强化学习又登Nature!结合知识图谱,训练效率提35%!
强化学习与知识图谱的融合研究进展 近年来,强化学习(RL)与知识图谱(KG)融合成为AI研究热点。传统RL面临试错成本高、训练周期长等问题,而知识图谱的结构化知识可以有效引导RL策略优化。最新研究表明,这种融合架构在游戏AI、电商推荐、交通控制等场景中显著提升性能(提升18-35%)。AutoGraph-R1创新性地将RL应用于KG构建本身,通过任务效用奖励直接优化图谱结构;DynaSearche
如今在智能决策、自动规划领域,强化学习(RL)与知识图谱的融合已成热门。近期NeurIPS、ICLR顶会成果,为传统RL模型发展指明新方向。做RL研究的同学常遇困境,传统RL太依赖试错学习,耗大量算力迭代才能找有效策略;面对智能推荐、游戏AI等复杂场景,不仅训练周期长,还因缺领域知识导致策略走偏,医疗、金融等对可靠性要求高的领域更难落地。而两者融合的架构,给RL注入知识储备,轻松破解这些难题。
知识图谱能把分散领域知识转化为结构化关联,让RL从盲目探索变为定向优化。比如MOBA游戏AI中,融合模型较纯DQN训练效率提35%;电商推荐时,转化率提升21%;城市交通控制中,通行效率提高18%,避免无效试错。
想发论文的同学,可关注知识图谱引导RL策略、动态知识融合、小样本知识迁移等方向。我整理了相关顶会/顶刊核心论文,涵盖不同时序任务的实现方案,部分还附带复现代码打包免费送,感兴趣的同学工种号 沃的顶会 扫码回复 “强化图谱” 领取
AutoGraph-R1:END-TO-END REINFORCEMENT LEARNING FOR KNOWLEDGE GRAPH CONSTRUCTION
文章解析
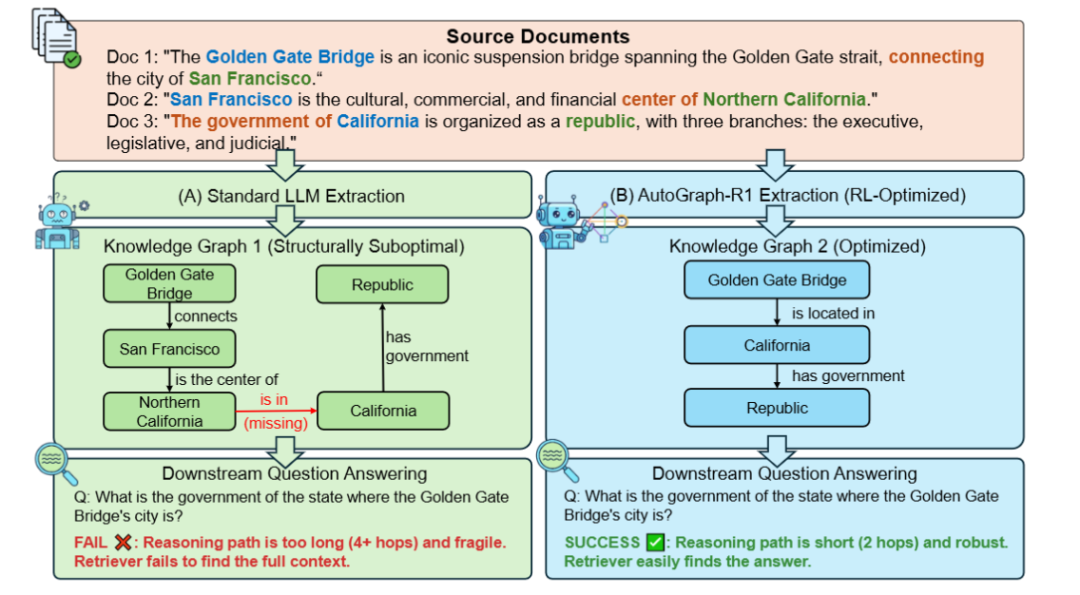
本文提出AutoGraph-R1,首个利用强化学习(RL)直接优化知识图谱(KG)构建以提升下游任务性能的框架。传统KG构建与下游应用脱节,导致结构虽在内在指标上表现良好,但在实际任务中效果不佳。AutoGraph-R1将图谱生成建模为策略学习问题,通过RAG流程中的任务效用(如问答准确性)提供奖励信号,驱动LLM构造器生成功能更优的图结构。实验表明,该方法显著提升了多跳问答等复杂任务的表现,实现了从构建‘好’图到构建‘有用’图的范式转变。
创新点
首次将强化学习应用于知识图谱构建过程本身,实现端到端的任务导向优化。
提出两种任务感知的奖励函数,分别衡量图作为知识载体和知识索引的有效性。
实现了KG构造与下游RAG任务之间的闭环反馈,使图结构直接服务于任务性能。
证明了功能导向的图结构优于传统基于精确率和覆盖率的内在质量导向图。
为LLM驱动的图谱构造器提供了可训练的策略路径,突破非可微构造过程的优化瓶颈。
研究方法
将知识图谱生成视为一个由LLM执行的策略行为,输入原始文本并输出三元组和实体链接。
在下游RAG pipeline中评估生成图的功能效用,并据此计算任务相关的奖励信号。
使用策略梯度方法(如REINFORCE)更新LLM构造器参数,使图结构逐步优化于目标任务。
设计两种奖励机制:一种基于检索到的支持文本的质量,另一种基于推理子图的完整性。
在多个需要多文档推理的QA基准上进行训练与验证,确保泛化能力。
研究结论
AutoGraph-R1能够显著提升现有图RAG方法在复杂问答任务上的表现。
任务感知的强化学习奖励能有效引导模型构建出更适合下游推理的图结构。
解耦的KG构建与应用范式可通过端到端学习被成功整合。
功能实用性应成为知识图谱评估的核心标准,而非仅依赖内在指标。
RL为不可微的符号化KG构建过程提供了可行的学习框架。
DynaSearcher:Dynamic Knowledge Graph Augmented Search Agent via Multi-Reward Reinforcement Learning
文章解析
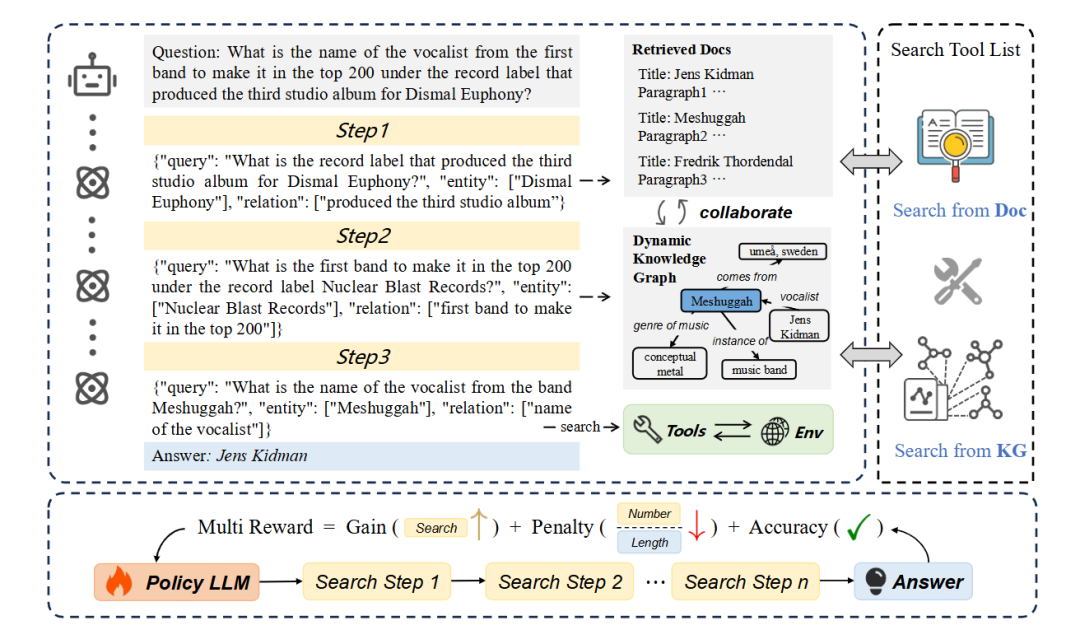
基于大语言模型(LLM)的多步检索系统在复杂信息搜索任务中表现出色,但常因中间查询的事实不一致和搜索路径低效导致推理偏差与冗余计算。本文提出DynaSearcher,通过引入动态知识图谱(KG)作为结构化外部知识,显式建模实体关系以确保中间查询的事实一致性,并结合多奖励强化学习(RL)框架对检索准确性、效率和响应质量进行细粒度优化。该方法有效提升中间查询质量和最终回答的完整性,抑制无效探索与信息遗漏。实验表明,DynaSearcher在六个多跳问答数据集上达到最优性能,具备良好的泛化性和鲁棒性,适用于不同检索环境和大规模模型。
创新点
首次将动态知识图谱集成到搜索代理中,通过显式建模实体关系提升中间查询的事实一致性。
提出多奖励强化学习机制,融合增益与惩罚信号,实现对检索精度、效率和响应质量的细粒度控制。
利用知识图谱结构引导推理路径,减少噪声和无关信息导致的推理偏差。
多奖励框架充分挖掘不同奖励信号间的依赖关系,增强对查询轨迹的显式指导。
在低资源情境下仍保持高性能,展现强泛化能力与实际应用潜力。
研究方法
使用知识图谱作为外部结构化知识源,在多步推理过程中建模实体间关系以指导搜索。
设计基于多奖励的强化学习框架,分别优化检索准确率、搜索效率和最终回答质量。
在训练中引入对中间查询质量的反馈机制,鼓励高质量查询生成并惩罚冗余或无效探索。
通过端到端训练使LLM自主调用检索工具,实现与外部环境的动态交互。
在多种多跳问答数据集和不同规模模型上进行评估,验证方法的通用性与鲁棒性。
研究结论
DynaSearcher在多个多跳问答任务上实现了最先进的答案准确率。
引入知识图谱显著提升了搜索过程的事实一致性与推理稳定性。
多奖励RL框架有效平衡了检索性能与计算效率。
该方法在不同检索环境和更大规模模型中表现出良好泛化能力。
DynaSearcher为构建高效、可靠、可扩展的智能搜索代理提供了新范式。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)