[图挖掘]图神经网络快速上手指南 — — DGL库
[图挖掘]图神经网络快速上手指南 — — DGL库

1. 概述
1.1 什么是图神经网络 (GNN)
图神经网络 (Graph Neural Networks, GNN) 是专门用于处理图结构数据的深度学习框架。与传统的网格数据(如图像)或序列数据(如文本)不同,图数据由节点(实体)和边(关系)组成,能够自然地表示现实世界中许多复杂系统:
- 社交网络:用户为节点,关注/好友关系为边
- 分子结构:原子为节点,化学键为边
- 推荐系统:用户和商品为节点,交互行为为边
- 知识图谱:实体为节点,关系为边
GNN的核心思想是通过邻居节点传递和聚合信息来学习节点表示,使每个节点能够捕获其局部图结构的上下文信息。
1.2 什么是 DGL
DGL官方文档:https://dgl.ac.cn/dgl_docs/
Deep Graph Library (DGL) 是一个开源深度学习框架,专门用于简化图神经网络的实现和训练。它提供了以下核心优势:
- 框架无关:支持PyTorch、TensorFlow和Apache MXNet作为后端
- 高性能:针对图计算优化的内核,支持GPU加速
- 易于使用:直观的API设计,降低GNN实现门槛
- 丰富模型:内置多种经典GNN模型和常见图数据集
- 可扩展性:支持从单机到分布式的多种部署场景
常用图深度学习框架:
- 主流通用框架(首选):DGL、PyG、StellarGraph。这三个社区活跃、文档齐全,是大多数情况下的起点。
- 工业级/大规模专用框架:Euler (阿里)、AliGraph (阿里)、PGL (百度)。为解决各自业务中超大规模图(数十亿点边)的分布式训练问题而生。
- 研究型/特定方向框架:NeuGraph (将数据流与图处理结合)。这类框架常为了验证某种新系统设计思想,社区和更新可能不稳定。
- 其他:如美团的 Tulong、PSGraph等,多为公司内部自研,公开资料和社区支持相对有限。
2. 环境安装与配置
2.1 环境说明
详情参考DGL官方文档,这里说下我本地的配置:
操作系统:Mac Pro14
CPU:M3 arm64
2.2 完整安装步骤
步骤1:安装Miniconda(如未安装)
# 1. 下载Miniconda安装脚本(Apple Silicon芯片)
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
# 2. 运行安装脚本
bash Miniconda3-latest-MacOSX-arm64.sh
# 3. 按照提示完成安装,然后刷新shell配置
source ~/.zshrc # 如果使用Zsh(macOS Catalina及以后默认)
# 4. 验证安装
conda --version
步骤2:创建并配置DGL专用环境
# 1. 创建新的conda环境(使用Python 3.12)
conda create -n dgl_env python=3.12 -y
# 2. 激活环境
conda activate dgl_env
# 3. 安装PyTorch及相关依赖
# 安装pytorch依赖
conda install pytorch==2.3.1 torchdata==0.7.1 -y
# 4. 安装DGL(CPU版本)
conda install -c dglteam dgl -y
# 查看已有的虚拟环境
# conda env list
# conda env remove -n dgl_env # 删除dgl_env这个虚拟空间
步骤3:验证安装
# 运行验证脚本
python -c "
import torch
import dgl
print('='*50)
print('安装验证报告')
print('='*50)
print('PyTorch版本:', torch.__version__)
print('GL版本:', dgl.__version__)
print('='*50)
print('✅ 所有组件安装成功!')
"
3. DGL核心概念快速掌握
3.1 图的基本表示
在DGL中,图是最基础的数据结构。下面通过一个完整的示例来理解图的构建和操作:
# 安装依赖
conda install networkx matplotlib -y
完整代码:
import dgl
import torch
# 创建一个简单的有向图
# 边: 0->1, 0->2, 1->2, 2->3
src_nodes = torch.tensor([0, 0, 1, 2]) # 源节点
dst_nodes = torch.tensor([1, 2, 2, 3]) # 目标节点
# 创建图对象
g = dgl.graph((src_nodes, dst_nodes))
print("图基本信息:")
print(f" 节点数量: {g.num_nodes()}") # 输出: 4
print(f" 边数量: {g.num_edges()}") # 输出: 4
print(f" 图的ID: {g}")
print(f" 节点度: {g.in_degrees().tolist()}") # 每个节点的入度
# 添加节点和边特征
g.ndata['feature'] = torch.randn(g.num_nodes(), 5) # 每个节点5维特征
g.ndata['label'] = torch.tensor([0, 1, 0, 2]) # 节点标签
g.edata['weight'] = torch.randn(g.num_edges()) # 边权重
print("\n节点特征形状:", g.ndata['feature'].shape)
print("边特征形状:", g.edata['weight'].shape)
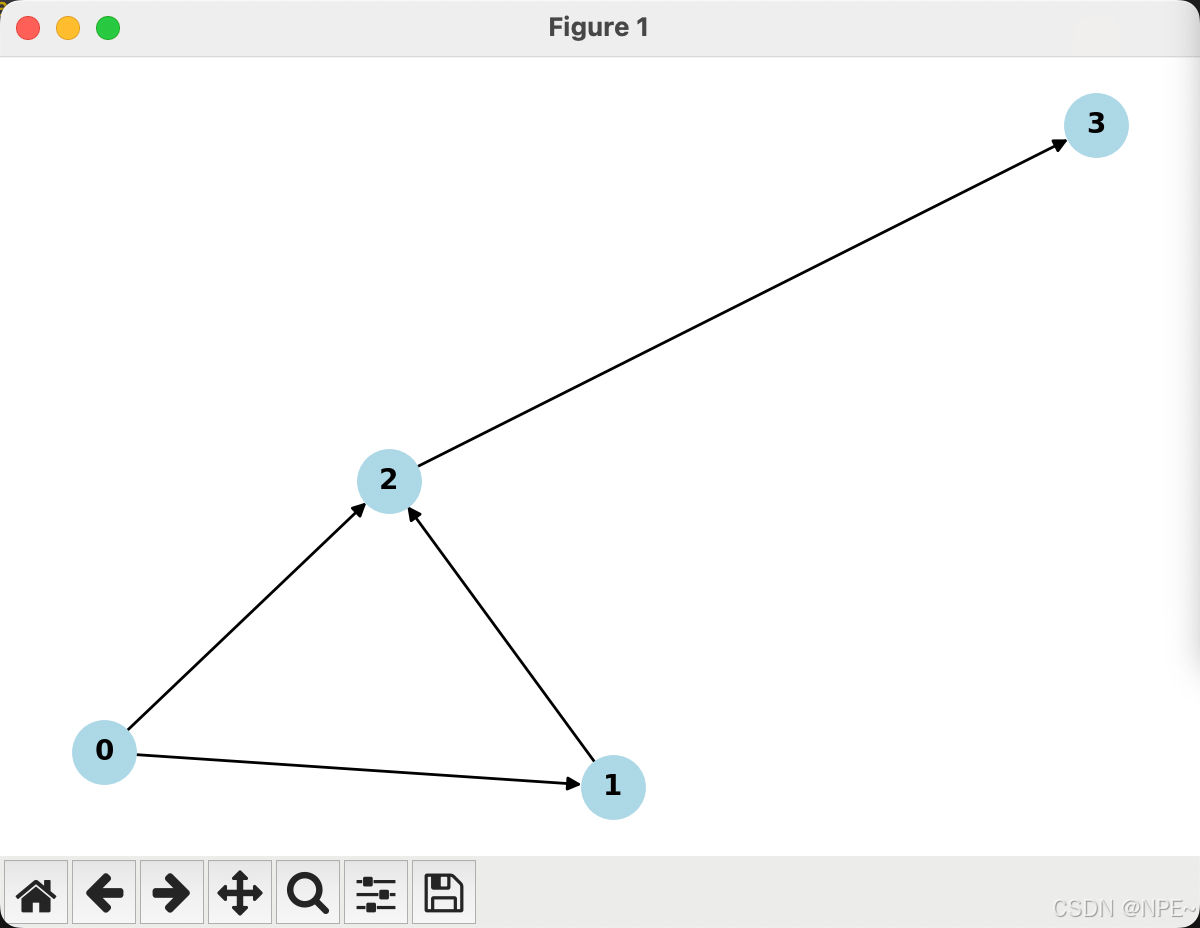
# 图的可视化(需要安装networkx)
try:
import networkx as nx
import matplotlib.pyplot as plt
nx_g = g.to_networkx()
plt.figure(figsize=(6, 4))
pos = nx.spring_layout(nx_g)
nx.draw(nx_g, pos, with_labels=True, node_color='lightblue',
node_size=500, font_size=10, font_weight='bold')
plt.title("示例图结构")
plt.show()
except ImportError:
print("\n⚠️ 安装networkx以启用可视化: pip install networkx matplotlib")
3.2 消息传递机制
消息传递是GNN的核心范式,包括三个步骤:
- 消息创建:从源节点生成消息
- 消息聚合:聚合邻居节点传来的消息
- 节点更新:用聚合后的消息更新节点状态
import dgl
import torch
import dgl.function as fn
print("=" * 50)
print("第一步:构建图结构")
print("=" * 50)
# 边列表:4条边 (0->1), (0->2), (1->2), (2->3)
edges_src = torch.tensor([0, 0, 1, 2])
edges_dst = torch.tensor([1, 2, 2, 3])
g = dgl.graph((edges_src, edges_dst))
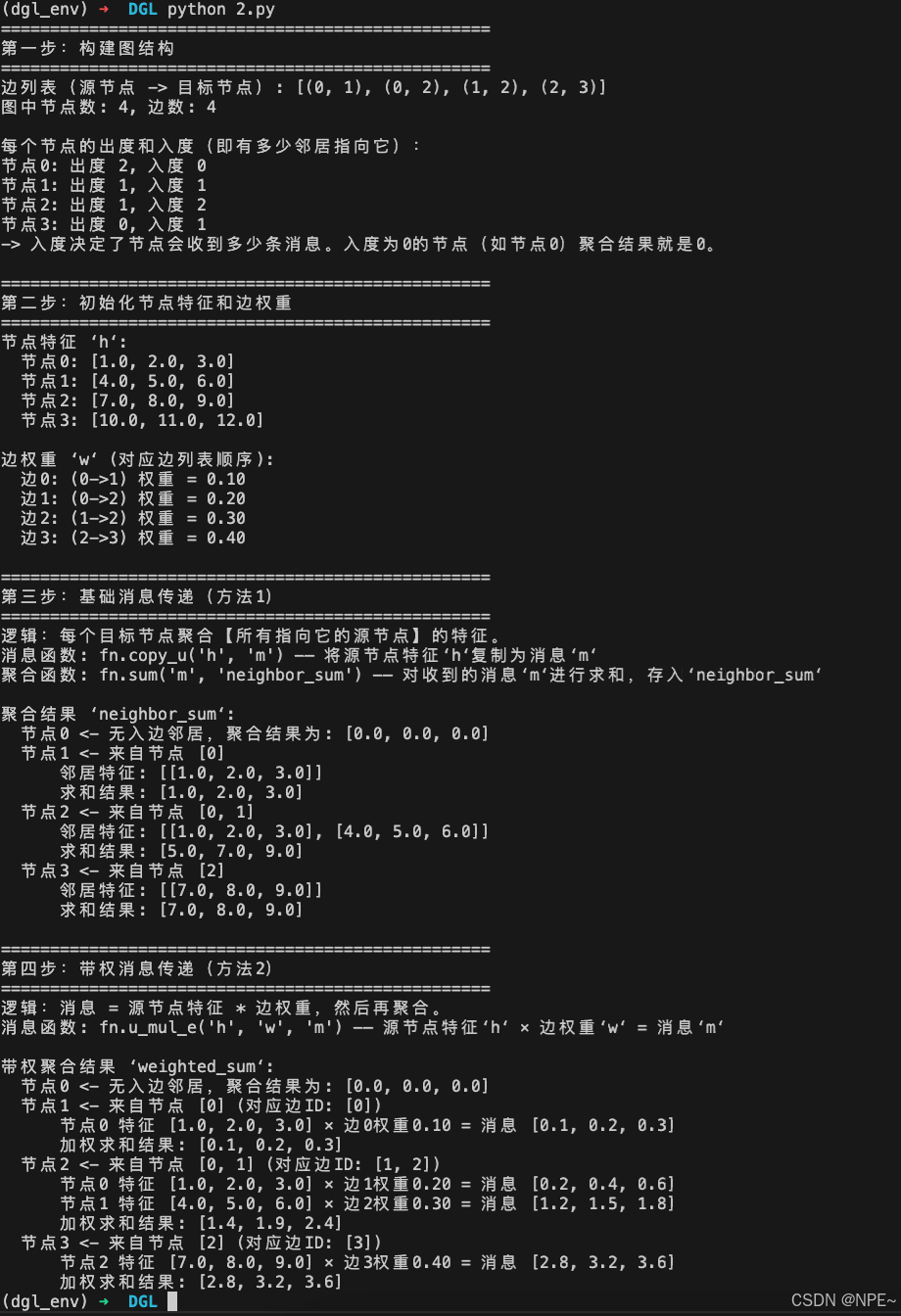
print(f"边列表(源节点 -> 目标节点): {list(zip(edges_src.tolist(), edges_dst.tolist()))}")
print(f"图中节点数: {g.num_nodes()}, 边数: {g.num_edges()}")
print("\n每个节点的出度和入度(即有多少邻居指向它):")
print(f"节点0: 出度 {g.out_degrees(0)}, 入度 {g.in_degrees(0)}")
print(f"节点1: 出度 {g.out_degrees(1)}, 入度 {g.in_degrees(1)}")
print(f"节点2: 出度 {g.out_degrees(2)}, 入度 {g.in_degrees(2)}")
print(f"节点3: 出度 {g.out_degrees(3)}, 入度 {g.in_degrees(3)}")
print("-> 入度决定了节点会收到多少条消息。入度为0的节点(如节点0)聚合结果就是0。")
print("\n" + "=" * 50)
print("第二步:初始化节点特征和边权重")
print("=" * 50)
# 固定随机种子,让每次运行结果一致,便于学习
torch.manual_seed(42)
node_features = torch.tensor([
[1.0, 2.0, 3.0], # 节点0的特征
[4.0, 5.0, 6.0], # 节点1的特征
[7.0, 8.0, 9.0], # 节点2的特征
[10.0, 11.0, 12.0] # 节点3的特征
])
edge_weights = torch.tensor([0.1, 0.2, 0.3, 0.4]) # 4条边的权重
g.ndata['h'] = node_features
g.edata['w'] = edge_weights
print("节点特征 ‘h‘:")
for i in range(g.num_nodes()):
print(f" 节点{i}: {g.ndata['h'][i].tolist()}")
print("\n边权重 ‘w‘ (对应边列表顺序):")
for i in range(g.num_edges()):
src, dst = edges_src[i].item(), edges_dst[i].item()
print(f" 边{i}: ({src}->{dst}) 权重 = {edge_weights[i]:.2f}")
print("\n" + "=" * 50)
print("第三步:基础消息传递(方法1)")
print("=" * 50)
print("逻辑:每个目标节点聚合【所有指向它的源节点】的特征。")
print("消息函数: fn.copy_u('h', 'm') —— 将源节点特征‘h‘复制为消息‘m‘")
print("聚合函数: fn.sum('m', 'neighbor_sum') —— 对收到的消息‘m‘进行求和,存入‘neighbor_sum‘")
# 在局部作用域内操作,不影响原始特征
with g.local_scope():
g.ndata['h'] = node_features
g.update_all(fn.copy_u('h', 'm'), fn.sum('m', 'neighbor_sum'))
print("\n聚合结果 ‘neighbor_sum‘:")
for i in range(g.num_nodes()):
# 找出当前节点i的所有入边邻居(消息发送者)
in_edges = g.in_edges(i)
if in_edges[0].numel() > 0:
src_nodes = in_edges[0].tolist()
neighbor_features = [g.ndata['h'][src].tolist() for src in src_nodes]
print(f" 节点{i} <- 来自节点 {src_nodes}")
print(f" 邻居特征: {neighbor_features}")
print(f" 求和结果: {g.ndata['neighbor_sum'][i].tolist()}")
else:
print(f" 节点{i} <- 无入边邻居,聚合结果为: {g.ndata['neighbor_sum'][i].tolist()}")
print("\n" + "=" * 50)
print("第四步:带权消息传递(方法2)")
print("=" * 50)
print("逻辑:消息 = 源节点特征 * 边权重,然后再聚合。")
print("消息函数: fn.u_mul_e('h', 'w', 'm') —— 源节点特征‘h‘ × 边权重‘w‘ = 消息‘m‘")
with g.local_scope():
g.ndata['h'] = node_features
g.edata['w'] = edge_weights
g.update_all(fn.u_mul_e('h', 'w', 'm'), fn.sum('m', 'weighted_sum'))
print("\n带权聚合结果 ‘weighted_sum‘:")
for i in range(g.num_nodes()):
in_edges = g.in_edges(i)
if in_edges[0].numel() > 0:
src_nodes = in_edges[0].tolist()
edge_ids = g.edge_ids(src_nodes, [i]*len(src_nodes)).tolist()
print(f" 节点{i} <- 来自节点 {src_nodes} (对应边ID: {edge_ids})")
for src, eid in zip(src_nodes, edge_ids):
feat = g.ndata['h'][src].tolist()
weight = g.edata['w'][eid].item()
weighted_msg = [f * weight for f in feat]
print(f" 节点{src} 特征 {feat} × 边{eid}权重{weight:.2f} = 消息 {[round(x,2) for x in weighted_msg]}")
print(f" 加权求和结果: {[round(x,4) for x in g.ndata['weighted_sum'][i].tolist()]}")
else:
print(f" 节点{i} <- 无入边邻居,聚合结果为: {g.ndata['weighted_sum'][i].tolist()}")
4. 实践项目:Cora数据集节点分类
4.1 项目简介
Cora数据集是图神经网络领域的"MNIST",包含:
- 2708个学术论文(节点)
- 5429个引用关系(边):该论文是否被其他论文引用、被引用
- 1433维词袋特征(节点特征):每篇论文的特征是通过词袋模型得到的,维度为1433,每一维表示一个词,1表示该词在这篇文章中出现过,0表示未出现。
- 7个类别(节点标签):论文被根据主题划分为7类,分别是神经网络、强化学习、规则学习、概率方法、遗传算法、理论研究、案例相关。
我们的目标:基于论文的引用关系和内容,预测论文所属的研究领域。
4.2 完整实现代码
机器学习最经典的三大方向:
- 回归方法:房价预测、股票走势等
- 分类方法:图像识别等,哪个是猫、哪个是狗
- 聚类方法:新闻聚类、文章推荐、客户分群
此次我们会采用图神经网络中经典GCN模型来实现我们的分类任务。
图神经网络GNN常见模型:GCN、GAT、GraphSAGE
官方教程:https://dgl.ac.cn/dgl_docs/tutorials/blitz/1_introduction.html#sphx-glr-tutorials-blitz-1-introduction-py
- 前向传播:就像一个学生(模型)拿到考卷(数据),凭借自己现有的知识(参数)写出答案(预测结果)的过程。
- 反向传播:就像试卷改完了之后发下来,学生发现刚刚考试的时候哪里错了(计算损失),然后开始修正自己对知识的认知(更新参数),以便下次考得更好。
代码实现:
# ============ 1. 环境与数据准备 ============
import os
os.environ["DGLBACKEND"] = "pytorch" # 设置DGL后端为PyTorch
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
# 加载Cora数据集(一个学术论文引用网络)
dataset = dgl.data.CoraGraphDataset()
print(f"数据集类别数: {dataset.num_classes}")
# 获取图数据
g = dataset[0]
print("\n图结构信息:")
print(f" 节点数: {g.num_nodes()}, 边数: {g.num_edges()}")
print(f" 节点特征维度: {g.ndata['feat'].shape[1]}")
print(f" 标签类别数: {dataset.num_classes}")
# 查看数据划分掩码(哪些节点用于训练/验证/测试)
print("\n数据划分:")
print(f" 训练节点数: {g.ndata['train_mask'].sum().item()}")
print(f" 验证节点数: {g.ndata['val_mask'].sum().item()}")
print(f" 测试节点数: {g.ndata['test_mask'].sum().item()}")
# ============ 2. 定义GCN模型 ============
from dgl.nn import GraphConv
class GCN(nn.Module):
"""一个两层的图卷积网络"""
def __init__(self, in_feats, h_feats, num_classes):
super(GCN, self).__init__()
# 第一层:将输入特征转换为隐藏层特征
self.conv1 = GraphConv(in_feats, h_feats)
# 第二层:将隐藏层特征转换为类别得分
self.conv2 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feat):
"""前向传播:像流水线一样处理特征"""
# 第一层GCN:聚合一阶邻居信息
h = self.conv1(g, in_feat)
h = F.relu(h) # 激活函数引入非线性
# 第二层GCN:聚合二阶邻居信息(通过邻居的邻居)
h = self.conv2(g, h)
return h # 输出每个节点的类别得分(logits)
# 创建模型实例
model = GCN(g.ndata["feat"].shape[1], 16, dataset.num_classes)
print(f"\n模型结构: 输入维度({g.ndata['feat'].shape[1]}) → 隐藏层(16) → 输出({dataset.num_classes})")
# ============ 3. 训练过程详解 ============
def train(g, model):
# 3.1 准备训练组件
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 优化器:调整模型参数
best_val_acc = 0
best_test_acc = 0
# 获取数据
features = g.ndata["feat"] # 所有节点的特征矩阵
labels = g.ndata["label"] # 所有节点的真实标签
train_mask = g.ndata["train_mask"] # 训练节点标识
val_mask = g.ndata["val_mask"] # 验证节点标识
test_mask = g.ndata["test_mask"] # 测试节点标识
print("\n开始训练...")
print("=" * 60)
for epoch in range(100): # 进行100轮训练
# ------ 前向传播:模型推理 ------
# 关键:GCN一次性处理图中所有节点,利用图结构聚合邻居信息
logits = model(g, features) # 输出:每个节点对应各类别的得分
# 预测类别:选择得分最高的类别
pred = logits.argmax(1)
# ------ 计算损失:模型表现量化 ------
# 仅计算训练节点的损失(这是半监督学习的特点)
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# ------ 计算准确率:监控训练进度 ------
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# 保存最佳验证结果对应的测试准确率
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# ------ 反向传播与优化:改进模型 ------
optimizer.zero_grad() # 清零梯度(防止梯度累积)
loss.backward() # 计算梯度(找出各参数对损失的影响程度)
optimizer.step() # 更新参数(沿梯度反方向调整参数)
# 每5轮打印一次进度
if epoch % 5 == 0:
print(f"轮次 {epoch:3d} | 损失: {loss:.3f} | "
f"验证准确率: {val_acc:.3f} (最佳 {best_val_acc:.3f}) | "
f"测试准确率: {test_acc:.3f} (最佳 {best_test_acc:.3f})")
print("=" * 60)
print(f"训练结束!最终测试准确率: {best_test_acc:.3f}")
# ============ 4. 开始训练 ============
train(g, model)
# ============ 5. 模型使用示例 ============
# 训练完成后,模型可用于预测新节点(但需要这些节点已嵌入图中)
print("\n如何使用训练好的模型:")
print("1. 获取任意节点的特征(需确保这些节点在图g中)")
print("2. 调用 model(g, features) 获取预测结果")
print("3. 使用 .argmax(1) 获取预测类别")
# 示例:查看前10个节点的预测结果
model.eval() # 设置模型为评估模式
with torch.no_grad():
logits = model(g, g.ndata["feat"])
predictions = logits.argmax(1)
print(f"\n前10个节点的预测类别: {predictions[:10].tolist()}")
print(f"前10个节点的真实类别: {g.ndata['label'][:10].tolist()}")
结果: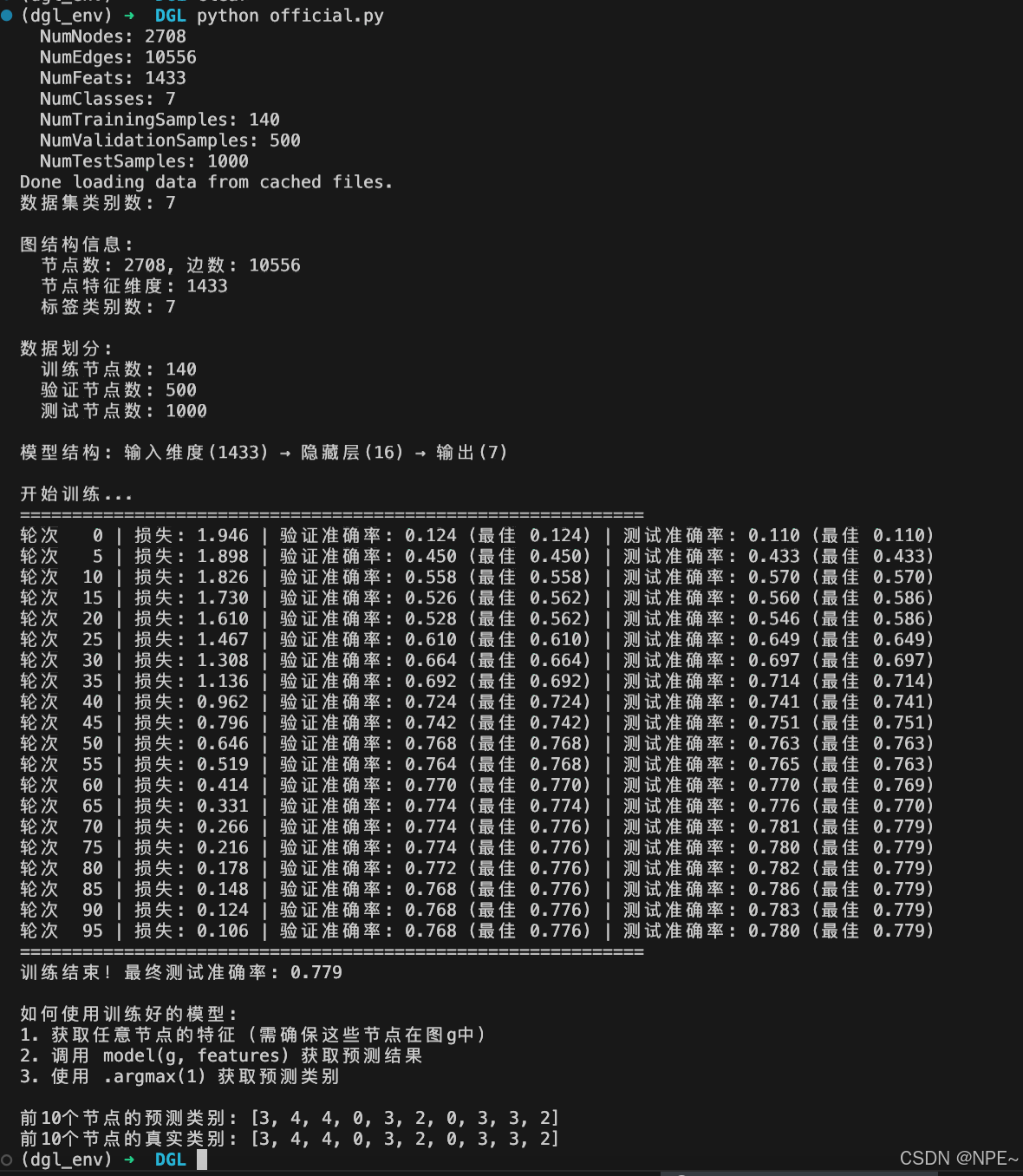
性能优化建议:
- 调整超参数:尝试不同的隐藏层维度(32, 64)、学习率(0.005, 0.001)
- 增加层数:尝试3层GCN(注意过平滑问题)
- 使用更先进的模型:GAT、GraphSAGE等,例如:把上面模型定义部分的GraphConv换成SAGEConv即可。
可用模型参考:https://dgl.ac.cn/dgl_docs/api/python/nn-pytorch.html
- 添加正则化:增加dropout率、L2正则化强度
5. 进阶学习路线
5.1 核心概念深入学习
| 主题 | 关键内容 | 学习资源 |
|---|---|---|
| 异构图 | 多种节点/边类型,关系表示 | dgl.heterograph,dgl.nn.HeteroGraphConv |
| 图采样 | 大规模图处理,邻居采样 | dgl.dataloading,NeighborSampler |
| 自监督学习 | 图对比学习,预训练 | DGL的GraphCL示例 |
| 动态图 | 时间演化图处理 | dgl.temporal,动态GNN |
5.2 实战项目建议
-
入门项目:Cora/PubMed节点分类(已完成)
-
中级项目:
- 使用GraphSAGE在Reddit数据集上进行社区预测
- 使用GAT进行知识图谱链接预测
-
高级项目:
- 实现图自编码器进行异常检测
- 在OGB(Open Graph Benchmark)基准测试上复现SOTA模型

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)