行人重识别(Deep-Person-ReID)环境搭建与实战教程:从环境配置到模型训练测试
本文详细介绍了基于PyTorch的行人重识别(ReID)系统搭建全流程。主要内容包括:1)使用conda创建Python3.10虚拟环境并安装PyTorch和deep-person-reid库;2)准备Market-1501等常用数据集;3)配置模型训练参数,包括网络结构选择、数据增强、损失函数等;4)执行训练和测试流程;5)结果评估指标解读(mAP、Rank-k等);6)常见问题解决方案。文章提
一、行人重识别技术简介

行人重识别(Person Re-identification,ReID)是计算机视觉领域的重要研究方向,旨在跨摄像头、跨场景下识别同一行人。随着深度学习技术的发展,基于深度学习的ReID方法在各种公开数据集上取得了显著成果。
本文将详细介绍如何使用 deep-person-reid(一个基于PyTorch的ReID开源库)搭建完整的行人重识别开发环境,并进行模型训练与测试的全流程。
相关资料链接:
二、环境搭建(Ubuntu 20.04 + Python 3.10)
2.1 基础环境准备
# 更新系统包
sudo apt update
sudo apt upgrade -y
# 安装必要的系统依赖
sudo apt install -y python3-pip python3-dev
sudo apt install -y libgl1-mesa-glx libglib2.0-0 libsm6 libxrender1 libxext6
sudo apt install -y git wget unzip2.2 创建虚拟环境(使用conda)
# 安装Anaconda(如果尚未安装)
# 官网下载Anaconda3的linux安装包,版本根据自己的需求定
bash Anaconda3-2024.06-1-Linux-x86_64.sh
# 按照提示安装,然后重启终端或执行 source ~/.bashrc
# 创建并激活虚拟环境
conda create -n reid python=3.10 -y
conda activate reid2.3 安装PyTorch及相关依赖
# 根据CUDA版本安装PyTorch(此处以CUDA 12.4为例)
# 查看CUDA版本:nvidia-smi
conda install pytorch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 pytorch-cuda=12.4 -c pytorch -c nvidia
# 或者使用pip安装
# pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu1242.4 安装deep-person-reid
# 克隆deep-person-reid仓库
git clone https://github.com/KaiyangZhou/deep-person-reid.git
cd deep-person-reid
# 安装requirements
pip install -r requirements.txt
# 安装torchreid包(开发模式)
# 避免依赖检查 --no-build-isolation
pip install -e . --no-build-isolation
# 验证安装
python -c "import torchreid; print(torchreid.__version__)"
# 输出torchreid版本号即为成功2.5 安装其他必要依赖
# 安装常用数据处理库
pip install pandas scikit-learn matplotlib seaborn
pip install opencv-python pillow tqdm
pip install tensorboard # 用于可视化训练过程
# 安装Jupyter Notebook(可选)
pip install jupyter notebook三、数据集准备与预处理
3.1 常用ReID数据集下载
# 创建数据集目录
mkdir reid_datasets
cd reid_datasets
# Market-1501数据集
wget http://188.138.127.15:81/Datasets/Market-1501-v15.09.15.zip
unzip Market-1501-v15.09.15.zip
mkdir market1501
mv Market-1501-v15.09.15/* market1501/
# DukeMTMC-reID数据集(需要申请,此处示例结构)
# 下载后组织为以下结构:
# duke/
# ├── bounding_box_train/
# ├── bounding_box_test/
# ├── query/
# └── README.txt
# MSMT17数据集
# 下载链接:http://www.pkuvmc.com/publications/msmt17.html官网下载Market-1501数据集非常慢甚至打不开网页,可以直接下载我上传的Market-1501数据集数据
3.2 数据集结构验证
Market-1501数据集结构示例:
market1501/
├── bounding_box_train/ # 训练集,751人,12936张图像
├── bounding_box_test/ # 测试集,750人,19732张图像
├── query/ # 查询集,750人,3368张图像
└── gt_bbox/ # 手工标注框(可选)3.3 数据集路径配置
# 在代码中设置数据集路径
import os
dataset_dir = '/home/yourname/reid_datasets'
# 以下数据集任选其一
market1501_path = os.path.join(dataset_dir, 'market1501')
duke_path = os.path.join(dataset_dir, 'duke')
msmt17_path = os.path.join(dataset_dir, 'msmt17')3.4 构建自己的数据集(可选)
如果想利用自己通过摄像头采集的数据制作ReID数据请参考我的另一篇博客
四、模型训练完整流程
4.1 修改训练参数
在deep-person-reid/scripts/下有两个python文件
default_config.py 模型训练/测试参数配置;
main.py 模型启动训练/测试。
主要修改default_config.py中get_default_config()函数的相关参数来实现相关配置,下面详细解读一下相关配置参数。
# model - 模型配置
cfg.model = CN()
cfg.model.name = 'osnet_x1_0' # 模型名称,可选:'resnet50', 'resnet101', 'osnet_x1_0', 'mobilenetv2_x1_0', 'vit_base_patch16_224'等
cfg.model.pretrained = True # 是否使用ImageNet预训练权重,True自动下载,False随机初始化
cfg.model.load_weights = "/home/project/deep-person-reid/models/osnet_x1_0_imagenet.pth" # 手动指定预训练权重文件路径(.pth格式),优先级高于pretrained
cfg.model.resume = '' # 恢复训练检查点路径(包含模型、优化器、epoch等信息),用于断点续训
# data - 数据配置
cfg.data = CN()
cfg.data.type = 'image' # 数据类型:'image'图像ReID 或 'video'视频ReID
cfg.data.root = 'reid-data' # 数据集根目录路径,改为你的实际路径如:'/home/user/datasets'
cfg.data.sources = ['market1501'] # 训练数据集列表,支持多个:['market1501', 'duke', 'msmt17']
cfg.data.targets = ['market1501'] # 测试数据集列表,可与sources相同(同域)或不同(跨域)
cfg.data.workers = 8 # 数据加载线程数,建议4-8(根据CPU核心数)
cfg.data.split_id = 0 # 数据集划分ID,某些数据集(如CUHK03)有多个划分,通常用0
cfg.data.height = 256 # 输入图像高度,常用:256、384、512
cfg.data.width = 128 # 输入图像宽度,常用:128、192、256,保持高宽比≈2:1
cfg.data.combineall = False # 是否合并所有数据训练,True:训练集+查询集+画廊集;False:仅训练集
cfg.data.transforms = ['random_flip'] # 数据增强列表,可选:'random_flip','random_crop','color_jitter','random_erase'(可组合)
cfg.data.k_tfm = 1 # 增强重复次数,1:每图增强一次;>1:每图独立增强多次生成多视图
cfg.data.norm_mean = [0.485, 0.456, 0.406] # 图像归一化均值(ImageNet标准)
cfg.data.norm_std = [0.229, 0.224, 0.225] # 图像归一化标准差(ImageNet标准)
cfg.data.save_dir = 'log' # 训练日志和模型保存目录,建议改为具体路径如:'log/resnet50_market1501'
cfg.data.load_train_targets = False # 是否加载目标域训练数据,用于域适应(跨数据集)场景
# specific datasets - 数据集特定配置
cfg.market1501 = CN()
cfg.market1501.use_500k_distractors = False # Market1501:是否使用包含50万干扰项的扩展画廊集(难度更大)
cfg.cuhk03 = CN()
cfg.cuhk03.labeled_images = False # CUHK03:使用标注框(True)还是检测框(False),标注框更准,检测框更真实
cfg.cuhk03.classic_split = False # CUHK03:使用经典划分(767/700)还是新划分(1367/100)
cfg.cuhk03.use_metric_cuhk03 = False # CUHK03:使用原始评估指标(一对一)还是标准指标
# sampler - 采样器配置
cfg.sampler = CN()
cfg.sampler.train_sampler = 'RandomSampler' # 源域训练采样器:'RandomSampler'随机,'RandomIdentitySampler'按ID,'RandomDomainSampler'按相机
cfg.sampler.train_sampler_t = 'RandomSampler' # 目标域训练采样器(域适应场景)
cfg.sampler.num_instances = 4 # RandomIdentitySampler:每个ID采样的图像数,batch_size = num_ids × num_instances
cfg.sampler.num_cams = 1 # RandomDomainSampler:每批包含的相机数
cfg.sampler.num_datasets = 1 # RandomDatasetSampler:每批包含的数据集数
# video reid setting - 视频ReID配置
cfg.video = CN()
cfg.video.seq_len = 15 # 每个视频片段采样的帧数,典型值:4-32
cfg.video.sample_method = 'evenly' # 采样方法:'evenly'均匀,'random'随机,'dense'密集(测试用)
cfg.video.pooling_method = 'avg' # 多帧特征聚合方法:'avg'平均池化,'max'最大池化,'attention'注意力池化
# train - 训练配置
cfg.train = CN()
cfg.train.optim = 'adam' # 优化器:'adam'(推荐)、'sgd'、'amsgrad'、'adagrad'、'rmsprop'
cfg.train.lr = 0.0003 # 初始学习率,Adam典型值:0.0001-0.001,SGD:0.01-0.1
cfg.train.weight_decay = 5e-4 # 权重衰减(L2正则化),防止过拟合,范围:1e-4 ~ 5e-4
cfg.train.max_epoch = 60 # 最大训练轮数,根据数据集调整:小数据集60-80,大数据集40-60
cfg.train.start_epoch = 0 # 起始轮数,恢复训练时自动设置
cfg.train.batch_size = 128 # 训练批次大小,根据GPU显存调整:4GB→16,6GB→32,8GB→64,11GB→128
cfg.train.fixbase_epoch = 0 # 固定基础层的轮数,0:不固定;>0:前N轮只训练分类层
cfg.train.open_layers = ['classifier'] # 固定基础层时,可训练的层列表,通常为分类器
cfg.train.staged_lr = False # 是否使用分层学习率,True:不同层不同学习率;False:所有层相同
cfg.train.new_layers = ['classifier'] # staged_lr=True时,新添加的层(使用基础学习率)
cfg.train.base_lr_mult = 0.1 # staged_lr=True时,基础层学习率乘数,base_lr = lr × base_lr_mult
cfg.train.lr_scheduler = 'single_step' # 学习率调度器:'single_step'单步,'multi_step'多步,'cosine'余弦,'linear'线性
cfg.train.stepsize = [20] # 学习率下降的轮数,如:[20]在第20轮下降,[20,40]在第20和40轮下降
cfg.train.gamma = 0.1 # 学习率下降倍数,新学习率 = 旧学习率 × gamma
cfg.train.print_freq = 20 # 日志打印频率(每N个batch打印一次),建议:20-50
cfg.train.seed = 1 # 随机种子,确保实验可复现
# optimizer - 优化器详细参数
cfg.sgd = CN()
cfg.sgd.momentum = 0.9 # SGD动量参数,范围:0.0-1.0,典型值:0.9
cfg.sgd.dampening = 0. # SGD动量阻尼,通常为0
cfg.sgd.nesterov = False # 是否使用Nesterov动量,True:使用;False:不使用
cfg.rmsprop = CN()
cfg.rmsprop.alpha = 0.99 # RMSprop平滑常数
cfg.adam = CN()
cfg.adam.beta1 = 0.9 # Adam一阶矩估计指数衰减率,通常0.9
cfg.adam.beta2 = 0.999 # Adam二阶矩估计指数衰减率,通常0.999
# loss - 损失函数配置
cfg.loss = CN()
cfg.loss.name = 'softmax' # 损失函数类型:'softmax'交叉熵,'triplet'三元组,'softmax_triplet'混合损失
cfg.loss.softmax = CN()
cfg.loss.softmax.label_smooth = True # 是否使用标签平滑,True:防止过拟合;False:标准交叉熵
cfg.loss.triplet = CN()
cfg.loss.triplet.margin = 0.3 # Triplet损失边界值,典型值:0.3-1.0,值越大对困难样本惩罚越大
cfg.loss.triplet.weight_t = 1. # Triplet损失权重(多任务学习时调整)
cfg.loss.triplet.weight_x = 0. # 交叉熵损失权重(混合损失时使用),如:softmax_triplet需设为1.0
# test - 测试配置
cfg.test = CN()
cfg.test.batch_size = 100 # 测试批次大小,可设较大(不计算梯度)
cfg.test.dist_metric = 'euclidean' # 距离度量:'euclidean'欧氏距离,'cosine'余弦距离(推荐)
cfg.test.normalize_feature = False # 是否对特征向量L2归一化,True:提高余弦距离鲁棒性;False:原始特征
cfg.test.ranks = [1, 5, 10, 20] # CMC评估的rank值,Rank-k:前k个结果包含目标的概率
cfg.test.evaluate = False # 是否仅测试不训练,True:测试模式;False:训练+测试模式
cfg.test.eval_freq = -1 # 评估频率(每N个epoch评估一次),-1:仅训练后评估;10:每10轮评估
cfg.test.start_eval = 0 # 开始评估的轮数,0:从第0轮开始;20:前20轮不评估
cfg.test.rerank = True # 是否使用重排序技术,True:显著提高mAP但计算量大;False:不使用
cfg.test.visrank = True # 是否可视化排序结果,True:生成可视化图像;False:不生成
cfg.test.visrank_topk = 10 # 可视化结果展示的前K个,典型值:10-204.2 启动训练
cd scripts
python main.py脚本启动后会输出训练参数以及详细环境信息,然后开始训练
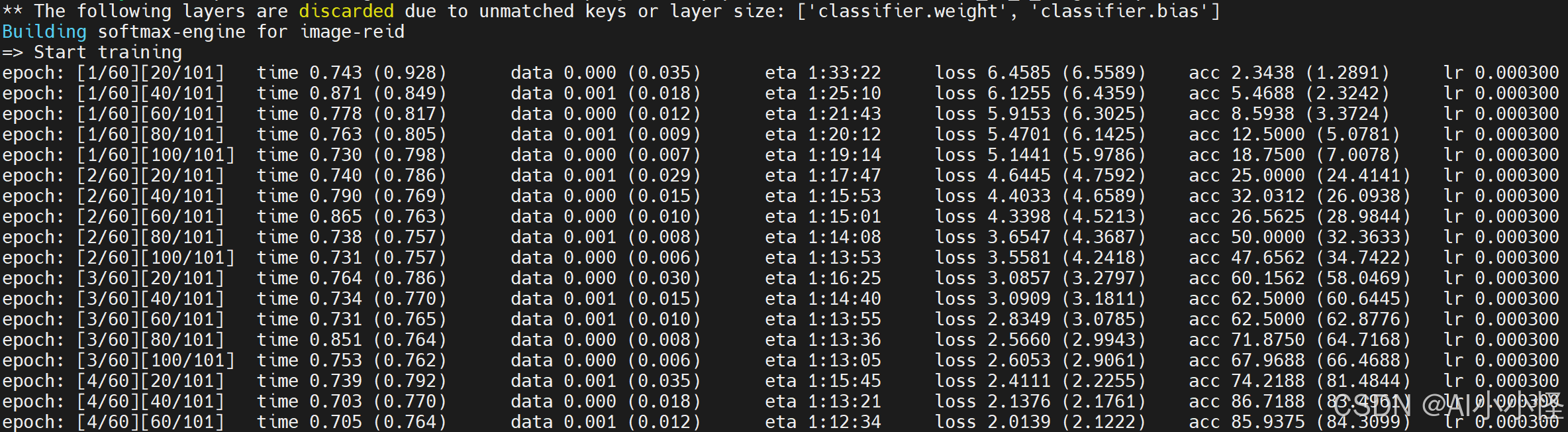
训练完成,权重自动保存
五、模型测试与评估
5.1 执行测试
修改default_config.py中get_default_config函数里的两处参数
cfg.model.load_weights = "/home/project/deep-person-reid/runs/osnet_x1_0_market1501/model/model.pth.tar-60"
cfg.test.evaluate = True # 启用测试模式
cfg.test.visrank = True # 启用可视化
运行测试
python main.py
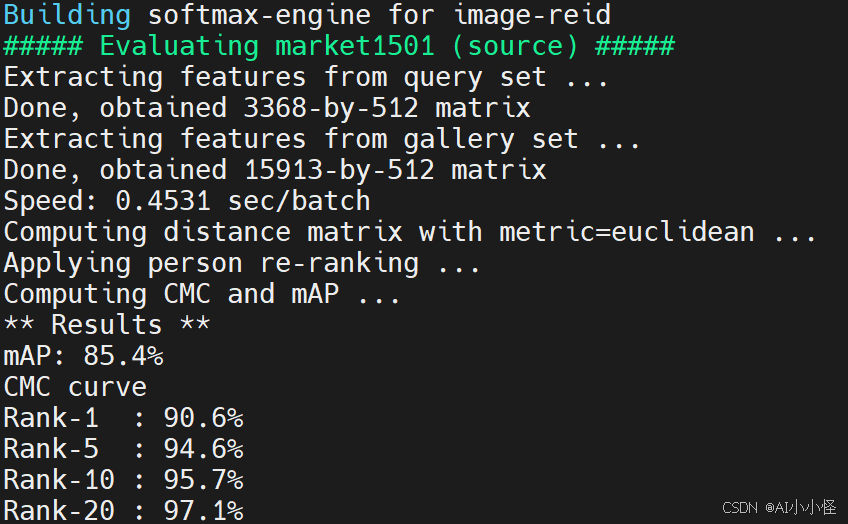
5.2 数据解读
-
mAP: 85.4% - 平均精度均值
-
这是ReID最重要的指标,衡量整体检索性能
-
85.4% 在 Market1501 上是非常不错的结果(SOTA在90%+,但需要复杂模型和技巧)
-
-
Rank-1: 90.6% - 首位命中率
-
查询图片在第一个结果就找到正确行人的概率
-
90.6% 是非常好的结果!
-
-
Rank-5: 94.6% - 前5命中率
-
前5个结果中包含正确行人的概率
-
94.6% 表示几乎总能找到
-
-
Rank-10: 95.7% - 前10命中率
-
前10个结果中包含正确行人的概率
-
-
Rank-20: 97.1% - 前20命中率
-
前20个结果中包含正确行人的概率
-
如果想提高测试精度可以修改以下参数
cfg.test.rerank = True # 启用重排序 (rerank),开启后可以提高mAP 5-10个百分点,但速度会降低
cfg.test.dist_metric = 'cosine' # 通常比euclidean更好
cfg.test.normalize_feature = True # 特征归一化5.3 测试结果可视化
在visrank_market1501中查看可视化测试结果






六、常见问题与解决方案
6.1 GPU内存不足
# 解决方法1:减小批次大小
cfg.train.batch_size = 64 # 从128减小到64
# 解决方法2:使用梯度累积
# 在训练循环中每N步更新一次梯度
accumulation_steps = 2
for i, data in enumerate(train_loader):
loss = model(data)
loss = loss / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()6.2 训练过拟合
# 1. 使用数据增强
cfg.data.transforms = ['random_flip', 'random_crop', 'random_erase', 'color_jitter']
# 2. 使用正则化
cfg.train.weight_decay = 5e-4
# 3. 使用dropout
model = torchreid.models.build_model(
name='resnet50',
num_classes=num_classes,
dropout=0.5 # 添加dropout
)6.3 跨数据集性能差
# 使用域适应方法
# 1. 在训练时混合多个数据集
cfg.data.sources = ['market1501', 'duke', 'msmt17']
# 2. 使用域不变特征学习
# 可以参考添加MMD损失或对抗训练七、总结
本文详细介绍了行人重识别环境搭建、模型训练、测试评估的完整流程。主要步骤包括:
-
环境搭建:使用conda创建虚拟环境,安装PyTorch和deep-person-reid
-
数据准备:下载并组织常用ReID数据集
-
模型训练:配置训练参数,监控训练过程
-
模型测试:评估模型性能,可视化结果
-
问题解决:常见问题分析与解决方案
行人重识别是一个快速发展的领域,建议关注以下方向:
-
使用更先进的网络结构(如Transformer-based模型)
-
探索无监督/自监督学习方法
-
研究跨域适应技术
-
优化推理速度,部署到实际应用

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)