、租户和租赁机构等多角色使用,满足不同用户的需求。
系统核心内容
本系统基于Spring Boot框架构建,结合Hadoop生态系统中的HDFS、MapReduce和Hive等组件,实现对海量租房数据的高效存储、处理和分析。通过Spring Boot的强大功能,系统具备良好的可扩展性和易维护性。同时,借助Hadoop的分布式计算能力,能够快速处理大规模数据,为用户提供实时、准确的分析结果。
功能总结
该系统通过数据采集、分析、可视化和用户推荐等功能,全面覆盖了租房市场的核心需求。它不仅为租户提供了便捷的房源查找和决策支持,也为房东和租赁机构提供了市场洞察和运营管理工具。通过数据安全与隐私保护措施,系统确保了用户信息的安全。此外,多用户支持和系统管理功能进一步提升了系统的实用性和稳定性,使其成为租房市场中一个高效、智能的数据分析平台。
注:完成的毕业设计程序以下面的的环境软件、功能图和界面为准。
系统所需要的环境软件:idea、eclipse+mysql5.7、8.0+Navicat+JDK1.8+tomcat7.0
3.4系统用例分析
在设计系统的过程中,用例图是系统设计过程中必不可少的模型,用例图可以更为细致的,结合系统中人员的有关分配,能够从细节上描绘出系统中有关功能所完成的具体事件,确切的反映出某个操作以及它们相互之间的内部联系。
其中参与者就是和系统能够发生交互的外在实体,一般可以指系统的某个用户。一个用例图就能对应出系统中的一个功能过程,系统中完整的功能都是由许多不同的用例图所组成的。
系统用例图如图3-1、图3-2所示。
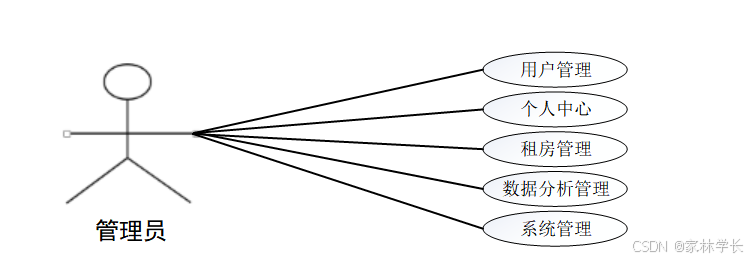
图3-1 管理员用例图
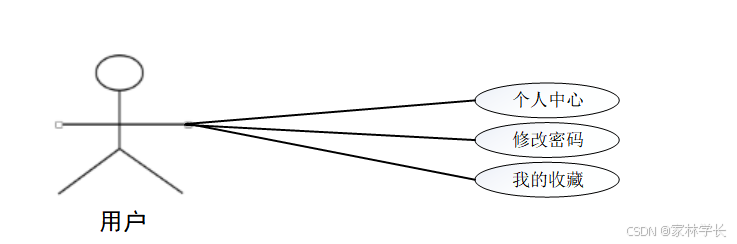
图3-2 用户用例图
3.5 系统流程图
流程图就是用它已经特定的图形符号以及相应的线条,用来展现出系统在执行中的整个的过程。由于这种图形能够很方便的描绘系统的一系列流程,所以它的所有的图形符号是比较关键的,基本都是一个图形符号就能表示某个过程的一个单独的步骤。流程图不只是提供出比较完整、全面的执行过程,而且在整个团队的协作设计过程中,还可以发现其中有可能存在的缺陷以及不足,便于在后续的过程中能够及时的纠正和完善系统。
登录流程图和添加信息流程图分别如图3-3、图3-4所示。
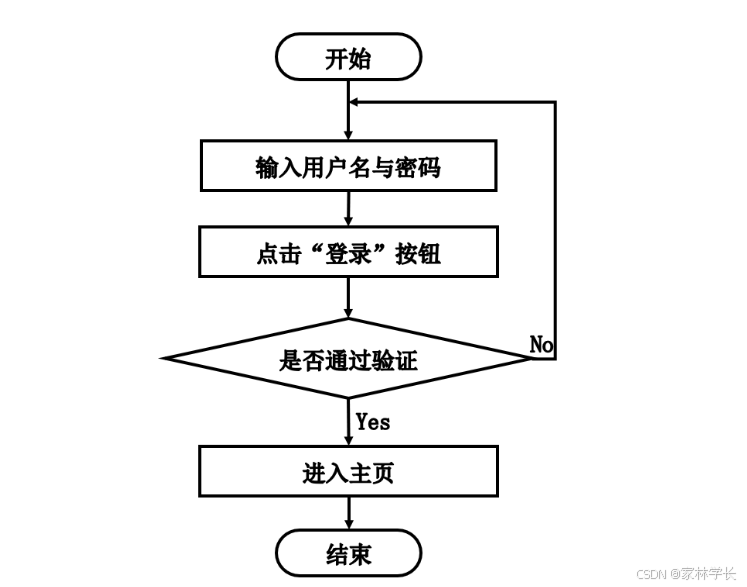
图3-3 登录流程图
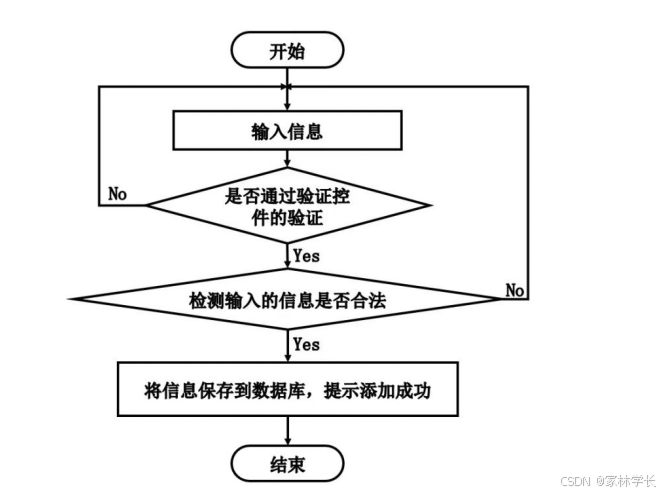
图3-4 添加信息流程图
4 系统设计
4.1系统功能结构设计图
系统的功能结构图如图4-1所示。
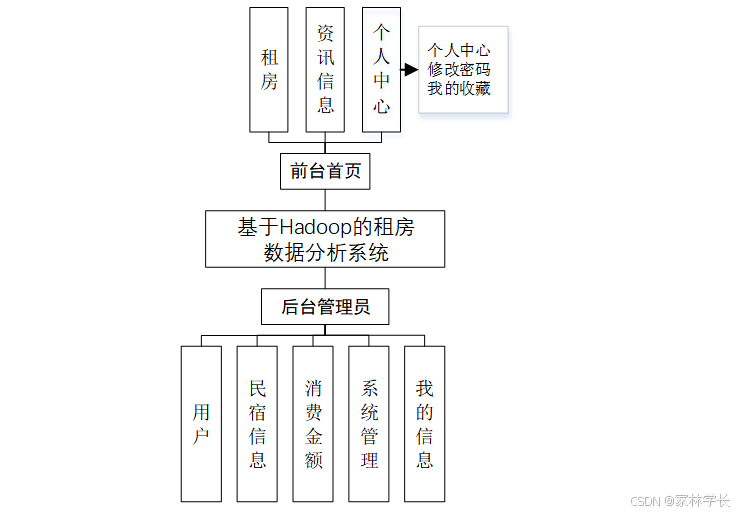
图 4-1系统功能结构图
4.2数据库设计
4.2.1数据库设计原则
学习程序设计,如果要了解数据库管理系统或者是根据需求而制定的系统接口,就必须创建一种数据库管理系统的模式,用来保存数据资料,这样当在应用编程过程中时候,就不需要再向操作系统页面上加载信息,进而增加了整个系统的工作效率。信息库管理系统中保存着许多数据,应该说是一个管理信息系统建设的中心和基础,而信息库管理系统也为管理信息系统建设提出了新增、删除、更改和搜索的操作功能,使管理信息系统建设能够迅速地查询所需要的数据,而不会直接从程序代码中查找。信息库管理系统通过将信息表的各个组成部分按照特定的方法准确地合并,排序和组成信息库管理系统。
通过对租房数据分析系统的主要功能信息进行规划并分为若干功能实体信息,实体信息将使用E-R图加以表示,本系统的几个主要功能“用户、看板、租房、管理员”实体图如图4-2所示。
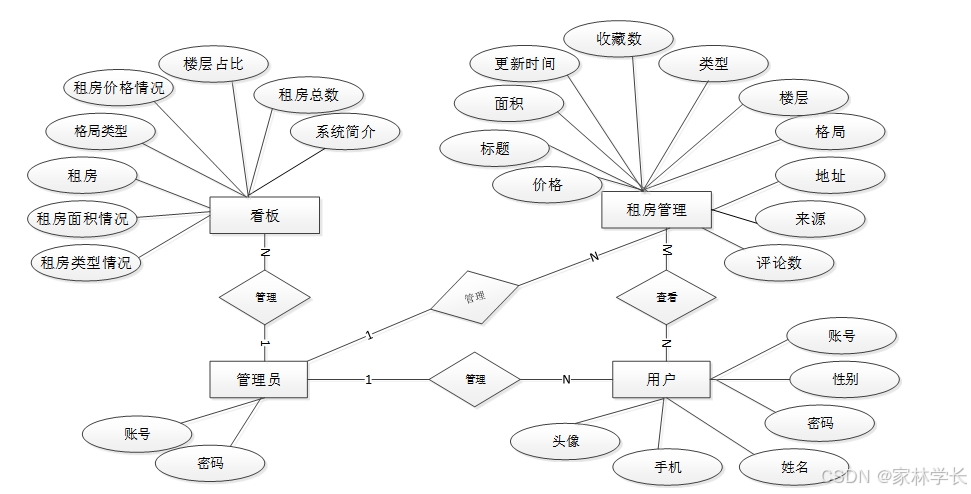
图4-2局部E-R图
5.1系统功能实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到租房数据分析系统的导航条和首页推荐信息等。系统首页界面如图5-1所示:
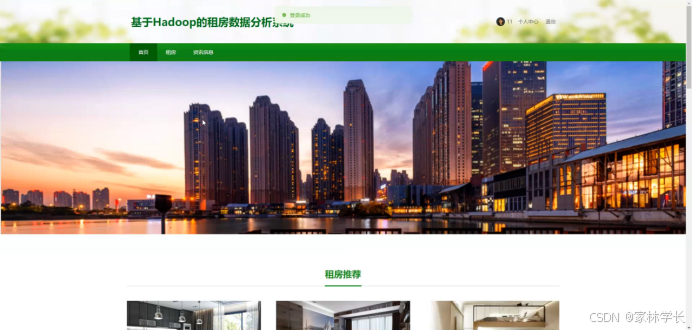
图5-1 系统首页界面
系统注册:在注册流程中,用户在Vue前端填写必要信息(如用户名、密码等)并提交。前端将这些信息通过HTTP请求发送到Java后端。后端处理这些信息,检查用户名是否唯一,并将新用户数据存入MySQL数据库。完成后,后端向前端发送注册成功的确认,前端随后通知用户完成注册。这个过程实现了新用户的数据收集、验证和存储。系统注册页面如图5-2所示:
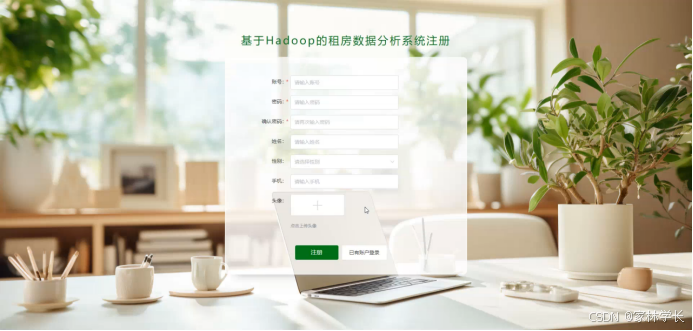
图5-2系统注册页面
租房:点击租房页面的输入栏输入标题、类型、格局进行查询,可以看到租房详情,并根据需要进行评论或收藏操作;租房页面如图5-3所示:

图5-3租房详细页面
资讯信息:在资讯信息页面的输入栏中输入标题进行搜索,可以查看到资讯信息详细信息,并根据需要进行点赞或收藏操作;资讯信息页面如图5-4所示:

图5-4资讯信息详细页面
个人中心:在个人中心页面可以对进行详细操作;个人中心页面如图5-5所示:
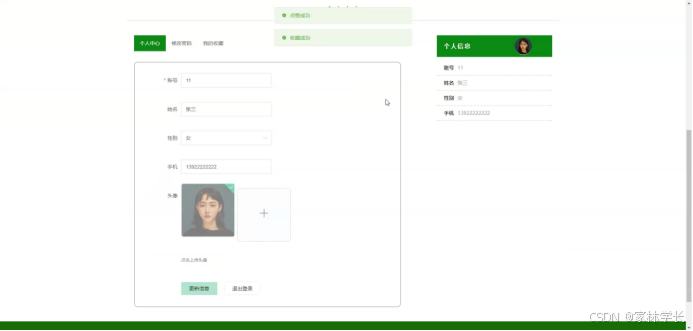
图5-5个人中心页面
5.2管理员模块实现
在登录流程中,用户首先在Vue前端界面输入用户名和密码。这些信息通过HTTP请求发送到Java后端。后端接收请求,通过与MySQL数据库交互验证用户凭证。如果认证成功,后端会返回给前端,允许用户访问系统。这个过程涵盖了从用户输入到系统验证和响应的全过程。如图5-6所示。
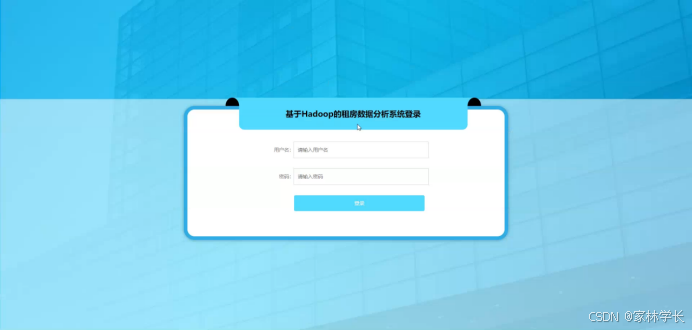
图5-6 后台登录界面
管理员进入主页面,主要功能包括对个人中心、用户管理、租房管理、数据分析管理、系统管理等进行操作。管理员主页面如图5-7所示:
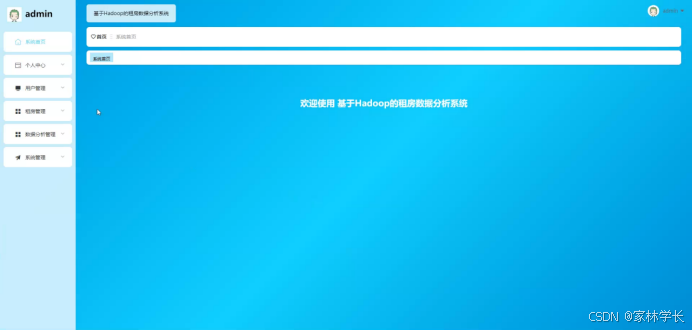
图5-7 管理员主界面
用户管理功能在视图层(view层)进行交互,比如点击“查询、添加或删除”按钮或填写用户管理信息表单。这些用户管理信息动作被视图层捕获并作为请求发送给相应的控制器层(controller层)。控制器接收到这些请求后,调用服务层(service层)以执行相关的业务逻辑,例如验证输入数据的有效性和与数据库的交互。服务层处理完这些逻辑后,进一步与数据访问对象层(DAO层)交互,后者负责具体的数据操作如查看、修改或删除用户管理信息,并将操作结果返回给控制器。最终,控制器根据这些结果更新视图层,以便用户管理功能可以看到最新的信息或相应的操作反馈。如图5-8所示:
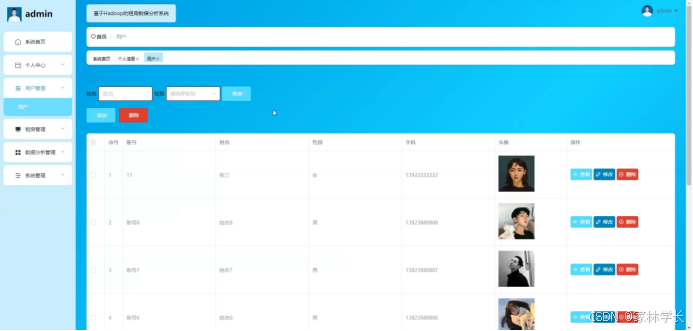
图5-8用户管理界面
租房管理功能在视图层(view层)进行交互,比如点击“查询、添加、爬取数据或删除”按钮或填写租房管理信息表单。这些租房管理信息动作被视图层捕获并作为请求发送给相应的控制器层(controller层)。控制器接收到这些请求后,调用服务层(service层)以执行相关的业务逻辑,例如验证输入数据的有效性和与数据库的交互。服务层处理完这些逻辑后,进一步与数据访问对象层(DAO层)交互,后者负责具体的数据操作如查看、修改、查看评论或删除租房管理信息,并将操作结果返回给控制器。最终,控制器根据这些结果更新视图层,以便租房管理功能可以看到最新的信息或相应的操作反馈。如图5-9所示:
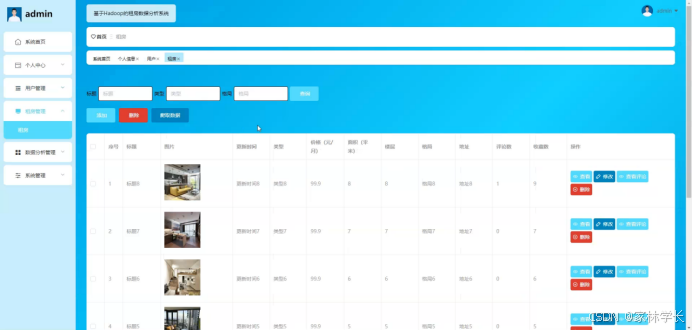
图5-9租房管理界面
数据分析管理;在数据分析管理页面输入标题、分析类型进行查询、添加或删除数据分析管理列表,并对数据分析管理详细信息进行查看、修改或删除操作;如图5-10所示:
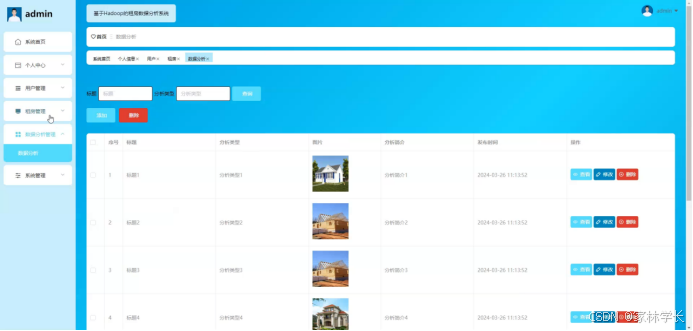
图5-10数据分析管理界面
系统管理;在系统管理的咨询信息页面输入进行查询、添加或删除系统管理列表,并对资讯详细信息进行查看、修改或删除操作;如图5-11所示:
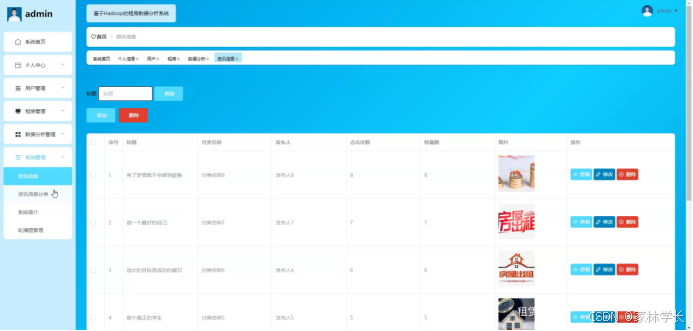
图5-11系统管理界面
管理员进行爬取数据后可以在看板页面查看到系统简介、租房、租房总数、租房类型情况、楼层占比、租房价格情况、格局类型、租房面积情况等实时的分析图进行可视化管理;看板大屏选择了Echart作为数据可视化工具,它是一个使用JavaScript实现的开源可视化库,能够无缝集成到Java Web应用中。Echart的强大之处在于其丰富的图表类型和高度的定制化能力,使得管理人员可以通过直观的图表清晰地把握租房的各项运营数据。
为了实现对租房信息的自动化收集和更新,我们采用了Apache Spark作为爬虫技术的基础。Spark的分布式计算能力使得系统能够高效地处理大规模数据,无论是从互联网上抓取最新的租房信息,还是对内部数据进行ETL(提取、转换、加载)操作,都能够保证数据的实时性和准确性。
在大数据分析方面,系统采用了Hadoop框架。Hadoop是一个能够处理大数据集的分布式存储和计算平台,它的核心是HDFS(Hadoop Distributed File System)和MapReduce计算模型。通过Hadoop,我们可以对收集到的大量数据进行存储和分析。如图5-12所示:
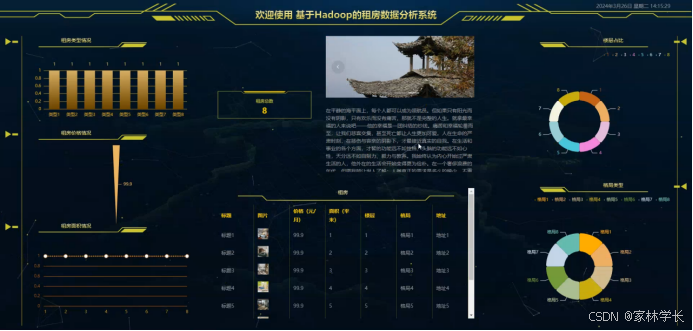
图5-12用户界面
源码无偿分享,文未领取

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 60
60 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)