强化学习入门学习第三课 —— 探索与利用:ε-greedy、UCB、Softmax、噪声策略
在强化学习的世界里,存在一个永恒的两难困境——探索(Exploration)还是利用(Exploitation)?是安于现状享受已知的美好,还是勇闯未知寻找更大的宝藏?今天,让我们深入研究四种经典的探索策略,看看它们如何在这场博弈中各显神通!
目录
4. Softmax(Boltzmann):按概率分配的"民主投票"
5.2.2 Ornstein-Uhlenbeck(OU)噪声
导读:在强化学习的世界里,存在一个永恒的两难困境——探索(Exploration)还是利用(Exploitation)?是安于现状享受已知的美好,还是勇闯未知寻找更大的宝藏?今天,让我们深入研究四种经典的探索策略,看看它们如何在这场博弈中各显神通!
1. 探索-利用困境:人生的永恒命题
1.1 什么是探索-利用困境?
想象你来到一个陌生城市,想找一家好吃的餐厅:
-
利用(Exploitation):去你已经知道好吃的那家店(保守但可靠)
-
探索(Exploration):尝试新店,可能发现更美味的(冒险但有惊喜)
画面感:你站在美食街入口,左边是你吃过3次、评分8分的老店;右边是从未尝试过的新店,招牌闪闪发光。你的选择,就是探索-利用困境的缩影!
1.2 数学定义
在多臂老虎机(Multi-Armed Bandit)问题中:
-
有
个动作(摇臂),每个动作有未知的期望奖励
-
目标:最大化累积奖励
-
困境:需要在估计值高的动作(利用)和不确定的动作(探索)之间权衡
遗憾(Regret)定义:

其中 是最优动作。我们希望最小化遗憾,即尽快找到并坚持最优动作。
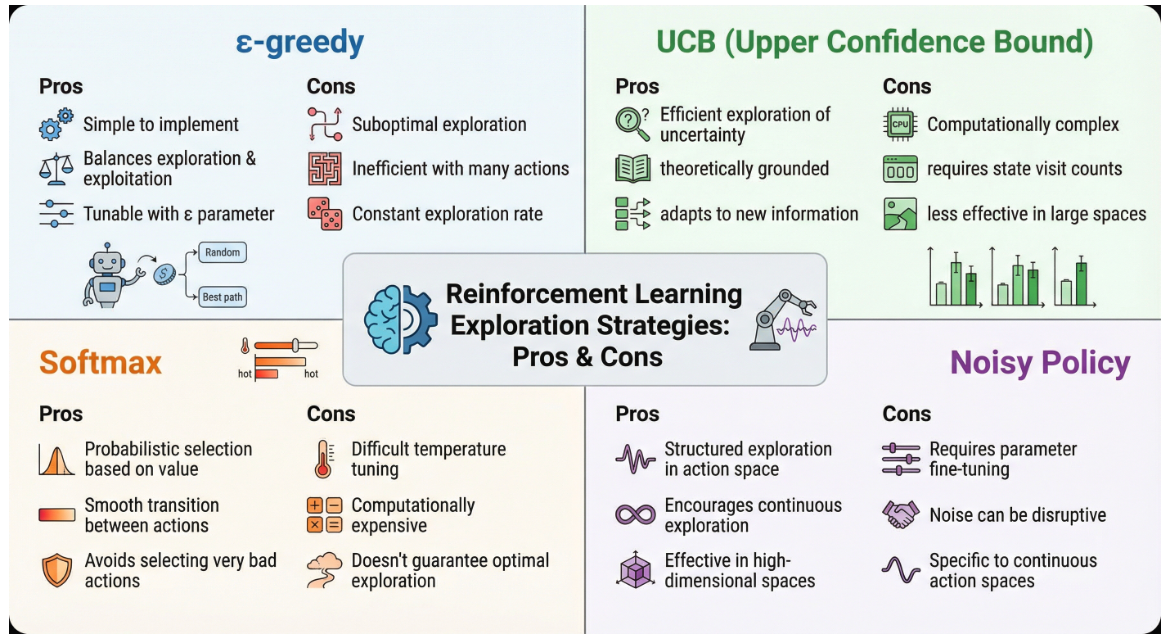
2. ε-greedy:简单粗暴的"抛硬币法"
2.1 核心思想
ε-greedy 是最简单直观的探索策略:
-
以概率
选择当前估计最优的动作(利用)
-
以概率
随机选择一个动作(探索)
2.2 数学表达
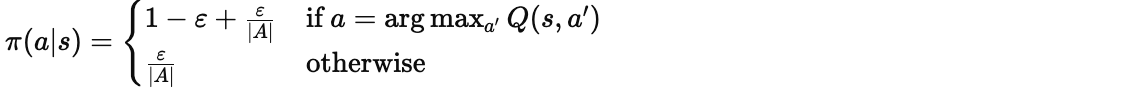
画面感:想象你手里有一枚特殊的硬币,正面概率是 90%(
)。每次做决定前抛一下:正面朝上就选"已知最好的",反面朝上就"闭眼随便选一个"。就是这么简单!
2.3 代码实现
import numpy as np
class EpsilonGreedy:
"""ε-greedy 探索策略"""
def __init__(self, n_actions, epsilon=0.1):
self.n_actions = n_actions
self.epsilon = epsilon
self.Q = np.zeros(n_actions) # 动作价值估计
self.N = np.zeros(n_actions) # 动作被选次数
def select_action(self):
"""选择动作"""
if np.random.random() < self.epsilon:
# 探索:随机选择
return np.random.randint(self.n_actions)
else:
# 利用:选择估计值最高的动作
# 如有多个最大值,随机选一个
max_q = np.max(self.Q)
best_actions = np.where(self.Q == max_q)[0]
return np.random.choice(best_actions)
def update(self, action, reward):
"""增量式更新 Q 值"""
self.N[action] += 1
# 增量更新公式:Q_new = Q_old + (1/N) * (R - Q_old)
self.Q[action] += (reward - self.Q[action]) / self.N[action]
# ==================== ε 衰减版本 ====================
class DecayingEpsilonGreedy(EpsilonGreedy):
"""ε 随时间衰减的 ε-greedy"""
def __init__(self, n_actions, epsilon_start=1.0, epsilon_end=0.01, decay_rate=0.995):
super().__init__(n_actions, epsilon_start)
self.epsilon_start = epsilon_start
self.epsilon_end = epsilon_end
self.decay_rate = decay_rate
self.step_count = 0
def select_action(self):
action = super().select_action()
# 衰减 ε
self.epsilon = max(
self.epsilon_end,
self.epsilon * self.decay_rate
)
self.step_count += 1
return action
2.4 优缺点分析
| 优点 | 缺点 |
|---|---|
| 实现极其简单 | 探索不考虑不确定性 |
| 计算开销几乎为零 | 所有非最优动作被探索的概率相同 |
| 效果出人意料地好 | 固定 ε 无法适应学习进程 |
| 广泛应用于 DQN 等算法 | 后期仍浪费资源在随机探索上 |
调参建议:
初学者:固定 $\varepsilon = 0.1$
进阶:使用衰减策略,从
衰减到
高手:根据任务特性自适应调整
3. UCB:自信与谦逊的完美平衡
3.1 核心思想
UCB(Upper Confidence Bound,置信上界)的哲学是:"乐观面对不确定性"。它不仅看动作的估计价值,还看我们对这个估计有多"不确定"。
核心原则:优先选择那些"可能很好"的动作——要么估计值高,要么尝试次数少(不确定性大)。
3.2 数学公式

其中:
-
:动作
的当前估计价值(利用项)
-
:置信上界(探索奖励项)
-
:探索程度超参数
-
:当前总步数
-
:动作
公式直觉图:
UCB(a) = Q(a) + 探索奖励 ↑ ↑ 估计值 不确定性奖励 ↑ ↑ "它看起来好" "但我还不太了解它" 探索奖励 = c × √(ln(总次数) / 选择此动作的次数) ↑ 选得越少,奖励越大!
3.3 代码实现
class UCB:
"""UCB1 算法"""
def __init__(self, n_actions, c=2.0):
self.n_actions = n_actions
self.c = c # 探索程度参数
self.Q = np.zeros(n_actions) # 动作价值估计
self.N = np.zeros(n_actions) # 动作被选次数
self.total_steps = 0
def select_action(self):
"""选择动作"""
self.total_steps += 1
# 确保每个动作至少被选一次
for a in range(self.n_actions):
if self.N[a] == 0:
return a
# 计算 UCB 值
ucb_values = self.Q + self.c * np.sqrt(
np.log(self.total_steps) / self.N
)
return np.argmax(ucb_values)
def update(self, action, reward):
"""更新估计值"""
self.N[action] += 1
self.Q[action] += (reward - self.Q[action]) / self.N[action]
# ==================== UCB 变体:UCB-Tuned ====================
class UCBTuned(UCB):
"""UCB-Tuned:考虑方差的 UCB"""
def __init__(self, n_actions, c=2.0):
super().__init__(n_actions, c)
self.sum_sq = np.zeros(n_actions) # 奖励平方和
def select_action(self):
self.total_steps += 1
for a in range(self.n_actions):
if self.N[a] == 0:
return a
# 计算样本方差
variance = self.sum_sq / self.N - self.Q ** 2
variance = np.maximum(variance, 0) # 数值稳定性
# UCB-Tuned 公式
exploration_term = np.sqrt(
(np.log(self.total_steps) / self.N) *
np.minimum(0.25, variance + np.sqrt(2 * np.log(self.total_steps) / self.N))
)
ucb_values = self.Q + exploration_term
return np.argmax(ucb_values)
def update(self, action, reward):
super().update(action, reward)
self.sum_sq[action] += reward ** 2
3.4 优缺点分析
| 优点 | 缺点 |
|---|---|
| 理论保证:对数级遗憾界 | 需要记录每个动作的选择次数 |
| 自动平衡探索与利用 | 对超参数 |
| 不确定性越大,探索越多 | 不适用于非平稳环境 |
| 无需随机性,确定性策略 | 状态空间大时计算量增加 |
性格比喻:UCB 像一个谨慎的投资者,在考虑投资回报的同时,也会给"潜力股"一些机会。但它从不盲目冒险——给的机会是有原则的(根据数学公式)!
4. Softmax(Boltzmann):按概率分配的"民主投票"
4.1 核心思想
Softmax 策略不是非黑即白地选择,而是让每个动作都有机会,但好的动作机会更大。它使用 Boltzmann 分布来计算每个动作的选择概率。
4.2 数学公式

其中 是温度参数(Temperature):
-
:接近贪婪策略(几乎只选最优)
-
:接近均匀随机(等概率选择)
-
:标准 Softmax
🎨温度参数直觉图:
假设有3个动作,Q值分别为 [1.0, 2.0, 3.0] τ = 0.1 (低温/冷却):π ≈ [0.00, 0.00, 1.00] ← 几乎只选最好的 "冰冷的理性,不给其他动作任何机会" τ = 1.0 (标准温度):π ≈ [0.09, 0.24, 0.67] ← 按比例分配 "温和的权衡,好的多选,差的少选" τ = 10.0 (高温/加热):π ≈ [0.30, 0.33, 0.37] ← 接近均匀 "热情的探索,每个动作都想试试"
4.3 代码实现
class Softmax:
"""Softmax (Boltzmann) 探索策略"""
def __init__(self, n_actions, temperature=1.0):
self.n_actions = n_actions
self.tau = temperature
self.Q = np.zeros(n_actions)
self.N = np.zeros(n_actions)
def _softmax(self, q_values):
"""计算 softmax 概率,带数值稳定性处理"""
# 减去最大值防止溢出
q_shifted = q_values - np.max(q_values)
exp_q = np.exp(q_shifted / self.tau)
return exp_q / np.sum(exp_q)
def select_action(self):
"""按概率选择动作"""
probs = self._softmax(self.Q)
return np.random.choice(self.n_actions, p=probs)
def update(self, action, reward):
"""更新 Q 值"""
self.N[action] += 1
self.Q[action] += (reward - self.Q[action]) / self.N[action]
# ==================== 温度衰减版本 ====================
class AnnealingSoftmax(Softmax):
"""温度随时间衰减的 Softmax"""
def __init__(self, n_actions, temp_start=10.0, temp_end=0.1, decay_rate=0.995):
super().__init__(n_actions, temp_start)
self.temp_start = temp_start
self.temp_end = temp_end
self.decay_rate = decay_rate
def select_action(self):
action = super().select_action()
# 温度衰减(退火)
self.tau = max(self.temp_end, self.tau * self.decay_rate)
return action
4.4 优缺点分析
| 优点 | 缺点 |
|---|---|
| 考虑了 Q 值的相对大小 | 需要调节温度参数 |
| 平滑的概率分布 | 计算指数运算开销 |
| 可解释性强 | 固定温度难以适应 |
| 适合策略梯度方法 | 不直接考虑不确定性 |
性格比喻:Softmax 像一个民主的领导者,让每个动作都能发声,但最终票数(概率)还是由实力(Q值)决定。温度参数就是"民主程度"的调节器!
5. 噪声策略:给决策加点"调味料"
5.1 核心思想
噪声策略的核心思想是:在动作选择过程中注入随机性,让探索成为一种"自然而然"的行为。主要有两种方式:
-
参数空间噪声(Parameter Noise):给神经网络权重加噪声
-
动作空间噪声(Action Noise):给输出的动作加噪声
5.2 主要方法
5.2.1 高斯噪声(Gaussian Noise)
最简单的方式,直接在动作上加高斯噪声:

5.2.2 Ornstein-Uhlenbeck(OU)噪声
一种时间相关的噪声,特别适合连续控制任务:

离散形式:

其中:
-
:回归速度(多快回到均值)
-
:长期均值(通常为0)
-
:波动程度
OU 噪声直觉:
想象一个醉汉在回家的路上: - 他总体上朝着家的方向走(均值回归) - 但每一步都会摇摇晃晃偏离一点(随机噪声) - 前一步的方向会影响下一步(时间相关性) 这种"有惯性的随机"比纯随机更适合物理控制任务!
5.2.3 NoisyNet(参数噪声)
在神经网络的权重上添加可学习的噪声:

其中:
-
:可学习的均值参数
-
:可学习的噪声标准差
-
:随机噪声(每次前向传播重新采样)
5.3 代码实现
# ==================== 高斯噪声 ====================
class GaussianNoise:
"""高斯噪声探索"""
def __init__(self, n_actions, sigma=0.1, sigma_decay=0.9999, sigma_min=0.01):
self.n_actions = n_actions
self.sigma = sigma
self.sigma_decay = sigma_decay
self.sigma_min = sigma_min
self.Q = np.zeros(n_actions)
self.N = np.zeros(n_actions)
def select_action(self):
"""在最优动作上加噪声"""
# 基础动作
base_action = np.argmax(self.Q)
# 加入高斯噪声(对连续动作空间更有意义)
noise = np.random.normal(0, self.sigma, self.n_actions)
noisy_q = self.Q + noise
# 衰减噪声
self.sigma = max(self.sigma_min, self.sigma * self.sigma_decay)
return np.argmax(noisy_q)
def update(self, action, reward):
self.N[action] += 1
self.Q[action] += (reward - self.Q[action]) / self.N[action]
# ==================== OU 噪声 ====================
class OUNoise:
"""Ornstein-Uhlenbeck 噪声(适合连续动作空间)"""
def __init__(self, action_dim, mu=0.0, theta=0.15, sigma=0.2):
self.action_dim = action_dim
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(action_dim) * mu
def reset(self):
"""重置噪声状态"""
self.state = np.ones(self.action_dim) * self.mu
def sample(self):
"""采样噪声"""
dx = self.theta * (self.mu - self.state) + \
self.sigma * np.random.randn(self.action_dim)
self.state += dx
return self.state
# ==================== NoisyNet 线性层 ====================
class NoisyLinear:
"""带参数噪声的线性层(简化版,实际应用需用PyTorch/TF)"""
def __init__(self, in_features, out_features, sigma_init=0.5):
self.in_features = in_features
self.out_features = out_features
# 可学习参数
self.weight_mu = np.random.randn(out_features, in_features) * 0.1
self.weight_sigma = np.full((out_features, in_features), sigma_init)
self.bias_mu = np.zeros(out_features)
self.bias_sigma = np.full(out_features, sigma_init)
# 噪声
self.weight_epsilon = None
self.bias_epsilon = None
def reset_noise(self):
"""重新采样噪声"""
self.weight_epsilon = np.random.randn(self.out_features, self.in_features)
self.bias_epsilon = np.random.randn(self.out_features)
def forward(self, x):
"""前向传播"""
if self.weight_epsilon is None:
self.reset_noise()
# 加噪声的权重
weight = self.weight_mu + self.weight_sigma * self.weight_epsilon
bias = self.bias_mu + self.bias_sigma * self.bias_epsilon
return np.dot(x, weight.T) + bias
5.4 优缺点分析
| 方法 | 优点 | 缺点 |
|---|---|---|
| 高斯噪声 | 实现简单;适合连续动作 | 噪声与状态无关;需要调参 |
| OU 噪声 | 时间相关性;适合物理控制 | 参数较多;主要用于连续空间 |
| NoisyNet | 自适应探索;无需超参数 | 计算开销大;实现复杂 |
6. 四大策略终极对决
6.1 实验设计
我们使用10-臂老虎机问题来对比四种策略:
import matplotlib.pyplot as plt
class MultiArmedBandit:
"""多臂老虎机环境"""
def __init__(self, n_arms=10):
self.n_arms = n_arms
# 每个臂的真实期望奖励(从标准正态分布采样)
self.q_true = np.random.randn(n_arms)
def pull(self, arm):
"""拉动摇臂,返回奖励"""
# 奖励 = 真实期望 + 高斯噪声
return self.q_true[arm] + np.random.randn()
def optimal_action(self):
"""返回最优动作"""
return np.argmax(self.q_true)
def run_experiment(n_arms=10, n_steps=1000, n_runs=200):
"""运行实验对比"""
strategies = {
'ε-greedy (ε=0.1)': lambda: EpsilonGreedy(n_arms, epsilon=0.1),
'UCB (c=2)': lambda: UCB(n_arms, c=2),
'Softmax (τ=0.1)': lambda: Softmax(n_arms, temperature=0.1),
'Decaying ε-greedy': lambda: DecayingEpsilonGreedy(n_arms),
}
results = {name: np.zeros(n_steps) for name in strategies}
optimal_actions = {name: np.zeros(n_steps) for name in strategies}
for run in range(n_runs):
bandit = MultiArmedBandit(n_arms)
optimal = bandit.optimal_action()
for name, strategy_fn in strategies.items():
strategy = strategy_fn()
for step in range(n_steps):
action = strategy.select_action()
reward = bandit.pull(action)
strategy.update(action, reward)
results[name][step] += reward
if action == optimal:
optimal_actions[name][step] += 1
# 计算平均
for name in strategies:
results[name] /= n_runs
optimal_actions[name] /= n_runs
return results, optimal_actions
def plot_results(results, optimal_actions):
"""绘制结果对比图"""
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
colors = ['#2ecc71', '#3498db', '#e74c3c', '#9b59b6']
# 平均奖励曲线
ax1 = axes[0]
for (name, data), color in zip(results.items(), colors):
ax1.plot(data, label=name, color=color, linewidth=1.5)
ax1.set_xlabel('Steps', fontsize=12)
ax1.set_ylabel('Average Reward', fontsize=12)
ax1.set_title('Average Reward over Time', fontsize=14)
ax1.legend(loc='lower right')
ax1.grid(True, alpha=0.3)
# 最优动作选择率
ax2 = axes[1]
for (name, data), color in zip(optimal_actions.items(), colors):
ax2.plot(data * 100, label=name, color=color, linewidth=1.5)
ax2.set_xlabel('Steps', fontsize=12)
ax2.set_ylabel('Optimal Action %', fontsize=12)
ax2.set_title('Percentage of Optimal Action Selected', fontsize=14)
ax2.legend(loc='lower right')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 运行实验
if __name__ == "__main__":
print("🎰 Running Multi-Armed Bandit Experiment...")
results, optimal_actions = run_experiment()
plot_results(results, optimal_actions)
6.2 实验结果分析
实验结果图描述:
图1:平均奖励曲线
奖励 ↑ 1.5 │ ═══════════════ UCB │ ════════════════════ 衰减ε 1.0 │ ════════════════════════ ε-greedy │ ═════════════════════════════ Softmax 0.5 │ ════ │════ 0.0 │ └────────────────────────────────────→ 步数 0 250 500 750 1000图2:最优动作选择率
比例 ↑ 100% │ ════════ UCB (~95%) │ ══════════════ 衰减ε (~90%) 80% │ ═══════════════════ ε-greedy (~85%) │ ════════════════════════ Softmax (~80%) 60% │ ═════ │════ └────────────────────────────────────→ 步数 0 250 500 750 1000
6.3 各策略表现总结
| 策略 | 最终奖励 | 最优率 | 收敛速度 | 适用场景 |
|---|---|---|---|---|
| ε-greedy | ★★★☆☆ | ~85% | 中等 | 通用场景,快速原型 |
| UCB | ★★★★★ | ~95% | 快 | 需要理论保证的场景 |
| Softmax | ★★★☆☆ | ~80% | 慢 | Q值差异明显时 |
| 衰减 ε | ★★★★☆ | ~90% | 中等 | 需要早期探索的场景 |
7. 深度强化学习中的探索
7.1 DQN 中的探索
# DQN 中典型的 ε-greedy 调度
epsilon_start = 1.0
epsilon_end = 0.01
epsilon_decay = 1_000_000 # 衰减步数
epsilon = epsilon_end + (epsilon_start - epsilon_end) * \
np.exp(-step / epsilon_decay)
7.2 Actor-Critic 中的探索
在策略梯度方法中,探索自然地由策略的随机性提供:

可以通过熵正则化鼓励探索:

其中 是策略熵。
7.3 前沿探索方法简介
| 方法 | 核心思想 |
|---|---|
| ICM(好奇心驱动) | 用预测误差作为内在奖励 |
| RND | 用随机网络蒸馏检测新颖状态 |
| Go-Explore | 记住有趣的状态,有目的地回访 |
| Bootstrap DQN | 用多个 Q 网络的分歧度量不确定性 |
8. 选择策略的决策树
决策流程图:
开始 │ ┌─────────▼─────────┐ │ 动作空间类型? │ └────────┬──────────┘ │ ┌──────────┴──────────┐ ▼ ▼ 离散 连续 │ │ ┌────▼────┐ ┌────▼────┐ │ 需要理论 │ │ 有物理 │ │ 保证? │ │ 惯性? │ └────┬────┘ └────┬────┘ │ │ ┌───┴───┐ ┌───┴───┐ 是 否 是 否 │ │ │ │ ▼ ▼ ▼ ▼ UCB ε-greedy OU噪声 高斯噪声 或Softmax
9. 总结:探索的艺术
9.1 一句话总结
| 策略 | 一句话精髓 |
|---|---|
| ε-greedy | "大部分时间做最好的,偶尔随便玩玩" |
| UCB | "给不确定的事物一个机会" |
| Softmax | "好的多选,差的少选,但都有机会" |
| 噪声策略 | "让随机性成为决策的一部分" |
9.2 探索的哲学
探索与利用的权衡,本质上是短期收益与长期学习的博弈:
-
过度利用:陷入局部最优,错过更好的可能
-
过度探索:浪费资源,收益低下
人生启示:我们的人生又何尝不是在探索与利用中寻找平衡?年轻时多探索(尝试不同职业、学习新技能),成熟后多利用(专注于擅长的领域)。但无论何时,都不要完全停止探索——因为世界在变,机会在变,最优解也在变
如果这篇文章帮助你理解了探索策略,别忘了点赞收藏哦! 👍⭐
有任何问题欢迎在评论区讨论~ 💬

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)