计算机视觉四大基本任务技术
从零掌握计算机视觉:四大核心任务全解析
计算机视觉(Computer Vision)作为人工智能领域的核心分支,旨在使机器能够"看懂"并理解视觉世界。它通过模拟人类视觉系统的工作原理,让计算机从图像或视频中提取语义信息、识别物体、理解场景,从而实现自动驾驶、医学影像分析、智能安防等革命性应用。在AI技术爆发的今天,计算机视觉已渗透到工业检测、农业监测、AR/VR等60+行业,全球市场规模预计2025年突破410亿美元。
对于初学者而言,掌握计算机视觉需从四大基础任务切入:图像分类(“这是什么?”)、目标定位(“它在哪里?”)、目标检测(“有什么?在哪里?”)和图像分割(“每个像素属于什么?”)。本文将系统解析这四大任务的技术原理、可视化案例、代码实现及学习路径,为你构建从理论到实践的完整知识体系。
一、图像分类
定义与应用
图像分类(Image Classification)是计算机视觉最基础的任务,旨在将输入图像分配到预定义类别的标签(如"猫"、“狗”)。作为视觉识别的基石,它支撑着人脸识别(手机解锁)、医学影像诊断(肿瘤筛查)、工业质检(零件缺陷识别)等核心应用。
技术原理
核心算法:卷积神经网络(CNN)
图像分类的革命性突破源于卷积神经网络(CNN) 的提出。与全连接网络不同,CNN通过局部感受野(模拟视觉皮层细胞响应)、权值共享(减少参数数量)和池化层(降维与平移不变性)三大特性,高效提取图像的层次化特征:
- 浅层:检测边缘、纹理等低级特征
- 中层:组合低级特征形成部件(如车轮、眼睛)
- 高层:抽象为语义概念(如"汽车"、“动物”)
经典CNN架构演进:
- LeNet-5(1998):首个CNN,用于手写数字识别
- AlexNet(2012):ReLU激活函数+GPU加速,ImageNet准确率提升10%
- ResNet(2015):残差连接解决梯度消失,深度达152层仍可训练
关键指标
- 准确率(Accuracy):正确分类样本占比,适用于平衡数据集
- 混淆矩阵(Confusion Matrix):展示各类别间的混淆情况,衍生出精确率(Precision)、召回率(Recall)和F1分数
- Top-K准确率:模型预测的Top-K结果中包含正确标签的概率(如ImageNet常用Top-5准确率)
可视化:ImageNet分类示例
如图1所示,ImageNet数据集包含1000个类别,每个类别有数千张图像。以下展示10类常见物体的分类结果,每类包含10个样本:
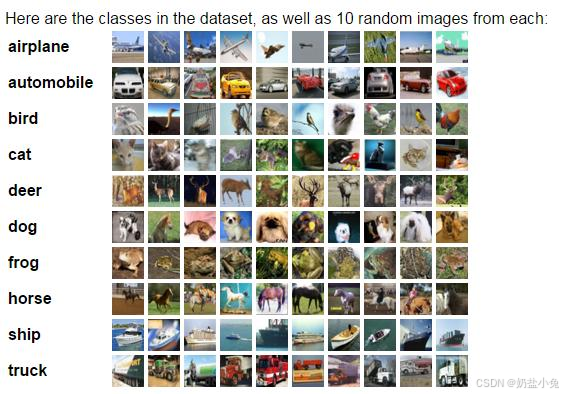
图1:ImageNet数据集10类常见物体分类结果(从左至右依次为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车)
代码实现:PyTorch基础分类模型
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 1. 数据预处理
transform = transforms.Compose([
transforms.Resize((32, 32)), # 调整图像大小
transforms.ToTensor(), # 转换为张量并归一化到[0,1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到[-1,1]
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
test_dataset = datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 2. 定义CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积层:3输入通道,16输出通道,5x5卷积核
self.conv1 = nn.Conv2d(3, 16, 5, padding=2)
# 池化层:2x2最大池化
self.pool = nn.MaxPool2d(2, 2)
# 卷积层:16输入通道,32输出通道,5x5卷积核
self.conv2 = nn.Conv2d(16, 32, 5, padding=2)
# 全连接层:展平后连接到120神经元
self.fc1 = nn.Linear(32 * 8 * 8, 120)
# 全连接层:120→84
self.fc2 = nn.Linear(120, 84)
# 输出层:84→10(CIFAR-10有10个类别)
self.fc3 = nn.Linear(84, 10)
# ReLU激活函数
self.relu = nn.ReLU()
def forward(self, x):
# 前向传播:conv1→relu→pool
x = self.pool(self.relu(self.conv1(x))) # 输出形状:(16, 16, 16)
# conv2→relu→pool
x = self.pool(self.relu(self.conv2(x))) # 输出形状:(32, 8, 8)
# 展平操作
x = x.view(-1, 32 * 8 * 8) # 形状:(32*8*8,)
# 全连接层
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x) # 无激活函数(交叉熵损失自带Softmax)
return x
# 3. 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss() # 分类任务常用交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 带动量的SGD
# 4. 训练模型
for epoch in range(5): # 训练5轮
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 获取输入和标签
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 打印统计信息
running_loss += loss.item()
if i % 200 == 199: # 每200批次打印一次
print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
print('Finished Training')
# 5. 保存模型
torch.save(model.state_dict(), 'cifar10_cnn.pth')
# 6. 测试模型
correct = 0
total = 0
with torch.no_grad(): # 测试时不计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 获取预测类别
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy on test images: {100 * correct / total:.2f}%')
代码说明:
- 数据集:使用CIFAR-10(32×32彩色图像,10个类别)
- 模型结构:2个卷积块(卷积+ReLU+池化)+3个全连接层
- 训练细节:SGD优化器(学习率0.001,动量0.9),交叉熵损失,训练5轮
- 预期效果:测试集准确率约65%-70%,可通过增加网络深度或使用预训练模型提升性能
二、目标定位
定义与应用
目标定位(Object Localization)在分类基础上增加了对目标位置的预测,通过边界框(Bounding Box) 标注物体在图像中的坐标(通常表示为[x_min, y_min, x_max, y_max]或[x_center, y_center, width, height])。与分类任务仅输出类别标签不同,定位需要同时预测:
- 物体类别(如"猫")
- 边界框坐标(如
[100, 80, 200, 180])
典型应用包括:人脸检测(相机自动对焦)、工业零件定位(机器人抓取)、自动驾驶障碍物定位。
技术原理
边界框表示方法
常用边界框格式:
- 像素坐标:直接使用图像像素值(如
x_min=50, y_min=30, x_max=250, y_max=200) - 归一化坐标:将坐标除以图像宽高,范围[0,1](如
x_center=0.3, y_center=0.4, w=0.5, h=0.6) - 锚框(Anchor Box):预定义多个不同尺度和比例的边界框,模型预测偏移量(Faster R-CNN、YOLO等采用)
技术演进
-
滑动窗口(Sliding Window)
传统方法通过固定大小窗口在图像上滑动,对每个窗口进行分类。缺点是计算量大(需遍历多尺度窗口),无法精确定位。 -
区域提议(Region Proposal)
- R-CNN(2014):使用选择性搜索(Selective Search)生成2000个候选区域,对每个区域提取特征并分类+回归边界框。
- Fast R-CNN(2015):共享卷积特征,避免重复计算,引入ROI Pooling层统一特征尺寸。
- Faster R-CNN(2016):提出区域生成网络(RPN),端到端生成高质量候选框,将定位精度提升至实时水平。
可视化:目标定位结果示意图
如图2所示,定位算法需在图像中准确标注多个物体的边界框及类别:
图2:多物体目标定位结果(蓝色框表示"车模位置光电检测"区域,黑色方块为AprilTag标记,蓝色圆形为目标靶,红色箭头标注关键尺寸)
代码实现:基于预训练模型的目标定位
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# 1. 加载预训练的Faster R-CNN模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval() # 设置为评估模式
# 2. 图像预处理
transform = transforms.Compose([
transforms.ToTensor() # 转换为Tensor并归一化
])
# 3. 加载图像
image = Image.open("test_image.jpg").convert("RGB") # 替换为你的图像路径
image_tensor = transform(image).unsqueeze(0) # 添加批次维度
# 4. 目标定位推理
with torch.no_grad():
predictions = model(image_tensor)
# 5. 解析预测结果(筛选置信度>0.5的目标)
pred_boxes = predictions[0]['boxes'].numpy()
pred_scores = predictions[0]['scores'].numpy()
pred_labels = predictions[0]['labels'].numpy()
# COCO数据集类别名称(共91类)
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana',
'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut',
'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A', 'N/A',
'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush'
]
# 6. 可视化结果
fig, ax = plt.subplots(1)
ax.imshow(image)
for i in range(len(pred_boxes)):
if pred_scores[i] > 0.5: # 仅显示置信度>0.5的结果
box = pred_boxes[i]
x_min, y_min, x_max, y_max = box
# 绘制边界框
rect = patches.Rectangle(
(x_min, y_min), x_max - x_min, y_max - y_min,
linewidth=2, edgecolor='r', facecolor='none'
)
ax.add_patch(rect)
# 添加类别和置信度标签
label = f"{COCO_INSTANCE_CATEGORY_NAMES[pred_labels[i]]}: {pred_scores[i]:.2f}"
plt.text(x_min, y_min - 10, label, color='red', fontsize=12, weight='bold')
plt.axis('off')
plt.savefig('localization_result.jpg', bbox_inches='tight')
plt.show()
代码说明:
- 模型:使用torchvision预训练的Faster R-CNN(基于ResNet-50-FPN backbone)
- 输入:任意RGB图像(代码中需替换为实际图像路径)
- 输出:边界框坐标、类别标签和置信度分数
- 后处理:筛选置信度>0.5的结果,可视化边界框和标签
三、目标检测
定义与应用
目标检测(Object Detection)是计算机视觉的核心任务之一,需同时完成多目标分类和精确定位,解决"图像中有什么物体?在哪里?"的问题。与定位任务仅处理单个目标不同,检测需应对:
- 多个物体的同时识别
- 不同尺度、姿态和遮挡的物体
- 实时性要求(如自动驾驶需30FPS以上)
工业应用包括:智能监控(行人/车辆计数)、无人机巡检(缺陷检测)、零售结算(商品识别)。
技术原理
算法对比:YOLO系列 vs Faster R-CNN
| 特性 | Faster R-CNN(双阶段) | YOLO(单阶段) |
|---|---|---|
| 检测流程 | 1. RPN生成候选框 2. 分类与回归 |
直接在网格上回归类别和边界框 |
| 速度 | 较慢(~5 FPS) | 快(YOLOv5达140 FPS) |
| 精度 | 高(COCO mAP@0.5: 0.78) | 中高(YOLOv5 mAP@0.5: 0.72) |
| 优势场景 | 高精度要求(医学影像) | 实时性要求(自动驾驶、视频监控) |
| 代表版本 | Faster R-CNN, Mask R-CNN | YOLOv5, YOLOv8, YOLOv11 |
技术差异:
- 双阶段检测:先通过区域提议网络(RPN)生成少量高质量候选框(~300个),再进行分类回归,精度高但速度慢。
- 单阶段检测:将图像划分为S×S网格,每个网格预测B个边界框和类别概率,端到端一次性输出结果,速度快但易产生冗余框。
可视化:检测效果对比图
如图3所示,不同算法在复杂场景下的检测性能差异明显:
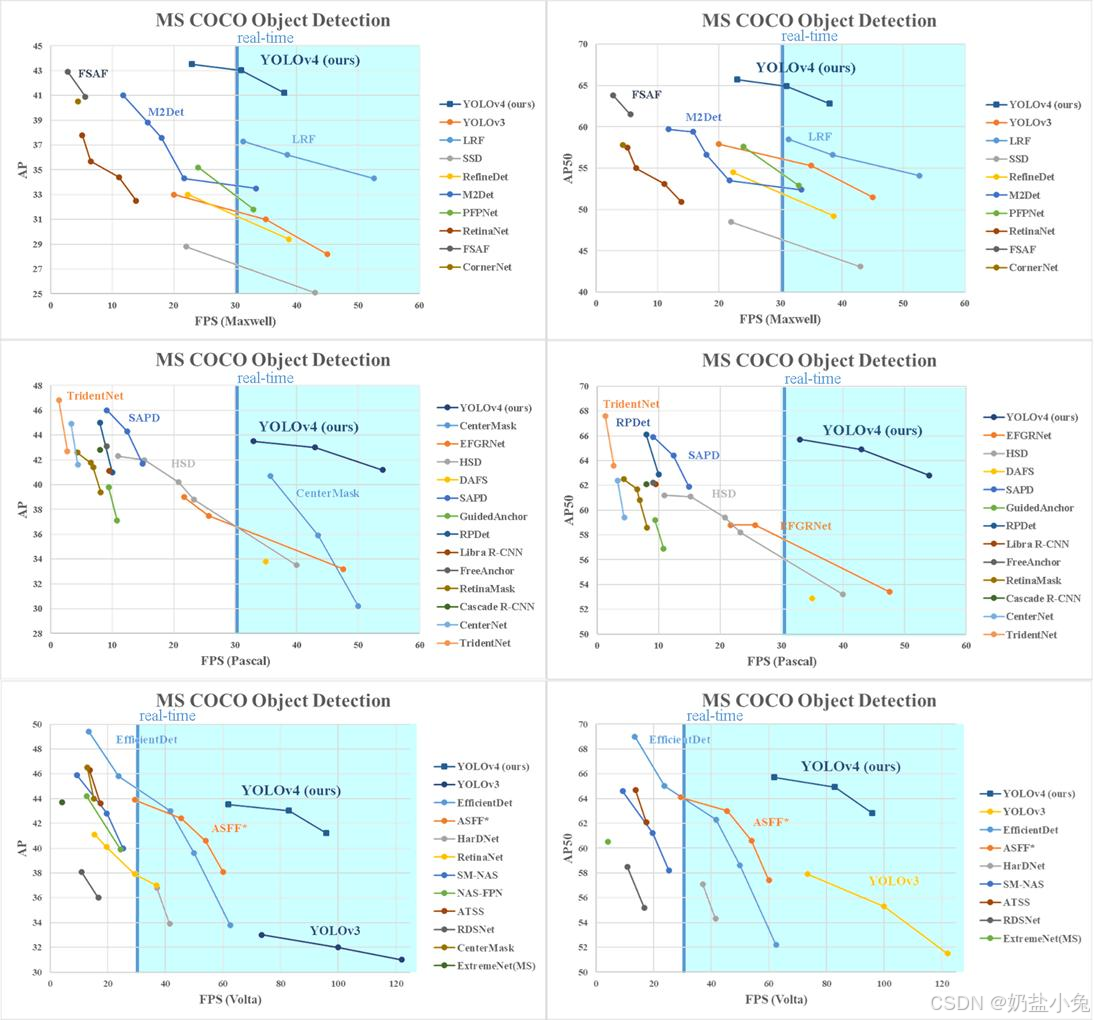
图3:MS COCO数据集上不同检测模型的性能对比(AP vs FPS)。YOLO系列在速度上优势显著,Faster R-CNN类模型在高精度区域表现更好。"real-time"线表示30 FPS实时阈值。
代码实现:YOLOv5简易检测
# 安装YOLOv5依赖
# !pip install ultralytics
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
# 1. 加载预训练模型(YOLOv5s,小型模型,速度快)
model = YOLO('yolov5s.pt') # 自动下载模型权重
# 2. 准备输入图像
image_path = 'test_image.jpg' # 替换为你的图像路径
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转换为RGB格式
# 3. 执行检测
results = model(image) # 输出包含检测框、类别和置信度
# 4. 解析结果并可视化
annotated_image = results[0].plot() # 自动绘制检测框和标签
# 5. 保存结果
plt.figure(figsize=(10, 10))
plt.imshow(annotated_image)
plt.axis('off')
plt.savefig('yolov5_detection.jpg', bbox_inches='tight')
plt.show()
# 6. 打印检测结果详情
for box in results[0].boxes:
class_id = int(box.cls[0])
confidence = float(box.conf[0])
xyxy = box.xyxy[0].tolist() # [x_min, y_min, x_max, y_max]
class_name = model.names[class_id]
print(f"Detected {class_name} with confidence {confidence:.2f} at {xyxy}")
代码说明:
- 模型:使用Ultralytics库的YOLOv5s(轻量级模型,适合CPU/GPU运行)
- 数据集:预训练于COCO数据集(80个类别)
- 输入输出:支持图像/视频/摄像头输入,输出边界框坐标、类别和置信度
- 扩展功能:可通过
model.train()在自定义数据集上微调,支持批量处理和导出为ONNX/TensorRT格式加速
四、图像分割
定义与应用
图像分割(Image Segmentation)是像素级别的精细分类,将图像分割为语义上有意义的区域,回答"每个像素属于哪个物体/背景?"的问题。主要分为:
- 语义分割(Semantic Segmentation):仅区分类别,不区分同一类别的不同实例(如所有"人"像素标为同一颜色)
- 实例分割(Instance Segmentation):区分同一类别的不同个体(如图像中3个人分别标注为不同颜色)
应用场景包括:医学影像(肿瘤区域勾画)、自动驾驶(可行驶区域分割)、影视特效(绿幕抠图)。
技术原理
技术难点
- 边界精确性:物体边缘(如发丝、玻璃杯)的像素级标注
- 小目标处理:小物体(如远处行人)的分割精度
- 类别平衡:前景背景像素比例失衡(如天空占比90%)
主流算法
- FCN(全卷积网络):将CNN最后的全连接层替换为卷积层,实现端到端像素预测
- U-Net:编码器-解码器架构+跳跃连接,保留低层级空间信息,适合医学影像
- Mask R-CNN:在Faster R-CNN基础上增加掩码分支,同时实现检测和实例分割
可视化:分割结果对比图
如图4所示,不同分割任务的输出差异显著:

图4:原图(左)、语义分割(中)、实例分割(右)对比。语义分割将同类物体标为同一颜色,实例分割区分不同个体。
代码实现:Mask R-CNN分割结果可视化
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
# 1. 加载预训练的Mask R-CNN模型(YOLOv8-seg)
model = YOLO('yolov8s-seg.pt') # 轻量级分割模型
# 2. 执行分割推理
image_path = 'test_image.jpg' # 替换为你的图像路径
results = model(image_path)
# 3. 可视化分割结果
result = results[0]
annotated_image = result.plot(masks=True) # 绘制掩码和检测框
# 4. 保存并显示结果
plt.figure(figsize=(10, 10))
plt.imshow(cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.savefig('segmentation_result.jpg', bbox_inches='tight')
plt.show()
# 5. 提取掩码数据(可选)
masks = result.masks # 掩码张量 (n_masks, h, w)
if masks is not None:
for i, mask in enumerate(masks.data):
mask_np = mask.cpu().numpy() # 转换为NumPy数组
# 保存单个掩码
cv2.imwrite(f'mask_{i}.png', (mask_np * 255).astype('uint8'))
代码说明:
- 模型:使用YOLOv8-seg(实时实例分割模型)
- 输出:每个实例的二进制掩码(mask)、类别标签和置信度
- 后处理:掩码可用于图像编辑(如替换背景)、目标计数(掩码数量=物体数量)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)