深度学习第七节 自注意力机制 self-attention
在自然语言处理(NLP)领域,让机器理解文字的含义、语境关联是核心难题。从早期的词编码到如今的大模型,技术迭代的核心围绕 “如何更好捕捉语言规律” 展开,而自注意力机制与 BERT 模型的出现,彻底改变了 NLP 的发展轨迹。本文将从基础到核心,拆解这两大关键技术的原理与价值。
在自然语言处理(NLP)领域,让机器理解文字的含义、语境关联是核心难题。从早期的词编码到如今的大模型,技术迭代的核心围绕 “如何更好捕捉语言规律” 展开,而自注意力机制与 BERT 模型的出现,彻底改变了 NLP 的发展轨迹。本文将从基础到核心,拆解这两大关键技术的原理与价值。
一、语言的 “数字化难题”:从词编码说起
要让机器处理文字,首先得将文字转化为可计算的向量,这就需要词编码技术:
- One-hot Encoding(独热编码):给每个词分配唯一的二进制向量,比如 “我”=[1,0,0,...]、“你”=[0,1,0,...]。但它存在致命缺陷 —— 维度会随词汇量爆炸式增长,且完全无法体现词与词的语义关联(比如 “猫” 和 “狗” 的向量毫无相似度)。
- Word Embedding(词嵌入):让模型自主学习词的低维稠密向量(常见维度 768),不仅解决了维度问题,还能自然呈现语义关联(“猫” 和 “狗” 的向量距离更近),成为现代 NLP 的基础输入形式。
二、语境捕捉的进化:从 RNN/LSTM 到自注意力
文字的含义依赖上下文,比如 “Can you can a can as a cancer can a can?” 中,多个 “can” 的词性需结合语境判断。早期模型的探索与局限如下:
- RNN(循环神经网络):按顺序逐个处理词语,通过记忆单元传递上下文信息,但存在 “长距离依赖” 问题 —— 距离过远的词语关联会被弱化(比如长句中开头与结尾的语义无法有效传递)。
- LSTM(长短期记忆网络):通过输入门、遗忘门、记忆门优化记忆机制,缓解了长距离依赖,但本质仍是串行处理,速度慢,无法并行计算。
- 核心痛点:无论是 RNN 还是 LSTM,都只能 “逐字推进”,无法同时俯瞰整个句子,效率和语境捕捉能力受限。
自注意力机制:并行处理 + 全局视野的突破
2017 年论文《Attention is All You Need》提出的自注意力机制(Self-attention),彻底解决了串行问题,其核心逻辑如下:
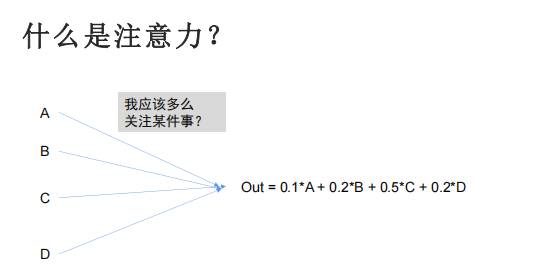
- 核心思想:让每个词语同时与句子中所有词语建立关联,计算注意力权重,从而一次性捕捉全局语境。
- 关键步骤:
- 对每个词的嵌入向量(a_i),通过三个可学习的权重矩阵(W_q、W_k、W_v)生成 Query(查询)、Key(键)、Value(值)。
- 计算 Query 与所有 Key 的点积,得到注意力分数(α),再通过 Softmax 归一化,得到每个词对其他词的关注程度。
- 用归一化后的注意力权重加权求和所有 Value,得到该词的最终特征向量(b_i)
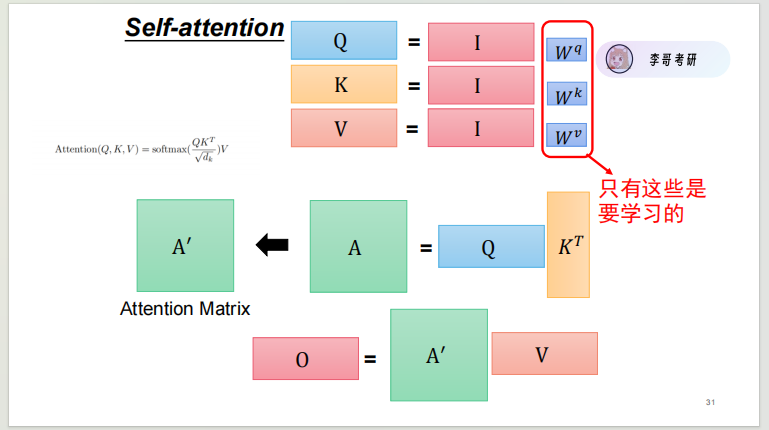
- 核心优势:完全并行计算,无需等待前一个词处理完成;全局视野,能直接捕捉任意两个词的关联,不受距离限制。
- 位置编码(Positional Encoding):自注意力本身不包含语序信息,因此需在词嵌入中加入位置编码,让模型区分词语的顺序差异(比如 “我爱你” 和 “你爱我”)。
自注意力机制的公式简洁而强大:Attention(Q,K,V)=softmax(dkQKT)V其中√d_k 是为了避免点积结果过大导致 Softmax 梯度消失。
soft-max (例如得到【1,2,4,5】 则经过soft-max为【1/(1+2+4+5),2/12,4/12,5/12)
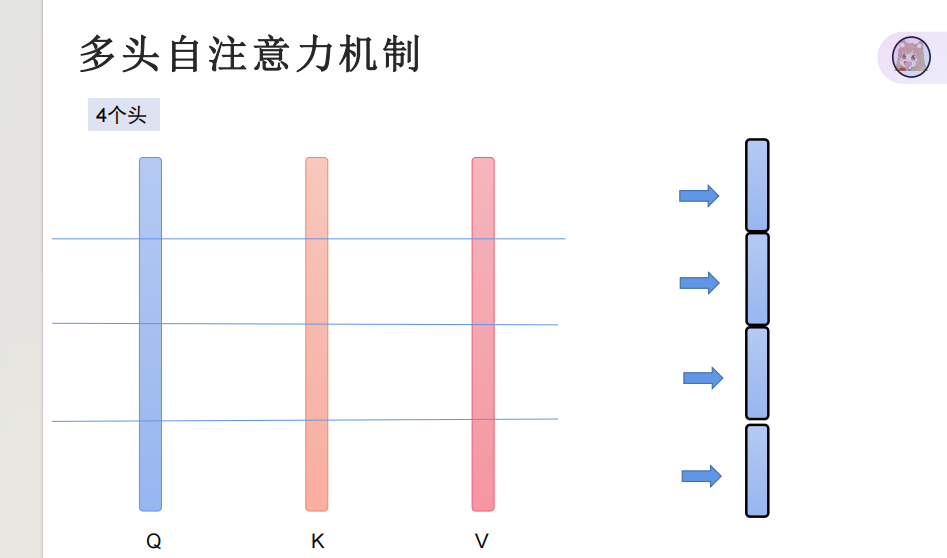
“多头注意力是将 Q/K/V 拆分为多个子空间,分别计算注意力后拼接,能捕捉不同语义维度的关联”。
三、BERT:基于自注意力的 “语言特征提取神器”
BERT(Bidirectional Encoder Representations from Transformers)以自注意力机制为核心,是 NLP 领域的里程碑模型,其核心设计如下:
1. 模型结构
- 输入层:由词嵌入(Token Embedding)、位置嵌入(Positional Embedding)、段落嵌入(Segment Embedding)三部分组成,分别捕捉词义、语序和段落边界信息。
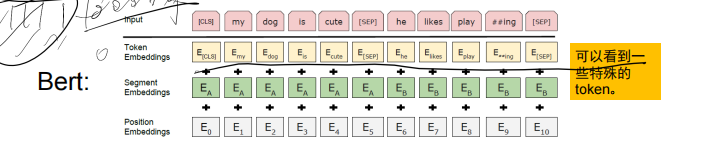
1. [CLS] 的作用
- 是 “Classification” 的缩写,代表分类标记。
- 在预训练(比如 BERT 的句子级任务)或下游分类任务中,模型会用这个 Token 对应的输出向量,来表示整个句子 / 文本的 “全局语义信息”,作为分类、匹配等任务的输入。
- 它是整个输入序列的第一个 Token。
2. [SEP] 的作用
- 是 “Separator” 的缩写,代表分隔标记。
- 用于分隔不同的文本片段(比如 BERT 的句子对任务:“句子 A [SEP] 句子 B”),告诉模型这是两个独立的文本单元。
- 图里也能看到:
[SEP]左侧的 Token 对应的 Segment Embedding 是E_A(属于句子 A),右侧是E_B(属于句子 B),[SEP]起到了区分两个片段的作用。
简单说:[CLS]负责 “代表整个文本的语义”,[SEP]负责 “分隔不同文本片段”,都是 Transformer 预训练模型的标准输入组件
- 中间层:堆叠多层多头自注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward),并通过 Add&Norm(残差连接 + 层归一化)稳定训练。
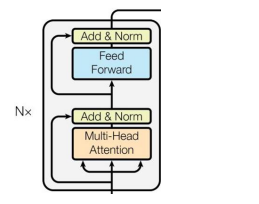
- 输出层:通过 Pooler(通常取 [CLS] token 的特征)或特定任务头(如分类、命名实体识别)输出结果。
2. 预训练 + 微调的范式
BERT 采用 “自监督预训练 + 下游任务微调” 的模式,彻底降低了 NLP 任务的落地门槛:
- 预训练任务:
- 掩码语言模型(Masked Language Model, MLM):随机掩盖句子中 15% 的 Token(80% 替换为 [MASK],10% 替换为随机词,10% 保持不变),让模型预测原词,从而学习上下文语义。
- 下一句预测(Next Sentence Prediction, NSP):判断两个段落是否为连续的上下文,培养模型的篇章级理解能力。
- 微调:预训练后的 BERT 具备强大的通用语言特征提取能力,针对情感分类、命名实体识别(NER)、机器翻译等下游任务,只需添加少量任务特定参数,即可快速适配。
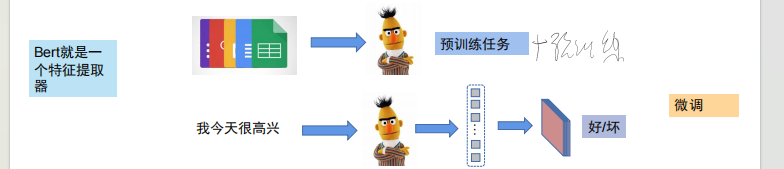
现在我们要做的都是微调 像预训练任务里的参数太多而且成本巨大 无法实现
3. 核心优势
- 双向语境理解:不同于单向的 GPT 模型,BERT 能同时捕捉左右两侧的上下文信息,语义理解更准确。
- 迁移学习能力强:预训练阶段使用海量无标注文本,微调阶段仅需少量标注数据就能达到优异效果。
- 任务适配广泛:可直接应用于分类、序列标注、问答、翻译等多种 NLP 任务,是通用型语言模型的基石。
- 技术迭代逻辑:从 One-hot 到 Word Embedding 解决了 “词的数字化”,从 RNN/LSTM 到自注意力解决了 “语境的高效捕捉”,BERT 则通过预训练范式让技术落地更高效。
- 核心价值:自注意力机制的并行性和全局视野是现代大模型高效运行的基础,而 BERT 开创的 “预训练 + 微调” 模式,成为后续 GPT、LLaMA 等模型的设计蓝本。
- 实际应用:如今,基于自注意力和 BERT 的技术已广泛应用于智能客服、情感分析、文本摘要、机器翻译、命名实体识别等场景,成为 NLP 工业化落地的核心支撑。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)