【python爬虫微博评论】根据帖子链接批量爬微博评论,含二级评论
·
一、背景分析
1.1 开发背景
微博是国内极具影响力的社交媒体平台,具有内容形式短平快、热点事件实时性强、舆论快速发酵、用户群体年轻且活跃等特点。其中,微博评论区是用户公开表达观点的重要场域,可通过评论区的数据,实时追踪情绪倾向、挖掘公众诉求、捕捉热点趋势、构建群体画像、从而进行社会学和传播学的研究等。
基于此,我用python开发了一个爬虫采集软件,下边详细介绍。
1.2 数据界面
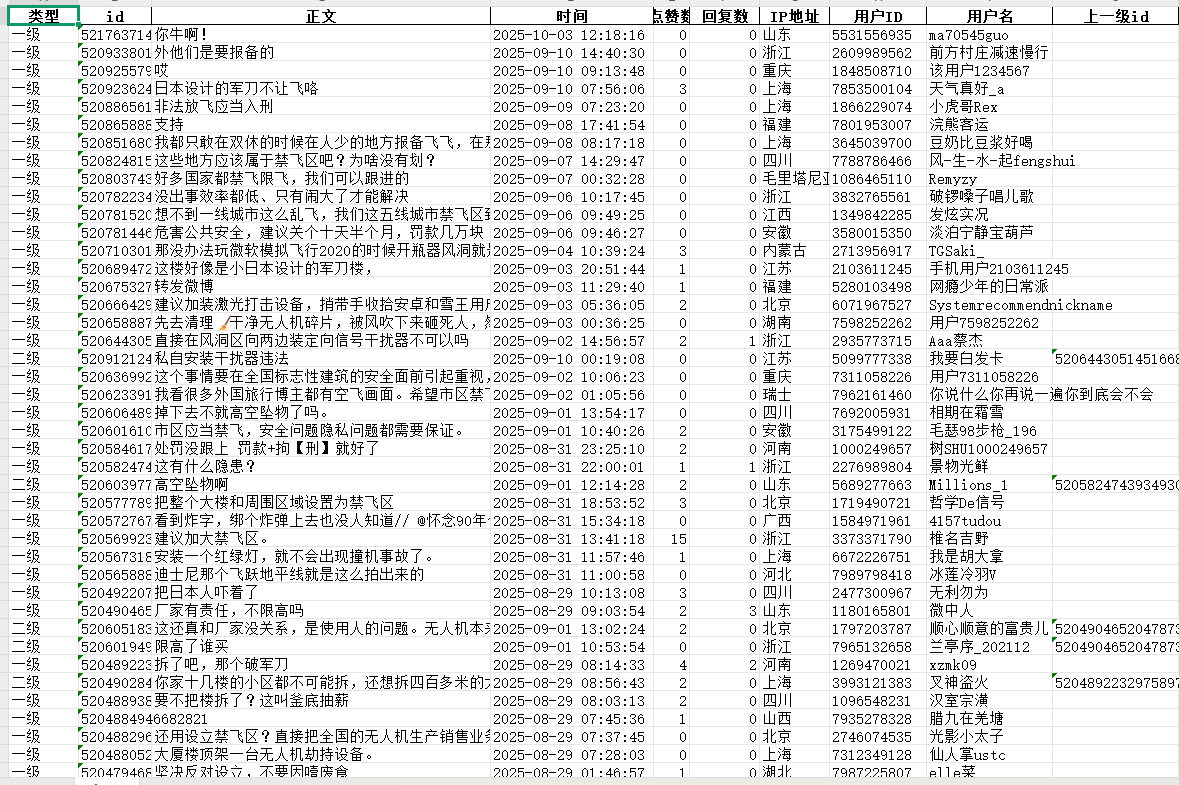
采集结果-微博评论数据
字段:类型(一级或者二级),评论id,评论正文,评论时间,点赞数,回复数,IP地址。用户id,用户名,上一级的id。
字段齐全,后续可用于数据分析等方面。
二、主要技术
软件全部模块采用python语言开发,核心函数如下:
def get_comments(self, weibo_id, max_id='', count=20, is_secondary=False):
url = 'https://weibo.com/ajax/statuses/buildComments'
params = {
'flow': 1,
'is_reload': 1,
'is_show_bulletin': 2,
'is_mix': 1 if is_secondary else 0,
'max_id': max_id,
'count': count,
'id': weibo_id
}
if is_secondary:
params['fetch_level'] = 1
response = self.session.get(url, params=params)
if response.status_code == 200:
return response.json()
print(f"获取评论失败,状态码: {response.status_code}")
return Nonewhile True:
print(f"正在爬取一级评论第{page}页...")
data = self.get_comments(weibo_id, max_id)
if not data or 'data' not in data or not data['data']:
print("没有更多评论了")
break
for comment in data['data']:
# 提取IP地址/地理位置
ip_location = self.extract_ip_location(comment)
primary_comment = {
'类型': '一级',
'id': str(comment['id']),
'正文': self.clean_text(comment['text']),
'时间': self.format_time(comment['created_at']),
'点赞数': comment['like_counts'],
'回复数': comment.get('total_number', 0),
'IP地址': ip_location,
'用户ID': comment.get('user', {}).get('id', ''),
'用户名': comment.get('user', {}).get('screen_name', '')
}
all_comments.append(primary_comment)
# 爬取二级评论
if get_secondary and comment.get('total_number', 0) > 0:
secondary_max_id = ''
secondary_page = 1
parent_id = str(comment['id']) # 父评论ID
while True:
print(f"正在爬取二级评论第{secondary_page}页,父评论id:{parent_id}...")
secondary_data = self.get_comments(parent_id, secondary_max_id, is_secondary=True)
if not secondary_data or 'data' not in secondary_data or not secondary_data['data']:
print("没有更多二级评论了")
break三、使用说明
1,运行前需更换最新cookie。
2,本作者一直在维护代码,确保您能顺利运行!
3,一起学习交流,通过公中号iFeng的小屋一键获取,有其他定制需要可以详细交流学习。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)